上下文工程的前世今生,一场关于理解的漫长修补
2025年Shopify的CEO Tobi Lütke和AI专家Andrej Karpathy在X上提出了"context engineering" over "prompt engineering".这一新概念。Karpathy解释道,它是一门微妙的艺术与科学,目标是提供恰到好处的信息,为AI下一步推理做准备。乍一听,这和提示词工程似乎差不多,但实际上,它的视野要更宏大,它不只是让AI理解一句话
2025年Shopify的CEO Tobi Lütke和AI专家Andrej Karpathy在X上提出了"context engineering" over "prompt engineering".这一新概念。Karpathy解释道,它是一门微妙的艺术与科学,目标是提供恰到好处的信息,为AI下一步推理做准备。
乍一听,这和提示词工程似乎差不多,但实际上,它的视野要更宏大,它不只是让AI理解一句话,而是系统化地让机器理解复杂、分散、甚至模糊的人类信息。前不久,上海交通大学和GAIR实验室的论文《上下文工程2.0:上下文工程的上下文》 进一步把这一概念完善,他们提出,上下文工程不仅是技巧,而是交流动力学的基础逻辑:人与机器之间的理解鸿沟,本质上是信息熵的差异。

接触这篇论文的时候,我的第一反应并不是又一个新概念来了,反而有点似曾相识的感觉。作者明明在谈的是上下文工程2.0,但读着读着,你会发现它其实对准的是一个更古老的问题——机器到底要怎样才能真正理解人?
人类的交流从来不是一句话、一条指令那么简单。我们说话有弦外之音,有潜台词,有历史背景,有今天早上刚发生的小情绪。论文引用了马克思的一句话,说人是社会关系的集合体,其实这句话放到机器身上同样成立。一个 AI 想理解你,光看你今天说的一句话是不够的,它得知道你之前经历了什么、现在处在什么状态、你打算往哪走。
过去因为机器笨,我们人必须迁就它。所以才有了按钮、图标、菜单、编程语言。这些东西不是为了方便人,而是为了让机器少出错——这是最早的上下文工程。只是那时候没人这样叫它。
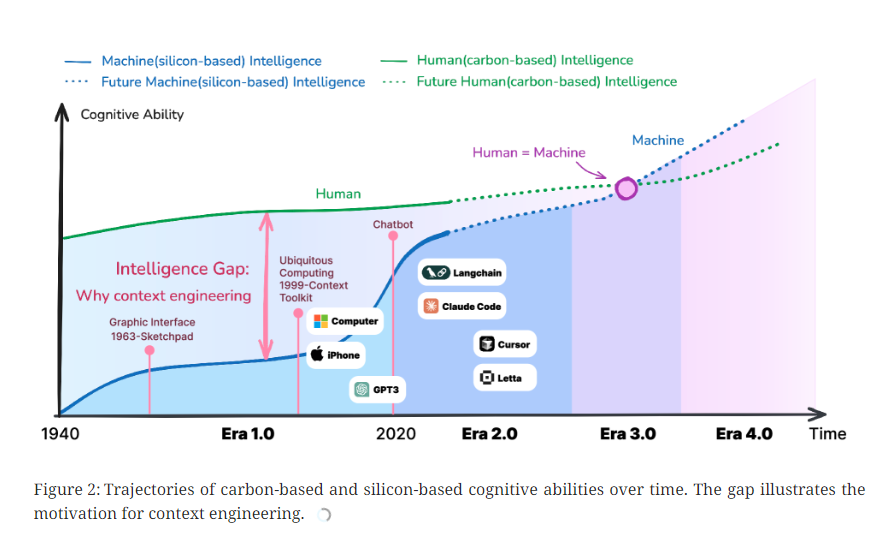
等到大模型时代到了,表面上看,人与机器之间好像终于能够直接对话了。你说一句,它回一句,好像一切都简单了。可一用就知道,简化的只是外壳。深层的问题一点没少。机器依旧难以理解真正的语境,只不过这次它看起来好像懂,反而更危险。
论文对这种错觉戳得很直接,人类的表达天然是高熵的,乱七八糟、信息丰富、充满隐含关系;而大模型本质上仍是低熵系统,它只能接受明确的输入。两者差得太远了,信息鸿沟无法靠几条提示词填平。
正是在这个背景下,上下文工程的概念才逐渐清晰起来。它不再是写点提示词的小技巧,而是试图重新搭建人与机器之间的理解桥梁,让高熵的人类世界可以被低熵的模型尽可能接住。论文把这件事拆成了收集、管理、使用三个部分,结构听起来很学术,但内容其实贴近我们每天遇到的尴尬。
AI为什么总是抓不到重点?
论文先从模型的四个硬伤讲起,这四点读起来特别有现实感。这四个缺陷叠加起来,就构成了为什么大模型听不懂你的全部答案。
最明显的一点,是模型的感官缺失。它看到的世界只有输入窗口那一小截。如果你今天心情不好,它不会知道;如果你说话带一点隐晦,它也不会理解。对人来说这是基本常识,对机器却是巨大的盲区。
第二个问题是理解力有限。模型对复杂结构、场景、多人交互还是很吃力。你给它发一张图,让它总结图里发生了什么,它能描述出物体,却不一定能理解关系。而关系恰恰是我们最依赖的东西。
第三个问题是记忆。哪怕模型的上下文窗口越来越大,它依然记不住长期信息。和人类那种同事之间积累多年的默契相比,它能存储的东西仍旧是断裂的。
最后一个问题是注意力涣散。这点特别有趣。人能自然判断什么重要、什么无关,而模型面对长文本时却容易被没用的内容吸引,真正关键的地方反而忽略掉。
上下文工程真正做的事情是什么?
