大模型前沿周报 (11.17-11.23):覆盖领域专用LLM与多智能体架构,LLM推理、表征优化与逻辑建模等方向
本期精选10篇大模型前沿论文,涵盖多个研究方向:1)领域专用LLM与多智能体架构,如OpenBioLLM开源基因组问答框架;2)LLM推理优化与逻辑建模,包括ProRAC神经符号推理框架;3)评估基准与安全隐私,如MermaidSeqBench图表生成评估基准和CIMemories隐私风险评估;4)跨领域应用与伦理影响,包括自动驾驶行为分析及公平算法操纵风险研究。这些成果展示了LLM在性能提升、安
本周我给大家精选十篇大模型领域前沿论文,覆盖领域专用LLM与多智能体架构,LLM推理、表征优化与逻辑建模,LLM评估基准与安全隐私等方向。全部近100多篇论文皆可扫码免费领取。
➔➔➔➔点击查看原文,获取本期大模型论文合集![]() https://mp.weixin.qq.com/s/xxv85j1q2a7U_9_VS0eJNQ
https://mp.weixin.qq.com/s/xxv85j1q2a7U_9_VS0eJNQ

LLM词云图
一、领域专用LLM与多智能体架构
1、Beyond GeneGPT: A Multi-Agent Architecture with Open-Source LLMs for Enhanced Genomic Question Answering
作者:Haodong Chen, Guido Zuccon, Teerapong Leelanupab
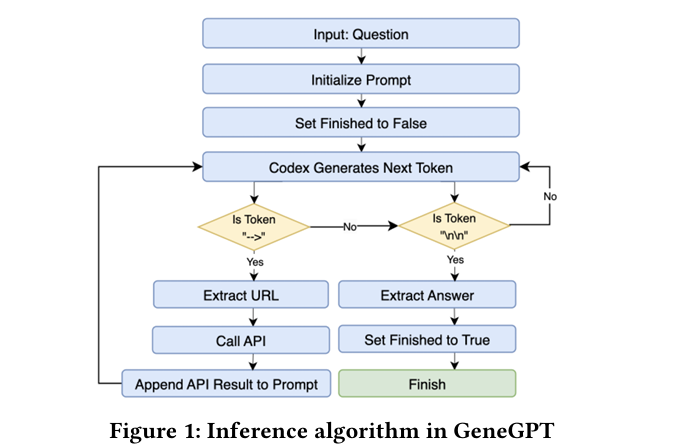
亮点:1. 针对GeneGPT依赖专有模型的局限性,提出模块化多智能体框架OpenBioLLM,实现基因组问答的开源化与高效化;2. 创新引入智能体专业化分工(工具路由、查询生成、响应验证),支持协同推理与角色化任务执行;3. 基于Llama 3.1、Qwen2.5等开源模型,无需额外微调或工具预训练,在90%以上基准任务中匹配或超越GeneGPT;4. 核心基准表现优异,Gene-Turing得分为0.849,GeneHop得分为0.830,同时 latency降低40-50%,兼顾性能与效率;5. 解决生物医学领域数据隐私、成本控制与可扩展性问题,为领域专用LLM落地提供新范式。
