【MHA/MQA/GQA 详解】
本文详细解析了三种注意力机制:多头注意力(MHA)、多查询注意力(MQA)和分组查询注意力(GQA)。核心区别在于如何分配注意力头数量,主要解决Transformer模型在推理阶段的显存占用和带宽瓶颈问题。MHA表达能力最强但显存占用高;MQA显存占用最小但性能损失较大;GQA作为折中方案,在保持接近MHA性能的同时大幅降低显存需求。现代大模型(如LLaMA-2/3)普遍采用GQA,因其能平衡推理
这是一篇关于 Self-Attention (MHA)、MQA (Multi-Query Attention) 和 GQA (Grouped-Query Attention) 的详细技术解析。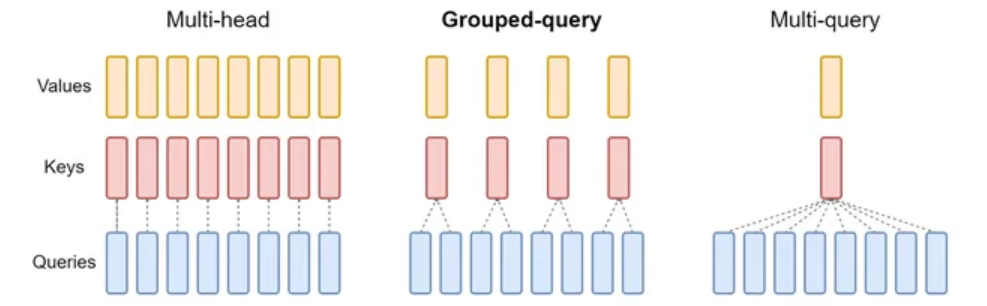
这三种机制的核心区别在于:如何分配 Query (Q)、Key (K) 和 Value (V) 的注意力头(Heads)数量。它们主要为了解决 Transformer 模型在推理(Inference)阶段的显存占用和带宽瓶颈问题。
1. Multi-Head Attention (MHA) —— 标准多头注意力
这是最初 Transformer (Vaswani et al., 2017) 提出的标准形式,也是 BERT、GPT-2 等早期模型的标配。
1.1 原理
在 MHA 中,输入序列被映射到 HHH 个不同的头。每个头都有自己独立的 Wq,Wk,WvW_q, W_k, W_vWq,Wk,Wv 权重矩阵。
这意味着:有多少个 Query 头,就有多少个 Key 和 Value 头。
- Query Heads (HqH_qHq): HHH 个
- Key Heads (HkH_kHk): HHH 个
- Value Heads (HvH_vHv): HHH 个
- 关系: Hq=Hk=Hv=HH_q = H_k = H_v = HHq=Hk=Hv=H
1.2 计算过程
假设 Batch Size 为 BBB,序列长度为 LLL,头数为 HHH,每个头的维度为 DDD。
- 生成 Q,K,VQ, K, VQ,K,V,形状均为 [B,H,L,D][B, H, L, D][B,H,L,D]。
- 每个头独立计算 Attention(Qi,Ki,Vi)Attention(Q_i, K_i, V_i)Attention(Qi,Ki,Vi)。
- 最后将所有头的结果拼接(Concat)并经过线性层输出。
1.3 优缺点
- 优点 (Pros):
- 表达能力最强:每个头可以独立关注输入序列的不同子空间(Subspace)特征,模型容量大,效果通常最好。
- 缺点 (Cons):
- 推理期 KV Cache 巨大:在生成式任务(如 GPT)中,为了加速,需要缓存过去 token 的 K 和 V。MHA 需要存储 HHH 组 K 和 V,显存占用极高。
- 内存带宽瓶颈 (Memory Bound):读取巨大的 KV Cache 需要消耗大量显存带宽,导致推理速度受限(尤其是长序列时)。
2. Multi-Query Attention (MQA) —— 多查询注意力
MQA 由 Shazeer 等人在 2019 年提出(Fast Transformer Decoding: One Write-Head is All You Need),旨在极致优化推理速度。
2.1 原理
MQA 保留了多个 Query 头,但所有的 Query 头共享同一组 Key 和 Value 头。
- Query Heads (HqH_qHq): HHH 个
- Key Heads (HkH_kHk): 1 个
- Value Heads (HvH_vHv): 1 个
- 关系: Hq=H,Hk=Hv=1H_q = H, \quad H_k = H_v = 1Hq=H,Hk=Hv=1
2.2 计算过程 (Broadcasting)
- QQQ 的形状为 [B,H,L,D][B, H, L, D][B,H,L,D]。
- K,VK, VK,V 的形状为 [B,1,L,D][B, 1, L, D][B,1,L,D]。
- 在计算 Attention Score 时,通过广播 (Broadcasting) 机制,将 KKK 和 VVV 复制(在逻辑上)HHH 次,使其与 QQQ 的头数匹配,进行计算。
2.3 优缺点
- 优点 (Pros):
- KV Cache 极小:显存占用减少为 MHA 的 1/H1/H1/H。
- 推理速度极快:需要从显存读取的数据量大幅减少,缓解了带宽压力,显著提升 Token 生成速度。
- 缺点 (Cons):
- 性能损失:由于所有头强行共享同一组 K 和 V,模型捕捉细节的能力下降,可能会导致困惑度(Perplexity)上升,生成质量不如 MHA。
