Claude Agent Skills完全指南(区别于MCP和Plugins)
Claude Agent Skills 完全指南,一个打造专属AI助手的新范式,区别于MCP和Plugins
文章目录
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
✈ 您的一键三连,是我创作的最大动力🌹
Claude Agent Skills 完全指南:打造专属AI助手的新范式
在AI应用开发的浪潮中,如何让Claude真正理解并执行你的工作流程?Agent Skills提供了一种革命性的解决方案——通过文件系统架构实现模块化能力扩展,让AI助手真正成为领域专家。
目录
- 什么是 Agent Skills?
- 核心概念:渐进式信息披露
- Claude Skills vs MCP vs 插件:三大扩展方式对比
- 技术架构深度解析
- 实战应用案例
- 最佳实践与开发指南
- 2025年生态发展展望
什么是 Agent Skills?
Agent Skills 是 Anthropic 于2025年10月推出的一种模块化能力扩展机制,它通过组织化的指令、脚本和资源文件夹,让 Claude 获得特定领域的专业知识和执行能力。
为什么需要 Skills?
传统的 AI 交互方式存在几个痛点:
- 重复性问题:每次对话都需要重新提供相同的背景信息和工作流程
- 上下文限制:大量的说明文档会快速消耗宝贵的上下文窗口
- 知识碎片化:团队知识和最佳实践难以系统化传承
- 可靠性不足:复杂任务的执行步骤容易遗漏或出错
Agent Skills 正是为解决这些问题而生。它让你可以将专业知识、工作流程、最佳实践打包成可重用的"技能包",Claude 会在需要时自动加载和使用。
Skills 的核心优势
核心概念:渐进式信息披露
Skills 最创新的设计是三层加载机制,这种架构确保了极高的令牌效率:
第1层:元数据 (始终加载,~100 tokens/skill)
---
name: pdf-processing
description: 从PDF文件中提取文本和表格、填充表单、合并文档。在处理PDF文件或用户提及PDF、表单或文档提取时使用。
---
启动时,所有 Skills 的元数据都会加载到系统提示中。Claude 知道有哪些 Skills 可用,但不知道具体怎么用——这就像一个目录索引。
第2层:指令 (触发时加载,<5k tokens)
当任务匹配 Skill 描述时,Claude 通过 bash 读取 SKILL.md 的主体内容:
# PDF 处理
## 快速入门
使用 pdfplumber 从PDF中提取文本:
\`\`\`python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
text = pdf.pages[0].extract_text()
\`\`\`
对于高级表单填充,请参阅 [FORMS.md](FORMS.md)。
第3层+:资源和代码 (按需加载,实际无限制)
pdf-skill/
├── SKILL.md # 主要指令
├── FORMS.md # 表单填充指南 (按需读取)
├── REFERENCE.md # 详细API参考 (按需读取)
└── scripts/
├── analyze_form.py # 可执行脚本 (运行,不加载代码)
└── fill_form.py # 表单填充脚本
关键洞察:
- 脚本通过 bash 执行,只有输出消耗令牌,代码本身不进入上下文
- 参考文档在被引用前不消耗任何令牌
- 你可以捆绑大量资源(API文档、示例、数据集)而无成本
这种架构意味着你可以创建包含数百页文档的comprehensive Skills,但只在需要时才加载相关部分。
Claude Skills vs MCP vs 插件:三大扩展方式对比
在 AI 能力扩展领域,目前存在三种主要方案。它们的定位、架构和使用场景各不相同:
核心定义对比
