PaLM:Pathways 驱动的大规模语言模型 scaling 实践
本文是对论文《PaLM: Scaling Language Modeling with Pathways》的深度解读。在大模型研究领域,如何实现高效规模化训练并解锁复杂任务能力,是核心挑战。Google Research 团队提出的 PaLM 模型,以 5400 亿参数稠密 Transformer 为基础,借助 Pathways 系统实现跨 TPU Pod 高效训练,在少样本推理、代码生成等任务中
PaLM(Pathways Language Model)作为 Google Research 推出的 5400 亿参数稠密激活 Transformer 语言模型,凭借 Pathways 系统的高效训练能力,在数百个自然语言理解与生成基准测试中刷新了少样本学习的性能上限。
原文链接:https://arxiv.org/pdf/2204.02311
沐小含将持续分享前沿算法论文,欢迎关注...
一、研究背景与核心目标
1.1 大模型发展现状与挑战
近年来,大型语言模型在少样本学习领域展现出惊人能力 —— 无需大规模任务特定数据微调,仅通过自然语言任务描述和少量示例即可完成任务。从 GPT-3(1750 亿参数)到 GLaM、Gopher 等后续模型,性能提升主要源于四个关键方向:
- 模型深度与宽度的规模扩张
- 训练 token 数量的增加
- 更高质量、更多样化的训练语料
- 稀疏激活模块实现算力高效的容量提升
但现有模型仍面临瓶颈:训练效率不足、多步推理能力有限、多语言任务表现不均衡,且模型规模与性能的关系尚未被充分探索。
1.2 PaLM 的核心研究目标
- 验证 Pathways 系统在大规模模型训练中的有效性,实现跨多个 TPU Pod 的高效训练
- 探索模型规模(参数与训练 token)对少样本学习性能的影响,验证 scaling 效应是否已达饱和
- 评估大模型在推理、代码生成、多语言任务等复杂场景的能力边界
- 系统分析模型的偏见、毒性与数据记忆问题,提出伦理风险缓解策略
二、模型架构设计
PaLM 采用解码器 - only 的 Transformer 架构,在标准设计基础上进行了多项优化,以平衡训练效率与模型性能:
2.1 关键架构修改
- SwiGLU 激活函数:采用
形式,相比 ReLU、GeLU 等激活函数显著提升模型质量,尽管需增加一次矩阵乘法,但在算力等价实验中表现更优;
