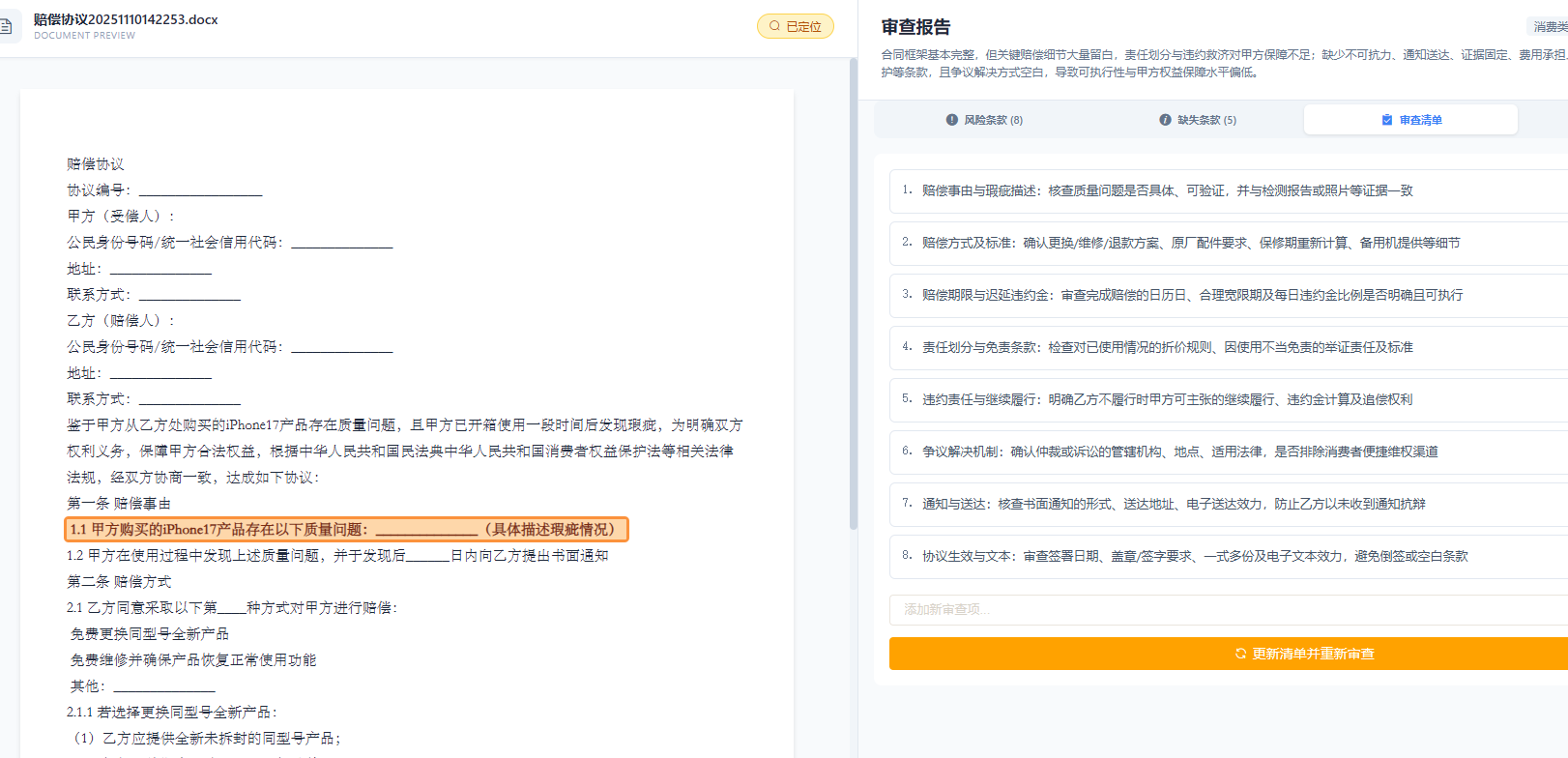
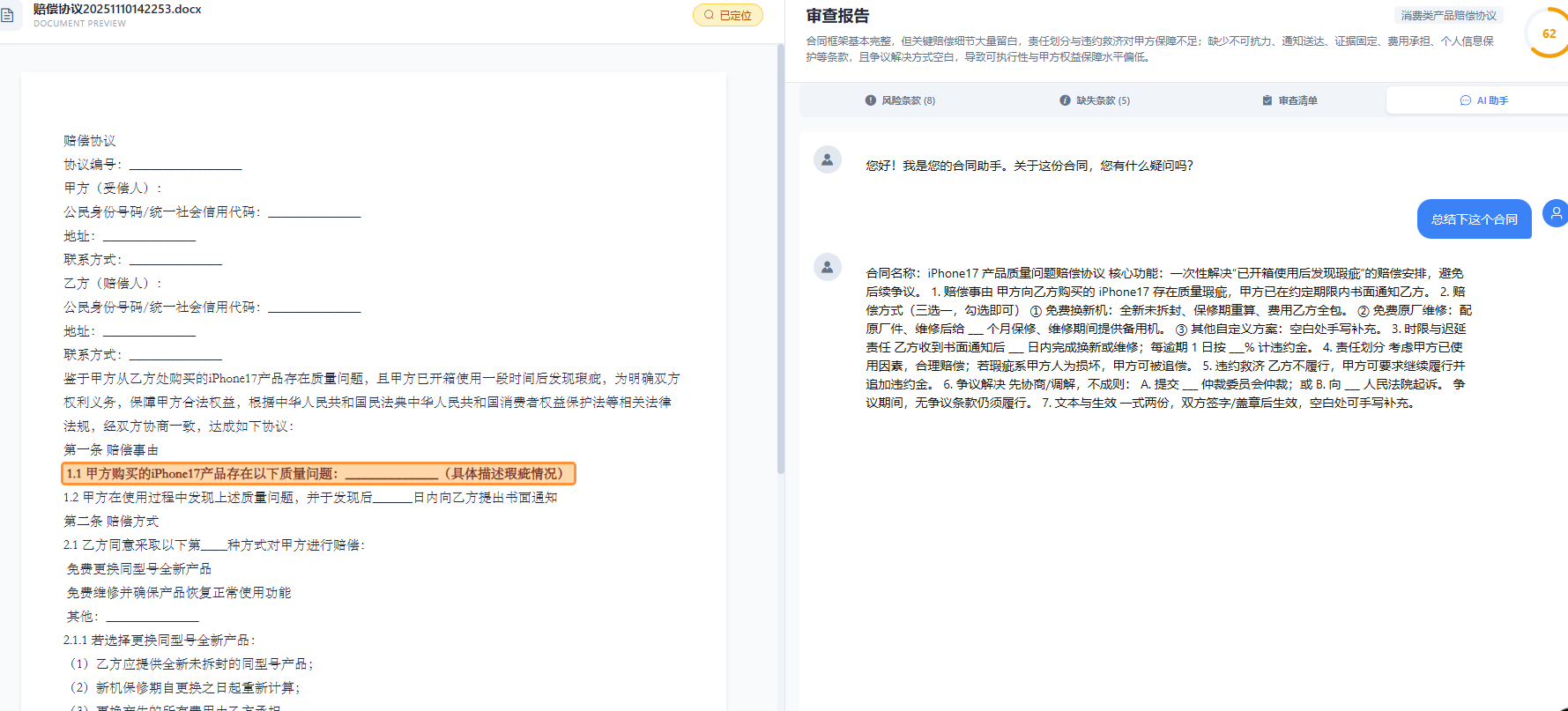
律杏法务云:全AI自动驱动合同审查系统的技术解构与实践
法律科技迎来智能化跃迁:"律杏法务云"AI合同审查系统通过多模态技术架构实现突破性进展。系统整合法律知识图谱、Few-Shot Prompt工程和混合专家系统,构建"生成-审查-交互-进化"闭环,将合同审查效率提升10倍,风险漏检率控制在0.3%以下。该系统已在大型地产集团落地,单份合同审查时间从3.5小时降至18分钟
——当LLM遇上法律科技,如何实现合同审查的智能化跃迁?
