三、大模型(LLM)内部核心机制
从整体上看Transformer LLM接收提示词输入,并输出生成的文本模型并不是一次性生成所有文本,而是一次生成一个词元。每个词元生成步骤都是模型的一次前向传播(在机器学习中,前向传播指的是输入进入神经网络并流经计算图,最终在另一端产生输出所需的计算过程)。在生成当前词元后,我们将输出词元追加到输入提示词的末尾,从而调整下一次生成的输入提示词。神经网络外围的软件基本上就是在循环运行这个模型,按顺
三、大模型(LLM)内部核心机制
我们将探讨Transformer LLM的主要工作原理。
LLM怎么做?我们需要先加载一个语言模型,并定义流水线,以备生成文本。
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=False,
)
# 创建流水线
generator = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
return_full_text=False,
max_new_tokens=50,
do_sample=False,
)
输出:
Transformer模型概述
输入和输出
从整体上看Transformer LLM接收提示词输入,并输出生成的文本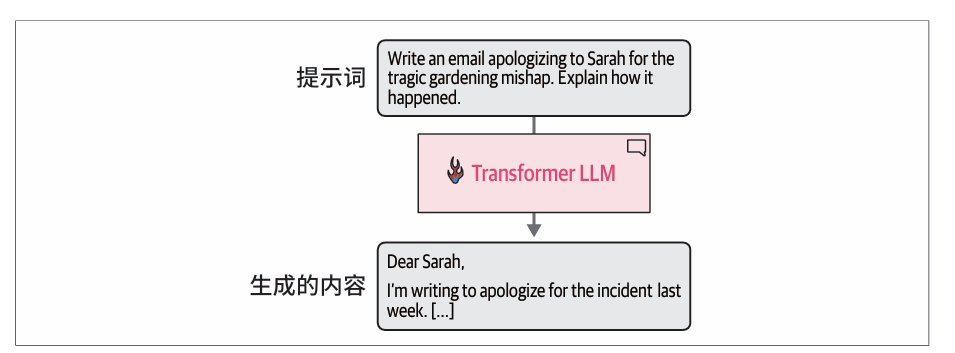
模型并不是一次性生成所有文本,而是一次生成一个词元。每个词元生成步骤都是模型的一次前向传播(在机器学习中,前向传播指的是输入进入神经网络并流经计算图,最终在另一端产生输出所需的计算过程)。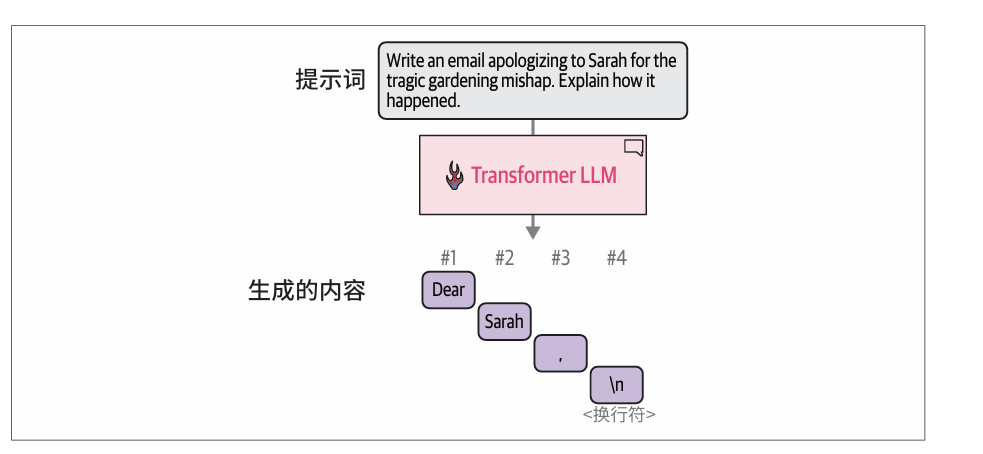
在生成当前词元后,我们将输出词元追加到输入提示词的末尾,从而调整下一次生成的输入提示词。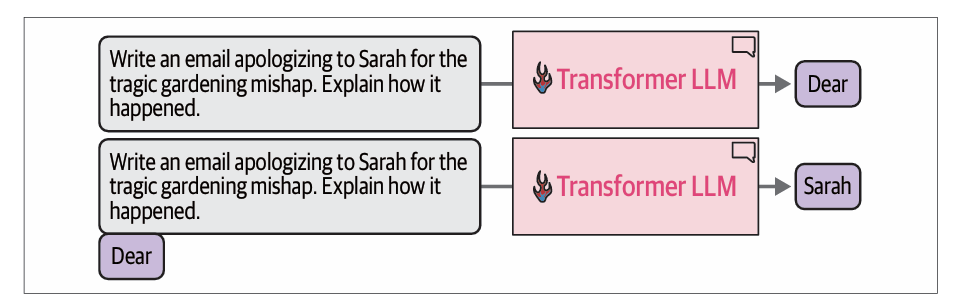
神经网络外围的软件基本上就是在循环运行这个模型,按顺序扩展生成的文本,直到完成。
在机器学习中,有一个专门的词用来描述使用早期预测来进行后续预测的模型(例如,模型使用生成的第一个词元来生成第二个词元),这类模型被称为自回归模型(autoregressive model)。这就是为什么文本生成式LLM也被称为自回归模型。这一名称通常用于区分文本生成模型与像BERT这样的非自回归的文本表示模型。
prompt = "Write an email apologizing to Sarah for the tragic gardening mishap. Explain how it happened."
