字节跳动开源PaSa:用强化学习重塑论文检索!2分钟搞定一周的调研工作量
字节跳动与北大联合推出PaSa智能体,革新学术论文检索方式。该智能体通过强化学习训练,能自主搜索、阅读和追踪引文网络,解决了传统搜索引擎关键词匹配不足和通用LLM幻觉问题。PaSa采用双Agent架构(Crawler和Selector)和创新的Session-Level PPO算法,在3.5万条训练数据上取得突破:相比Google Scholar召回率提升39.9%,7B参数模型性能超越GPT-4
你是还在手动翻Google Scholar,还是已经习惯了用GPT-4o帮你读论文?
做过科研的人都知道,学术检索绝对是痛点中的痛点。现有的搜索引擎(如Google Scholar)只能做关键词匹配,无法理解复杂的逻辑;而通用的LLM(如ChatGPT)虽然能读,但受限于幻觉和上下文窗口,很难进行大规模、深度的引文追踪。
最近,字节跳动研究院)联合北京大学,丢出了一个王炸级Agent——PaSa (Paper Search Agent)。
它不仅仅是一个搜索工具,更是一个模仿人类研究员行为的智能体。它能自主调用搜索工具、阅读全文、根据引文顺藤摸瓜,甚至还能“自我反思”决策路径。
更硬核的是,PaSa通过强化学习解决了Agent在长链路任务中容易“迷路”的问题,在真实场景下,不仅吊打Google Scholar,甚至超越了Google + GPT-4o的组合。
今天,我们就来深度拆解PaSa背后的技术原理,看看它是如何利用RL让7B模型跑出SOTA效果的!
1. 核心资源速览
论文标题: PaSa: An LLM Agent for Comprehensive Academic Paper Search
机构: ByteDance Research, Peking University
项目主页: pasa-agent.ai
代码仓库: Github/bytedance/pasa
论文链接: arXiv:2501.10120
2. PaSa 到底强在哪?
传统的搜索是“一锤子买卖”,你给词,它给结果。
而 PaSa 是“以过程为导向”的智能体。它模拟了人类做调研的三个核心动作:
-
Search(搜):自主生成关键词,调用API。
-
Read & Select(读与选):像教授一样快速扫读Abstract,判断是否相关。
-
Expand(扩):这是PaSa的杀手锏。它会阅读论文的Related Work章节,根据引文网络去挖掘更多Google搜不到的“长尾”论文。
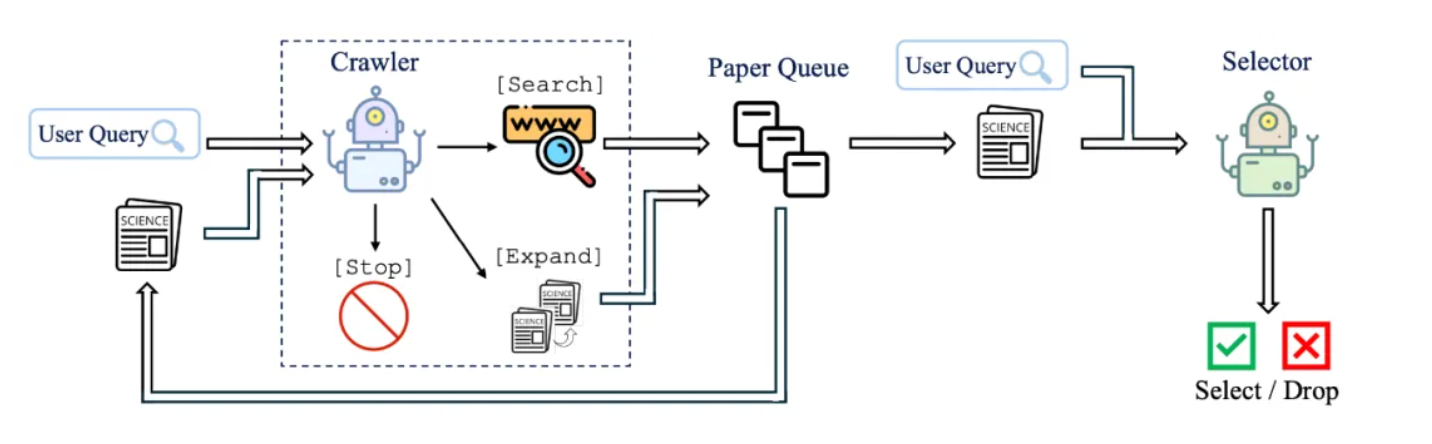
为了实现这个复杂的流程,PaSa设计了双Agent架构:
-
Crawler(爬虫):负责干活。决定搜什么、读哪篇、去哪里扩展引文。
-
Selector(筛选者):负责把关。作为Reward Model,精准判断Crawler找到的论文是否符合用户需求。
3. 核心技术解密:强化学习如何让Agent变聪明?
