CANN 架构深度解析:从技术原理到工程实践(昇腾 AI 异构计算核心)
引言:CANN 是什么?为什么重要?
在 AI 算力需求爆炸式增长的背景下,异构计算(CPU+GPU/AI 加速器)已成为支撑大模型训练、推理及高性能计算的核心架构。然而,不同硬件架构的编程接口差异、算力调度效率低下、算子开发复杂度高等问题,长期制约着 AI 应用的落地效率。
华为推出的 CANN(Compute Architecture for Neural Networks,神经网络计算架构) 正是为解决这一痛点而生 —— 它是昇腾 AI 生态的核心软件底座,通过 “统一编程接口 + 高效算力调度 + 自动算子优化”,打通了从 AI 框架到昇腾 AI 处理器(Ascend 910/310 等)的全栈链路,让开发者无需关注底层硬件细节,即可高效利用昇腾算力。
本文将从 概念定义、核心架构、技术原理、实践案例、生态资源 五个维度,系统讲解 CANN 的技术细节,并附带可复现的代码示例与权威参考链接,为 AI 开发者提供从理论到工程落地的完整指南。
一、CANN 核心概念与技术定位
在深入技术细节前,需先明确 CANN 的核心术语与生态定位,避免后续理解偏差。
1.1 CANN 的核心定义
根据华为昇腾官方文档(CANN 技术白皮书),CANN 是:
一套面向昇腾 AI 处理器的异构计算架构,提供从算子开发、模型训练 / 推理到应用部署的全流程工具链,通过 “硬件抽象 + 自动优化” 降低异构计算编程门槛,同时最大化释放昇腾 AI 处理器的算力性能。
1.2 CANN 与昇腾生态的关系
CANN 处于昇腾 AI 生态的 “软件中间件层”,承上启下:
- 向上:对接 MindSpore、TensorFlow、PyTorch 等主流 AI 框架(通过 Framework Engine 适配);
- 向下:管理昇腾 AI 处理器的计算核心(如 AI Core、AI CPU)、存储资源(Global Memory、Local Memory);
- 向外:提供算子开发工具(TE/TBE)、性能分析工具(Profiling)、部署工具(Ascend Deploy Manager)。
其生态层级可简化为:
plaintext
应用层(AI 业务:如大模型推理、计算机视觉)
↓
框架层(MindSpore/TensorFlow/PyTorch)
↓
CANN 层(算子库、算力调度、自动优化)
↓
硬件层(昇腾 AI 处理器:Ascend 910/310/710)
1.3 关键术语辨析
| 术语 | 全称 | 核心作用 |
|---|---|---|
| AI Core | AI 计算核心 | 昇腾处理器的核心算力单元,负责执行矩阵运算、向量运算等 AI 密集型任务 |
| AI CPU | AI 控制核心 | 负责执行 scalar 运算、流程控制等轻量级任务,辅助 AI Core 提升效率 |
| TE | Tensor Engine | CANN 的算子开发接口,支持开发者自定义高性能算子(基于 DSL 语法) |
| TBE | Tensor Boost Engine | CANN 内置的算子优化引擎,自动对算子进行融合、并行化、数据排布优化 |