output = generator(prompt)
print(output[0]['generated_text'])
因为设置的 max_new_tokens 为50 的限制。如果我们将这个值设置得更大,它会继续生成内容,直到完成这封邮件。
输出:
前向传播
前向传播包括两个关键的内部组件:分词器和语言建模头(language modeling head,LM head)。
Transformer LLM由分词器、堆叠的Transformer块和语言建模头组成: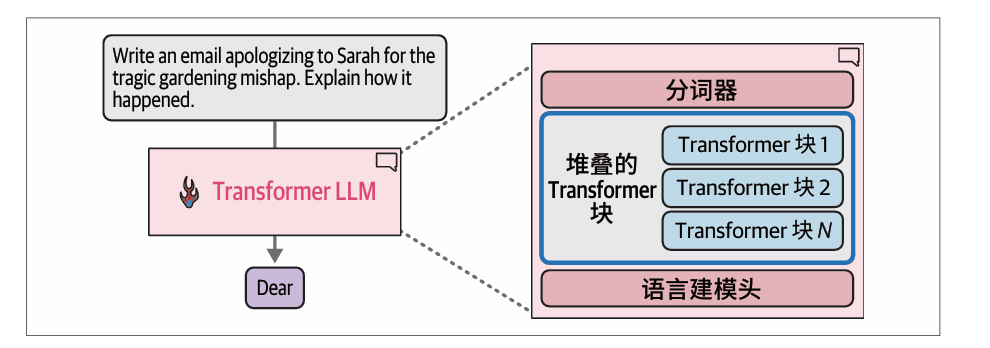
分词器拥有50 000个词元的词表,模型为这些词元关联了词元嵌入: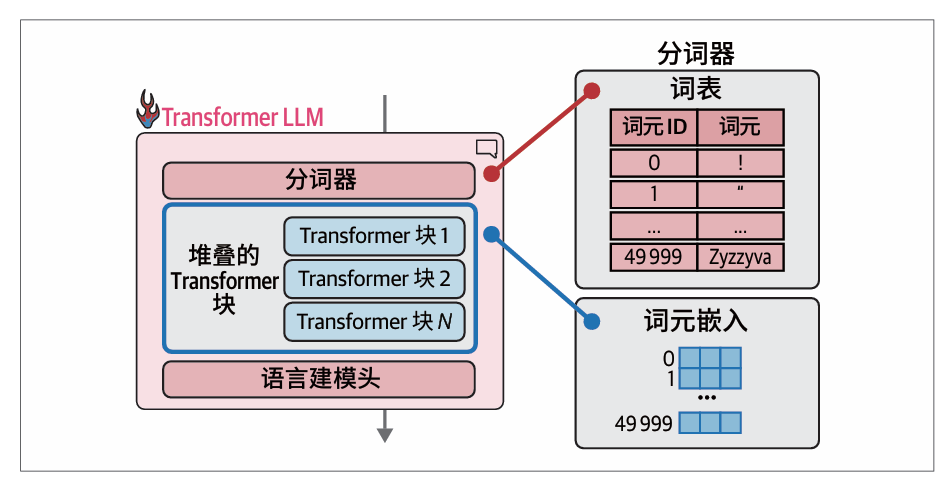
计算流按照箭头方向从上到下进行。对于每个生成的词元,处理过程会按顺序依次经过堆叠成一列的所有Transformer块,然后到达语言建模头,最后输出下一个词元的概率分布: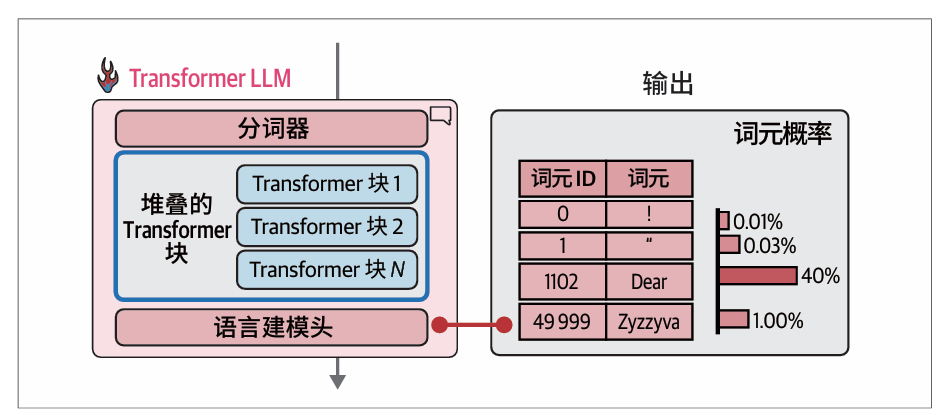
我们只需打印模型变量,就可以按顺序显示所有层:
print(model)
输出:
Phi3ForCausalLM(
(model): Phi3Model(
(embed_tokens): Embedding(32064, 3072, padding_idx=32000)
(layers): ModuleList(
(0-31): 32 x Phi3DecoderLayer(
(self_attn): Phi3Attention(
(o_proj): Linear(in_features=3072, out_features=3072, bias=False)
(qkv_proj): Linear(in_features=3072, out_features=9216, bias=False)
)
(mlp): Phi3MLP(
(gate_up_proj): Linear(in_features=3072, out_features=16384, bias=False)
(down_proj): Linear(in_features=8192, out_features=3072, bias=False)
(activation_fn): SiLUActivation()
)
(input_layernorm): Phi3RMSNorm((3072,), eps=1e-05)
