AI论文整理:SENet(WMV 核心模型)- Squeeze-and-Excitation Networks
Squeeze-and-Excitation Networks(SENet)核心是Squeeze-and-Excitation(SE)块,该模块通过Squeeze操作(全局平均池化)聚合特征图的空间信息生成通道描述符,再经Excitation操作(双全连接层+Sigmoid激活)学习通道间依赖并生成自适应权重,最终通过Scale操作(权重与特征图逐通道相乘)实现通道特征重校准;SE块可灵活堆叠或替
论文标题:《Squeeze-and-Excitation Networks》
下载链接:https://arxiv.org/pdf/1709.01507.pdf
1. 一段话总结
Squeeze-and-Excitation Networks(SENet)核心是Squeeze-and-Excitation(SE)块,该模块通过Squeeze操作(全局平均池化) 聚合特征图的空间信息生成通道描述符,再经Excitation操作(双全连接层+Sigmoid激活) 学习通道间依赖并生成自适应权重,最终通过Scale操作(权重与特征图逐通道相乘) 实现通道特征重校准;SE块可灵活堆叠或替换现有CNN(如ResNet、Inception)的模块,在轻微计算成本增加(如SE-ResNet-50比ResNet-50仅多0.26% GFLOPs)下显著提升模型表征能力,其在ILSVRC 2017图像分类竞赛中获冠军,top-5误差降至2.251%(相对2016年冠军提升约25%),且在ImageNet、CIFAR、COCO、Places365等数据集及图像分类、目标检测、场景识别任务中均验证了通用性。
2. 思维导图(mindmap)
## 一、研究背景与目标
- 1. CNN核心:卷积融合空间+通道信息
- 2. 现有研究:侧重优化空间相关性(如Inception、空间注意力)
- 3. 本文目标:聚焦**通道间依赖**,通过SE块提升特征表征能力
## 二、SE块核心结构
- 1. Squeeze操作
- 机制:全局平均池化(聚合H×W空间维度)
- 输出:通道描述符Z(维度C)
- 公式:z_c = (1/(H×W))×∑(i=1到H)∑(j=1到W) u_c(i,j)
- 2. Excitation操作
- 机制:双FC层(降维比r→ReLU→升维)+ Sigmoid
- 输出:通道权重s(维度C)
- 关键:学习非线性通道依赖,允许多通道同时被强调
- 3. Scale操作
- 机制:权重s与特征图U逐通道相乘
- 输出:重校准特征图X̃(维度H×W×C)
## 三、SENet架构设计
- 1. 构建方式
- 堆叠SE块
- 替换现有CNN模块(如ResNet残差分支、Inception模块)
- 2. 典型实例
- SE-ResNet:SE块作用于残差分支(图3)
- SE-Inception:SE块作用于整个Inception模块(图2)
- SE-ResNeXt、SE-MobileNet、SE-ShuffleNet
- 3. 层间差异
- 早期层:类无关响应,增强共享低维特征
- 后期层:类特异性响应,适配任务需求
## 四、模型复杂度分析
- 1. 计算量:SE-ResNet-50(3.87 GFLOPs)vs ResNet-50(3.86 GFLOPs),增加0.26%
- 2. 参数:SE-ResNet-50多250万参数(总2810万),占比~10%(移除末层SE块可降至~4%)
- 3. 推理时间
- GPU(8 Titan X):SE-ResNet-50(209ms)vs ResNet-50(190ms)
- CPU:SE-ResNet-50(167ms)vs ResNet-50(164ms)
## 五、实验验证(关键结果)
- 1. 图像分类(ImageNet)
- SE-ResNet-50:top-5误差6.62%(原ResNet-50为7.48%)
- SE-ResNeXt-50:top-5误差5.49%(原ResNeXt-50为5.90%)
- SE-MobileNet:top-1误差25.3%(原MobileNet为28.4%)
