【大模型高效微调】BitFit、promp_tuning、p_tuning、prefix_tuning
一、BitFit
(论文:BitFit: Simple Parameter-efficient Fine-tuning or Transformer-based Masked Language-models)是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。
对于Transformer模型而言,冻结大部分 transformer-encoder 参数,只更新bias参数跟特定任务的分类层参数。涉及到的bias参数有attention模块中计算query,key,value跟合并多个attention结果时涉及到的bias,MLP层中的bias,Layernormalization层的bias参数。
# bitfit
# 选择模型参数里面的所有bias部分
num_param = 0
for name, param in model.named_parameters():
if "bias" not in name:
param.requires_grad = False
else:
num_param += param.numel()二、Prompt-Tuning
(论文:The Power of Scale for Parameter-Efficient Prompt Tuning)https://arxiv.org/abs/2104.08691
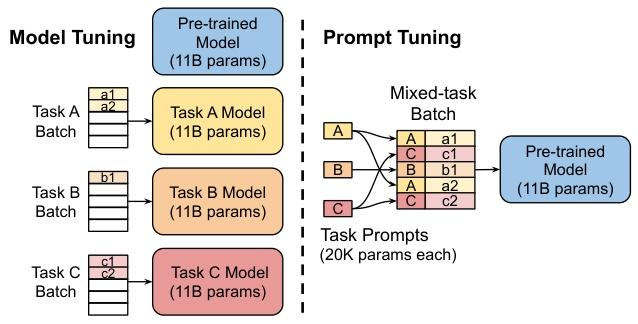
- 模型本身完全 “冻结”:pre-trained 好的大模型参数一动不动,所有任务共用这一个 “基础模型”,不用重复存储;
- 只训练 “小提示”:针对每个任务,额外加一段短的 “虚拟提示词”(不是真实文字,是模型能理解的数值向量),只训练这段 “提示” 的参数,让它学会 “告诉” 模型该做什么任务;
Ptompt-Tuning的思想:冻结模型全部参数,在训练数据前加入一小段Prompt,只训练Prompt表示层,即一个Embedding模块,Prompt又存在两种形式,一种是Hard Prompt,一种是soft Prompt
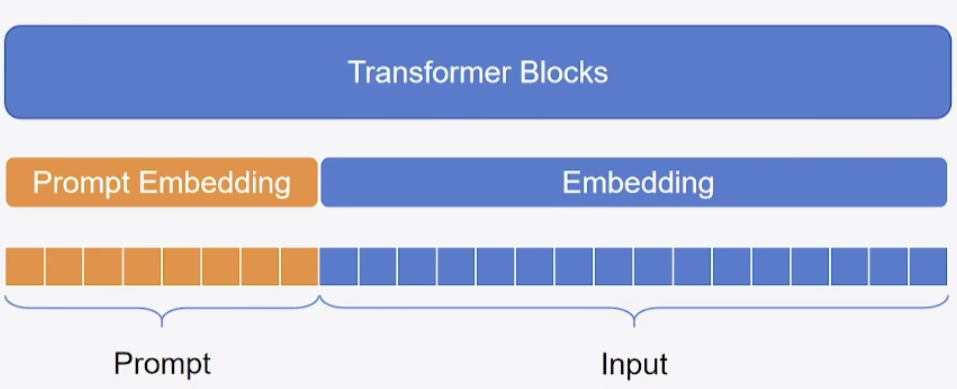
from peft import PromptTuningConfig, get_peft_model, TaskType, PromptTuningInit
# Soft Prompt
# config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10)
# config
# Hard Prompt
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