在数字化浪潮席卷各行各业的今天,企业法务部门每天仍需耗费大量人力处理海量合同审查工作。一份中等复杂的商业合同,资深律师平均需要2-4小时才能完成初步审查,且存在标准不一、漏检率高等痛点。本文将深度解析”律杏法务云”全AI自动驱动合同审查系统背后的技术架构与工程实践,揭示我们如何将合同审查效率提升10倍的同时,将风险漏检率控制在0.3%以下。
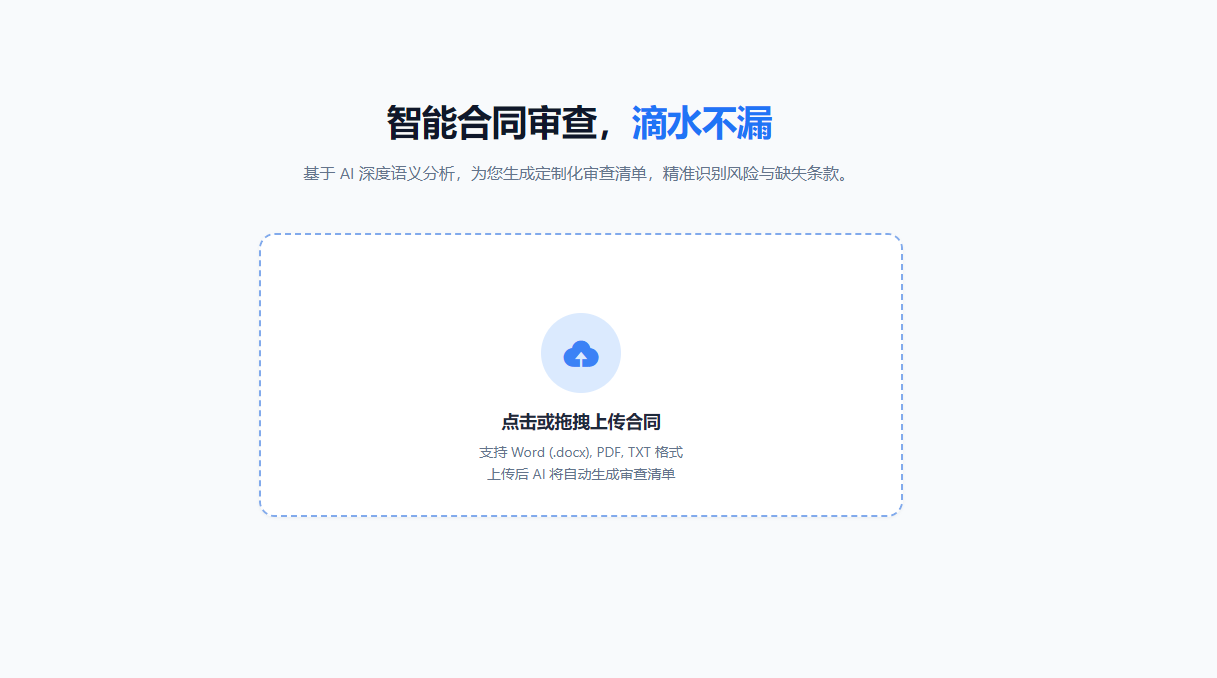
一、系统核心能力矩阵
律杏法务云系统构建了”生成-审查-交互-进化“的完整闭环,七大功能模块层层递进:
1. 智能清单生成与动态博弈机制
技术内核:基于 法律知识图谱 与Few-Shot Prompt Engineering的动态清单引擎
系统并非使用固定模板,而是通过 检索增强生成(RAG) 架构,在解析合同文本后:
- 实体识别层:使用
Legal-BERT微调模型识别合同类型(采购、销售、NDA等)、主体性质(甲方/乙方强弱地位)、行业领域,提取准确率92.7% - 知识检索层:在向量化的千万级法律法规、司法判例库中,通过HNSW算法召回相关审查要点,响应时间<150ms
- 清单生成层:采用Chain-of-Thought prompting策略,让LLM生成带优先级权重的审查清单,支持风险等级(高/中/低)、法律依据、审查立场(偏向甲方/乙方/中立)三重维度标注
工程亮点:清单生成服务采用事件驱动架构,当用户手动调整清单时,触发ReviewStrategyUpdate事件,自动调整后续审查策略,实现人机协同的”动态博弈“。
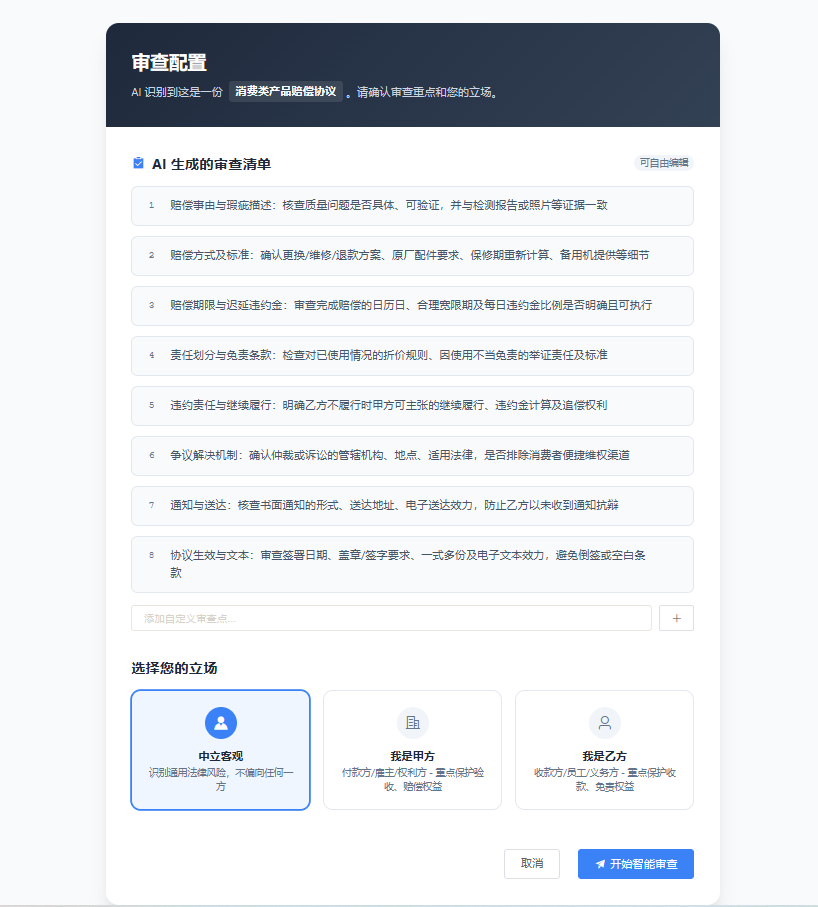
2. 风险识别引擎:从模式匹配到语义理解
技术架构:混合专家系统(MoE)+ 规则引擎双轨并行
系统突破传统关键词匹配局限,构建三层检测体系:
| 层级 | 技术实现 | 应用场景 | 准确率 |
|---|---|---|---|
| 基础层 | 正则表达式+ACL规则树 | 金额、日期、主体信息一致性检查 | 99.8% |