- 2. 小样本分类(CIFAR-10/100)
- SE-ResNet-110:CIFAR-10误差5.21%(原6.37%),CIFAR-100误差23.85%(原26.88%)
- 3. 目标检测(COCO)
- SE-ResNet-50:AP 40.4(原ResNet-50为38.0),提升2.4%
- 4. 场景识别(Places365)
- SE-ResNet-152:top-5误差11.01%(原ResNet-152为11.61%)
- 5. 竞赛成绩(ILSVRC 2017)
- 冠军:top-5误差2.251%,相对2016年提升~25%
## 六、消融实验结论
- 1. 降维比r:r=16时性能(top-5误差6.03%)与复杂度平衡最优
- 2. Squeeze操作:全局平均池化(top-5误差6.03%)略优于最大池化(6.09%)
- 3. Excitation非线性:Sigmoid最优(6.03%),Tanh次之(6.38%),ReLU最差(6.98%)
- 4. SE块位置:PRE/Identity/标准设计优(top-5误差~6.00%),POST设计差(6.35%)
## 七、SE块作用机制
- 1. Squeeze:全局信息嵌入是关键,无Squeeze(NoSqueeze)时top-5误差升至6.39%
- 2. Excitation:层越深响应越类特异性,末层(SE_5_2/SE_5_3)作用减弱(可移除降参)
## 八、结论与意义
- 1. 提升CNN表征能力,兼容多架构/多任务
- 2. 为模型压缩(如通道剪枝)提供特征重要性依据
- 3. 启发通道注意力机制后续研究(如CBAM)
3. 详细总结
一、研究背景与核心动机
- CNN的固有局限:卷积操作虽融合空间与通道信息,但通道间的依赖关系是隐式且局部的(仅依赖卷积核 receptive field),现有研究多聚焦空间相关性优化(如Inception的多尺度融合、空间注意力机制),忽略通道维度的动态校准。
- 核心目标:提出SE块,通过显式建模通道间依赖,实现自适应特征重校准——增强有用特征通道、抑制冗余通道,进而提升CNN的表征能力。
二、SE块(Squeeze-and-Excitation Block)细节
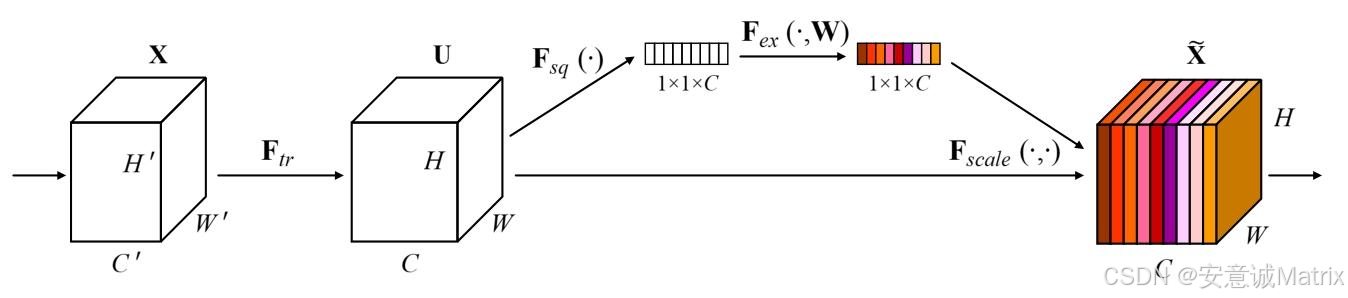
SE块以任意卷积变换FtrF_{tr}Ftr为基础(输入X∈RH′×W′×C′X \in \mathbb{R}^{H' \times W' \times C'}X∈RH′×W′×C′,输出特征图U∈RH×W×CU \in \mathbb{R}^{H \times W \times C}U∈RH×W×C),通过“信息聚合-权重学习-特征校准”三步实现通道级优化,具体细节如下:
1. Squeeze(全局信息嵌入)
- 核心机制:通过全局平均池化(Global Average Pooling) 消除特征图的空间维度((H \times W)),将每个通道的空间信息聚合为1个全局统计量,生成通道级描述符(Z \in \mathbb{R}^C)((C)为通道数)。
- 数学公式(对应文档式(2)):
zc=Fsq(uc)=1H×W∑i=1H∑j=1Wuc(i,j)z_c = F_{sq}(u_c) = \frac{1}{H \times W} \sum_{i=1}^H \sum_{j=1}^W u_c(i,j)zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
其中,(u_c(i,j))表示特征图(U)第(c)个通道在空间位置((i,j))处的像素值,(z_c)为第(c)个通道的全局均值统计量。 - 核心目的:突破传统卷积“局部感受野局限”,让每个通道都能获取网络的全局 receptive field 信息,为后续通道权重学习提供全局上下文。
2. Excitation(自适应通道权重学习)
- 核心机制:设计轻量级门控模块,通过“降维-非线性激活-升维”流程,显式学习通道间的非线性依赖关系,最终输出与通道数匹配的自适应权重(s \in \mathbb{R}^C)(权重范围([0,1]),实现“增强有用通道、抑制冗余通道”)。具体步骤:
- 降维:通过全连接层(FC_1)将通道描述符(Z)的维度从(C)降至(C/r)((r)为降维比,默认(r=16)),减少计算复杂度;
- 非线性激活:使用ReLU函数引入非线性,捕捉通道间复杂依赖;
- 升维:通过全连接层(FC_2)将维度从(C/r)升回(C),恢复通道维度;
- 权重输出:使用Sigmoid激活函数,将输出映射到([0,1])区间,得到通道权重(s)。
- 关键要求:需满足两点——① 非线性:通过ReLU和Sigmoid捕捉通道间非简单线性的依赖;② 非互斥性:Sigmoid输出避免“one-hot”激活,允许多个通道同时被强调(区别于传统注意力的“单通道聚焦”)。
- 文档依据:消融实验显示(Table 12),Sigmoid是最优激活选择(top-5误差6.03%),Tanh次之(6.38%),ReLU最差(6.98%,因无法抑制冗余通道)。
3. Scale(特征重校准)
- 核心机制:将Excitation输出的通道权重(s)与原特征图(U)进行逐通道相乘,用权重对每个通道的特征进行“缩放”——权重接近1的通道被增强,接近0的通道被抑制,生成重校准后的特征图(\tilde{X})。
- 数学公式(对应文档式(4)):
x~c=Fscale(uc,sc)=sc⋅uc\tilde{x}_c = F_{scale}(u_c, s_c) = s_c \cdot u_cx~c=Fscale(uc,sc)=sc⋅uc
其中,(\tilde{x}_c)表示重校准后第(c)个通道的特征图,(\tilde{X} = [\tilde{x}_1, \tilde{x}_2, …, \tilde{x}_C])为SE块的最终输出,可直接输入网络后续层。 - 核心作用:实现“动态特征校准”——权重随输入图像内容变化,而非固定(传统卷积权重由核参数决定),让网络能根据具体图像的特征重要性“按需分配计算资源”。
三、SENet架构与实例
- 构建方式:
- 直接堆叠SE块;
- 作为“即插即用”模块,替换现有CNN的核心单元(如ResNet的残差分支、Inception的模块)。
- 典型实例(Table 1展示核心配置):
-
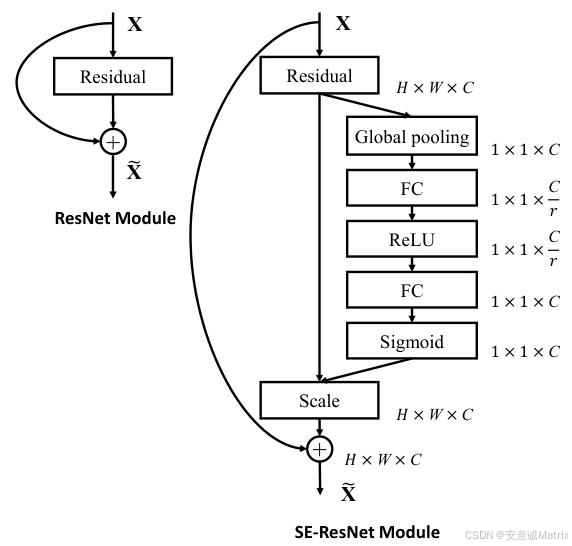
SE-ResNet:SE块作用于ResNet的非恒等残差分支,在残差相加前完成重校准(图3);
-
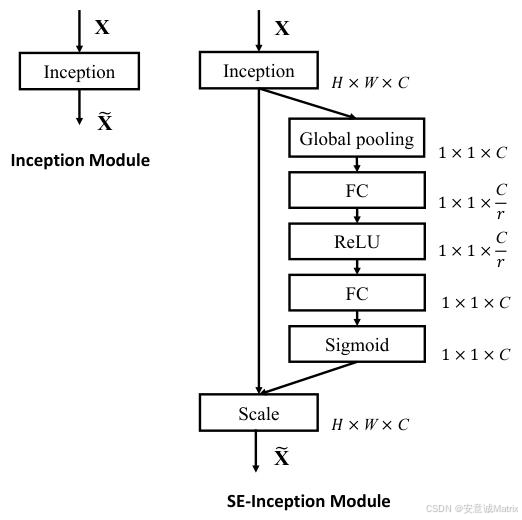
SE-Inception:SE块作用于整个Inception模块,输出端完成重校准(图2);
-
其他:SE-ResNeXt、SE-MobileNet、SE-ShuffleNet(均通过类似方式集成)。
-
- 层间功能差异:
- 早期层(如Stage 2):SE块生成类无关响应,强化边缘、纹理等共享低维特征;
- 后期层(如Stage 4):SE块生成类特异性响应,适配具体任务的判别性特征;
- 末层(如SE_5_2/SE_5_3):权重趋近于1,作用减弱(移除后仅损失<0.1% top-5误差,可降低参数~6%)。
四、模型复杂度分析(以ResNet-50 vs SE-ResNet-50为例)
| 指标 | ResNet-50 | SE-ResNet-50 | 变化幅度 |
|---|---|---|---|
| 计算量(GFLOPs) | 3.86 | 3.87 | +0.26% |
| 参数数量(M) | 25.6 | 28.1 | +2.5M(+~10%) |
| GPU推理时间(ms) | 190(batch=256) | 209(batch=256) | +19ms |
| CPU推理时间(ms) | 164(224×224) | 167(224×224) | +3ms |
- 结论:SE块引入的计算与参数开销极小,是“轻量高效”的优化模块。
五、实验验证(多任务+多数据集)
1. 图像分类任务
- 数据集:ImageNet(128万训练图,5万验证图,1000类)、CIFAR-10/100(32×32图像,10/100类)。
- 关键结果(ImageNet单裁剪验证误差,Table 2/3):