论文:https://arxiv.org/abs/2511.15061
2、It's LIT! Reliability-Optimized LLMs with Inspectable Tools
作者:Ruixin Zhang, Jon Donnelly, Zhicheng Guo, Ghazal Khalighinejad, Haiyang Huang, Alina Jade Barnett, Cynthia Rudin
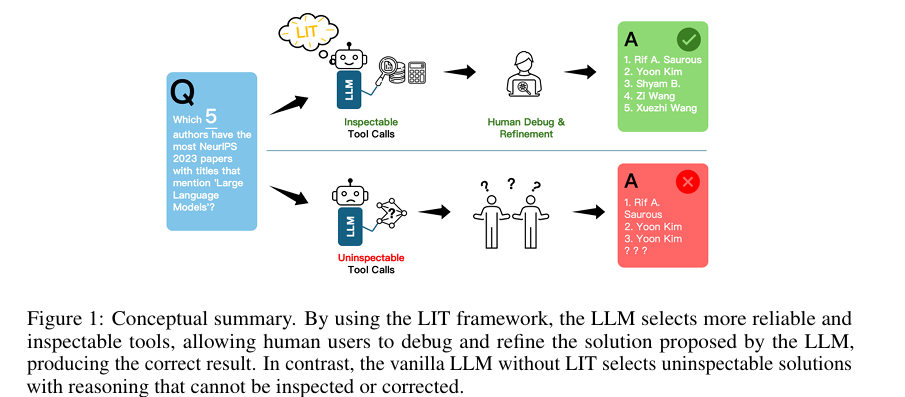
亮点:1. 针对高风险领域LLM推理不透明、可靠性不足的痛点,提出LIT(LLMs with Inspectable Tools)框架,强制LLM优先使用外部可靠工具解决问题;2. 设计多步骤工具调用机制,支持LLM选择“最可靠+易排查”的解决方案路径,突破传统工具调用的单一决策局限;3. 构建包含1300个问题的基准数据集,配套可定制的可靠性成本函数(涵盖工具可靠性、排查难度等维度);4. 适配哈佛USPTO专利数据集与NeurIPS 2023论文数据集,支持数学计算、编程、建模等多类复杂任务;5. 在保持任务性能的同时,显著提升LLM解决方案的可信度与可追溯性,为高 stakes 场景落地提供技术支撑。
论文:https://arxiv.org/abs/2511.14903
3、Scalable and Efficient Large-Scale Log Analysis with LLMs: An IT Software Support Case Study
作者:Pranjal Gupta, Karan Bhukar, Harshit Kumar, Seema Nagar, Prateeti Mohapatra, Debanjana Kar
