当AI成为“数字员工”:企业落地大模型的四类风险与治理框架
【摘要】将AI大模型类比为“数字员工”,系统剖析其在企业落地时面临的幻觉、安全、隐私和可解释性四类核心风险,并提出技术与应用双轮驱动的系统化治理框架。
【摘要】将AI大模型类比为“数字员工”,系统剖析其在企业落地时面临的幻觉、安全、隐私和可解释性四类核心风险,并提出技术与应用双轮驱动的系统化治理框架。

引言
近两年,以ChatGPT、DeepSeek为代表的AI大模型能力突飞猛进,在个人消费市场掀起热潮。然而,这股热潮并未顺利传导至企业应用层。数据显示,超过95%的企业AI试点项目以失败告终。这种鲜明反差背后,是企业面临的一个核心矛盾,一方面,企业渴望利用大模型实现效率变革与业务创新;另一方面,又必须审慎控制其应用成本与潜在风险。
在当前阶段,风险控制已成为阻碍大模型在企业规模化落地的主要矛盾。这些风险与社会国家层面关注的“宏观风险”不同,它们是企业在日常运营中必须直面和解决的“微观风险”,直接关系到业务成败、品牌声誉乃至法律合规。本文将聚焦于此,深入剖析企业应用大模型的四类核心风险,并构建一个从技术到应用、从工具到流程的系统化治理框架。
一、核心矛盾:能力跃迁与落地困境

大模型展现出的强大能力是毋庸置疑的。它能理解自然语言、生成代码、分析数据、进行多模态交互,潜力巨大。但企业应用不同于个人娱乐,它是一个严谨的系统工程,对可靠性、安全性、合规性的要求极高。当一个看似无所不能的AI被置于严肃的商业环境中,其固有的技术缺陷和不确定性便会被无限放大,形成巨大的风险敞口。
企业决策者和技术负责人普遍的焦虑在于,如何将一个充满不确定性的概率性工具,安全、可控地嵌入到确定性的商业流程中。这种不确定性,正是企业落地失败率居高不下的根源。本文将这些不确定性归纳为四类具体的微观风险。
二、四类核心微观风险:企业到底在怕什么?
2.1 幻觉风险 (Hallucination)
幻觉,指大模型生成内容逻辑通顺、语言流畅,但事实层面完全错误或凭空捏造。这是企业应用中最常见也最棘手的风险。
2.1.1 风险根源:统计机器的“先天缺陷”
大模型的本质是一个基于概率预测的语言模型,而非一个存储事实的数据库。其核心工作机制是通过海量数据学习词与词之间的统计关联,然后像一个极其复杂的“自动补全”工具一样,预测下一个最可能出现的词。它追求的是统计上的“合理性”,而非事实上的“真实性”。
这种机制决定了它不具备人类的认知与事实核查能力。当遇到以下情境时,幻觉极易发生。
-
知识盲区:训练数据未覆盖的领域或专业知识。
-
信息模糊:用户输入的问题含糊不清或存在歧义。
-
知识过时:需要训练截止日期之后的最新信息。
2.1.2 业务影响:高精度场景的“定时炸弹”
幻觉风险在不同业务场景下的影响差异巨大。在创意文案、头脑风暴等容错率高的场景,幻觉甚至可能带来意外的灵感。但在金融、医疗、法务、客服等对信息准确性要求极高的领域,幻觉则是致命的。
|
业务场景 |
幻觉风险的具体表现 |
可能造成的后果 |
|---|---|---|
|
智能客服 |
编造不存在的产品条款或售后政策。 |
误导客户,引发客诉,造成经济损失。 |
|
法务咨询 |
引用错误的法律条文或虚构的判例。 |
