通过Flink 1.19 客户端实现Flink集群连接paimon基础测试
python版本:3.8.20该测试旨在描述如何通过 Python 自动化脚本远程连接 Flink 集群,并对 Paimon 数据湖格式进行基础的 CRUD(增删改查)及压力测试。描述了一套基于 Pythonparamiko库实现的自动化测试流程。该流程通过 SSH 连接到部署了 Flink 客户端的远程服务器,利用提交 SQL 任务到 Flink on YARN 集群,完成针对 Paimon 表
目录
Step 1: 创建 Paimon Catalog 与测试表
python版本:3.8.20
该测试旨在描述如何通过 Python 自动化脚本远程连接 Flink 集群,并对 Paimon 数据湖格式进行基础的 CRUD(增删改查)及压力测试。描述了一套基于 Python paramiko 库实现的自动化测试流程。该流程通过 SSH 连接到部署了 Flink 客户端的远程服务器,利用 sql-client.sh 提交 SQL 任务到 Flink on YARN 集群,完成针对 Paimon 表的批量读写、更新和删除操作,并进行数据一致性校验。
1 测试目标
-
验证 Flink Client 与 Yarn Session 集群的连通性。
-
验证 Paimon Catalog 及 Hive Metastore 的集成配置。
-
验证 Paimon Primary Key 表在 Batch(批处理) 模式下的以下能力:
-
建表 (DDL)
-
批量写入 (Batch Insert)
-
行级更新 (Upsert via Insert)
-
批量删除 (Batch Delete)
-
数据查询与结果校验 (Query & Count)
-
2 环境依赖与架构
2.1 架构拓扑
-
控制端 (Local): 运行 Python 脚本,负责逻辑控制、SQL 生成、结果解析。
-
网关机 (Remote SSH): 安装有 Flink 客户端和 Hadoop 环境的 Linux 服务器。
-
执行集群: Flink on YARN (Session Cluster)。
-
存储层: HDFS (存放 Paimon 文件) + Hive Metastore (元数据管理)。
2.2 前置条件
-
Python 环境: 安装
paramiko库 (pip install paramiko). -
Flink 集群: 需预先启动一个 Flink Yarn Session,并获取
Application ID。 -
网络: 本地需能通过 SSH (端口 22) 访问网关机 IP (
10.x.xx.214)。
3 配置说明
脚本头部定义了关键配置项,运行前需确认以下信息:
| 配置项 | 变量名 | 说明 |
|---|---|---|
| YARN 应用ID | YARN_APP_ID |
必须修改。当前运行的 Flink Session ID (如 application_1763460582895_0081)。 |
| SSH 连接信息 | SSH_HOST, SSH_USER... |
远程网关机的登录凭证。 |
| Flink 路径 | REMOTE_FLINK_HOME |
远程服务器上 Flink 的安装目录。 |
| Hive 配置 | HIVE_CONF_DIR |
用于连接 Hive Metastore 的配置文件路径。 |
| 测试数据量 | TOTAL_ROWS |
初始化插入的总行数 (默认 1000)。 |
| 变更数据量 | UPDATE_COUNT / DELETE_COUNT |
随机更新和删除的行数。 |
4 测试流程详解
测试脚本 test_workflow 执行了完整的生命周期验证:
Step 0: 环境初始化与诊断
-
动作: SSH 连接成功后,执行
source /etc/profile并检查hadoop命令是否存在。 -
SQL 设置: 每次执行 SQL 前,脚本会自动注入以下 Header 以确保环境正确:
SET 'execution.runtime-mode' = 'BATCH'; -- 强制批模式 SET 'sql-client.execution.result-mode' = 'TABLEAU'; -- 格式化输出以便解析 SET 'execution.attached' = 'true'; -- 阻塞等待结果 SET 'execution.checkpointing.mode' = ''; -- 批模式下禁用 CP SET 'parallelism.default' = '2'; -- 并行度设置
Step 1: 创建 Paimon Catalog 与测试表
-
SQL 逻辑:
CREATE CATALOG paimon_catalog WITH ( 'type' = 'paimon', 'warehouse' = 'hdfs:///user/hive/warehouse', 'metastore' = 'hive', 'hive-conf-dir' = '/home/bigdata/CDH/etc/hive/conf' ); CREATE TABLE t_paimon_batch_random_test ( id BIGINT NOT NULL, content_text STRING, dt STRING, PRIMARY KEY (id, dt) NOT ENFORCED ) WITH ( 'bucket' = '4', 'file.format' = 'parquet', 'merge-engine' = 'deduplicate' -- 主键重复时覆盖 (Last-Win) );
Step 2: 批量数据生成与写入
-
逻辑: Python 生成
1到1000的连续 ID。 -
执行: 拼接巨大的
INSERT INTO ... VALUES ...语句一次性写入 Paimon。
Step 3: 随机更新测试 (Upsert)
-
逻辑: Python 利用
random.sample随机抽取 200 个已存在的 ID。 -
操作: 构造新的
INSERT语句,修改content_text字段。 -
原理: Paimon 在
deduplicate模式下,检测到相同 Primary Key (id, dt) 会自动用新数据覆盖旧数据。
Step 4: 随机删除测试
-
逻辑: Python 从剩余的 ID 中随机抽取 150 个 ID。
-
操作: 构造
DELETE FROM ... WHERE id IN (...)语句。 -
验证: 验证 Paimon 在 Batch 模式下的标准 SQL 删除能力。
Step 5: 最终一致性校验
-
逻辑:
-
数量校验: 预期总数 =
TOTAL_ROWS(1000) -DELETE_COUNT(150) = 850。 -
内容校验: 抽样查询一个“被更新的ID”和一个“被删除的ID”,确认内容变更是否生效。
-
5 核心代码逻辑解析
5.1 远程执行引擎
脚本的核心在于 execute_single_sql 方法,它屏蔽了远程文件交互的复杂性:
-
生成 SQL: 将 Header 和具体的业务 SQL 组合。
-
上传 SQL: 将组合后的内容写入本地临时文件,并通过 SFTP 上传至远程服务器 (
/home/bigdata/temp_flink_task.sql)。 -
调用 Client: 发送 SSH 命令启动 Flink SQL Client:
/home/bigdata/download/flink-1.19.3/sql-client.sh -Dexecution.target=yarn-session -Dyarn.application.id=... -f /remote/path/temp.sql -
解析结果: 捕获
stdout,分析执行状态(SUCCESS/FAILED)并提取表格数据。
5.2 日志记录
脚本会自动生成格式为 flink_random_test_YYYYMMDD_HHMMSS.log 的日志文件,记录每一步的:
-
执行 SQL 摘要
-
耗时 (Duration)
-
状态 (SUCCESS/FAILED)
-
报错详情(如果失败)
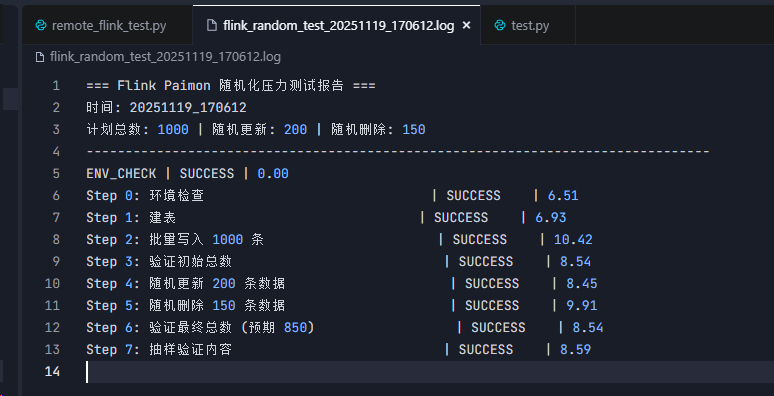
6 预期输出示例
如果测试成功,控制台输出将如下所示:
[LOG] 日志文件: flink_random_test_20251119_170612.log
[INIT] 连接 SSH: 10.x.xx.214...