| FE | Framework Engine | CANN 与 AI 框架的适配层,实现框架算子到 CANN 算子的映射 |
| ATC | Ascend Tensor Compiler | CANN 的模型编译工具,将 TensorFlow/PyTorch 模型转为昇腾可执行的 om 模型 |
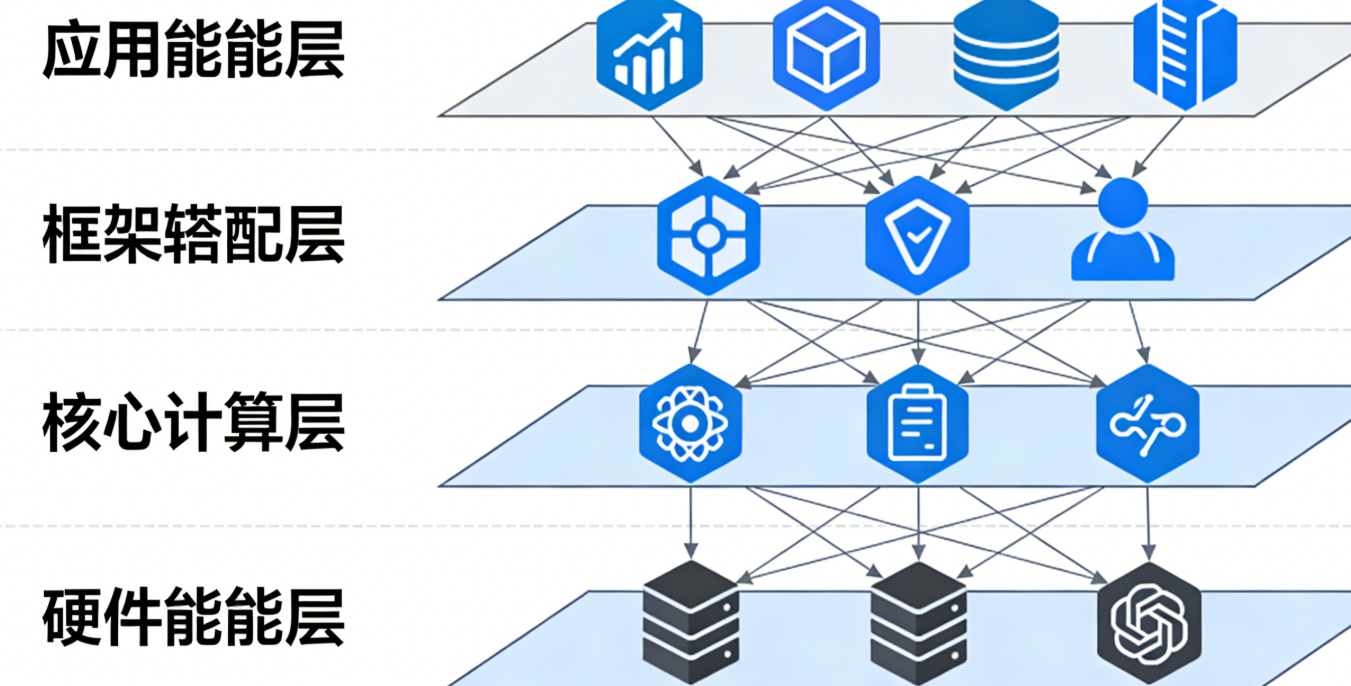
二、CANN 核心技术架构深度解析
CANN 采用 “分层解耦 + 模块化设计”,核心架构分为 4 层,每层职责明确且可独立扩展。以下结合华为官方架构图(CANN 架构文档)展开讲解。
2.1 应用使能层(Application Enablement Layer)
定位:为开发者提供 “零门槛” 的应用开发接口,无需关注底层算力细节。核心组件:
- Ascend SDK:提供 C/C++/Python 接口,支持快速开发推理 / 训练应用(如视频分析、NLP 任务);
- ModelZoo:昇腾官方预训练模型库(Ascend ModelZoo),包含 ResNet、BERT、YOLO 等主流模型的 CANN 适配版本,可直接下载使用;
- Sample Code:场景化示例代码(如 “图片分类”“目标检测”),覆盖从模型加载到结果输出的全流程。
示例场景:开发者通过 Ascend SDK 的 aclrtCreateContext 接口初始化昇腾设备,调用 aclmdlLoadFromFile 加载 om 模型,即可完成推理应用的核心流程(后续实践部分会详细演示)。
2.2 框架适配层(Framework Adaptation Layer)
定位:解决 AI 框架与硬件的 “兼容性问题”,让主流框架无需修改代码即可运行在昇腾上。核心能力:
- 多框架支持:已适配 MindSpore(原生支持)、TensorFlow(1.x/2.x)、PyTorch(1.10+)、MXNet 等;
- 算子映射:将框架原生算子(如 TensorFlow 的
tf.matmul)自动映射为 CANN 算子库中的优化算子; - 自动降级:若框架算子无直接匹配的 CANN 算子,FE 会自动通过 TE 生成临时算子,保障模型正常运行。
技术细节:以 TensorFlow 适配为例,CANN 通过 TensorFlow Plugin 机制,在 TensorFlow 执行图构建阶段,将计算密集型算子(如卷积、全连接)替换为 CANN 优化算子,轻量级算子(如 tf.add)由 CPU 执行,实现 “算力最优分配”。
2.3 核心计算层(Core Computing Layer)
定位:CANN 的 “算力调度大脑”,负责算子优化、内存管理、任务调度,是性能优化的核心。核心组件与技术:
(1)算子库与算子开发工具
- 内置算子库:包含 2000+ 常用 AI 算子(覆盖 CNN、Transformer、RNN 等网络结构),经 TBE 优化后,性能比通用实现高 30%+(华为昇腾性能报告);
- TE(Tensor Engine):开发者自定义算子的核心接口,基于 DSL(领域特定语言)语法,支持对算子的计算逻辑、数据排布、并行策略进行精细化控制;
- AutoTune:算子自动调优工具,通过遍历不同的算子参数(如线程数、数据分块大小),找到性能最优的配置(无需人工干预)。
