从“救火队”到“架构师”:一线 SRE 如何用 SREWorks 搭起云原生数智运维的“乐高积木”?
《SREWorks:云原生运维操作系统的工程实践》摘要 SREWorks是阿里开源的"一站式云原生数智运维平台",旨在解决传统运维工具链碎片化问题。其架构分为三层:基础设施层集成Prometheus/ES等观测组件;平台层通过AppManager实现统一应用模型管理;SaaS层提供开箱即用的运维应用。核心创新包括:1)应用包机制标准化交付流程;2)DataOps实现运维数据闭环
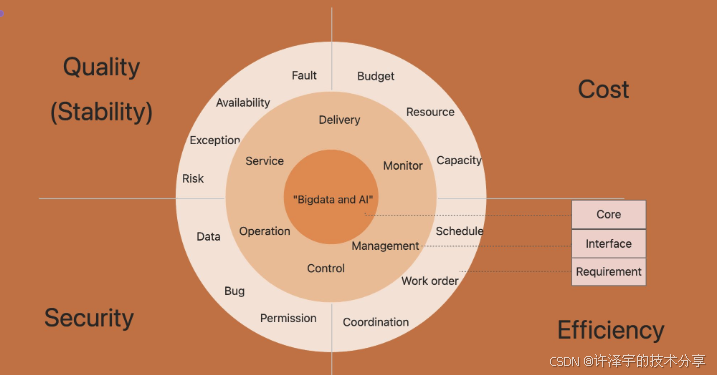
本文预计 30~40 分钟阅读时间,如果你正被 Kubernetes 集群、业务告警和领导的 KPI 三杀连环 combo 困扰,不妨泡杯咖啡,慢慢看完这篇文章——也许是你从“救火队员”升级为“运维架构师”的一个起点。
一、为什么我们需要 SREWorks?——先聊聊那些年被运维“支配的恐惧”
如果你在互联网一线做过几年运维/SRE,大概率经历过类似的场景:
-
业务要上云,领导一句“全量上 K8s”,你从 bash 脚本一路卷到 Helm Chart,依然搞不清楚是谁在生产集群上
kubectl apply了一个奇怪的 YAML; -
指标在 Prometheus,日志在 Elasticsearch,调用链在 SkyWalking,告警在钉钉群,排查问题先打开 7 个浏览器标签页;
-
大量日常工作是“体力活”:调资源、拉日志、查配置、清告警,真正有技术挑战的自动化、智能化场景,总是排在“这周先把火灭了再说”后面。
这本质上是一个结构性问题:
业务系统已经全面云原生化了,但运维工具链还停留在“拼装货”阶段。
有监控、有日志、有告警、有 CMDB,看起来什么都有,凑在一起却像一只被拆散又用胶水粘回去的高达——能用,但晃一晃就掉件。
SREWorks 正是针对这个痛点诞生的:
-
站位: 不是单点工具,而是“一站式云原生数智运维平台”;
-
理念: 把 Google SRE 理念与阿里多年大数据、AI 运维实践结合起来,真正落到工程化体系,而不是 PPT;
-
目标用户: 以 SRE/运维工程师为核心,同时覆盖平台研发、业务研发、架构师等角色。
简单一句话概括:
SREWorks 想做的,是“应用为中心的云原生运维操作系统”,而不仅仅是一组“好用的小工具”。
下面,我们从架构、能力到落地场景,系统拆解一下这套“操作系统”到底长什么样、怎么玩、能解决什么问题。
二、整体技术架构:一眼望去,既是“平台”也是“应用商店”
从代码仓库结构和 Helm 部署清单(chart/sreworks.yaml)可以看出,SREWorks 的整体架构大致可以拆成三层:
-
基础设施与中间件层:MySQL、Redis、Kafka、对象存储 MinIO、OpenEBS 本地存储、Elastic Stack、SkyWalking、Prometheus、Grafana 等;
- 平台能力层(PaaS / AppManager):
-
统一的应用与资源管理平台(
paas/、appmanager/); -
AppManager 应用模型、包管理、部署编排等能力;
-
SWCLI 命令行工具;
-
- 垂直域 SaaS 运维套件层(SaaS Apps):
-
saas/dataops:数据化运维/DataOps 能力; -
saas/aiops:智能运维/AIOps 能力; -
saas/cluster、saas/app、saas/system等围绕集群、应用、系统的运维能力; -
saas/desktop、saas/swadmin、saas/template等统一工作台与运维门户。
-
用一句更“接地气”的比喻:
最底下是云原生基础设施和观测组件,中间这一层是“应用交付与运维中台”,最上面一层则是一个个“开箱即用”的运维 SaaS 应用。
2.1 从 sreworks.yaml 看平台“全家桶”
chart/sreworks.yaml 是一份合成后的大型 Kubernetes 清单,它基本铺开了 SREWorks 在集群中的“落地图”:
-
创建专用命名空间:
sreworks、sreworks-dataops、sreworks-aiops; - 部署中间件:
-
sreworks-mysql(MySQL 数据库,用于 AppManager 和业务元数据); -
