【论文精读】Clarify When Necessary: Resolving Ambiguity Through Interaction with LMs
本文提出一个任务无关的评估框架,解决交互式AI助手在人机交互中的消歧问题。核心挑战在于如何确定何时需要与用户交互以澄清模糊请求。作者将模糊性量化为用户意图的熵,提出意图-SIM(intent-SIM)方法,通过模拟用户交互估算熵值来判断是否需要澄清。实验表明,该方法在识别需澄清的错误预测上优于其他不确定性评估基准。评估框架采用三阶段流程:识别需澄清的输入、生成澄清问答对、预测最终输出,并通过交互预
读前先问
读论文之前首先要问几个问题:
- 这篇论文大方向的目标是什么?
交互式AI助手在人机交互过程中的如何消歧 - 这个方向目前有什么问题?
无法确定何时需要与用户进行交互来澄清模糊性 - 这篇论文要解决什么问题?
何时提出澄清问题 - 这个问题为什么难?
是否提出模糊请求的澄清问题取决于模型知识、领域的常识和用户的偏好 - 作者是怎么解决这些问题的?
将模糊性量化为模拟用户意图的熵 - 怎么验证论文的解决方法是否有效?
(个人感觉论文中并没有说清楚到底什么时候才需要对问题进行澄清,而且论文前面说的综合考量更多微妙因素,在后面也没有体现到。)
论文精读
引言
歧义性是自然语言的固有特征,一个简单的陈述句也有可能有多种解释,这时就需要通过进一步的互动来消除歧义,通常需要通过提问和回答澄清问题来达成共识。
基于大语言模型开发的交互式AI助手通常无法确定何时需要与用户进行交互来澄清模糊性,这也是限制这些系统提出澄清问题能力的核心挑战之一。
以往大多数自然语言处理领域的模棱两可建模研究都将歧义视为二元分类任务(即输入是否具有多个有效解释?),但系统在判断何时需要请求澄清时,需要综合考量更多微妙因素。例如,模棱两可的表述是否具有可推断的主导解释,以及用户对 LLM 速度与易用性的重视程度,相较于其严谨性有多高。
作者开发了一个任务无关的评估框架,采用三阶段澄清流程解决歧义问题。
- 第一步是目标任务,系统需要识别哪些输入需要澄清。
- 第二步,在确定需要澄清后提供与黄金解释相对应的澄清问答对。
- 最后一步,LLM 会根据输入和澄清问答对预测输出结果。
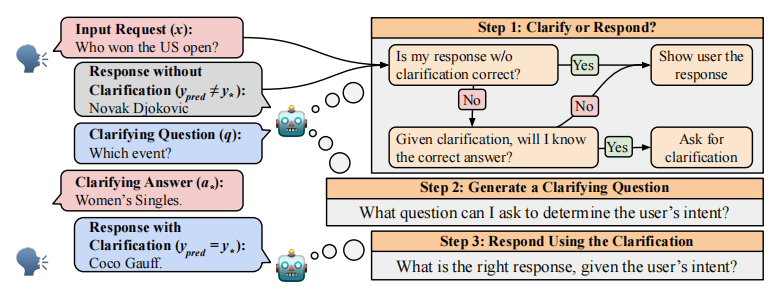
最后,作者提出意图-SIM(intent-SIM)方法,通过模拟用户与智能助手的多次交互,估算用户意图的熵值来判断何时需要澄清。实验结果表明,意图-SIM在识别需要澄清的错误预测方面,始终优于其他不确定性评估基准方法。
方法
确定何时澄清
首先先确定形式化的问题:用户向 LLM 提交初始输入请求 x x x 时,部分输入可能存在歧义,导致系统可选择的输出响应集合为 Y = { y i } 1 k Y=\{y_i\}^k_1 Y={yi}1k。其中某个输出 y ∗ ∈ Y y_∗ \in Y y∗∈Y 代表用户模糊请求背后的金标准输出。为明确用户意图,系统会提出澄清问题 q q q,用户则给出与其意图对应的澄清回答 a ∗ ∈ A = { a i } 1 k a_∗ \in A=\{a_i\}^k_1 a∗∈A={ai}1k。为简化模型,作者假设澄清回答集合 A A A 与可行最终响应集合 Y Y Y 之间存在二分匹配关系。每个输入x在不同解释上的分布由概率 P ( y = y ∗ ∣ x ) P(y=y_∗|x) P(y=y∗∣x) 表示。
