EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test翻译
现代 LLM 的顺序特性导致其计算成本高昂且速度缓慢,而推测性采样已被证明是解决这一问题的有效方案。诸如 EAGLE 之类的方法在特征层执行自回归,通过重用目标模型中的顶层特征来获得比传统推测性采样更好的结果。**LLM 领域的一个发展趋势是扩展训练数据以在不增加推理成本的情况下提升模型智能**。然而,我们观察到,扩展数据对 EAGLE 的改进有限。我们发现,这种限制源于 EAGLE 的特征预测约
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
现代 LLM 的顺序特性导致其计算成本高昂且速度缓慢,而推测性采样已被证明是解决这一问题的有效方案。诸如 EAGLE 之类的方法在特征层执行自回归,通过重用目标模型中的顶层特征来获得比传统推测性采样更好的结果。LLM 领域的一个发展趋势是扩展训练数据以在不增加推理成本的情况下提升模型智能。然而,我们观察到,扩展数据对 EAGLE 的改进有限。我们发现,这种限制源于 EAGLE 的特征预测约束。在本文中,我们提出了 EAGLE-3,它放弃了特征预测,转而采用直接 token 预测,并通过一种名为训练时测试的技术,用多层特征融合取代了对顶层特征的依赖。这些改进显著提升了性能,并使 draft 模型能够充分利用扩展训练数据的优势。我们的实验包括聊天模型和推理模型,并在五个任务上进行了评估。结果表明,EAGLE-3 的加速比最高可达 6.5 倍,比 EAGLE-2 提升了约 1.4 倍。在 SGLang 框架中,EAGLE3 在批处理大小为 64 时实现了 1.38 倍的吞吐量提升。代码可在 https://github.com/SafeAILab/EAGLE 获取。
1.介绍
现代大语言模型(LLM)正被应用于更多领域,其性能的提升得益于模型参数规模的扩大——一些LLM的参数数量已超过数千亿。在自回归生成过程中,每个 token 都需要访问所有模型参数,这使得LLM推理速度缓慢且成本高昂。
近年来,测试时扩展性问题备受关注。诸如 ChatGPT o1 和 DeepSeek-R1 等模型在响应前会进行深思熟虑的推理,以更长的推理时间为代价,拓展了逻辑推理模型(LLM)的能力边界。然而,这些模型通常需要冗长的推理过程,导致其成本极高,而增加的响应时间也会严重影响用户满意度。这些推理模型显著提高了整个逻辑推理模型流程中推理成本的比例,促使研究人员探索更经济、更快速的推理优化方法。
推测性采样方法可以通过部分并行化生成过程来降低 LLM 的延迟。这些方法快速生成草稿 token,然后并行验证它们。这使得在一次前向传播中可以生成多个 token,从而显著降低推理延迟。在传统的推测性采样中,draft 模型是一个独立的、较小的 LLM,通常是与目标模型来自同一系列的低参数版本。该 draft 模型独立于目标模型运行。与传统的推测性采样不同,EAGLE重用了目标模型的顶层特征(LM 头之前的特征)。它训练 draft 模型自回归地预测下一个特征,然后使用目标模型的 LM 头来获取 draft token。通过利用目标模型的丰富信息,EAGLE 相比传统的推测性采样实现了显著更高的加速。后续方法如 HASS 和 Falcon 也采用了利用当前特征序列预测下一个特征的方法。