[INIT] 连接成功.
==================== 开始随机化压力测试 ====================
============================================================
正在诊断远程环境变量...
[CHECK] Hadoop 命令路径: /home/bigdata/CDH/lib/hadoop/bin/hadoop
------------------------------------------------------------
>>> [17:06:13] 执行: Step 0: 环境检查
SQL: USE CATALOG paimon_catalog;
SHOW DATABASES;
[SUCCESS] 耗时: 6.51s
[RESULT] 表格截取:
Flink SQL> +------------------+
| database name |
+------------------+
| ceshi |
| default |
| dwd |
| ods |
| ods_syx |
| paimon |
| paimon_only_test |
| test1 |
+------------------+
>>> [17:06:19] 执行: Step 1: 建表
SQL: USE CATALOG paimon_catalog;
USE ods;
DROP TABLE IF EXISTS t_paimon_batch_random_test;
CREATE TABLE t_paimon_batch_random_test (
id BIGINT NOT NULL,
content_text STRING,
dt STRING,
PRIMARY KEY (id, dt) NOT ENFORCED
... [Length: 487 chars]
[SUCCESS] 耗时: 6.93s
[PYTHON] 正在生成 1000 条初始数据...
>>> [17:06:26] 执行: Step 2: 批量写入 1000 条
SQL: USE CATALOG paimon_catalog;
USE ods;
INSERT INTO t_paimon_batch_random_test VALUES
(1, 'Original_Content_1', '2025-11-19'), (2, 'Original_Content_2', '2025-11-19'), (3, 'Original_Content_3', '2025-11-19'), (4, 'Original_Content_4', '2025-11-19'), (5, 'Original_Content_5', '2 ... [Length: 44911 chars]
[SUCCESS] 耗时: 10.42s
>>> [17:06:37] 执行: Step 3: 验证初始总数
SQL: USE CATALOG paimon_catalog;
USE ods;
SELECT COUNT(*) as cnt_init FROM t_paimon_batch_random_test;
[SUCCESS] 耗时: 8.54s
[RESULT] 表格截取:
+----------+
| cnt_init |
+----------+
| 1000 |
+----------+
[PYTHON] 随机选中 200 个ID进行更新: [4, 5, 6, 15, 23, 31, 33, 34, 35, 36] ...
>>> [17:06:45] 执行: Step 4: 随机更新 200 条数据
SQL: USE CATALOG paimon_catalog;
USE ods;
INSERT INTO t_paimon_batch_random_test VALUES
(4, 'Random_Updated_V2_4', '2025-11-19'), (5, 'Random_Updated_V2_5', '2025-11-19'), (6, 'Random_Updated_V2_6', '2025-11-19'), (15, 'Random_Updated_V2_15', '2025-11-19'), (23, 'Random_Updated_V ... [Length: 9263 chars]
[SUCCESS] 耗时: 8.45s
[PYTHON] 随机选中 150 个ID进行删除: [11, 14, 17, 25, 29, 61, 65, 78, 82, 87] ...
