RAG 还是微调?AI 工程师必须掌握的技术选型指南
摘要: RAG(检索增强生成)与微调(Fine-tuning)是企业应用大模型的两种主流技术。RAG通过动态检索外部知识库生成答案,适合知识高频更新、需可解释性的场景;微调则将特定知识内化到模型中,适用于风格/格式固定的任务。两者各有优势:RAG开发成本低、更新灵活,微调在复杂指令和性能上更优。混合方案(RAG+轻量微调)能兼顾实时性与输出一致性。技术选型需考虑数据合规性、更新频率及成本,建议优先
在大模型落地企业场景的过程中,RAG(Retrieval-Augmented Generation) 与 Fine-tuning(微调) 成为两种主流技术路径。许多团队面临一个核心问题:何时该用 RAG,何时该用微调?甚至是否可以两者结合? 本文从实际工程视角出发,帮你构建一套科学、可落地的技术选型框架,避免“用错工具、花冤枉钱、做无用功”。
一、RAG vs 微调:本质差异在哪里?
RAG 的核心思想是“外挂知识库”——模型本身不变,通过检索外部知识(如文档、数据库)动态拼接上下文,让大模型基于最新、最相关的片段生成答案。
而 Fine-tuning 则是将特定领域的知识或行为模式“内化”到模型参数中,使其在推理阶段无需额外输入即可输出符合预期的内容。
这两种方法在目标、机制和适用边界上存在根本差异。
RAG 的三大优势
- 知识可动态更新:政策文件、产品手册、FAQ 等内容频繁变更时,只需更新向量库,无需重新训练模型。
- 无需训练成本:省去数据标注、模型训练、GPU 资源调度等复杂流程,开发周期短、上线快。
- 可解释性强:生成结果可溯源至具体文档片段,便于审计、合规与人工复核——这对金融、医疗、政务等强监管场景至关重要。
微调的三大优势
- 风格与格式对齐:若需模型以特定语气(如客服话术、法律文书风格)或固定格式(如 JSON、Markdown 表格)输出,微调效果更稳定。
- 复杂指令遵循:当任务逻辑嵌套较深(如“先判断用户类型,再根据权限返回不同层级信息”),微调可将这类逻辑编码进模型行为中。
- 推理性能更优:微调后模型在特定任务上可减少 token 消耗,降低延迟,尤其适合高并发场景。
⚠️ 注意:微调需将训练数据“喂”给模型,若数据含 PII(个人身份信息)或敏感内容,必须严格脱敏,否则存在数据泄露风险。而 RAG 的知识库可独立部署、权限隔离,更易满足 GDPR、等保等合规要求。
二、决策树:一张图帮你选对技术路径
下图提供一个清晰的技术选型决策流程,适用于大多数企业 AI 应用场景: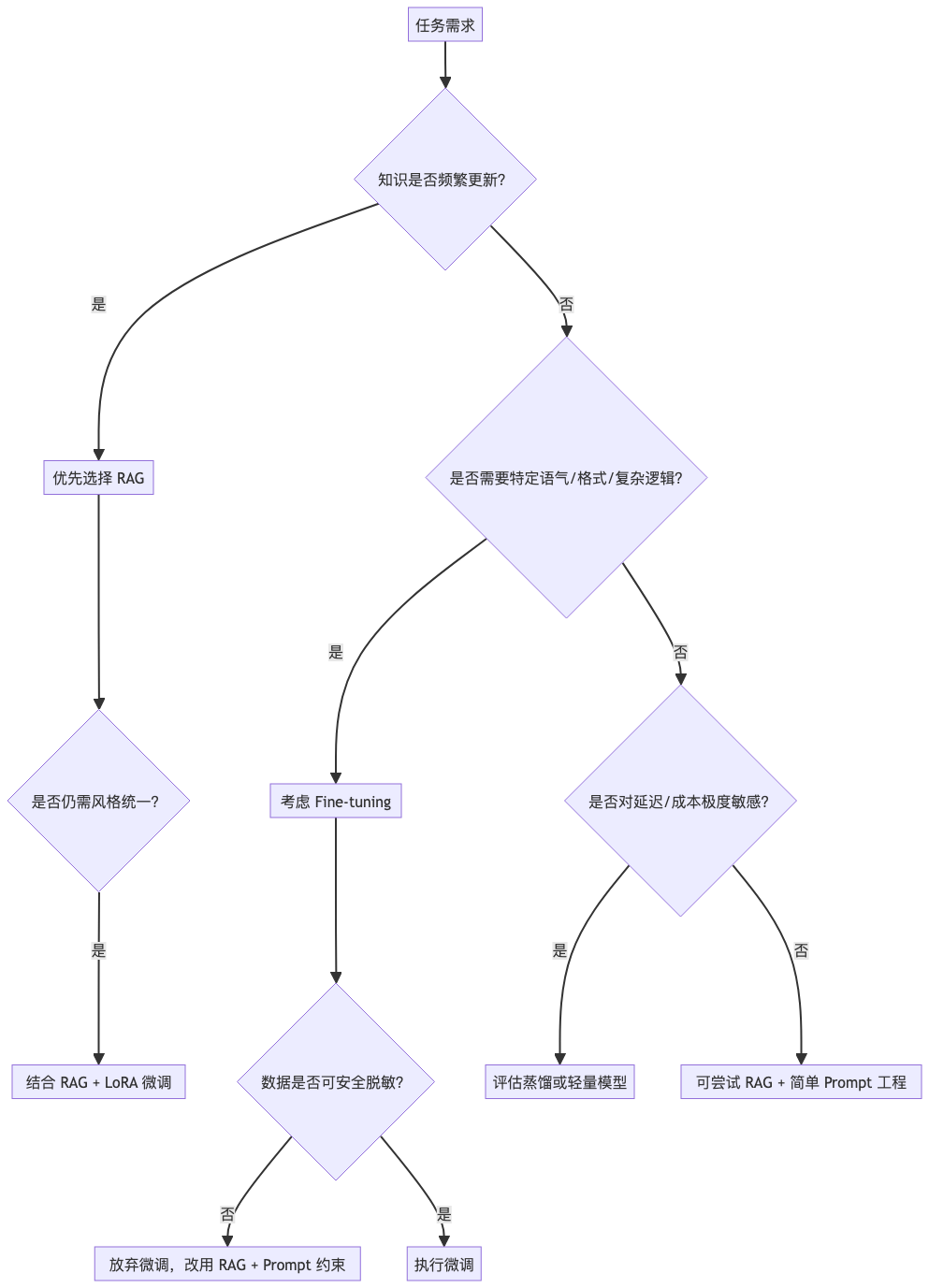
该决策树的核心逻辑如下:
- 知识高频变更 → RAG
比如客服系统需每日同步最新政策、产品更新。RAG 只需增量更新向量库(甚至支持流式更新),无需重新训练。 - 需特定风格/格式 → 微调(或 LoRA)
例如法律咨询助手需输出“依据《XX法》第X条……”的固定结构,或企业内部 Bot 需使用“亲~”等客服语气。 - 两者兼有?→ RAG + LoRA