PaSa最大的亮点,在于它不是简单地Prompt一下GPT-4,而是使用了强化学习(RL) 来训练Crawler。
为什么要用RL?因为学术搜索面临两个巨大的挑战:
-
稀疏奖励(Sparse Reward):Agent可能忙活了半天(搜索、阅读、跳转),最后才找到一篇真正有用的论文。中间的步骤很难获得即时反馈。
-
长轨迹(Long Trajectories):一个完整的调研过程可能涉及数百个动作,Context长度不仅撑爆显存,也会让LLM迷失方向。
PaSa 祭出了Session-Level PPO 加上 混合奖励机制,成功解决了这些问题。
3.1. 独特的奖励函数设计
PaSa 不仅看结果,还看过程和成本。其奖励函数 ![]()
设计得非常精妙:
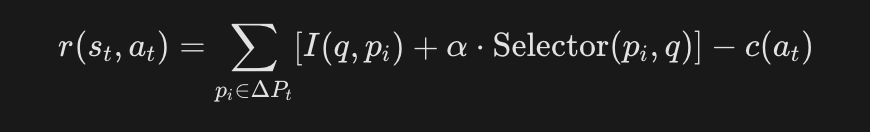
看不懂公式?没关系,我们来翻译一下:
-
命中奖励
I(q,pi):如果你找到了一篇全新的、完全匹配用户Query的论文,奖励+1。这是硬指标。 -
Selector 辅助奖励
α⋅Selector:由于真实的目标论文(Ground Truth)很稀疏,PaSa引入了训练好的Selector模型打分。只要Selector觉得这篇论文靠谱,就给Crawler一个“小红花”(辅助奖励)。这大大缓解了奖励稀疏的问题。 -
动作成本惩罚
c(at):天下没有免费的午餐。每一次搜索、每一次展开阅读都是有成本的。为了防止Agent为了刷分而无限乱搜,PaSa给每个动作加了负向惩罚。
总结: 这个Reward函数教会了Agent——“要找得准(Match),要找得像(Selector),还要找得快(Cost)”。
3.12. Session-Level PPO (会话级近端策略优化)
为了解决“长轨迹”问题,PaSa没有把整个搜索过程扔给PPO,而是切分成了多个 Session(会话)。
-
传统RL:从开始搜索到最终结束,可能几百步,梯度传播困难。
-
PaSa策略:
-
将搜索拆解为短片段:Context + Action -> Stop。
-
Agent在每个Session中决定是继续Search、Expand还是Stop。
-
这使得7B模型也能在有限的上下文窗口内,高效地学习到长期的规划能力。
-
3.13. 模仿学习与正则化 (SFT + RL)
PaSa并没有直接从零开始RL,而是先通过 SFT(监督微调) 学习人类专家的搜索行为(Imitation Learning)。在RL阶段,为了防止模型练“偏”了(Reward Hacking),还加上了SFT策略的KL散度作为正则项。
4. 数据集:为了训练它,字节造了3.5万条数据
高质量的数据是Agent成功的基石。字节团队构建了两个关键数据集
| 特性 | AutoScholarQuery (合成) | RealScholarQuery (真实) |
| 来源 | AI顶会论文 Related Work + GPT-4 | 真实研究员的大脑 |
| 风格 | 规整、学术化、教科书式 | 复杂、口语化、包含具体约束条件 |
| 难度 | ⭐️⭐️⭐️ (容易通过关键词命中) | ⭐️⭐️⭐️⭐️⭐️ (需要理解逻辑和排除法) |
| 作用 | 练基本功:让Agent学会“搜-读-找引用”的基本动作 | 实战考核:检验Agent是否真的懂科研,能不能解决只有专家才懂的长尾问题 |
PaSa 的强悍之处在于:它仅仅是在“教科书”(AutoScholarQuery)上训练出来的,但在面对“刁钻考题”(RealScholarQuery)时,依然表现出色,说明强化学习让它掌握了通用的搜索策略,而不仅仅是记住了数据。
4.1 AutoScholarQuery (合成训练集)
核心逻辑:GPT-4 扮演出题老师。它看着答案(已有的论文引文),反推题目(用户可能会怎么问)。
举例说明
假设我们有一篇关于 大模型微调(LLM Fine-tuning) 的顶会论文,它的 Related Work(相关工作) 章节里写了这么一段话:
原文片段:
"...In recent years, parameter-efficient fine-tuning (PEFT) has gained attention. Hu et al. (2021) proposed LoRA [1], which freezes the pre-trained model weights and injects trainable rank decomposition matrices. Similarly, Houlsby et al. (2019) introduced Adapter layers [2] to reduce the number of trainable parameters..."注:这里引用了 [1] LoRA 和 [2] Adapter 两篇论文。
构建过程:
PaSa 的开发者把这段话扔给 GPT-4,下达指令:“请根据这段话中引用的论文 [1] 和 [2],生成一个用户可能会搜索的查询(Query)。”
GPT-4 生成结果:
-
生成的 Query:"What are the representative methods for parameter-efficient fine-tuning (PEFT) that utilize low-rank adaptation or adapter layers?" (有哪些利用低秩适应或适配器层的参数高效微调代表性方法?)