(2)任务调度与内存优化
- 异构任务调度:基于 “任务依赖图”(DAG),自动调度 AI Core、AI CPU、CPU 的任务执行顺序,避免资源空闲;
- 内存池管理:通过 “内存复用”“按需分配” 减少内存申请 / 释放开销,支持 Global Memory(全局内存)与 Local Memory(片上内存)的高效数据搬运;
- 算子融合:自动将多个连续的算子(如 Conv + BatchNorm + Relu)融合为一个算子,减少数据在内存中的搬运次数(可降低 20%-50% 的内存带宽消耗)。
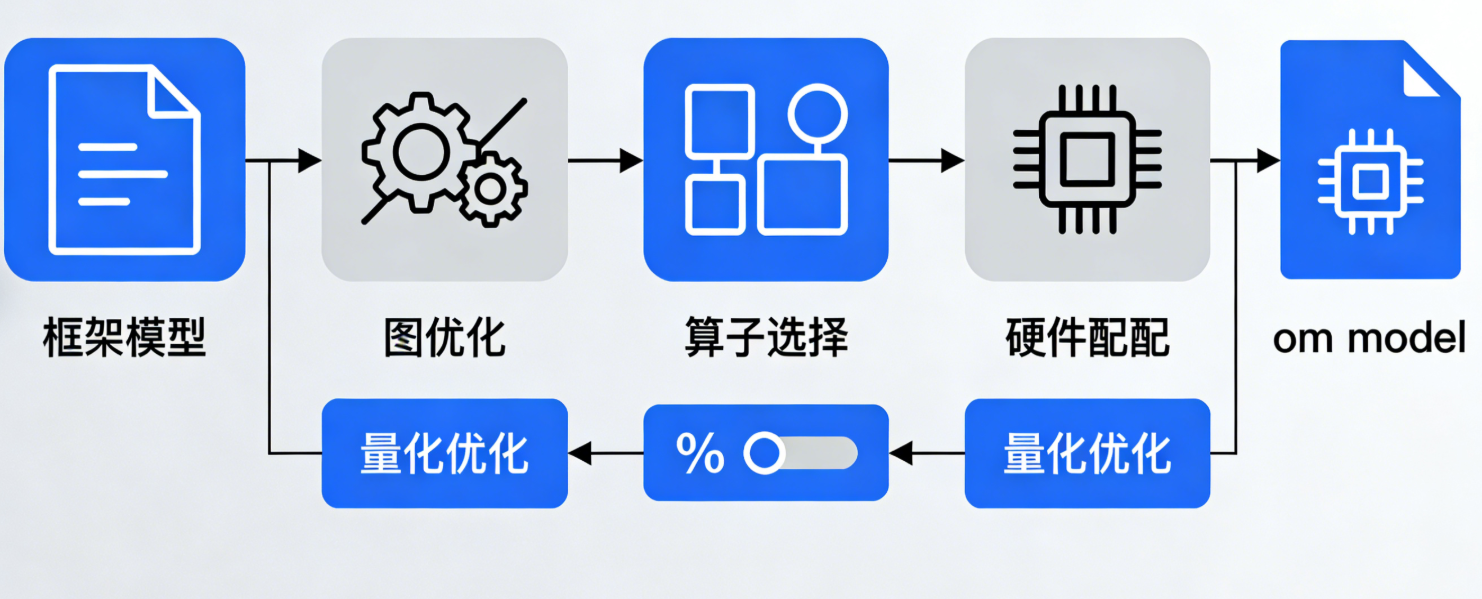
(3)编译优化(ATC 工具)
ATC(Ascend Tensor Compiler)是 CANN 模型编译的核心工具,负责将 “框架模型”(如 TensorFlow 的 pb 模型)转为 “昇腾可执行模型”(om 模型),核心优化步骤包括:
- 图优化:删除冗余节点、算子融合、常量折叠;
- 算子选择:为每个计算节点匹配最优的 CANN 算子(优先选择内置优化算子);
- 硬件适配:根据目标昇腾设备(如 Ascend 310)的硬件参数(如 AI Core 数量),生成对应的指令集;
- 量化优化:支持 INT8/FP16 量化,在保证精度的前提下提升性能(如 INT8 量化可使推理性能提升 2-4 倍)。
2.4 硬件使能层(Hardware Enablement Layer)
定位:CANN 与昇腾硬件的 “桥梁”,实现对硬件资源的抽象与管控。核心能力:
- 硬件抽象接口:提供统一的硬件资源访问接口(如 AI Core 数量、内存大小),上层无需关注硬件型号差异;
- 驱动适配:对接昇腾设备驱动(Ascend Driver),负责指令下发、数据搬运、硬件状态监控;
- 功耗与热管理:根据任务负载动态调整硬件功耗(如低负载时降低 AI Core 频率),平衡性能与功耗。
三、CANN 工程实践:从环境搭建到算子开发
理论需结合实践,本节将通过 3 个核心案例(环境搭建、自定义算子开发、模型推理),带大家亲手体验 CANN 的使用流程,所有代码均可复现(基于 CANN 6.0.RC1 版本,昇腾 310 设备)。
3.1 环境搭建:Ubuntu + CANN + 昇腾驱动
前置条件
- 硬件:昇腾 310 开发者套件(如 Atlas 200 DK)或云服务器(华为云 ECS 昇腾实例);
- 系统:Ubuntu 18.04/20.04(64 位);
- 依赖:gcc 7.5.0、g++ 7.5.0、Python 3.7-3.9。
步骤 1:安装昇腾驱动
- 下载驱动包(需注册华为账号):昇腾驱动下载页(选择与硬件匹配的版本,如 Atlas 200 DK 对应驱动版本 22.0.2);
- 安装驱动依赖:
bash
运行
sudo apt-get install -y dkms gcc make linux-headers-$(uname -r) - 执行驱动安装脚本:
bash
运行