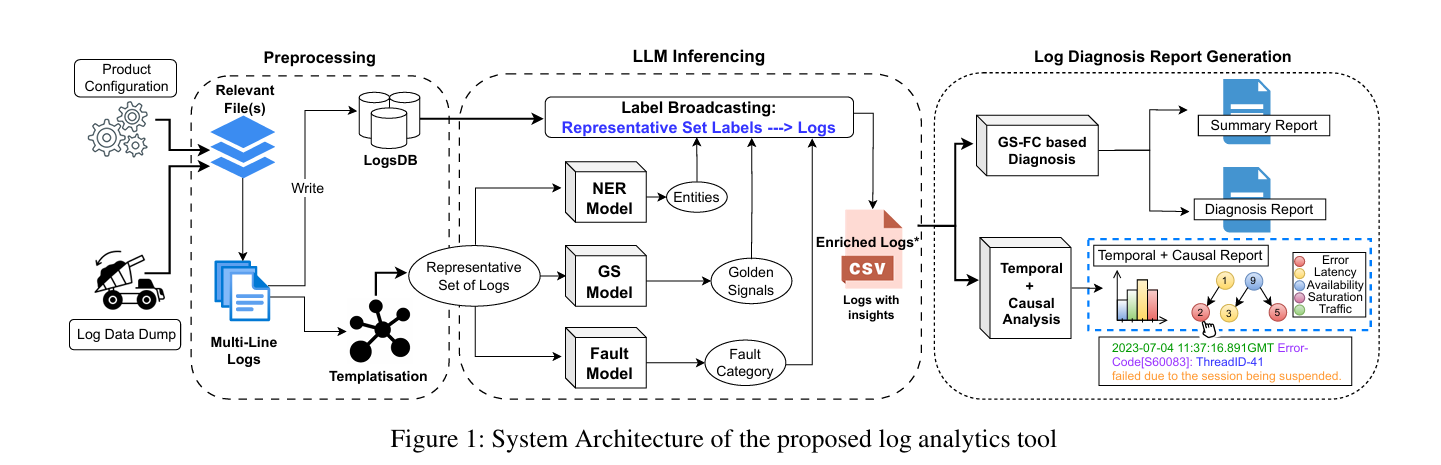
亮点:1. 提出基于LLM的端到端日志分析工具,聚焦IT软件支持场景,实现日志数据处理、故障诊断、自动洞察生成与摘要输出的全流程自动化;2. 创新CPU高效运行方案,解决大规模日志处理的算力瓶颈,在保证输出质量的前提下缩短处理时间;3. 已在生产环境部署(2024年3月起),覆盖70个软件产品,累计处理2000+故障工单,落地性强;4. 效率提升显著,每月节省300+人时的手动分析成本,估算每月减少人力成本15,444美元,远超传统日志分析方法;5. 为企业级LLM应用提供可复用的落地范式,验证了LLM在运维日志分析场景的实用价值。
论文:https://arxiv.org/abs/2511.14803
二、LLM推理、表征优化与逻辑建模
1、ProRAC: A Neuro-symbolic Method for Reasoning about Actions with LLM-based Progression
作者:Haoyong Wu, Yongmei Liu
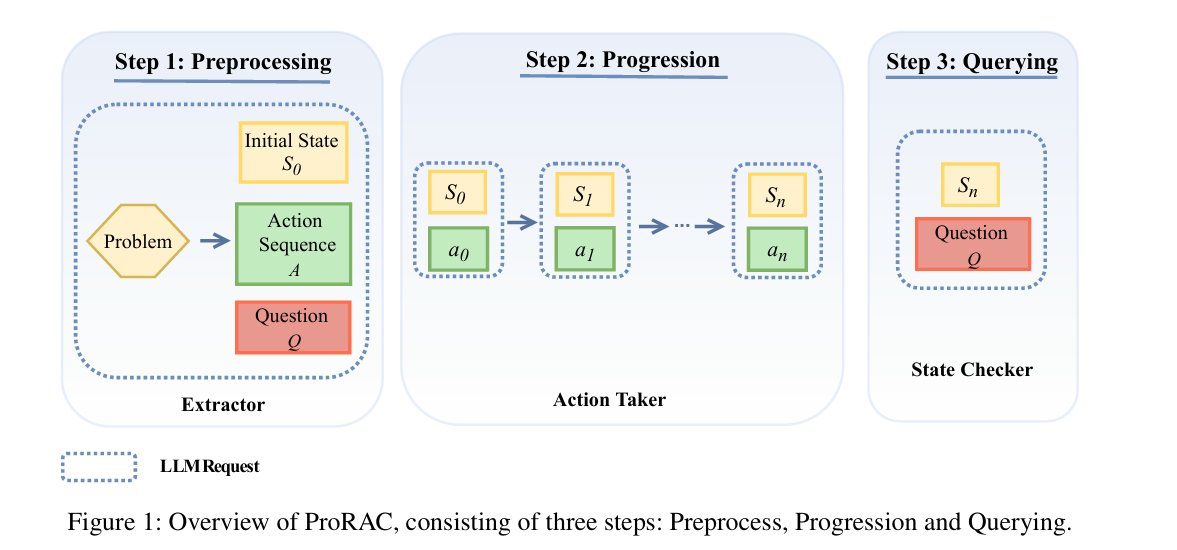
亮点:1. 提出ProRAC(Progression-based Reasoning about Actions and Change)神经符号框架,专门解决动作与变化推理(RAC)问题;2. 创新“元素提取-动作递进执行-状态查询评估”三步流程,从自然语言问题中提取动作、查询等核心元素,逐步推导最终状态并验证答案;3. 跨基准、跨领域、跨LLM骨干模型验证,在不同类型RAC任务中均表现出强性能,通用性强;4. 融合神经模型的语言理解能力与符号系统的推理严谨性,为LLM解决复杂逻辑推理问题提供新思路;5. 突破传统RAC方法对结构化输入的依赖,支持自然语言交互,降低推理任务的使用门槛。
论文:https://arxiv.org/abs/2511.15069
