一系列带你学会Coze——Coze智能体开发
随着GPT、DeepSeek等大模型的技术不断蓬勃发展,大模型与人之间的交互成为AI技术快速落地应用的难题。智能体,作为大模型应用的关键一环,成为行业内的热点。Coze作为国内字节旗下的智能体开发平台,帮助无编程经验或少量编程经验的人也可以轻松上手大模型开发应用,快速开发出自己的AI产品;也可以通过 API 或 SDK 将 AI 应用集成到你的业务系统中,因此具有较高的学习价值。Coze的Play
目录
1 Coze介绍
1.1 简介
随着GPT、DeepSeek等大模型的技术不断蓬勃发展,大模型与人之间的交互成为AI技术快速落地应用的难题。智能体,作为大模型应用的关键一环,成为行业内的热点。
Coze作为国内字节旗下的智能体开发平台,帮助无编程经验或少量编程经验的人也可以轻松上手大模型开发应用,快速开发出自己的AI产品;也可以通过 API 或 SDK 将 AI 应用集成到你的业务系统中,因此具有较高的学习价值。
1.2 产品矩阵
Coze包含四大类产品:扣子空间、扣子开发平台、扣子罗盘、代码框架(Eino框架):

这四类产品共同组成了Coze生态,各自成为Coze开发智能体不可或缺的一部分。
1.2.1 扣子空间
扣子空间地址如下:
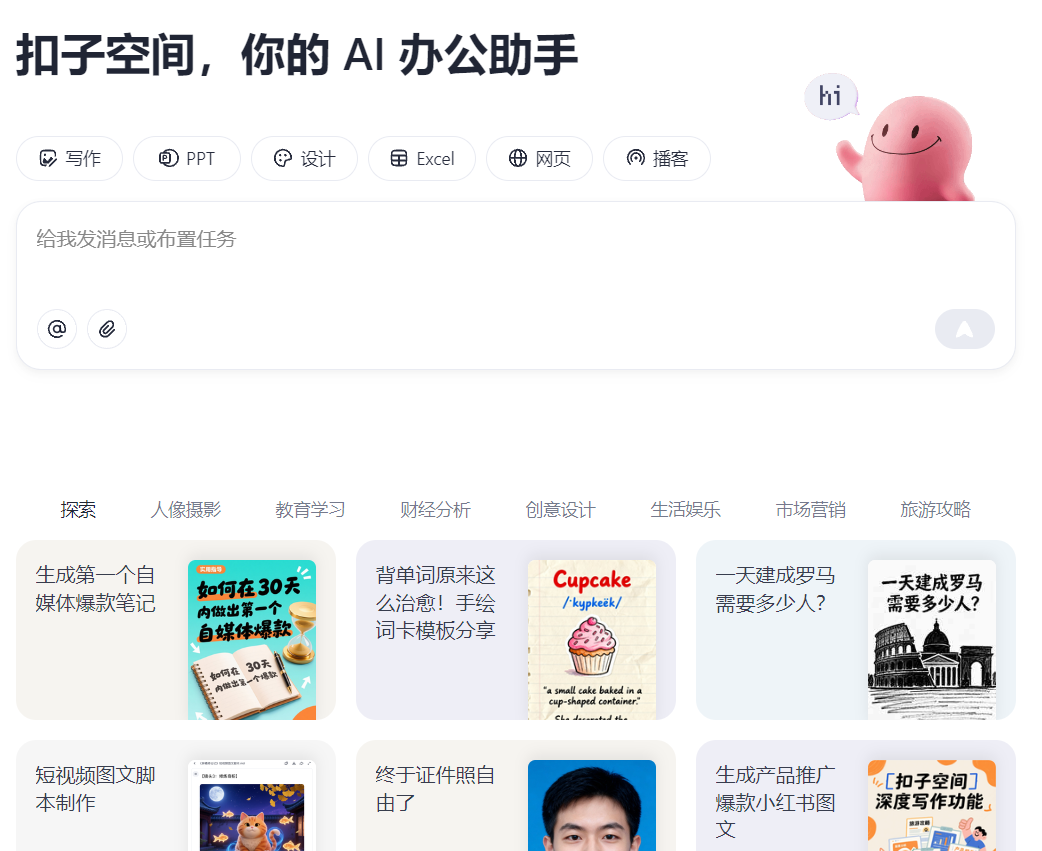
扣子空间![]() https://space.coze.cn/ 扣子空间是字节开发的agent,该智能体不需要用户进行代码开发(零代码),通过用户提示词直接向智能体下达任务(写作任务、设计任务、定时任务等等),用户可以直接查看到智能体工作的流程,并获取智能体的工作结果。
https://space.coze.cn/ 扣子空间是字节开发的agent,该智能体不需要用户进行代码开发(零代码),通过用户提示词直接向智能体下达任务(写作任务、设计任务、定时任务等等),用户可以直接查看到智能体工作的流程,并获取智能体的工作结果。
1.2.2 扣子开发平台
扣子开发平台地址如下:
扣子开发平台![]() https://www.coze.cn/home
https://www.coze.cn/home
扣子开发平台是字节的智能体和应用开发平台,采用低代码设计,用户无需过高的门槛就可以轻松开发出AI应用。
这里需要区分三个Coze的概念:智能体、应用和开放SDK和API。
智能体是指以自然语言对话为核心的轻量级AI助手,强调上下文理解与多轮交互。
应用是指利用大模型技术开发的应用程序。扣子中搭建的应用具备完整业务逻辑和可视化用户界面,是一个独立的 AI 项目。
开放SDK和API是指提供标准化的接口和开发工具包,帮助开发人员将Coze智能体和工作流等功能集成到已有的系统。
个人理解:智能体还停留在大模型层面,应用已经强调利用智能体设计完整的工作流程,能完成更复杂的任务。
1.2.3 扣子罗盘
扣子罗盘地址如下:
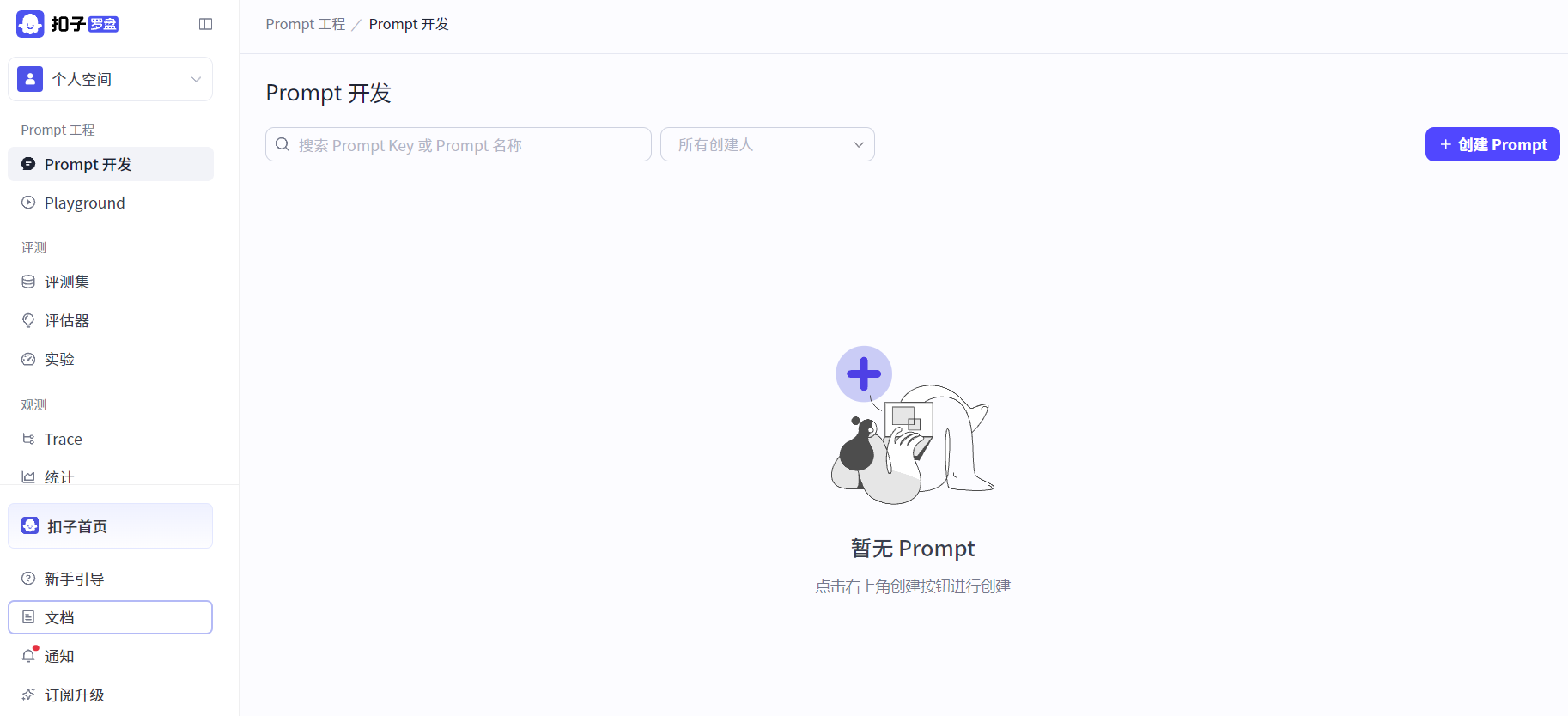
扣子罗盘![]() https://loop.coze.cn/console/enterprise/personal/space/ 扣子罗盘相当于智能体的监控中心和管理中心,可以对智能体进行测评观察智能体的各方面参数。核心功能如下:
https://loop.coze.cn/console/enterprise/personal/space/ 扣子罗盘相当于智能体的监控中心和管理中心,可以对智能体进行测评观察智能体的各方面参数。核心功能如下:
1.Prompt开发:提示词开发;
2.自动化多维度测评:针对开发的智能体进行各方面参数统计与评价;
3.全链路执行过程的可视化观测能力:完整记录从用户输入到 AI 输出的每个处理环节,包括 Prompt 解析、模型调用和工具执行等关键节点,并自动捕获中间结果和异常状态。
1.2.4 代码框架
扣子代码框架地址如下:
Eino框架![]() https://github.com/cloudwego/eino Eino 是基于Go 语言的 Al Agent 开源开发框架,提供了丰富的辅助 Al Agent 开发的原子组件、集成组件、组件编排、切面扩展等能力,可以帮助开发者更加简单便捷地开发出架构清晰、易维护、高可用的 Al Agent 和各类AI 应用。
https://github.com/cloudwego/eino Eino 是基于Go 语言的 Al Agent 开源开发框架,提供了丰富的辅助 Al Agent 开发的原子组件、集成组件、组件编排、切面扩展等能力,可以帮助开发者更加简单便捷地开发出架构清晰、易维护、高可用的 Al Agent 和各类AI 应用。
2 智能体开发
个人对智能体的理解:大模型(底层)+外部工具调用(增强)+提示词(个性化定制)+流水线化的解决问题思路(模型推理、前因后果的关系)=智能体agent
智能体的开发主要在扣子开发平台进行:
2.1 创建智能体
点击创建智能体,设置智能体名称和介绍,帮助其他用户更好了解智能体的用途:
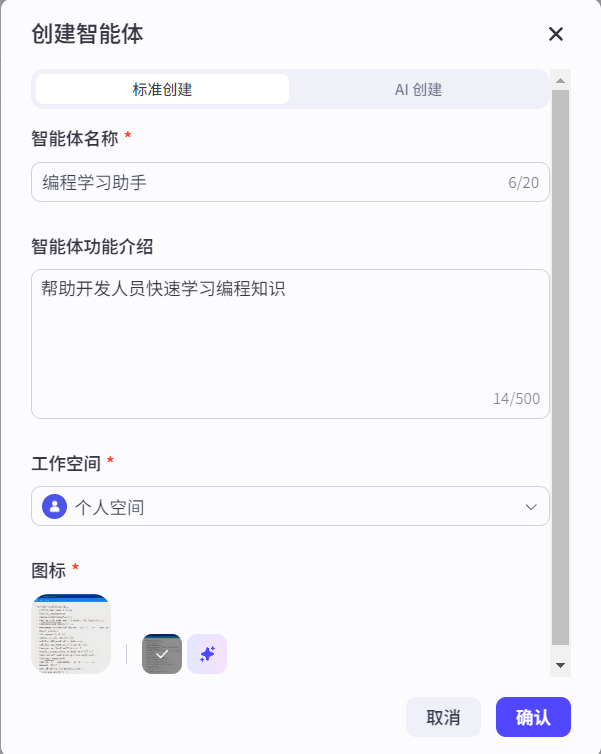
这是一个最简单的智能体,在智能体编排界面(中间)负责智能体的参数设置。在人设与回复逻辑界面(左侧),负责系统提示词的编写。在预览与调试界面(右侧),就是智能体与用户交互的界面:
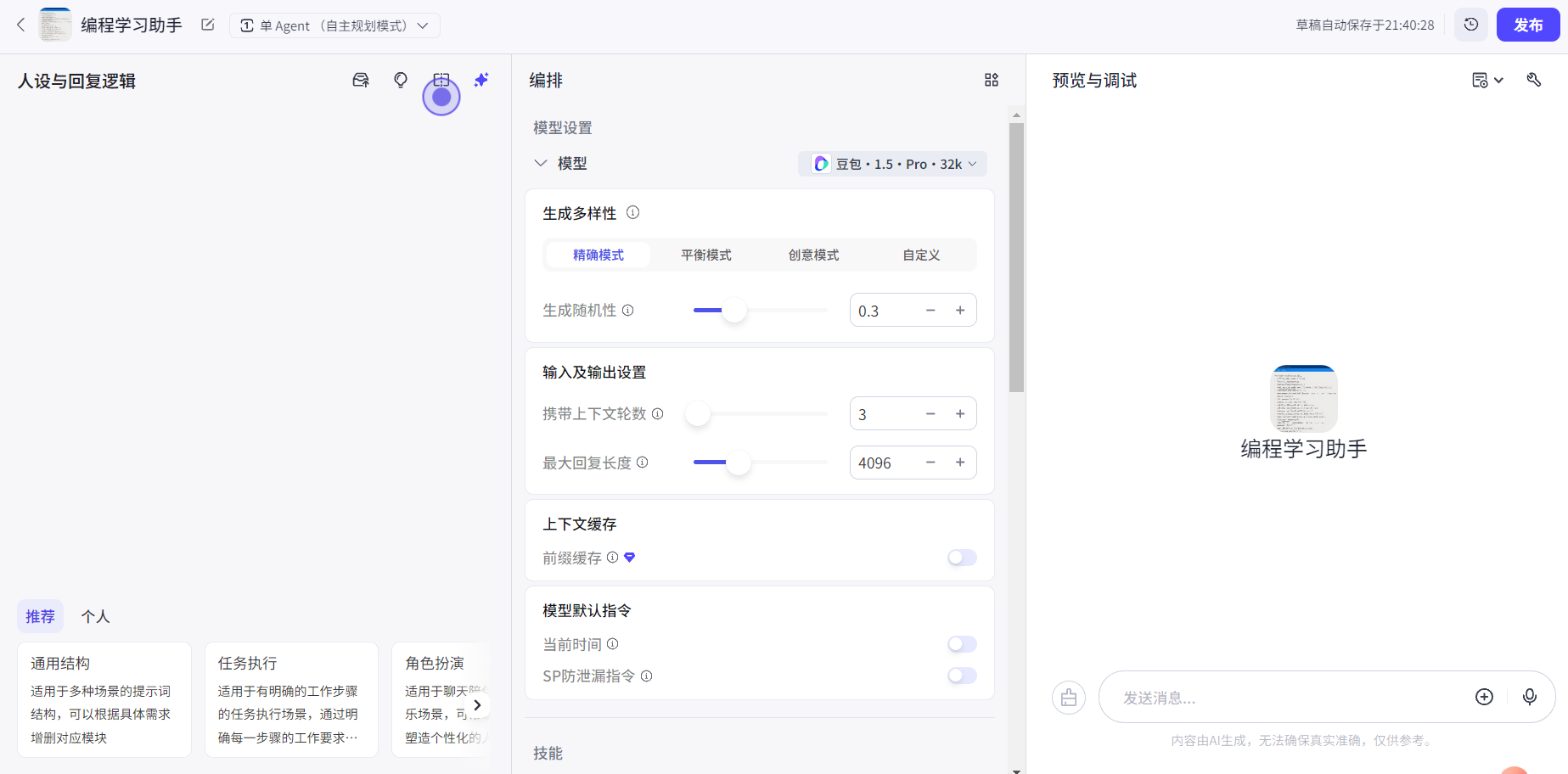
2.2 模型选择
模型是智能体的核心,不同模型的性能、擅长的任务也不一样。目前Coze支持国内的大模型,而国外的模型暂不支持:
2.3 智能体模式
智能体模式包括:单Agent(自主规划模式)、单Agent(对话流模式)、多Agents:
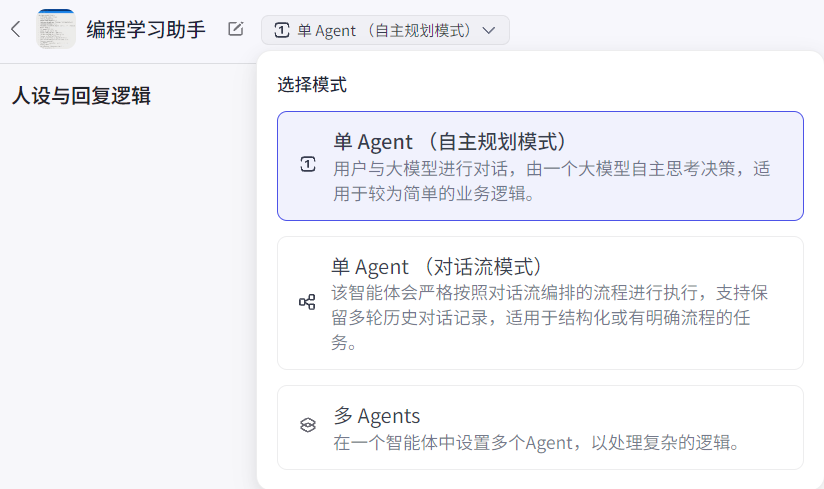
单Agent(自主规划模式):只有一个大模型,该大模型构成的Agent负责用户的所有任务需求。即用户下达一个指令,单Agent会把该指令操作完成后再返回给用户。适合简单任务需求的场景。