>>> [17:06:54] 执行: Step 5: 随机删除 150 条数据
SQL: USE CATALOG paimon_catalog;
USE ods;
DELETE FROM t_paimon_batch_random_test WHERE id IN (11, 14, 17, 25, 29, 61, 65, 78, 82, 87, 89, 90, 103, 106, 113, 115, 123, 127, 134, 140, 154, 156, 163, 169, 175, 176, 206, 214, 218, 243, 244, 246, 248, 252, 256, 261, 268, 269, 271, 278, 282, 28 ... [Length: 861 chars]
[SUCCESS] 耗时: 9.91s
[PYTHON] 预期剩余数据量: 850
[PYTHON] 预期剩余数据量: 850
>>> [17:07:04] 执行: Step 6: 验证最终总数 (预期 850)
SQL: USE CATALOG paimon_catalog;
USE ods;
SQL: USE CATALOG paimon_catalog;
USE ods;
USE ods;
SELECT COUNT(*) as final_cnt FROM t_paimon_batch_random_test;
SELECT COUNT(*) as final_cnt FROM t_paimon_batch_random_test;
[SUCCESS] 耗时: 8.54s
[RESULT] 表格截取:
+-----------+
| final_cnt |
+-----------+
| 850 |
+-----------+
SELECT COUNT(*) as final_cnt FROM t_paimon_batch_random_test;
[SUCCESS] 耗时: 8.54s
[RESULT] 表格截取:
+-----------+
| final_cnt |
+-----------+
SELECT COUNT(*) as final_cnt FROM t_paimon_batch_random_test;
[SUCCESS] 耗时: 8.54s
[RESULT] 表格截取:
+-----------+
| final_cnt |
SELECT COUNT(*) as final_cnt FROM t_paimon_batch_random_test;
[SUCCESS] 耗时: 8.54s
[RESULT] 表格截取:
+-----------+
SELECT COUNT(*) as final_cnt FROM t_paimon_batch_random_test;
[SUCCESS] 耗时: 8.54s
[RESULT] 表格截取:
SELECT COUNT(*) as final_cnt FROM t_paimon_batch_random_test;
[SUCCESS] 耗时: 8.54s
[RESULT] 表格截取:
SELECT COUNT(*) as final_cnt FROM t_paimon_batch_random_test;
[SUCCESS] 耗时: 8.54s
[SUCCESS] 耗时: 8.54s
[RESULT] 表格截取:
+-----------+
| final_cnt |
+-----------+
[RESULT] 表格截取:
+-----------+
| final_cnt |
+-----------+
| 850 |
+-----------+
[PYTHON] 抽样验证: ID 4 应为更新状态, ID 11 应不存在
[RESULT] 表格截取:
+-----------+
| final_cnt |
+-----------+
| 850 |
+-----------+
[PYTHON] 抽样验证: ID 4 应为更新状态, ID 11 应不存在
[RESULT] 表格截取:
+-----------+
| final_cnt |
+-----------+
| 850 |
+-----------+
[RESULT] 表格截取:
+-----------+
| final_cnt |
+-----------+
+-----------+
| final_cnt |
+-----------+
| final_cnt |
+-----------+
| 850 |
+-----------+
[PYTHON] 抽样验证: ID 4 应为更新状态, ID 11 应不存在
>>> [17:07:12] 执行: Step 7: 抽样验证内容
SQL: USE CATALOG paimon_catalog;
USE ods;
SELECT * FROM t_paimon_batch_random_test WHERE id IN (4, 11);
[SUCCESS] 耗时: 8.59s
[RESULT] 表格截取:
+----+---------------------+------------+
| id | content_text | dt |
+----+---------------------+------------+
| 4 | Random_Updated_V2_4 | 2025-11-19 |
+----+---------------------+------------+7 故障排查指南
-
连接失败:
-
检查
SSH_HOST是否可达。 -
检查密码是否过期。
-
-
Flink 任务提交失败:
-
检查
YARN_APP_ID是否在 YARN 界面上显示为RUNNING。 -
如果报错
No Executor found,请确认 Flink Session 集群资源是否耗尽。