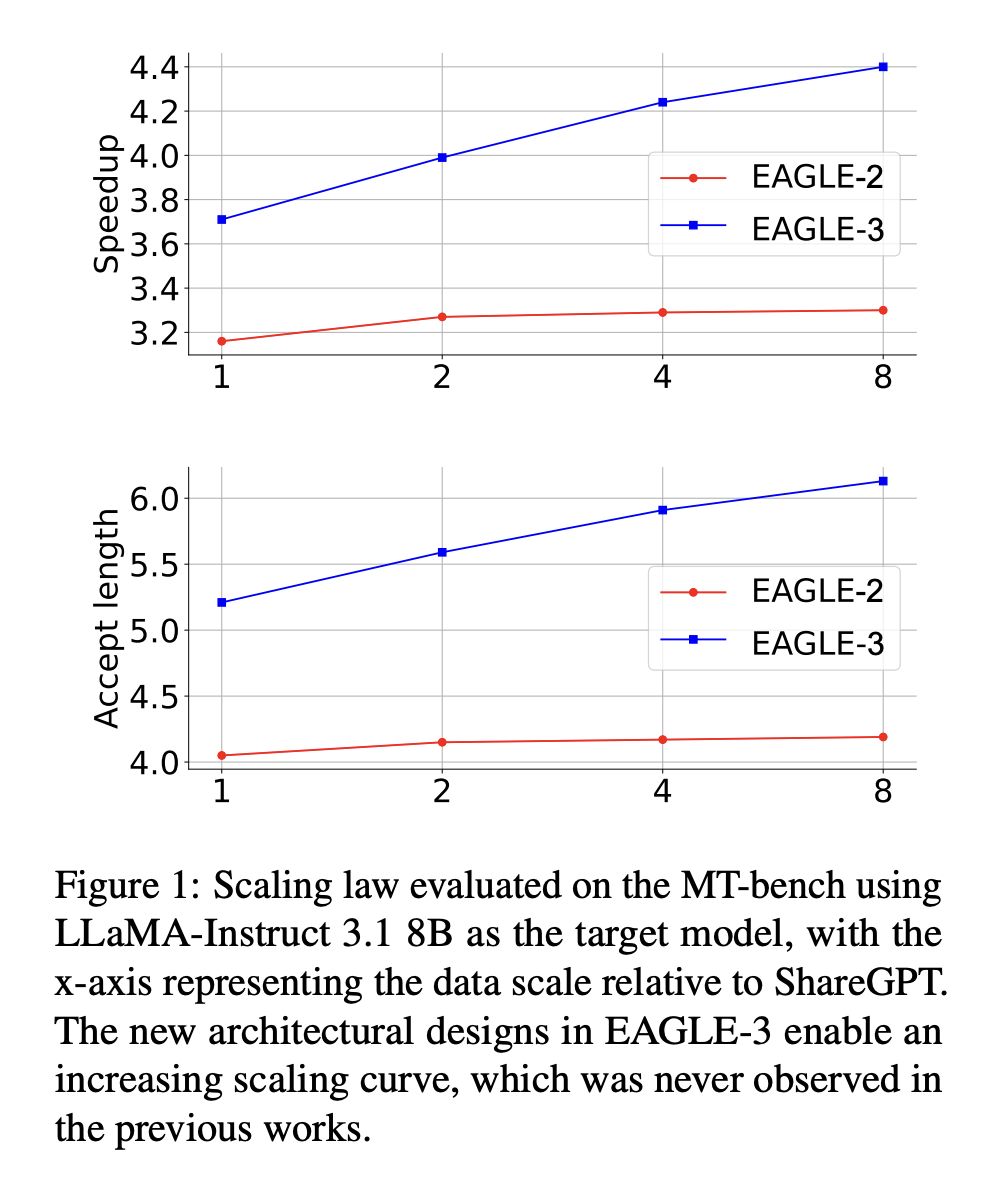
近年来,语言学习模型(LLM)越来越依赖于更大的训练数据集来提升性能。例如,LLaMA 系列模型规模分别为 70 亿(80 亿),LLaMA 1、LLaMA 2 和 LLaMA 3 分别使用了 1 万亿、2 万亿和 15 万亿个 token 的训练数据,在保持模型架构和推理成本基本不变的情况下,显著提升了各项指标。类似地,我们旨在通过增加训练数据来提高 EAGLE 的接受率和加速比。然而,我们发现 EAGLE 从额外训练数据中获得的收益有限。我们分析了造成这种现象的原因。如图 3 上半部分所示,EAGLE 在特征级别执行自回归预测,预测下一个特征,然后将该特征输入到目标模型的语言模型头部,以获得 token 分布。 EAGLE 的损失函数由两部分组成:特征预测损失 lfeal_{fea}lfea 和 token 预测损失 ltokenl_{token}ltoken。得益于特征预测损失,仅在第一步训练的 draft 模型可以适应第二步,并获得多步预测能力。然而,由于最终目标是 token 预测,特征预测可以被视为一种额外的约束,它限制了 draft 模型的表达能力,使其难以从增加的数据中获益。移除特征约束并扩展训练数据后(图 3 中间部分),如图 4 所示,第一个 draft token 的接受率 0−α0_{-α}0−α 显著提高。然而,步骤 1 中 draft 模型的输出(记为 a^t+1\hat a_{t+1}a^t+1)与真实值 ft+1f_{t+1}ft+1 相差甚远,导致步骤 2 中的输入序列 f1,f2,⋅⋅⋅,ft,a^t+1f_1, f_2, · · · , f_t, \hat a_{t+1}f1,f2,⋅⋅⋅,ft,a^t+1 与训练分布存在显著偏差,从而导致第二个 draft token的接受率 1−α1_{-α}1−α 非常低,如图 4 所示。我们可以通过将步骤 1 融入训练过程(图 3 底部)来解决这个问题。使用这种方法,增加训练数据的优势将更加明显。我们将此技术称为训练时测试。
EAGLE 和诸如 Medusa 之类的推测性采样方法会重用目标模型的顶层特征,特别是语言模型头之前的那些特征。对于权重矩阵满秩的语言模型头,对应于下一个 token 的 logits 的顶层特征是唯一的,这确保了这些特征中包含的信息与下一个 token 的 logits 直接对应。然而,仅基于顶层特征(其本质上仅限于下一个词元)来预测下一个 token 是一个重大挑战。幸运的是,上述训练时测试技术允许使用中间层的特征,而不是仅仅依赖顶层特征,因为特征预测损失 lfeal_{fea}lfea 已在训练过程中被移除。
综上所述,本文介绍了EAGLE3,它是EAGLE的增强版本,显著提高了运行速度。EAGLE-3实现了并行化,并且与EAGLE-2中的草图树技术完全兼容。我们的主要贡献包括:
- 一种新的 draft 模型训练时测试架构:我们移除了特征预测约束,在训练过程中模拟多步生成的同时直接预测 token。这种直接 token 预测方式赋予了 draft 模型输入极大的灵活性。我们并非仅复用顶层特征,而是整合并利用目标模型的低层、中层和高层特征,从而捕获来自不同层次的丰富语义信息。
- 发现大语言模型推理加速的缩放规律:在新架构中,我们观察到,增加 draft 模型的训练数据量会导致 EAGLE-3 加速比成比例地增加。如图 1 所示,这种缩放行为在原始 EAGLE 架构中并未观察到。
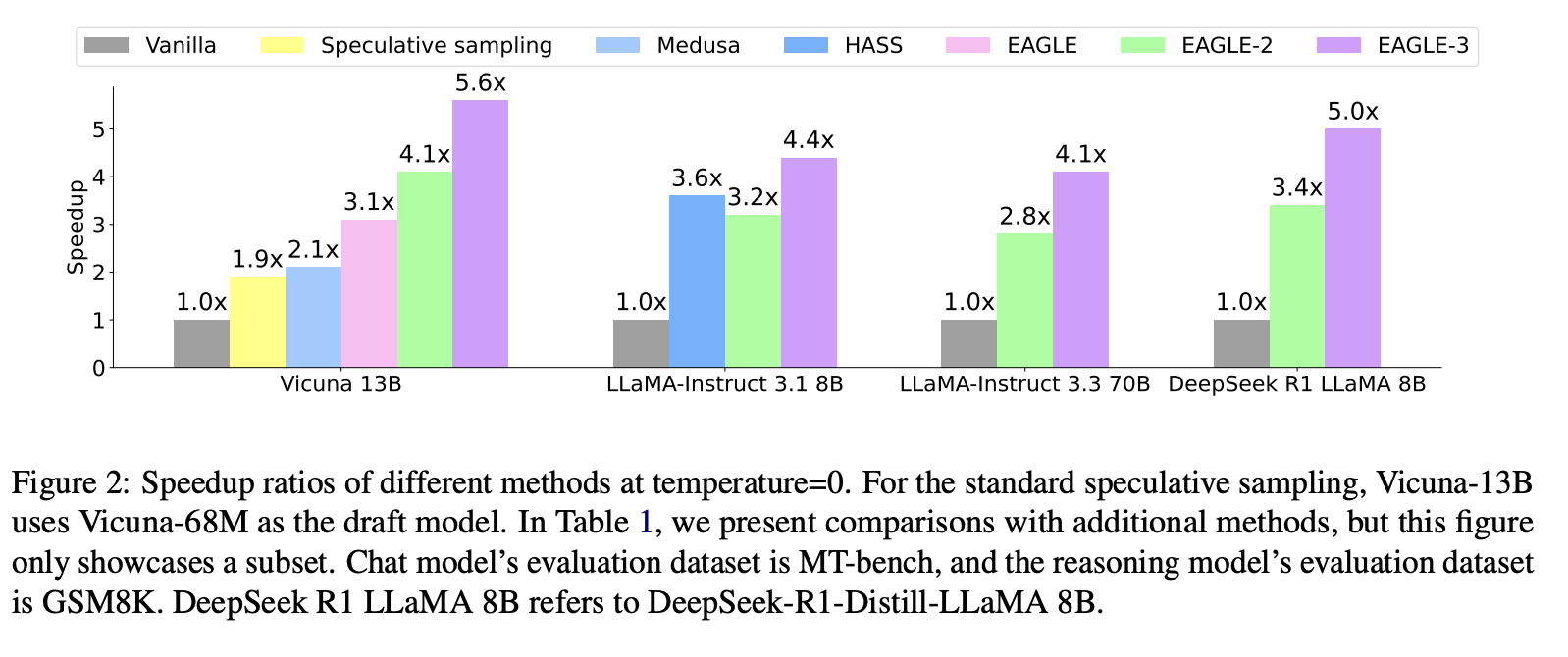
- 推理加速性能提升:EAGLE3 的训练数据量约为 EAGLE 的 8 倍,在 batch 大小为 1 时,其延迟速度比 EAGLE-2 提升了 1.4 倍。人们通常认为,在大 batch size 下,推测性采样会降低吞吐量。然而,在生产级框架 SGLang 中,EAGLE-3 在批处理大小为 64 时,吞吐量提升了 40%。我们预期更大的数据量将带来更高的加速比。

2.Preliminaries
2.1 Speculative Sampling
推测采样是一种无损 LLM 加速技术,它在 draft 生成和验证之间交替进行。draft 生成成本低,而验证则并行化,分别对应于 draft 的生成和验证过程。我们用 tit_iti 表示第 iii 个 token,用 Ta:bT_{a:b}Ta:b 表示 token 序列 ta,ta+1,⋅⋅⋅,tbt_a, t_{a+1}, · · · , t_bta,ta+1,⋅⋅⋅,tb。当使用 T1:jT_{1:j}T1:j 作为前缀时,推测采样的两个阶段如下。
在 drafting 阶段,推测抽样利用 draft 模型(与目标模型同一系列的较小版本)自回归生成 kkk 个 token 以形成草稿 T^j+1:j+k\hat T_{j+1:j+k}T^j+1:j+k,同时记录每个 token 的概率 p^\hat pp^。
在 verification 阶段,推测抽样调用目标模型来评估草稿 T^j+1:j+k\hat T_{j+1:j+k}T^j+1:j+k 并记录其概率 ppp。然后,推测抽样从前到后依次确定草稿 token 的接受情况。对于 token t^j+i\hat t_{j+i}t^j+i,其接受概率由 min(1,pj+i(t^j+i)/p^j+i(t^j+i))min(1, p_{j+i}(\hat t_{j+i})/\hat p_{j+i}(\hat t_{j+i}))min(1,pj+i(t^j+i)/p^j+i(t^j+i)) 给出。如果该 token 被接受,则继续处理下一个 token。否则,从分布 norm(max(0,pj+i−p^j+i))norm(max(0, p_{j+i} − \hat p_{j+i}))norm(max(0,pj+i−p^j+i)) 中抽取一个 token 来替换 tˆj+i,并将草稿中剩余的 token 丢弃。(Leviathan et al., 2023) 的附录 A.1 证明了推测抽样与标准自回归解码的分布一致。
2.2 EAGLE and EAGLE-2