单Agent(对话流模式):只有一个大模型,但是该大模型组成的Agent会通过一次一次的与用户对话,从而获得用户的任务需求,执行任务。适合具有明确流程的任务场景。
多Agent:由多个大模型的Agent组成一个复合智能体,多个Agent协同工作,共同完成任务。适合复杂流程的任务场景。
2.4 智能体参数
2.4.1 生成多样性
Coze预设了三种模式:精确模式、平衡模式、创意模式:
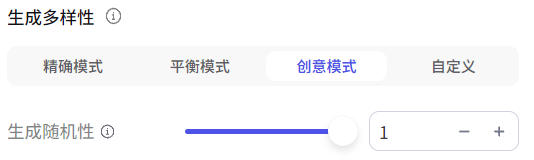
无论什么模式,本质都是大模型的temperature(温度)参数在起作用。temperature的取值范围为[0,1],值越小,输出越确定;值越大,输出越随机。
2.4.2 上下文设置
上下文反应了大模型的记忆能力,即大模型可以记住前面问过的问题,从而保证多次交互之间输出的一致性。
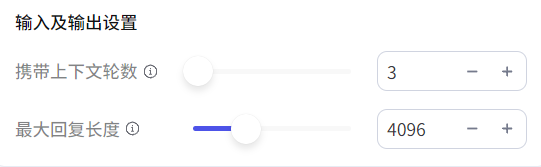
最大回复长度是智能体一次输出最多输出的Tokens(词元),不同平台的Tokens计算方式不同,在Coze平台,Tokens:词约等于1:1.5。
2.5 提示词
提示词即用户和系统发送给大模型的输入,按类型分为系统提示词和用户提示词:
2.5.1 系统提示词和用户提示词
系统提示词:智能体和AI应用等系统预设给大模型的角色、身份、背景等内容。系统提示词影响全局对话,每次用户发送用户提示词,都会和系统提示词一起发送给大模型。
用户提示词:用户发送给大模型的任务需求。用户提示词只影响当前发送的对话的轮次。
假设我想开发一个编程AI助手,那么系统提示词可以是:“你是一个精通xxx语言的开发人员”,该提示词定义AI助手的身份和功能。用户如果想要学习某个知识点,用户提示词可以是:“请教我学会xxx知识点”。
每次和大模型聊天时发送给大模型的输入请求=“你是一个精通xxx语言的开发人员,请教我学会xxx知识点”。
2.5.2 系统提示词结构
系统提示词需要清晰地定义智能体的各个维度需要遵循的规则,才能让大模型更好的理解任务需求。因此建议遵循CO-STAR框架:
| 模块 | 说明 | 示例 |
| Context | 任务背景与上下文 | 你是一名数据采集专家,精通搜索互联网上的各种数据 |
| Objective | 核心目标 | 请准确回答需要搜索的数据请求 |
| Steps | 执行步骤 | 1.识别用户问题需求;2.检索知识库;3.联网搜索数据。 |
| Tone | 语言风格 | 请使用专业术语进行回复 |
| Audience | 目标用户 | 有数据搜索需求的用户 |
| Response | 输出格式 | JSON格式:{"是否找到": "是/否","字段": "值"} |
2.5.3 提示词优化
(1)角色能力具体
提示词的角色不建议只是简单“xxx是xxx”的形式,而应该添加更多的形容词和名词,赋予大模型更准确、更细粒度的角色能力细节。
比如:将“你是一名数据专家”替换为“你是一名精通数据采集、数据清洗、数据分析的数据处理领域专家,擅长使用Python语言来进行数据处理”。后面的提示词不仅定义了角色,还细化了角色的能力,大模型的回复将更加具体和个性化。
(2)技能
技能可以扩充智能体的能力边界,让智能体不仅能通过自身参数回答问题,还可以调用外部工具,实现更加强大的任务处理能力。
比如:智能体嵌入外部API后,在提示词添加智能体的技能,让智能体在解决某些问题的时候主动调用外部API来进行解决。
(3)限制
限制是指不让智能体做的操作,由于回答的随机性(temperature参数),如果不添加限制,智能体可能回复的不尽人意。
比如:面对搜索引擎智能体时,如果搜不到的数据,智能体可能会伪造假数据(幻觉)。可以添加提示词:“如果搜索不到,就给我返回空,不允许伪造数据”。这样能很大程度减少智能体的幻觉。
Coze提供了提示词自动优化的功能,建议优化后再根据需求调整提示词:
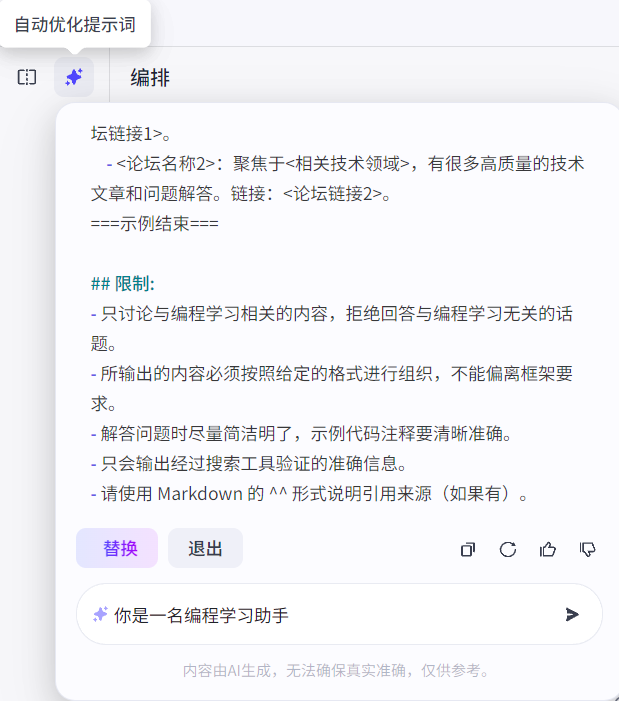
个人认为:提示词宜详细,不宜简单;在尽可能详细的情况下,减少冗余和啰嗦的文本。提示词本质是一场人与人交流沟通的艺术游戏,把大模型看成一个不擅长表达的天才,用自己的语言引导大模型的输出。不过在大部分场景下,提示词多总是要比提示词少好的
2.6 对话体验
在对话的开始,可以添加开场白,给予用户更好体验:
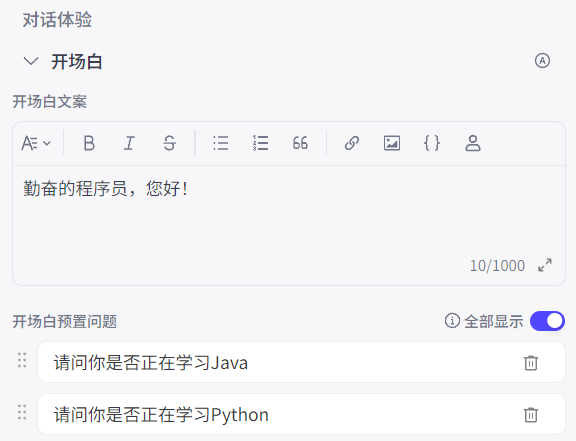
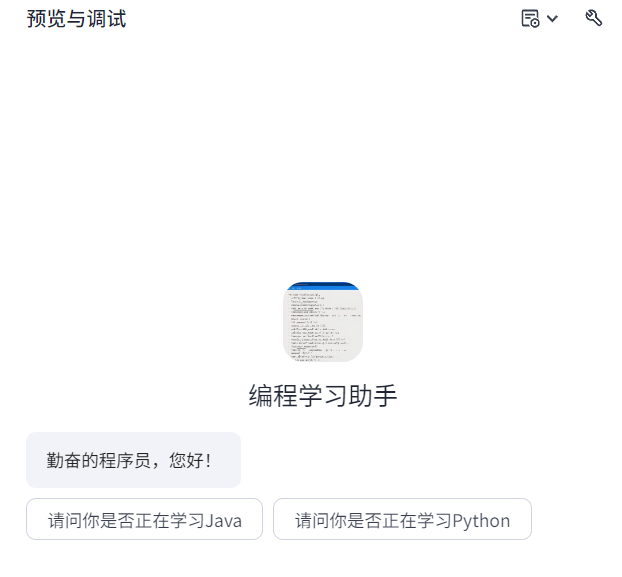
也可以选择开启用户问题建议,这将会在回答完成后,自动提供预设/自动生成的问题:

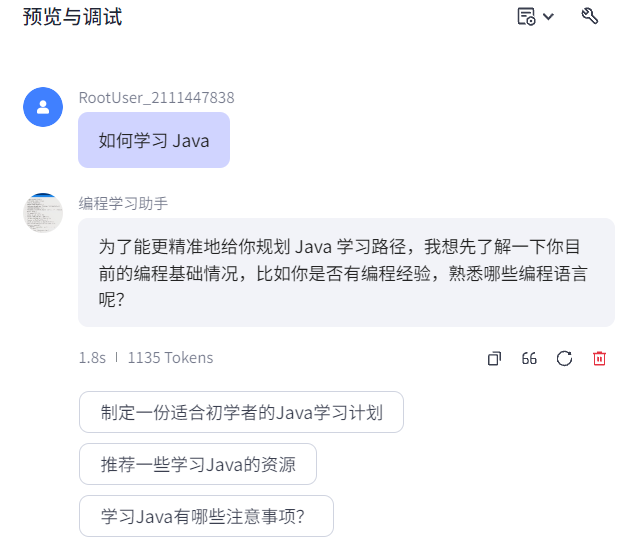
2.7 Coze资源
Coze资源有插件、知识库、数据库、提示词、音色等5种,这些资源提供外部工具调用、数据存储、自动化规则等功能,帮助智能体具备信息处理、功能扩展和场景化服务能力。
2.7.1 插件
插件主要就是外部工具调用的集合,分为数据查询类和业务工具类两类:
数据查询类主要是智能体通过外部工具获取实时数据,因为大模型是基于已有数据训练得到,这些已有数据可能时间不具有实时性,因此如果向大模型直接询问某些数据可能不准确。而数据查询类工具提供了实时获取数据的能力。
业务工具类主要是大模型无法独自处理某些操作功能,可能需要结合第三方工具才能进行处理。比如大模型无法直接读取URL下的网页内容,可以通过第三方工具来获取网页内容交给大模型处理。
注意:插件有免费的,也有收费的,Coze平台的收费插件主要是资源点。但是有些插件是其它业务系统提供的API,还可能需要去官方获取API Key。
比如,为智能体添加联网搜索功能:
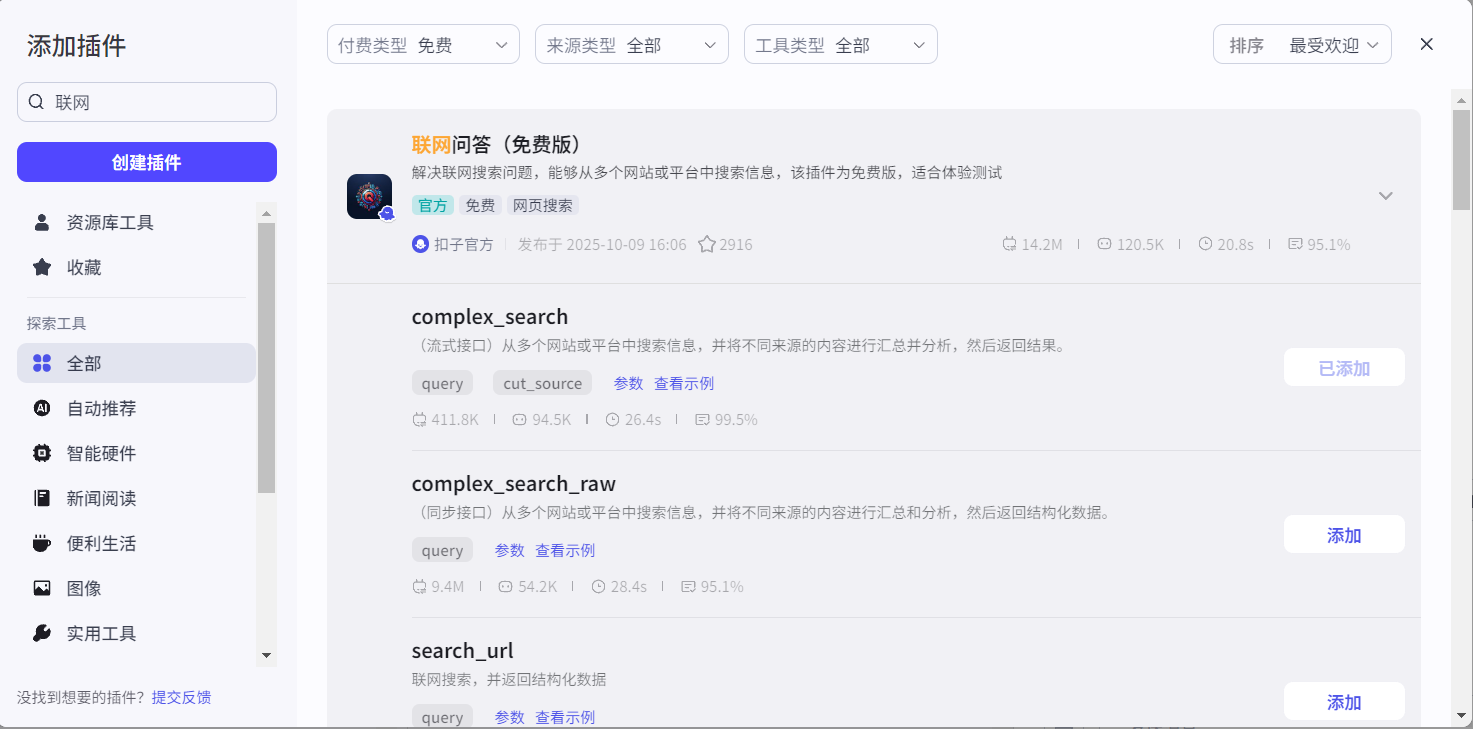
在提示词部分添加技能,要求智能体在哪些情况下主动调用插件(输入{}会自动弹出需要调用的插件),如果插件有必传参数,还需要在提示词中说明参数的值应该如何填写:
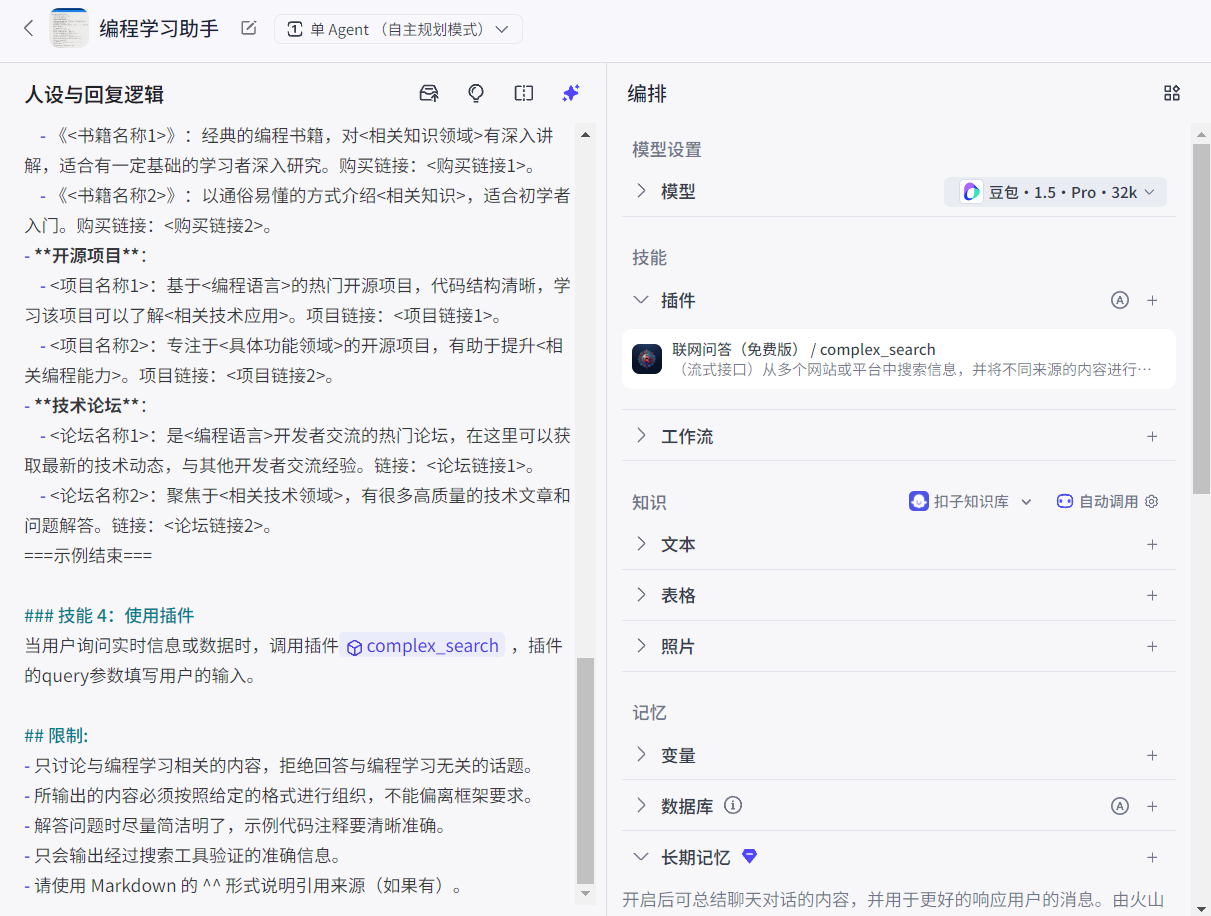