sreworks-redis(Redis 作为缓存与会话存储); -
sreworks-kafka(事件流与异步任务总线); -
sreworks-minio(对象存储,承载制品、包等); -
openebs存储类,用于本地持久卷;
-
-
部署 AppManager 及相关 ConfigMap(
sreworks-appmanager-server-configmap)——里面配置了数据库、存储、Redis、Kafka、认证等几乎全部运行参数; - 初始化脚本与 ConfigMap(
init-build、init-configmap、init-run)负责:-
使用
swcli自动构建/导入应用包(app-package build/import/oneflow); -
以 Pipeline 方式按顺序拉起
core(平台核心)、desktop、swadmin、template等基础 SaaS; -
在 DataOps、AIOps 命名空间中动态合并 YAML、构建和部署组件(Elasticsearch/Grafana/Logstash/Prometheus/VVP 等)。
-
代码中有一段很关键的 Python 脚本(reduce.py),用于把多个组件的 YAML 进行“聚合”:
def merge(a, b):
if b is None:
return a
if a is None:
return b
parameterValues = [x["name"] for x in a.get("spec").get("parameterValues")]
for p in b.get("spec").get("parameterValues"):
if p["name"] in parameterValues: continue
if p["name"] == "COMPONENT_NAME": continue
a["spec"]["parameterValues"].append(p)
a["spec"]["components"] += b["spec"]["components"]
return a
它实际上体现了一个重要理念:
应用是组件的组合,配置可以按“乐高方式”动态合并,而不是写一堆难以维护的超长 YAML。
这也是 SREWorks“以应用为中心”的一个具象实现。
2.2 AppManager:SREWorks 的“内核”
从代码目录上看,appmanager/ 模块是整个平台的“心脏”,涵盖:
-
应用建模与定义(
tesla-appmanager-definition); -
应用元信息、工作流、部署配置(
tesla-appmanager-meta-*、tesla-appmanager-workflow); -
Kubernetes 集成与 Operator 能力(
tesla-appmanager-kubernetes、appmanager-kind-operator); -
统一服务接口与鉴权(
tesla-appmanager-api、tesla-appmanager-auth); -
通用工具 & SDK(
tesla-appmanager-util、plugin-api); -
各种 Plug-in 扩展(
tesla-appmanager-plugin)。
简单理解,SREWorks 没有直接把“每一个业务系统”当成一个 Kubernetes Deployment,而是:
- 先抽象成 AppManager 中的“应用模型”:
-
一个应用由若干组件组成(API、UI、Job、Addon 等);
-
组件本身可以绑定镜像、配置、依赖;
-
应用版本、环境(stage)、命名空间等元信息统一管理;
-
- 再由 Operator 将这些模型投射到 K8s 对象上:
-
CRD 如
applications.apps.abm.io、jobs.apps.abm.io,在sreworks.yaml中可以看到; -
AppManager 负责生成并协调 Deployment/StatefulSet/Service/Ingress 等资源;
-
- 所有部署操作都走 AppManager API 或 SWCLI:
-
你不是在“手动写 K8s YAML”,而是在“发布一个应用版本”;
-
自动化流程(部署、回滚、灰度、扩缩容)可以基于应用维度编排。
-
从工程视角看,这是典型的“控制平面 + 数据平面”划分:
- 控制平面在 AppManager 中:
-
管应用、管包、管版本、管环境;
-
暴露统一 API 与 CLI,提供权限控制和审计;
-
- 数据平面是 Kubernetes 集群本身:
-
执行容器编排、负载均衡、调度等;
-
存放日志、指标、事件等运行时数据。
-
这也是为什么很多同类型平台停留在“Dashboard 工具集合”,而 SREWorks 更像一个“运维操作系统”的原因——它有自己的“内核”和“进程模型”。
三、核心能力与实现思路:从“堆功能”走向“编排能力”
基于上面的架构,我们可以从“工程实现”的角度拆解 SREWorks 的核心能力。这里我不按传统的“监控/日志/告警”来罗列,而是从 SRE 日常工作流的视角,分成几条主线来看。
3.1 应用与资源的统一管理:不再被 YAML 牵着鼻子走
在传统 K8s 运维中,经常出现这样一个场景:
-
研发提一个新服务,给你一个
deployment.yaml和一个service.yaml; -
运维需要手动补齐 ConfigMap、Secret、Ingress、安全策略等;
-
版本升级时,又得一次次对比 diff,容易出错也难以审计。
SREWorks 借助 AppManager 引入了一套“应用包(AppPackage)”机制:
-
应用的所有组件、配置、运维脚本,被打包成一个 zip(在
init-run中能看到大量pack.py与app-package import操作); - 应用包内部可以包含:
-
元信息
meta.yaml(包含appId、packageVersion等) -
构建描述
build.yaml(如何在不同环境构建) -
发布描述
launch.yaml(如何部署/联动其他组件)
-
- SWCLI 负责:
-
执行
app-package build:本地构建镜像、上传到镜像仓库、生成应用包; -
执行
app-package import:将外部应用包引入 AppManager; -
执行
deployment launch:根据launch.yaml在目标环境拉起部署。
-
这一整套机制有几个明显的工程收益:
- 版本可追踪、可对比:
-
packageVersion清晰标识版本号,配合version_check.py可以判断“是否需要升级”; -
应用实例实际运行的
simpleVersion也可以对齐校验;
-
- 交付标准化:
-
不再是“把几个 YAML 扔给运维”,而是以“应用包”作为交付物;
-
这对多团队、多业务线协作极其重要;
-
- 环境差异可参数化:
-
很多脚本里用
envsubst把环境变量注入 YAML(如NAMESPACE_ID、ACCESS_MODE等); -
通过
parameterValues动态合并组件配置,避免复制粘贴同一套配置到不同环境。
-
换句话说,SREWorks 把“运维自动化”这件事,从“写脚本堆工具”升级成了“建立一套应用交付与运维模型”。
3.2 DataOps:让运维数据“成系统地说话”
阿里大数据 SRE 团队一直强调“数据化运维”,SREWorks 在 saas/dataops 中,把这一理念工程化成了一整套 DataOps 闭环体系。
在 init-run 的 saas-dataops.sh 中,可以看到完整的编排脚本:
envsubst < /root/saas/dataops/api/grafana/build.yaml.tpl > tmp-build.yaml
envsubst < /root/saas/dataops/api/grafana/launch.yaml.tpl > tmp-launch.yaml
split
envsubst < /root/saas/dataops/api/kibana/build.yaml.tpl > tmp-build.yaml
envsubst < /root/saas/dataops/api/kibana/launch.yaml.tpl > tmp-launch.yaml
split
envsubst < /root/saas/dataops/api/metricbeat/build.yaml.tpl > tmp-build.yaml
envsubst < /root/saas/dataops/api/metricbeat/launch.yaml.tpl > tmp-launch.yaml
split
...