| 维度 | Claude Skills | MCP (Model Context Protocol) | 传统插件 |
|---|---|---|---|
| 本质 | 程序知识包 | 数据连接标准 | 功能扩展模块 |
| 作用 | 教 Claude “怎么做” | 让 Claude “访问什么” | 给平台"添加功能" |
| 类比 | 工作手册/SOP | 数据库连接器 | 浏览器扩展 |
| 标准化 | Anthropic 定义 | 开放协议(跨厂商) | 平台特定 |
技术架构对比
Claude Skills: 基于文件系统的指令集
✓ 文件夹结构组织
✓ Markdown 指令 + Python/Bash 脚本
✓ 渐进式加载(三层机制)
✓ 在代码执行容器中运行
MCP: 客户端-服务器架构
✓ 标准化 JSON-RPC 协议
✓ 双向通信(工具调用 + 资源访问)
✓ 独立进程运行
✓ 支持 Resources、Tools、Prompts、Sampling
传统插件: 平台集成模块
✓ 平台 API 调用
✓ 运行时动态加载
✓ 通常需要网络访问
✓ 平台依赖(OpenAI、Claude.ai 等)
令牌效率对比
这是 Skills 相比 MCP 的核心优势之一:
“GitHub 的官方 MCP 服务器会消耗数万个令牌的上下文,一旦添加几个 MCP 服务器,LLM 几乎没有剩余空间做实际工作。相比之下,Skills 的令牌效率要高得多。”
— Simon Willison, Claude Skills are awesome
原因分析:
- MCP: 需要在上下文中加载完整的工具定义、架构描述、示例
- Skills: 只加载元数据,主体内容按需读取,脚本执行不消耗上下文
使用场景建议
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 访问外部数据源 (数据库、API、文件系统) | MCP | 原生设计目的,标准化连接 |
| 封装工作流程 (代码审查、报告生成、测试流程) | Skills | 程序知识封装,令牌高效 |
| 平台功能增强 (特定网站集成、专有服务) | 插件 | 平台深度集成能力 |
| 复杂数据处理 + 业务流程 | MCP + Skills | MCP提供数据,Skills定义处理逻辑 |
协同使用示例
# MCP 提供数据库访问
# Skills 定义分析流程
# 1. MCP 连接到 BigQuery
mcp_connection = {
"type": "bigquery",
"project": "my-project"
}
# 2. Skills 定义财务分析工作流
skill = {
"type": "custom",
"skill_id": "financial-analysis",
"version": "latest"
}
# Claude 通过 MCP 获取数据,按 Skill 定义的流程分析
response = client.messages.create(
container={"skills": [skill]},
# MCP 工具会自动可用
messages=[{"role": "user", "content": "分析Q4财务数据"}]
)
2025年发展态势
MCP 采用情况:
- OpenAI 于2025年3月正式采用 MCP 标准
- Google DeepMind 在2025年4月确认 Gemini 支持 MCP
- 社区已构建数千个 MCP 服务器
- 所有主流编程语言都有 SDK
Skills 生态:
- Anthropic 提供预构建 Skills: PowerPoint、Excel、Word、PDF
- 企业开始封装内部流程为自定义 Skills
- Claude Code 原生支持 Skills 开发和调试
安全性考量:
2025年4月,安全研究人员指出 MCP 存在多个安全问题:
- 提示注入攻击
- 工具权限组合可能导致文件泄露
