windows11配置LocalAI,解决curl unable to get local issuer certificate问题
本文介绍了LocalAI开源项目的部署过程和使用体验。LocalAI是一个兼容OpenAI API的本地AI推理平台,支持多种模型和消费级硬件。作者详细记录了在Windows11+NVIDIA显卡环境下通过Docker部署的过程,包括解决证书验证、后端加载等技术难点。实际测试发现,该平台虽然功能强大(支持LLM、TTS、SD等),但对硬件要求较高,在16G内存和RTX4060显卡配置下模型加载缓慢
“LocalAI 是免费的开源 OpenAI 替代品。它是一个与 OpenAI(包括 Elevenlabs、Anthropic 等)API 规范兼容的本地 AI 推理的即插即用替代 REST API。它允许您在本地或本地服务器上使用消费级硬件运行大型语言模型、生成图像、音频(等等),支持多个模型系列。无需 GPU。”
这是localAi项目说明https://github.com/mudler/LocalAI,它不仅支持LLMg还支持TTS,SD和Reranker。我之所以尝试这个模型部署平台,主要是其所说“消费级硬件硬件”需求和支持reranker。在经过1天的尝试后,我将部署过程中遇到的问题梳理一下,以供大家参考。
一、安装LocalAi
如果电脑是windows11+nvidia显卡,则建议直接使用docker部署NVIDIA GPU Images。
# CUDA 12.0
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12
# CUDA 11.7
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-11我的电脑nvidia系统软件及驱动配置如下:
nvidia-smi输出:NVIDIA GeForce RTX 4060,CUDA Version: 12.9, Driver Version: 577.03。
因此使用上述CUDA 12.0的docker镜像部署。
同时为了解决git、curl的证书验证问题和huggingface镜像,我创建了一个.env文件,将以下环境变量加入其中:
HF_ENDPOINT=https://hf-mirror.com
CURL_SSL_NO_VERIFY=1
GIT_SSL_NO_VERIFY=1同时在我的工作目录中创建一个models目录,映射到localai项目的models目录,以便我管理已经下载的模型文件。
我的docker部署命令如下:
docker run -ti --name local-ai -p 8080:8080 -v D:\AiTools\lmstudio\models:/models --env-file .env --gpus all localai/localai:latest-gpu-nvidia-cuda-12
运行上述使命后,docker下载了4.96GB的镜像,并加载名称为local-ai的容器。