导致错误的法律决策,引发合规风险。 |
|
医疗诊断 |
提供不准确的病情分析或用药建议。 |
威胁患者生命安全,引发医疗事故。 |
|
金融风控 |
基于虚构的数据点生成错误的信用评估报告。 |
导致信贷损失,破坏风控体系。 |
一个关键认知是,幻觉在当前技术范式下不可被根除,只能被有效压降。企业必须放弃“让AI永远不说假话”的幻想,转而思考如何构建一个能识别、过滤并修正其假话的系统。
2.2 输出安全与价值对齐风险
大模型从互联网这个“大染缸”里学习,不可避免地会吸收其中存在的偏见、歧视、极端言论和违法信息。如果缺乏有效约束,模型就可能成为一个“言论失当”的“数字员工”,给企业带来品牌、公关和监管三重风险。
2.2.1 风险来源:训练数据的“原罪”
模型的价值观和行为模式高度依赖其预训练数据。互联网数据中充斥着各种未经筛选的信息,导致模型可能“学坏”,具体表现为。
-
偏见与歧视:生成基于性别、种族、地域等的歧视性言论。
-
违法与不当内容:提供关于暴力、色情、赌博等违法活动的建议。
-
价值观冲突:输出与企业倡导的文化、价值观相悖的内容。
2.2.2 风险表现:从品牌受损到平台滥用
这类风险在与用户直接交互的场景中尤为突出。
-
品牌与公关危机:一个面向公众的AI助手如果发表不当言论,会迅速通过社交媒体发酵,对企业品牌造成难以挽回的损害。
-
监管风险:若模型被用于提供金融、法律等专业建议,其输出的违法内容可能直接触犯监管红线,导致企业被处罚。
-
平台滥用风险:恶意用户可能通过提示注入 (Prompt Injection) 等手段,诱导模型生成诈骗话术、钓鱼邮件、攻击代码等有害内容,使企业提供的AI服务沦为网络犯罪的工具。
2.3 隐私与数据合规风险
数据是企业的核心资产。将内部数据,尤其是敏感数据,交由大模型处理,如同将保险箱的钥匙交给一个不完全受控的“外人”,隐私与合规风险随之而来。
2.3.1 风险路径:从API调用到模型记忆
企业数据泄露的风险主要通过两条路径发生。
-
公有云API的数据采集:当员工通过公开的第三方大模型服务处理内部数据(如会议纪要、财务报表、源代码)时,这些数据很可能在用户协议的默认条款下,被服务商收集、存储,甚至用于其模型的后续训练。这相当于企业在无意中用自己的核心机密“喂养”了别人的模型。
-
模型的“过拟合记忆”:大模型在训练过程中,有可能会“记住”训练数据中的具体片段,尤其是那些重复出现或独特的个人信息。在后续的交互中,模型可能在无意或被恶意提示词引导的情况下,复现其“记住”的敏感信息,造成隐私泄露。这种攻击被称为成员推断攻击 (Membership Inference Attack)。
2.3.2 合规挑战:与法律法规的直接冲突
这种数据处理方式与全球日益严格的数据保护法规存在潜在冲突。
-
国家法规:中国的《数据安全法》、《个人信息保护法》对数据的分类分级、出境安全评估、个人信息处理等都做出了明确规定。随意将包含个人信息或重要数据的业务内容发送给境外云服务商,可能直接违法。
-
行业监管:金融、医疗、军工等行业对数据有极其严格的监管要求,核心业务数据通常禁止离开本地或指定的合规环境。
2.4 可解释性风险