chmod +x Ascend-hdk-910-npu-driver_22.0.2_linux-x86_64.run sudo ./Ascend-hdk-910-npu-driver_22.0.2_linux-x86_64.run --install - 验证驱动安装:
bash
运行
npu-smi info # 若输出昇腾设备信息,说明驱动安装成功
步骤 2:安装 CANN 开发套件
- 下载 CANN 包(CANN 下载页),选择 “开发套件(Ascend-cann-toolkit)”;
- 解压并安装 CANN:
bash
运行
tar -zxvf Ascend-cann-toolkit_6.0.RC1_linux-x86_64.run sudo ./Ascend-cann-toolkit_6.0.RC1_linux-x86_64.run --install --install-path=/usr/local/Ascend - 配置环境变量(在
~/.bashrc中添加):bash
运行
export ASCEND_HOME=/usr/local/Ascend export PATH=$ASCEND_HOME/ascend-toolkit/latest/bin:$ASCEND_HOME/ascend-toolkit/latest/compiler/bin:$PATH export LD_LIBRARY_PATH=$ASCEND_HOME/ascend-toolkit/latest/lib64:$LD_LIBRARY_PATH - 生效环境变量并验证:
bash
运行
source ~/.bashrc atc --version # 若输出 AT版本信息,说明 CANN 安装成功
3.2 案例 1:用 TE 开发自定义加法算子
场景:实现一个简单的 “张量加法” 算子(输入两个 Tensor,输出其元素 - wise 和),并通过 CANN 编译验证。
步骤 1:编写 TE 算子代码(add_op.py)
python
运行
import te.lang.cce
from te import tvm
from te.platform.cce_conf import api_check_support
from te.utils.op_utils import *
from topi import generic
# 1. 定义算子接口(输入输出参数、属性)
@check_op_params(REQUIRED_INPUT, REQUIRED_INPUT, REQUIRED_OUTPUT, KERNEL_NAME)
def add_op(x1, x2, y, kernel_name="add_op"):
# 2. 检查输入参数合法性(数据类型、形状)
check_dtype(x1.dtype, ["float32"], param_name="x1")
check_dtype(x2.dtype, ["float32"], param_name="x2")
check_shape(x1.shape, param_name="x1")
check_shape(x2.shape, param_name="x2")
if x1.shape != x2.shape:
raise RuntimeError("x1 and x2 must have the same shape!")