容量有限的 draft 模型难以精确逼近大规模目标模型。EAGLE 利用目标模型的顶层特征作为附加信息,并在特征层执行自回归,从而简化草稿生成过程。EAGLE 在特征层执行自回归,然后使用目标模型的语言模型头来获取草稿 token。由于 token 层的采样结果是隐藏的,特征层自回归会引入不确定性。EAGLE 通过将前一时刻的 token 序列(即采样结果)输入草稿模型来解决这个问题。与 Vanilla 推测采样生成的链状草稿不同,EAGLE 在同一位置生成多个草稿 token,从而形成树状草稿。在验证阶段,EAGLE 使用树注意力机制来并行验证草稿树。有趣的是,EAGLE 启发了 DeepSeekv3 预训练中使用的多 token 预测技术,而 DeepSeekv3 又启发了 EAGLE-3 中的新架构设计。
EAGLE 和 Medusa 等算法采用树状草稿结构,其结构预先定义、静态且与上下文无关。草稿的难度与上下文密切相关,静态草稿树会导致资源浪费。EAGLE2 利用草稿模型的置信度来近似估计接受率,并在此基础上动态生成草稿树,在草稿阶段结束时对草稿树进行剪枝。EAGLE-3 也采用了 EAGLE-2 中提出的上下文感知动态草稿树。
3.EAGLE-3
本节将详细介绍 EAGLE-3 的实现。
3.1 Inference Pipeline

与其他推测采样方法一致,EAGLE-3 在草稿阶段和验证阶段之间交替进行。EAGLE-3 与 EAGLE 的区别在于草稿阶段,我们通过一个示例来介绍该阶段,如图 5 所示。考虑前缀“How can”。在预填充阶段或之前的验证阶段,目标模型执行前向传播以生成下一个 token “I”。我们记录目标模型前向传播的低层、中层和高层特征序列,分别记为 lll、mmm 和 hhh。我们将 kkk 维向量 l、m 和 h 连接起来形成一个 3k3k3k 维向量,然后通过一个全连接层将其降维到 kkk 维,从而得到一个整合了不同层信息的特征 ggg。这里,kkk 指的是目标模型的隐藏层大小。
我们的目标是生成一个以“How can I”为前缀的草稿 token 序列。由于仅输入 ghowg_{how}ghow 和 gcang_{can}gcan,草稿模型无法进行随机采样。因此,类似于EAGLE,我们引入了采样 token “I”的嵌入向量eIe_IeI。将拼接后的向量通过全连接层(FC层)降维至 kkk 维,然后输入到单层解码器,得到输出 aaa。最后,我们将aI输入到语言模型(LM)头部进行采样,得到草稿 token “do”。
在步骤 1 中,前缀为“How can”,我们复用了目标模型中的 ghowg_{how}ghow 和 gcang_{can}gcan。在步骤 2 中,前缀变为“How can I”。理想情况下,我们应该复用目标模型中的 ghowg_{how}ghow、gcang_{can}gcan 和 gIg_IgI。然而,由于目标模型尚未检查 token “I”,我们无法获取 gIg_IgI,因此无法实现。取而代之的是,我们使用上一步草稿模型的输出 aIa_IaI 来替换 gIg_IgI,并将 aIa_IaI 与采样结果“do”的嵌入 edoe_{do}edo 连接起来,作为步骤 1 中草稿模型的输入。在步骤 3 中,我们同样无法获取 gdog_{do}gdo,因此我们使用 adoa_{do}ado 作为替代,并将 adoa_{do}ado 与 eite_{it}eit 连接起来,作为草稿模型的输入。后续步骤均采用相同的方法。