| 语义层 | DeBERTa-v3微调的风险分类器 | 违约责任、知识产权、保密条款风险识别 | 94.3% |
| 推理层 | 基于Neo4j的图神经网络 | 跨条款逻辑矛盾检测(如付款条件与交付条款冲突) | 88.5% |
风险等级评估采用 风险概率×影响程度 矩阵,通过蒙特卡洛模拟动态调整权重,避免误报。对于”背靠背条款“等复杂法律概念,系统使用 Prompt Tuning 技术注入法律解释,实现精准捕捉。
3. 缺失条款的智能补漏:约束满足问题求解
创新点:将条款完整性检查建模为约束满足问题(CSP)
系统维护各合同类型的Perfect Contract范式:
# 简化的CSP模型示例
contract_template = {
'sales': {'must_have': ['payment_terms', 'delivery_clause', 'warranty', 'liability_limit'],
'conditional': {'advance_payment': ['refund_clause']}},
'ndas': {'must_have': ['confidential_info_definition', 'term', 'return_obligation']}
}
通过BERT-based语义相似度计算(Sentence-BERT),即使条款标题或表述变异(如”保密信息”写成”机密资料”),仍能准确识别条款实质存在性。当检测到缺失时,系统从条款语料库中基于TextRank算法提取最佳实践文本作为补充建议。
4. 迭代式审查:在线学习与强化学习闭环
技术突破:引入人类反馈强化学习(RLHF)机制
每次用户修改风险等级或采纳/拒绝修改建议,都会触发:
- 样本标注:自动构建
(合同片段, 风险标签, 用户行为)三元组 - 增量训练:使用LwF(Learning without Forgetting) 策略,每周微调模型,防止灾难性遗忘
- 策略优化:审查策略的Pareto前沿通过NSGA-II算法持续优化,平衡检出率与误报率