envsubst < /root/saas/dataops/api/build.yaml.tpl > tmp-build.yaml
envsubst < /root/saas/dataops/api/launch.yaml.tpl > tmp-launch.yaml
split
cat tmp-merge-build.yaml | python -c 'import sys;print("\n---\n".join([raw.strip() for raw in sys.stdin.read().strip().split("---") if raw.strip()]))' > merge-build.yaml
cat tmp-merge-launch.yaml | python /app/reduce.py > merge-launch.yaml
这段脚本做了几件关键的事:
-
按组件维度拆分构建/发布模板:Grafana、Kibana、Metricbeat、Filebeat、SkyWalking、Prometheus、Logstash、VVP 等;
- 基于环境变量注入配置,例如:
-
数据库地址:
DATAOPS_DB_HOST; -
Elasticsearch 地址:
DATA_ES_HOST、DATA_ES_PASSWORD; -
Grafana 管理员密码:
GRAFANA_ADMIN_PASSWORD;
-
- 将所有组件的构建和发布 YAML 聚合成一份“拼装式应用”:
-
使用
reduce.py合并parameterValues与components; -
形成统一的 DataOps 应用模型,交给 AppManager 去运维。
-
最后,再通过 saas-dataops-grafana-import.sh 自动把数据源和看板导入 Grafana:
for file in /root/saas/dataops/ui/grafana/datasource/*.json ; do
curl --request POST \
http://admin:${GRAFANA_ADMIN_PASSWORD}@${SAAS_STAGE_ID}-dataops-grafana.${NAMESPACE_DATAOPS}/api/datasources \
--header "Content-Type: application/json" \
--data-binary "@$file"
done
这形成了一个闭环:
采集 → 存储 → 建模 → 可视化 → 运维决策,每一步都有默认工程实现,你拿来就能用、也能根据自己场景改造。
对一线团队来说,这意味着:
-
不必从零搭建 Prometheus + ES + Grafana 的杂糅体系;
-
可以在 SREWorks 框架下,把自己特定的运维数据模型(例如 SLA、发布风险、容量模型)逐步固化下来;
-
用一个统一的 DataOps 平台,对接上层报表/运营分析,将“运维数据”真正纳入企业数据资产的一部分。
3.3 AIOps:不是“玄学智能”,而是有工程抓手的智能运维
很多人提到 AIOps,会不自觉地联想到几个关键词:
-
黑盒模型、效果玄学、落地困难、运维团队“不敢用”。
SREWorks 的 AIOps(saas/aiops)并不是“一上来就搞一个什么神奇模型”,而是站在 DataOps 基础之上,把智能能力有机地镶嵌进具体运维场景中,例如:
-
告警压缩/归并:基于历史模式,把同源告警聚合起来;
-
故障根因分析:结合拓扑、调用链、日志、指标,辅助定位问题;
-
异常检测:在时序指标上做突变/周期异常识别;
-
智能巡检与报表:自动给出“某业务本周健康周报”。
从代码与初始化脚本看,SREWorks 在 AIOps 上的工程路径大致是:
-
重用 DataOps 的数据底座:告警、日志、指标、调用链等统一进入数据平台;
- 通过 AIOps SaaS(
aiops应用包)暴露统一入口:-
在
saas-aiops.sh中可以看到launch-backend.yaml与launch-frontend.yaml的编排; -