- 仿冒工具可能静默替换可信工具
Skills 的沙箱环境(无网络访问)在一定程度上避免了这些问题。
技术架构深度解析
运行时环境
Skills 在代码执行容器中运行,这个环境具有以下特性:
✓ 文件系统访问
✓ Bash 命令执行
✓ Python/Node.js 代码运行
✗ 无网络访问
✗ 无运行时包安装
Claude 如何访问 Skills
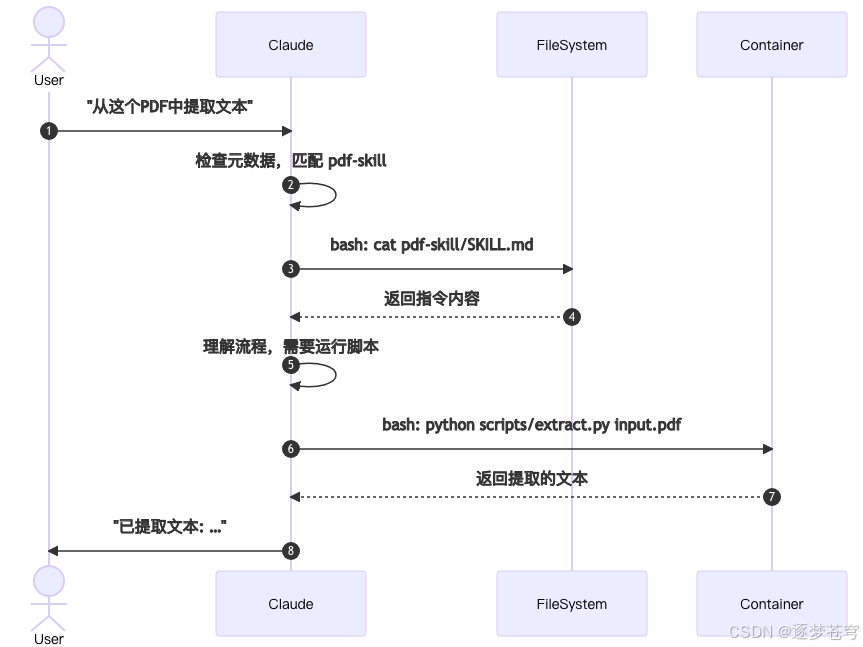
Skill 目录结构最佳实践
my-awesome-skill/
├── SKILL.md # 必需:主指令文件
│ ├── YAML frontmatter # 元数据(name, description)
│ └── Markdown body # 核心工作流指南
│
├── reference/ # 按领域组织的参考文档
│ ├── finance.md # 财务相关架构和查询
│ ├── sales.md # 销售数据说明
│ └── product.md # 产品指标定义
│
├── scripts/ # 可执行脚本(确定性操作)
│ ├── validate.py # 数据验证脚本
│ ├── transform.sh # 数据转换脚本
│ └── analyze.py # 分析脚本
│
├── examples/ # 示例和模板
│ ├── example_query.sql # SQL 查询示例
│ └── report_template.md # 报告模板
│
└── data/ # 静态数据文件
├── schema.json # 数据库架构
└── lookup_table.csv # 查找表
为什么这个架构高效?
-
按需文件访问:Claude 只读取任务需要的文件
- 用户询问销售数据 → 仅读取
reference/sales.md - finance.md、product.md 保持在文件系统,零令牌消耗
- 用户询问销售数据 → 仅读取
-
脚本执行不消耗上下文:
- Claude 运行
python scripts/validate.py data.csv - 脚本代码(可能数百行)不进入上下文
- 只有输出(如 “验证通过” 或错误信息)消耗令牌
- Claude 运行
-
无限制的捆绑内容:
- 可以包含完整的API文档(数千行)
- 大型数据集、广泛示例
- 在访问前不产生任何成本
实战应用案例
案例1:企业客服系统 (40分钟搭建)
某团队使用 Claude Skills 构建了完整的智能客服系统,包含:
技能组合:
skills:
- product-search # 产品搜索技能
- order-query # 订单查询技能
- customer-lookup # 客户信息查询
- return-processing # 退货流程处理
关键技术:
- Next.js 前端
- Clerk 身份认证
- Google ADK 多代理框架
- Skills 实现业务逻辑封装
成果:
- 从概念到上线仅需 40 分钟
- 支持多轮对话上下文
- 业务流程可配置化
来源: Claude Skills 40分钟构建企业级智能客服系统
案例2:财务报表自动化分析
场景:每月需要处理数十份财务报表,提取关键指标并生成分析报告
Skill 设计:
---
name: financial-report-analyzer
description: 自动化财务报表分析,提取关键指标并生成报告。在处理损益表、资产负债表、现金流量表时使用。
---
# 财务报表分析器
## 工作流程
1. 识别报表类型(P&L/Balance Sheet/Cash Flow)
2. 从 reference/accounting_standards.md 获取会计准则
3. 从 reference/tax_laws.md 获取税法规定
4. 执行数据提取 → 验证 → 分析 → 报告生成
5. 使用 pandas 和 openpyxl 生成Excel报告