任务定义
现有 NLP 应用中的歧义建模方法,主要将歧义视为二元标签处理:输入内容要么具有多个有效解释,要么没有。虽然对歧义输入始终要求澄清看似合理,但由 P ( y = y ∗ ∣ x ) P(y=y_∗|x) P(y=y∗∣x) 给出的预期解释分布,往往是被单一最可能的解释所主导。在这种情况下,直接响应用户请求可能比要求澄清更为合适。
系统判断是否提出模糊请求的澄清问题取决于领域的需求和用户的偏好。在高风险场景中,我们可能希望系统频繁地请求澄清。同样地,在时间敏感的问题上,我们可能希望减少交互次数。因此,作者将确定何时进行澄清的任务定义为不确定性估计目标:给定一个输入请求 x x x,系统必须预测一个标量不确定性估计值 u ( x ) u(x) u(x),该值与澄清后预期性能提升的程度相关。
这项任务与标准不确定性评估存在本质区别。标准评估旨在生成与预测正确性相关的不确定性估计,而确定何时需要澄清任务的目标,则是识别那些既存在错误又能在澄清后得到改善的预测。这要求系统能够区分导致模型不确定性的两个因素:认知不确定性与随机不确定性。
- 认知不确定性源于知识不足,例如在问答系统中遇到大语言模型未见过的实体,或在机器翻译中遇到未见过的翻译词汇。
- 随机不确定性则源自输出结果的内在随机性,这种随机性通常由歧义性引起,而我们通过交互可以消除这种歧义。
针对该任务的系统需要识别具有高随机不确定性的场景(用户意图模糊),以及认知不确定性较低的场景(用户在澄清后已掌握所需知识)。
评估框架
评估框架基于如上图所示的三阶段流程构建:
- 首先要求系统判断哪些示例需要 LLM 进行澄清,哪些示例需要直接通过预测 y p r e d y_{pred} ypred 进行回应。
- 第二步中,允许 LLM 向用户提出澄清问题 q q q,并接收用户的回应 a ∗ a_∗ a∗。
- 最后一步中,LLM 根据输入内容及其澄清请求预测 y p r e d y_{pred} ypred。
在上述设置中,请求澄清的实用性高度依赖于
- 澄清性问答对的质量
- LLM 利用澄清信息确定正确输出的能力
评估指标
评估指标用于衡量系统在最大化 LLM 预测性能 y p r e d y_{pred} ypred的同时,最小化用户澄清请求次数的能力。
作者定义了两个用于评估不确定性估计值 u ( x ) u(x) u(x) 的指标,以确定何时需要进行澄清:
- 在固定交互预算下的系统性能评估:为评估确定何时需要澄清的不确定性估计,为系统提供交互预算 b ∈ [ 0 , 100 ] b \in [0,100] b∈[0,100],并允许系统对 b% 的输入示例提出澄清请求。利用每个系统的不确定性估计值 u ( x ) u(x) u(x) 来确定需要澄清的前 b% 示例,随后在此交互预算下评估系统的性能表现。
- AUROC:该指标常用于不确定性量化,以评估不确定性估计器在所有可能置信度阈值下正确与错误预测的分类能力。在作者的场景中,调整该指标以评估不确定性估计值识别哪些预测将通过澄清得到改善的能力。
数据集和应用
QA
