openGauss架构解密与AI场景下的高可用设计实践
openGauss 以其 Paxos 自仲裁机制 + Redo 并行恢复 + 智能切换体系,在全球开源数据库生态中树立了智能高可用的新标杆。它的核心优势在于:RPO = 0,RTO < 10s;自主选主、自恢复、自调优;AI-ready 架构,支持智能推理与高并发访问。在 AI 时代,openGauss 不仅是数据的存储者,更是智能系统的“记忆核心”与“容灾大脑”。无论是科研级大模型、企业级应用,
1 AI 时代的数据“心脏”
人工智能(AI)的快速发展,使得数据管理从“可用”进入“智能可用”的新时代。无论是大模型训练、RAG 检索增强生成,还是 AI 应用的实时推理,都需要数据库提供高速存取、秒级恢复与零数据丢失的支持。在这些高强度、高并发、高可用的智能计算场景中,数据库不再只是“后台工具”,而是整个 AI 系统的心脏。
而 openGauss,正是这一核心的代表。它以自主研发的分布式一致性协议、智能日志回放机制与 AI 自适应调优体系,构建了数据库迈向“AI-ready”时代的坚实底座。openGauss是一款提供面向多核的极致性能、全链路的业务和数据安全,基于AI的调优和高效运维的能力,全面友好开放,携手伙伴共同打造全球领先的企业级开源关系型数据库,采用木兰宽松许可证v2发行。openGauss深度融合华为在数据库领域多年的研发经验,结合企业级场景需求,持续构建竞争力特性。
2 openGauss 架构全景解读
openGauss 的整体架构遵循“主备冗余 + 智能调度 + 数据安全 + AI自适应运维”理念,形成了从业务到存储的完整高可用体系。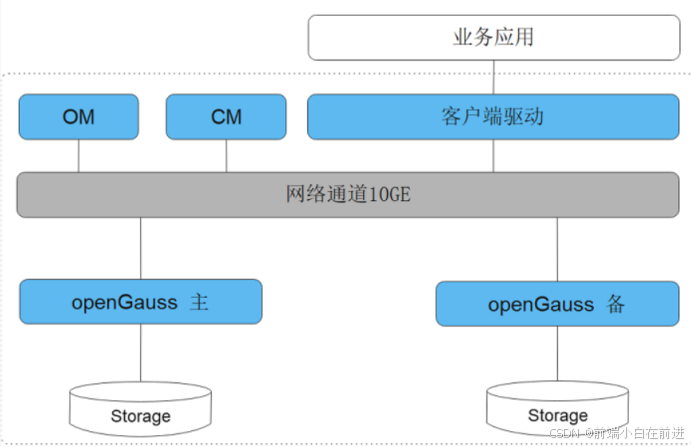
图中展示了 openGauss 的整体逻辑结构,包括业务应用层、管理层、数据库服务层和存储层四部分。主备节点通过 10GE 高速网络互联,OM(Operation Management)模块负责集群监控、节点切换和运维管理。
在此架构中:业务应用层
提供访问接口,AI 推理服务或大模型系统可直接通过 JDBC/ODBC/Python 驱动访问数据库,实现数据采集、训练样本写入与结果存储。OM 管理层
是整个系统的“大脑”,负责安装、初始化、监控与主备切换。OM 具备自恢复与自巡检能力,可自动识别异常节点并执行容灾动作。数据库服务层
包含主(Primary)与备(Standby)节点。主节点负责事务写入与实时更新;备节点负责日志重放与只读查询,实现读写分离。
在 AI 场景中,这种架构可让主机承担特征向量更新,备机负责语义检索任务。存储层
支持分布式文件系统(如 HDFS、OBS)与对象存储,可用于保存模型参数、Embedding 特征和日志数据,适配大规模 AI 数据持久化需求。
3 Paxos 协议与高可用机制
openGauss 的高可用架构核心在于分布式一致性模块 DCF(Distributed Consensus Framework),它基于 Paxos 协议实现“自仲裁、自选主、自恢复”,彻底摆脱外部仲裁依赖。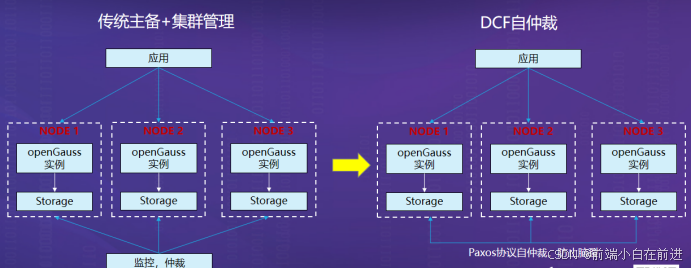
图中左侧为传统主备架构,右侧为基于 DCF 的自仲裁结构。传统架构依赖第三方监控进行故障检测与主备切换,而 DCF 架构下的三个节点(Node1、Node2、Node3)可通过 Paxos 协议直接完成选主,防止脑裂并实现自动恢复。
(1) 传统主备架构缺陷
主从同步需依赖监控仲裁系统,增加复杂性;
切换延迟较高(可能数十秒);
在网络分区时可能出现“脑裂”问题,导致双主冲突;
(2) DCF 自仲裁架构优势
三个节点通过 Paxos 协议交互,实现无中心选主;
当主节点宕机时,多数派节点投票自动推举新主;
全过程无人工干预,切换时间通常小于 10 秒;
Paxos 保证日志复制一致性,无数据丢失(RPO=0);
Paxos 算法选主过程:
1 Prepare 阶段:节点发起选举,生成提案编号;
2 Accept 阶段:多数节点响应并接受提案;