## 验证规则
运行验证脚本确保数据完整性:
\`\`\`bash
python scripts/validate_financial_data.py input.xlsx
\`\`\`
如果验证失败,检查:
- 必填字段完整性
- 数值格式正确性
- 借贷平衡关系
成果:
- 处理时间从 “一天工作量” 降至 “一小时完成”
- 数据准确率接近100%
- 可复用于不同会计期间
案例3:代码审查工作流
技术架构:
# skill 结构
code-review-skill/
├── SKILL.md # 审查流程指南
├── checklists/
│ ├── security.md # 安全检查清单
│ ├── performance.md # 性能检查清单
│ └── style.md # 代码风格检查清单
└── scripts/
├── run_linters.sh # 运行代码检查工具
└── generate_report.py # 生成审查报告
工作流定义:
## 代码审查流程
复制此清单并跟踪进度:
\`\`\`
审查进度:
- [ ] 步骤1: 运行自动化检查工具
- [ ] 步骤2: 分析代码结构和组织
- [ ] 步骤3: 检查安全隐患
- [ ] 步骤4: 验证性能考虑
- [ ] 步骤5: 生成审查报告
\`\`\`
**步骤1: 运行自动化工具**
\`\`\`bash
bash scripts/run_linters.sh src/
\`\`\`
**步骤2-4**: 参考对应的检查清单文档...
优势:
- 标准化审查流程
- 不遗漏关键检查点
- 可累积最佳实践
案例4:文档自动生成 (PowerPoint/Excel)
Anthropic 提供的预构建 Skills 可以直接使用:
import anthropic
client = anthropic.Anthropic()
# 使用 PowerPoint Skill 创建演示文稿
response = client.beta.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=4096,
betas=["code-execution-2025-08-25", "skills-2025-10-02"],
container={
"skills": [
{"type": "anthropic", "skill_id": "pptx", "version": "latest"}
]
},
messages=[{
"role": "user",
"content": "创建一个关于可再生能源的5页演示文稿"
}],
tools=[{"type": "code_execution_20250825", "name": "code_execution"}]
)
# 下载生成的文件
file_id = extract_file_id(response)
file_content = client.beta.files.download(
file_id=file_id,
betas=["files-api-2025-04-14"]
)
file_content.write_to_file("renewable_energy.pptx")
可用的预构建 Skills:
pptx- PowerPoint 演示文稿xlsx- Excel 电子表格docx- Word 文档pdf- PDF 文档生成
最佳实践与开发指南
核心原则
1. 简洁是关键
上下文窗口是公共资源。只添加 Claude 没有的知识:
❌ 不好的例子 (过于冗长,~150 tokens):
## 提取PDF文本
PDF(便携式文档格式)文件是一种常见的文件格式,包含文本、图像和其他内容。
要从PDF中提取文本,您需要使用一个库。有许多库可用于PDF处理,但我们建议
使用 pdfplumber,因为它易于使用且能处理大多数情况。首先,您需要使用 pip
安装它。然后您可以使用下面的代码...