数据集:AmbigQA,该数据集对 NaturalQuestions 中的问题进行了是否含糊的重新标注。对于每个含糊示例,研究者还标注了不同意图作为初始问题及其对应答案的消歧修订版本。作者使用NaturalQuestions原始标注答案作为意图真实分布的样本,通过识别包含相同答案的消歧版本,将这些采样输出映射到其对应意图。
评估指标:检测标准化处理后的输出结果中是否出现黄金答案串
NLI
数据集:AmbiEnt,该数据集包含模糊的前提/假设对及其每个解释的消歧修订。首先向数据集标注者展示模糊输入,并要求他们将其标记为 NLI 示例。然后向标注者展示每个输入的不同消歧版本,并要求他们再次标注每个解释。作者利用这些多重标注来识别哪个解释的标签与标注者最初给模糊输入的标签一致。随后,作者将匹配的解释作为采样的用户意图和输出标签。
评估指标:三分类(包含、矛盾、中性)分类准确率
机器翻译
数据集:DiscourseMT,通过人工整理构建了一个英法翻译的模棱两可测试集,每个示例包含一个模棱两可的测试句和两个可能的上下文句,测试句的翻译结果取决于其前文的上下文句。作者将这些无上下文的测试句作为模拟用户输入的歧义示例,将其两种翻译结果视为可行输出集。同时,作者还收录了仅有一个可行翻译的上下文句作为无歧义输入的示例。虽然该数据集未包含用于估计解释分布的标注,但其中的句子经过精心设计具有高度模棱两可性。因此,在实验中作者直接采用解释的均匀分布作为基准。
评估指标:采用对比准确度进行评估,用于衡量 LLM 是否对歧义句子的预期译文赋予更高似然值。对于明确无误的案例,直接判定系统无需解释即可正确理解。
消歧流水线
为降低对语言模型生成高质量澄清问题的依赖,作者采用了一个 Oracle 系统来生成澄清问题与答案。该系统基于 GPT-3.5 和少样本提示技术,通过提供系统指令和两个示例,实现以下任务:给定模糊输入 x x x 及其不同解释,每个解释对应一个输出 y ∈ { y i } 1 k y \in \{y_i\}^k_1 y∈{yi}1k,系统需生成 (1) 区分每个解释的澄清问题 q q q,以及 (2) 与每个解释对应的澄清回答 { a i } 1 k \{a_i\}^k_1 {ai}1k。
下表包含使用该 Oracle 系统生成的澄清问题示例。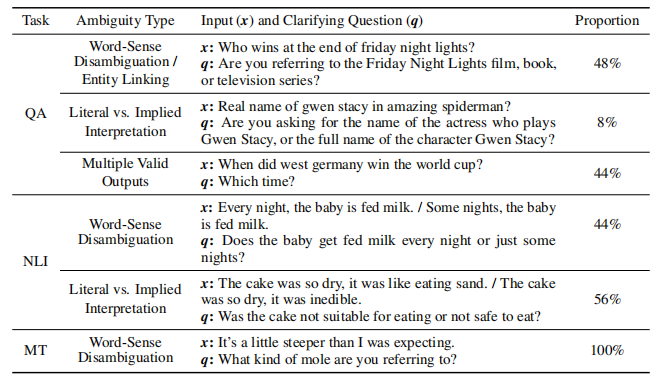
生成 LLM 预测时,作者采用标准四次提示法(four-shot prompting)进行训练。通过向 LLM 提供目标任务的示范样本(样本包含或不包含澄清信息),以验证测试案例是否符合要求。
LLM 是否能够采用澄清性互动?
在评估系统何时需要进行澄清之前,首先需要确认:LLM 确实具备使用澄清功能的能力,且提供澄清操作能够提升生成的数据集质量。为此,作者通过对比选择不澄清输入与澄清所有输入两种方案的性能表现,对现有的歧义消解流程进行了实验验证。同时,作者还设置了对照组——不进行任何澄清操作,而是直接使用各基础数据集提供的已消歧版本作为输入。
作者在下表中报告了以 LLAMA-2-Chat 和 GPT-3 的实验结果。研究发现,无论任务类型或系统环境如何,LLM 均可通过利用澄清性问题与答案来提升其响应质量。
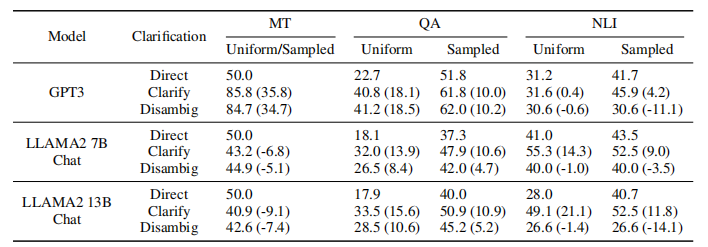