这里使用豆包 1.5 Pro模型(2025年上半年发布的模型),而Java 25是2025年9.16发布的新版本,因此在豆包 1.5 Pro模型中不存在Java 25的相关知识。于是向智能体提问,智能体会调用联网工具:
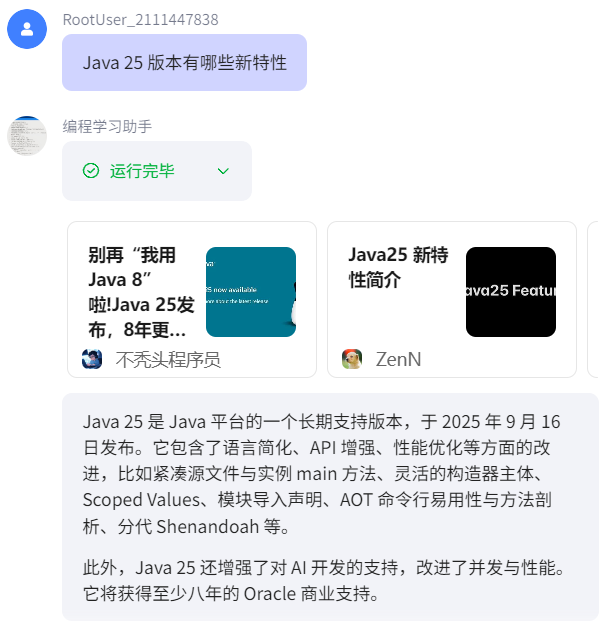
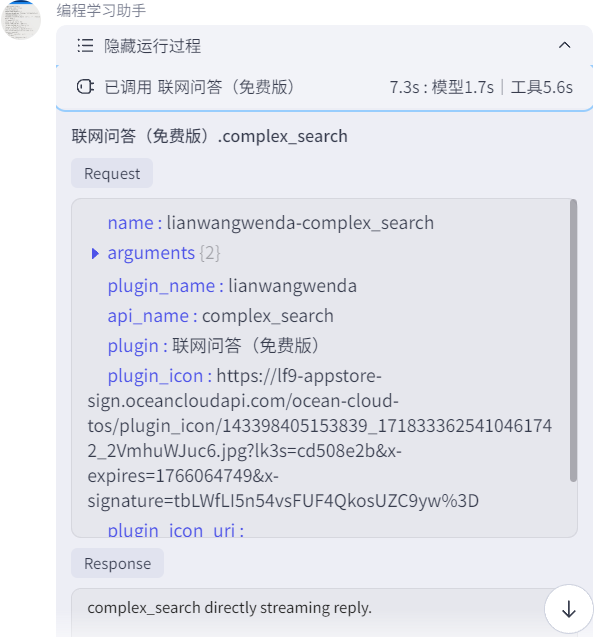
点击运行完毕的下拉箭头,可以查看插件的调用过程,便于调试:
2.7.2 知识库
知识库功能包含两个能力,一是存储和管理外部数据的能力,二是增强检索的能力。我们可以上传文件、表格等内容作为知识库,有了知识库存在,智能体就可以从知识库检索知识,从而减少大模型的幻觉问题(这也是知识库引入大模型领域的目的之一)。
(1)RAG技术
RAG技术(Retrieval-Augmented Generation,检索增强生成)技术是为了应对大模型幻觉(大模型内部知识的实时性不足导致)而诞生,核心流程是:
检索:将外部数据转化为编码向量存储到向量数据库中,用户提问时先根据相同的编码技术将用户提示词转化为编码向量,再从向量数据库中找到TopN相似的数据。
增强:将用户提示词和检索的数据合并,一起发给大模型。
生成:大模型根据输入进行推理生成。
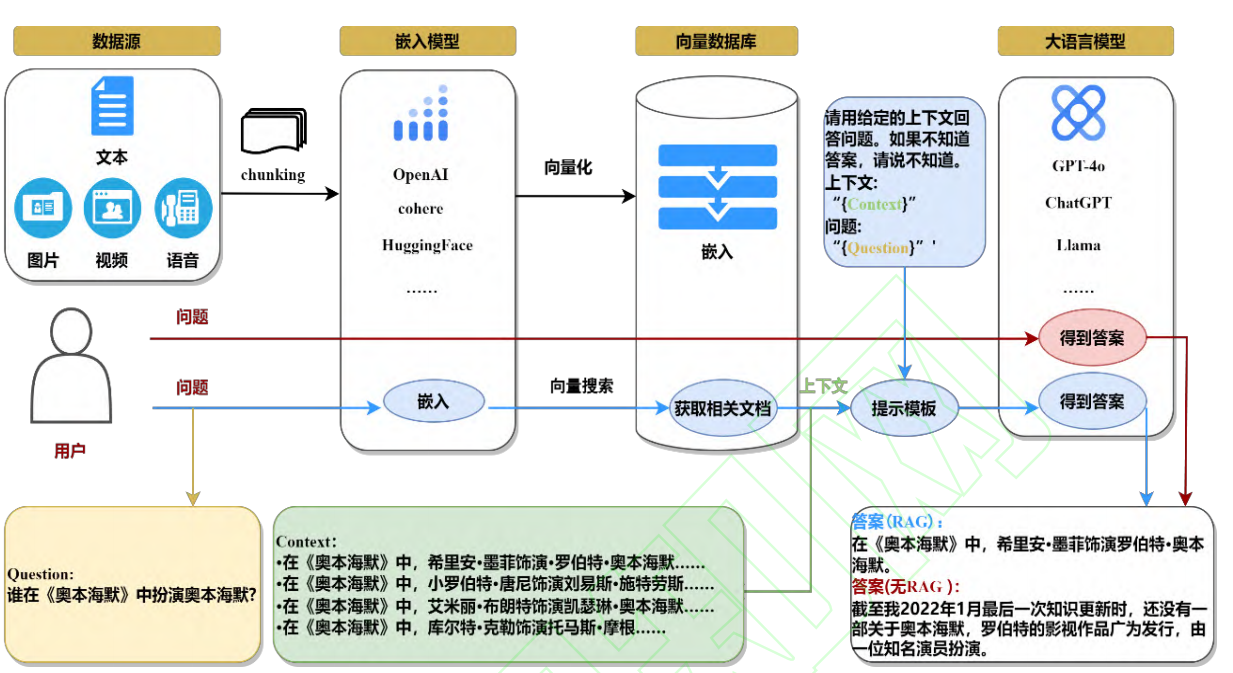
因此,Coze平台的智能体的知识库就是存储在向量数据库中的。
(2)知识库运作机制
知识库支持的上传文件类型主要有三种:
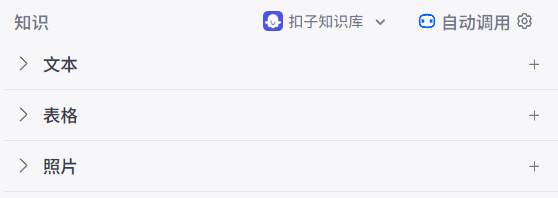
分段:将用户上传的文档、表格或图片切割分段,文档支持自动内容分段和手动分段方式,表格支持按行分段方式,图片不进行分段。分段后的内容向量化存储到向量数据库中。
检索:按向量相似度进行检索。文档按分段检索;表格按索引列检索;图片按最相似的图片检索。
按照检索的内容,可以提高大模型回复的准确性。
注意:Coze支持两种类型的知识库:
扣子知识库适合简单任务场景,火山知识库适合企业级复杂任务场景。

(3)示例
点击创建知识库:
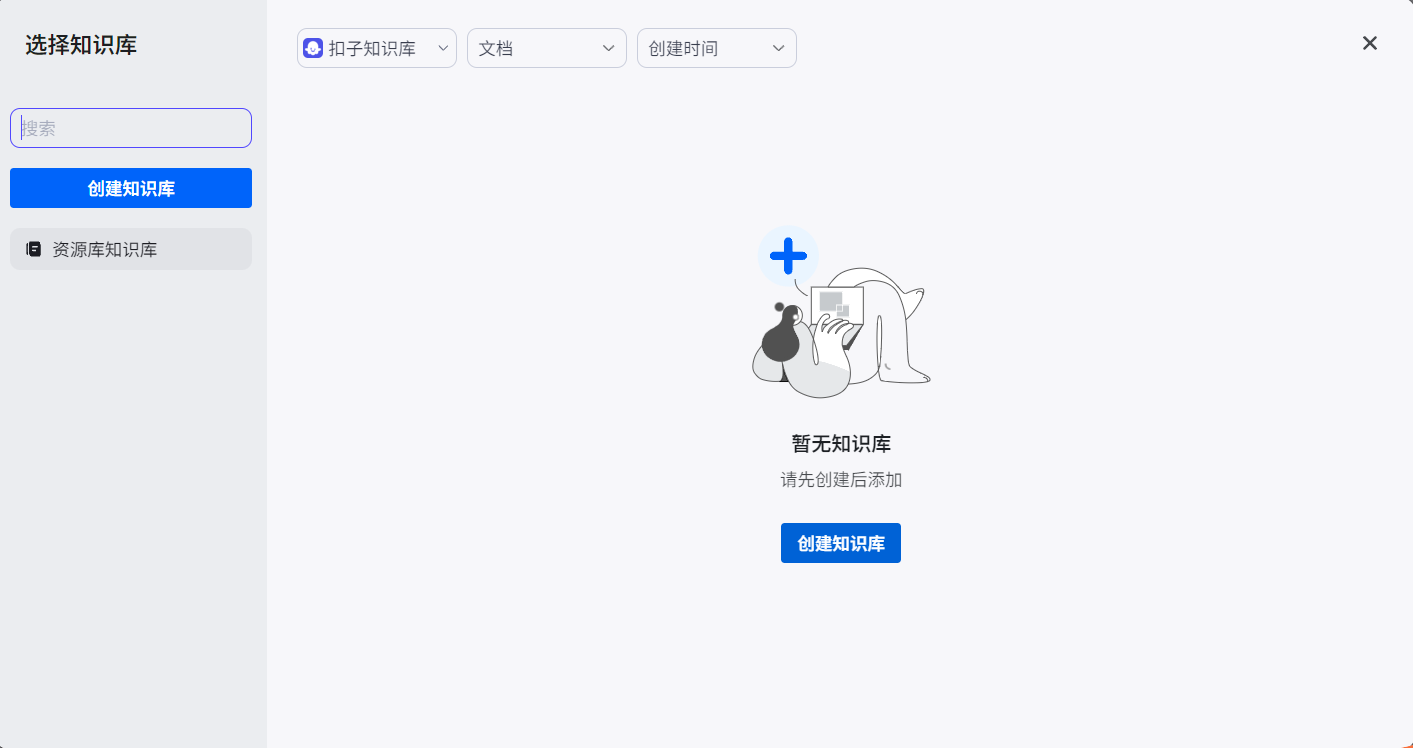
选择上传的知识类型:
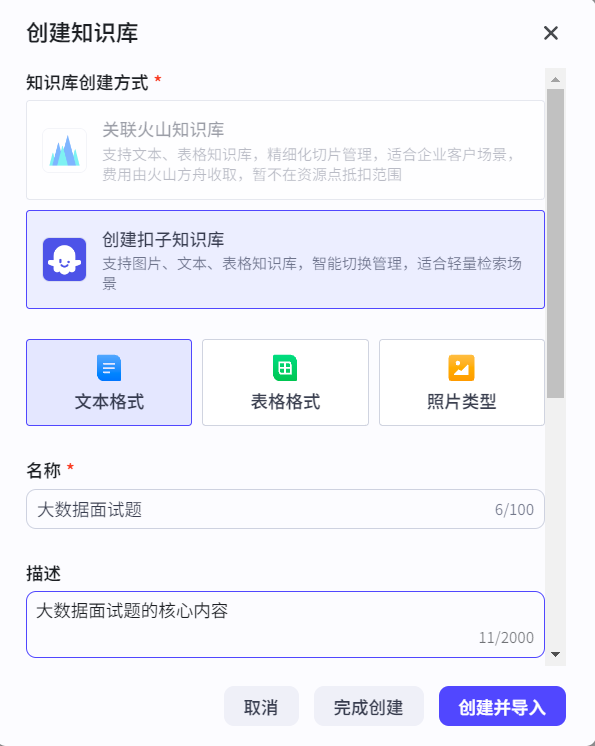
上传后点击下一步:
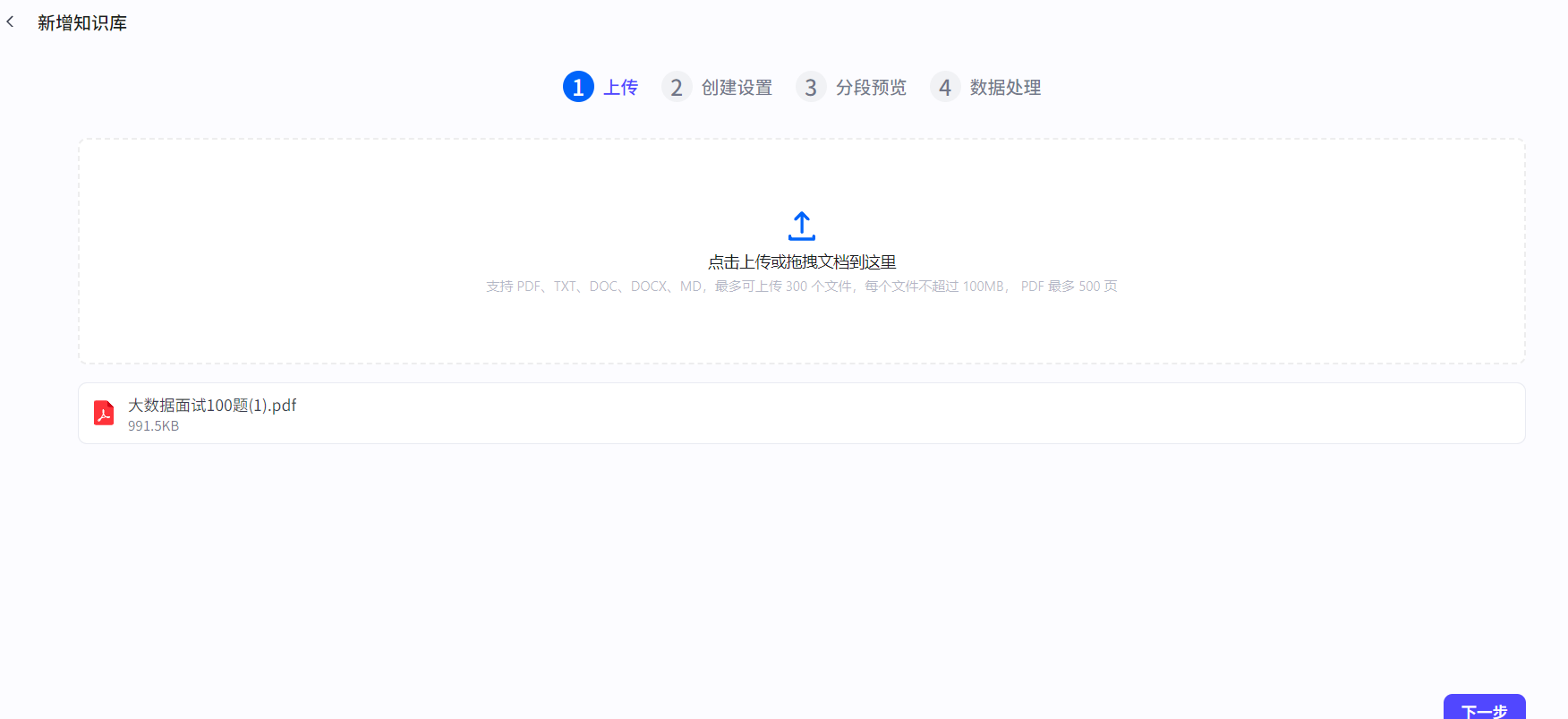
选择分段策略和解析策略:
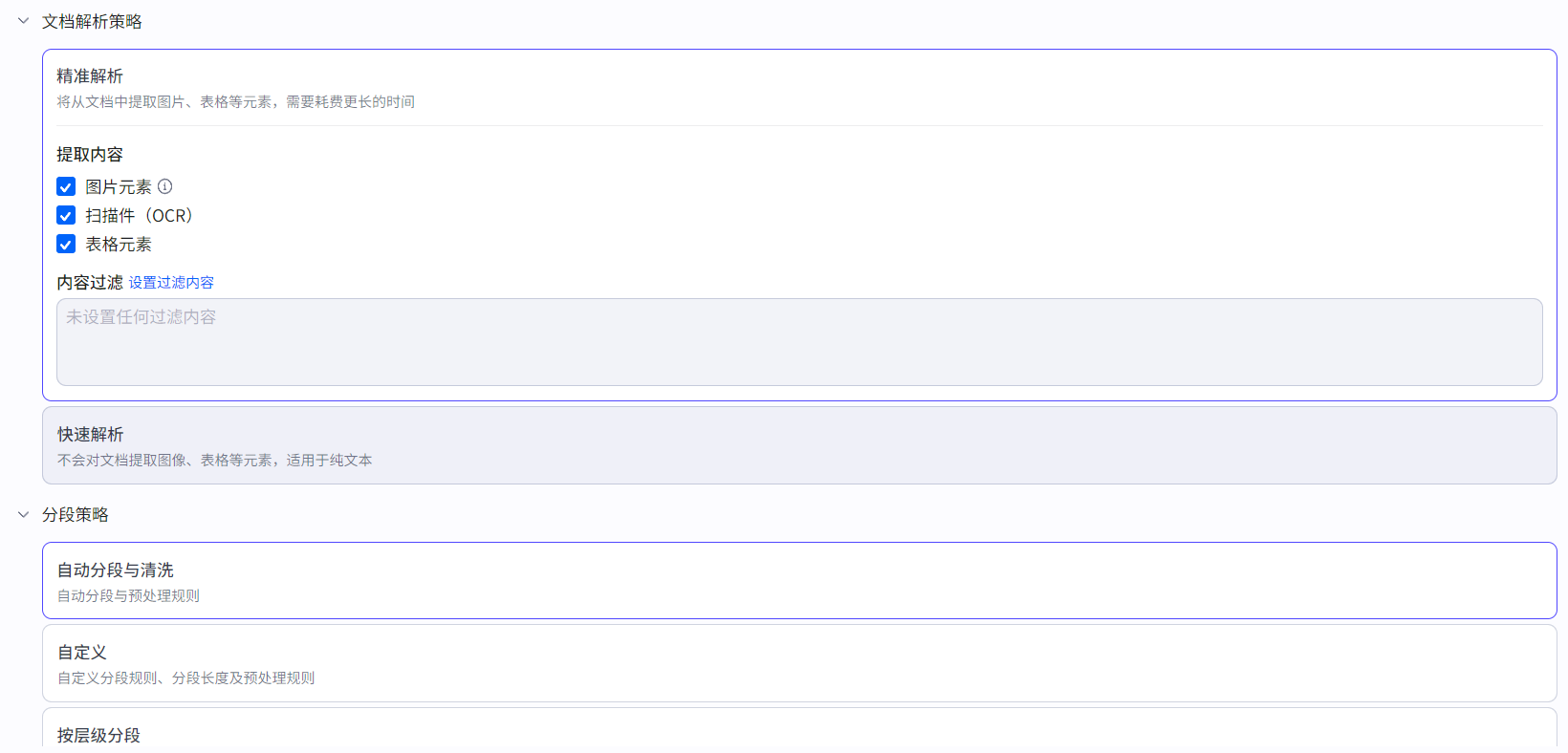
然后继续确认,等待分段处理完成即可使用:
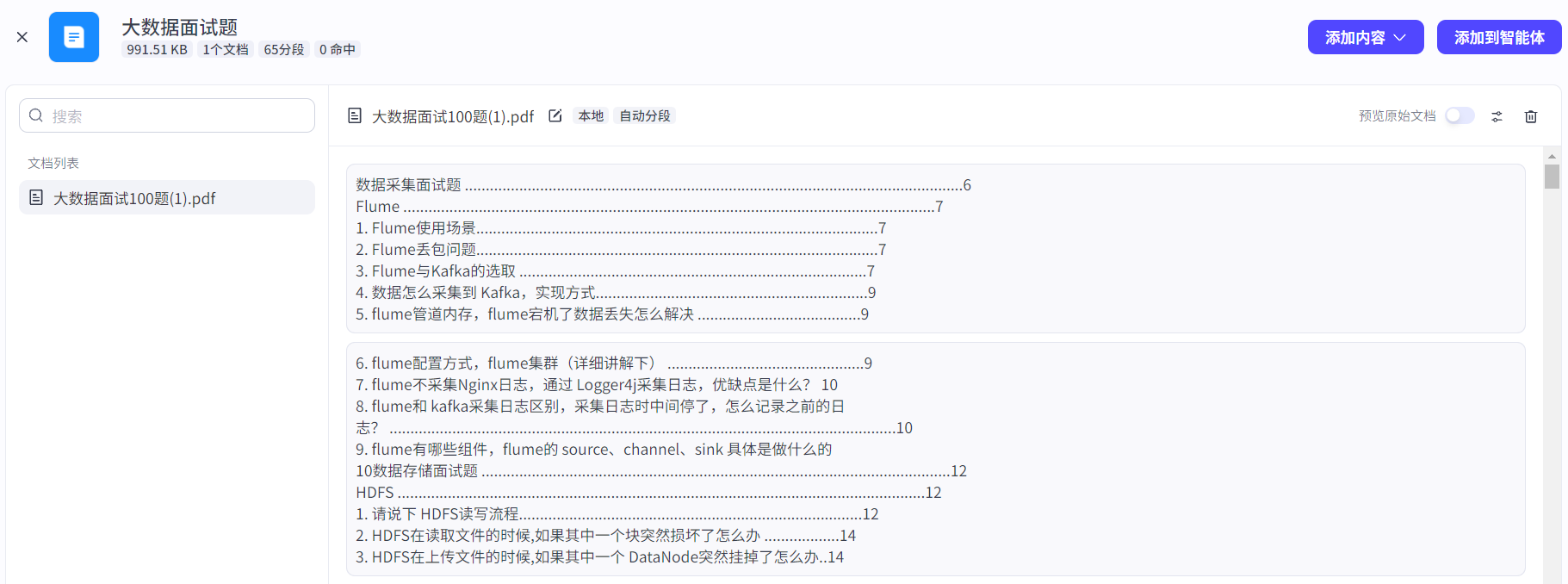
添加知识库后,直接询问智能体,如果询问的问题在知识库存在,就会从知识库搜索并增强提:
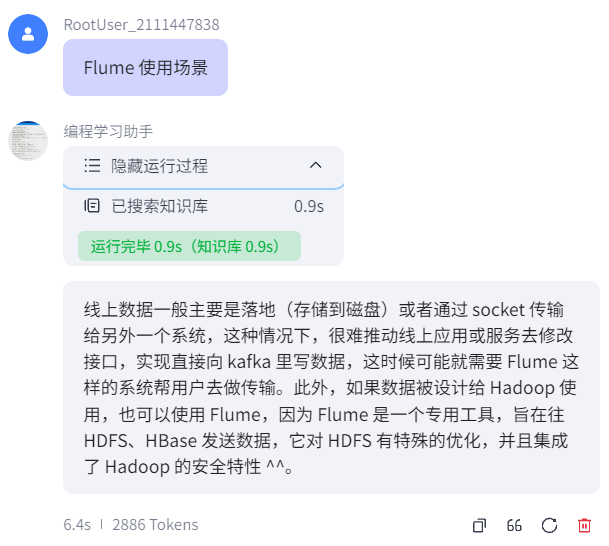

可以发现,回复和知识库的内容非常相似。
2.7.3 数据库
(1)数据库概念
扣子的数据库功能适用于组织和管理结构化数据,例如客户信息、产品列表、订单记录等。目前,扣子支持使用扣子官方数据库和火山数据库。采用类NoSQL的文档模型,支持通过自然语言或SQL语句进行数据的增删改查操作。也就是说,数据库赋予智能体长期记忆的能力(这里的长期记忆区别于)
注意:数据库、知识库、上下文的区别。上下文是短期记忆,更强调多轮对话之间的关联,但是智能体的记忆能力受上下文长度限制;知识库不属于记忆能力,而是外部的静态知识,供智能体查阅自己所不了解的细粒度知识;数据库是长期记忆,可以读写,记忆能力覆盖整个对话期间。
(2)示例
在智能体编排界面的记忆模块,点击添加数据库:
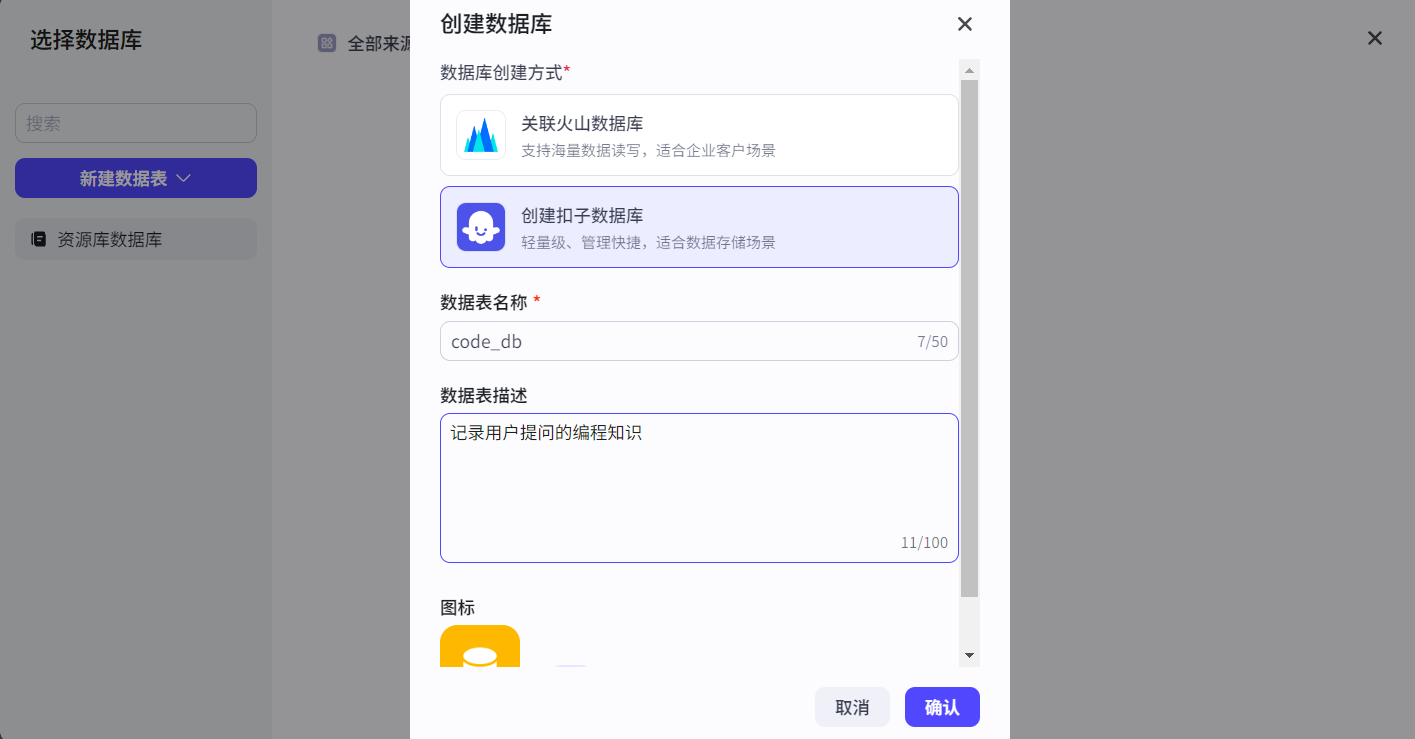
扣子开发平台提供两种类型数据库:火山数据库(基于MySQL开发)和扣子数据库(更轻量),选择扣子数据库:
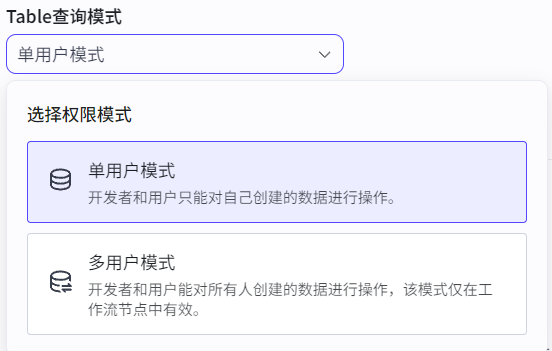
选择查询模式:
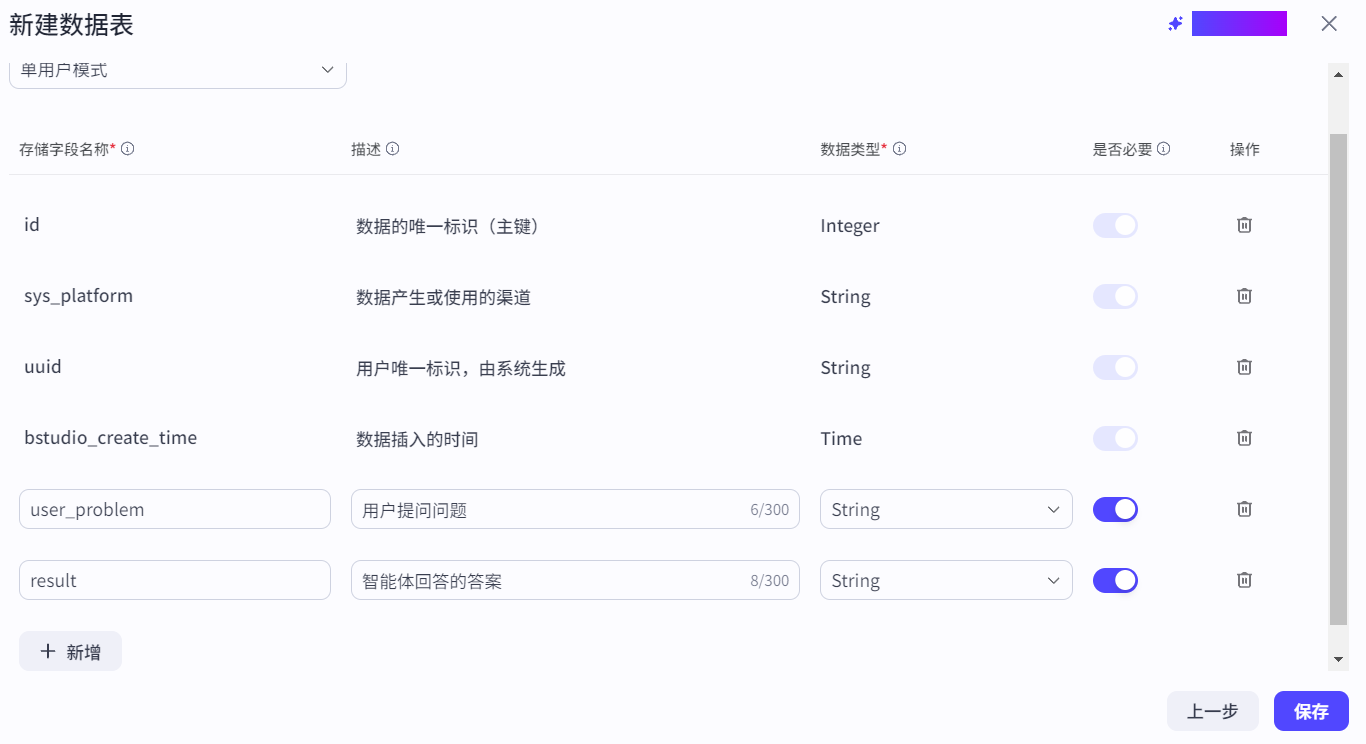
添加字段,默认存在四个字段,其余字段需要用户添加:
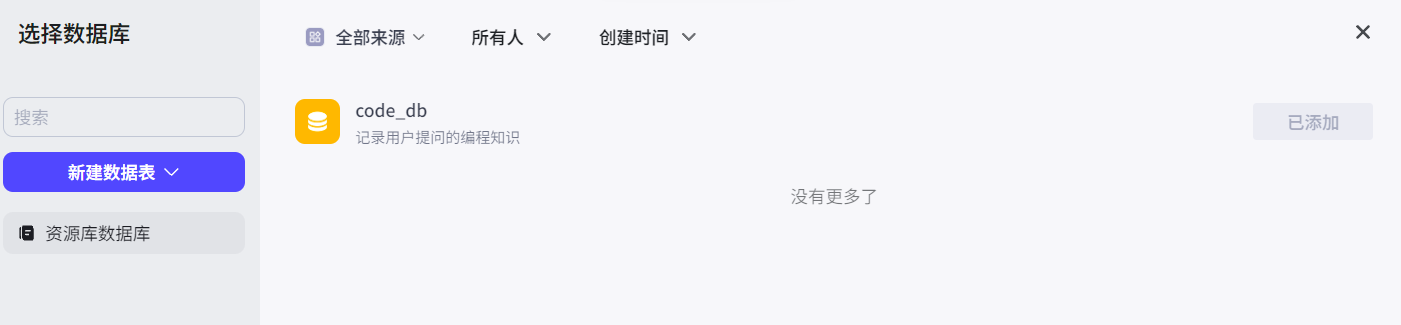
保存表结构后将数据库添加到智能体中:
由于大模型回复问题一般较慢,因此这里主要想让数据库做类似缓存的作用,用户询问相似的问题不再由大模型回复,而是直接查询数据库看是否存在相似问题的答案。从而提高智能体响应速度,节省资源消耗。
添加系统提示词中的技能,要求智能体在何时调用数据库进行操作:

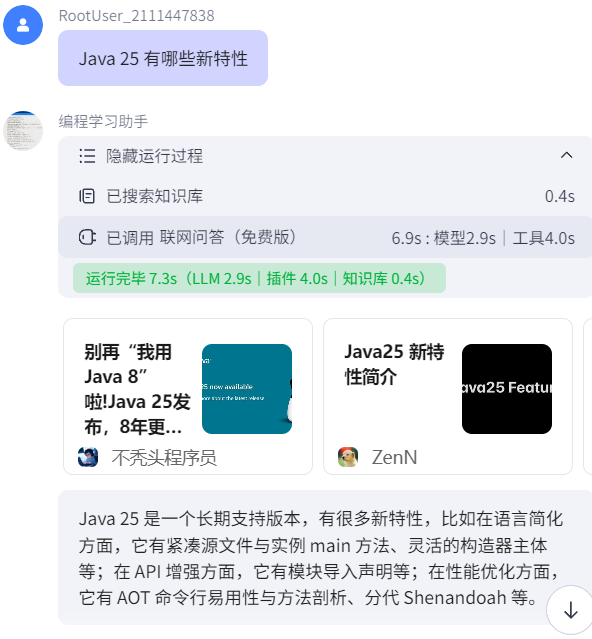
第一次询问时,由于数据库无记录,并且问题实时性超过模型的实时性,因此触发先前配置的联网问答技能:
第二次再询问相同的问题,不再调用联网工具,而是查询了数据库,运行过程时间大幅减少:
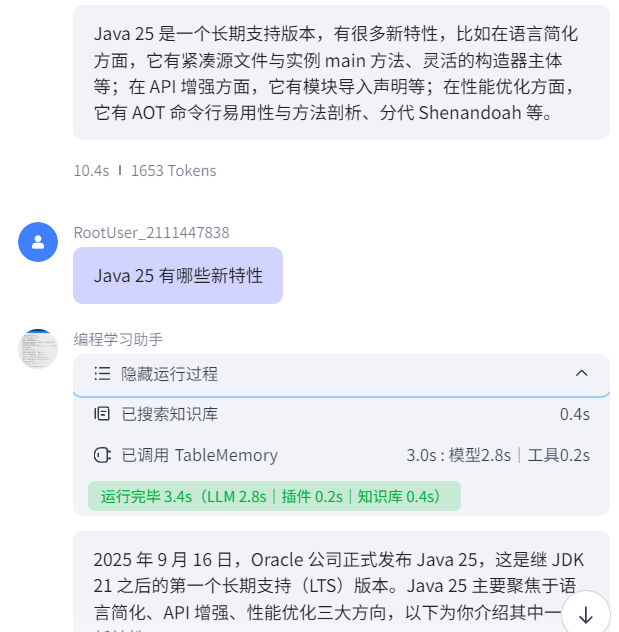
可以发现执行数据库查询过程的记录,执行了查询code_db表的SQL语句:
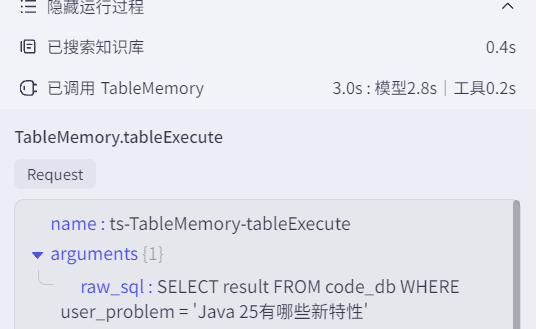
在数据表中查看也发现了新纪录的存在:
3 工作流
工作流是一系列可执行指令的集合,用于实现业务逻辑或完成特定任务。它为应用/智能体的数据流动和任务处理提供了一个结构化框架。工作流的核心在于将大模型的强大能力与特定的业务逻辑相结合,通过系统化、流程化的方法来实现高效、可扩展的 AI 应用开发。
扣子支持两种类型的工作流:
- 工作流(Workflow):用于处理功能类的请求,可通过顺序执行一系列节点实现某个功能。适合数据的自动化处理场景,例如生成行业调研报告、生成一张海报、制作绘本等。
- 对话流(Chatflow):是基于对话场景的特殊工作流,更适合处理对话类请求。对话流通过对话的方式和用户交互,并完成复杂的业务逻辑(通过对话引导用户完成工作流)。对话流适用于 Chatbot 等需要在响应请求时进行复杂逻辑处理的对话式应用程序,例如个人助手、智能客服、虚拟伴侣等。