✅ 好的例子 (简洁明了,~50 tokens):
## 提取PDF文本
使用 pdfplumber 进行文本提取:
\`\`\`python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
\`\`\`
2. 设置适当的自由度
根据任务的脆弱性匹配具体程度:
高自由度 (基于启发式):
## 代码审查流程
1. 分析代码结构和组织
2. 检查潜在的错误或边界情况
3. 建议改进可读性和可维护性
4. 验证是否遵守项目约定
低自由度 (特定脚本):
## 数据库迁移
运行完全相同的脚本:
\`\`\`bash
python scripts/migrate.py --verify --backup
\`\`\`
⚠️ 不要修改命令或添加其他标志。
类比:
- 窄桥 (两侧悬崖) → 低自由度,精确指令
- 开阔田野 (无危险) → 高自由度,一般方向
3. 使用所有目标模型测试
Skills 的有效性依赖于底层模型:
- Claude Haiku (快速、经济) → 可能需要更多细节
- Claude Sonnet (平衡) → 适中的指导
- Claude Opus (强大推理) → 避免过度解释
技术最佳实践
渐进式披露模式
模式1: 高级指南 vs 参考
# PDF 处理
## 快速开始
[基本用法说明]
## 高级功能
**表单填充**: 参阅 [FORMS.md](FORMS.md) 获取完整指南
**API参考**: 参阅 [REFERENCE.md](REFERENCE.md) 获取所有方法
Claude 只在需要高级功能时加载对应文档。
模式2: 特定领域组织
bigquery-skill/
├── SKILL.md # 概述和导航
└── reference/
├── finance.md # 收入、计费指标
├── sales.md # 机会、管道
├── product.md # API使用、功能
└── marketing.md # 活动、归因
当用户询问销售指标时,Claude 只读取 sales.md,其他文件不消耗令牌。
避免深层嵌套引用
❌ 不好: 引用链太深
SKILL.md → advanced.md → details.md → actual_info.md
Claude 可能只部分读取文件,导致信息不完整。
✅ 好: 保持一级引用
# SKILL.md
**基本用法**: [本文档中的说明]
**高级功能**: 参阅 [advanced.md](advanced.md)
**API参考**: 参阅 [reference.md](reference.md)
提供可验证的中间输出
对复杂任务使用 “计划-验证-执行” 模式:
## PDF表单填充工作流
1. **分析表单** → 生成 fields.json
2. **验证映射** → 运行 validate_fields.py
3. **仅在验证通过后执行填充**
4. **验证输出** → 运行 verify_output.py
如果验证失败,返回步骤2修复问题。
这种模式可以及早捕获错误,避免在错误数据上执行破坏性操作。
开发工作流
与 Claude 协同开发
最有效的开发模式是与 Claude 协作:
-
在没有 Skill 的情况下完成任务 (与 Claude A 对话)
- 自然提供上下文和指导
- 注意重复提供的信息
-
识别可重用模式
- 哪些信息对类似任务有用?
- 哪些规则需要始终遵循?
-
要求 Claude A 创建 Skill
"创建一个 Skill 来捕获我们刚刚使用的 BigQuery 分析模式。 包括表架构、命名约定和关于过滤测试账户的规则。" -
审查简洁性
"删除关于什么是赢率的解释 - Claude 已经知道这个。" -
在类似任务上测试 (与 Claude B - 新实例)
- 观察 Claude B 如何使用 Skill
- 是否正确应用规则?
- 是否遗漏了什么?
-
迭代改进
"当 Claude 使用此 Skill 时,它忘记了为 Q4 按日期过滤。 我们应该添加关于日期过滤模式的部分吗?"