作者还发现澄清往往并非推断正确解释的必要条件,即便经过澄清,模型仍频繁产生错误。这些观察结果证明了在确定何时需要澄清时的挑战:系统必须能够识别出当输入存在歧义时,其解释是否具有主导性且可推断;同时必须能够区分不同形式的不确定性,从而判断错误预测何时可以通过澄清得到解决,何时无法解决。
实验
INTENT-SIM
无监督方法在 LLM 中进行不确定性量化时,通常依赖于估计输出分布的熵,利用高熵来识别错误输出。虽然这些方法在识别错误预测方面表现良好,但它们无法确定预测为何出错。
要确定何时需要澄清,需要超越简单地预测正确性,系统需要识别不确定性是否由模糊性引起。在作者提出的方法intent-SIM中,通过显式估计给定输入的模糊性来区分这两个因素,作者将模糊性量化为模拟用户意图的熵。下表展示了作者的方法。使用相同的少样本提示结构回答带有澄清的问题,根据用户的请求贪婪地生成澄清问题。然后,通过采样对澄清问题的不同响应来模拟不同的用户意图。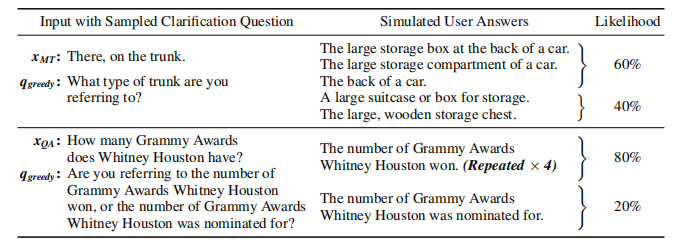
作者使用在 MNLI 上微调的 DeBERTa-large NLI 模型对语义等效的响应集进行聚类。作者定义两个回答等价的条件是:若其中任一对澄清性问答对相互蕴含,则将每个集合的似然度估计为其样本占比。最终通过计算语义不同回答的分布熵来确定不确定性估计值。
Baselines
- Likehood
使用与前述相同的少样本提示,引导模型直接生成输出而无需解释。随后通过分析贪婪输出的似然值来判断何时需要补充说明。 - Self-Ask
Self-Ask 要求模型将输入分解为多个子问题和答案,再组合成最终答案。作者将该技术调整为关注外部上下文查询而非输入分解,具体做法是:在每次输入查询后,通过修改之前的少样本提示,向 LLM 询问“此处是否需要后续问题?”。系统根据生成“否”的置信度来判断是否需要澄清。 - Sample Entropy
在 LLM 的不确定性估计方面,先前的研究通过采样多个输出并归类等效响应来估计 LLM 输出空间的熵。基于这些研究,作者使用少样本提示 LLM 提供一个无需澄清的输出。然后使用预训练的 NLI 模型(与意图-SIM相同)对等效采样响应进行归类,以确定等效采样问答输出。
实验结果
在下表中,作者报告了使用不同方法决定何时澄清的结果。
通过将这些系统与随机基线进行比较,后者随机选择b%的示例进行澄清,并实现与b%相同的性能提升,可以观察到 Likehood 和 Self-Ask 表现出混合结果。尽管这些系统通常比随机方法表现更好,但在许多设置下,它们的表现明显逊于随机方法。
相比之下,使用 Sample Entropy 和 INTENT-SIM 的方法始终优于所有其他基线。仅在比较 Sample Entropy 和 INTENT-SIM 时,作者发现 INTENT-SIM 在实验的约三分之二的 AUROC 和预算设置中表现更优。此外,值得注意的是,在 INTENT-SIM 达到最佳 AUROC 性能的四个设置中,有三个设置的差异与其他所有基线相比具有统计学意义。而其他系统达到最佳 AUROC 的两个设置中则未出现这种情况。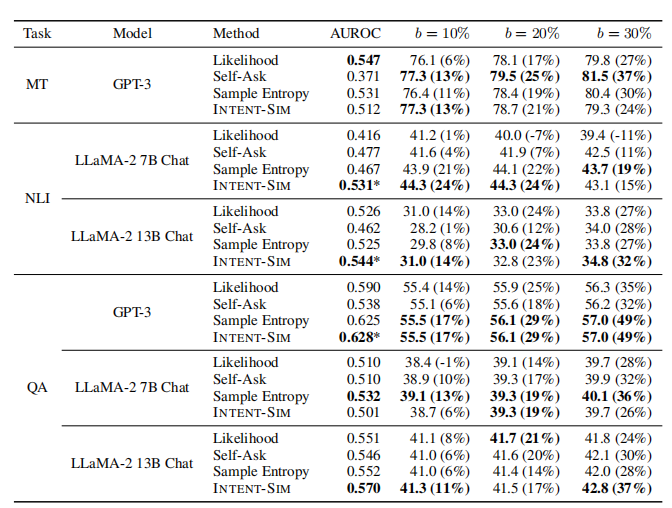

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)