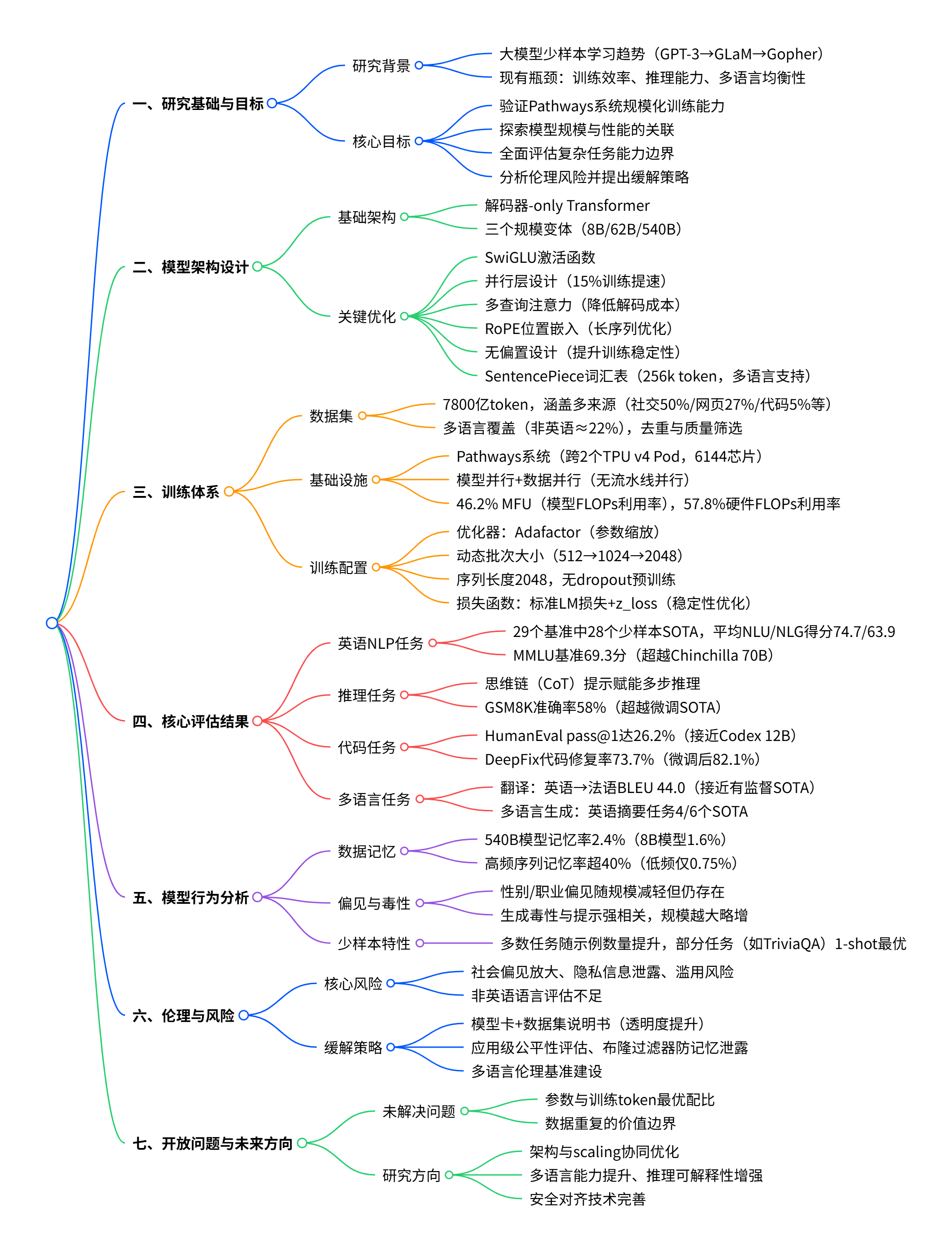
- 并行层设计:将标准串行结构
改为并行结构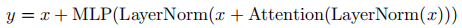
使 MLP 与注意力机制的输入矩阵乘法可融合,大规模训练速度提升约 15%;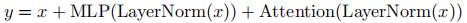
- 多查询注意力(Multi-Query Attention):共享所有注意力头的 key/value 投影,仅 query 保持多头投影,在不影响模型质量和训练速度的前提下,大幅降低自回归解码时的计算成本;
- RoPE 位置嵌入:替代绝对或相对位置嵌入,在长序列任务中表现更优;
- 共享输入输出嵌入:减少参数冗余,是大模型设计中的常用优化;
- 无偏置设计:所有稠密核与层归一化中均不使用偏置,提升大模型训练稳定性;
- SentencePiece 词汇表:包含 256k token,支持 100 + 语言,保留空格(对代码任务至关重要),数字拆分为单个字符,确保 Unicode 字符无损处理。
2.2 模型规模配置
论文对比了三个不同参数规模的模型变体,所有模型使用相同数据和词汇表训练,仅批次大小存在差异:
注:feed-forward 维度固定为
,注意力头大小固定为 256。
三、训练数据集与基础设施
3.1 训练数据集构成
PaLM 基于 7800 亿 token 的高质量语料训练,涵盖多种数据源,确保语料多样性与质量:

语料特点:包含 100 + 语言(非英语占比约 22%),代码部分来自开源仓库,经 Levenshtein 距离去重;所有模型训练一个 epoch,避免数据重复。
3.2 训练基础设施与 Pathways 系统
3.2.1 硬件配置
- 基于 JAX 和 T5X 框架训练,部署在 TPU v4 Pods 上
- PaLM 540B 跨两个 TPU v4 Pod 训练,每个 Pod 包含 3072 个 TPU v4 芯片和 768 台主机,总计 6144 个 TPU v4 芯片
- 采用模型并行与数据并行结合的方式,无需流水线并行即可实现高效扩展
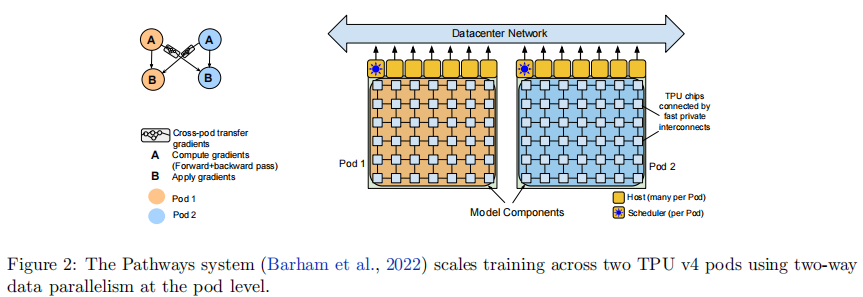
3.2.2 Pathways 系统核心优势