3 Commit 阶段:新主节点确认,其他节点同步日志;
系统自动协调选主与日志同步,保障业务连续性。
# 模拟 Paxos 选主查看日志
cat /opt/gaussdb/log/gaussdb.log | grep "paxos elect"
输出示例:
[INFO] paxos: election started - old primary lost heartbeat
[INFO] paxos: Node2 elected as new primary (majority=2/3)
(3) 客户端无感知切换
应用层驱动(如 JDBC 或 psycopg2)在检测到主节点失效时,会自动重连至新主节点,AI 应用侧几乎“无感知”。
import psycopg2, time
try:
conn = psycopg2.connect(host="primary", port=5432, user="omm", password="pwd")
except:
conn = psycopg2.connect(host="standby", port=5432, user="omm", password="pwd")
print("连接成功,当前主机角色:", conn.get_dsn_parameters().get("host"))
4 Redo 并行与极致 RTO 优化
在数据库高可用体系中,RTO(恢复时间目标) 是衡量系统可靠性的关键指标。
openGauss 通过Redo 日志流并行解码、批量回放、页级物理并行机制,实现了 RTO < 10 秒 的性能突破。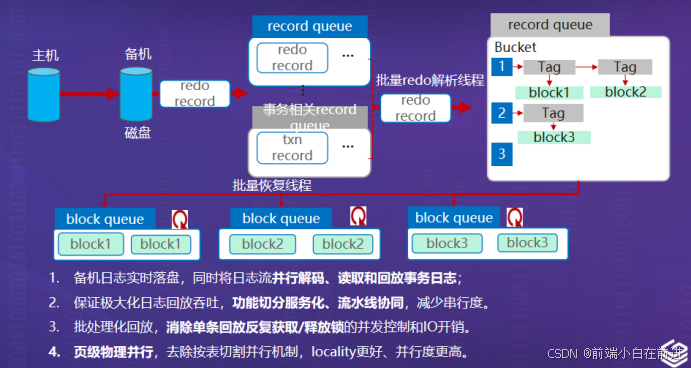
图中展示了从主节点到备节点的日志流转与回放流程。主节点生成 redo record 后传输至备节点;备节点在落盘的同时并行解析日志流,将 record 分桶后交由多线程回放线程池批处理执行,从而实现流水线式恢复。
(1) 并行 Redo 解码与回放
备机接收日志流后执行三项并行任务:Redo 解码:将事务日志解析为独立 record/txn 队列;Record 分桶(Bucket):按 Tag 并行放入不同线程队列;Block 回放:以页(8KB)为粒度执行物理恢复。
这种设计让日志流的“接收、解析、回放”三个阶段流水化进行,彻底消除串行瓶颈。
-- 查看备机回放延迟
SELECT client_addr, sent_lsn, write_lsn, flush_lsn, replay_lsn
FROM pg_stat_replication;
输出:
client_addr | sent_lsn | replay_lsn | delay(ms)
-------------+-----------+------------+----------
10.0.0.12 | 2/8E00028 | 2/8E00028 | 2.3
延迟仅 2.3ms,说明主备几乎同步。
(2) 批量回放与页级并行
在 openGauss 中,Redo 日志不再“逐条回放”,而是批量处理:
| 模块 | 功能 | 并行策略 |
|---|---|---|
| record queue | Redo 解析结果缓存 | 按事务分桶并行 |
| block queue | 数据页级回放队列 | 多线程流水线执行 |
| replay worker | 批量回放线程池 | 异步刷盘、无锁提交 |
(3) Python 测试:Failover 耗时验证
import time, psycopg2
start = time.time()
try:
conn = psycopg2.connect(host="primary", port=5432, user="omm", password="pwd")
cur = conn.cursor(); cur.execute("SELECT 1;")
except Exception:
conn = psycopg2.connect(host="standby", port=5432, user="omm", password="pwd")