-
-
数据校验不匹配:
-
查看生成的日志文件,确认是否有
INSERT或DELETE步骤虽然 Exit Code 为 0 但包含 Java Exception。 -
确认 Paimon 表的
bucket数和并行度设置,有时并发写冲突可能导致问题(但在 Batch 模式下较少见)。
-
8 测试代码
# -*- coding: utf-8 -*-
import paramiko
import time
import os
import sys
import uuid
import datetime
import random # <--- 新增:用于随机抽取数据
# ================= 1. 基础配置 =================
SSH_HOST = "xx.x.xx.xx"
SSH_PORT = 22
SSH_USER = "xxxx"
SSH_PASSWORD = "xxxxxxxxx"
REMOTE_FLINK_HOME = "/home/bigdata/download/flink-1.19.3"
REMOTE_SQL_CLIENT = os.path.join(REMOTE_FLINK_HOME, "bin/sql-client.sh").replace("\\", "/")
REMOTE_TEMP_SQL_PATH = "/home/bigdata/temp_flink_task.sql"
# 【重要】请确认 Session ID
YARN_APP_ID = "application_1763460582895_0081"
# ================= 2. 业务配置 =================
HIVE_CONF_DIR = "/home/bigdata/CDH/etc/hive/conf"
PAIMON_WAREHOUSE = "hdfs:///user/hive/warehouse"
TEST_DB_NAME = "ods"
TEST_TABLE_NAME = "t_paimon_batch_random_test"
# 数据量配置
TOTAL_ROWS = 1000 # 总插入行数
UPDATE_COUNT = 200 # 随机更新行数
DELETE_COUNT = 150 # 随机删除行数
# ===============================================================
class RemoteFlinkTest:
def __init__(self):
self.ssh = None
self.sftp = None
self.log_file = None
# 初始化日志
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
self.log_filename = f"flink_random_test_{timestamp}.log"
try:
self.log_file = open(self.log_filename, "w", encoding="utf-8")
self.log_to_file(f"=== Flink Paimon 随机化压力测试报告 ===")
self.log_to_file(f"时间: {timestamp}")
self.log_to_file(f"计划总数: {TOTAL_ROWS} | 随机更新: {UPDATE_COUNT} | 随机删除: {DELETE_COUNT}")
self.log_to_file("-" * 80)
print(f"[LOG] 日志文件: {self.log_filename}")
except Exception as e:
print(f"[WARN] 日志创建失败: {e}")
self.connect()
def log_to_file(self, message):
if self.log_file:
self.log_file.write(message + "\n")
self.log_file.flush()
def connect(self):
try:
print(f"[INIT] 连接 SSH: {SSH_HOST}...")
self.ssh = paramiko.SSHClient()
self.ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
self.ssh.connect(SSH_HOST, port=SSH_PORT, username=SSH_USER, password=SSH_PASSWORD)
self.sftp = self.ssh.open_sftp()
print(f"[INIT] 连接成功.\n")
except Exception as e:
print(f"[ERROR] 连接失败: {e}")
sys.exit(1)
def close(self):
if self.sftp: self.sftp.close()
if self.ssh: self.ssh.close()
if self.log_file: self.log_file.close()
def debug_environment(self):
"""诊断环境"""
print(f"{'='*60}")
print("正在诊断远程环境变量...")
stdin, stdout, stderr = self.ssh.exec_command("source /etc/profile; which hadoop")
hadoop_path = stdout.read().decode().strip()
if not hadoop_path:
print("[FATAL] 远程无法找到 hadoop 命令!")