- 训练不稳定:早期实验表明 MQA 较难训练收敛(但在现代 LLM 中通过微调已有改善,如 Falcon 模型)。
3. Grouped-Query Attention (GQA) —— 分组查询注意力
GQA 是 MHA 和 MQA 的折中方案,由 Google 在 2023 年提出(应用于 LLaMA 2、LLaMA 3 等现代主流大模型)。
3.1 原理
GQA 将 Query 头分成 GGG 个组(Group),每个组内的 Query 头共享同一组 Key 和 Value 头。
- Query Heads (HqH_qHq): HHH 个
- Groups (GGG): 1<G<H1 < G < H1<G<H (通常 HHH 能被 GGG 整除)
- Key Heads (HkH_kHk): GGG 个
- Value Heads (HvH_vHv): GGG 个
- 每组包含的 Query 头数: H/GH / GH/G
3.2 举例
假设模型有 H=8H=8H=8 个头。
- MHA: 8 个 Q,8 个 K,8 个 V。(1对1)
- MQA: 8 个 Q,1 个 K,1 个 V。(8对1)
- GQA (G=2): 分成 2 组。每组 4 个 Q 共享 1 个 K 和 1 个 V。总共 8 个 Q,2 个 K,2 个 V。(4对1)
3.3 优缺点
- 优点 (Pros):
- Sweet Spot (最佳平衡点):GQA 的显存占用和速度接近 MQA,但模型效果(Quality)非常接近 MHA。
- 灵活性:可以通过调整 GGG 的大小,在速度和质量之间权衡。
- 应用: LLaMA-2-70B, LLaMA-3 全系列, Mistral 等模型均采用 GQA。
4. 核心对比总结
假设模型参数:Hidden Size = 1024, Heads = 8, Head Dim = 128。
| 特性 | MHA (Multi-Head) | GQA (Grouped-Query) | MQA (Multi-Query) |
|---|---|---|---|
| Q 头数量 | 8 | 8 | 8 |
| K, V 头数量 | 8 | 2 (假设分组为2) | 1 |
| KV Cache 大小 | 100% (基准) | 25% (1/4) | 12.5% (1/8) |
| 推理速度 | 慢 (带宽受限) | 快 | 极快 |
| 模型质量 | ⭐⭐⭐⭐⭐ (最好) | ⭐⭐⭐⭐☆ (接近 MHA) | ⭐⭐⭐☆☆ (有损失) |
| 代表模型 | BERT, GPT-3, LLaMA-1 | LLaMA-2/3, Mistral | Falcon, StarCoder |
5. 代码层面的形状变换 (PyTorch 伪代码)
为了直观理解,我们看 Tensor 的形状变化:
# B: Batch, S: Seq Len, H: Num Heads, D: Head Dim
# H_kv: KV Heads count
# 1. MHA (H_q = H_kv = 8)
# Q: [B, 8, S, D]
# K: [B, 8, S, D]
# score = Q @ K.transpose(-2, -1) --> [B, 8, S, S] (直接匹配)
# 2. MQA (H_q = 8, H_kv = 1)
# Q: [B, 8, S, D]
# K: [B, 1, S, D]
# 需要 expand/repeat K
# K_expanded = K.expand(B, 8, S, D)
# score = Q @ K_expanded.transpose(-2, -1)
# 3. GQA (H_q = 8, H_kv = 2, Group_Size = 4)
# Q: [B, 8, S, D] -> reshape -> [B, 2, 4, S, D] (2组,每组4个头)
# K: [B, 2, 1, S, D] (2个KV头)
# score = (Q @ K.transpose) ... 在组内进行广播计算
6. 为什么现在流行 GQA?
在 LLM 时代,上下文窗口(Context Window)越来越长(从 4k 到 128k 甚至 1M)。
- 如果用 MHA,KV Cache 会大到显存装不下。例如 128k 长度的序列,KV Cache 可能比模型权重本身还大。
- 如果用 MQA,虽然省显存,但对于这种超大模型,智力(推理能力)下降是不可接受的。
- GQA 通过只保留少量的 KV 头(例如 8 个),既把显存占用压缩到了 MHA 的 1/8 左右,又保留了足够的“多视角”特征提取能力,因此成为当前大模型的事实标准。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)