(post_attention_layernorm): Phi3RMSNorm((3072,), eps=1e-05)
(resid_attn_dropout): Dropout(p=0.0, inplace=False)
(resid_mlp_dropout): Dropout(p=0.0, inplace=False)
)
)
(norm): Phi3RMSNorm((3072,), eps=1e-05)
(rotary_emb): Phi3RotaryEmbedding()
)
(lm_head): Linear(in_features=3072, out_features=32064, bias=False)
)
我们可以看到
- 这个结构展示了模型的各种嵌套层。模型的主要部分标记为model,随后是lm_head。
- 在Phi3Model 内部,我们可以看到嵌入矩阵embed_tokens及其维度。它有32 064个词元,每个词元的向量大小为3072。
- dropout层是为了防止过拟合的随即丢失,此处设置为0不进行丢失。
- 我们可以看到下一个主要组件是堆叠的Transformer解码器层。它包含32个Phi3DecoderLayer 类型的块。
- 这些Transformer 块中的每一个都包含一个注意力层和一个前馈神经网络(也称为MLP或多层感知器)。
- 最后,我们看到lm_head接收一个大小为3072的向量,并输出一个大小等于模型所知词元数量的向量。该输出是每个词元的概率分数,帮助我们选择输出词元。
采样/解码
在处理结束时,模型会为词表中的每个词元输出一个概率分数。从概率分布中选择单个词元的方法称为解码策略。
经过模型前向传播后,基于上下文,模型可能输出的概率最高的几个词元。我们的解码策略通过基于概率的采样来决定输出哪个词元: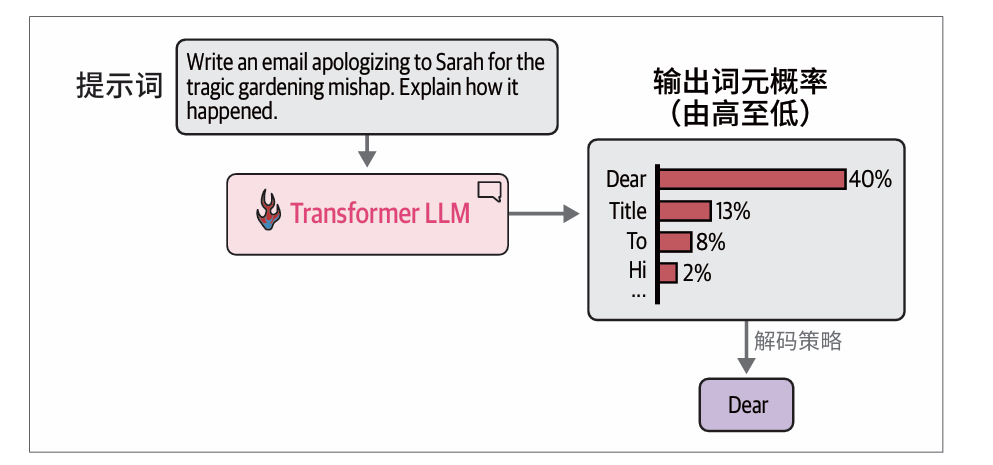
最简单的解码策略就是始终选择概率分数最高的词元。但在实践中,对于大多数使用场景来说,这种方法往往无法产生最佳输出。一个更好的方法是引入一些随机性,有时选择概率第二高或第三高的词元。用统计学家的话来说,这种思想就是根据概率分数对概率分布进行采样。举例来说就是如果Dear作为下一个词元的概率为40%,那么它被选中的概率就是40%(而不是像贪心搜索那样,直接选择这个得分最高的词元)。这样,其他词元也有机会根据其分数被选中。