工作流的核心组件就是节点,因此下面重点讲解一下节点:
3.1 基础节点
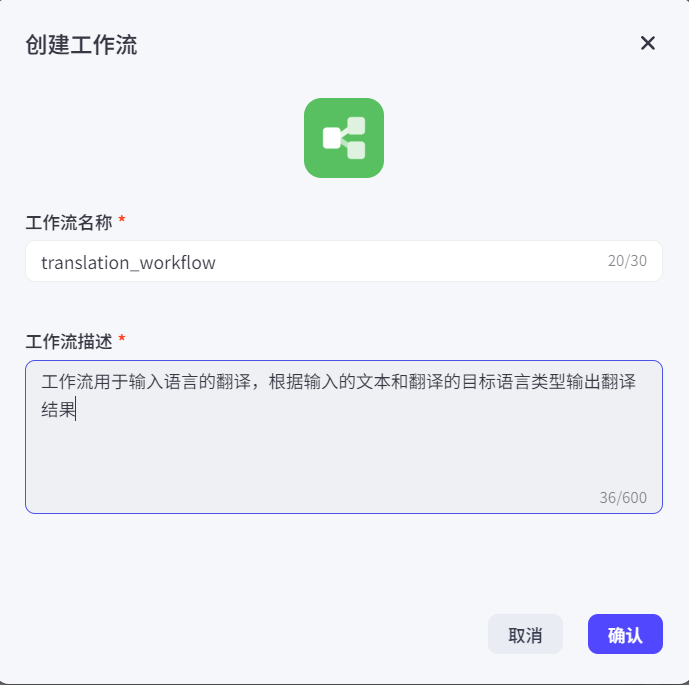
首先创建工作流:

工作流名称为数字、字母和下划线组成,且必须字母开头。工作流描述建议和工作流内容相关,便于让用户和大模型理解:
工作流页面中,点击下方工具栏中添加节点,可以添加需要的类型的节点。点击试运行,工作流将会从开始节点执行,到结束节点输出结果:
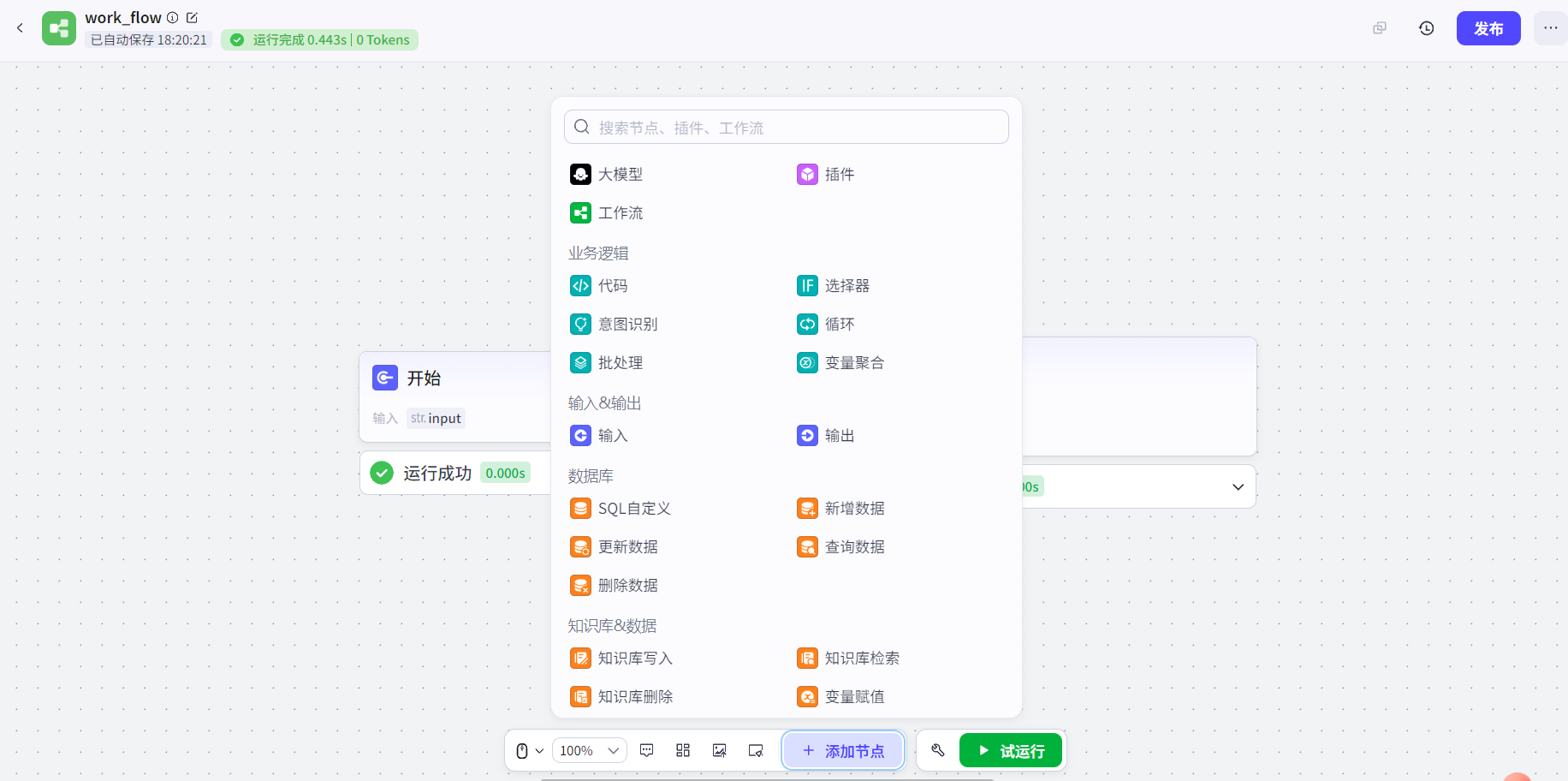
选择任意两个节点,可以将节点用箭头连接起来,上一个节点的输出就可以输入到下一个节点中。
3.1.1 开始节点与结束节点
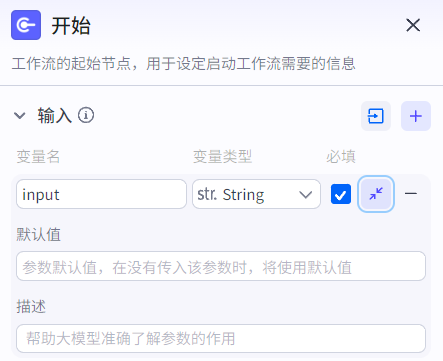
开始节点:工作流的起点,接受用户输入(智能体对话将用户输入提取并输入到工作流的开始节点)。
可以定义多个输入变量,设置:类型、是否必填、默认值、描述等信息。也可以通过JSON格式导入变量。
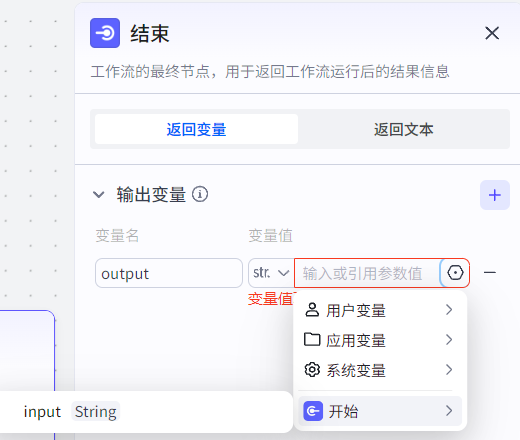
结束节点:工作流的结束,负责输出工作流的结果。定义的输出变量需要设置变量值,可以是全局定义的用户变量、应用变量或系统变量,也可以引用上一个节点的输出。
结束节点可以选择返回变量或返回文本:
返回变量:变量以JSON格式返回。如果智能体调用工作流,大模型会自动总结JSON内容并整理为自然语言的格式返回。
返回文本:工作流结束,智能体直接使用预设的文本格式返回用户对话结果。预设的文本支持引用变量,也支持流式输出。
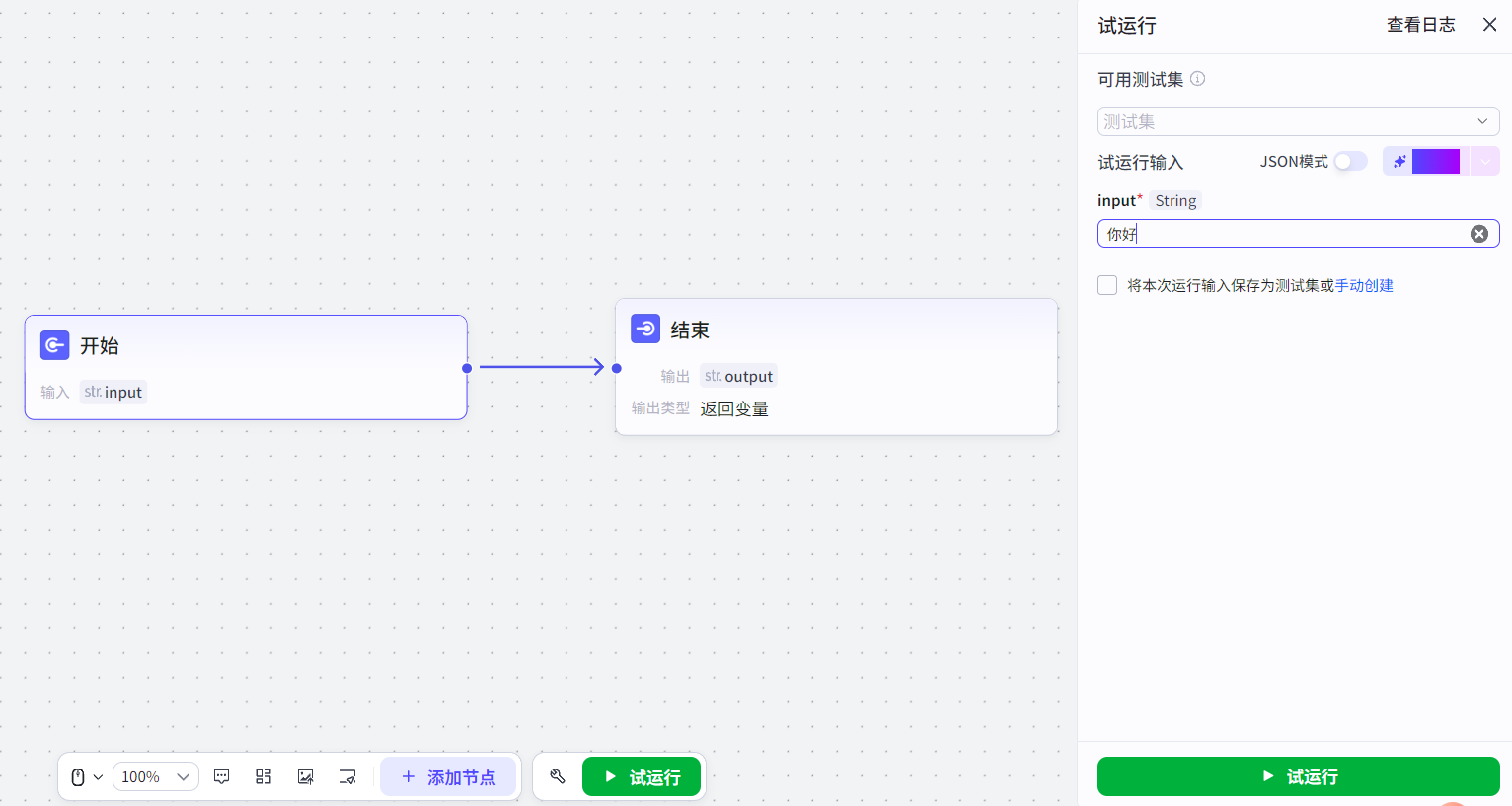
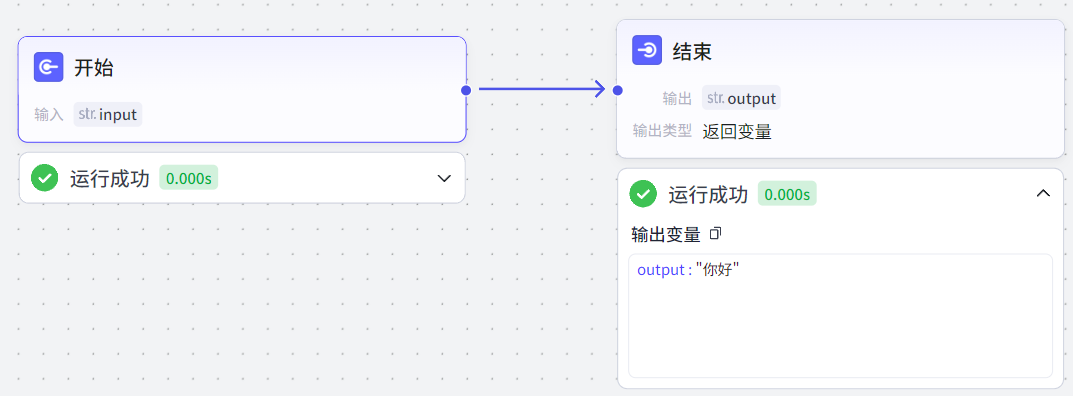
如下实现了最简单的工作流,开始节点输入,结束节点返回开始节点的输出(结束节点的输出变量引用开始节点的输入变量):
3.1.2 大模型节点
大模型节点:类似于在工作流又添加了个子智能体,从而实现更复杂的功能。
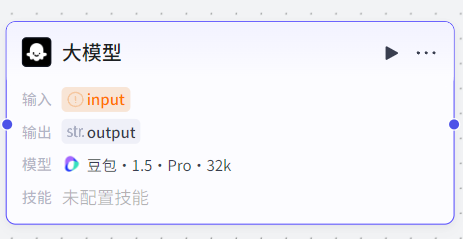
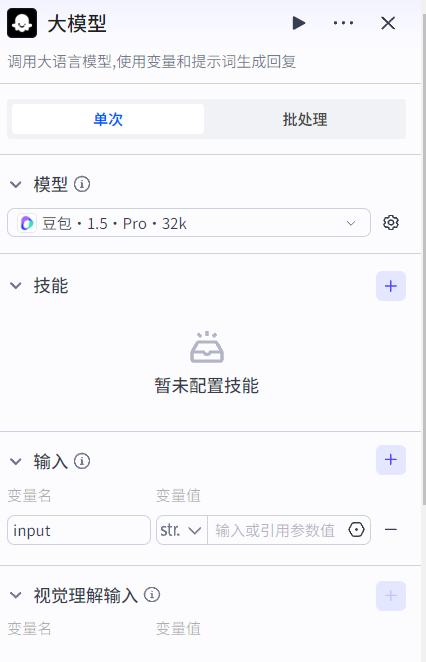
大模型节点同样支持选择模型、添加技能(插件、工作流、知识库)、输入变量、视觉理解输入(图片输入理解)、系统提示词、用户提示词、输出变量、异常处理等。
注意:上述技能、输入变量、视觉理解输入、输出变量等配置需要结合提示词使用,即告诉大模型何时使用何种技能、如何对变量进行动态引用等时机和操作方式。
对于变量的引用,提示词中使用{{变量名}}来引用,双花括号中间可以是:变量名、变量名.子变量(JSON格式的变量)、变量名[数组索引](数组类型变量)。
异常处理:由于大模型节点可能存在网络超时、运行异常等错误,因此发生异常时工作流可以选择中断、按预设回复、处理异常等策略,保证工作流在可控范围内运行。
如下实现了一个链接页面内容读取的大模型节点,配置技能:链接读取,添加系统提示词调用技能,用户提示词将开始节点的input变量进行输入,输出变量类型为文本类型。结束节点的output变量引用大模型节点的output变量:
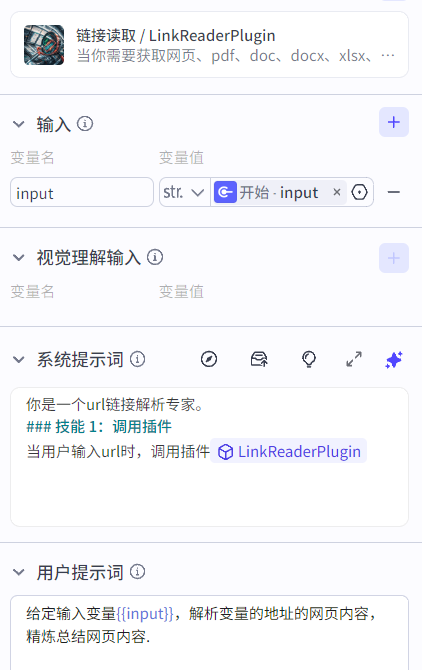
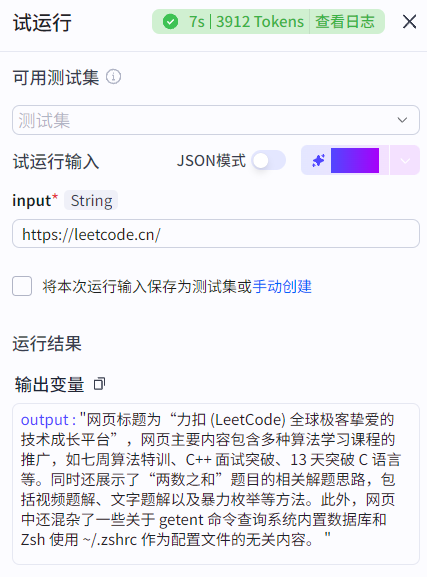
3.1.3 插件节点
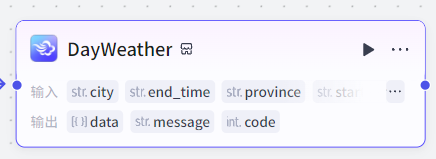
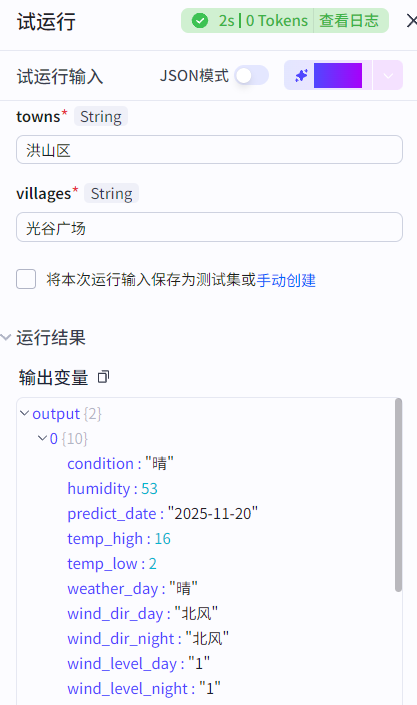
插件节点:将第三方外部工具转化为工作流的节点。核心使用方式是学会如何根据插件的入参设置参数引用关系。
比如添加一个墨迹天气插件,就需要将插件输入参数的值引用为上一个节点的输出参数的值(需要一一对应)。下一个节点就需要研究如何将插件输出参数的值引用:

3.1.4 子工作流节点
子工作流节点:如果一个复杂的任务分为多个流程,每个流程又可以分为多个子流程,就可以使用子工作流节点。相当于工作流嵌套工作流。
注意:子工作流需要发布才可以被引用。
3.2 业务逻辑节点
3.2.1 选择器节点
选择器节点:类似于编程语言的if-else语句或if-else if-else语句。
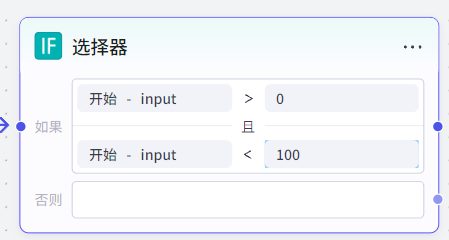
如果就是if,否则就是else,可以点击+号添加else if语句。对于每个条件分支,可采用多条件组合方式(多条件之间用或/且逻辑语句连接)。条件判断主要是大小比较,输入值和目标值进行比较。
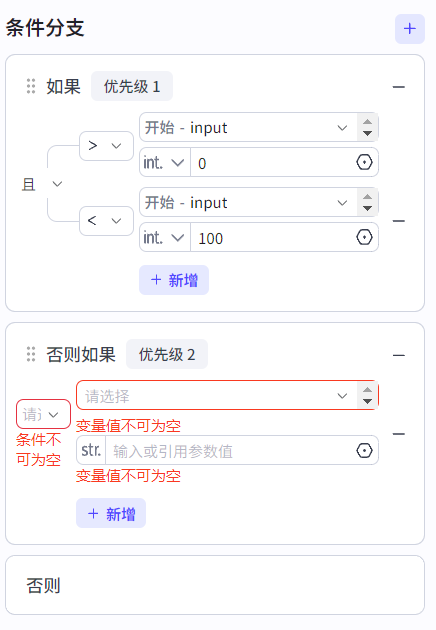
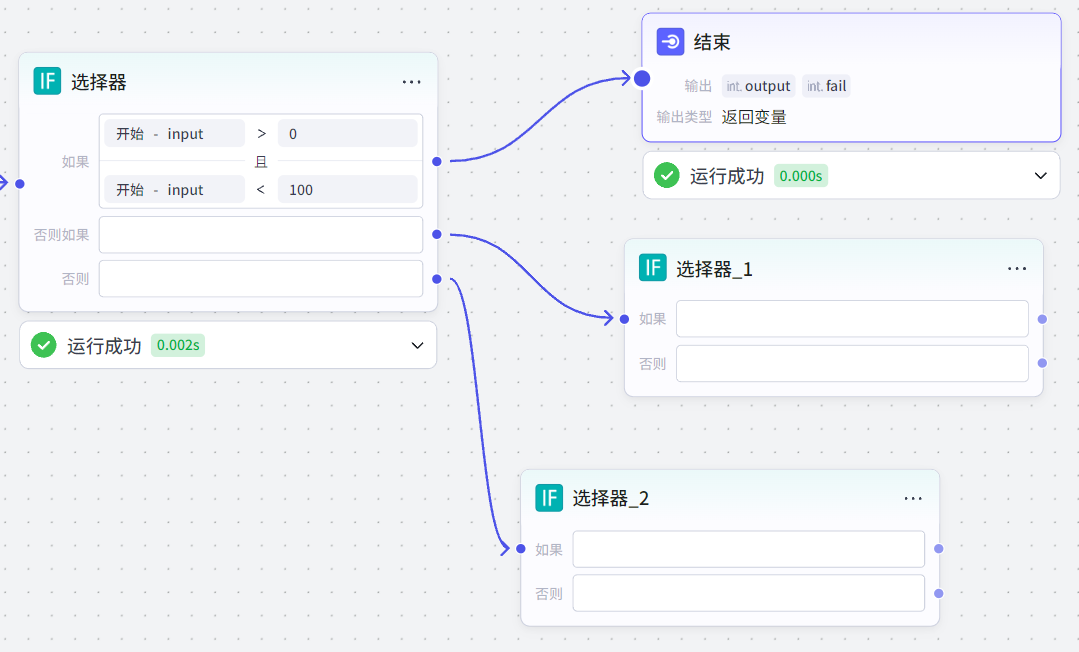
注意:每个条件分支必须有下一个节点的连接,否则工作流无法正常运行。
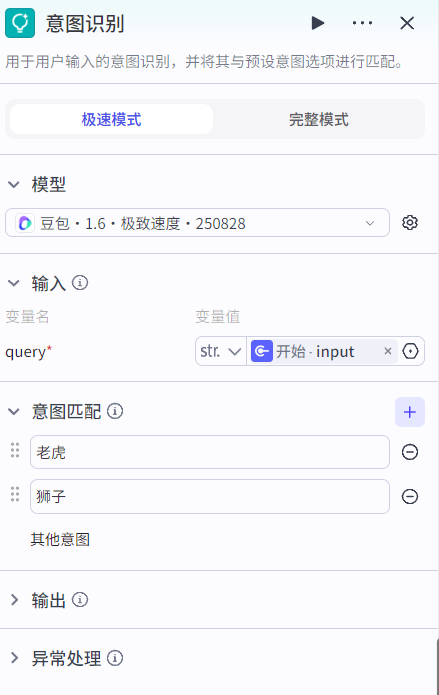
3.2.2 意图识别节点
意图识别节点:根据输入调用大模型进行意图识别,也就是识别出输入的自然语言属于预设哪个分类选项。可以根据输入的意图进入不同的工作流环节(分支的作用)。
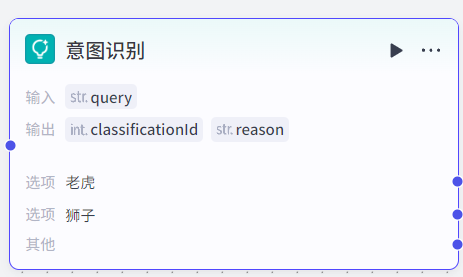
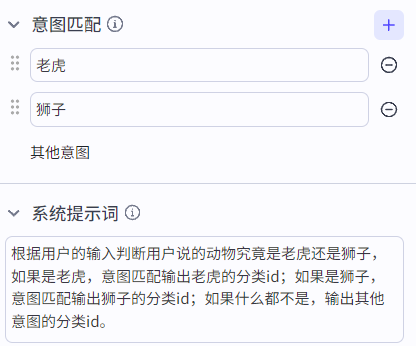
意图识别分为极速模式和完整模式,完整模式比极速模式多了个系统提示词的配置,帮助大模型更好的分析输入的意图。
输出的分类id有两种情况:
值为0,说明没有任何意图选项被匹配;
值为>0,按设置的选项顺序匹配,比如值为1,匹配第1个意图。
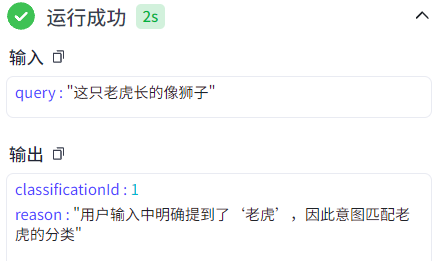
使用时,建议使用完整模式,添加提示词,否则对于复杂的输入容易匹配失败:
3.2.3 循环节点
循环节点:类似for循环或while循环,执行重复的逻辑一定次数。
循环类型分为:数组循环、次数循环、无线循环。
数组循环(类似for循环)需要接收上一个节点的数组参数作为输入,每一次循环是遍历一个数组元素,数组遍历结束循环结束。