# 3. 获取输入 Tensor 的 TVM 表达式
x1_tensor = tvm.placeholder(x1.shape, name="x1", dtype=x1.dtype)
x2_tensor = tvm.placeholder(x2.shape, name="x2", dtype=x2.dtype)
# 4. 定义计算逻辑(元素-wise 加法)
with tvm.target.cce():
res = te.lang.cce.vadd(x1_tensor, x2_tensor) # TE 内置向量加法接口
sch = generic.auto_schedule(res) # 自动生成调度策略
# 5. 构建算子并输出
config = {"print_ir": False, "name": kernel_name, "need_build": True, "auto_broadcast": False}
te.lang.cce.cce_build_code(sch, [x1_tensor, x2_tensor, res], config)
步骤 2:编写算子测试代码(test_add_op.py)
python
运行
import numpy as np
from add_op import add_op
import te.platform.cce as cce
# 1. 生成测试数据(float32 类型,形状为 (2,3))
x1_data = np.random.rand(2, 3).astype(np.float32)
x2_data = np.random.rand(2, 3).astype(np.float32)
expect_data = x1_data + x2_data # 预期结果
# 2. 初始化昇腾设备上下文
cce.init()
# 3. 调用自定义算子
output = cce.ndarray.empty_like(cce.ndarray.array(x1_data))
add_op(cce.ndarray.array(x1_data), cce.ndarray.array(x2_data), output, kernel_name="add_op_test")
# 4. 验证结果(误差小于 1e-5 则视为成功)
output_data = output.asnumpy()
if np.allclose(output_data, expect_data, atol=1e-5):
print("自定义加法算子测试成功!")
else:
print("自定义加法算子测试失败!")
print("预期结果:", expect_data)
print("实际结果:", output_data)
步骤 3:运行测试并验证
bash
运行
python3 test_add_op.py # 若输出“测试成功”,说明自定义算子开发正确

\3.3 案例 2:用 CANN 实现 ResNet50 模型推理
场景:将 TensorFlow 预训练的 ResNet50 模型,通过 ATC 编译为 om 模型,再通过 CANN SDK 实现图片分类推理。
步骤 1:准备预训练模型
- 下载 TensorFlow ResNet50 模型(TensorFlow Hub 链接);
- 将模型转为 pb 格式(若已为 pb 格式可跳过):
python
运行
import tensorflow as tf import tensorflow_hub as hub # 加载模型并保存为 pb model = hub.KerasLayer("https://tfhub.dev/tensorflow/resnet_50/classification/1") input_tensor = tf.keras.Input(shape=(224, 224, 3), dtype=tf.float32) output_tensor = model(input_tensor) tf.saved_model.save(model, "./resnet50_tf") # 转换为 pb 格式 converter = tf.lite.TFLiteConverter.from_saved_model("./resnet50_tf") converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS, tf.lite.OpsSet.SELECT_TF_OPS] tflite_model = converter.convert() with open("resnet50.tflite", "wb") as f: f.write(tflite_model)
步骤 2:用 ATC 编译模型为 om 格式
bash
运行
# 编译命令:--model 为输入模型,--framework 为框架类型,--output 为输出 om 模型,--input_shape 为输入形状
atc --model=resnet50.tflite --framework=5 --output=resnet50_om --input_shape="input_1:1,224,224,3" --log=info
--framework=5:表示输入模型为 TFLite 格式(TensorFlow 为 3,PyTorch 为 6);- 若编译成功,会在当前目录生成
resnet50_om.om文件。
步骤 3:用 CANN SDK 实现推理代码(resnet50_infer.py)
python
运行
import cv2
import numpy as np
from ascend.sdk import acl
# 1. 初始化 ACL 环境(CANN SDK 核心接口)
acl.init()
# 2. 选择昇腾设备(0 表示第一个设备)
device_id = 0
acl.rt.set_device(device_id)
# 3. 创建上下文
context, ret = acl.rt.create_context(device_id)