模型 原模型top-5误差(%) SE模型top-5误差(%) 提升幅度(%) ResNet-50 7.48 6.62 0.86 ResNeXt-50 5.90 5.49 0.41 VGG-16(带BN) 8.81 7.70 1.11 MobileNet 9.40 7.70 1.70 - CIFAR结果(Table 4/5):SE-ResNet-110在CIFAR-10误差5.21%(原6.37%),CIFAR-100误差23.85%(原26.88%),验证小样本场景有效性。
2. 目标检测任务
- 数据集:COCO(8万训练+3.5万验证,80类),采用Faster R-CNN框架。
- 关键结果(Table 7):
骨干网络 AP@IoU=0.5(%) AP(%) 提升幅度(AP) ResNet-50 57.9 38.0 - SE-ResNet-50 61.0 40.4 +2.4 ResNet-101 60.1 39.9 - SE-ResNet-101 62.7 41.9 +2.0
3. 场景识别任务
- 数据集:Places365(800万训练图,3.65万验证图,365类)。
- 关键结果(Table 6):SE-ResNet-152 top-5误差11.01%(原ResNet-152为11.61%),超越此前SOTA模型Places-365-CNN(11.48%)。
4. 竞赛成绩(ILSVRC 2017)
- SENet作为竞赛提交基础,通过模型集成(多尺度+多裁剪融合),在ImageNet测试集实现top-5误差2.251%,相对2016年冠军(2.991%)提升约25%,获分类任务冠军。
六、消融实验(关键发现)
1. 降维比r的影响(Table 10)
- 目的:平衡性能与参数复杂度。
- 结果:r=16时最优(top-5误差6.03%,参数28.1M);r<16时参数激增(r=2时45.7M),r>16时性能下降(r=32时top-5误差6.20%)。
2. Squeeze操作的选择(Table 11)
- 对比:全局平均池化 vs 全局最大池化。
- 结果:平均池化略优(top-5误差6.03% vs 6.09%),但两者均有效,说明Squeeze的核心是“全局信息聚合”而非具体池化方式。
3. Excitation非线性的选择(Table 12)
- 对比:Sigmoid vs Tanh vs ReLU。
- 结果:Sigmoid最优(6.03%),Tanh次之(6.38%),ReLU最差(6.98%,甚至低于原ResNet-50的6.55%);原因是ReLU会输出非负权重,无法“抑制”冗余通道。
4. SE块集成位置的影响(Table 14/15)
- 对比:标准SE(残差分支内)、SE-PRE(残差单元前)、SE-POST(残差相加后)、SE-Identity(恒等分支上)、SE-3×3(3×3卷积后)。
- 结果:SE-PRE(6.00%)、标准SE(6.03%)、SE-Identity(6.15%)性能接近;SE-POST(6.35%)性能下降;SE-3×3(6.02%)参数更少(25.8M),性价比更高。
七、SE块的核心作用
- Squeeze的必要性:对比“SE块”与“NoSqueeze块”(用1×1卷积替代全局池化,仅局部信息),前者top-5误差6.03%,后者6.39%(Table 16);说明全局信息嵌入是提升性能的关键。
- Excitation的动态性:
- 早期层:不同类别激活分布相似(类无关),强化通用特征;
- 后期层:不同类别激活分布差异显著(类特异性),聚焦判别特征;
- 实例内差异:同一类别的不同图像,激活权重也存在动态调整(图7),适配图像细节。
八、结论与意义
- 性能优势:SE块在极小开销下,显著提升CNN在分类、检测、场景识别等任务的性能,兼容ResNet、Inception、MobileNet等多种架构。
- 理论价值:首次系统性地将“通道注意力”作为独立模块融入CNN,为后续通道注意力研究(如CBAM、ECA-Net)奠定基础。
- 实用价值:SE块的“特征重要性权重”可用于模型压缩(如剪枝冗余通道),且适配移动端(SE-MobileNet/ShuffleNet性能提升显著)。
4. 关键问题
问题1:SE块的核心工作机制是什么?其相比传统CNN模块,在特征处理上的核心突破是什么?