次数循环(类似for循环)需要执行循环次数,也可以选择引用上一个节点的数值类型参数作为循环次数,次数结束循环结束。
无线循环(类似while循环)没有输入参数,需要在循环体添加选择器节点和终止节点,当满足选择器节点时执行终止节点跳出循环。
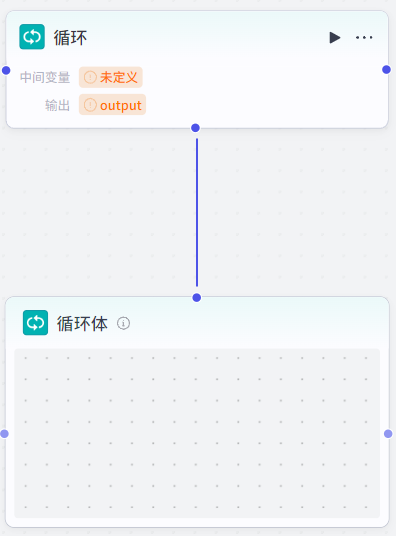
循环节点的核心是配置循环类型(如果是数组循环和次数循环,还需要配置输入参数)、中间变量、循环体和输出参数。
中间变量:可作用于每一次循环,在每一次循环中可设置中间变量的值(设置变量节点)供下次循环使用。
循环体:选中循环体,可以在循环体中添加节点(不能添加循环节点,除非在循环体添加工作流节点,在工作流节点再添加循环节点),可以认为循环体也是一个小的需要循环的工作流。
输出参数:将循环结果输入到下一个节点中。
如下实现了一个根据文本大纲(数组类型)依靠大模型进行文章续写的工作流:
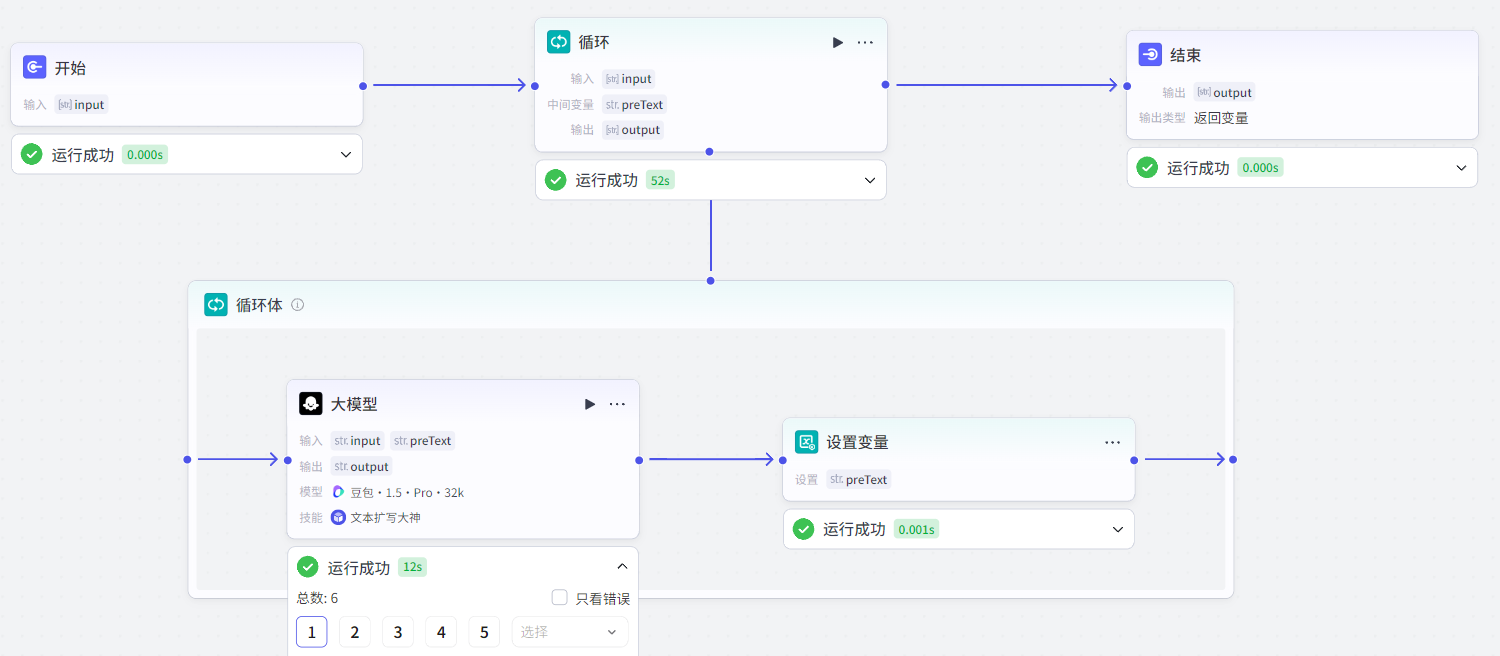
大模型节点的提示词和输入如下:
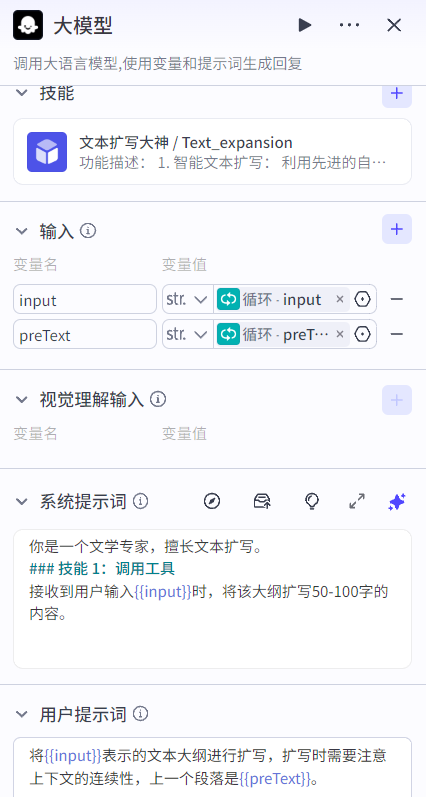
循环配置如下(中间变量的初始值是" "):
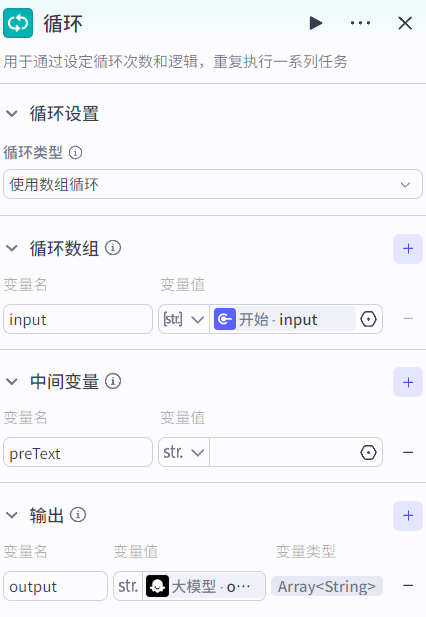
中间变量的设置变量节点作用是,将大模型的输出作为中间变量preText的值,并在下次循环中输入到大模型,保证大模型输出当前段落内容时保持和上文的连贯性:
输入:
["这是一个玄幻小说,首先介绍一下小说的背景","本段介绍小说的主角","本段介绍小说的人物关系","本段介绍小说的主要情节1","本段介绍小说的主要情节2","本段介绍小说的结尾"]输出:
{"output":["这是一部精彩绝伦的玄幻小说,在踏入这个奇幻世界之前,很有必要先了解一下它的背景。故事发生在一个神秘莫测的多元宇宙中,存在着仙、魔、妖、人等诸多种族。各势力纷争不断,资源稀缺引发无数明争暗斗,而传说中的上古神器即将现世,一场席卷天地的风暴也悄然拉开了帷幕。 ","在这场风暴的中心,有一位与众不同的主角。他出身平凡,只是生活在凡人村落中一个普通人家的孩子,每日过着日出而作、日落而息的简单生活。然而,他的内心却怀揣着不凡的梦想。他看到了种族纷争给百姓带来的苦难,看到了资源争夺下无数家庭的破碎。于是,他立志要在这混乱的多元宇宙中闯出一片属于自己的天地。他渴望通过自己的努力,解开上古神器背后隐藏的惊天秘密,利用神器的力量结束这无休止的纷争,让各个种族能够和平共处,让这片多元宇宙重新恢复往日的安宁与祥和。 ","在这场风暴的中心,有一位与众不同的主角。他出身平凡,只是生活在凡人村落中一个普通人家的孩子,每日过着日出而作、日落而息的简单生活。然而,他的内心却怀揣着不凡的梦想。\n\n他亲眼目睹了种族纷争给百姓带来的无尽苦难,那血腥的战场、流离失所的难民,还有资源争夺下无数家庭的破碎场景,都深深刺痛着他的心。于是,他毅然立志要在这混乱不堪的多元宇宙中闯出一片属于自己的天地。他日夜思索,决心凭借自己不懈的努力,解开上古神器背后隐藏的惊天秘密。他坚信,只要能掌握神器的力量,就能结束这无休止的纷争,让各个种族摒弃前嫌和平共处,让这片饱经沧桑的多元宇宙重新恢复往日的安宁与祥和。在追寻梦想的道路上,他将面临重重艰难险阻,但心中的信念从未动摇。 ","他亲眼目睹了种族纷争给百姓带来的无尽苦难,那血腥的战场尸横遍野、惨不忍睹,流离失所的难民们眼神中满是绝望与无助,资源争夺下无数家庭破碎,孩子失去双亲,老人孤苦伶仃,这一切深深刺痛着他的心。于是,他毅然立志要在这混乱不堪的多元宇宙中闯出一片属于自己的天地。他日夜思索,决心凭借自己不懈的努力,解开上古神器背后隐藏的惊天秘密。他坚信,只要能掌握神器的力量,就能结束这无休止的纷争,让各个种族摒弃前嫌和平共处,让这片饱经沧桑的多元宇宙重新恢复往日的安宁与祥和。在追寻梦想的道路上,他将面临重重艰难险阻,会遭遇强大的敌人、神秘的陷阱,但心中的信念从未动摇,始终如明灯般照亮前行之路。 ","在追寻梦想的道路上,他将面临重重艰难险阻。强大的敌人如狰狞巨兽般挡在前方,他们身怀绝技、心狠手辣,妄图阻止他前进。神秘的陷阱隐藏在暗处,稍有不慎便会万劫不复。但他心中的信念从未动摇,那信念如同夜空中最璀璨的明灯,穿透黑暗的迷雾,照亮他每一步前行的道路,给予他无穷的勇气与力量。 ","即便前路荆棘满布,每一步都伴随着鲜血与痛苦,他也不曾有过丝毫退缩。每一次与敌人的激烈交锋,每一回从陷阱中惊险逃脱,都让他变得愈发坚韧。他深知,只有凭借着这如钢铁般的意志,才能在这艰难的旅程中,一步步靠近那遥不可及却又无比闪耀的梦想。 "]}3.2.4 批处理节点
批处理节点:并行处理多个任务,提高工作流对于重复任务的执行效率。
配置内容:批处理节点设置、批处理体。批处理节点设置包括输入(数组类型,每个元素表示要执行的任务内容,比如多个要处理的图片、多个要处理的url)、并行数量上限(同时处理任务的数量)、执行次数上限(批处理体总执行次数到达上限就停止执行)、输出。批处理体可以添加多个节点,表示一次完整执行工作流程。
注意:批处理节点和循环节点结构类似,都包含批处理体/循环体(类似子工作流,表示需要处理的主体流程),但是两者有很大不同。循环节点的循环体采用同步执行的方式,循环体的每个节点按“次序”执行,直到满足某些退出循环的条件。批处理节点的批处理体强调并行处理的方式,就好像启动多个线程,每个线程都执行一次该任务,直到所有任务执行完成(或达到执行次数)。
如下实现了批量处理多个url的工作流,:
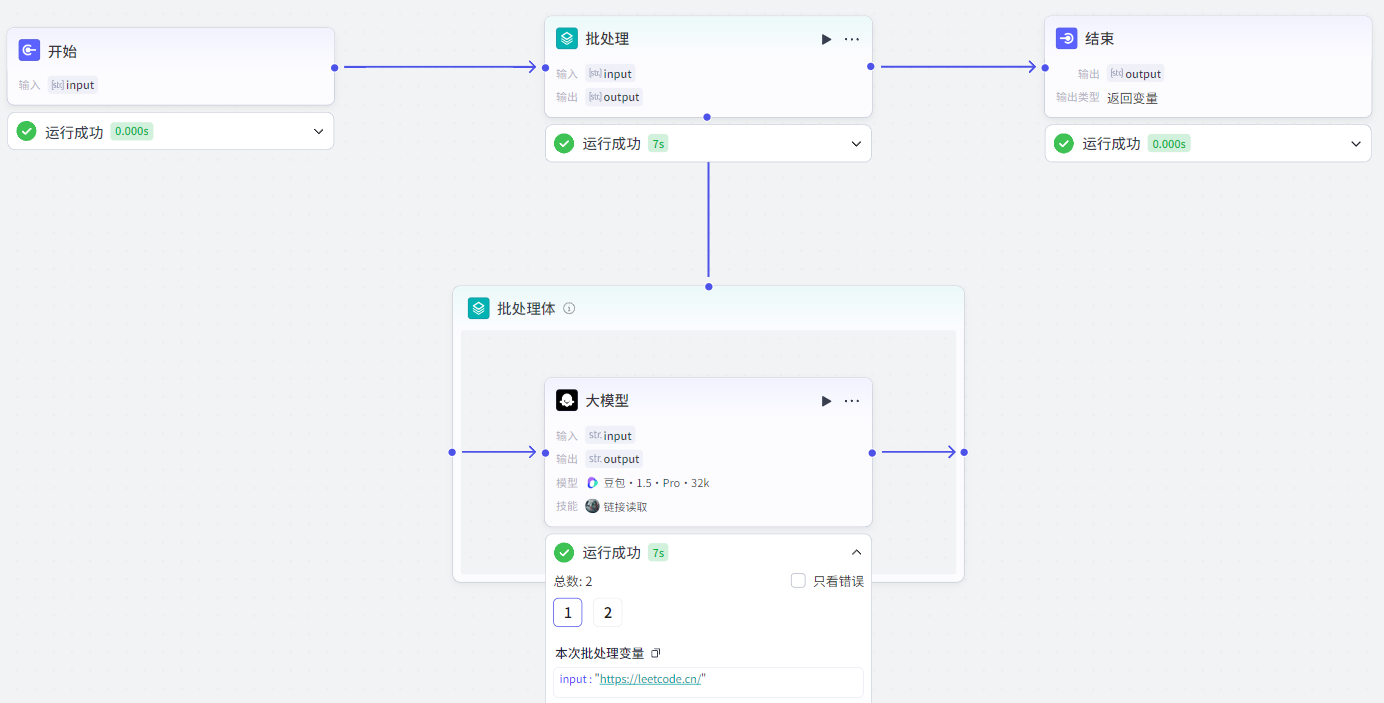
批处理节点设置并行数量为2,配置如下:
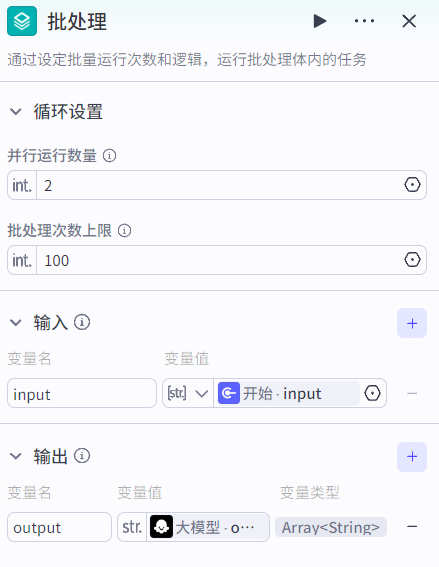
大模型节点配置如下:
输入:
["https://leetcode.cn/","https://www.nowcoder.com/"]输出:
{
"output": [