self.log_to_file("ENV_CHECK | FAILED | NO_HADOOP")
else:
print(f"[CHECK] Hadoop 命令路径: {hadoop_path}")
self.log_to_file("ENV_CHECK | SUCCESS | 0.00")
print(f"{'-'*60}\n")
def get_common_sql_header(self):
"""生成 SQL 头"""
return f"""
-- 1. 运行模式: 微批 (Batch)
SET 'execution.runtime-mode' = 'BATCH';
SET 'sql-client.execution.result-mode' = 'TABLEAU';
SET 'execution.attached' = 'true';
-- 2. Batch 模式下禁用 Checkpoint
RESET 'execution.checkpointing.interval';
RESET 'execution.checkpointing.mode';
-- 3. Paimon 配置
SET 'table.local-time-zone' = 'Asia/Shanghai';
SET 'table.exec.sink.upsert-materialize' = 'NONE';
-- 调大并行度以加快批量操作
SET 'parallelism.default' = '2';
-- 4. Catalog 定义
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = '{PAIMON_WAREHOUSE}',
'metastore' = 'hive',
'hive-conf-dir' = '{HIVE_CONF_DIR}'
);
"""
def execute_single_sql(self, description, sql_body, verify_result=False):
"""执行单条 SQL"""
# 日志优化:如果 SQL 太长(例如批量插入),只打印前 200 字符
sql_preview = sql_body.strip()
if len(sql_preview) > 300:
sql_preview = sql_preview[:300] + " ... [Length: {} chars]".format(len(sql_body))
print(f"\n>>> [{time.strftime('%H:%M:%S')}] 执行: {description}")
print(f" SQL: {sql_preview}")
full_sql = self.get_common_sql_header() + "\n" + sql_body
# 上传
local_file = f"temp_{uuid.uuid4().hex}.sql"
try:
with open(local_file, "w", encoding='utf-8') as f:
f.write(full_sql)
self.sftp.put(local_file, REMOTE_TEMP_SQL_PATH)
except Exception as e:
print(f"[ERROR] 上传失败: {e}")
return
finally:
if os.path.exists(local_file): os.remove(local_file)
# 执行命令
cmd = (
f"source /etc/profile; source ~/.bashrc; "
f"export HADOOP_CLASSPATH=`hadoop classpath` && "
f"{REMOTE_SQL_CLIENT} "
f"-Dexecution.target=yarn-session "
f"-Dyarn.application.id={YARN_APP_ID} "
f"-f {REMOTE_TEMP_SQL_PATH}"
)
start_time = time.time()
stdin, stdout, stderr = self.ssh.exec_command(cmd)
exit_status = stdout.channel.recv_exit_status()
duration = time.time() - start_time
output = stdout.read().decode('utf-8', errors='ignore')
error = stderr.read().decode('utf-8', errors='ignore')
# 解析结果
data_lines = []
for line in output.splitlines():
if "+-" in line or "|" in line:
data_lines.append(line)
# 判定逻辑
is_failed = (exit_status != 0)
if "Exception" in output or "Exception" in error:
if not ("INFO" in output and "at " not in output):
is_failed = True
if verify_result and not data_lines:
print(" [FATAL] 预期有结果但未返回,可能是环境问题!")
is_failed = True
status = "FAILED" if is_failed else "SUCCESS"
self.log_to_file(f"{description:<40} | {status:<10} | {duration:.2f}")
if is_failed:
print(f"[FAILED] Code: {exit_status}")
print("ERROR LOG:\n" + (output + error)[-2000:])
else:
print(f"[SUCCESS] 耗时: {duration:.2f}s")
if data_lines:
print("[RESULT] 表格截取:")
# 如果结果太多,只打印首尾
if len(data_lines) > 20:
for l in data_lines[:10]: print(f" {l}")
print(f" ... (省略 {len(data_lines)-20} 行) ...")
for l in data_lines[-10:]: print(f" {l}")
else:
for l in data_lines: print(f" {l}")
def test_workflow(self):
print(f"\n{'='*20} 开始随机化压力测试 {'='*20}")
self.debug_environment()
# 1. 环境检查
step0_check = """
USE CATALOG paimon_catalog;
SHOW DATABASES;
"""
self.execute_single_sql("Step 0: 环境检查", step0_check, verify_result=True)
# 2. 建表
step1_ddl = f"""
USE CATALOG paimon_catalog;
USE {TEST_DB_NAME};
DROP TABLE IF EXISTS {TEST_TABLE_NAME};
CREATE TABLE {TEST_TABLE_NAME} (
id BIGINT NOT NULL,
content_text STRING,
dt STRING,
PRIMARY KEY (id, dt) NOT ENFORCED
) WITH (
'bucket' = '4',
'file.format' = 'parquet',
'changelog-producer' = 'input',
'merge-engine' = 'deduplicate'
);
"""
self.execute_single_sql("Step 1: 建表", step1_ddl)
# 3. 批量插入初始数据 (1~1000)
print(f"\n[PYTHON] 正在生成 {TOTAL_ROWS} 条初始数据...")