3.2 Draft Model Training

EAGLE 中草稿模型的输入要么是目标模型的顶层特征 f1,f2,…,ftf_1, f_2, …, f_tf1,f2,…,ft,要么至少近似于目标模型的顶层特征。相比之下,EAGLE-3 中 draft 模型的输入可能包含目标模型的特征 g1,g2,…,gtg_1, g_2, …, g_tg1,g2,…,gt,也可能包含 draft 模型的输出 at+1,at+2,…,at+ja_{t+1}, a_{t+2}, …, a_{t+j}at+1,at+2,…,at+j。因此,我们需要训练 draft 模型以适应不同的输入。在训练过程中,我们会执行测试步骤,生成一个测试样本并将其反馈到 draft 模型中进行进一步训练。
EAGLE-3 模型的核心是 Transformer 解码器层。除了自注意力机制之外,没有其他组件与上下文交互,因此在训练或测试过程中无需进行任何修改。唯一需要稍作修改的组件是自注意力机制,我们将在下文中详细描述。
尽管实际输入包含特征,但为了清晰起见,我们使用 token 作为输入来描述该过程。如图 6 所示,原始训练数据是一个长度为 3 的序列“How can I”,其上下文具有正常的序列依赖关系。因此,注意力掩码是一个标准的下三角矩阵。三个位置的输出分别为“are”、“we”和“do”,它们与“how”、“can”和“I”之间存在树状的上下文关系。因此,当输入“are”、“we”和“do”进入步骤 2 时,需要相应地调整注意力掩码,如图 6 右上角所示。所有注意力掩码都是对角矩阵,除非使用原始训练数据作为键。在这种情况下使用矩阵乘法会造成大量的计算浪费,因此我们可以使用向量点积来仅计算对应位置的注意力得分。
HASS 和 EAGLE-3 都对注意力机制进行了类似的修改,以在训练过程中模拟测试过程,但这并非 EAGLE-3 的主要关注点。两种方法的动机、方法和结果截然不同。HASS 的动机在于缓解 EAGLE 中因特征预测不准确而导致的误差累积。HASS 仍然执行特征预测,包含特征预测损失函数 lfeal_{fea}lfea,并且 draft 模型的输入必须是顶层特征。相比之下,EAGLE-3 的动机在于移除不必要的约束以增强模型的表达能力。EAGLE-3 不再要求 draft 模型的输出与目标模型的顶层特征相匹配,从而避免了误差累积。移除特征预测后,EAGLE-3 的输入完全自由,取而代之的是来自不同语义信息层的特征融合。移除特征预测损失函数也使我们能够发现一种此前从未发现的推理加速的新尺度律。图 2 还显示了 EAGLE-3 和 HASS 的加速情况,其中 EAGLE-3 的性能明显更好。
4.Experiments


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)