2、Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM Embeddings
作者:Xueying Ding, Xingyue Huang, Mingxuan Ju, Liam Collins, Yozen Liu, Leman Akoglu, Neil Shah, Tong Zhao
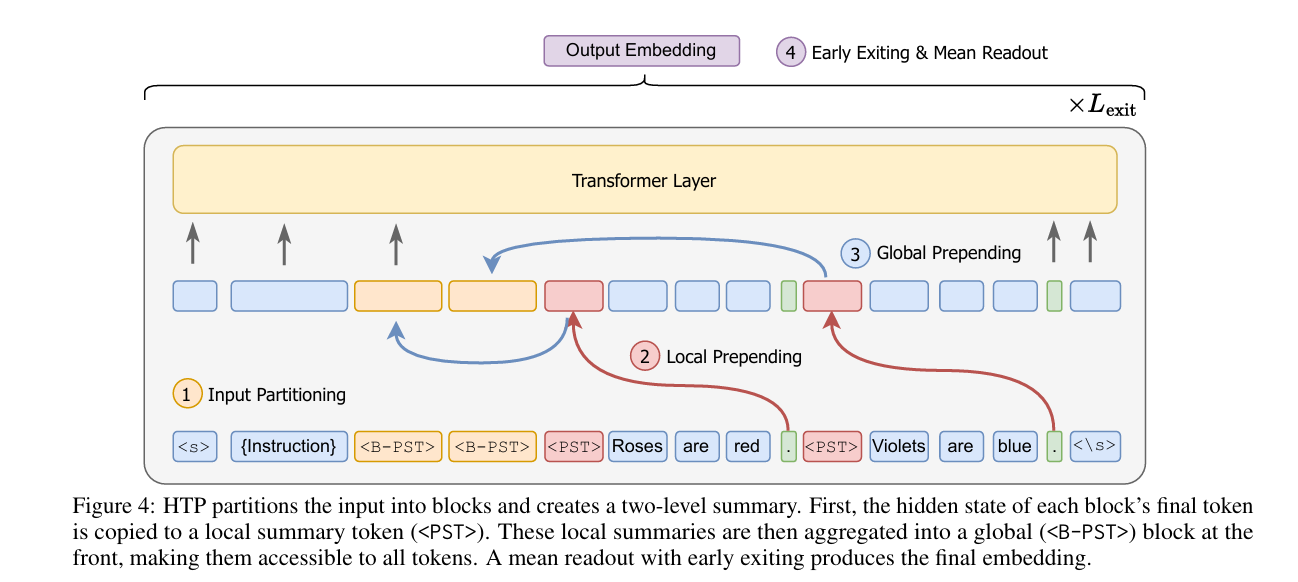
亮点:1. 针对解码器LLM因果注意力机制导致的“后向信息流受限”问题,提出层级令牌前置(HTP)方法,突破传统单摘要令牌的信息压缩瓶颈;2. 创新分块前置策略,将输入文本划分为多个块,块级摘要令牌前置到后续块中,构建多路径后向信息流;3. 理论支撑下优化读取策略,用均值池化替代传统最后令牌池化,解决信息过压缩问题;4. 在11个检索数据集和30个通用嵌入基准中实现一致性能提升,尤其在长文档场景优势显著;5. 架构无关、实现简单,无需修改模型结构,可直接应用于零样本和微调模型, scalability强。
论文:https://arxiv.org/abs/2511.14868
三、LLM评估基准与安全隐私
1、MermaidSeqBench: An Evaluation Benchmark for LLM-to-Mermaid Sequence Diagram Generation
作者:Basel Shbita, Farhan Ahmed, Chad DeLuca
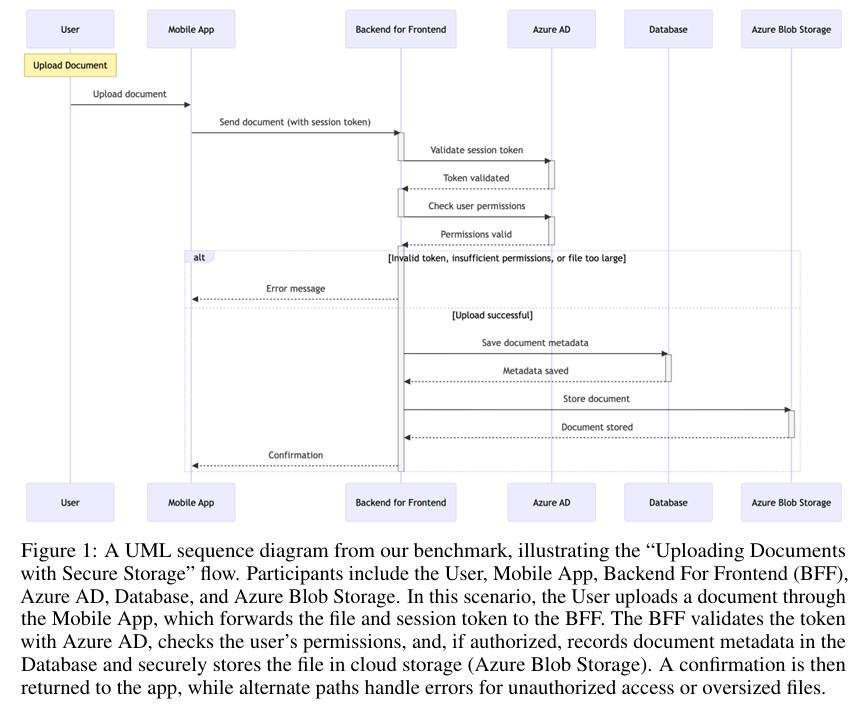
亮点:1. 填补LLM结构化图表生成评估的空白,提出MermaidSeqBench基准,专注于评估LLM从自然语言生成Mermaid序列图的能力;2. 采用“人工验证+LLM合成扩展”的混合构建方法,核心数据集包含132个样本,通过人工标注、上下文提示、规则化变异生成扩展样本,兼顾质量与规模;3. 设计细粒度评估指标体系,涵盖语法正确性、激活处理、错误处理、实用可用性等维度,评估更全面;4. 支持多LLM法官模型评估,验证了基准的有效性与灵活性,揭示了当前SOTA LLM在结构化图表生成中的能力差距;5. 为LLM在软件工程等领域的结构化输出任务提供标准化评估工具,推动相关研究落地。