Pathways 是 Google 推出的新型机器学习系统,支持跨数千个加速器芯片的高效训练,其核心设计包括:
- Pod 级双向数据并行:单个 Python 客户端将训练批次拆分到两个 Pod,每个 Pod 独立执行前向 / 反向计算,随后交换梯度并并行更新参数,确保参数一致性
- 异步调度与分片数据流:通过 Pod 级调度器的异步调度掩盖任务分发延迟,采用分片数据流模型降低数据传输成本
- 优化的跨 Pod 梯度传输:将梯度数据拆分为小块,通过多路径路由避免网络拥堵,实现 97% 的弱扩展效率(理论 2 倍吞吐量,实际达 1.95 倍)
3.2.3 训练效率评估
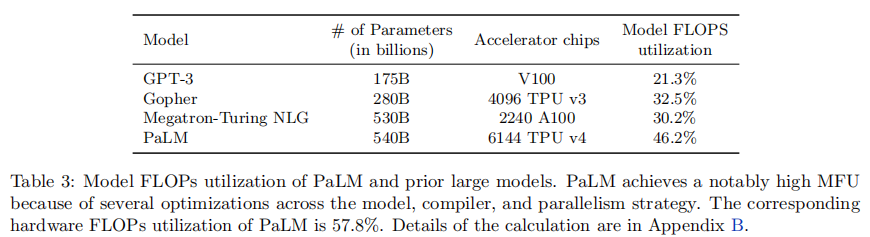
论文提出模型 FLOPs 利用率(MFU) 指标,相比传统硬件 FLOPs 利用率(HFU)更具可比性,定义为实际 token 吞吐量与理论最大吞吐量的比值(仅计算前向 + 反向必需操作,不包含重计算)。PaLM 540B 的 MFU 达到 46.2%(含自注意力),硬件 FLOPs 利用率为 57.8%,显著优于同类大模型:
四、训练设置与优化策略
4.1 核心训练配置
- 权重初始化:核权重采用 "fan-in 方差缩放"(
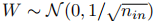 ),输入嵌入初始化为
),输入嵌入初始化为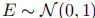 ,由于输入输出嵌入共享,预 softmax 输出 logits 缩放
,由于输入输出嵌入共享,预 softmax 输出 logits 缩放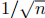 (
(为嵌入维度)
- 优化器:使用 Adafactor 优化器(无分解),等价于带参数缩放的 Adam,自动适配不同参数矩阵的学习率
- 学习率策略:前 10,000 步使用 10⁻² 的固定学习率,之后按
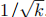 衰减(
衰减(为步数);动量
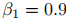 ,二阶矩插值
,二阶矩插值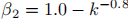
- 损失函数:标准语言建模损失(无标签平滑)+ 辅助损失