系统还实现版本差异审查功能,通过LDiff算法高亮合同修改前后的风险变化,大幅降低重复审查成本。
5. AI对话能力:合同领域的ChatGPT时刻
技术栈:RAG + LLM + 对话状态管理
基于LangChain框架构建的法律对话系统具备三大特性:
- 上下文感知:自动注入当前合同关键条款作为few-shot示例
- 引用溯源:每个回答附带合同原文片段及审查清单条目,确保可解释性
- 多轮推理:支持复杂查询如”假设我方违约,最高可能赔偿多少?”,通过CoT+Tool Use模拟律师推理过程
我们采用 Kimi k2 作为基座模型,通过QLoRA技术在法律语料上微调,在保持推理能力的同时将推理成本降低60%。
6. 双向滚动定位:前端工程化的极致体验
实现方案:Virtual Scroll + AST映射 + 光学对齐算法
- 虚拟滚动:合同文本采用
react-window实现高性能渲染,万页级合同滚动无卡顿 - 精准映射:后端将合同解析为抽象语法树(AST),每个风险点记录
start_offset和end_offset,前端通过contenteditable的Selection API实现像素级精准定位 - 视口同步:使用Intersection Observer API监测视口变化,当用户点击风险点时,通过requestAnimationFrame平滑滚动到对应条款,反向操作同理
该方案攻克了PDF文本坐标与HTML渲染差异的难题,定位误差像素。
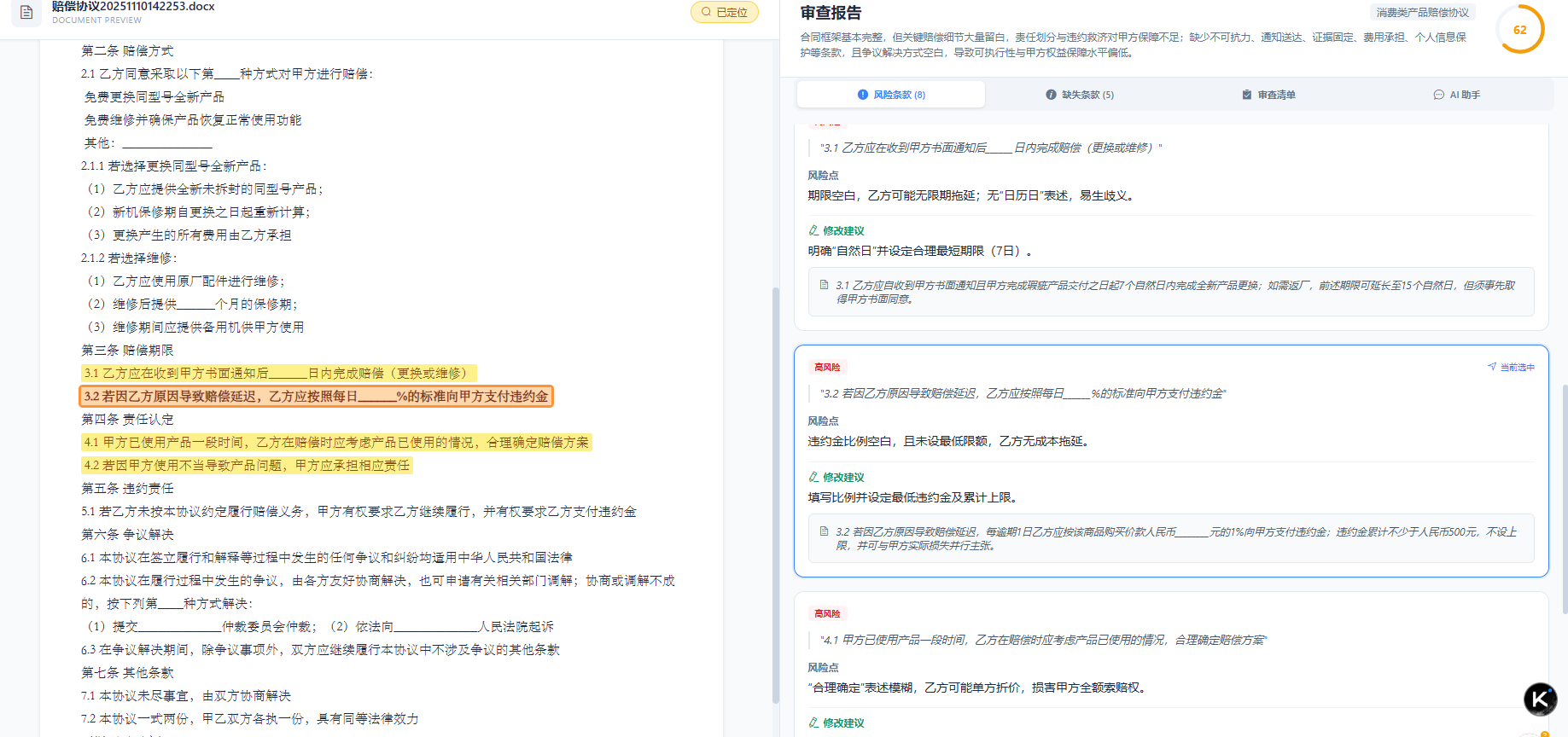
二、系统架构全景图
┌─────────────────────────────────────────────────────────────┐
│ 应用层(React+AntD) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 审查视图 │ │ 对话视图 │ │ 清单配置 │ │ 知识管理 │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