每次都选择概率分数最高的词元的策略被称为贪心解码。这就是在LLM中将温度(temperature)参数设为零时会发生的情况。
让我们来看看,我们先将输入词元传递给模型,然后传给lm_head:
prompt = "The capital of France is"
# Tokenize the input prompt
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
# Tokenize the input prompt
input_ids = input_ids.to("cuda")
# Get the output of the model before the lm_head
model_output = model.model(input_ids)
# Get the output of the lm_head
lm_head_output = model.lm_head(model_output[0])
lm_head_output.shape
输出:
torch.Size([1, 5, 32064])
我们可以使用 lm_head_output[0,-1] 来访问最后生成的词元的概率分数,其中索引 0 用于批次维度,表示一批数据中的第一个,索引 -1 用于获取序列中的最后一个词元。现在我们得到了全部 32 064个词元的概率分数
列表。接下来我们可以获取得分最高的词元ID,然后解码,以得到生成的输出词元:
token_id = lm_head_output[0,-1].argmax(-1)
tokenizer.decode(token_id)
输出:
Paris
并行词元处理和上下文长度
每个词元都通过自己的计算流进行处理(之后我们会看到,它们在注意力步骤中会有一些交互)
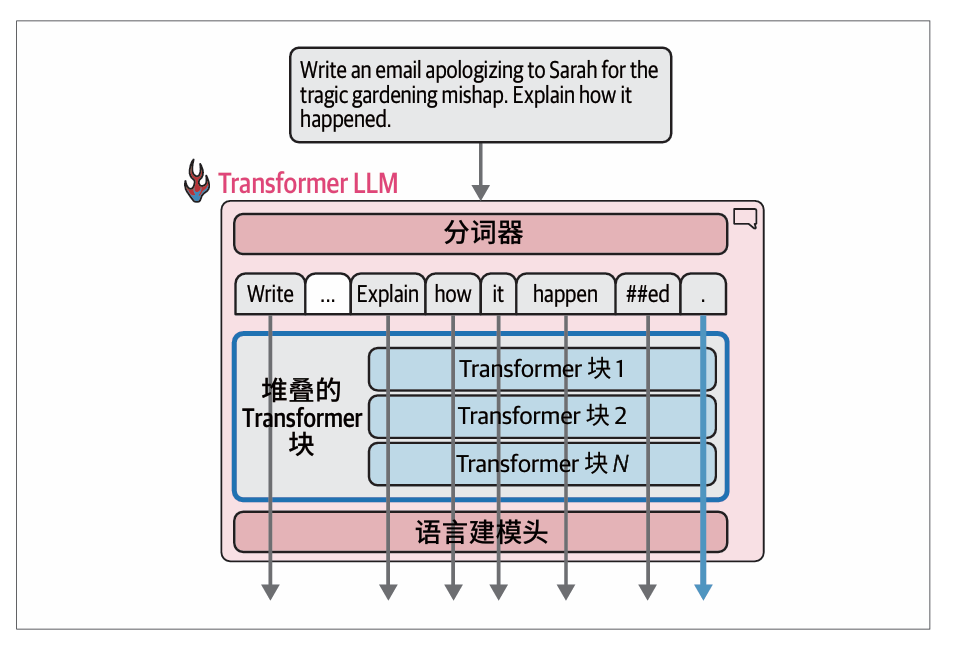
当前的 Transformer 模型对一次可以处理的词元数量有限制,这个限制被称为模型的上下文长度。一个具有4K上下文长度的模型只能处理4000个词元,也就是只有4000条这样的流。
每条处理流接收一个向量作为输入,并生成一个大小相同的最终结果向量(这一大小通常称为模型维度)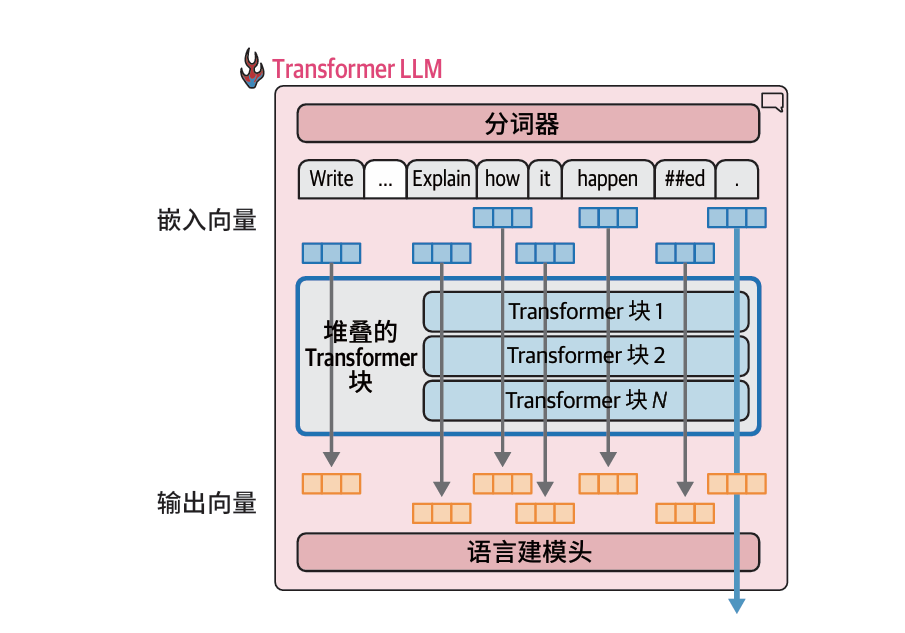
虽然对于文本生成来说,只有最后一条计算流的输出结果用于预测下一个词元。但是之前的流的计算结果是最终的流所必需的。我们不会使用它们的最终输出向量,但会在每个Transformer块的注意力机制中使用其早期输出。