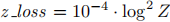 ,确保 softmax 归一化器接近 0,提升训练稳定性
,确保 softmax 归一化器接近 0,提升训练稳定性 - 序列长度:固定为 2048token,输入示例拼接后拆分,无填充 token,示例间用 [eod] 分隔
- 动态批次大小:随训练进度增大批次(540B 模型:512→1024→2048),平衡早期样本效率与后期训练效率
- 位级确定性:基于 JAX+XLA+T5X 实现完全可复现训练,确保从相同检查点重启可获得一致结果
- 无 dropout:预训练时不使用 dropout,微调时通常使用 0.1 的 dropout 率
4.2 训练不稳定性处理
PaLM 540B 训练过程中出现约 20 次损失尖峰(小规模模型未观察到),解决方案为:从尖峰前 100 步的检查点重启训练,跳过 200-500 个数据批次。实验表明,损失尖峰是特定数据批次与模型参数状态共同作用的结果,而非单一 "坏数据" 导致。
五、全面评估结果与分析
论文对 PaLM 进行了多维度、大规模的评估,涵盖英语 NLP、推理、代码、翻译、多语言生成等任务,全面验证模型能力。
5.1 英语 NLP 任务评估
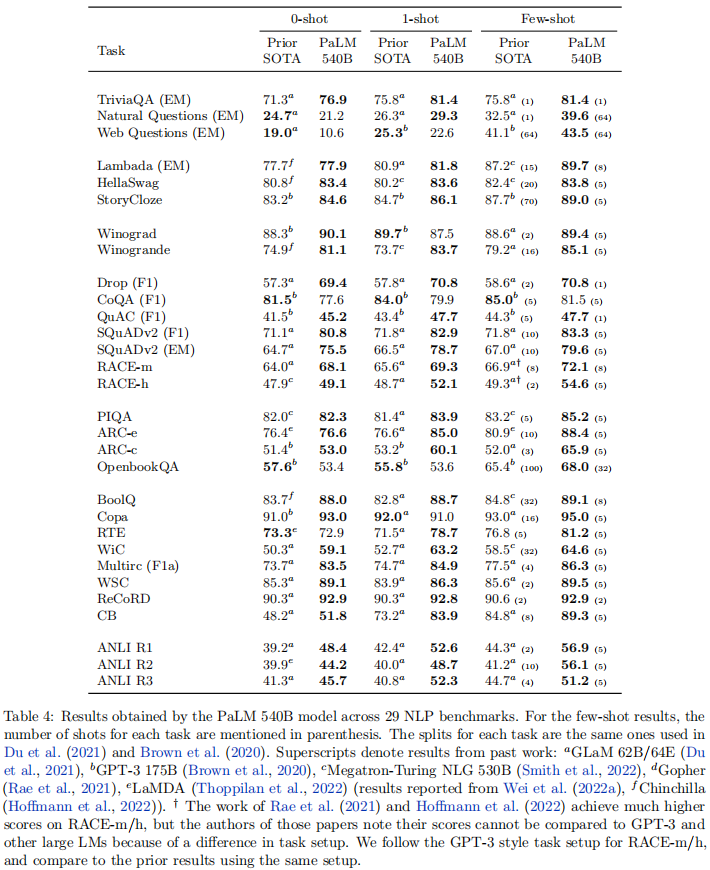
在 29 个常用英语 NLP 基准测试中,PaLM 540B 表现惊艳:
- 少样本设置下,28 个任务超越现有 SOTA,部分阅读理解和自然语言推理任务领先幅度超 10 分
- 1 样本设置下,24 个任务超越现有 SOTA
- 相比同等规模的 Megatron-Turing NLG 530B,所有基准测试均实现性能超越,证明训练数据、策略与 token 数量的重要性
不同规模 PaLM 模型的平均 NLG/NLU 得分对比(1 样本评估):
在 MMLU(涵盖 57 个任务的多领域问答基准)中,PaLM 540B 以 69.3 的平均分超越 Chinchilla 70B(67.5),除 "其他" 类别外,所有类别均实现性能领先。
5.2 BIG-bench 基准测试
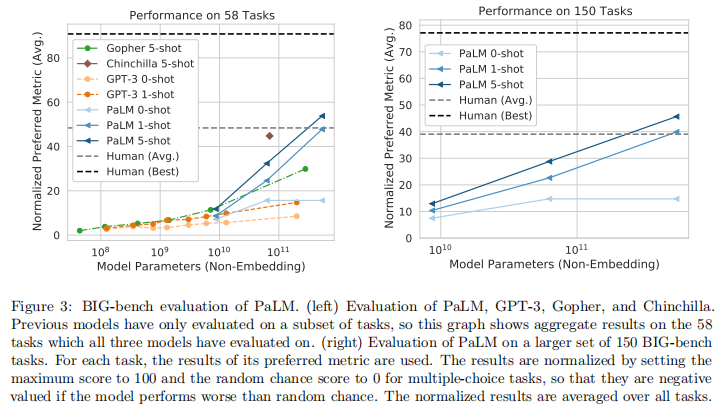
BIG-bench 包含 150 + 挑战性语言任务,是评估大模型综合能力的关键基准:
- PaLM 540B 5 样本设置下,平均得分超过人类平均水平,在 58 个共同任务中 44 个超越现有 SOTA