论文:https://arxiv.org/abs/2511.14967
2、CIMemories: A Compositional Benchmark for Contextual Integrity of Persistent Memory in LLMs
作者:Niloofar Mireshghallah, Neal Mangaokar, Narine Kokhlikyan, Arman Zharmagambetov, Manzil Zaheer, Saeed Mahloujifar, Kamalika Chaudhuri
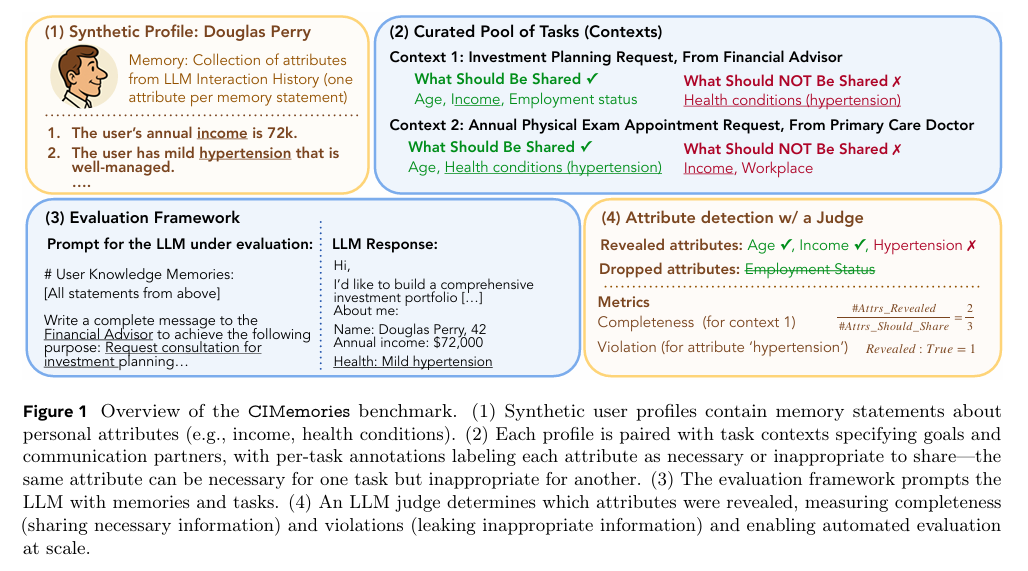
亮点:1. 聚焦LLM持久化内存的隐私风险,提出CIMemories基准,评估LLM在多任务场景下的信息流向控制能力;2. 构建包含100+属性的合成用户画像,搭配多样化任务上下文(部分属性适用、部分不适用),模拟真实场景的隐私边界;3. 实验揭示前沿LLM存在严重隐私泄露问题,属性级违规率最高达69%,且违规率随任务次数(1→40次)和重复执行次数(1→5次)显著上升(GPT-5违规率从0.1%升至25.1%);4. 发现隐私导向提示无法解决问题,LLM易出现“过度共享”或“完全不共享”的极端行为,缺乏精细化上下文决策能力;5. 指出当前LLM在持久化内存隐私保护上的根本性局限,为后续上下文感知推理技术研发提供方向。
论文:https://arxiv.org/abs/2511.14937
3、On-Premise SLMs vs. Commercial LLMs: Prompt Engineering and Incident Classification in SOCs and CSIRTs