# 4. 加载 om 模型
model_path = "./resnet50_om.om"
model_id, ret = acl.mdl.load_from_file(model_path)
# 获取模型描述信息
model_desc = acl.mdl.create_desc()
ret = acl.mdl.get_desc(model_desc, model_id)
# 5. 准备输入数据(预处理:读取图片→Resize→归一化)
def preprocess_image(image_path):
# 读取图片
img = cv2.imread(image_path)
# Resize 到 224x224
img = cv2.resize(img, (224, 224))
# BGR→RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 归一化(ResNet50 要求输入归一化到 [0,1])
img = img / 255.0
# 调整形状为 (1,224,224,3)(batch_size=1)
img = np.expand_dims(img, axis=0).astype(np.float32)
return img
# 读取并预处理图片(替换为你的图片路径)
input_data = preprocess_image("./cat.jpg")
# 分配输入内存(设备侧内存)
input_size = input_data.nbytes
input_ptr, ret = acl.rt.malloc(input_size, acl.rt.MEMORY_DEVICE)
# 将主机侧数据拷贝到设备侧
ret = acl.rt.memcpy(input_ptr, input_size, input_data.ctypes.data, input_size, acl.rt.MEMCPY_HOST_TO_DEVICE)
# 6. 准备输出内存
output_num = acl.mdl.get_num_outputs(model_desc)
output_ptr_list = []
output_size_list = []
for i in range(output_num):
output_size = acl.mdl.get_output_size_by_index(model_desc, i)
output_size_list.append(output_size)
output_ptr, ret = acl.rt.malloc(output_size, acl.rt.MEMORY_DEVICE)
output_ptr_list.append(output_ptr)
# 7. 执行模型推理
input_ptr_list = [input_ptr]
ret = acl.mdl.execute(model_id, input_ptr_list, output_ptr_list)
# 8. 处理输出结果(设备侧→主机侧,解析分类结果)
output_data = np.zeros(output_size_list[0] // 4, dtype=np.float32) # float32 占 4 字节
ret = acl.rt.memcpy(output_data.ctypes.data, output_size_list[0], output_ptr_list[0], output_size_list[0], acl.rt.MEMCPY_DEVICE_TO_HOST)
# 获取概率最大的类别(ResNet50 输出 1000 个类别的概率)
pred_class = np.argmax(output_data)
# 加载 ImageNet 类别标签(可从 https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt 下载)
with open("ImageNetLabels.txt", "r") as f:
labels = f.readlines()
print(f"推理结果:类别 {pred_class},标签 {labels[pred_class].strip()}")
# 9. 释放资源(避免内存泄漏)
for ptr in output_ptr_list:
acl.rt.free(ptr)
acl.rt.free(input_ptr)
acl.mdl.destroy_desc(model_desc)
acl.mdl.unload(model_id)
acl.rt.destroy_context(context)
acl.rt.reset_device(device_id)
acl.finalize()
步骤 4:运行推理并验证
- 下载 ImageNet 类别标签:ImageNetLabels.txt;
- 准备一张测试图片(如 cat.jpg);
- 运行推理代码:
bash
运行
若输出类似 “推理结果:类别 285,标签 Egyptian cat”,说明推理成功。python3 resnet50_infer.py
四、CANN 性能优化技巧与工具
在工程落地中,“性能” 是核心需求。CANN 提供了丰富的优化工具与策略,以下介绍常用的 3 种优化方向。
4.1 算子级优化:AutoTune 自动调优
对于自定义算子或性能未达标的内置算子,可通过 AutoTune 工具自动优化参数(如线程数、数据分块大小、计算单元选择)。
使用步骤
- 准备算子配置文件(autotune_config.json):
json
{ "op_name": "add_op", "input_shapes": [[2,3]], "input_dtypes": ["float32"], "output_shapes": [[2,3]], "output_dtypes": ["float32"], "tune_iterations": 100 # 调优迭代次数(越多越可能找到最优解) } - 运行 AutoTune:
bash
运行