- 约 25% 的任务呈现不连续提升:从 62B 扩展到 540B 的性能提升远大于 8B 到 62B 的提升(如英语谚语任务:62B 准确率 25%,540B 达 87%)
- 模型性能随规模呈对数线性增长,未出现饱和迹象,表明进一步扩大规模仍可能解锁新能力
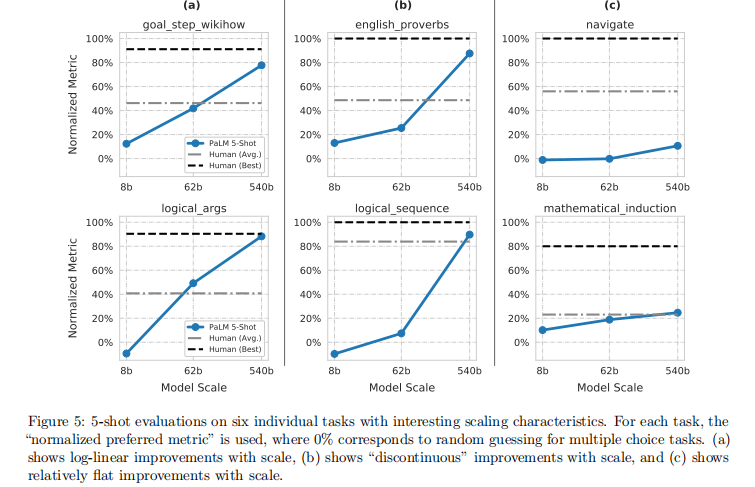
典型任务的 scaling 特征示例:
- 对数线性提升:目标步骤推理(goal_step_wikihow)、逻辑论证(logical_args)
- 不连续提升:英语谚语(english_proverbs)、逻辑序列(logical_sequence)
- 提升平缓:导航(navigate)、数学归纳(mathematical_induction)
5.3 推理任务评估
推理任务(尤其是多步数学和常识推理)是大模型的传统弱项,PaLM 通过思维链(Chain-of-Thought, CoT)提示实现突破:
- 结合模型规模与 CoT 提示,无需任务特定微调、领域特定架构或验证器,即可在多个推理任务中超越现有 SOTA
- GSM8K(小学数学应用题)中,PaLM 540B+CoT + 计算器实现 58% 准确率,超越此前 SOTA(55%,需微调 + CoT + 计算器 + 验证器)
- 错误分析表明,规模从 62B 扩展到 540B 可显著修复语义理解、步骤缺失等推理错误

5.4 代码任务评估
PaLM 在代码生成、翻译、修复等任务中表现优异,甚至超越专用代码模型:
- 文本到代码:HumanEval(0 样本)pass@1 达 26.2%,接近 Codex 12B(28.8%);GSM8K-Python(4 样本)pass@1 达 51.3%,超越 Davinci Codex(32.1%)
- 代码到代码:C++ 到 Python 翻译(3 样本)pass@1 达 51.8%,超越 Davinci Codex(54.4%);DeepFix 代码修复(2 样本)pass@1 达 73.7%,接近 Davinci Codex(81.1%)
- 微调优化:PaLM-Coder(540B + 代码微调)在 HumanEval pass@100 达 88.4%,DeepFix 修复率达 82.1%,进一步提升代码任务性能

