2025年AI开发者必备的五大 RAG 框架深度解析!
本文将探讨五个著名的RAG框架:LangChain、LlamaIndex、LangGraph、Haystack和RAGFlow。每个框架都提供独特的功能,可以改进你的人工智能项目。
2025年,RAG(检索增强生成)已成为一项热门技术,它避免了昂贵且耗时的模型微调。当前,对RAG框架的需求日益增长,让我们来了解一下它们。检索增强生成(RAG)框架是人工智能领域的重要工具。它们通过允许大型语言模型(LLM)从外部来源检索相关信息来增强其能力。这使得响应更加准确和上下文感知。
本文将探讨五个著名的RAG框架:LangChain、LlamaIndex、LangGraph、Haystack和RAGFlow。每个框架都提供独特的功能,可以改进你的人工智能项目。
1. LangChain
LangChain是一个灵活的框架,简化了使用LLM开发应用程序的过程。它提供了构建RAG应用的工具,使集成变得简单直接。
主要特点:
- 模块化设计,易于定制。
- 支持各种LLM和数据源。
- 内置文档检索和处理工具。
- 适用于聊天机器人和虚拟助手。
实践操作:
安装以下库:
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
设置OpenAI API密钥和操作系统环境:
from getpass import getpassopenai = getpass("OpenAI API Key:")import osos.environ["OPENAI_API_KEY"] = openai
导入以下依赖项:
import bs4from langchain import hubfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_community.vectorstores import Chromafrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAI, OpenAIEmbeddings
使用WebBaseLoader加载RAG文档(请替换为你的数据):
# Load Documentsloader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ),)docs = loader.load()
使用RecursiveCharacterTextSplitter对文档进行分块:
# Splittext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = text_splitter.split_documents(docs)
将向量文档存储在ChromaDB中:
# Embedvectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())retriever = vectorstore.as_retriever()
从LangChain hub拉取RAG提示并定义LLM:
# Promptprompt = hub.pull("rlm/rag-prompt")# LLMllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
处理检索到的文档:
# Post-processingdef format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)
创建RAG链:
# Chainrag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
调用链并提问:
# Questionrag_chain.invoke("What is Task Decomposition?")
输出:
‘Task Decomposition is a technique used to break down complex tasks into smaller and simpler steps. This approach helps agents to plan ahead and tackle difficult tasks more effectively. Task decomposition can be done through various methods, including using prompting techniques, task-specific instructions, or human inputs.’
另请阅读:https://www.analyticsvidhya.com/blog/2024/06/langchain-guide/
2. LlamaIndex
LlamaIndex,前身为GPT Index,专注于为LLM应用高效组织和检索数据。它帮助开发者快速访问和使用大型数据集。
主要特点:
- 组织数据以实现快速查找。
- 可定制的RAG工作流组件。
- 支持多种数据格式,包括PDF和SQL。
- 与Pinecone和FAISS等向量存储集成。
实践操作:
安装以下依赖项:
!pip install llama-index llama-index-readers-file!pip install llama-index-embeddings-openai!pip install llama-index-llms-openai
导入以下依赖项并初始化LLM和嵌入模型:
from llama_index.llms.openai import OpenAIfrom llama_index.embeddings.openai import OpenAIEmbeddingllm = OpenAI(model='gpt-4o')embed_model = OpenAIEmbedding()from llama_index.core import SettingsSettings.llm = llmSettings.embed_model = embed_model
下载数据(你可以替换为自己的数据):
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/uber_2021.pdf' -O './uber_2021.pdf'
使用SimpleDirectoryReader读取数据:
from llama_index.core import SimpleDirectoryReaderdocuments = SimpleDirectoryReader(input_files=["/content/uber_2021.pdf"]).load_data()
使用TokenTextSplitter对文档进行分块:
from llama_index.core.node_parser import TokenTextSplittersplitter = TokenTextSplitter( chunk_size=512, chunk_overlap=0,)nodes = splitter.get_nodes_from_documents(documents)
将向量嵌入存储在VectorStoreIndex中:
from llama_index.core import VectorStoreIndexindex = VectorStoreIndex(nodes)query_engine = index.as_query_engine(similarity_top_k=2)
使用RAG调用LLM:
response = query_engine.query("What is the revenue of Uber in 2021?")print(response)
输出:
‘The revenue of Uber in 2021 was $171.7 million.