all_ids = list(range(1, TOTAL_ROWS + 1))
values = []
for i in all_ids:
values.append(f"({i}, 'Original_Content_{i}', '2025-11-19')")
step2_insert = f"""
USE CATALOG paimon_catalog;
USE {TEST_DB_NAME};
INSERT INTO {TEST_TABLE_NAME} VALUES
{", ".join(values)};
"""
self.execute_single_sql(f"Step 2: 批量写入 {TOTAL_ROWS} 条", step2_insert)
# 4. 验证初始总数
step3_count = f"""
USE CATALOG paimon_catalog;
USE {TEST_DB_NAME};
SELECT COUNT(*) as cnt_init FROM {TEST_TABLE_NAME};
"""
self.execute_single_sql("Step 3: 验证初始总数", step3_count, verify_result=True)
# ==============================================
# 随机化逻辑
# ==============================================
# 1. 随机选择要更新的 ID
update_ids = sorted(random.sample(all_ids, UPDATE_COUNT))
print(f"\n[PYTHON] 随机选中 {UPDATE_COUNT} 个ID进行更新: {update_ids[:10]} ...")
update_values = []
for uid in update_ids:
update_values.append(f"({uid}, 'Random_Updated_V2_{uid}', '2025-11-19')")
step4_update = f"""
USE CATALOG paimon_catalog;
USE {TEST_DB_NAME};
INSERT INTO {TEST_TABLE_NAME} VALUES
{", ".join(update_values)};
"""
self.execute_single_sql(f"Step 4: 随机更新 {UPDATE_COUNT} 条数据", step4_update)
# 2. 随机选择要删除的 ID (从剩下的里面选,方便验证)
remaining_ids = list(set(all_ids) - set(update_ids))
delete_ids = sorted(random.sample(remaining_ids, DELETE_COUNT))
print(f"\n[PYTHON] 随机选中 {DELETE_COUNT} 个ID进行删除: {delete_ids[:10]} ...")
# 构造 DELETE WHERE id IN (...)
delete_id_str = ", ".join(map(str, delete_ids))
step5_delete = f"""
USE CATALOG paimon_catalog;
USE {TEST_DB_NAME};
DELETE FROM {TEST_TABLE_NAME} WHERE id IN ({delete_id_str});
"""
self.execute_single_sql(f"Step 5: 随机删除 {DELETE_COUNT} 条数据", step5_delete)
# ==============================================
# 最终验证
# ==============================================
# 预期剩余数量 = 总数 - 删除数
expected_count = TOTAL_ROWS - DELETE_COUNT
print(f"\n[PYTHON] 预期剩余数据量: {expected_count}")
step6_verify_count = f"""
USE CATALOG paimon_catalog;
USE {TEST_DB_NAME};
SELECT COUNT(*) as final_cnt FROM {TEST_TABLE_NAME};
"""
self.execute_single_sql(f"Step 6: 验证最终总数 (预期 {expected_count})", step6_verify_count, verify_result=True)
# 抽样验证:取一个被更新的,取一个被删除的
check_update_id = update_ids[0]
check_delete_id = delete_ids[0]
print(f"[PYTHON] 抽样验证: ID {check_update_id} 应为更新状态, ID {check_delete_id} 应不存在")
step7_sample = f"""
USE CATALOG paimon_catalog;
USE {TEST_DB_NAME};
SELECT * FROM {TEST_TABLE_NAME} WHERE id IN ({check_update_id}, {check_delete_id});
"""
self.execute_single_sql("Step 7: 抽样验证内容", step7_sample, verify_result=True)
if __name__ == "__main__":
if "application_" not in YARN_APP_ID:
print("[ERROR] 请更新 YARN_APP_ID")
sys.exit(1)
tester = RemoteFlinkTest()
try:
tester.test_workflow()
finally:
tester.close()对应的日志记录文件内容如下:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)