PaLM 代码任务性能优势源于:跨语言 / 自然语言的迁移能力、大模型的样本高效性(仅使用 2.7B Python token 训练,远少于 Codex 的 100B)
5.5 翻译任务评估
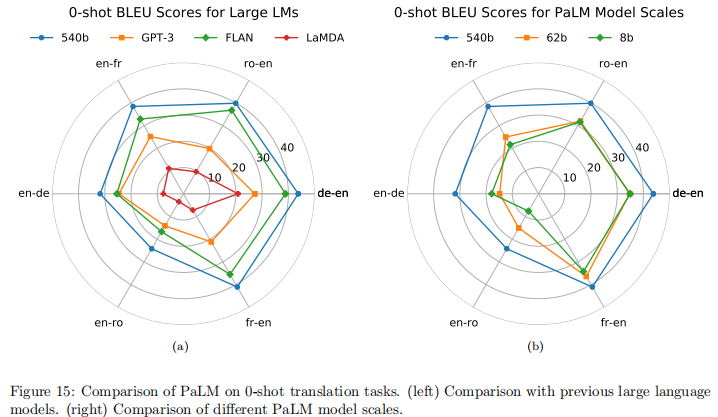
PaLM 未专门训练平行语料,但仍展现出强大的翻译能力:
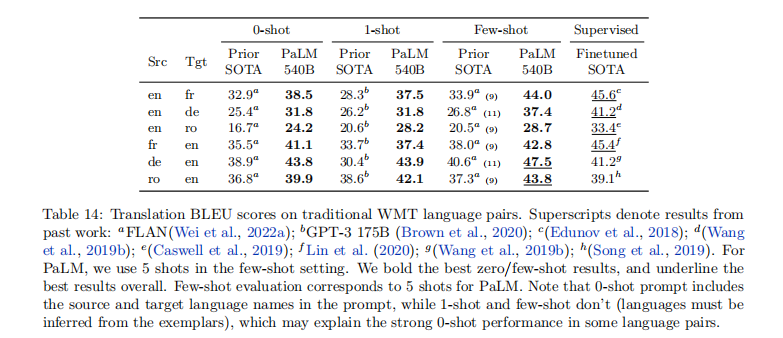
- 英语中心语言对:英语到法语(少样本 BLEU 44.0)、德语到英语(47.5)等任务表现接近或超越有监督 SOTA
- 直接翻译(非英语中介):法语到德语(0 样本 BLEU 25.2)接近有监督 SOTA(24.9)
- 极低资源语言对:英语到哈萨克语(少样本 BLEU 5.1),尽管与有监督 SOTA(15.5)有差距,但考虑到训练数据中哈萨克语仅 1.34 亿 token,表现已属突出
- 关键发现:翻译到英语的质量优于从英语翻译;0 样本设置(包含语言名称提示)性能常优于 1 样本 / 少样本(需推断语言)
5.6 多语言自然语言生成与问答
5.6.1 多语言生成
在 GEM 基准的摘要生成和数据到文本任务中:
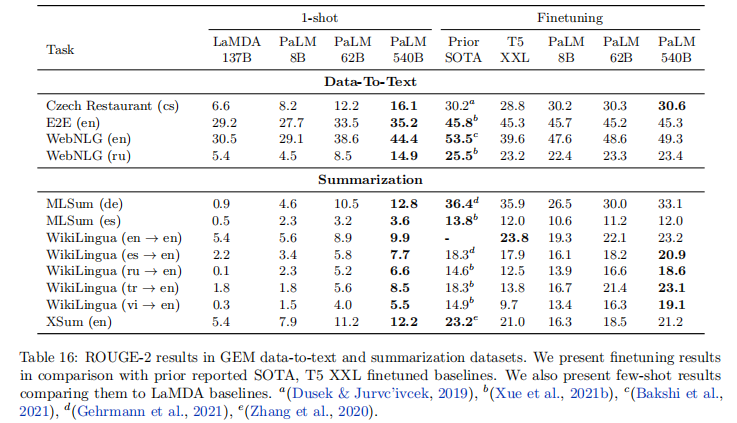
- 微调后,PaLM 540B 在 4/6 个英语摘要任务中实现 SOTA,证明规模可弥补解码器 - only 架构的固有劣势
- 非英语生成任务(如德语 MLSum)表现稍逊,表明非英语训练数据不足(22%)的影响
- 少样本生成性能随模型规模提升显著,但与微调结果仍有差距,为后续优化留下空间
5.6.2 多语言问答
TyDiQA-GoldP 基准(9 种语言)中:
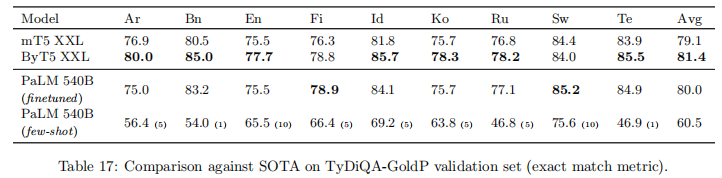
- 微调后 PaLM 540B 平均 EM 得分为 80.0,超越 mT5 XXL(79.1),接近 ByT5 XXL(81.4)
- 少样本与微调差距较大,但斯瓦希里语、芬兰语等语言的差距较小,提示语言特性对少样本性能的影响
5.7 少样本学习特性分析
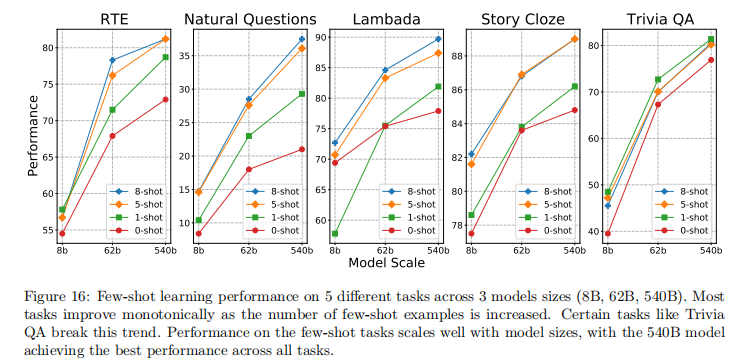
- 样本数量影响:多数任务随少样本示例数量增加性能提升,但 TriviaQA 任务中 1 样本表现优于 5 样本 / 8 样本