3. LangGraph
LangGraph将LLM与基于图的数据结构连接起来。此框架对于需要复杂数据关系的应用程序非常有用。
主要特点:
- 高效地从图结构中检索数据。
- 将LLM与图数据结合以获得更好的上下文。
- 允许自定义检索过程。
代码:
安装以下依赖项:
%pip install --quiet --upgrade langchain-text-splitters langchain-community langgraph langchain-openai
初始化模型、嵌入和向量数据库:
from langchain.chat_models import init_chat_modelllm = init_chat_model("gpt-4o-mini", model_provider="openai")from langchain_openai import OpenAIEmbeddingsembeddings = OpenAIEmbeddings(model="text-embedding-3-large")from langchain_core.vectorstores import InMemoryVectorStorevector_store = InMemoryVectorStore(embeddings)
导入以下依赖项:
import bs4from langchain import hubfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_core.documents import Documentfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langgraph.graph import START, StateGraphfrom typing_extensions import List, TypedDict
使用WebBaseLoader下载数据集(请替换为你的数据集):
# Load and chunk contents of the blogloader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs=dict( parse_only=bs4.SoupStrainer( class_=("post-content", "post-title", "post-header") ) ),)docs = loader.load()
使用RecursiveCharacterTextSplitter对文档进行分块:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)all_splits = text_splitter.split_documents(docs)# Indexchunks_ = vector_store.add_documents(documents=all_splits)
从LangChain hub提取提示:
# Define prompt for question-answeringprompt = hub.pull("rlm/rag-prompt")
在LangGraph中定义状态、节点和边:
# Define state for applicationclass State(TypedDict): question: str context: List[Document] answer: str# Define application stepsdef retrieve(state: State): retrieved_docs = vector_store.similarity_search(state["question"]) return {"context": retrieved_docs}def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content}
编译图:
# Compile application and testgraph_builder = StateGraph(State).add_sequence([retrieve, generate])graph_builder.add_edge(START, "retrieve")graph = graph_builder.compile()
调用LLM进行RAG:
response = graph.invoke({"question": "What is Task Decomposition?"})print(response["answer"])
输出:
Task Decomposition is the process of breaking down a complicated task into smaller, manageable steps. This can be achieved using techniques like Chain of Thought (CoT) or Tree of Thoughts, which guide models to reason step by step or evaluate multiple possibilities. The goal is to simplify complex tasks and enhance understanding of the reasoning process.
4. Haystack
Haystack是一个用于开发由LLM和Transformer模型驱动的应用程序的端到端框架。它擅长文档搜索和问答。
主要特点:
- 将文档搜索与LLM功能相结合。
- 使用各种检索方法以获得最佳结果。
- 提供预构建的管道以实现快速开发。
- 兼容Elasticsearch和OpenSearch。
实践操作:
安装以下依赖项:
!pip install haystack-ai!pip install "datasets>=2.6.1"!pip install "sentence-transformers>=3.0.0"
导入并初始化VectorStore:
from haystack.document_stores.in_memory import InMemoryDocumentStoredocument_store = InMemoryDocumentStore()
从数据集库加载内置数据集:
from datasets import load_datasetfrom haystack import Documentdataset = load_dataset("bilgeyucel/seven-wonders", split="train")docs = [Document(content=doc["content"], meta=doc["meta"]) for doc in dataset]
下载嵌入模型(你也可以替换为OpenAI嵌入):
from haystack.components.embedders import SentenceTransformersDocumentEmbedderdoc_embedder = SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")doc_embedder.warm_up()docs_with_embeddings = doc_embedder.run(docs)document_store.write_documents(docs_with_embeddings["documents"])
将嵌入存储在VectorStore中:
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetrieverretriever = InMemoryEmbeddingRetriever(document_store)
定义RAG的提示:
from haystack.components.builders import ChatPromptBuilderfrom haystack.dataclasses import ChatMessagetemplate = [ ChatMessage.from_user( """Given the following information, answer the question.Context:{% for document in documents %} {{ document.content }}{% endfor %}Question: {{question}}Answer:""" )]prompt_builder = ChatPromptBuilder(template=template)
初始化LLM:
from haystack.components.generators.chat import OpenAIChatGeneratorchat_generator = OpenAIChatGenerator(model="gpt-4o-mini")
定义管道节点:
from haystack import Pipelinebasic_rag_pipeline = Pipeline()# Add components to your pipelinebasic_rag_pipeline.add_component("text_embedder", doc_embedder) # Corrected from text_embedderbasic_rag_pipeline.add_component("retriever", retriever)basic_rag_pipeline.add_component("prompt_builder", prompt_builder)basic_rag_pipeline.add_component("llm", chat_generator)
连接各个节点:
# Now, connect the components to each otherbasic_rag_pipeline.connect("text_embedder.embedding", "retriever.query_embedding")basic_rag_pipeline.connect("retriever", "prompt_builder")basic_rag_pipeline.connect("prompt_builder.prompt", "llm.messages")
使用RAG调用LLM:
question = "What does Rhodes Statue look like?"response = basic_rag_pipeline.run({"text_embedder": {"text": question}, "prompt_builder": {"question": question}})print(response["llm"]["replies"][0].text)
输出:
Batches: 100% 1/1 [00:00<00:00, 17.91it/s]‘The Colossus of Rhodes, a statue of the Greek sun-god Helios, is believed to have stood approximately 33 meters (108 feet) tall and was constructed with iron tie bars and brass plates forming its skin, filled with stone blocks. Although the specific details of its appearance are not definitively known, contemporary accounts suggest that it had curly hair with bronze or silver spikes radiating like flames on the head. The statue likely depicted Helios in a powerful, commanding pose, possibly with one hand shielding his eyes, similar to other representations of the sun god from the time. Overall, it was designed to project strength and radiance, celebrating Rhodes' victory over its enemies.’