大模型的决策过程在很大程度上是一个“黑箱”。它由万亿级的参数和深层神经网络构成,输入信息经过复杂的非线性变换得到输出。人类很难从中倒推出一条清晰、可供理解的决策路径来回答“为什么是这个结果”。
2.4.1 风险本质:“说不清”比“算不准”更可怕
在高风险、高合规的业务场景中,一个无法解释其背后逻辑的决策,无论结果多么精准,都可能因其合规性与可靠性存疑而成为一颗“定时炸弹”。
-
金融风控:一个拒绝用户贷款申请的AI模型,如果无法解释拒绝的具体原因(如信用记录、负债率等),就可能违反金融消费者权益保护的相关规定。
-
医疗诊断:AI给出的诊断建议,如果医生无法理解其判断依据,就无法真正信任并采纳,更无法在出现问题时承担责任。
-
自动驾驶:在发生交通事故后,如果无法解释车辆的决策逻辑,事故责任的认定将变得极其困难。
2.4.2 业务阻碍:信任、审计与问责的基石缺失
缺乏可解释性会直接阻碍业务的深入应用。
-
阻碍信任:业务团队无法完全信任一个“说不清”的系统来处理核心任务。
-
审计困难:内部审计和外部监管机构无法对AI的决策过程进行有效审查。
-
问责无法落地:当AI决策导致损失时,无法定位问题根源,责任追溯变得不可能。
三、风险治理的双轮驱动框架

面对上述四类风险,企业不能坐等技术完美,也不能因噎废食。有效的风险治理需要一个双轮驱动的框架,即技术侧缓解与应用侧治理并行。
-
技术侧缓解:指大模型开发者从技术源头提升模型本身的性能和安全水位,为企业提供更可靠的“技术底座”。这相当于“向上游要安全能力”。
-
应用侧治理:指大模型的使用企业在应用层建立一套完善的管理体系,通过工具、流程和制度,主动将风险控制在可接受范围内。这相当于“像管理员工一样管理AI”。
下图展示了这一双轮驱动的治理框架。
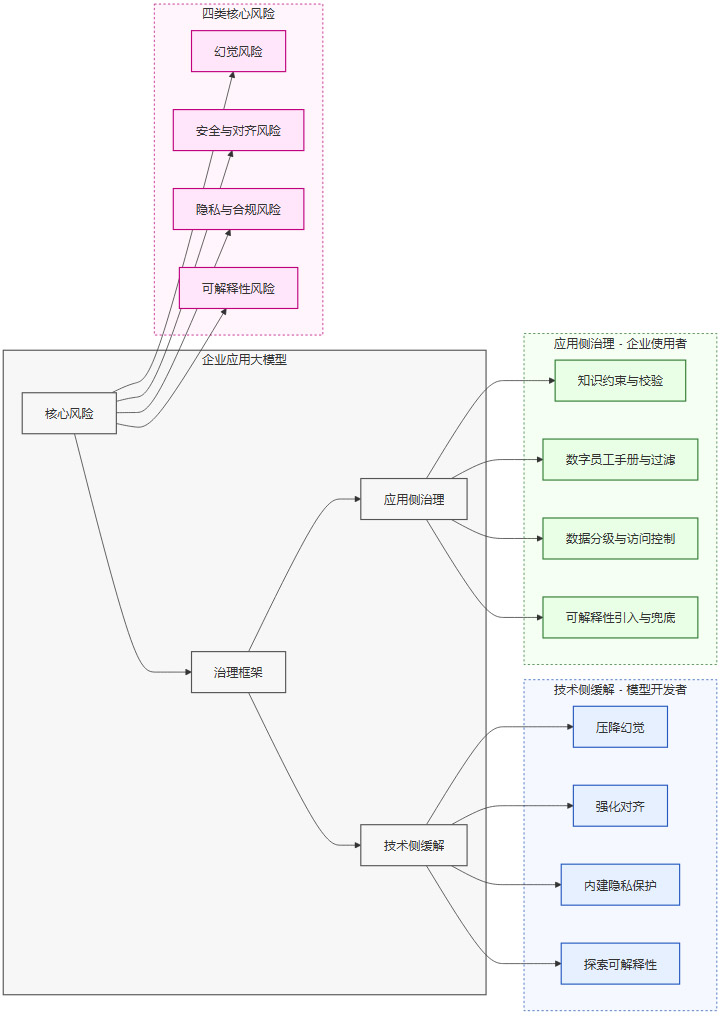
企业需要清醒地认识到,技术侧的努力只能缓解问题,而无法根除。最终的风险控制责任,必然落在应用企业自己身上。接下来的两章将详细拆解这两个轮子的具体举措。
四、技术侧缓解:从源头提升模型的“安全水位”
大模型厂商之间的竞争,已从单纯的参数规模和性能跑分,转向了可靠性、安全性等企业级特性的比拼。主流开发者正在从以下四个方面努力,为企业提供更安全的模型基座。
4.1 压降幻觉:让模型更诚实
4.1.1 提升推理能力
模型的逻辑推理能力越强,就越能通过上下文理解和内部知识关联来判断信息的矛盾之处,从而减少胡编乱造。新一代模型(如GPT-5的深度推理模型)在复杂推理任务上的进步,直接带来了幻觉率的大幅降低。
4.1.2 增强不确定性意识
更先进的模型正在被训练得更“诚实”。通过强化学习等方法,模型在面对其知识边界之外的问题时,会倾向于回答“我不知道”或“根据我掌握的信息无法回答”,而不是强行编造一个答案。这是模型从“无所不知的表演者”向“严谨的助理”转变的关键一步。
4.2 强化对齐:让模型价值观正确
对齐 (Alignment) 技术的目标是让模型的行为和价值观与人类的期望保持一致。
-
指令微调 (Instruction Tuning):使用大量高质量的“指令-回答”数据对预训练模型进行微调,教会模型如何遵循人类的指令。
-