这种分层迭代模式让你能够:
- 基于真实使用而不是假设改进 Skills
- 发现你自己使用中的盲点
- 持续优化 Skill 的有效性
命名和组织规范
命名约定 (使用动名词):
- ✅
processing-pdfs - ✅
analyzing-spreadsheets - ✅
managing-databases - ❌
helper(太模糊) - ❌
anthropic-tools(包含保留字)
描述编写 (第三人称,包含触发条件):
description: 从PDF文件中提取文本和表格、填充表单、合并文档。在处理PDF文件或用户提及PDF、表单或文档提取时使用。
安全考虑
⚠️ 仅使用可信来源的 Skills
恶意 Skill 可能:
- 指导 Claude 调用工具执行非预期操作
- 泄露敏感数据到外部系统
- 创建冲突或错误的输出
安全清单:
- ✅ 审查所有捆绑文件(SKILL.md、脚本、资源)
- ✅ 检查是否有异常的网络调用或文件访问
- ✅ 验证外部URL的可信度
- ✅ 在沙箱环境中测试
- ❌ 不要使用未经审查的第三方 Skills
- ❌ 注意从外部URL获取内容的 Skills
2025年生态发展展望
行业采用趋势
企业级应用:
- NBIM、Brex 等企业在 AWS Bedrock 上构建可靠的 AI 代理
- Rakuten 通过 Skills 实现效率提升:“一天工作量” → “一小时完成”
- 越来越多的企业开始封装内部 SOP 为自定义 Skills
开发者生态:
- Claude Code 成为 Skills 开发的主要工具
- Skills marketplace 可能在2025年下半年推出
- 社区贡献的 Skills 数量快速增长
技术演进方向
1. Skills 与 MCP 的深度集成
# 未来可能的集成方式
response = client.messages.create(
container={
"skills": [
{
"type": "custom",
"skill_id": "financial-analysis",
"mcp_connections": ["bigquery", "excel"] # Skill 声明需要的 MCP 连接
}
]
}
)
2. 版本管理和依赖解析
# SKILL.md frontmatter 可能的扩展
---
name: advanced-analytics
version: 2.0.0
dependencies:
skills:
- data-preprocessing: "^1.5.0"
- visualization: "^2.0.0"
mcp:
- bigquery: "latest"
---
3. Skills 组合和继承
# base-reporting-skill/SKILL.md
## 基础报告流程
[通用报告生成逻辑]
---
# sales-reporting-skill/SKILL.md
---
extends: base-reporting-skill
---
## 销售报告专用配置
[覆盖或扩展基础配置]
潜在挑战
安全性:
- Skill 注入攻击的防范
- 权限边界的明确定义
- 审计和合规性要求
可维护性:
- Skills 的版本冲突处理
- 大规模 Skills 管理
- 团队协作和知识共享
性能优化:
- 更智能的 Skill 匹配算法
- 预测性加载机制
- 上下文窗口管理优化
结语:Skills 开启 AI 应用新范式
Agent Skills 代表了一种范式转变:从 “每次对话重新教AI” 转向 “系统化封装可重用知识”。
它的核心创新在于:
- 渐进式信息披露 - 极高的令牌效率
- 文件系统架构 - 灵活而强大
- 程序知识封装 - 可传承、可复用
相比 MCP (数据连接)和传统插件(功能扩展),Skills 专注于 “如何做” 的知识传递,填补了 AI 应用开发的重要空白。
2025年,随着企业对 AI 应用的深入,Skills 生态必将迎来爆发性增长。那些能够有效封装领域知识、构建 Skills 库的组织,将在 AI 时代获得显著的竞争优势。
立即开始:
- 识别团队中重复性的工作流程
- 将最佳实践文档化为 Skills
- 通过 Claude API 或 Claude Code 实验
- 持续迭代优化,构建你的 Skills 资产
AI 不仅仅是工具,更是知识的载体。而 Skills,正是让这些知识得以传承和放大的关键。
参考资源
官方文档
技术深度分析
- Claude Skills vs MCP vs LLM Tools: 2025 Comparison Guide
- Claude Agent Skills: A First Principles Deep Dive
- Understanding Claude Code's Full Stack
- Skills explained: How Skills compares to prompts, Projects, MCP, and subagents
实战案例
- Claude Skills 40分钟构建企业级智能客服系统
- Getting Started with Claude Skills - Neon
- 如何在 Claude 与 Claude Code 中创建并使用 Skills
MCP 相关
- Introducing the Model Context Protocol
- Code execution with MCP: building more efficient AI agents
- A Complete Guide to the Model Context Protocol (MCP) in 2025
社区讨论

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)