autotune --config=autotune_config.json --output=autotune_result.json - 应用调优结果:在算子代码中加载
autotune_result.json,即可使用优化后的参数。
4.2 模型级优化:ATC 编译参数调整
通过 ATC 的编译参数,可进一步提升模型性能,常用参数如下:
| 参数 | 作用 | 示例 |
|---|---|---|
| --precision_mode | 精度模式(支持 FP32/FP16/INT8) | --precision_mode=force_fp16(强制用 FP16 计算,提升性能) |
| --fusion_switch_file | 算子融合配置文件 | 自定义哪些算子需要融合(减少数据搬运) |
| --dynamic_batch_size | 动态 batch 大小 | --dynamic_batch_size=1,2,4(支持多 batch 推理,提升灵活性) |
| --input_format | 输入数据格式 | --input_format=NCHW(若模型要求 NCHW 格式,需显式指定) |
示例:用 FP16 精度编译 ResNet50 模型:
bash
运行
atc --model=resnet50.tflite --framework=5 --output=resnet50_om_fp16 --input_shape="input_1:1,224,224,3" --precision_mode=force_fp16
4.3 性能分析:Profiling 工具
CANN 的 Profiling 工具可精准定位性能瓶颈(如算子耗时、内存搬运耗时、任务调度耗时),步骤如下:
- 配置 Profiling(在推理代码中添加 Profiling 初始化):
python
运行
# 初始化 Profiling profiler = acl.prof.create_profiler() acl.prof.start_profiler(profiler, acl.prof.PROF_ALL) # 采集所有类型的性能数据 # ... 执行推理代码 ... # 停止并保存 Profiling 结果 acl.prof.stop_profiler(profiler) acl.prof.save_profiler(profiler, "./profiling_result") acl.prof.destroy_profiler(profiler) - 运行推理代码,生成 Profiling 结果文件(如
profiling_result.zip); - 用 Ascend Profiler 可视化工具(下载链接)打开结果,分析:
- 算子耗时 Top10(识别耗时最长的算子);
- 内存带宽利用率(若利用率低,需优化数据搬运);
- AI Core 利用率(若利用率低,需增加任务并行度)。
五、CANN 生态资源与学习路径
为帮助开发者快速上手,华为提供了丰富的 CANN 学习资源,以下是核心资源汇总:
5.1 官方文档与工具
- CANN 官方文档:CANN 6.0.RC1 文档中心(包含架构、API、工具使用指南);
- 昇腾开发者社区:昇腾论坛(提问、交流、获取技术支持);
- Ascend Samples:GitHub 代码仓库(包含 100+ 场景化示例,如大模型推理、视频分析);
- 昇腾 ModelZoo:Gitee 仓库(预训练模型库,支持直接下载使用)。
5.2 学习路径(从入门到精通)
-
入门阶段:
- 学习《CANN 快速入门》(链接),掌握环境搭建与基础 API;
- 运行 Ascend Samples 中的 “图片分类”“目标检测” 示例,理解推理流程。
-
进阶阶段:
- 学习《TE 算子开发指南》(链接),掌握自定义算子开发;
- 学习《ATC 模型编译优化指南》,理解模型优化的核心策略。
-
精通阶段:
- 基于 Profiling 工具进行性能调优,解决工程中的性能瓶颈;
- 参与昇腾开源项目(如 MindSpore、CANN 算子库),贡献代码。
六、总结与展望
CANN 作为昇腾 AI 生态的核心软件底座,通过 “统一接口 + 自动优化 + 全栈工具链”,有效解决了异构计算的编程门槛高、算力利用率低的问题。本文从概念、架构、实践、优化四个维度,系统讲解了 CANN 的技术细节,并通过可复现的代码示例,帮助开发者快速上手。
未来,随着大模型、生成式 AI 的发展,CANN 将进一步聚焦以下方向:
- 大模型优化:针对 GPT、LLaMA 等大模型,提供更高效的算子融合、内存复用策略,降低大模型推理的显存占用;
- 多硬件支持:除昇腾处理器外,逐步支持更多异构硬件(如 GPU、CPU),实现 “一次开发,多硬件运行”;
- 开源生态:进一步开放算子库、优化工具的源代码,吸引更多开发者参与生态建设。
对于 AI 开发者而言,掌握 CANN 不仅能提升昇腾硬件的使用效率,更能深入理解异构计算的核心原理,为应对未来更复杂的 AI 算力需求奠定基础。建议大家结合官方资源与实践案例,逐步深入,将 CANN 技术应用到实际业务中。
参考链接汇总:
- CANN 官方文档:https://www.hiascend.com/document/detail/zh/cann/601/index.html
- 昇腾驱动下载:https://www.hiascend.com/hardware/driver-document
- Ascend Samples:https://github.com/Ascend/samples
- 昇腾 ModelZoo:https://gitee.com/ascend/modelzoo
- CANN 技术白皮书:https://www.hiascend.com/document/detail/zh/cann/601/overview/intro/intro-0000001527958997
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)