5. RAGFlow
RAGFlow专注于集成检索和生成过程。它简化了RAG应用程序的开发。
主要特点:
- 简化检索和生成之间的连接。
- 允许定制工作流以满足项目需求。
- 易于与各种数据库和文档格式集成。
实践操作:
- 在RAGFlow上注册,然后点击“Try RAGFlow”。
- 点击“Create Knowledge Base”(创建知识库)。
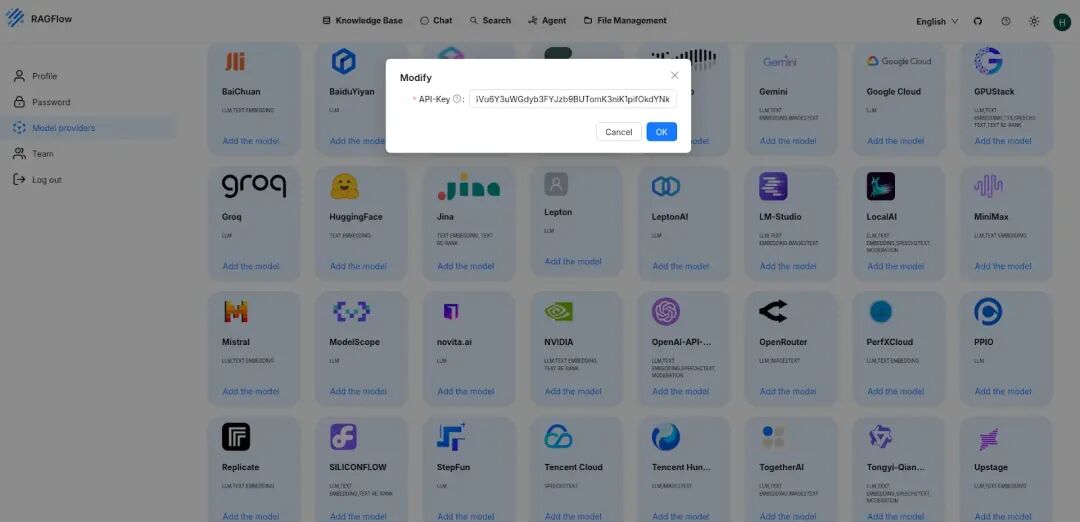