为了弥补这些缺陷,论文提出了一个完整框架,从收集、管理到使用,用一种更工程化的方式告诉我们,要让模型理解,就得先帮它把基础设施搭好。
收集阶段做的是补足感官缺失。模型看不到的东西,我们通过记录、传感器、多模态输入、日志、文件结构等方式帮它补上。就像替它打开窗户,让它能看到一个更真实的用户。
管理阶段针对的是理解与记忆的问题。人类的大脑天生有能力把杂乱的信息整理成结构化的知识,而模型却不行。它需要有人给它搭脚手架,告诉它哪些是背景、哪些是事实、哪些需要存档、哪些必须建成更持久的知识。
使用阶段则是帮助模型解决注意力涣散。它不应该把输入当成一锅粥,而是学会选重点,学会推理的顺序,学会从已有知识中调用信息,而不是硬吞所有内容。
一旦这三个环节串起来,模型呈现出来的就不再是回答问题,而是理解你想干什么,这两者之间差得非常远。

技术案例背后的现实意义
论文里提到的Gemini CLI、DeepResearch、Remember AI这些案例,看似很技术,其实背后的逻辑都一样,让模型不再每次都从零开始,而是具备一种持续存在的自我。
Gemini CLI那个 GMI 文件表面上只是一个项目配置文档,但它承担的角色更像是给模型写一本属于这个项目的常识。只要它存在,模型在项目中做事就不会迷路,也不会忘记进展。它不再是一问一答,而是参与一个长周期的任务。
DeepResearch更极端,它几乎在模拟人类研究者的工作方式,搜索、提问、整合、反推、再次验证。它通过不断压缩和重写自己的上下文,把短期信息迁移成长期知识。这就是管理阶段最理想的形态。
看到这些例子,你会发现上下文工程不是抽象的理论,而是正在发生的事实。论文虽然技术味很浓,但处处都在提醒读者一件事,今天的AI看起来聪明,但其实只是看起来。
它的回答之所以流畅,是因为模型学会了模仿语言的表面形式,而不是理解背后的结构。它不会在信息不全时主动找补,也不会在逻辑模糊时停下来澄清。
所以上下文工程的出现并不是锦上添花,而是给AI补课,让它具备最基本的理解能力。如果没有这些脚手架,它就只能停留在一问一答的机械模式里,看似聪明,实则脆弱。
向前走会发生什么?
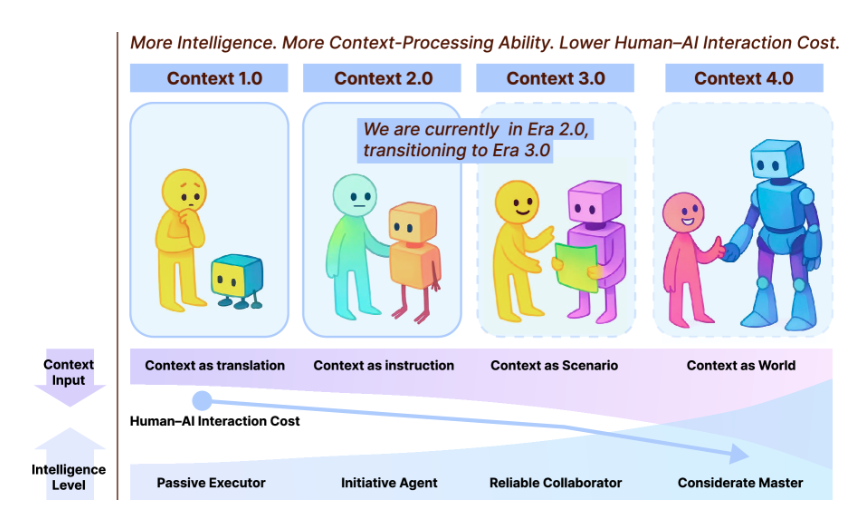
论文把未来分成了几个阶段。早期的人机交互是命令式的,到了现在进入人-代理模式,而未来更可能进入一种意图级交互。
当模型能真正抓住用户长期的习惯、偏好、动机,交流会越来越像人与人之间的协作,而不是指令执行。最远的未来,论文甚至提到上下文熵可能会降到几乎为零,也就是说,机器能在极少提示下就明白你想干什么。这听上去很科幻,但如果上下文工程继续发展下去,它也许真的会变成AI世界的基础设施,像今天的注意力机制一样,从外挂变成体系本身。
这篇论文给我的最大启发,不在技术,而在态度。AI看起来越来越像人,但与其把它当成会思考的生命体,不如把它当成还没长全的大脑。它需要感官、记忆、结构化知识、长期背景、注意力系统,而所有这些都不是凭空生长出来的。
上下文工程做的,就是在模型稚嫩的地方铺路,把缺失的能力补上,让它有机会看得更远、理解得更深。真正的智能不会从提示词里长出来,也不会从模型大小中溢出来。它来自人与机器共同搭建的理解结构。而上下文工程,就是这座结构最早的脚手架。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)