- 训练稳定性:模型性能在训练过程中存在波动(如 Web Questions 任务),部分检查点性能优于最终检查点
- 数据污染分析:10/29 个英语任务存在部分数据污染,但清洁子集与完整数据集的性能差异不大,表明污染对结果影响有限
六、模型行为分析:记忆、偏见与毒性
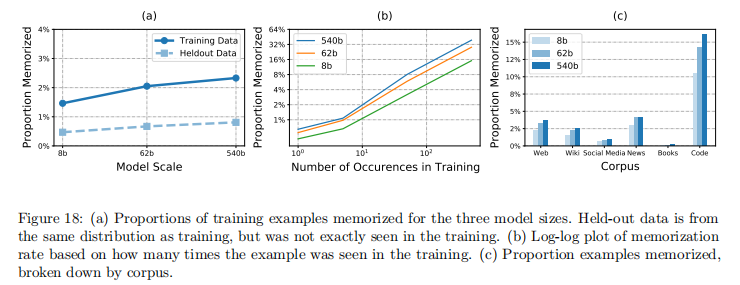
6.1 数据记忆分析
通过测试模型对训练数据中 100token 序列的续写能力(前 50token 提示,评估后 50token 匹配度):
- 模型规模越大,记忆能力越强:8B 模型记忆率 1.6%,540B 模型达 2.4%
- 数据重复次数是记忆的关键因素:训练中出现 500 + 次的序列记忆率超 40%,仅出现 1 次的序列记忆率仅 0.75%
- 代码语料记忆率最高(含大量模板化许可文本),书籍语料记忆率最低(内容独特性高)
6.2 表征偏见分析
6.2.1 性别与职业偏见
- Winogender 共指消解任务中,PaLM 540B 在 1 样本 / 少样本设置下实现 SOTA,且性能随规模提升,表明规模扩大有助于减轻部分性别偏见
- 刻板印象偏差仍存在:"典型" 性别 - 职业组合(如护士 - 女性)的准确率高于 "反刻板" 组合(如护士 - 男性),但随少样本示例增加,差距逐渐缩小
6.2.2 种族 / 宗教偏见
- 共现分析显示,模型存在刻板印象关联(如穆斯林与恐怖主义、暴力等词汇关联),且跨模型规模表现一致
- 提示文本微小变化会导致偏见表现大幅差异(如 "拉丁裔" 相关提示在特定表述下出现暴力相关词汇)
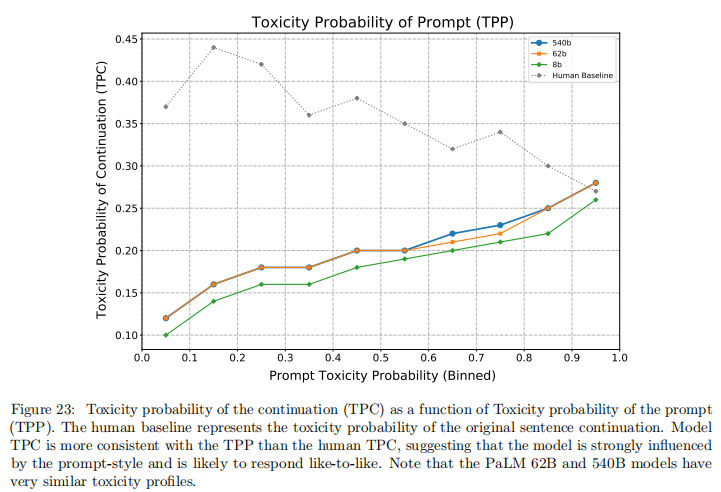
6.3 毒性生成分析
- 模型规模与毒性存在关联:62B 和 540B 模型生成内容的毒性略高于 8B 模型
- 模型生成毒性与提示文本毒性高度相关(人类生成无此强相关性),表明模型倾向于模仿提示风格
- 限制生成长度(如仅评估首句)会降低毒性评分,提示毒性随文本长度增加而上升
七、伦理考量与风险缓解
7.1 核心伦理风险
- 训练数据中的社会偏见被模型捕获并放大,可能强化刻板印象
- 数据记忆可能导致隐私信息泄露,尤其是高频出现的文本片段
- 大规模生成能力可能被滥用,用于虚假信息传播或针对性骚扰
- 非英语语言的偏见与毒性评估不足,多语言场景风险未被充分覆盖
7.2 缓解策略建议