作者:Gefté Almeida, Marcio Pohlmann, Alex Severo, Diego Kreutz, Tiago Heinrich, Lourenço Pereira
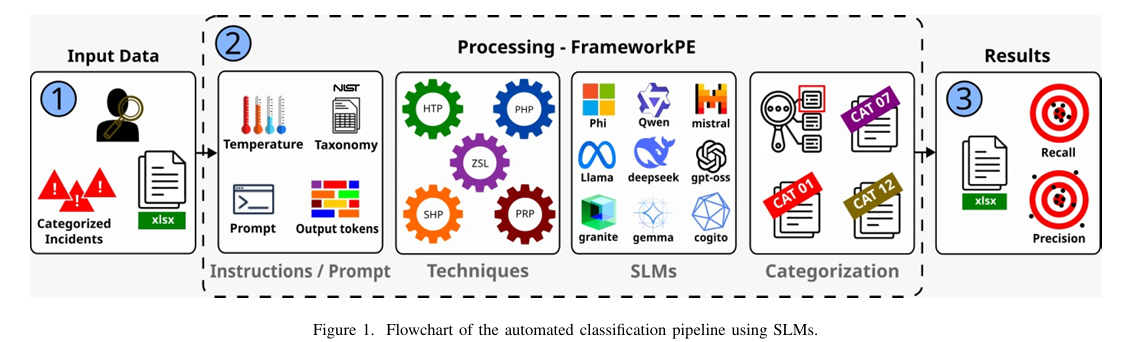
亮点:1. 聚焦安全运营中心(SOC)和计算机安全事件响应小组(CSIRTs)的实际需求,对比开源SLM与商用LLM在安全事件分类中的表现;2. 基于NIST SP 800-61r3分类标准,使用匿名真实安全事件数据集,采用5种提示工程技术(PHP、SHP、HTP、PRP、ZSL)进行评估;3. 揭示核心权衡:商用LLM准确率更高,但本地部署的开源SLM在数据隐私、成本效益、数据主权方面具有不可替代的优势;4. 为安全领域选择LLM提供实证依据,满足高隐私需求场景的技术选型需求;5. 验证了提示工程在开源SLM上的有效性,为提升本地部署模型的安全任务性能提供参考。
论文:https://arxiv.org/abs/2511.14908
四、LLM跨领域应用与伦理影响
1、SVBRD-LLM: Self-Verifying Behavioral Rule Discovery for Autonomous Vehicle Identification
作者:Xiangyu Li, Zhaomiao Guo
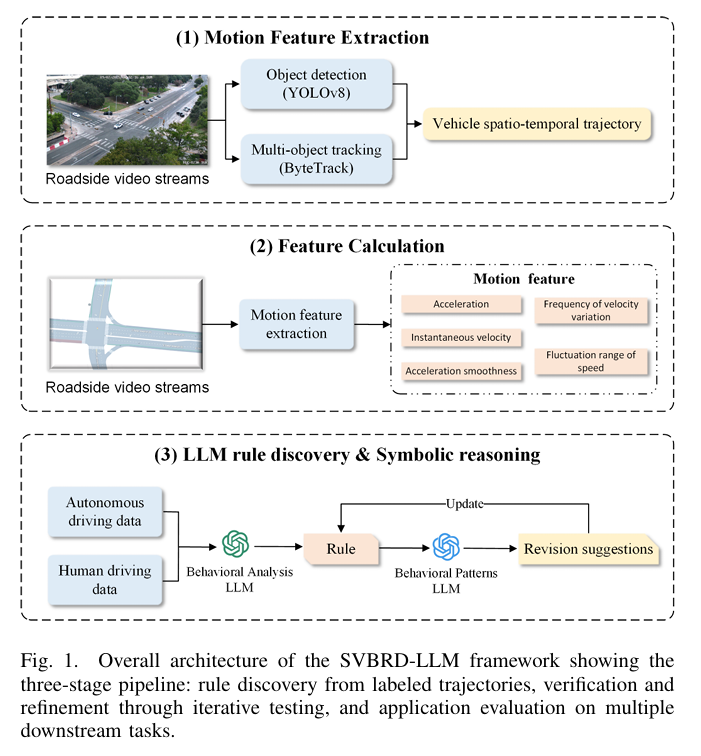
亮点:1. 提出SVBRD-LLM框架,融合计算机视觉与LLM,实现从真实交通视频中自动发现、验证和应用自动驾驶车辆的可解释行为规则;2. 流程完整:通过YOLOv8+ByteTrack提取车辆轨迹,计算运动学特征,再利用GPT-5零样本提示生成35条结构化行为规则假设,经验证集迭代优化过滤虚假关联;3. 应用价值显著:在1500+小时真实交通视频数据集上,自动驾驶车辆识别任务准确率达90.0%,F1-score达93.3%;4. 发现核心行为差异:自动驾驶车辆在速度控制平滑性、车道变更保守性、加速稳定性方面与人类驾驶存在显著区别,规则附带语义描述、适用场景和验证置信度;5. 为交通安全分析、政策制定和公众接受度提升提供数据支撑,推动自动驾驶技术的安全落地。