打开docker desktop软件,查看local-ai容器的运行log,会发现大量类似如下的警告提示:
12:22PM WRN Failed to read system backends, proceeding with user-managed backends error="open /usr/share/localai/backends: no such file or directory"
12:22PM INF Using forced capability run file () capability="nvidia\n" capabilityRunFile=/run/localai/capability这是因为nvidia镜像没有直接安装llama-cpp、reranker等的后端即backend,localai运行时将自动下载安装llama-cpp、cuda-llama-cpp后端。localai本身没有加载不同模型的能力,它是通过这些后端加载这些模型后,利用backend.proto文件定义的gRPC服务接口实现信息互通和集成。没有backend,localai无法发挥其功能。
二、下载backend和模型
local-ai容器成功运行后,会在docker desktop的log中展示容器中nvidia-smi运行结果和如下提示:
LocalAI API is listening! Please connect to the endpoint for API documentation. endpoint=http://0.0.0.0:8080现在我们用浏览器打开localhost:8080地址,你将看到localai的主页面,初始页面上Installed Models和Installed Backends列表都是空的,现在先点击“Backends"标签,下载需要的backend,如果你在打开Backends页面时,在页面的下方显示”No models found matching your criteria“,那么,恭喜,你遇到了和我一样的问题,这篇文章能够帮上你的忙。
造成”No models found matching your criteria“的原因,是curl下载时证书验证出错。
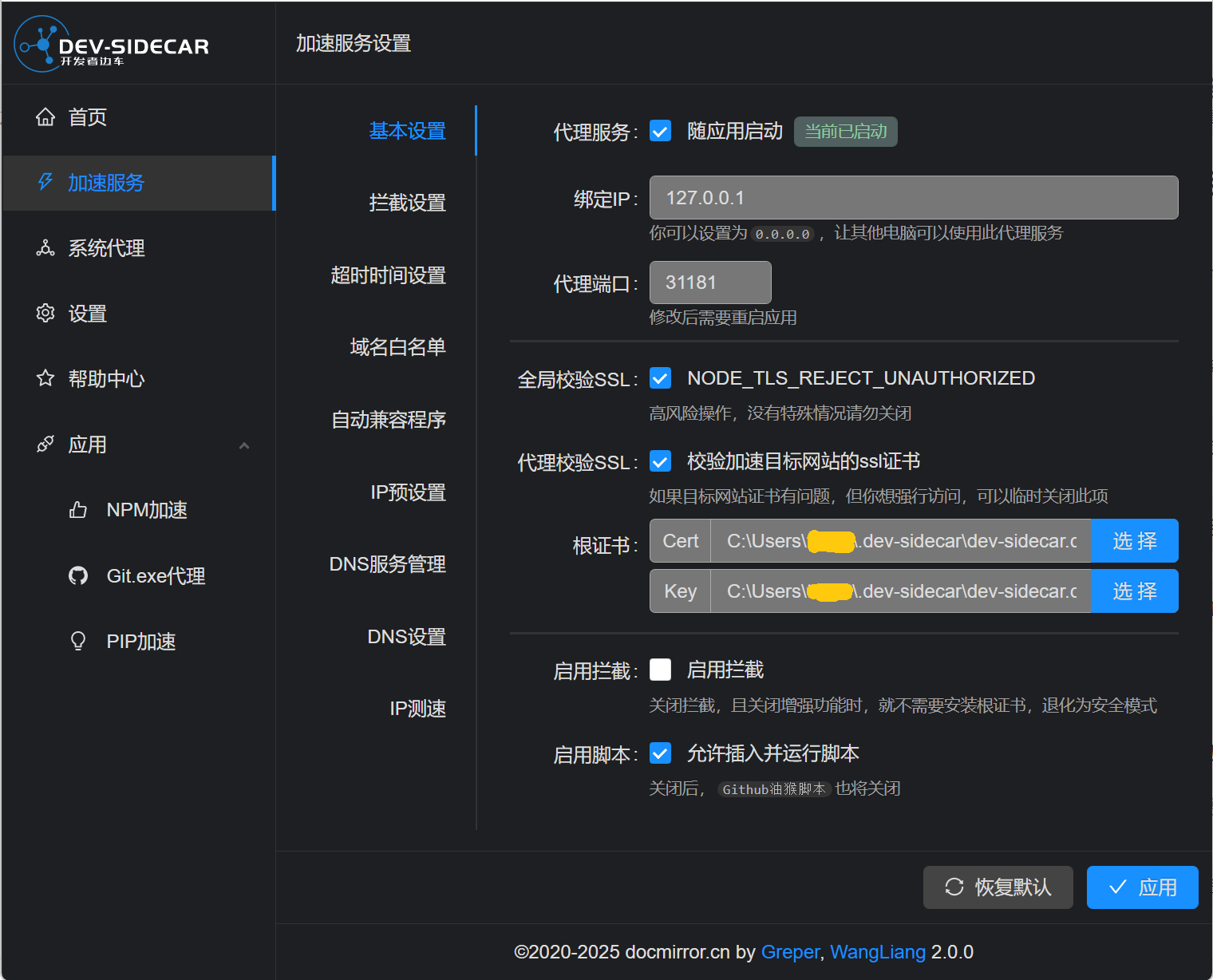
打开Backends页面时,localai会使用curl获取https://raw.githubusercontent.com/mudler/LocalAI/master/backend/index.yaml文件内容,由于我使用dev-sidecar(开发者边车docmirror/dev-sidecar: 开发者边车,github打不开,github加速,git clone加速,git release下载加速,stackoverflow加速)作为访问github的代理工具,在loacal-ai容器中如果没有安装这个软件证书,则会引发curl: (60) SSL certificate problem: unable to get local issuer certificate错误。我在前述的.env中已经通过设置环境变量禁用了git和curl的验证,但没有效果。而当在local-ai容器的bash窗口中,将dev-sidecar软件安装目录中的dev-sidecar.ca.crt文件,复制到local-ai容器的/usr/local/share/ca-certificates目录下,并运行update-ca-certificates命令后,再次运行如下命令成功:
curl -v https://raw.githubusercontent.com/mudler/LocalAI/master/backend/index.yaml此时,刷新Backends页面,页面下方会出现backend列表,你选择需要的backend下载就好。下载的backend会被保存在容器中的/backends目录中,其在docker中是单独放在一个数据卷中,可在docker desktop的卷列表中点击查看。
在模型仓库页面,其会下载https://raw.githubusercontent.com/mudler/LocalAI/master/gallery/index.yaml内容,如果不解决curl的证书问题,也会无法加载模型列表。
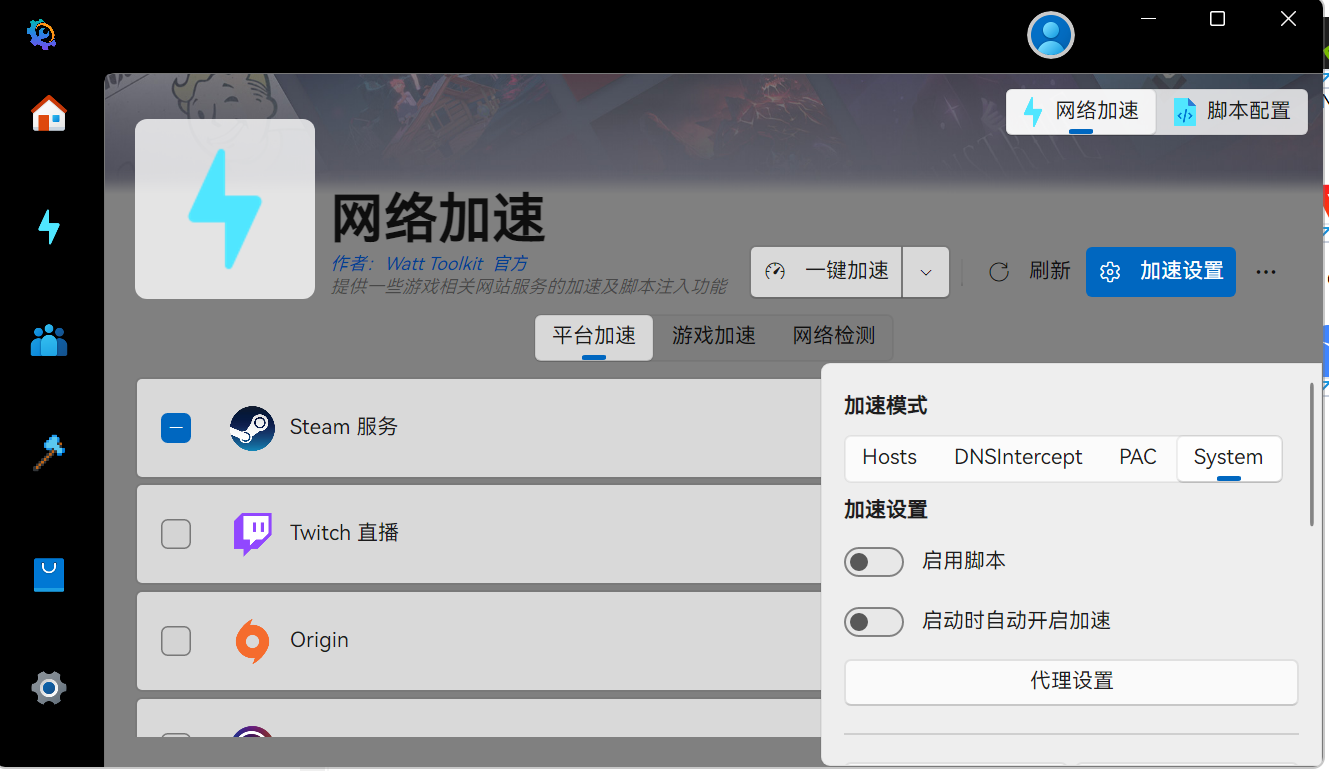
另外,在安装了dev-sidecar.ca.crt证书后,还可能无法加载模型仓库和后端仓库,对于dev-sidecar软件,可以使用其”安装模式“,对于Steam++,则需要使用system加速模式。
dev-sidecar.ca.crt证书位置如下图:
Steam++ system加速如下图:
三、使用模型和后端
在localai的说明文档中,通过模型仓库下载的模型会自动匹配计算机配置的后端,而我的本地计算机上已经通过ollama和lmstudio下载了多个LLM模型,我想将已经下载的llm模型导入到localai中。
按照localai的指导编写yaml文件,但是加载模型时均不能成功。无奈下,我尝试下载了仓库中的模型galatolo-Q4_K.gguf。经试运行,因为我的电脑是16G RAM和nvidia 4060/8G显存,加载该模型过程极其缓慢,chat对话之间的等待时间超这2分钟。而我在llmstuio、ollama和SillyTavern中加载qwen14B_q4_k_m模型,对话响应时间均不超过1分钟。另外还有一个明显的问题:当我加载一个模型后,再加载另外一个模型时,前一个模型占用的gpu显存并不能被释放,在我持续变更三个模型后,我的显存占用已经达到14G。这可能是我没有精准设置localai参数,但对于初用者来讲,显存释放确实是比较难解决的问题。
从整体功能而言,localai功能非常强大,尤其兼顾LLM、TTS、SD、Reranker,这是很多本地部署平台没有的能力,对于电脑性能较好或者小型的开发团队和企业来讲,localai应该是非常好的选择,但是对于电脑硬件一般的人来讲,使用localai可能需要重新考虑预算。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)