答案:
SE块通过“三步机制”实现通道特征重校准:① Squeeze(全局平均池化):聚合特征图的空间信息,生成通道级全局描述符,解决传统卷积“局部信息局限”问题;② Excitation(双FC+Sigmoid):学习通道间非线性依赖,生成自适应权重,突破传统卷积“通道依赖隐式化”的局限;③ Scale(逐通道相乘):用权重增强有用通道、抑制冗余通道,实现动态特征优化。
核心突破:传统CNN的通道交互依赖卷积核的局部感受野,且通道权重固定(由卷积核参数决定);SE块通过显式建模全局通道依赖,让通道权重随输入图像动态调整,既能利用全局信息,又能针对性优化特征通道,实现“按需分配特征重要性”。
问题2:论文通过哪些关键实验验证了SENet的“通用性”?请列举至少3个不同任务场景、对应数据集及核心性能提升数据。
答案:
SENet的通用性通过“多任务+多数据集”验证,关键场景如下:
- 图像分类(小样本场景):数据集CIFAR-10/100;SE-ResNet-110在CIFAR-10的分类误差从6.37%降至5.21%(-1.16%),CIFAR-100从26.88%降至23.85%(-3.03%),验证小样本场景有效性。
- 目标检测:数据集COCO minival;以SE-ResNet-50为Faster R-CNN骨干网络,AP(平均精度)从38.0提升至40.4(+2.4%),AP@IoU=0.5从57.9提升至61.0(+3.1%),验证检测任务适配性。
- 场景识别:数据集Places365;SE-ResNet-152的top-5误差从11.61%降至11.01%(-0.6%),且超越此前SOTA模型Places-365-CNN(11.48%),验证复杂场景理解能力。
- 移动端架构优化:数据集ImageNet;SE-MobileNet的top-1误差从28.4%降至25.3%(-3.1%),仅增加3 MFLOPs计算量,验证移动端兼容性。
问题3:消融实验中关于“SE块集成位置”的结论,对实际工程中集成SE块有何指导意义?如何在“性能”与“参数效率”间平衡?
答案:
-
集成位置的指导意义:
消融实验表明(Table 14/15):① SE块集成在“残差单元前(SE-PRE)”“残差分支内(标准SE)”或“恒等分支上(SE-Identity)”时性能接近(top-5误差~6.00%);② 集成在“残差相加后(SE-POST)”时性能下降(6.35%),原因是残差相加后特征已融合,再校准效果减弱;③ 集成在“3×3卷积后(SE-3×3)”时,性能与标准SE接近(6.02%),但参数更少(25.8M vs 28.1M)。
工程指导:实际集成时无需严格遵循“标准位置”,可根据架构灵活调整(如移动端优先选SE-3×3),但需避免在“特征融合后”集成。 -
性能与参数效率的平衡策略:
① 降维比r选择:优先选r=16(性能最优且参数适中),若参数受限可适当增大r(如r=32,参数减少但性能仅轻微下降);② 末层SE块移除:网络末层(如ResNet-50的Stage 5)SE块作用减弱,移除后仅损失<0.1% top-5误差,参数占比从10%降至4%;③ 轻量化集成位置:优先选择“SE-3×3”等与低通道层结合的位置,在保证性能的同时减少参数(如SE-3×3比标准SE少2.3M参数)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)