在代码中我们可以看到,lm_head的输出形式为[1, 5, 32064],这是因为它的输入形式为[1, 5, 3072](即(lm_head): Linear(in_features=3072, out_features=32064, bias=False)),代表一个批次中包含一个输入字符串,该字符串包含5个词元,每个词元都由一个大小为3072的向量表示,这些向量对应着堆叠的Transformer块处理后的输出向量。
缓存键−值加速
在生成第二个词元时,我们只是简单地将输出词元追加到输入的末尾,然后再次通过模型进行前向传播。如果模型能够缓存之前的计算结果(特别是注意力机制中的一些特定向量),就不需要重复计算之前的流,而只需要计算最后一条流了。这种优化技术被称为键-值(key-value,KV)缓存,它能显著加快生成过程。键和值是注意力机制的核心组件。
在生成文本时,重要的是缓存之前词元的计算结果,而不是反复进行相同的计算:
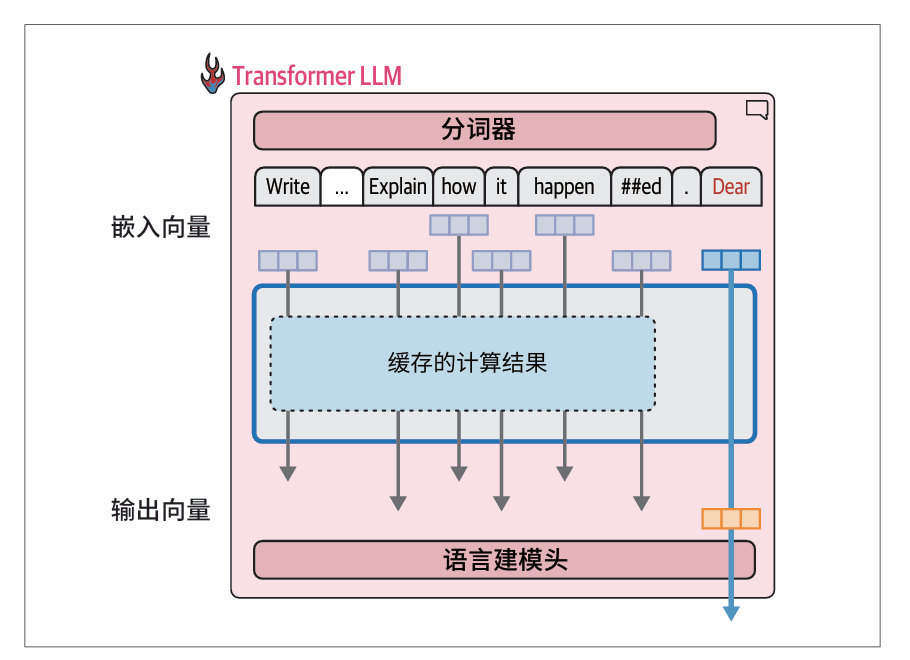
在Hugging Face Transformers 中,缓存默认是启用的,可以将use_cache设置为False来禁用。我们可以请求一个较长的生成任务,并对比启用和禁用缓存的生成时间
prompt = "Write a very long email apologizing to Sarah for the tragic gardening mishap. Explain how it happened."
# Tokenize the input prompt
# 对输入提示词进行分词
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
input_ids = input_ids.to("cuda")
我们测量启用缓存后生成100个词元所需的时间。我们可以在Jupyter或Colab中使用%%timeit 魔法命令来计时(它会多次运行命令并取用时的平均值):
%%timeit -n 1
# Generate the text
generation_output = model.generate(
input_ids=input_ids,
max_new_tokens=100,
use_cache=True
)