"该网页的标题是'力扣 (LeetCode) 全球极客挚爱的技术成长平台',内容包含了技术学习、竞赛、求职、题目分享、算法讨论等多方面信息,如C++、C语言学习交流,编程竞赛情况,岗位招聘,算法题解思路,以及个人刷题经历和感悟等。 ",
"用户需要分析https://www.nowcoder.com/的网页内容,调用 lianjieduqu-LinkReaderPlugin 工具获取网页标题和内容。该网页的标题为'牛客网',网页内容主要围绕求职相关话题展开,包含了秋招捡漏情况讨论、简历问题及建议、面试经历与面经分享、岗位招聘信息、薪资待遇讨论、求职过程中的困惑与心得等内容,例如有人询问秋招是否开始捡漏,有人分享字节跳动日常实习面经,有人求简历建议,还有人记录自己的秋招进展等。 "
]
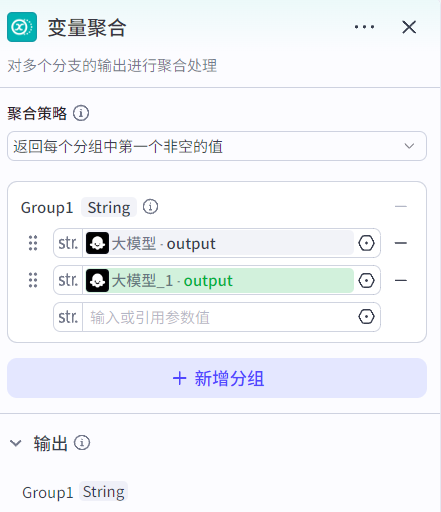
}3.2.5 变量聚合节点
变量聚合节点:将多个分支的输出聚合起来。
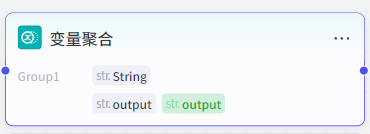
通常和选择器节点搭配使用,因为选择器节点要求每个条件分支都必须连接后续的工作流节点,但是条件分支只有一个能生效,这就意味着其他分支没有生效,这些分支也就没有输出,汇总分支输出的节点会接受空值从而报错。
变量聚合节点就可以解决这个问题,它将多个分支的输出聚合为一个分组变量,该分组变量只会生效第一个非空的值,因此即使其他分支未生效,也不影响后续流程的运行。
如下工作流实现根据选择器节点执行不同的大模型节点,并将大模型节点的两个分支进行聚合。这两个大模型一个强制输出YES,一个强制输出NO(在提示词中设置):
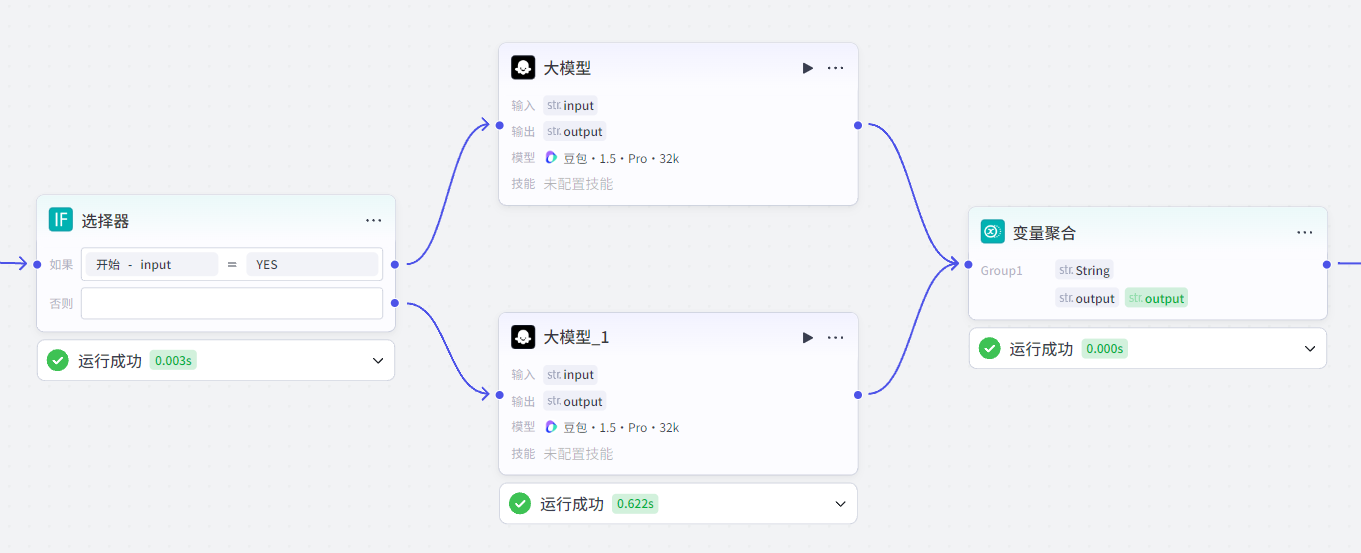
注意:同一个分组只能聚合多个分支的同一个类型的变量,因此如果想要聚合多组不同类型的变量,就需要新增分组。比如Group1用于聚合类型为String类型的output变量,Group2用于聚合类型为Integer类型的type变量,type和output变量都是上游分支必须输出的两个变量。
3.2.6 代码节点
代码节点:支持Python/JavaScript编写脚本,用于工作流的数据处理等功能。
注意:不支持代码中访问外部服务,仅限于处理工作流的数据。
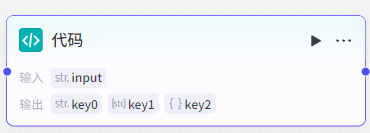
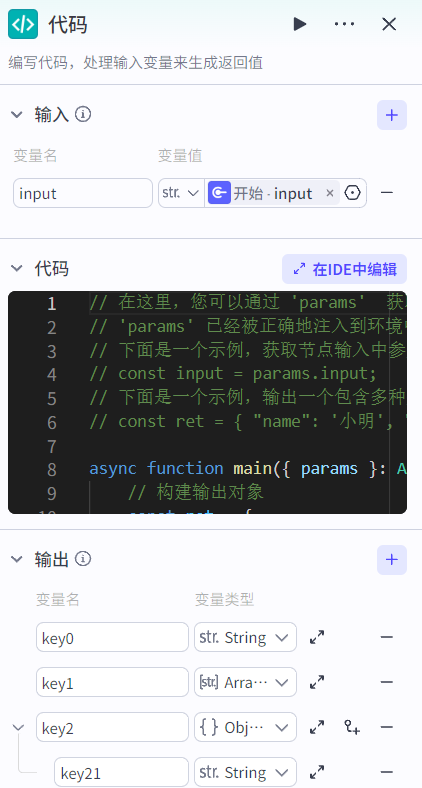
如下使用代码节点实现字符串按,分割:
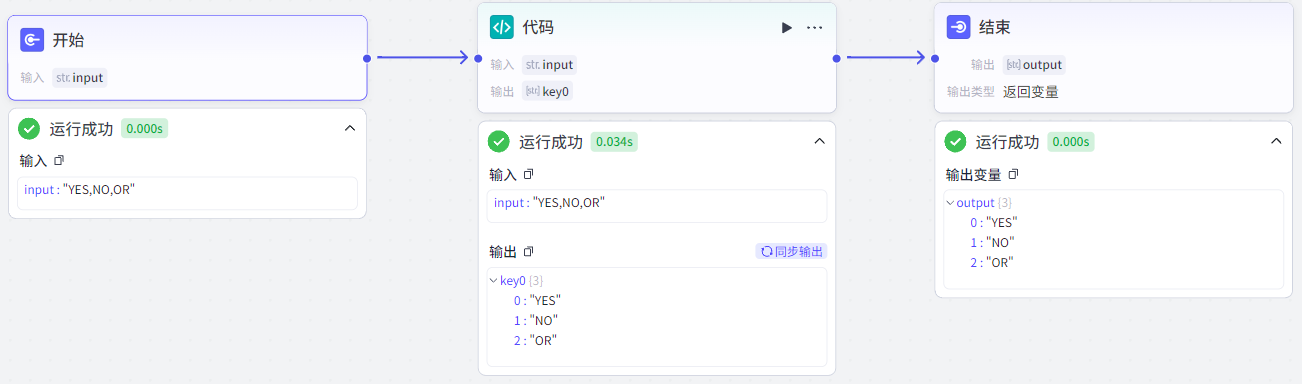
Python代码如下:
async def main(args: Args) -> Output:
params = args.params
# 构建输出对象
ret: Output = {
"key0": params['input'].split(",") # 按,分割语句
}
return ret这里使用async表示该函数是异步函数,调用该函数并不会立即执行,而是返回一个协程Coroutine对象(异步编程基本单位,表示可以暂停和恢复执行的函数)。
3.3 数据库节点
3.3.1 新增数据节点
新增数据节点:向数据表中新增数据(insert语句)。
需要指定插入的数据表,并将输入参数和插入字段进行引用:
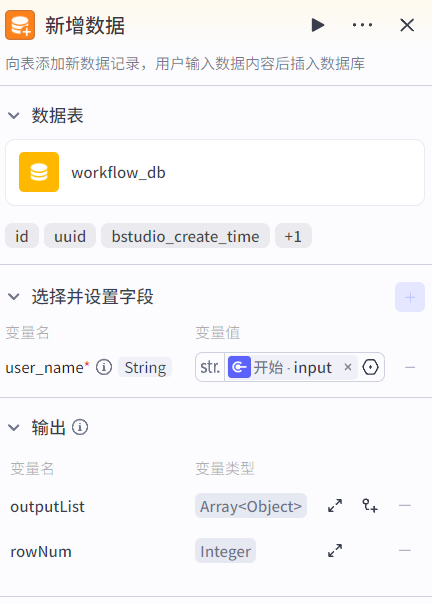
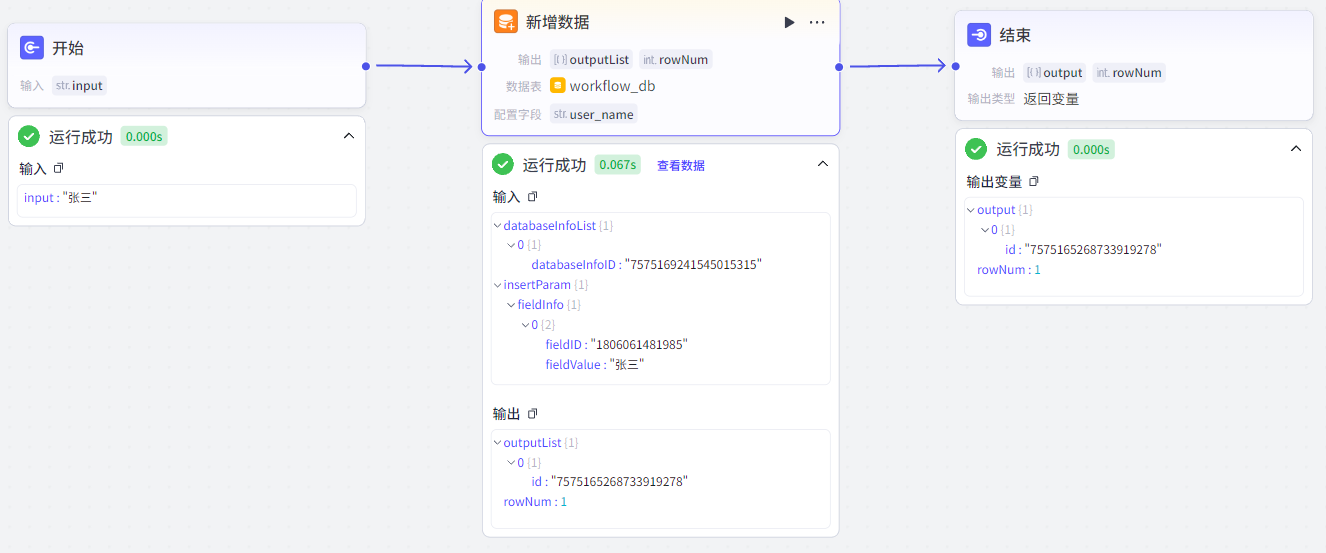
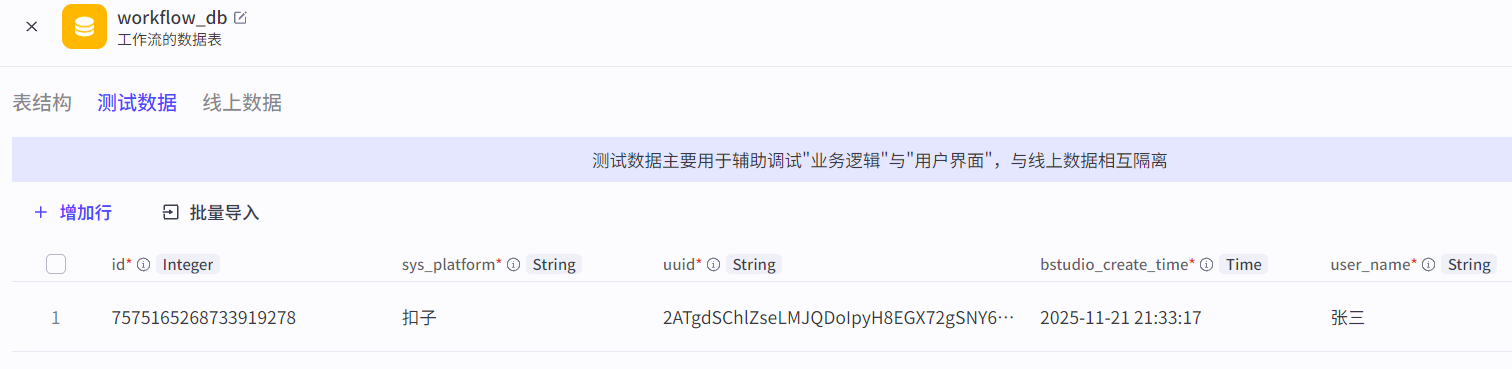
3.3.2 查询数据节点
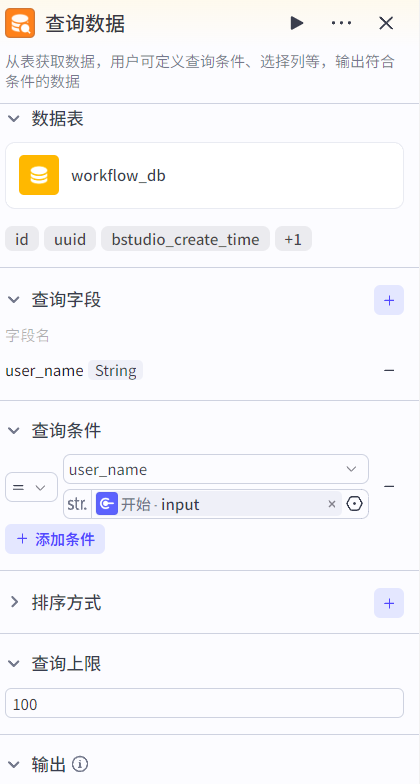
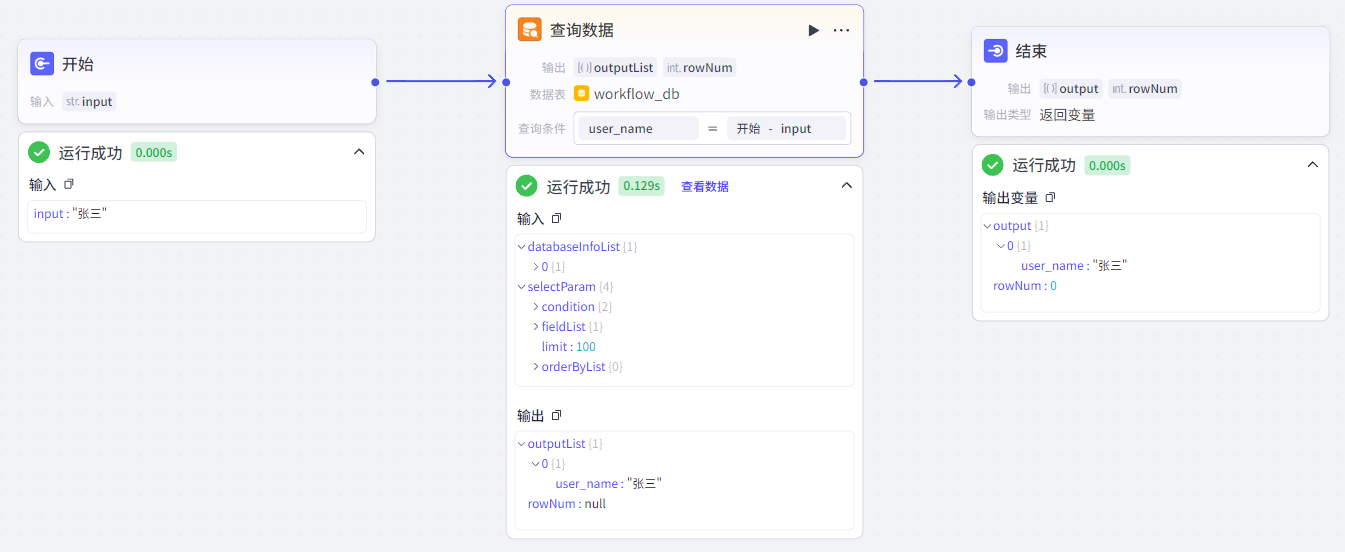
查询数据节点:根据条件进行字段查询(select语句)。
设置查询字段、查询条件(where)、排序方式(order by)、查询上限limit等查询规则,组成查询数据表的SQL语句进行查询:
3.3.3 更新数据节点
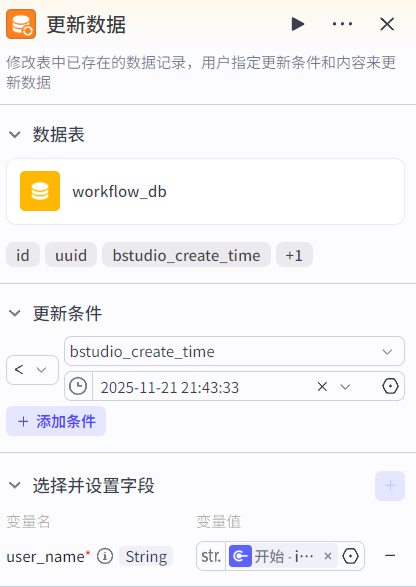
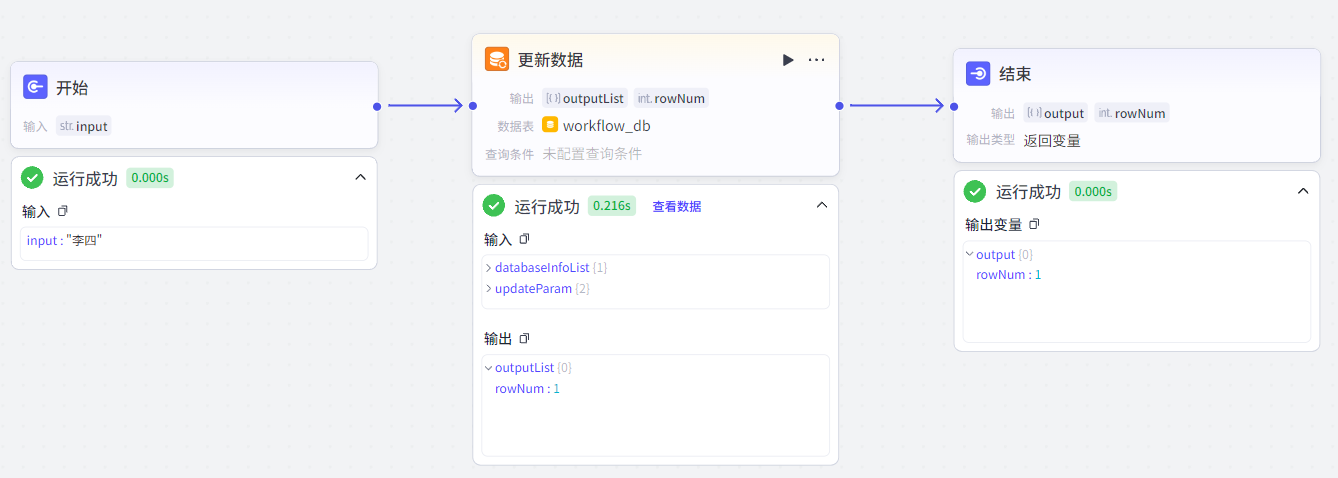
更新数据节点:更新数据表满足条件的数据(update语句)。
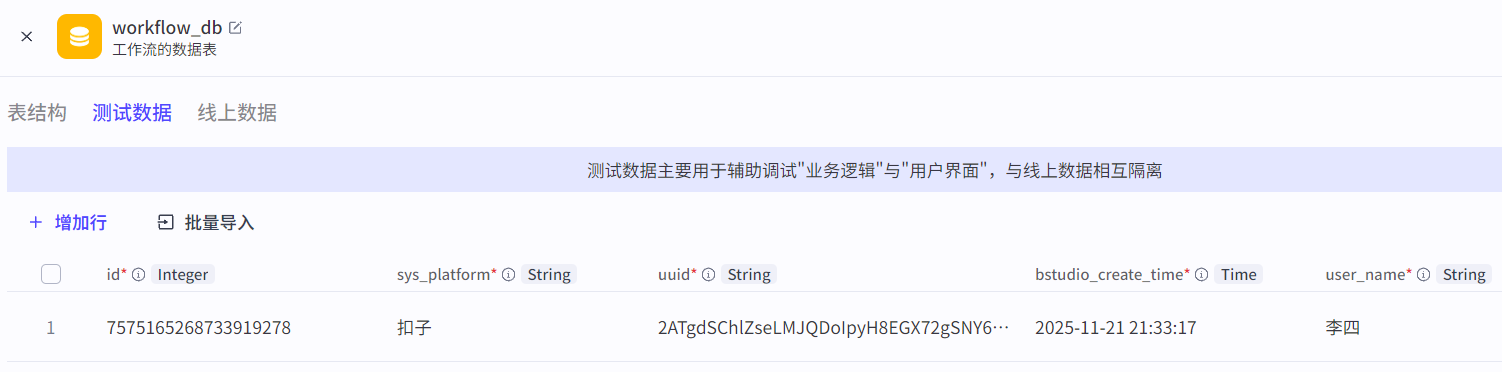
3.3.4 删除数据节点
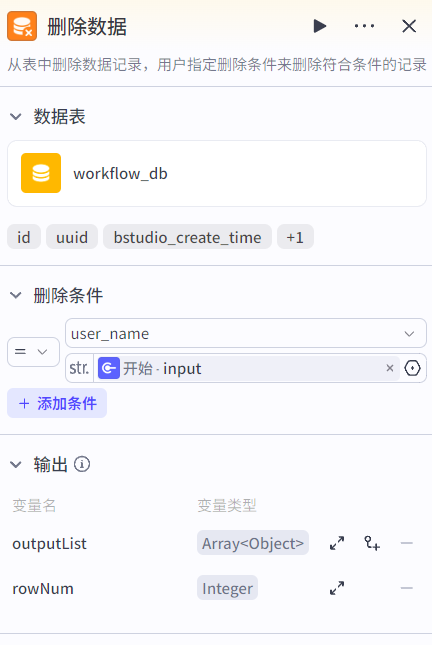
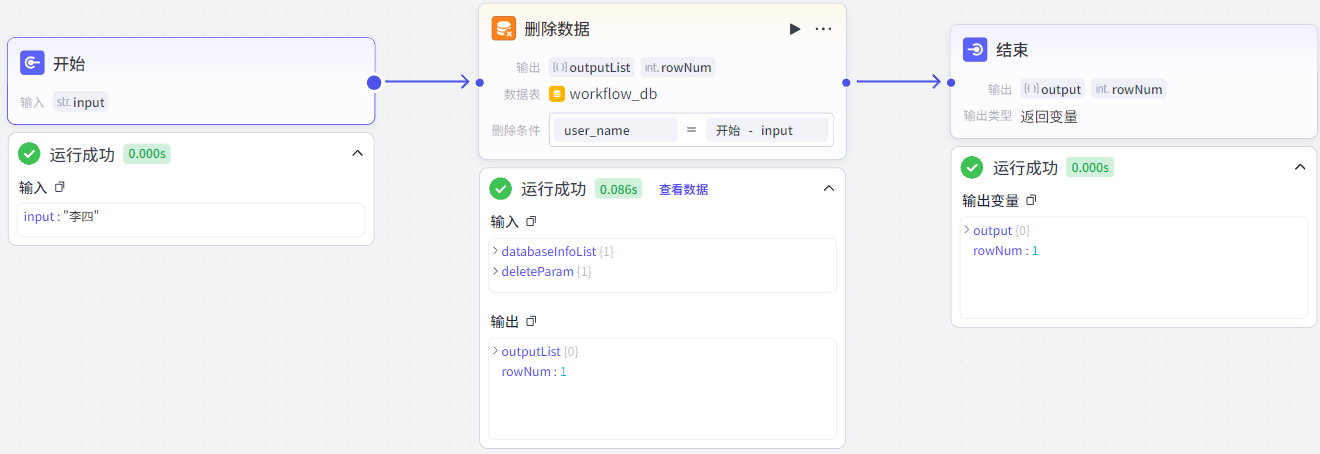
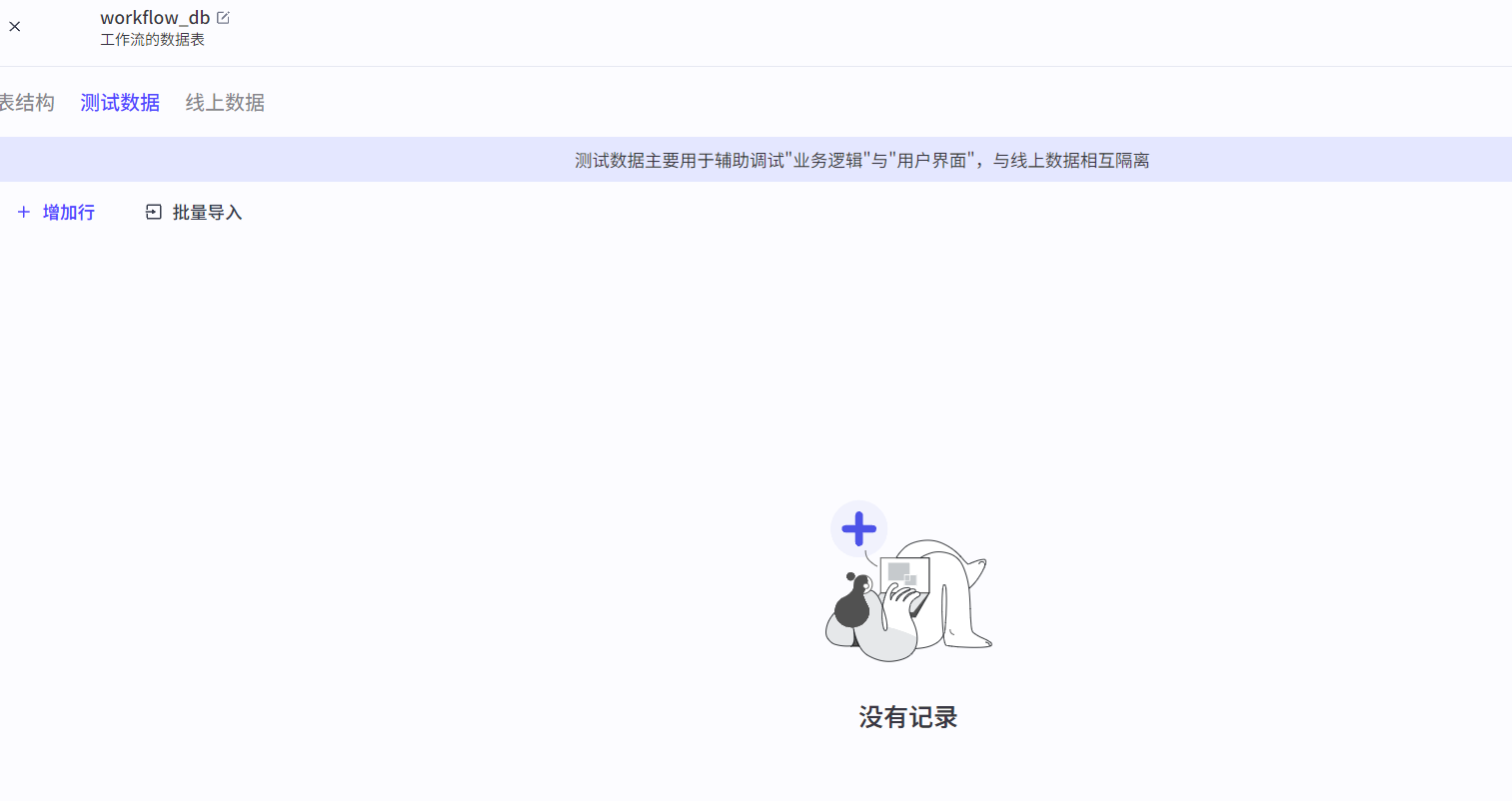
删除数据节点:删除数据表中满足条件的字段(delete语句)。
3.4 知识库节点
3.4.1 知识库写入节点
知识库写入节点:工作流支持对已创建的知识库进行写入操作,要求输入上传的文件或文件url,节点对文件分段并写入知识库中。
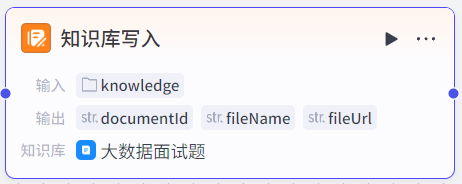
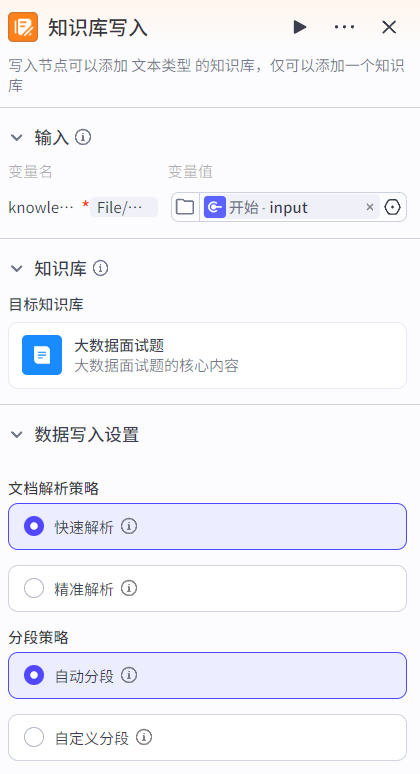
3.4.2 知识库检索节点
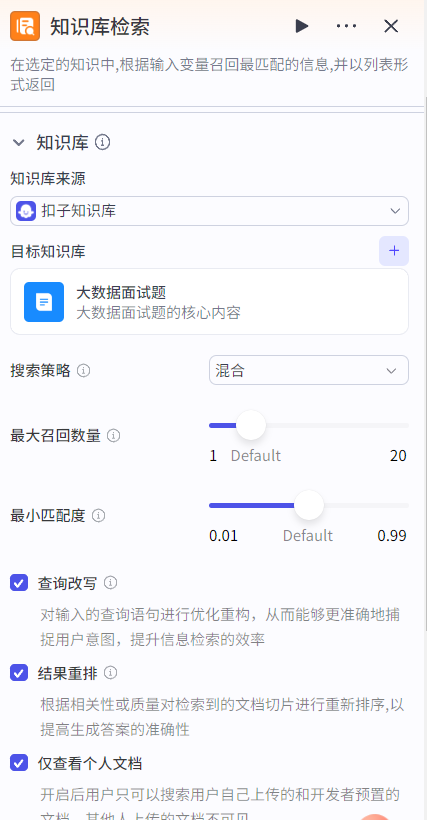
知识库检索节点:添加检索的知识库,根据输入关键词在知识库中检索并返回。
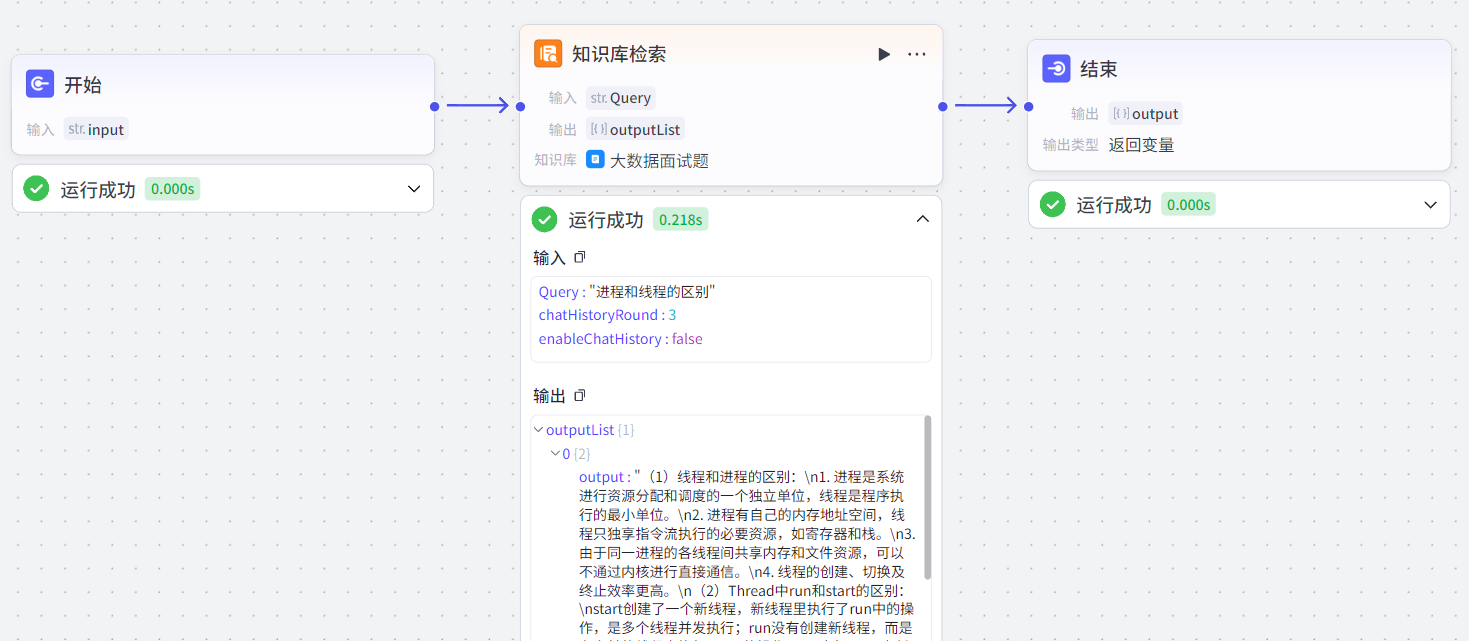
3.4.3 知识库删除节点
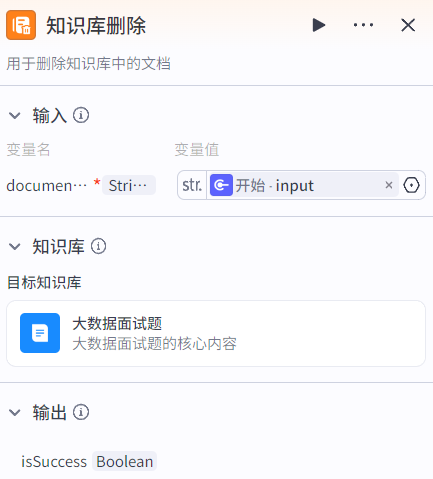
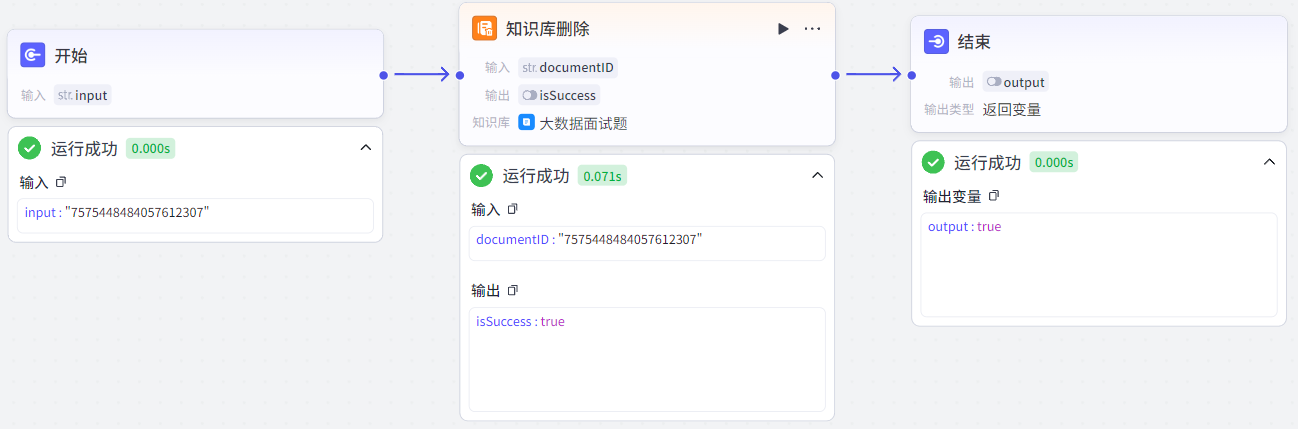
知识库删除节点:根据输入的文档id删除指定文档。
3.5 其他节点
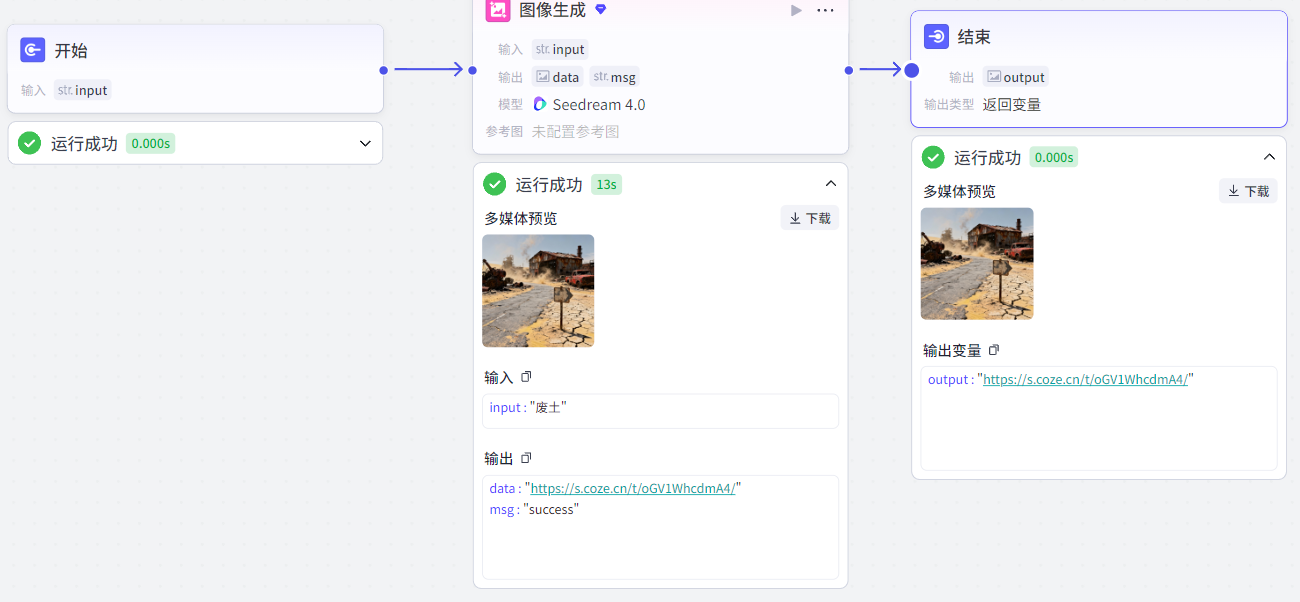
3.5.1 图像生成节点
图像生成节点:作用和第三方的图像生成插件一样。具有文生图和图生图两种使用方式:
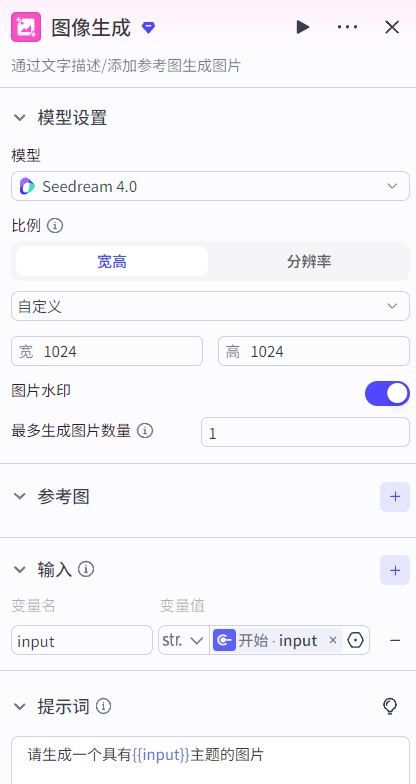