prompt_tuning_init_text="下面是一段人与机器人的对话。",
num_virtual_tokens=len(tokenizer("下面是一段人与机器人的对话。")["input_ids"]),
tokenizer_name_or_path="Langboat/bloom-1b4-zh")三、P-Tuning & P-Tuning V2
P-tuning:
https://arxiv.org/abs/2103.10385
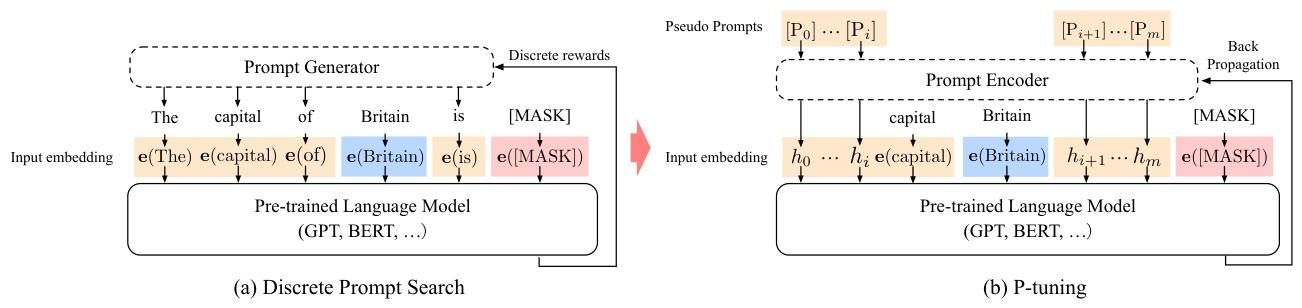
P-Tuning的思想:在Prompt-Tuning的基础上,对Prompt部分进行进一步的编码计算,加速收敛。具体来说,PEFT中支持两种编码方式,一种是LSTM,另一种是MLP,与prompt-Tuning不同的是,prompt的形式只有soft-Prompt
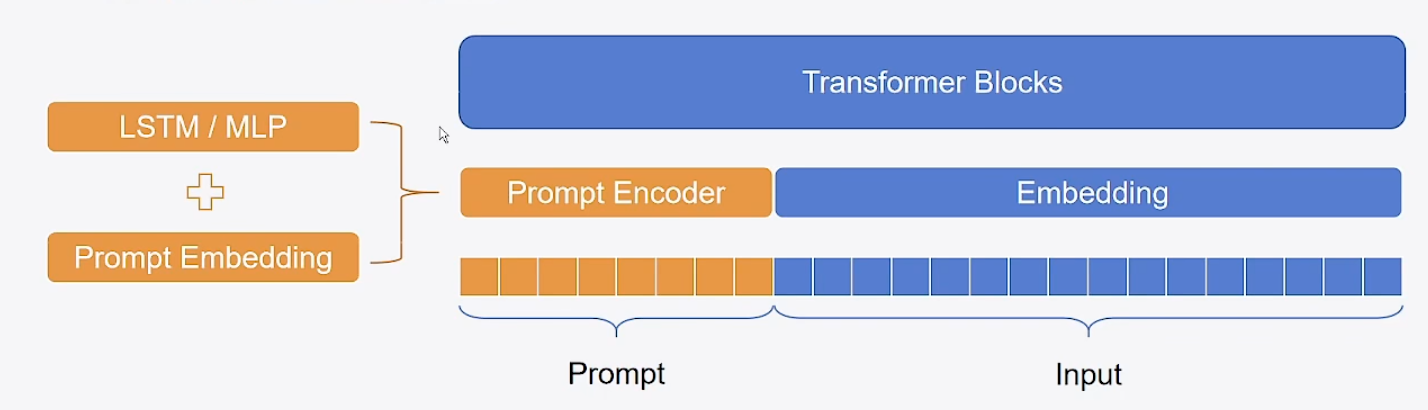
from peft import PromptEncoderConfig, TaskType, get_peft_model, PromptEncoderReparameterizationType
config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10,
encoder_reparameterization_type=PromptEncoderReparameterizationType.MLP,
encoder_dropout=0.1, encoder_num_layers=5, encoder_hidden_size=1024)P-Tuning v2:
https://aclanthology.org/2022.acl-short.8/
传统提示调优仅在输入层插入连续提示,存在 “提示容量有限、对预测影响间接” 的缺陷,导致模型规模 < 10B 时性能远差于微调。P-tuning v2 通过核心设计 —— 在模型每一层插入连续提示(深度提示调优)
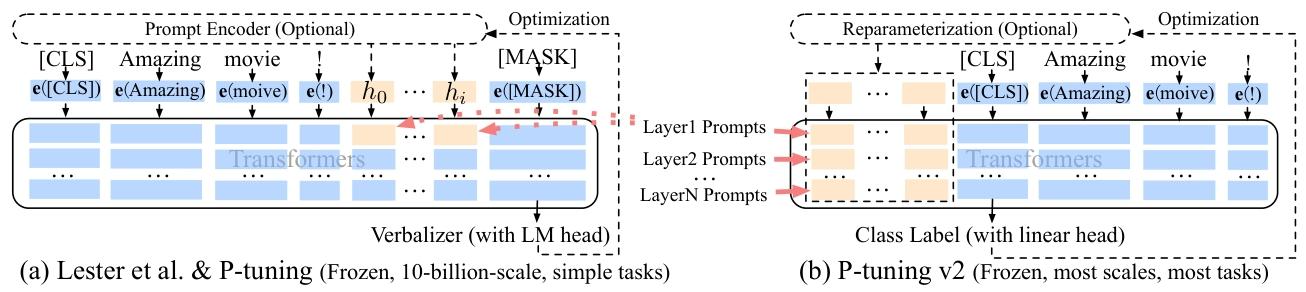
四、Prefix-Tuning
https://arxiv.org/abs/2101.00190
ptrfix-Tuning的思想:相较于Prompt-Tuning和P-Tuning,prefix-Tuning不再将prompt加在embedding层,而是将其作为可学习的前缀,放置在Transformer模型的每一层中,具体表现形式为past_key_values。
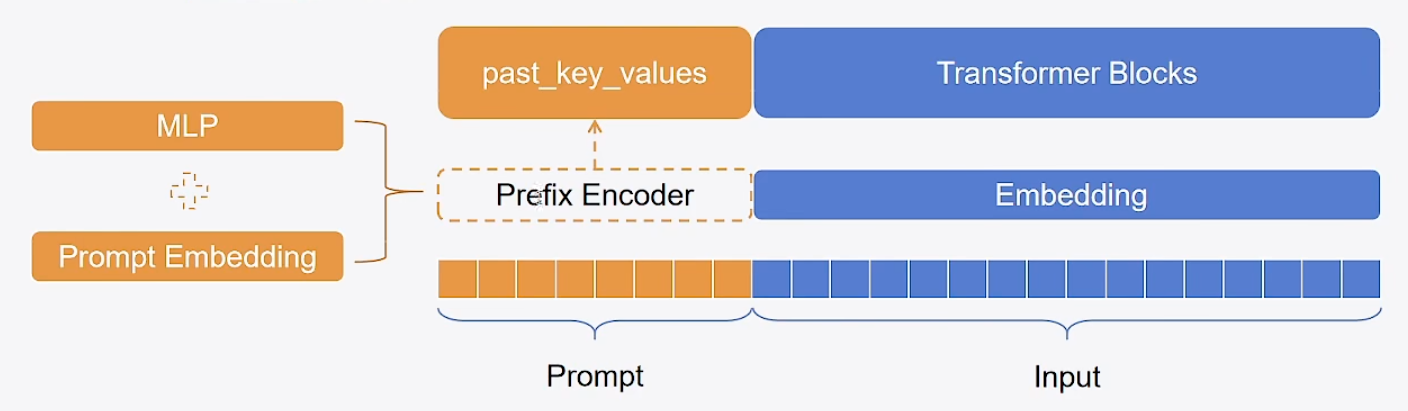