-
标准答案:
-
LoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021)
-
Parameter-Efficient Transfer Learning for NLP (Houlsby et al., 2019)
-
为什么这样做?
-
优点:能够极低成本生成海量数据(3.5万条)。因为顶会论文的 Related Work 本质上就是人类专家整理好的“问题-答案”对,质量极高。
-
局限:问题通常比较规整,像教科书,不像真人说话。
4.2 RealScholarQuery (真实测试集)
核心逻辑:真实的人类研究员不仅逻辑复杂,还喜欢用模糊词、限定词,甚至跨领域提问。这是检验 Agent 是否“死记硬背”的试金石。
场景:一个正在研究自动驾驶的研究员,他在寻找非常细分的技术方案,不仅仅是搜关键词。
真实人类 Query:
"I am looking for papers that address the straggling worker problem in distributed deep learning training, specifically using redundancy-based methods like coded computation, rather than just gradient accumulation."
(我在找解决分布式深度学习训练中“落后节点问题”的论文,特别关注使用像编码计算这种“基于冗余的方法”,而不是仅仅使用梯度累积。)
分析这个 Query 的难度:
-
多重限制:
-
领域:分布式深度学习
-
问题:Straggling worker (掉队节点/落后节点)
-
方法:Redundancy-based (基于冗余)
-
具体技术:Coded computation (编码计算)
-
排除项:NOT gradient accumulation (不要梯度累积)
-
-
Google 的痛点:如果你直接搜这些词,Google 可能会把“梯度累积”的论文也推给你,因为它只看到了关键词匹配,不懂“rather than”(而不是)这个逻辑。
-
PaSa 的挑战:Agent 必须先搜“straggling worker”,读论文Abstract,发现是讲“梯度累积”的就扔掉(Selector的作用),发现是讲“编码计算”的才保留,并顺着引文去找更多基于冗余的方法(Crawler Expand的作用)。