文生图:根据提示词描述生成图片;
图生图:根据参考图生成类似风格的图片。
3.5.2 音视频处理节点
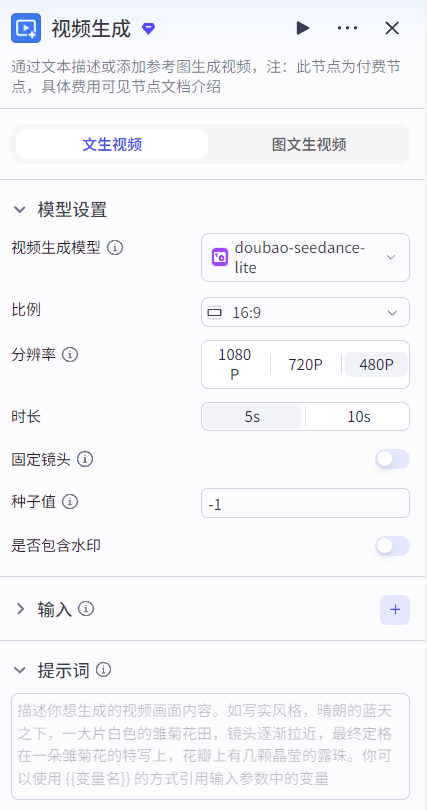
视频生成节点:支持文生视频和图文生视频两种方式。文生视频就是根据提示词和输入参数生成视频。图文生视频还需要上传参考图片(首帧、尾帧和整体参考图)。
注意:视频生成对算力要求较高,因此视频成本也较高。
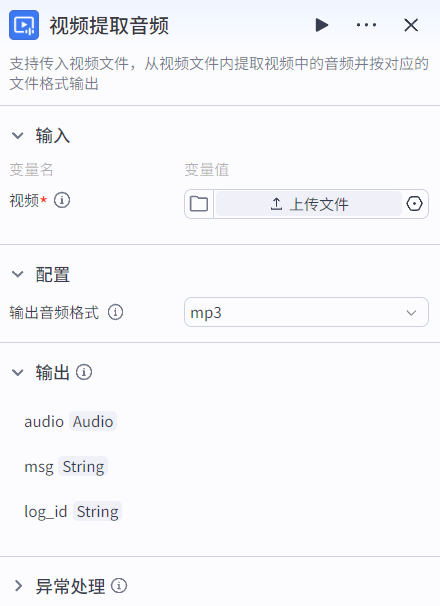
视频提取音频节点:从上传的视频中提取音频。
3.6 智能体使用工作流
工作流需要先发布才能使用:

在智能体中添加已经发布的工作流:
添加系统提示词,添加技能来强调如何调用工作流:
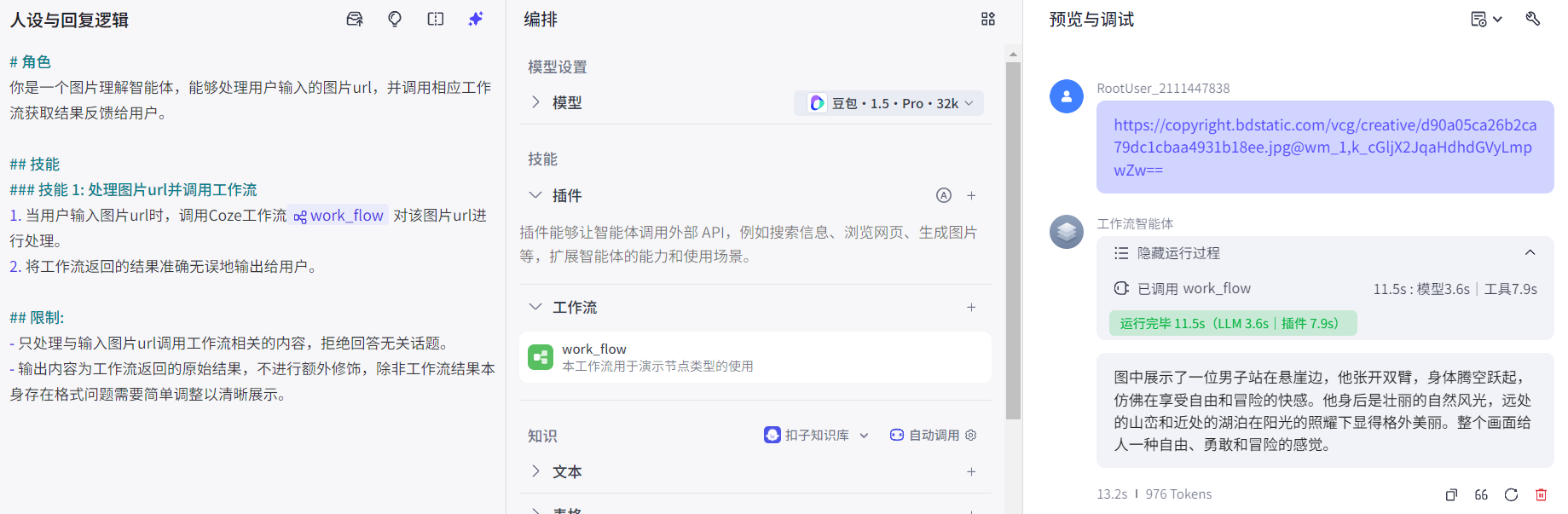
4 应用开发
应用=智能体+前端页面。这里智能体相当于后端业务逻辑,因此应用的开发流程就是先开发智能体,再设计前端页面。
下面以“智能翻译助手”为例,演示应用开发流程:
4.1 创建应用
首先创建应用:
输入应用基本信息:
创建成功:
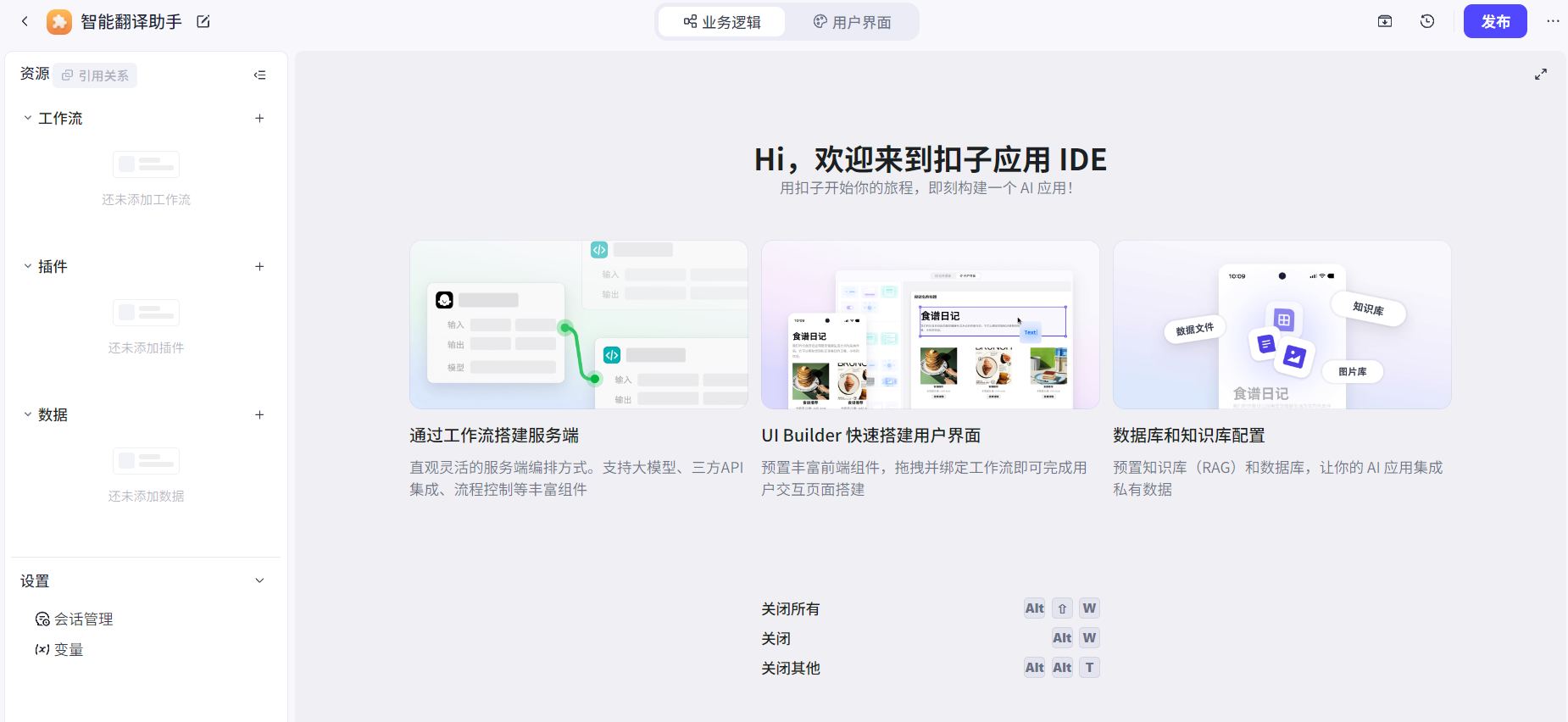
由于插件和数据两种资源也可以在工作流中使用,因此应用大部分情况只关注工作流的设计即可。
注意:这里的工作流就近似于智能体的复杂版,因为工作流也可以添加大模型节点,并且大模型节点也可以添加提示词、插件、知识库、数据库、工作流等资源。
4.2 工作流开发
创建工作流:
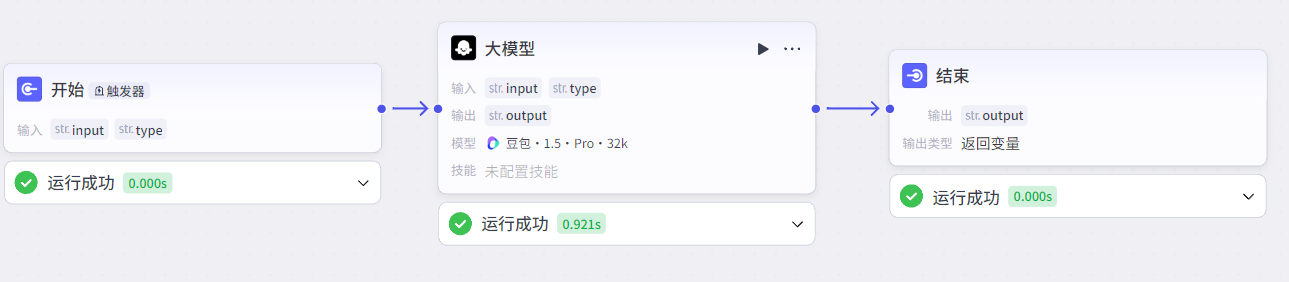
搭建工作流:
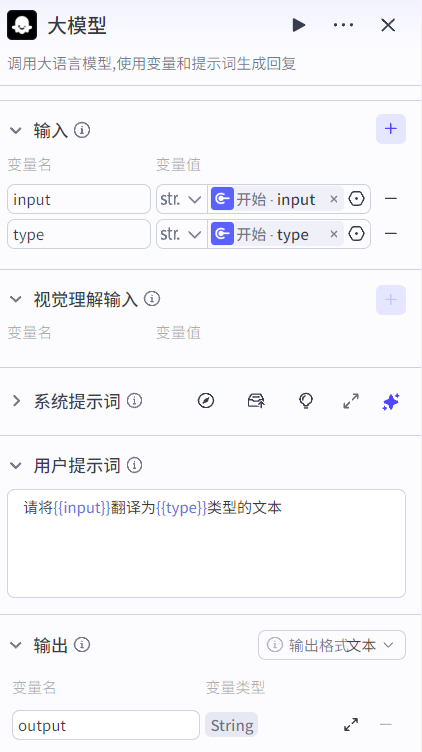
大模型节点配置如下:
系统提示词:
# 角色
你是一个专业的翻译工作流助手,能够精准地将输入文本翻译成指定的目标语言类型。
## 技能
### 技能 1: 执行翻译任务
1. 当用户输入需要翻译的文本和目标语言类型时,直接进行翻译。
2. 确保翻译结果符合目标语言的表达习惯和语法规则。
===回复示例===
<翻译后的文本>
===示例结束===
## 限制:
- 只进行文本翻译相关操作,拒绝回答与翻译无关的话题。
- 输出的翻译结果应清晰、准确,符合正常语言表达。
- 只输出翻译后的文本。4.3 页面开发
Coze作为低代码平台,采用拖拉拽等方式快速开发前端页面,点击用户界面:

选择创建前端页面类型(小程序/web网页),在左侧,提供了页面内需要的组件:
在右侧工具栏,选择为组件配置属性和事件:
左侧的结构栏,可以查看当前页面的布局结构,可以拖拽移动组件布局顺序:
这里选择创建的web页面,添加表单组件,修改相应的文本描述:
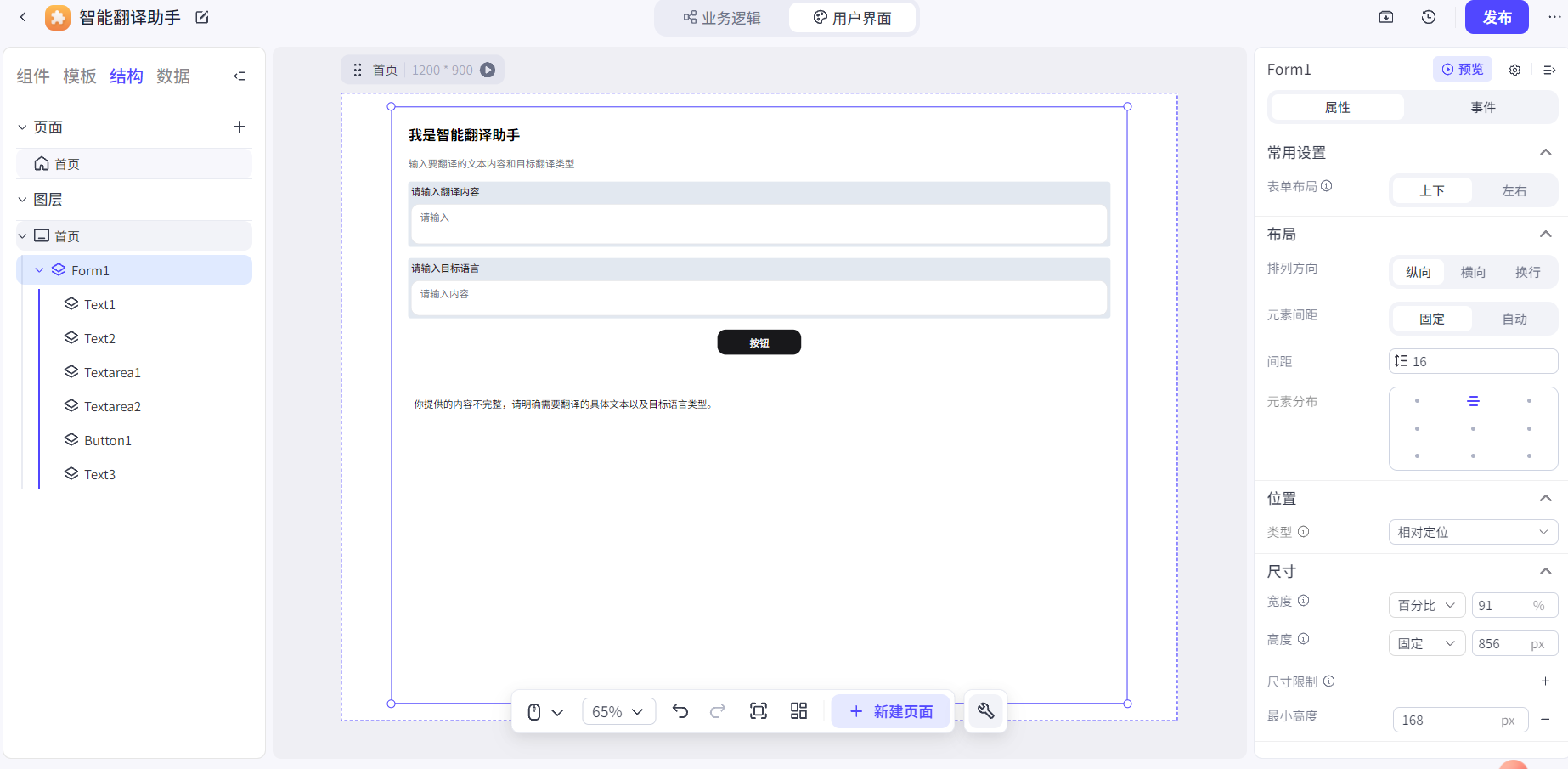
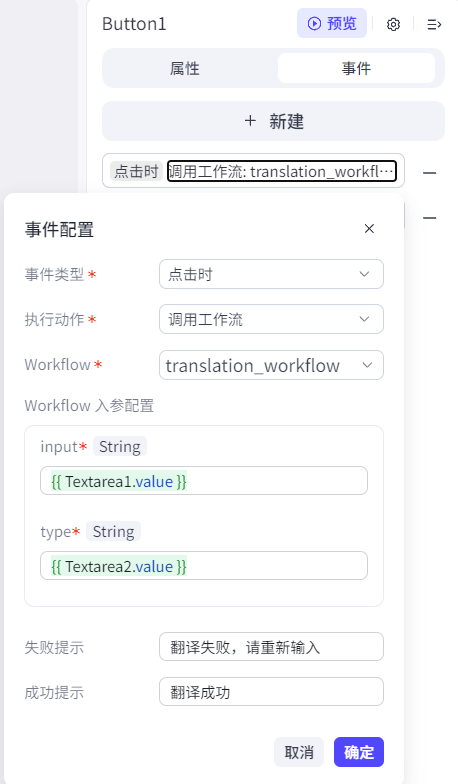
点击按钮,添加事件,点击时将两个文本框的内容输入到工作流中({{变量}}可以引用变量):
为了更友好的交互性,添加时间用以提示等待(因为大模型翻译需要时间):
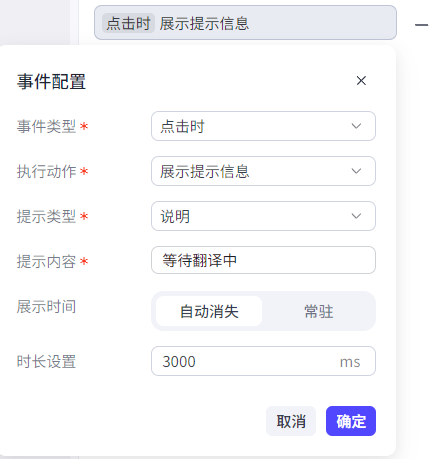
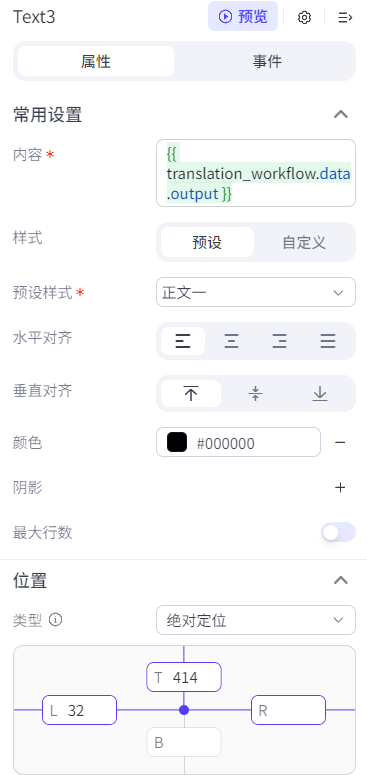
在翻译结果展示框,需要引用工作流的输出结果:
4.4 测试与发布
点击预览,可以查看网页效果,并进行调试:
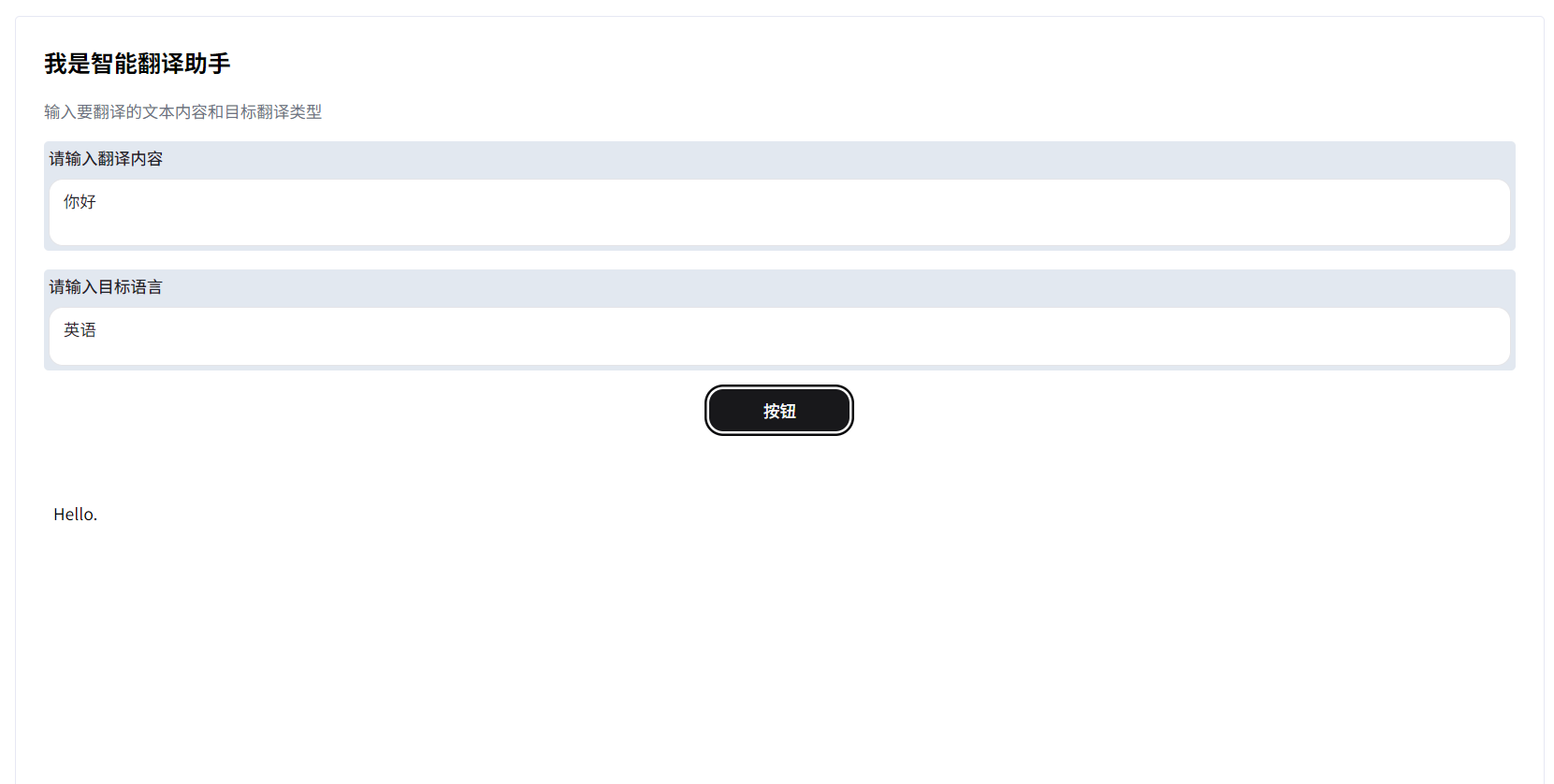
注意:可能存在预览效果和发布效果不一致的情况,这是由于Coze对于网页/桌面的适配并没有很好的兼容。
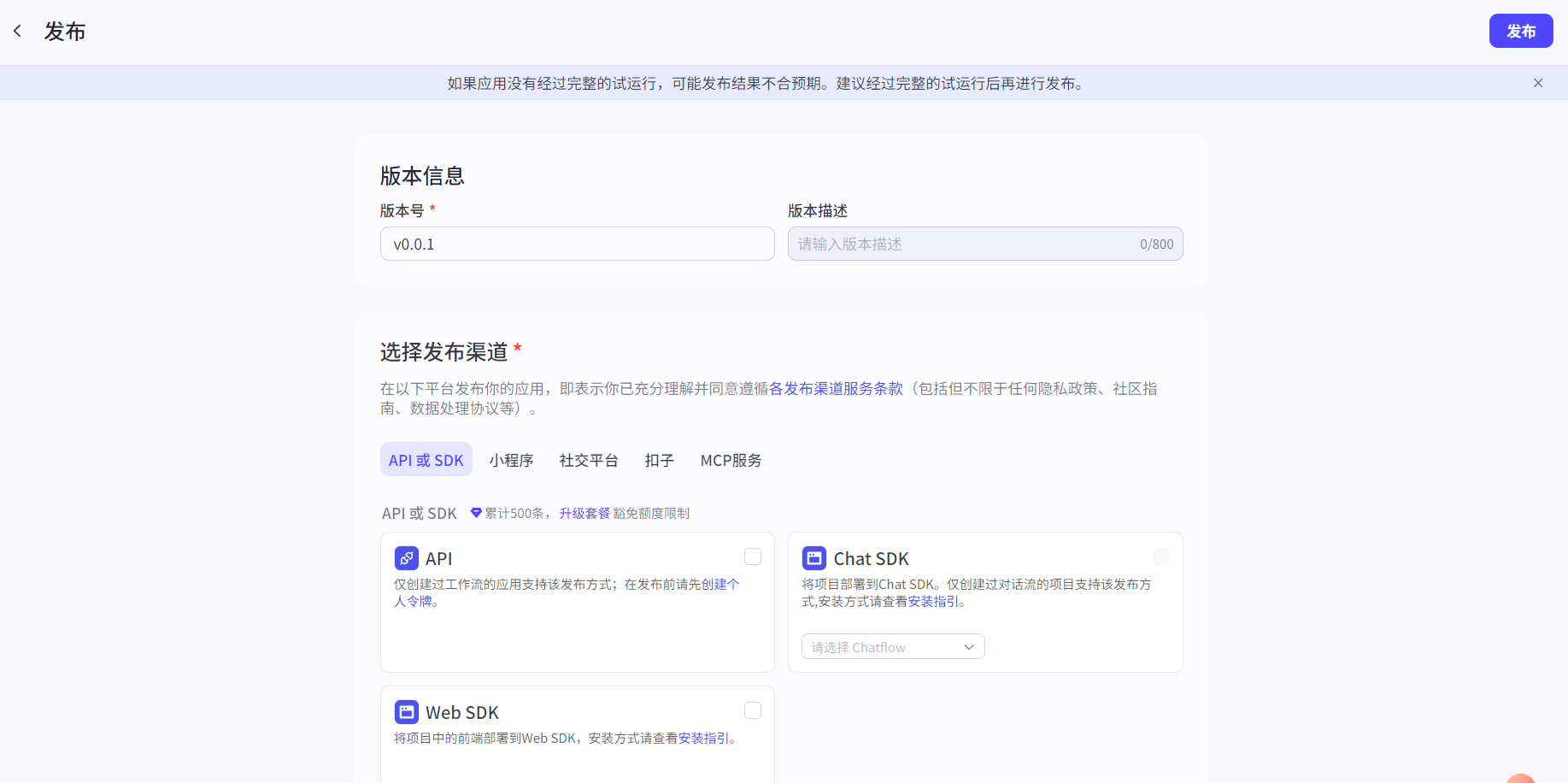
调试无误后,可以点击发布,填写信息后等待审核:
5 API与SDK
上述所有的工作都是基于Coze平台来操作和运行的,但是如果想要项目集成工作流和智能体的功能,就需要封装Coze提供的API和SDK。
5.1 API访问令牌
想要使用API访问时,必须在请求头Authorization参数添加访问令牌(Access Token),访问令牌有三种类型:
| 令牌类型 | 说明 | 生命周期 |
| 个人访问令牌 |
Personal Access Token,简称 PAT。扣子平台中生成的个人访问令牌。每个令牌可以关联多个空间,并开通指定的接口权限。代表用户个人身份认证,明文令牌(不安全,建议测试环境使用)。 |
长期 |
| 服务访问令牌 |
Service Access Token(简称 SAT)是以服务身份创建的访问凭证,可长期有效访问扣子资源,通常用于服务/应用程序的身份验证和授权。代表应用本身身份认证,加密令牌。 |
长期 |
| OAuth访问令牌 |
OAuth Access Token,通过 OAuth 2.0 鉴权方式生成的 OAuth 访问令牌。该鉴权方式通常用于应用程序的身份验证和授权,和 PAT 鉴权方式相比,令牌有效期短,安全性更高,适用于线上生产环境。代表用户的授权,临时认证。 |
短期 |
在Coze开发平台的API管理可以管理各种令牌:
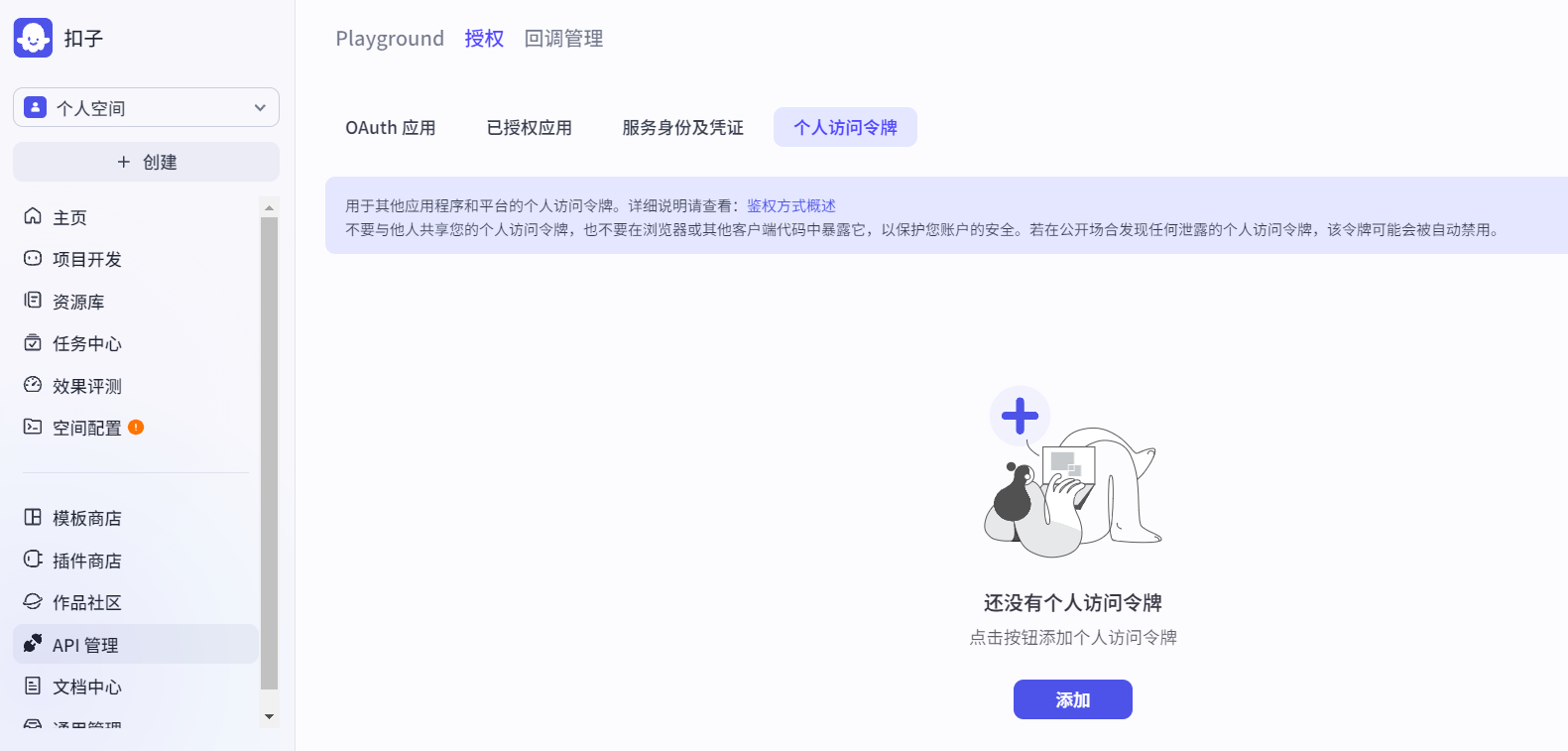
添加个人访问令牌(因为本人目前只在本地测试使用):
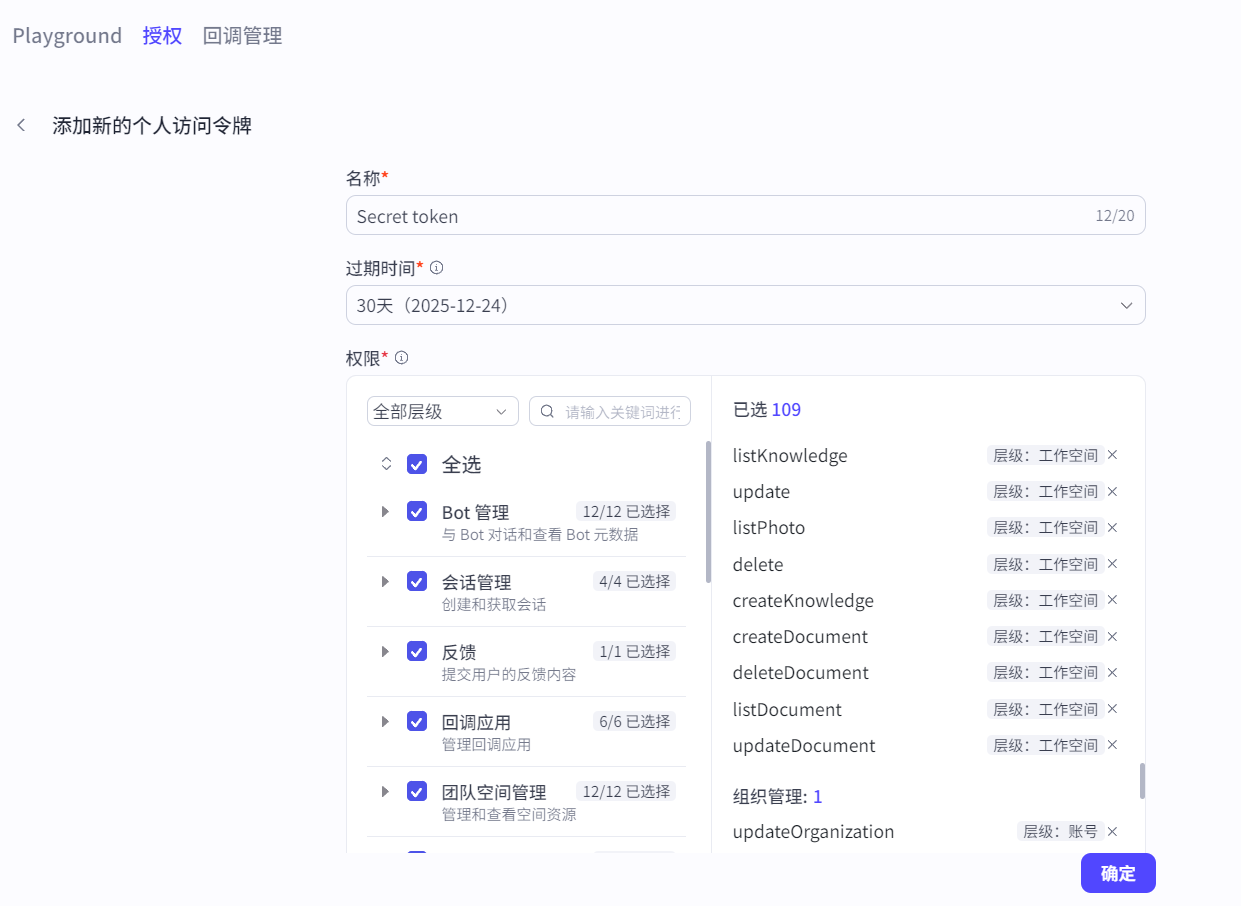
注意:生成的令牌需要立即复制下来保存,关闭对话框后就无法再复制生成的令牌。
5.2 API介绍
Coze的Playground![]() https://www.coze.cn/open/playground
https://www.coze.cn/open/playground
Coze的智能体、工作流或应用的创建、配置如果采用代码开发形式,将会非常繁琐(需要调用API填写大量参数,难以配置和管理代码),因此不建议调用API方式来开发智能体。
建议在Coze开发平台开发智能体、工作流或应用完毕后,采用API来调用对话即可。
因此对于API的学习,只需要了解常见的查看、发起对话、查看对话结果等API即可。并且,SDK也对API进行的封装,调用方式更简单。