from peft import PrefixTuningConfig, get_peft_model, TaskType
config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10, prefix_projection=True)五、LoRa
https://arxiv.org/pdf/2106.09685
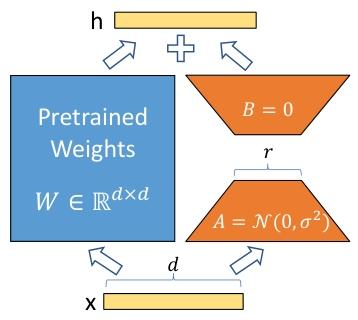
本文提出LoRA(Low-Rank Adaptation,低秩适配) 方法,核心是冻结预训练语言模型的所有权重,通过在 Transformer 每层注入可训练的低秩分解矩阵(A 和 B) 实现下游任务适配,大幅减少可训练参数。实验表明,LoRA 在 RoBERTa、DeBERTa、GPT-2 及GPT-3 175B上性能与全微调相当甚至更优:相较于 GPT-3 全微调,可训练参数减少10,000 倍,GPU 内存需求降低3 倍(从 1.2TB 降至 350GB),且无额外推理延迟(区别于 Adapter);在低数据场景(如 MNLI-100 样本)表现优于全微调,对未见过主题的外推能力更强。同时,研究发现模型适配时权重更新的 “内在秩” 极低(GPT-3 中 r=1-2 即可),为 LoRA 的有效性提供理论支撑。
假设权重更新具有低 “内在秩”,用BA(低秩矩阵)近似
,公式为
from peft import LoraConfig, TaskType, get_peft_model
config = LoraConfig(task_type=TaskType.CAUSAL_LM, target_modules=".*\.1.*query_key_value", modules_to_save=["word_embeddings"])
六、PEFT
https://arxiv.org/pdf/2303.15647
本文系统综述了 2019 年初至 2024 年中的50 余篇参数高效微调(PEFT)相关论文,提出 PEFT 方法的三级分类体系(添加型、选择型、重参数化型),并通过覆盖0.7B-11B 参数模型、5 个数据集(SuperGLUE 的 BoolQ/RTE/COPA 及 CNN-Dailymail)的大规模实验,对比 14 种主流 PEFT 方法的性能与效率。核心发现包括:Houlsby Adapters 与 LoRA在全模型规模下性能持平甚至超越全微调,且无需复杂超参调优;Layer Norm(LN)调优作为轻量方法表现意外优异;混合 PEFT 方法(如 UniPELT、MAM)存在高超参敏感性,在资源受限场景下难超 LoRA;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)