标准答案
由提出这个问题的人类专家,人工筛选出的几篇真正符合要求的论文(例如 Gradient Coding, Coded Distributed Computing 等)。
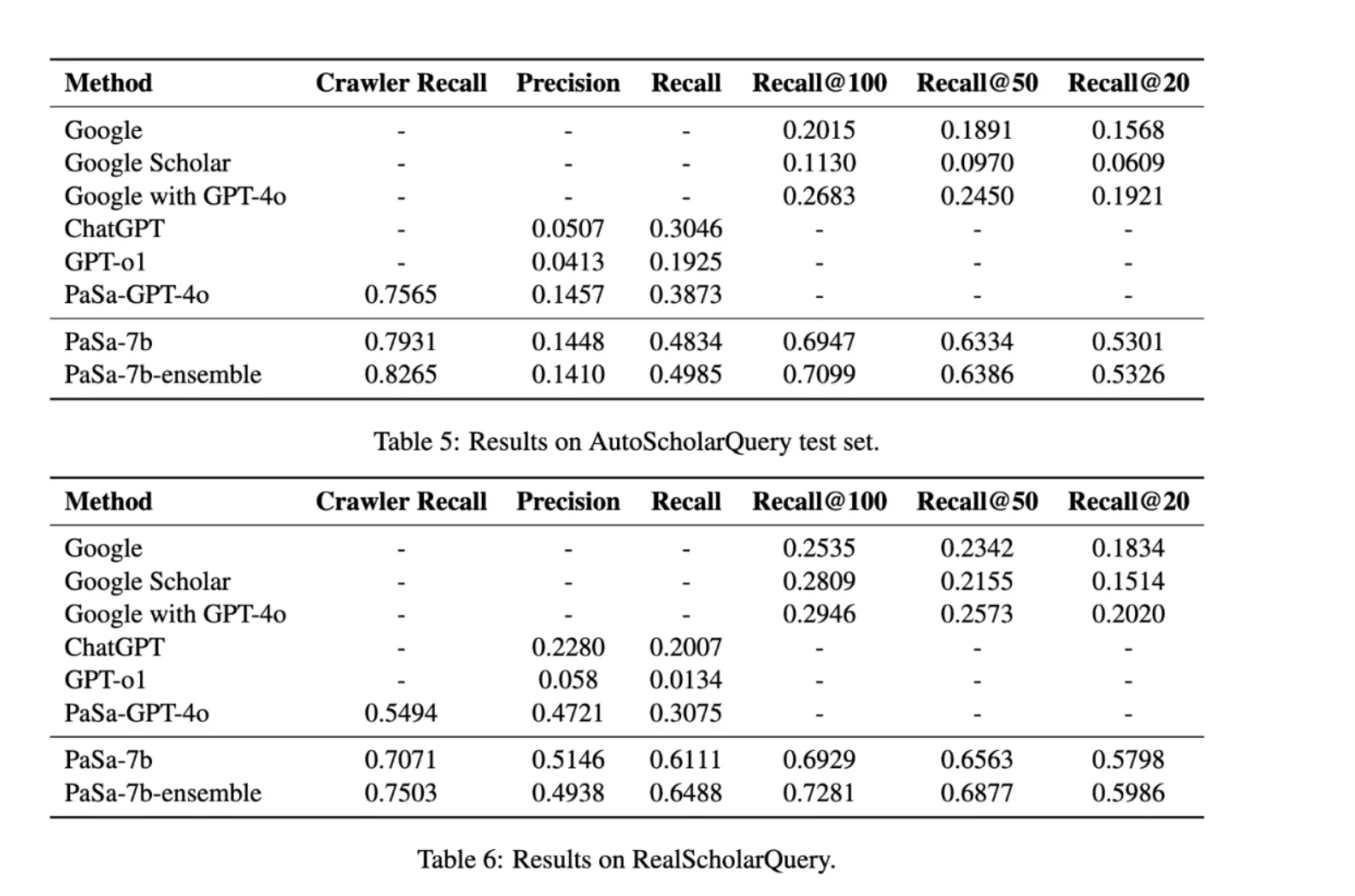
5.结果:吊打 GPT-4o?
实验数据说明一切。在 RealScholarQuery 真实基准测试上,PaSa-7B 的表现令人咋舌:
-
对比 Google Scholar:PaSa 在召回率(Recall@50)上提升了 39.90%。
-
对比 GPT-4o Agent:PaSa(仅7B参数)比通过Prompt工程搭建的 PaSa-GPT-4o 召回率还高出 30.36%。
-
成本优势:PaSa 基于 Qwen2.5-7B 微调,推理成本远低于调用 GPT-4o API。
6. 为什么这很重要?
PaSa 的成功不仅仅是一个工具的胜利,它向我们展示了 LLM Agent 的未来趋势:
-
RL is All You Need for Agents:单纯的Prompt工程(Prompt Engineering)是有上限的。通过构建合理的Reward Function,让Agent在环境中自我进化,是突破能力瓶颈的关键。
-
小模型 + 强逻辑 > 大模型 + 弱逻辑:7B模型经过特定任务的RL训练,可以在特定领域(如学术搜索)击败通用的GPT-4o。
-
引文网络挖掘(Expand)是核心:真正的学术调研不是关键词匹配,而是知识图谱的游走。PaSa 证明了让Agent学会“顺藤摸瓜”的巨大价值。
7. 想自己试一试?
PaSa 已经完全开源!你可以直接去 Demo 站体验,或者拉取代码在本地部署。
GitHub: git clone https://github.com/bytedance/pasa
HuggingFace: 模型权重已发布。
对于开发者来说,PaSa 的 crawler.py 和 reward.py 是学习 Agent RL 极佳的教科书级范例。
别再让调研占满你的周末了,让 PaSa 帮你打工吧!
喜欢这类硬核技术解读吗?欢迎点赞、关注,获取更多前沿AI技术干货!
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)