输出:4.65 s ± 377 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit -n 1
# Generate the text
generation_output = model.generate(
input_ids=input_ids,
max_new_tokens=100,
use_cache=False
)
输出:30.6 s ± 109 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
明显加速利用这种方式能加速很多。
Transformer块的内部结构
Transformer LLM 由一系列Transformer 块组成(在原始Transformer 论文中约为6 个,而在许多LLM中超过100个)每个块处理其输入,然后将其处理结果传递给下一个块。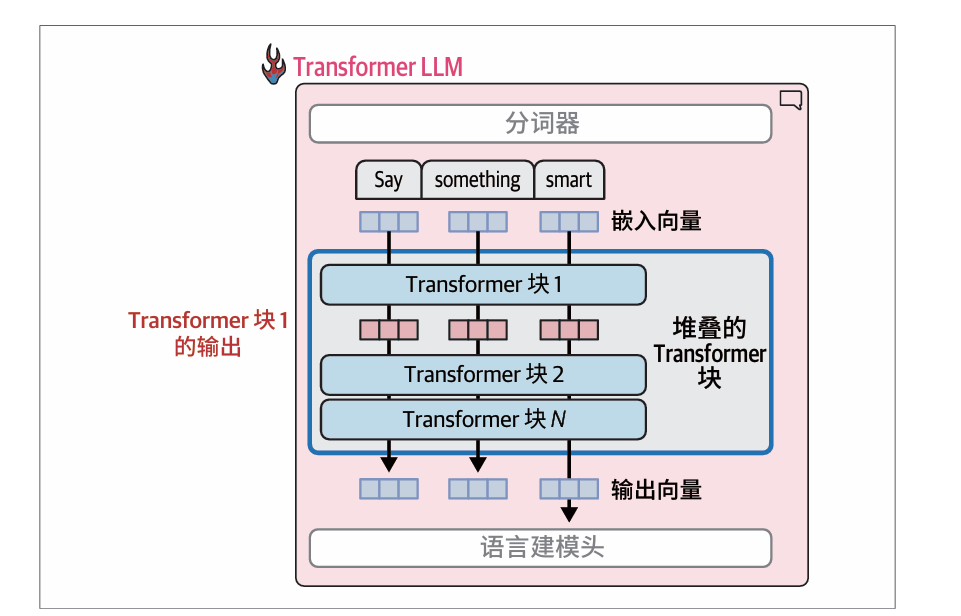
Transformer块由以下两个首尾相接的组件构成:
- 自注意力层,主要负责整合来自其他输入词元和位置的相关信息。
- 前馈神经网络层,包含模型的主要处理能力。
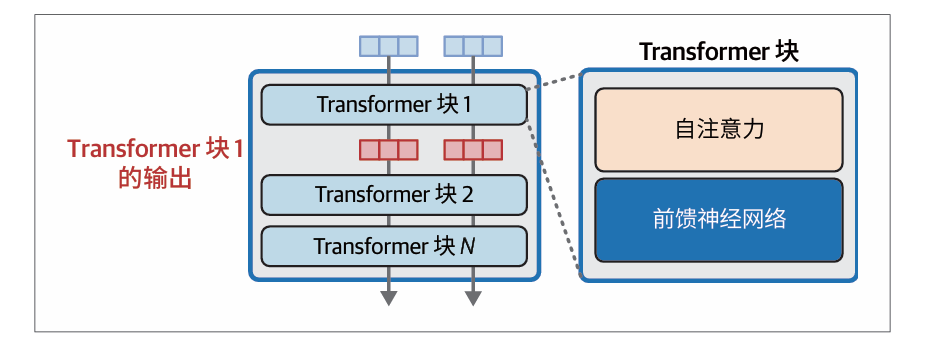
前馈神经网络层块
当模型在大规模文本数据(包含大量对“The Shawshank Redemption”的引用)上完成训练后,它学习并存储了完成这项任务所需的信息(和行为),这就是前馈神经网络(分布在所有模型层中),就是这些信息的来源。Transformer 块中的前馈神经网络层可能承担了模型大部分的记忆和插值工作。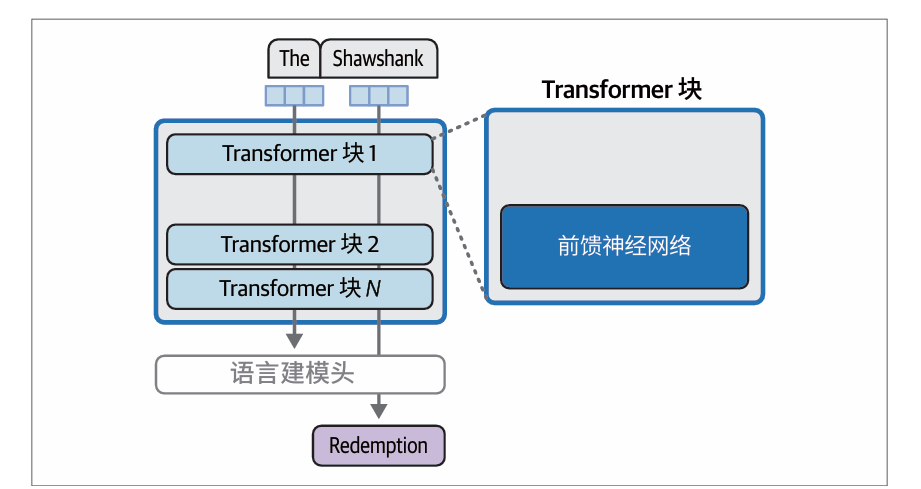
自注意力层块
上下文对于正确建模语言至关重要。仅仅依靠基于前一个词元的简单记忆和插值是远远不够的。自注意力层整合了来自前序位置的相关信息,用于处理当前词元。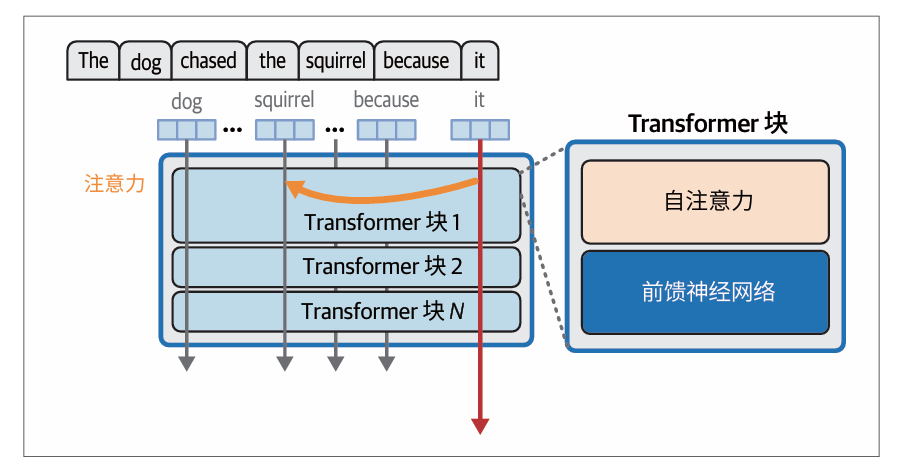
注意力机制
注意力机制包含以下两个主要步骤:
- 对当前处理的词元(粉色箭头所示)与之前输入词元的相关性评分。
- 利用这些分数,将不同位置的信息组合成单一的输出向量。
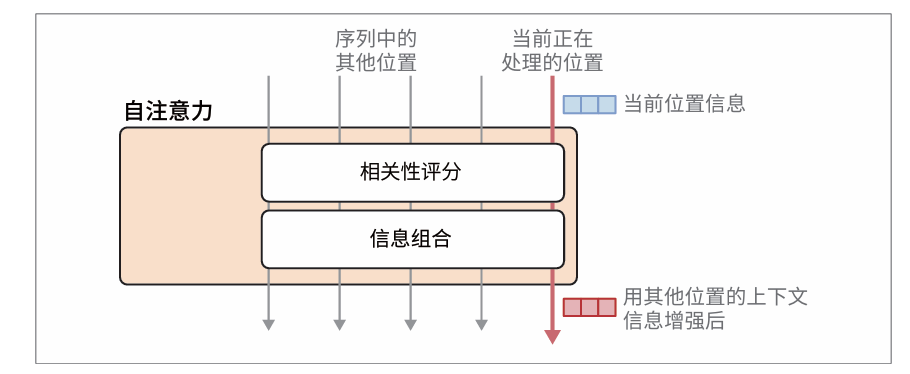