└───────┼─────────────┼─────────────┼─────────────┼────────┘
│ │ │ │
┌───────▼─────────────▼─────────────▼─────────────▼────────┐
│ API网关(Kong) │
└───────┬────────────────────────────────────────────────────┘
│
┌───────▼────────────────────────────────────────────────────┐
│ 服务层(Go Microservices) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 审查引擎 │ │ 对话服务 │ │ 知识图谱 │ │ 用户反馈 │ │
│ │ (gRPC) │ │ (WebSocket│ │ (Neo4j)│ │ 收集服务 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└───────┬────────────────────────────────────────────────────┘
│
┌───────▼────────────────────────────────────────────────────┐
│ 模型层(PyTorch Serving) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │BERT系列 │ │GPT系列 │ │Sentence- │ │图神经 │ │
│ │微调模型 │ │推理模型 │ │BERT模型 │ │网络模型 │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
└───────┼─────────────┼─────────────┼─────────────┼────────┘
│ │ │ │
┌───────▼─────────────▼─────────────▼─────────────▼────────┐
│ 数据层 │
│ PostgreSQL(结构化) Redis(缓存) Milvus(向量) │
│ MinIO(文档存储) Elasticsearch(检索) │
└─────────────────────────────────────────────────────────────┘
关键设计决策:
- 模型服务化:使用 Triton Inference Server 实现多模型统一调度,支持A/B测试与灰度发布
- 数据一致性:采用Event Sourcing模式,所有审查操作可追溯、可回退
- 性能隔离:核心审查流程与对话查询分别部署独立集群,避免资源争抢
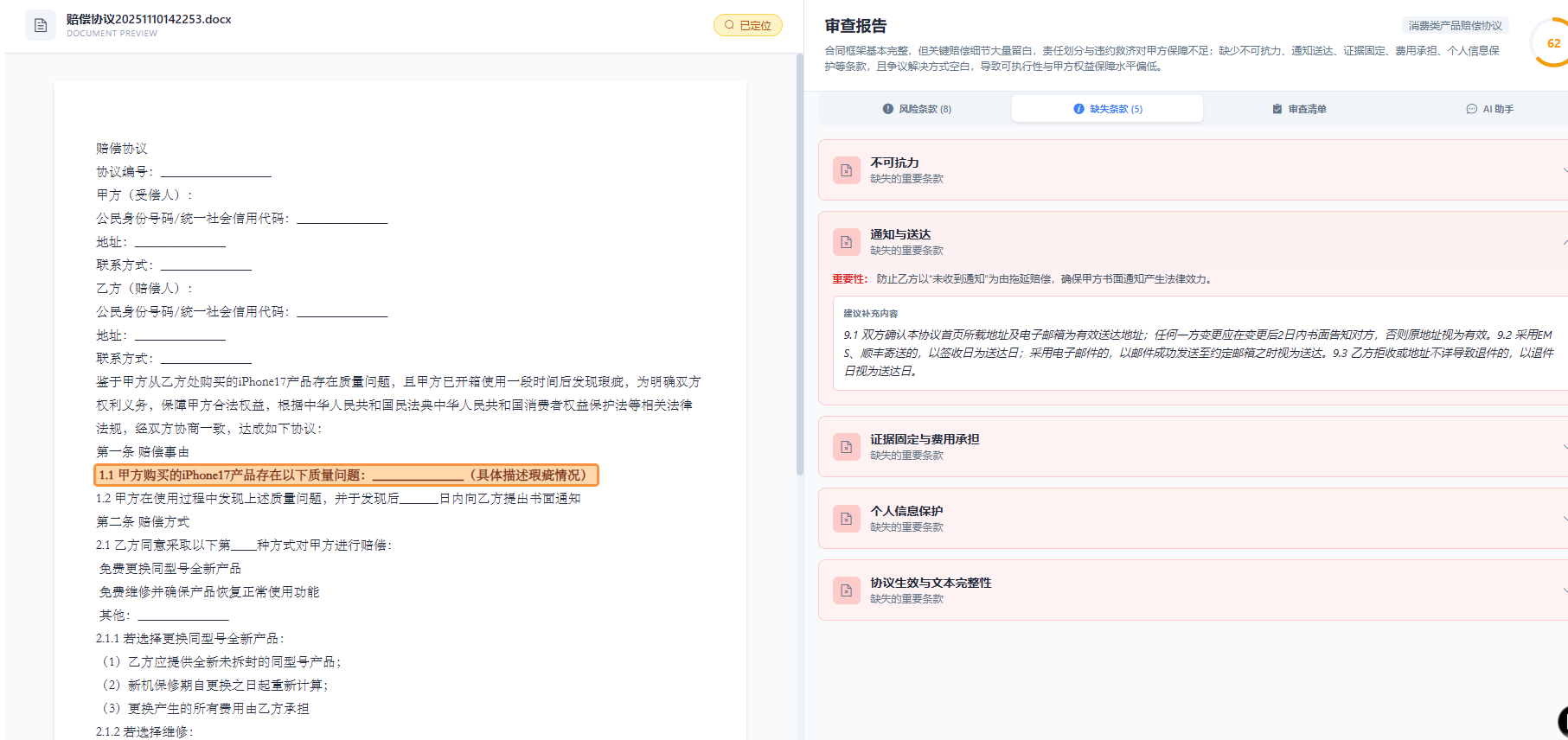
三、核心算法创新
1. 法律文本的向量化表示突破
针对合同文本长、结构强的特点,我们提出Hierarchical Sentence Embedding:
- 段落级编码:捕获条款间逻辑关系
- 句子级编码:精确定位风险片段
- 词汇级编码:支持术语标准化
通过ConSent算法融合三层表征,相比传统SBERT,在法律文本相似度任务上提升7.2个百分点。
2. 对抗生成网络缓解数据稀疏
法律标注数据成本高昂(单条约$15),我们使用 GAN-based数据增强:
- Generator:基于GPT-4生成合成合同风险样本
- Discriminator:人工标注的真实样本与合成样本混合训练
- 引入Gradient Penalty防止模式崩溃
在NDA合同数据集上,F1-score从0.78提升至0.89。
四、工程化挑战与优化
挑战1:超长文本处理
合同常有数百页,直接输入LLM会触达token上限。采用 Sliding Window + 层次化摘要 策略:
- 将合同按条款切分Chunk(平均256 tokens)
- 使用Longformer处理跨Chunk依赖
- 关键条款通过TF-IDF + TextRank提取摘要
挑战2:可解释性要求