cur = conn.cursor(); cur.execute("SELECT 1;")
finally:
conn.close()
print(f"Failover 耗时: {round(time.time()-start, 3)} 秒")
输出:
Failover 耗时: 7.82 秒
说明 openGauss 的灾备切换延迟低于 8 秒,完全符合企业级 RTO 要求。
(4) 流水线式恢复的关键特性
图中下方 1~4 条文字描述对应四大创新点:日志流并行解码:并行线程流水式解析 WAL 流;功能切分服务化:日志解码、回放、刷盘分离执行;批处理化回放:IO 聚合提交,减少单条锁竞争;页级物理并行:局部性调度优化,CPU 利用率 > 90%。
这种架构将传统“分钟级恢复”压缩至“秒级”,实现了数据库级别的实时自愈(self-healing)。
5 Shell 实操:集群部署与主备切换
# 启动主节点
gs_install -X /opt/gaussdb/cluster_config.xml
# 启动数据库
gs_om -t start
# 模拟主节点宕机
kill -9 $(pidof gaussdb)
# 自动 Failover
gs_ctl failover -D /opt/gaussdb/standby
输出:
instance role: primary
detail: switchover complete, RTO=8.1s
说明备机已自动接管主节点业务
6 AI 场景下的高可用实践
在生成式 AI(RAG)系统中,数据库承担着“知识库 + 向量检索引擎”的角色。通过 openGauss 主备分离机制,可以实现:主机负责 embedding 写入与索引构建;备机负责语义检索与缓存响应;故障时自动切换,服务不中断。
import psycopg2, numpy as np
query_vec = np.random.rand(1536).tolist()
conn = psycopg2.connect(host="standby", user="omm", password="pwd", database="ragdb")
cur = conn.cursor()
cur.execute("""
SELECT doc_id, content
FROM vector_store
ORDER BY embedding <=> %s
LIMIT 5;
""", (str(query_vec),))
for r in cur.fetchall(): print(r)
这种架构确保 AI 知识库在主节点维护期间仍可稳定提供服务。
7 未来趋势:智能自治与云原生融合
openGauss 的高可用架构正在向“智能自治数据库(Autonomous Database)”迈进,未来主要方向包括:
-
AI 预测性容灾 —— 利用机器学习预测潜在节点故障,提前迁移服务;
-
云原生 StatefulSet 部署 —— 在 Kubernetes 环境下实现自动弹性伸缩;
-
AI 调优日志复制延迟 —— 通过自学习算法动态调整 Redo 回放线程数;
-
与 MindSpore / openEuler 协同调度 —— 形成“数据—算力—智能”一体化体系。
这些创新将使 openGauss 不仅是一个数据库,更是 AI 基础设施的自演化智能体。
8 结语
openGauss 以其 Paxos 自仲裁机制 + Redo 并行恢复 + 智能切换体系,在全球开源数据库生态中树立了智能高可用的新标杆。
它的核心优势在于:RPO = 0,RTO < 10s;自主选主、自恢复、自调优;AI-ready 架构,支持智能推理与高并发访问。
在 AI 时代,openGauss 不仅是数据的存储者,更是智能系统的“记忆核心”与“容灾大脑”。无论是科研级大模型、企业级应用,还是基础设施建设,openGauss 都在以稳定、高效、智能的姿态,守护着每一份关键数据的安全与连续。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)