对每个位置进行相关性评分,然后基于这些评分进行信息组合。为了赋予Transformer 更强大的注意力能力,注意力机制被复制多份,并行执行。这些并行的注意力执行过程被称为注意力头(attention head)。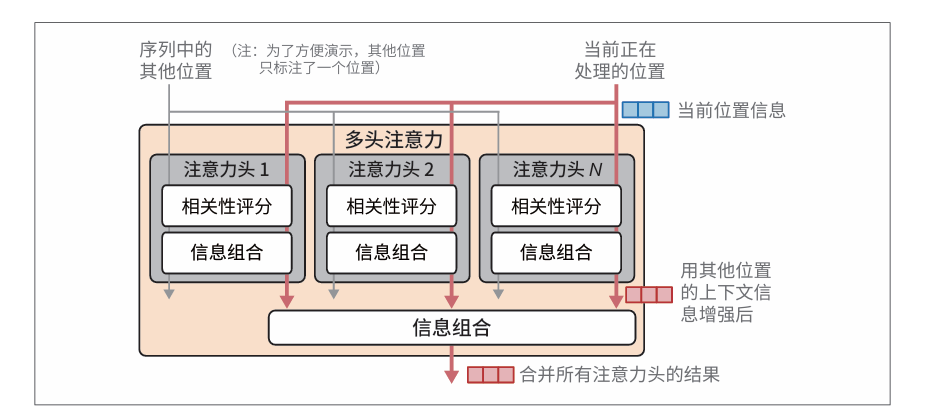
通过并行执行多次注意力计算来获得更好的LLM,提高模型关注不同类型的信息的能力。
注意力的计算方式
注意力首先将输入与投影矩阵相乘,得到三个新矩阵,称为查询矩阵、键矩阵和值矩阵。这些矩阵包含了投影到三个不同空间的输入词元信息,用于执行注意力的两个步骤:相关性评分和信息组合。
重点是其中的训练过程会产生三个投影矩阵,用于生成参与计算的组件:
- 查询投影矩阵
- 键投影矩阵
- 值投影矩阵
在开始注意力计算之前,该层的输入和查询、键、值的投影矩阵已准备就绪: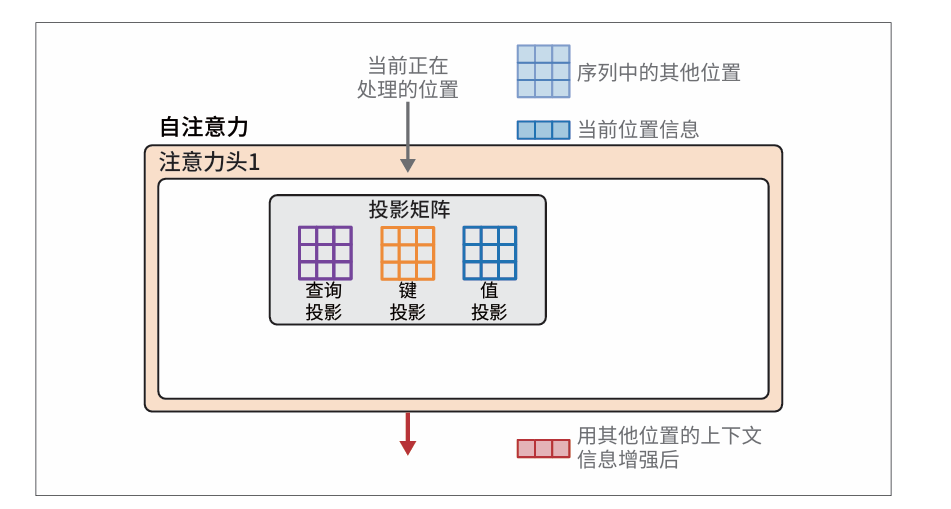
注意力是通过查询矩阵、键矩阵和值矩阵的交互来执行的。这些矩阵是将层的输入与投影矩阵相乘得到的:
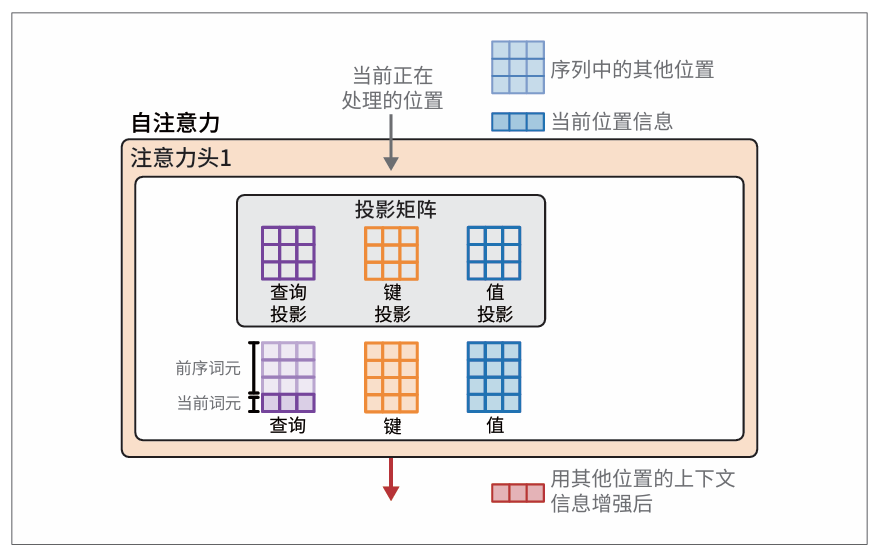
相关性评分
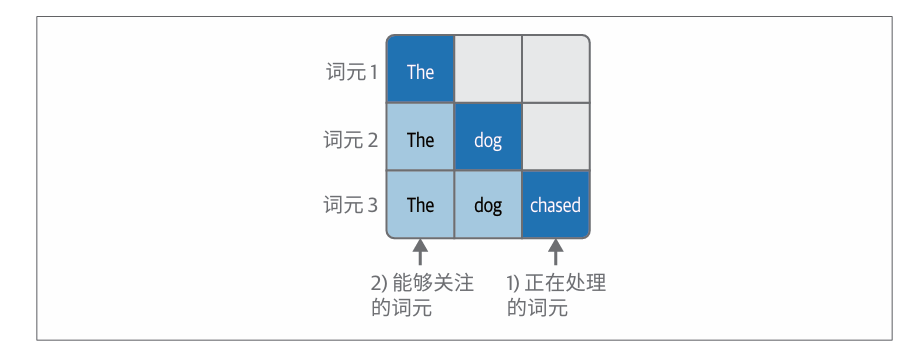
在生成式 Transformer 中,一次生成一个词元意味着一次处理一个位置。因此,注意力机制在这里只关注这一个位置(当前位置),以及如何从其他位置提取信息来为当前位置提供参考。
注意力机制的相关性评分步骤是通过将当前位置的查询向量与键矩阵相乘来实现的。操作会产生一组分数,用以衡量当前位置之前的每一个词元的相关性。接下来,通过softmax 操作对这些分数进行归一化,使它们的和为1。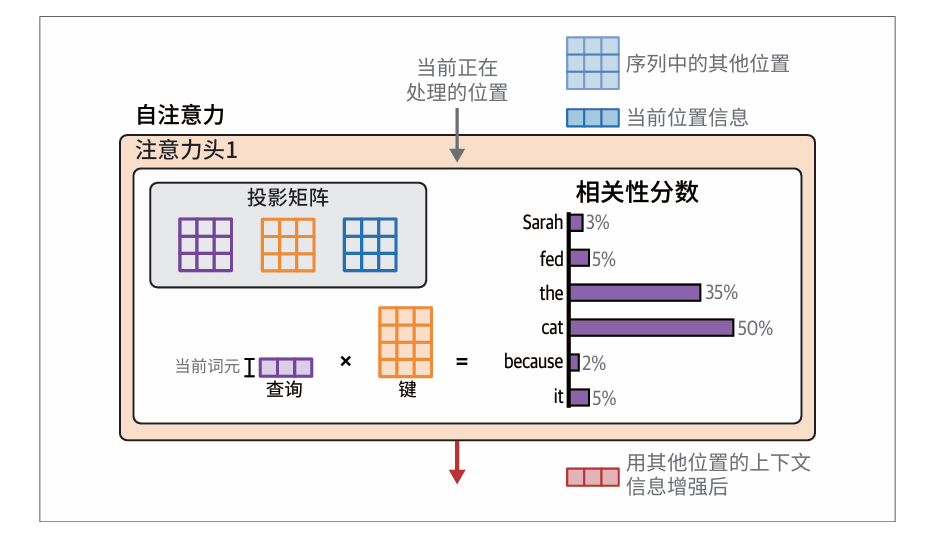
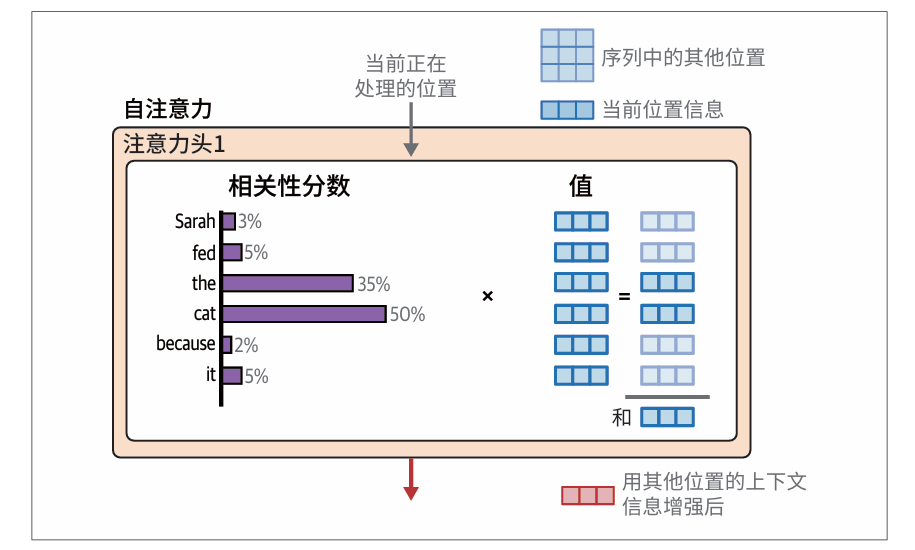
信息组合
有了相关性分数,我们用每个词元对应的值向量乘以该词元的分数,然后将这些结果向量相加,就得到了注意力步骤的输出
Transformer架构改进
更高效注意力机制
稀疏注意力
随着Transformer 规模越来越大,稀疏注意力(参见论文“Generating Long Sequences with Sparse Transformers”)和滑动窗口注意力(参见论文“Longformer: The Long-Document Transformer”)等理念提高了注意力计算的效率。