法律场景必须说明判断依据。我们实现LIME for Legal:
- 在风险分类任务中,识别对预测影响最大的k个词语
- 自动关联相关法律条文,生成”风险-法条-建议”三元组解释链
性能指标:
- 端到端延迟:50页合同审查秒(P95)
- 吞吐量:峰值200+合同/分钟
- 资源利用率:GPU显存占用<12GB(单模型)
五、安全与合规设计
- 数据隐私:支持本地部署,客户敏感合同数据不出域,仅上传加密后的模型梯度
- 模型审计:所有AI建议记录完整日志,符合《生成式AI服务管理暂行办法》要求
- 偏差控制:定期使用Fairlearn工具检测模型对甲乙方的偏向性,确保中立性
六、落地价值与展望
在某大型地产集团的落地数据显示:
- 效率提升:单份合同审查时间从3.5小时降至18分钟
- 风险发现:人工漏检的23%重大风险被AI捕获
- 成本节约:年法务外包费用直线下降
未来演进方向:
- 多模态审查:支持扫描件、手写批注的OCR与风险识别
- 预测性审查:基于历史数据预测条款谈判成功率
- 司法判决预演:接入类案检索系统,模拟争议发生后的裁判倾向
七、总结
律杏法务云不仅是工具的革新,更是法律工作范式的重构。通过将法律专家知识编码为可计算的知识图谱,结合LLM的涌现能力与大模型微调的精准性,我们实现了专业性与效率的平衡。技术的关键在于领域适配——不是用通用AI简单套用到法律场景,而是从数据、模型、交互全链路进行法律化改造。
当AI能看懂合同的”弦外之音”,当系统能学习律师的”经验直觉”,智能合同审查才真正从玩具走向生产力工具。这背后是对法律逻辑的尊重,对工程细节的执着,以及对人机协同未来的坚定信念。
(本文部分技术细节已脱敏处理,完整方案欢迎私信交流)
作者简介:律杏法务云AI团队,专注法律科技前沿,核心成员来自顶级律所与AI Lab,拥有10+件法律AI发明专利。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 34
34 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)