前后端都封装成应用组件,由 AppManager 管管控;
-
- 在具体功能中以模块方式接入模型或算法服务:
-
比如可以使用 Flink、BentoML 等组件(在
init-configmap中可以看到相关镜像配置); -
结合 Ververica Platform(Flink 的企业级平台),做实时计算和在线学习。
-
也就是说,SREWorks 在 AIOps 上更多扮演的是:
一个工程化的“智能运维应用载体”,而不是一套封闭的黑盒算法产品。
这对一线 SRE/平台团队来说有两层好处:
-
你可以先享受开箱即用的告警聚合、异常检测等能力;
-
当你团队有自己的算法/模型时,也可以比较自然地挂载进来,而不是从零搭一整套平台。
3.4 桌面与运维门户:让复杂能力以“应用视角”暴露给人
运维工具的一个常见问题是:
各种系统都在,但入口非常分散,而且大多是“基础组件视角”,而非“业务应用视角”。
SREWorks 在这方面做了两层统一:
- 统一工作台(
saas/desktop):-
拉起之后,提供一个聚合的运维“桌面”;
-
各个运维应用(集群管理、应用管理、DataOps、AIOps、健康巡检等)可以在这个 Portal 中统一呈现;
-
- 平台管理后台(
saas/swadmin):-
面向平台管理员,对用户、权限、租户、配置等进行集中管理;
-
结合
ACCOUNT_SUPER_CLIENT_ID、ACCOUNT_SUPER_SECRET_KEY等参数,构建统一认证体系。
-
这背后其实是一个很重要的产品与工程观点:
运维平台最终是“给人用”的,复杂度应该由平台内部来消化,对外呈现尽量是“应用视角 + 任务视角”,而不是堆满 API 和 Dashboard。
四、典型落地场景:从单集群到多租户,从传统系统到云原生
上面讲的更多是架构和实现思路,这一节我们换个视角,用几个稍微拟人化的场景,看看 SREWorks 在实际工作中能怎么帮你“省命”。
4.1 场景一:传统业务逐步上云,SRE 如何稳住节奏?
背景设定:
-
公司有一大堆历史系统:Java 单体、早期 Spring Cloud、甚至还有几套 .NET;
-
领导决定启动“云原生改造计划”,先从新业务和部分非核心业务上 K8s;
- 运维团队的诉求是:
-
不要一上来就推翻所有现有体系;
-
能有一套统一的平台,帮大家在“传统 + 云原生”的过渡期中稳住阵脚。
-
SREWorks 的用法可以是这样:
- 先把 SREWorks 当成“云原生运维平台 + 多租户工作台”搭起来:
-
使用官方文档的快速安装/源码安装流程,把
sreworks、sreworks-dataops、sreworks-aiops基础设施拉起; -
通过
desktop、swadmin建一个运维工作台,给不同团队分配空间;
-
- 把新业务优先接入 AppManager 应用模型:
-
新业务从一开始就按“应用包”的方式交付;
-
发布、扩缩容、灰度等全走平台流程;
-
- 用 DataOps 统一看数,逐步替换零散监控系统:
-
把 Prometheus、ES、Grafana 的指标和看板搬到 DataOps;
-
老系统保留原有告警,但逐步把告警聚合和事件关联迁到 SREWorks;
-
- 在此基础上逐步引入 AIOps 能力:
-
先从告警聚合、健康评分等“低风险能力”开始;
-
等团队信心足够,再逐步接入自动化诊断、智能巡检等功能。
-
这个过程中,SREWorks 最大的价值不是某一个“炫酷功能”,而是:
给团队提供了一条从“烟囱式运维系统”走向“平台化运维”的现实路径,而且这条路径是可渐进、可回滚、可自定义的。
4.2 场景二:Kubernetes 集群已经很多,运维团队已经“手忙脚乱”
另一个典型场景是:
-
业务增长很快,集群从 1 个变成 5 个,再变成十几个;
-
每个集群有不同的用途:生产、预发、测试、专项、海外……
-
各个业务线自建了一堆“脚本 + Grafana Dashboard”,团队内“野生标准”横飞。
此时 SREWorks 的价值点更多体现在“规范化 + 聚合”上:
- 统一接管应用维度的发布与变更:
-
用 AppManager 把跨集群应用的部署逻辑固化下来,避免每个团队各搞一套 Helm;
-
用 SWCLI 把常见操作(发布、回滚、扩缩容)收敛成可审计的命令行;
-
- 接管监控、日志和调用链落地点:
-
通过 DataOps 统一对接各集群的数据采集;
-
使用统一的 ES/Prometheus/SkyWalking 规范,而不是到处 copy-paste;
-
- 在 Portal 上提供“多集群视角”的看板与操作入口:
-
例如按业务应用维度聚合多集群状态;
-
一键下钻到某个 Pod/实例的全链路数据;
-
- 结合告警 & AIOps,减少“人肉值班消耗”:
-
对多集群告警做统一压缩和分派;
-
按业务责任人、集群责任人自动路由问题。
-
如果把多集群环境比作一个“多租户大楼”,SREWorks 的角色很像是:
既负责搭电梯、铺管道、装监控,也负责给每一层楼配置前台、监控屏和消防通道设计。
4.3 场景三:你是 SRE 团队负责人,想做一个“运维产品”给全公司用
还有一类读者,可能并不是单纯的 SRE,而更像是“平台产品经理 + 技术负责人”:
-
你希望团队不再只当“救火队”,而是把运维能力“产品化”输出给内部业务团队;
-
你需要一套支持“二次开发、定制集成、可插拔能力”的平台;
-
你不想所有东西都从头造,希望能在成熟的开源基础上演进。
SREWorks 在这类诉求下的优势主要体现在:
- 完善且工程化的代码结构:
-
Java 后端按领域拆分多个模块,依赖清晰;
-
前端有统一的 Portal 与各个 SaaS 子应用;
-
- 天然支持插件与扩展:
-
plugin-api与各类tesla-appmanager-*模块,让你可以相对容易地扩展新的运维能力;
-
- AppPackage & SWCLI 让你能“封装自己的最佳实践”:
-
比如你设计了一套标准的“业务巡检应用”,完全可以自己做成应用包,挂到 SREWorks 上,成为公司内部的“运维 App 商店”之一;
-
- 开源 + 文档 + 社区:
-
源码在 GitHub/Gitee,文档在语雀,国内社区活跃度还不错;
-
遇到非共性问题,你可以选择自研,也可以和社区一起寻找通用解法。
-
从这个角度看,SREWorks 更像是给你提供了一套“搭建企业级运维产品”的基础设施,而不仅是一堆现成功能的集合。
五、如何上手:从“先用起来”到“玩明白”的建议路径
聊到这里,可能你会问两个很现实的问题:
-
这东西这么复杂,我要多久才能“跑起来”?
-
跑起来之后,怎么避免变成“又一个巨型系统,没人敢动”?
结合官方文档与代码结构,我的建议是:
5.1 第一步:在测试环境快速跑通
参考仓库中的 “快速安装/源码安装” 文档,大致步骤通常是:
-
准备一个 Kubernetes 集群(本地 kind / 单节点 / 云上皆可);
-
根据
chart/sreworks-chart/values.yaml配置存储类、域名等基础信息; -
使用 Helm 或脚本(
build.sh、sbin/upgrade-cluster.sh等)完成安装; -
等待
sreworks、sreworks-dataops、sreworks-aiops命名空间中 Pod 全部 Running; -
访问平台主页,登录后台,确认
desktop、swadmin等 SaaS 正常工作。
这一阶段的目标很简单:
先把东西跑起来,熟悉一下“从界面看过去”是一个什么样的平台。
5.2 第二步:选一条业务线,做“样板间”
在真实企业环境里,不建议一上来就“全量接入”,而是:
-
选一个业务线(或一个部门),作为试点对象;
- 帮他们把一个典型业务按 AppPackage 模式迁移进来:
-
先用最小集成方式:只接入发布、监控和日志;
-
再逐步扩大范围:接入 DataOps 回流、接入 AIOps 告警等;
-
- 把这条业务线的实践沉淀成“最佳实践模板”,例如:
-
xxx-业务标准应用模板; -
xxx-业务标准告警与巡检看板;
-
-
在平台内侧广泛宣传,让更多团队看到“别人是怎么玩的”。
这一阶段的关键,不是让所有团队立刻迁移,而是:
建立“标杆”和“可复制的路径”,让平台不再是运维团队的“自嗨项目”。
5.3 第三步:把 DataOps & AIOps 做成真正的“平台能力”
当你有了几个成功样板之后,可以考虑进一步升级 DataOps & AIOps:
- 把运维数据真正纳入企业数据资产体系:
-
与数仓、BI 团队一起定义运维相关 ODS/DWD/DWS 模型;
-
让“运维健康度”、“发布质量”、“业务可用性”等指标进入管理报表;
-
- 把 AIOps 能力封装为平台服务:
-
提供统一的“异常检测服务”、“根因分析服务”等;
-
对各个业务线暴露简单的 API/配置界面,而不是让他们自己去搞算法;
-
- 把平台演进纳入公司的技术规划:
-
每半年/一年复盘一次平台能力;
-
看哪些能力可以上升为“集团级/公司级标准”;
-
哪些是只在特定 BU/业务线下落地的“定制能力”。
-
到这一步,你会发现:
SREWorks 已经不再是“某个运维系统”,而成为了你们“运维数字化与智能化”的承载平台。
六、未来演进与思考:从平台到生态,从工具到方法论
站在今天的时间点回头看,SREWorks 做的是一件不容易的事:
-
既要处理 K8s 这一层复杂度极高的基础设施;
-
又要兼顾大数据、AI、可观测性等多种技术栈;
-
还要把 Google SRE 理念、中国企业的实际国情,以及阿里内部多年运维经验融合起来。
从项目当前的代码结构和文档来看,未来可以预期的演进方向,大致有这么几个:
- 更强的多云与混合云能力:
-
目前已经能较好地支持 K8s 集群,未来可以在“跨云统一管理、边缘场景”上进一步增强;
-
- 更丰富的生态集成:
-
与主流 CI/CD、服务网格、安全平台等形成更紧密的联动;
-
提供标准化 Webhook/插件接口,方便企业内已有系统对接;
-
- 更好的自动化闭环:
-
今天的自动化更多集中在“发布与部署流水线”,未来可以在“自愈、变更风险控制、容量自动调整”等方面加深;
-
- 方法论与最佳实践的系统输出:
-
结合阿里的经验,把 SREWorks 背后的“运维方法论”讲清楚,沉淀成一套可复制、可落地的体系;
-
帮助更多团队少踩坑、少走弯路。
-
对使用者来说,更重要的也许不是“这个平台现在做到什么程度了”,而是:
它是否给了你一条可行的道路,让你可以从今天的现实条件出发,一步步往“数智运维”走过去。
在这一点上,SREWorks 的开源无疑是一件很有价值的事:
-
你可以从中借鉴架构与实现思路,哪怕不直接使用整个平台;
-
你可以把自己的实践反哺到社区,共同打磨更通用的能力;
-
你也可以把它作为内部平台建设的“参考蓝本”,制定更贴合自身业务的演进路线。
七、写在最后:给正在一线“救火”的你
如果你读到了这里,很大概率你是:
-
正在一线处理业务告警的 SRE;
-
正在思考怎样把“运维变成产品”的平台负责人;
-
或者,是对云原生运维深感兴趣、正在寻找突破口的工程师。
也许你会问:
“我今天就一个三节点的 K8s 集群,有必要上这么一整套 SREWorks 吗?”
坦白讲,答案未必是绝对的“是”。但不妨换个角度:
- 即便你暂时不打算“直接用”,也完全可以从 SREWorks 里学到很多:
-
如何用 AppManager 这类模型,把应用的交付与运维结构化表达出来;
-
如何搭建 DataOps 底座,让运维数据不再散落在四处;
-
如何在真实工程中把 AIOps 做成“轻量而可控”的增量,而不是一把梭的重构;
-
-
当有一天,你所在的团队需要从“人肉救火”升级为“平台化运维”时,这些思路会极大降低你们的试错成本。
最后,用一句略带鸡汤却很真诚的话收个尾:
真正优秀的 SRE,从来不只是“修好系统的人”,而是“让系统更容易被修好的人”。
如果 SREWorks 能在这个过程中,帮你少踩几个坑、多搭几块“乐高积木”,那它就已经实现了开源的价值之一。
有兴趣的话,不妨亲手在测试环境里把它拉起来,
—— 也许下一次凌晨被电话叫醒时,你会发现,事情已经比今天好一点点了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)