人类反馈强化学习 (RLHF):这是目前最主流的对齐技术。它通过收集人类对模型不同回答的偏好排序,训练一个奖励模型,再用这个奖励模型作为“导师”,通过强化学习来优化大模型的输出,使其更符合人类的价值观。
-
红队测试 (Red Teaming):专门聘请攻击团队,从各种刁钻的角度测试模型的安全漏洞,诱导其生成有害内容,然后将这些失败案例加入训练数据,帮助模型“查漏补缺”。
4.3 内建隐私保护:让模型更健忘
为了解决模型“过拟合记忆”带来的隐私风险,开发者正在探索多种技术。
-
差分隐私 (Differential Privacy):在模型训练过程中,对数据加入经过精确计算的“噪声”。这种噪声既能保护个体用户的隐私不被泄露,又能在宏观统计层面基本不影响模型的整体性能。
-
数据最小化与去标识化:在数据预处理阶段,就对训练数据进行严格的清洗,去除个人身份信息(PII)和其他敏感数据,从源头上减少隐私泄露的可能。
4.4 探索可解释性:让模型更透明
提升模型的可解释性是一个前沿研究领域,目前主要有几个方向。
-
思维链 (Chain-of-Thought, CoT):通过在提示中加入示例,引导模型在给出最终答案前,先输出一步步的推理过程。这种方法虽然只是模型对人类思维过程的模拟,但极大地提升了决策过程的透明度。
-
注意力可视化 (Attention Visualization):通过热力图等方式,直观展示模型在生成某个词时,对输入文本中各个部分的关注程度,帮助我们理解其决策依据。
-
机制可解释性 (Mechanistic Interpretability):这是一个更底层的研究方向,试图通过“逆向工程”的方式,理解神经网络中每个神经元或每个回路的具体功能,从根本上“看透”AI的内部工作机理。
五、应用侧治理:构建企业的“数字员工”管理体系

技术侧的进步为企业提供了更好的工具,但如何用好这些工具,则取决于企业自身的治理能力。一个非常有效的思路是,将AI大模型或由其驱动的AI智能体,想象成一位新入职的、能力超强但心智尚不成熟的“数字员工”。企业完全可以将其管理人类员工的丰富经验,迁移到对AI的管理上来。
5.1 知识约束与多模型校验:应对幻觉风险
对于人类员工,企业如何减少其提供虚假信息的情况?无非是选拔有真才实学的员工,并要求其工作“有理有据、交叉核对”。管理AI同理。
5.1.1 引入检索增强生成 (RAG)
RAG是当前企业应用中对抗幻觉最核心的技术。它改变了模型单纯依赖内部参数“回忆”知识的工作模式,转而让模型成为一个基于外部知识库进行阅读理解和归纳总结的“信息处理器”。
其工作流程如下:
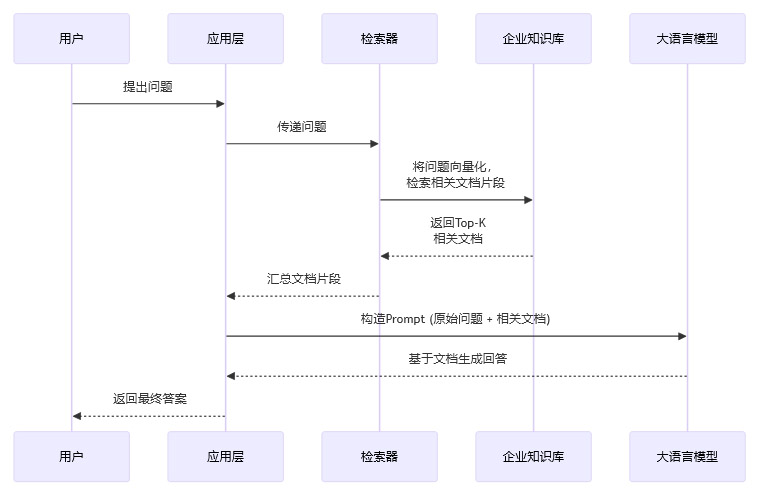
通过RAG,模型被强制要求**“基于提供的材料回答问题”**,而不是凭空想象。这极大地降低了幻觉的概率,并将答案的来源限定在企业可控的内部知识库范围内。
5.1.2 强制引用来源
在应用层面,可以强制要求模型在生成每一个关键论点或数据时,都明确标注其引用的来源是知识库中的哪一篇文档、哪一个段落。这不仅便于人工核查,也反向约束了模型的行为,使其不敢轻易“杜撰”。
5.1.3 多模型交叉验证
对于关键决策任务,可以借鉴“开评审会”的思路。将同一个问题交给多个不同架构或不同厂商的大模型进行处理,然后比对它们的答案。
-
结果一致:则该结果的可信度较高。