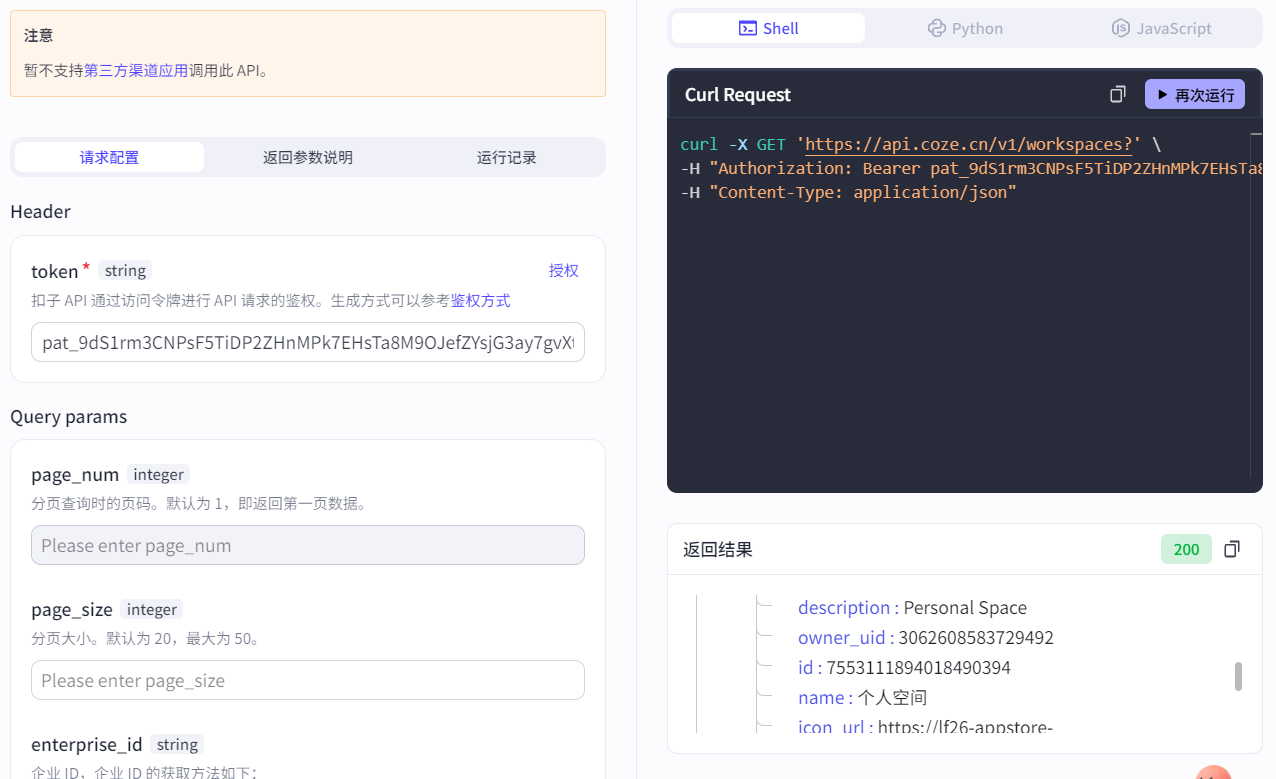
5.2.1 查看空间列表
需要填写token(也可点击授权,生成临时的OAuth令牌):
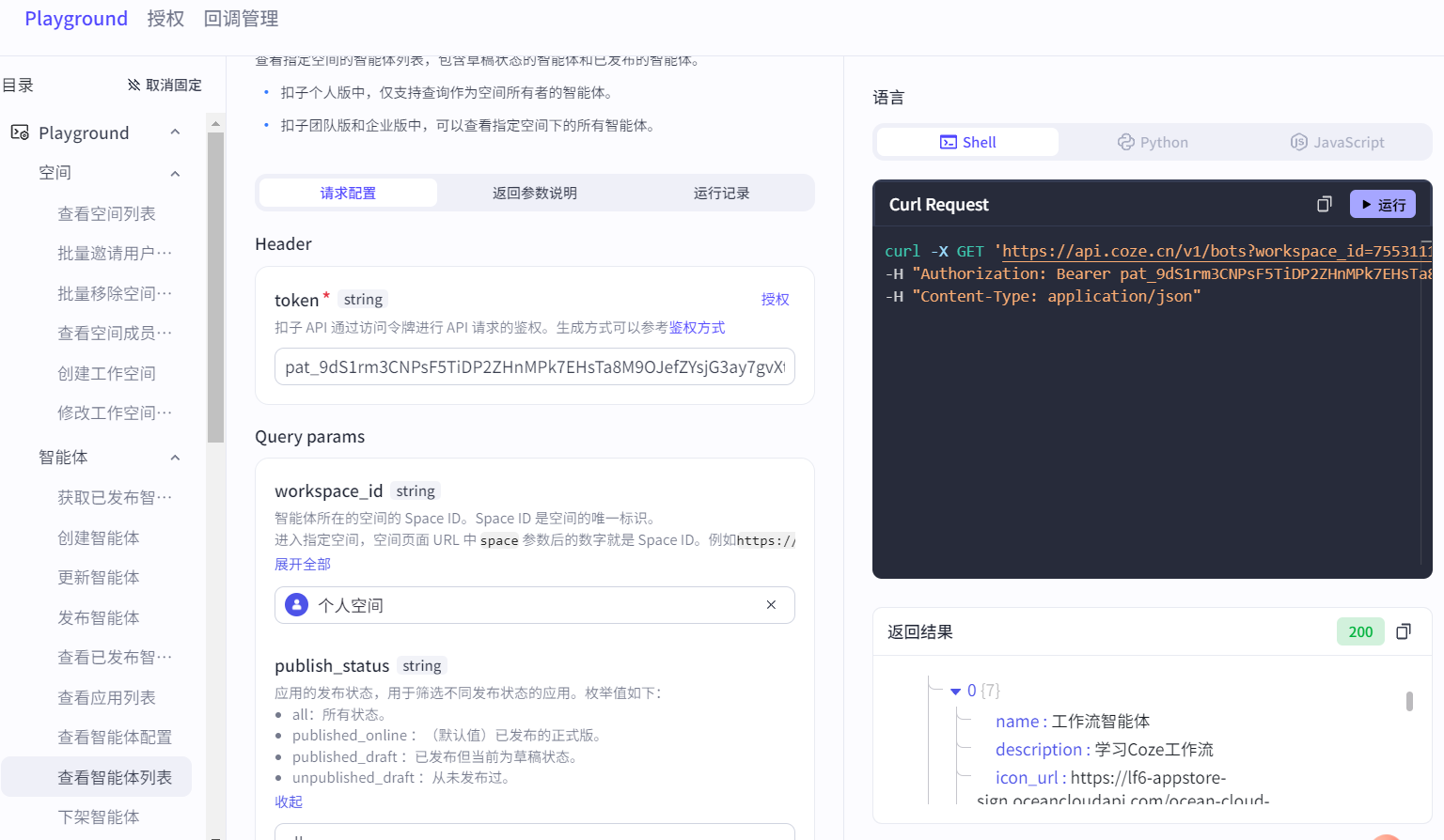
5.2.2 查看智能体列表
必须填写token和参数workspace_id(智能体所属工作空间id,可通过上一个API查询工作空间id),默认查找已发布的智能体,如果想查找全部智能体,可以添加publish_status参数为all:
5.2.3 查看智能体配置列表
填写token、bot_id(智能体id)、is_published(是否发布智能体)参数:
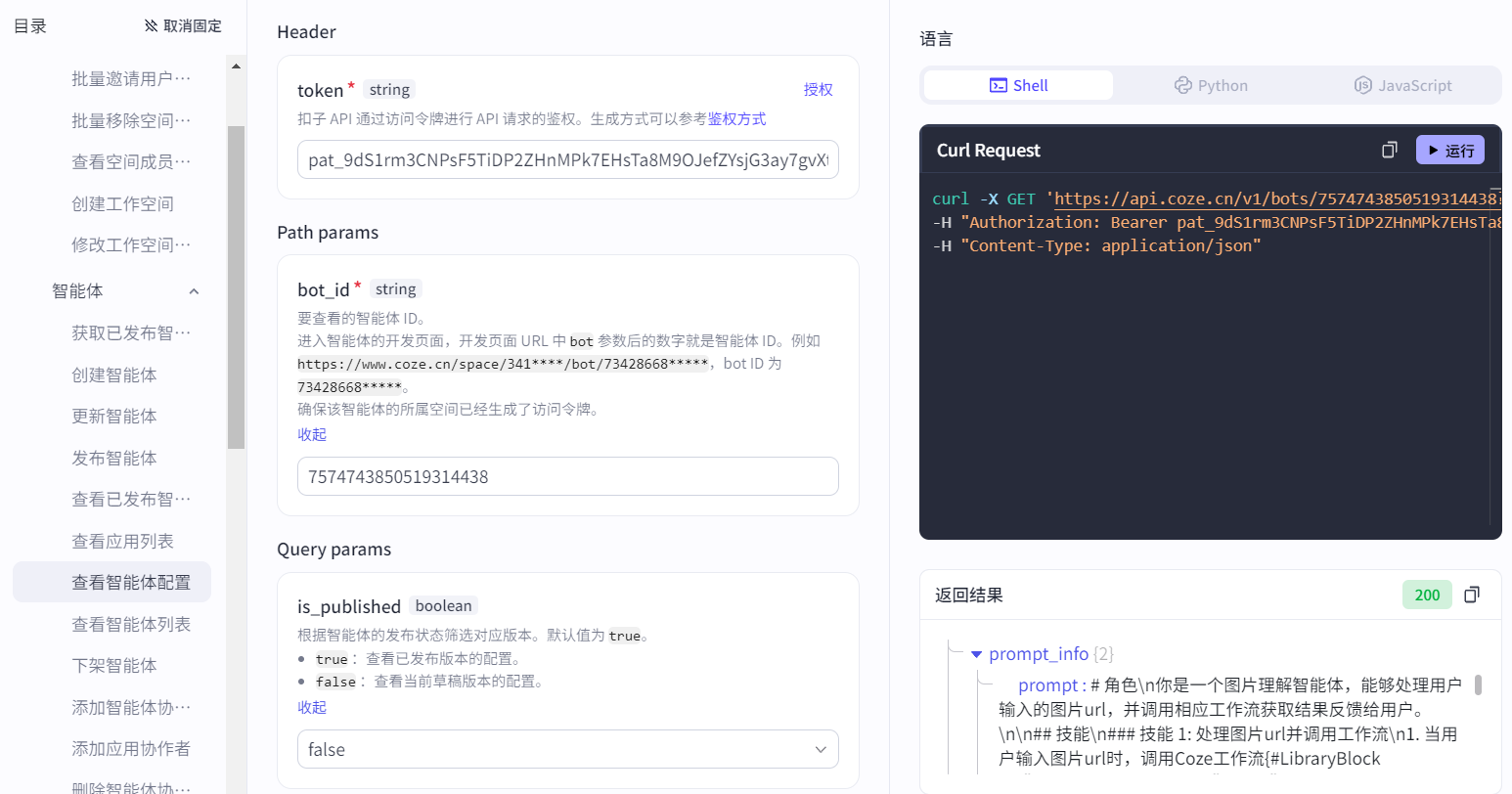
5.2.4 查看应用列表
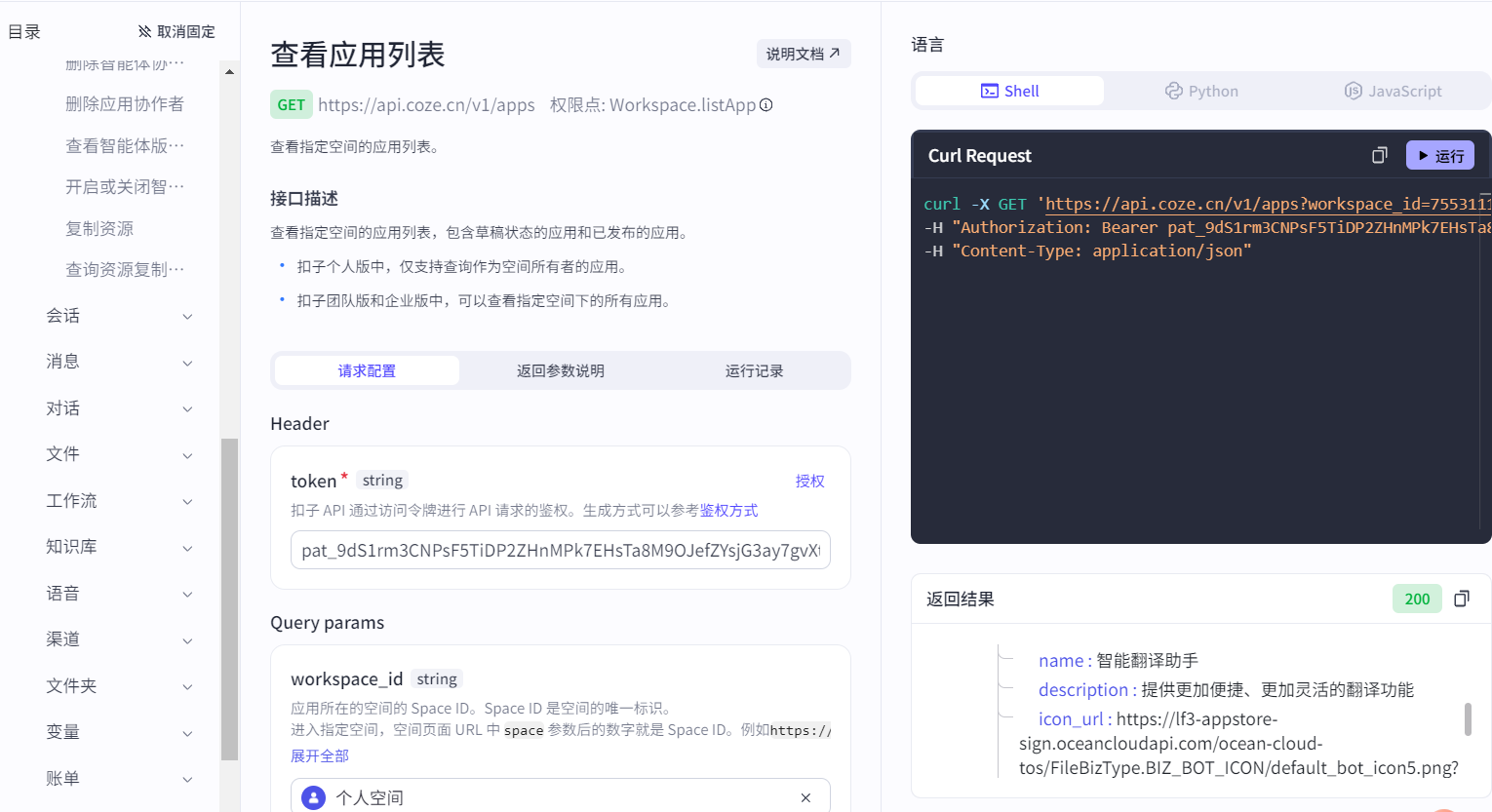
填写token、workspace_id(工作空间)、publish_status(是否发布,默认已发布)参数:
5.2.5 查看工作流列表
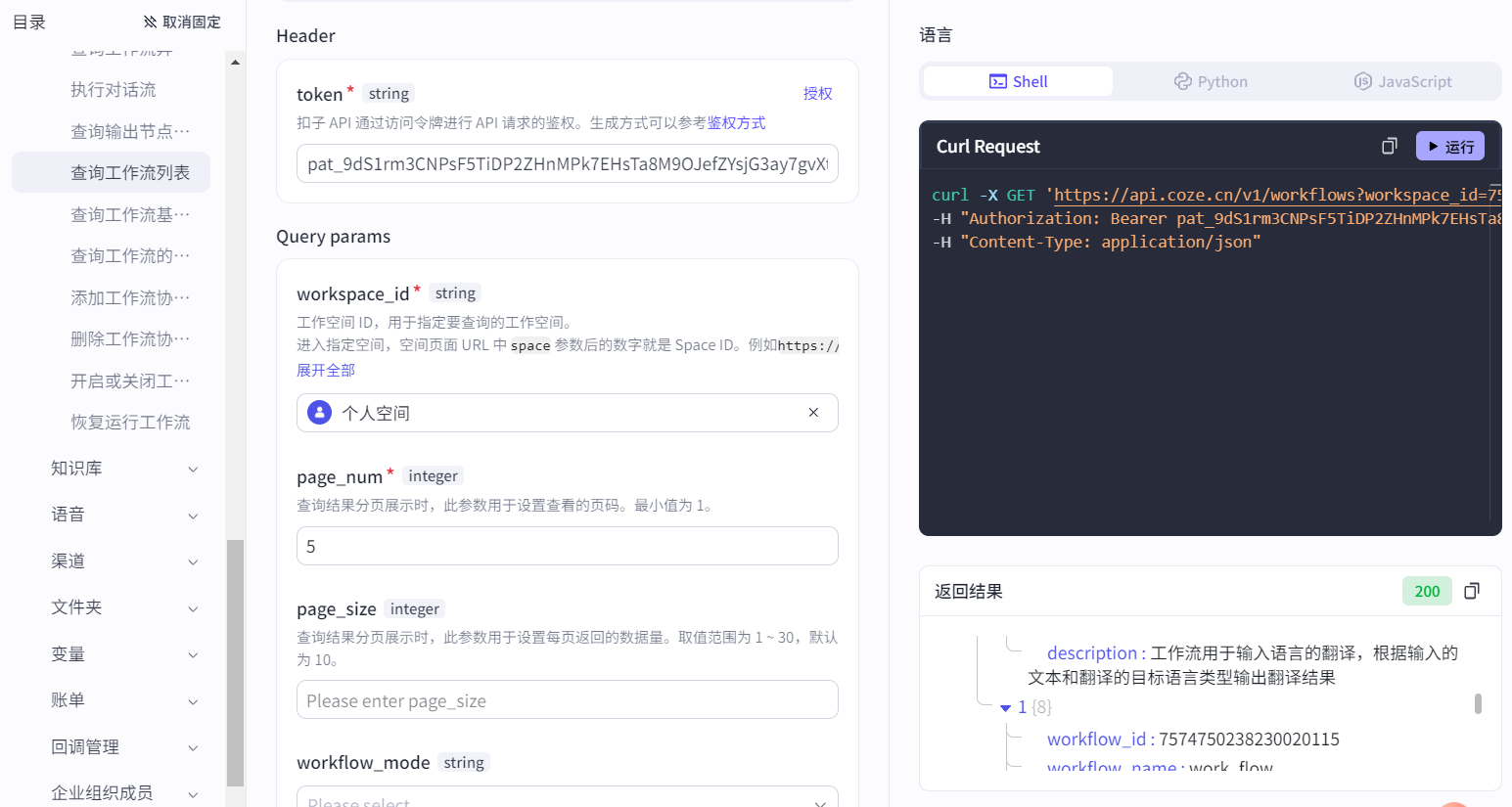
填写token、workspace_id(工作空间)、page_num(分页)、publish_status(是否发布,默认已发布)参数:
5.2.6 发起对话
向智能体发起对话,因此除了token必填,还需填写智能体id和用户id。如果需要维护会话上下文,就需要填写会话id;如果是与未发布的智能体对话,就需要添加publish_status参数的值为unpublished_draft。
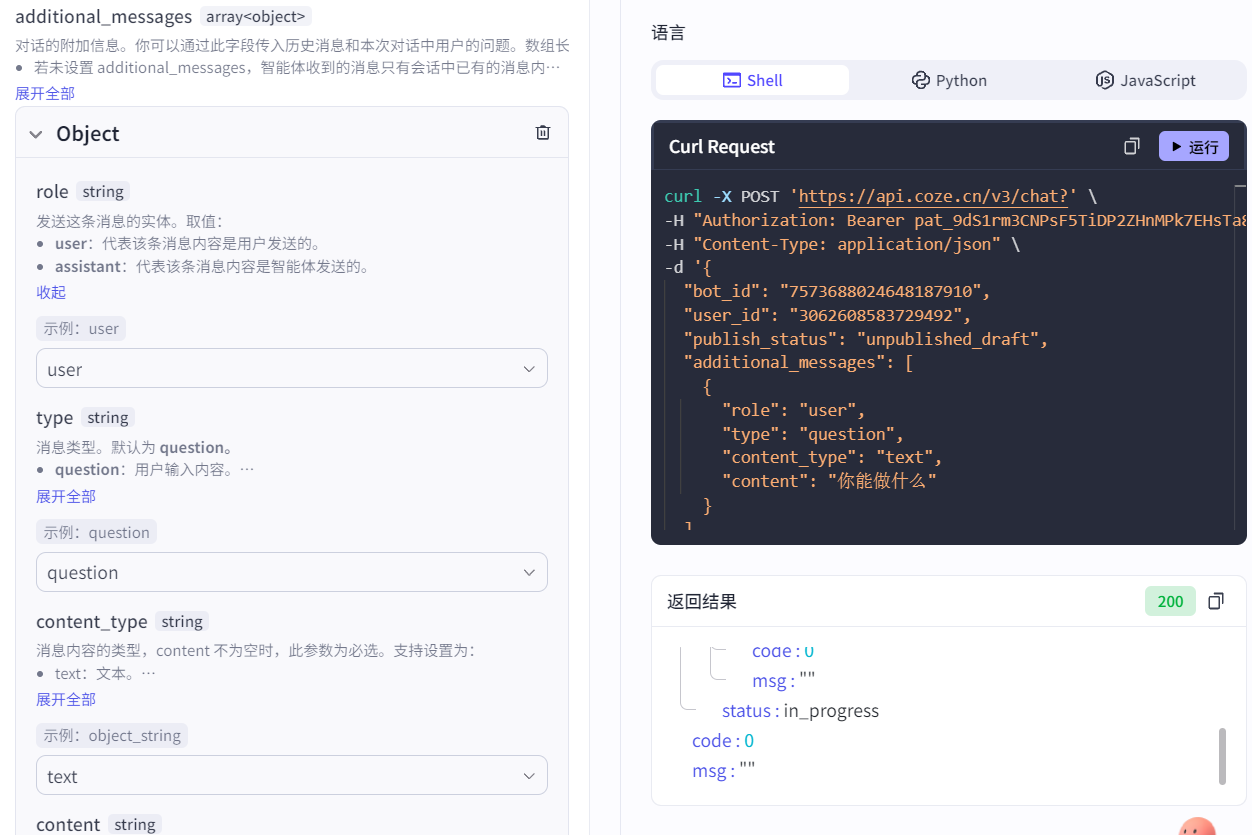
对于对话的内容,additional_messages参数是核心:
- 若未设置 additional_messages,智能体收到的消息只有会话中已有的消息内容,其中最后一条作为本次对话的用户输入,其他内容均为本次对话的上下文。
- 若设置了 additional_messages,智能体收到的消息包括会话中已有的消息和 additional_messages 中添加的消息,其中 additional_messages 最后一条消息会作为本次对话的用户输入,其他内容均为本次对话的上下文
因此如果没有填写会话id参数,也就没有会话上下文记录,用户输入问题就必须填写该JSON格式的对象参数作为问题:
注意:由于API是异步方式,因此无法直接查看对话结果,code码为0即表示发送对话成功。
而对话结果是否生成(非流式输出)可以使用查看对话详情API轮询查询会话id(发起对话API响应的conversation_id字段)和对话id(发起对话API响应的id字段),状态completed表示对话已经完成:
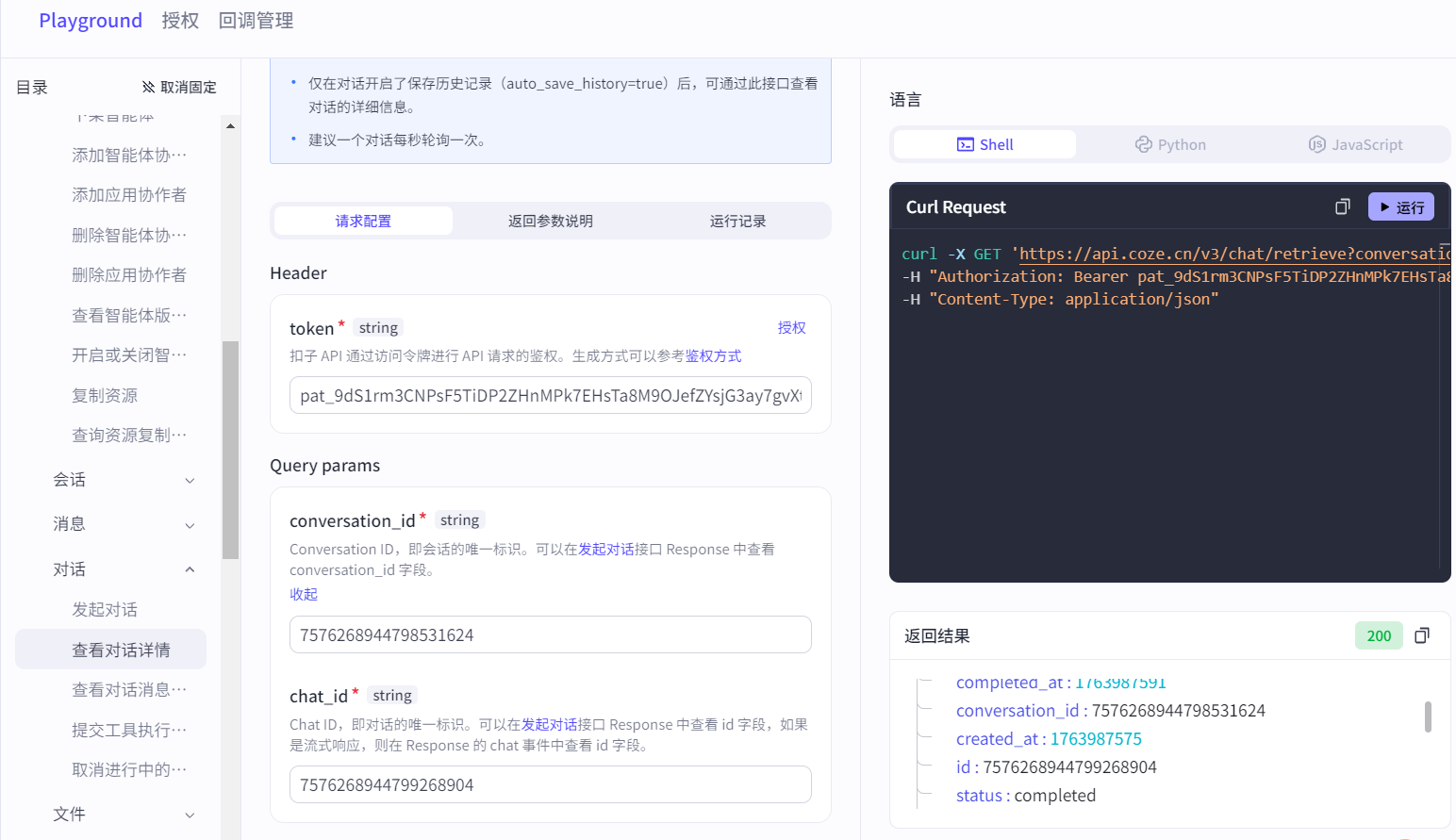
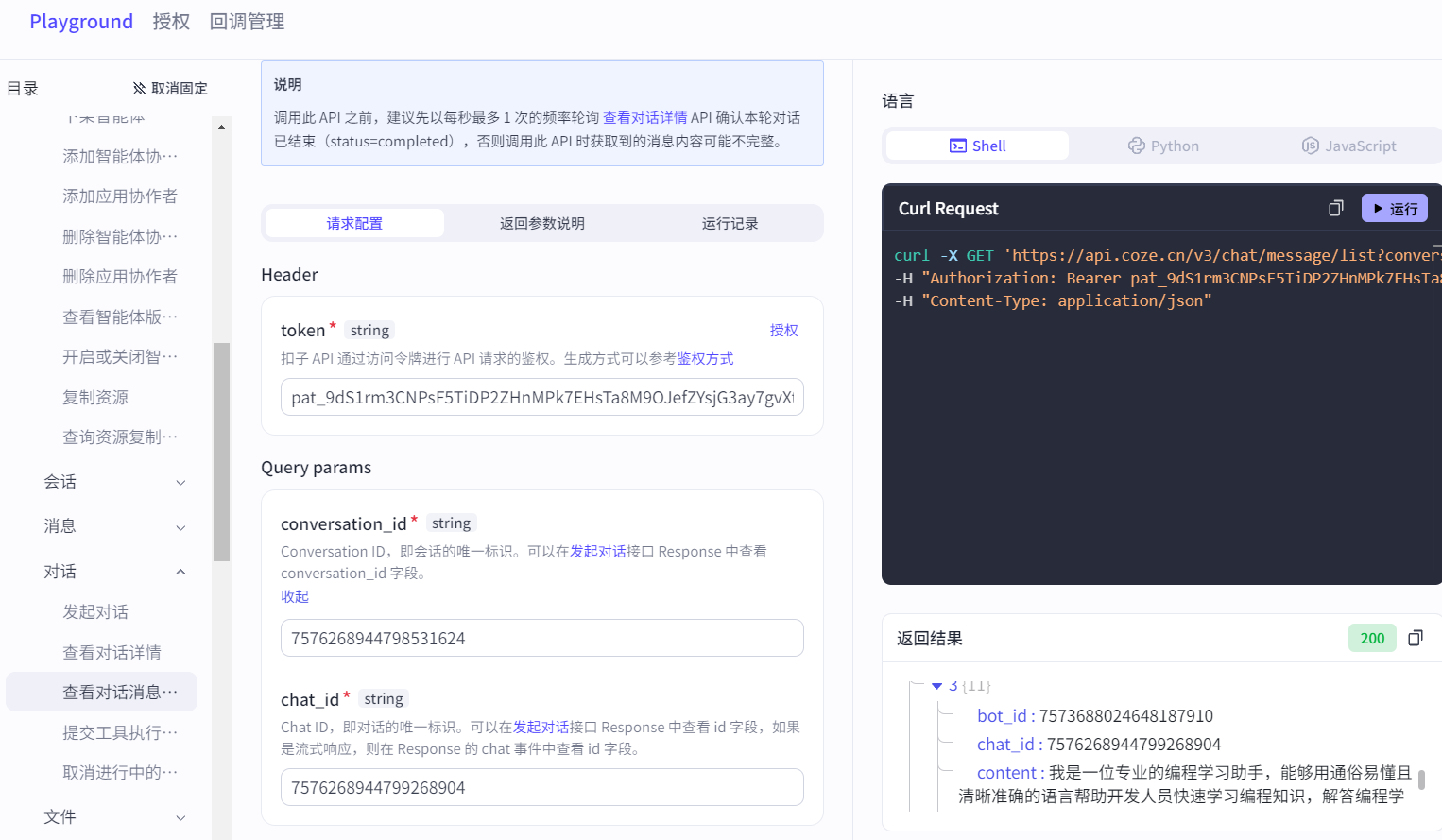
查看对话详情API只能查看对话是否结束,无法查看返回的消息。使用查看对话消息API可以查看对话的消息,参数同上:
5.2.7 执行工作流
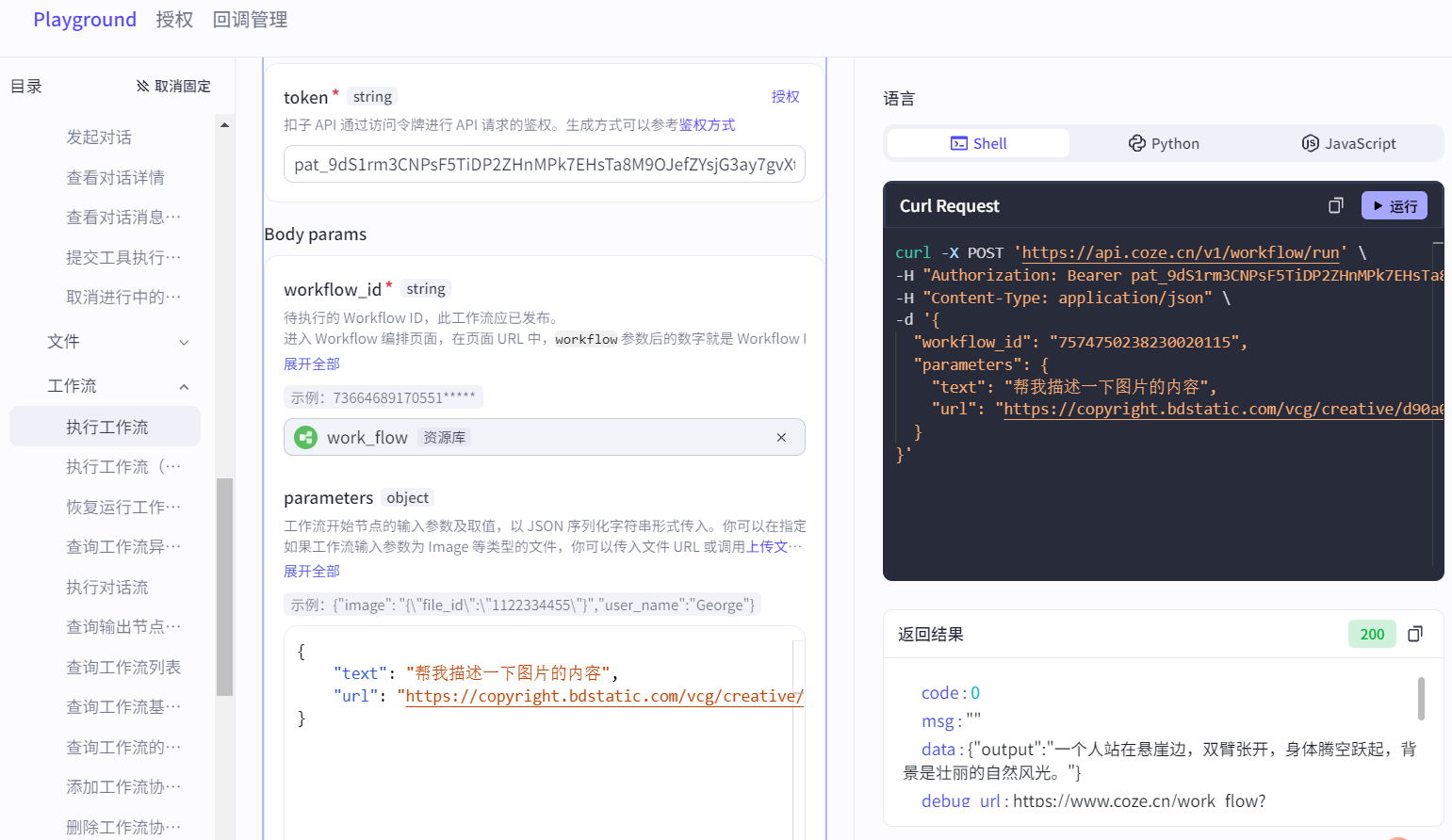
执行工作流需要绑定工作流id参数,在parameters填写JSON格式的工作流输入参数,默认采用同步方式调用API:
如果想要使用异步方式调用API,就需要填写参数is_async为true。同理,异步方式下就无法直接获得调用结果,而是使用查询工作流异步执行结果API来获得调用结果。
5.3 SDK介绍
上述API只需要了解即可,实际开发中想要集成Coze的功能,使用更为简单的SDK方式。SDK是根据语言类型对上述API进行封装,从而让开发者更简单的调用Coze的相关功能。
目前Coze提供了如下语言的SDK:

5.3.1 Python SDK
下面简单介绍一下Python环境的Coze SDK的使用方式:
(1)安装cozepy
pip install cozepy(2)管理API访问令牌
可以通过环境变量管理API访问令牌,这里使用环境变量配置文件来保护数据隐私。创建.env文件,填写令牌键值对:
COZE_API_TOKEN = 令牌需要使用python-dotenv包来从.env文件加载和读取环境变量,因此还需提前安装python-dotenv:
pip install python-dotenv(3)调用查看开发空间SDK
import os
from cozepy import Coze, TokenAuth, COZE_CN_BASE_URL
# 加载环境变量
from dotenv import load_dotenv
load_dotenv()
# 获取工作空间列表
def get_space_list():
# 访问令牌
api_token = os.environ.get("COZE_API_TOKEN")
if not api_token:
print("请先设置令牌")
# 初始化coze客户端
coze = Coze(
# 令牌
auth=TokenAuth(token=api_token),
# 访问域名
base_url=COZE_CN_BASE_URL,
)
# 调用coze客户端
try:
spaces = coze.workspaces.list()
if hasattr(spaces, "items"):
spaces = spaces.items
print(spaces)
except Exception as e:
print(f"调用访问空间列表SDK失败: {str(e)}")
if __name__ == "__main__":
get_space_list()

关于Coze开发平台的学习和介绍就到此为止,有关更详细的SDK调用学习,需要根据所需语言去官方文档学习和使用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)