这是当前最推荐的混合方案:用 RAG 提供最新事实,用轻量微调(如 LoRA)控制输出风格,兼顾灵活性与一致性。
三、成本与工程复杂度对比
|
维度 |
RAG |
Fine-tuning |
|
开发周期 |
1–2 周(含向量化、检索优化) |
2–8 周(数据清洗、标注、训练、评估) |
|
GPU 成本 |
仅推理阶段(可 CPU 推理) |
训练阶段高消耗(需 A100/H100 等) |
|
维护成本 |
向量库运维、冷启动优化、缓存策略 |
模型版本管理、A/B 测试、回滚机制 |
|
知识更新延迟 |
分钟级(配合 Kafka + Flink 流处理) |
天级或周级(需重新训练) |
|
数据安全 |
知识库可本地化、权限控制 |
训练数据需完全脱敏,否则有泄露风险 |
特别提醒:微调一旦将敏感数据注入模型,即使删除原始数据,模型参数中仍可能残留信息,存在“记忆泄露”(Memorization)风险。而 RAG 的知识库可随时清空或加密,更安全。
四、真实场景示例:客服系统如何融合两者?
假设你正在构建一个金融客服问答系统,需求包括:
- 实时回答最新监管政策(每日更新)
- 输出格式必须为“【政策依据】+【简明解释】”
- 语气需专业、克制,避免“亲”“哈喽”等不合规表达
解决方案:RAG + LoRA 微调
- RAG 部分:
-
- 使用 Qwen/GLM 等本地 LLM + sqlite-vss(或轻量 Milvus)构建向量库
- 每日通过 ETL 将最新监管文件嵌入并更新索引
- 查询时检索 Top-3 相关片段作为上下文输入模型
- LoRA 微调部分:
-
- 在脱敏后的历史客服对话上,用 LoRA 微调模型输出风格
- 约束输出必须包含“【政策依据】”字段,避免自由发挥
- 微调仅需少量 GPU 资源(单卡 24G 显存即可),成本可控
这种混合架构已在多家银行、保险公司的智能客服中落地,既保证知识实时性,又满足合规输出格式要求。
五、给技术决策者的建议
- 优先考虑 RAG:除非有明确风格/格式需求,否则 RAG 应作为默认选项——它更灵活、更安全、更易迭代。
- 微调需谨慎评估数据合规性:任何包含用户数据、内部文档的微调,必须经过 PII 脱敏(如用 Presidio 或 spaCy 识别并掩码)。
- 拥抱混合架构:RAG + 轻量微调(LoRA/QLoRA)是当前性价比最高的方案,尤其适合边缘设备(如 iPhone 端侧 RAG + 小模型微调)。
- 建立评估机制:通过人工审核 + 自动指标(如答案相关性、格式合规率)持续监控两种方案效果,避免“技术选型一次性拍板”。
结语
RAG 与微调并非对立,而是互补。RAG 解决“知道什么”,微调解决“怎么表达”。在企业级 AI 落地中,真正的高手不是选择“非此即彼”,而是懂得“何时叠加、如何协同”。希望本文的决策框架能帮助你少走弯路,把有限的工程资源用在刀刃上。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)