-
结果不一致:则提示需要人工介入进行最终裁决。
这种“集体智慧”可以有效识别和修正单个模型的偶然性错误。
5.2 “数字员工手册”与安全过滤:应对安全与对齐风险
企业会给员工发放员工手册,进行大量岗位培训和企业文化教育,并严格审核对外发布的内容。对于AI员工,也可以建立一套类似的数字治理体系。
5.2.1 系统提示词 (System Prompt) 作为“数字员工手册”
系统提示词是与大模型交互时,设定其全局角色、行为准则和约束边界的最高指令。企业可以精心设计一套系统提示词,作为AI的“数字员工手册”。
-
定义角色:例如,“你是一位专业的、严谨的、富有同理心的客户服务专家。”
-
设定行为红线:例如,“绝不提供任何法律、金融或医疗建议。绝不使用任何带有歧视性或攻击性的语言。遇到敏感话题,应礼貌地拒绝回答并引导用户寻求专业帮助。”
-
注入企业价值观:例如,“我们的核心价值观是客户第一、诚信、创新。在你的回答中,请始终体现这些原则。”
5.2.2 安全数据微调 (Fine-tuning) 作为“岗前培训”
对于有更高定制化需求的场景,企业可以使用自己标注的安全问答数据集对模型进行微调。通过大量正向(应该如何回答)和负向(不应该如何回答)的案例“喂给”模型,对其进行持续的“企业文化熏陶”,使其行为模式更贴合企业的特定要求。
5.2.3 内容过滤器作为“内容审核”
在AI服务的输入和输出两端部署内容过滤器是必不可少的最后一道防线。
-
输入端过滤:拦截用户输入的恶意指令、诱导性问题或违法内容,防止模型被“带坏”。
-
输出端过滤:在模型生成内容后、返回给用户前,进行一次快速扫描,拦截其中可能存在的涉政、涉黄、涉暴、歧视性言论或隐私信息。
5.3 数据分级与访问控制:应对隐私与合规风险
企业管理员工数据权限时,会遵循严格的保密协议和最小权限原则。管理AI处理数据,逻辑完全一致。
5.3.1 建立数据分级分类体系
企业需要对自己内部的数据进行盘点,按照敏感度进行分级分类。
|
数据级别 |
定义 |
允许的AI处理方式 |
|---|---|---|
|
公开 (Public) |
已对外公开的信息,如官网介绍、产品手册。 |
可使用任何公有云大模型服务。 |
|
内部 (Internal) |
仅限内部员工访问的非敏感数据,如通用工作文档。 |
可使用签订了数据处理协议(DPA)的合规云服务。 |
|
机密 (Confidential) |
包含个人隐私、商业秘密的敏感数据,如财务报表、客户名单。 |
优先采用私有化部署或可信执行环境(TEE)。 |
|
绝密 (Top Secret) |
核心源代码、战略规划等最高级别机密。 |
原则上禁止接入任何大模型系统,或在完全物理隔离的环境中使用。 |
5.3.2 应用最小权限原则与脱敏处理
向AI提供数据时,应严格遵循**“非必要,不提供”的最小权限原则。如果必须提供包含敏感信息的数据,应先进行脱敏处理**,例如将真实姓名替换为“张先生”,将具体金额替换为“[金额]”。
5.3.3 选择合适的部署模式
根据业务的数据敏感度,企业可以选择不同的部署模式。
-
公有云API:适用于处理非敏感数据,成本低、灵活性高。但必须选择能够签署DPA、承诺数据不用于再训练的头部云厂商。