- 完善透明度文档:提供模型卡(Model Card)和数据集说明书(Datasheet),明确模型能力与局限
- 针对性数据优化:改进训练数据过滤策略,平衡毒性过滤与边缘群体内容代表性
- 应用级风险控制:部署前针对具体场景进行公平性评估,而非依赖预训练模型优化
- 技术防护措施:如通过布隆过滤器限制训练数据中 verbatim 内容生成,减少记忆泄露风险
- 扩展评估覆盖:建立多语言、多文化背景的偏见与毒性基准,完善风险评估体系
八、开放问题与未来方向
8.1 模型 scaling 的关键未解问题
- 参数规模与训练 token 的最优配比:62B 模型训练 7T token 与 540B 模型训练 780B token,哪个更高效?
- 数据重复的价值边界:训练数据重复使用的收益递减点在哪里?刷新数据集 vs 重复训练的权衡如何?
- 架构创新与规模扩展的协同:稀疏激活、检索增强等技术与规模扩展结合的潜力未被充分探索
8.2 未来研究方向
- 探索更多架构与训练策略,结合 Pathways 的 scaling 能力,开发更高效的大模型
- 提升多语言能力:增加非英语训练数据占比,优化低资源语言的模型表现
- 增强推理可解释性:进一步发展思维链提示技术,提升模型推理过程的透明度
- 完善安全对齐:开发更有效的偏见与毒性缓解技术,确保模型能力与社会价值对齐
9. 总结与启示
PaLM 作为 5400 亿参数的大规模语言模型,通过 Pathways 系统实现了高效训练,其全面的评估结果与深入的行为分析为大模型研究提供了宝贵启示:
- scaling 效应仍未饱和:模型性能随参数规模和训练 token 数量持续提升,部分任务呈现不连续提升,表明更大规模模型可能解锁全新能力
- 效率优化是关键:Pathways 系统实现 46.2% 的 MFU,证明合理的并行策略与系统设计可显著提升大模型训练效率
- 提示工程赋能复杂任务:思维链提示与规模扩展结合,使少样本推理性能超越微调 SOTA,为复杂任务优化提供新范式
- 伦理风险不可忽视:模型偏见、毒性与数据记忆问题随规模提升并未消失,需从数据、技术、应用多个层面建立风险防控体系
PaLM 不仅刷新了大模型性能基准,更通过系统性的实验设计与分析,为大模型的可持续发展提供了重要参考,其技术创新与实践经验将深刻影响未来大规模语言模型的研究与应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)