- 进入“Model Providers”(模型提供商),选择你要使用的LLM模型(这里我们使用Groq),并粘贴其API密钥。
- 进入“System Model settings”(系统模型设置),从那里选择聊天模型。
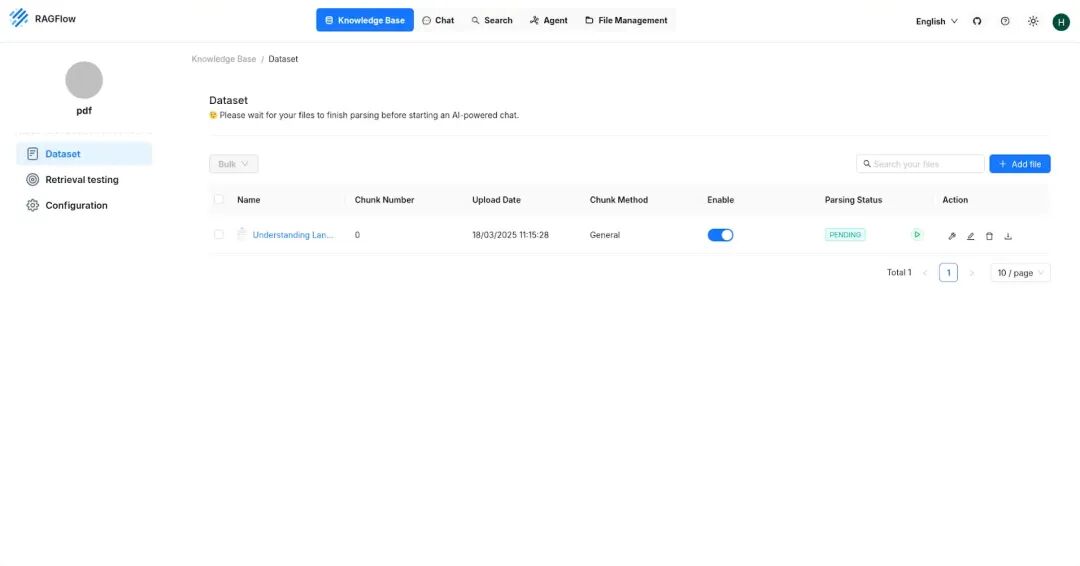
- 现在进入“datasets”(数据集),上传你想要的PDF,然后点击“Parsing status”(解析状态)列旁边的“Play”按钮,等待PDF解析完成。