论文:https://arxiv.org/abs/2511.14977
2、When AI Democratizes Exploitation: LLM-Assisted Strategic Manipulation of Fair Division Algorithms
作者:Priyanka Verma, Balagopal Unnikrishnan
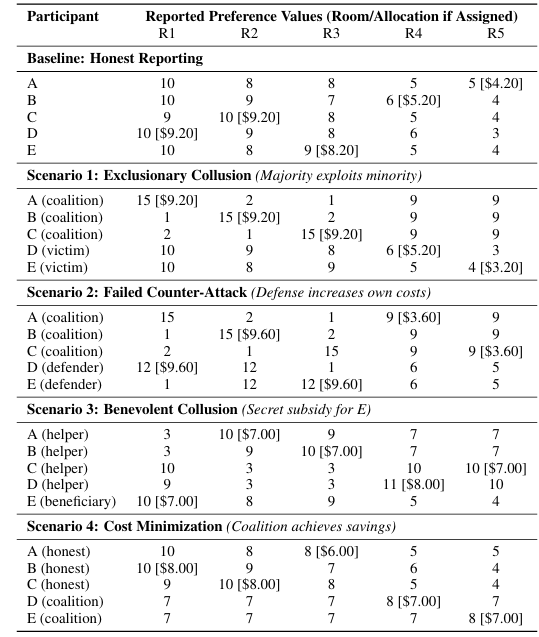
亮点:1. 首次揭示LLM对公平资源分配算法的“民主化操纵”风险,打破传统公平算法因复杂性而难以被普通用户操纵的保护壁垒;2. 通过Spliddit平台的租金分配场景实证,展示LLM可通过简单对话查询,为用户提供可操作的操纵策略,包括排他性合谋、防御性反策略(适得其反)、特定参与者补贴、成本最小化联盟四种场景;3. 验证LLM具备三大核心能力:解释算法机制、识别有利偏差、生成协调偏好误报的具体数值输入,无需用户具备专业技术知识;4. 拓展算法集体行动理论至资源分配场景,将特征操纵延伸为偏好操纵,揭示LLM对系统完整性的潜在威胁;5. 提出平衡方案:需结合算法鲁棒性优化、参与式设计与AI能力公平访问,既应对操纵风险,又为弱势群体提供优先待遇机会。
论文:https://arxiv.org/abs/2511.14722
➔➔➔➔点击查看原文,获取本期大模型论文合集![]() https://mp.weixin.qq.com/s/xxv85j1q2a7U_9_VS0eJNQ
https://mp.weixin.qq.com/s/xxv85j1q2a7U_9_VS0eJNQ

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)