-
私有化部署:将大模型部署在企业自己的服务器或私有云上。数据完全不出企业内网,安全性最高,但成本和运维复杂度也最高。
-
可信执行环境 (TEE):这是一种折中方案。它像在公有云上租用一个加密的“保险箱”,数据在计算过程中全程加密,即使是云服务商也无法窥探。兼顾了安全与灵活性。
5.4 可解释性引入与人工兜底:应对可解释性风险
有些经验丰富的员工基于优秀的业务直觉做出判断,但要说服团队支持,仍需补全背后的思考,拆解清楚其中的逻辑。对于AI员工,我们同样可以要求它“展示思考过程”,并在关键节点设置“人工审批”。
5.4.1 强制输出“思维链”
在应用设计上,可以要求模型在给出最终答案前,先输出一步步的推理过程。这有助于人类专家快速理解其决策逻辑,判断其推理过程是否合理、依据是否充分。
5.4.2 有限授权与人工复核
企业需要对AI进行严格的授权管理。
-
低风险领域:在创意、文案初稿等主观性强、风险低的领域,可以允许大模型相对自由地发挥。
-
高风险领域:在金融风控、医疗诊断等事关企业命脉的领域,AI的“锦囊妙计”只能作为人类专家的参考。最终决策必须由具备资质的人类专家进行复核和签署,即所谓的**“人在回路” (Human-in-the-Loop)** 或“AI+人工双签”机制。
六、责任与问责:AI不能背锅
将AI类比为“数字员工”,有一个至关重要的区别,大模型目前无法成为法律上的责任主体。如果模型出错导致客户损失或公司声誉受损,企业不能简单地“开除”它来解决问题。责任最终只能追溯到人类。
因此,企业在引入大模型时,必须设计清晰的问责框架。
-
明确责任主体:需要明确规定,谁是批准使用AI的业务负责人,谁是负责部署和维护的技术团队,谁是对AI输出结果负责的最终审核人。
-
纳入KPI体系:将AI应用的性能指标(如准确率、效率提升)和风险指标(如幻觉率、违规内容拦截率、人工干预率)纳入相关团队和个人的KPI考核中。
-
建立审计与追溯机制:所有AI与用户的交互、AI的决策过程(如思维链)、人工的审核记录,都必须被完整记录下来,形成可审计、可追溯的日志,以便在出现问题时进行复盘和归因。
结论
企业控制AI大模型风险,是一项需要技术与管理深度融合的系统工程。它不是一次性的项目,而是一个持续迭代、动态优化的过程。当前阶段,人和AI各有优劣,最优模式是“人机协同”,而非“谁替代谁”。AI适合处理海量、重复性的信息处理任务,而人类则负责设定目标、进行价值判断和承担最终责任。
企业需要将大模型视为一项需要长期建设的基础设施和核心能力,而非一个即插即用的工具。只有坚持技术创新和制度完善并举,将AI的强大能力与企业的业务流程、合规体系深度融合,并在组织、流程与文化层面将这位“数字员工”纳入成熟的管理体系,才能在享受技术红利的同时,将风险牢牢关在可控的范围内,最终实现安全、合规与创新的共赢。
📢💻 【省心锐评】
别把AI当神,也别当魔。把它当成一个能力超群但需要严格管理的“实习生”,用成熟的“用人”经验去约束它,风险自然可控。人机协同,各司其职,才是正解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献366条内容
已为社区贡献366条内容

所有评论(0)