- 现在进入“chat”(聊天)部分,在那里创建一个助手,给它命名,并选择你创建的知识库。
- 然后创建一个新聊天并提问,它将对你的知识库执行RAG并相应地回答。
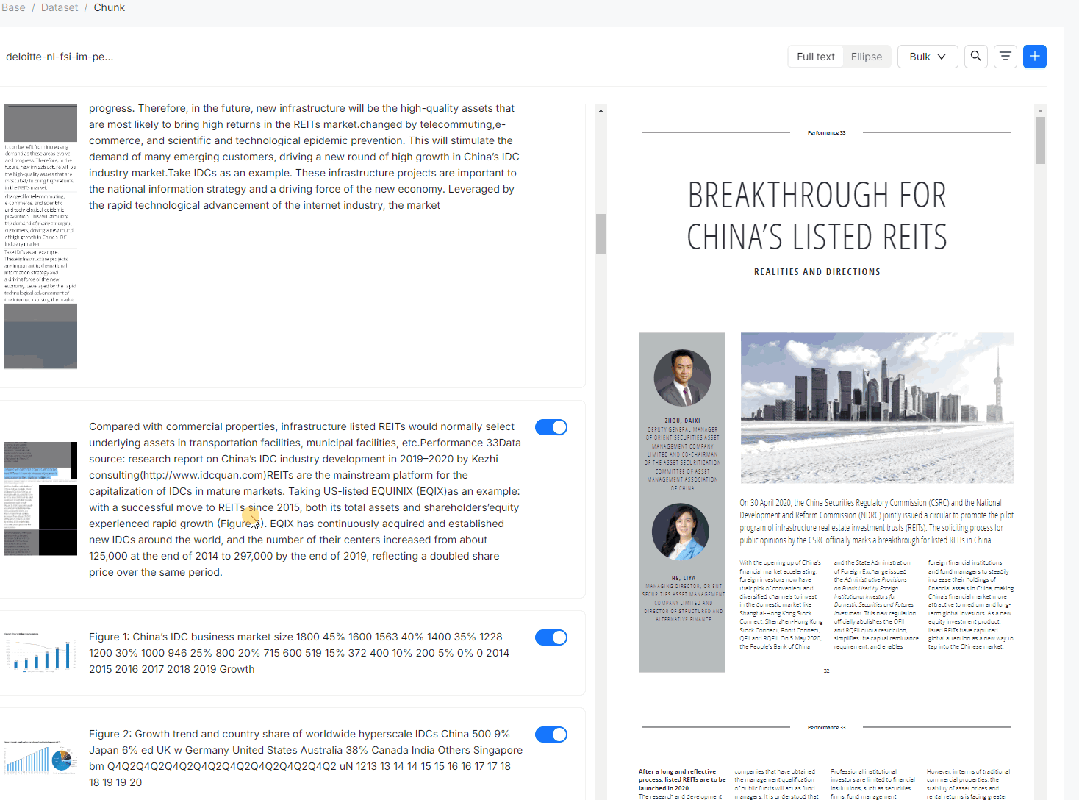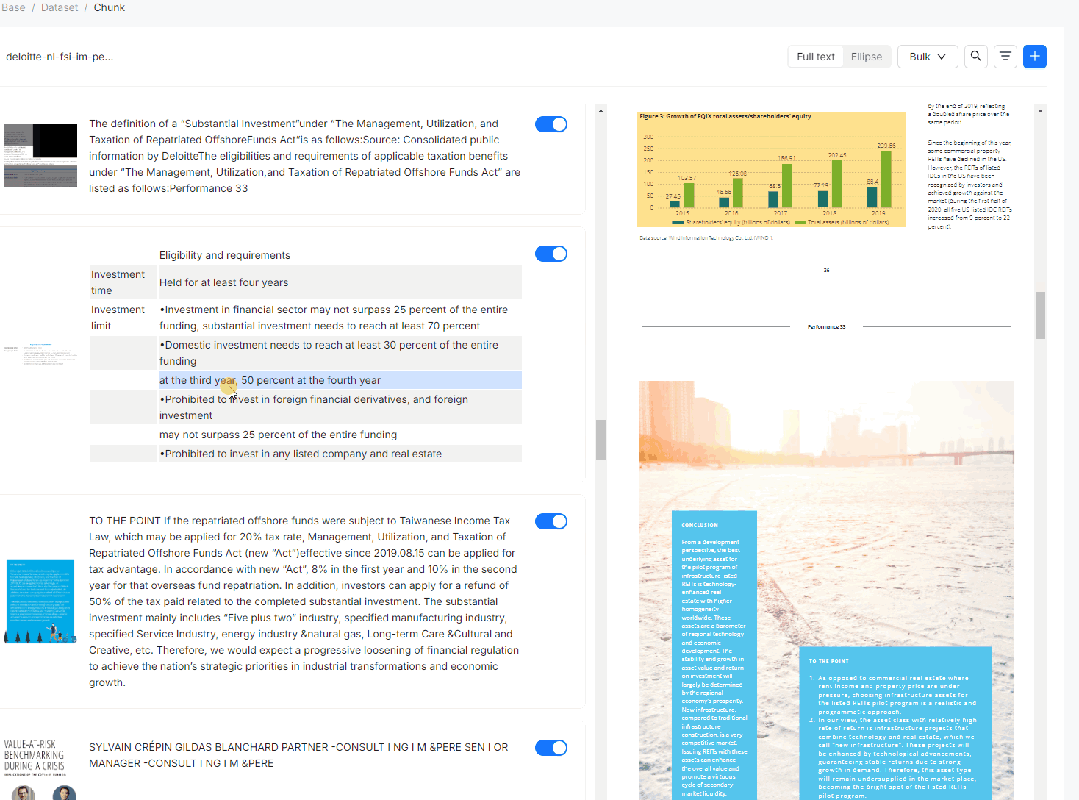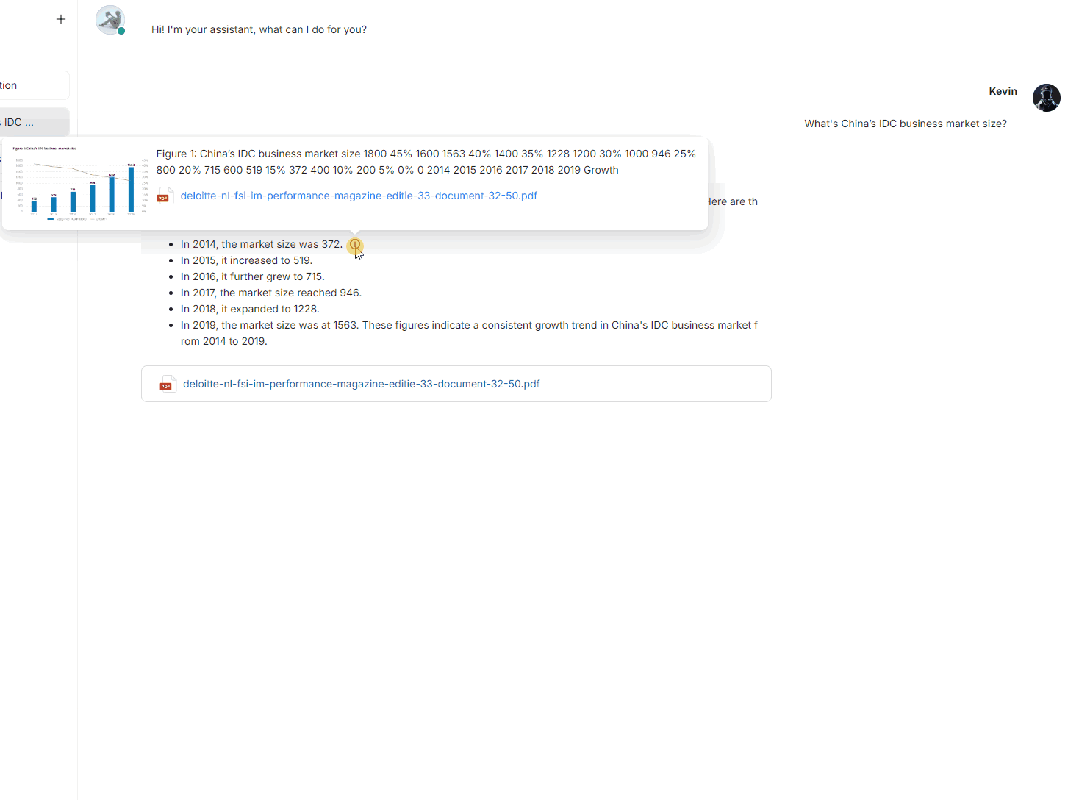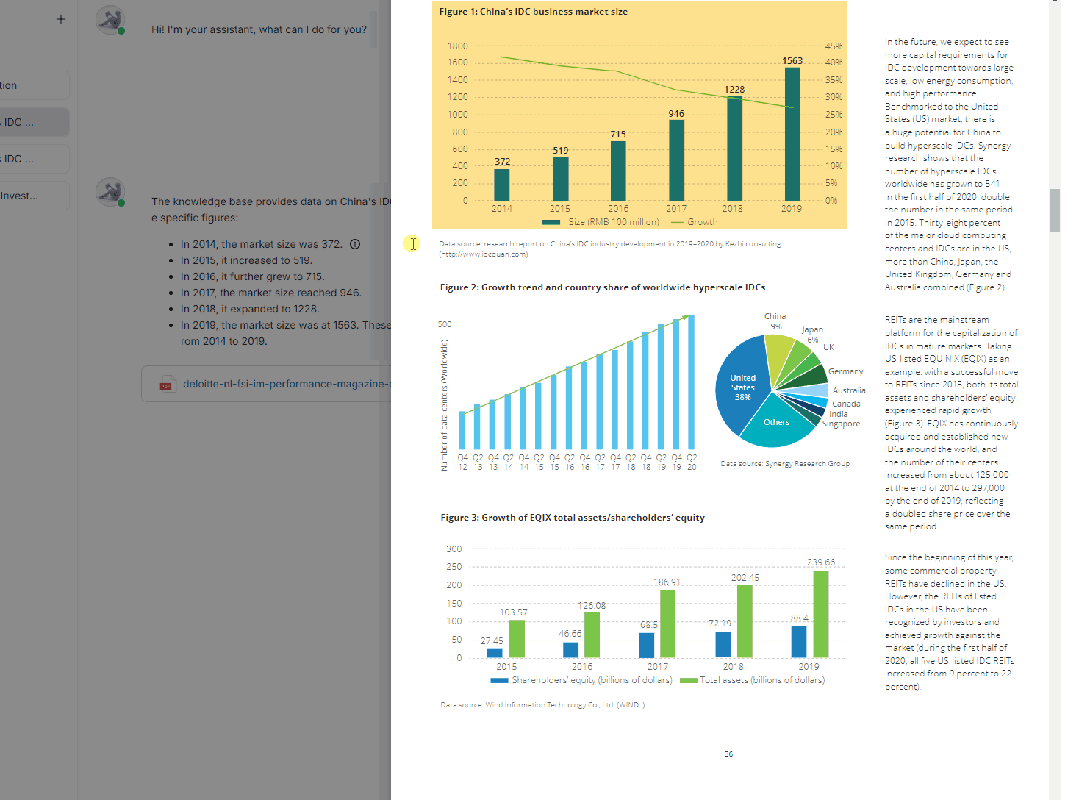
总结
RAG在近期已成为自定义企业数据集的重要技术,因此对RAG框架的需求急剧增加。LangChain、LlamaIndex、LangGraph、Haystack和RAGFlow等框架代表了AI应用的重大进步。通过使用这些框架,开发者可以创建提供准确和相关信息的系统。随着AI的不断发展,这些工具将在塑造智能应用程序方面发挥重要作用。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献435条内容
已为社区贡献435条内容

所有评论(0)