稀疏注意力通过只关注少量前序位置来提升性能(GPT-3 就是一个集成了这种机制的模型,GPT-3架构交替使用全注意力和稀疏注意力的Transformer块。):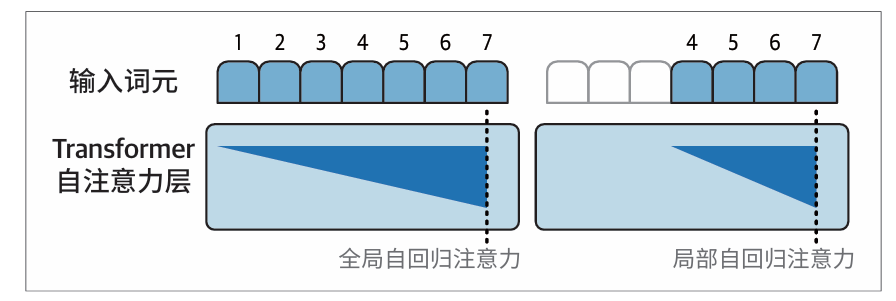
全注意力与稀疏注意力的对比,每一行对应正在处理一个词元。颜色编码表示模型在处理深蓝色单元格中的词元时能够关注哪些词元: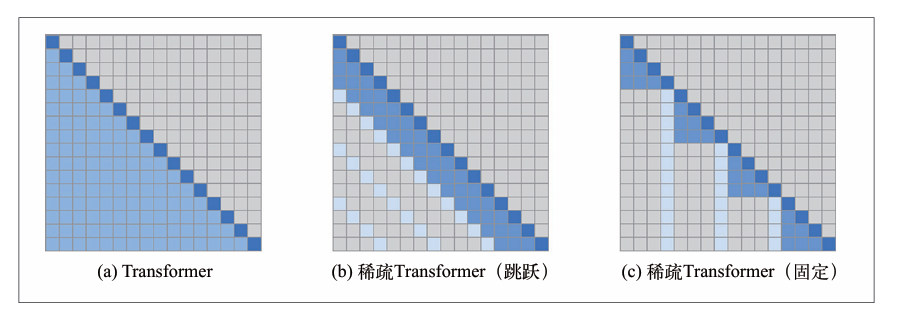
多/分组查询注意力
关于Transformer中的注意力,最近一项提高效率的改进是分组查询注意力(grouped-query attention,GQA,参见论文“GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”),它被Llama 2和Llama 3等模型使用。
不同类型注意力的比较:原始的多头注意力、分组查询注意力和多查询注意力:
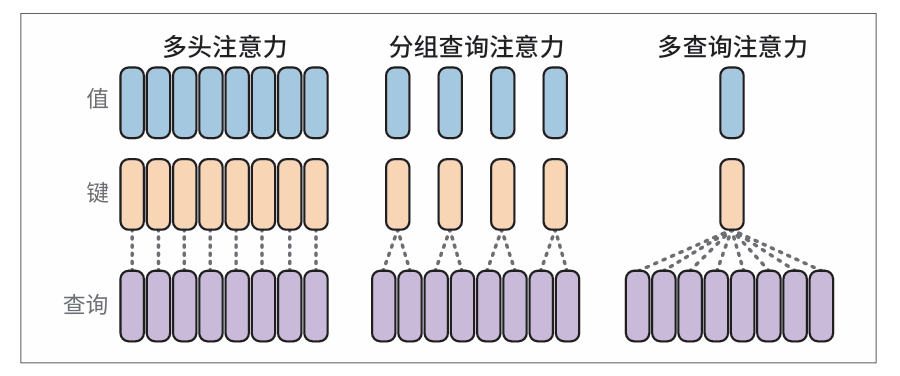
优化注意力机制
主要是从多头到多查询再到分组查询的更新。
注意力机制通过查询矩阵、键矩阵和值矩阵来实现。在多头注意力中,每个注意力头都有一组独立的查询矩阵、键矩阵和值矩阵: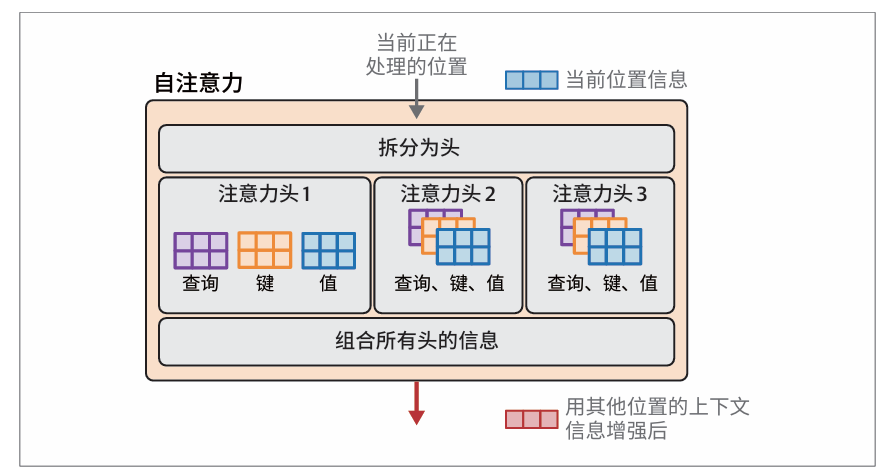
多查询注意力通过在所有注意力头之间共享键矩阵和值矩阵来实现优化,每个注意力头只保留独特的查询矩阵:
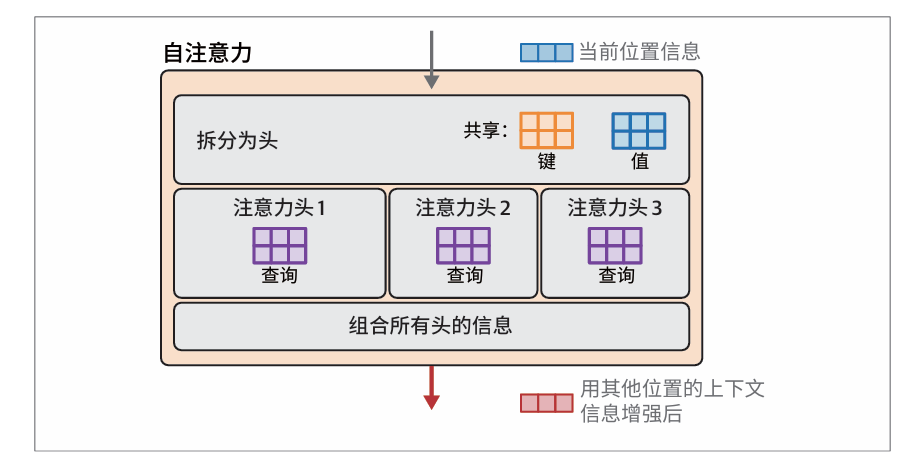
然而,随着模型规模的增长,这种优化可能会带来过大的性能损失。分组查询注意力利用多组共享的键矩阵和值矩阵,牺牲了一些多查询注意力的效率来换取质量的大幅提升。每个分组都有其对应的注意力头集合: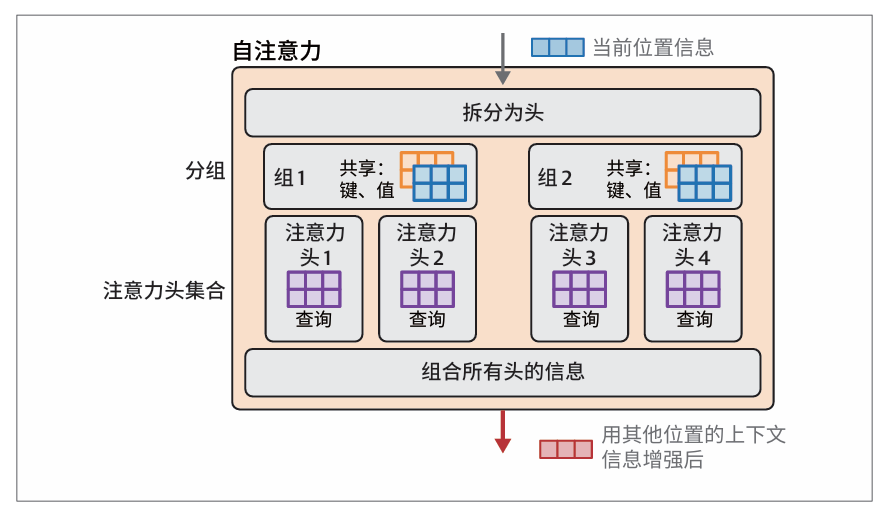
Flash Attention
它通过优化GPU共享内存(GPU’s shared memory,SRAM)和高带宽内存(high bandwidth memory,HBM)之间的数据加载和迁移来加速注意力计算。详细内容可参见论文“FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”以及后续的“FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning”。
Transformer块
原始Transformer论文中的Transformer块: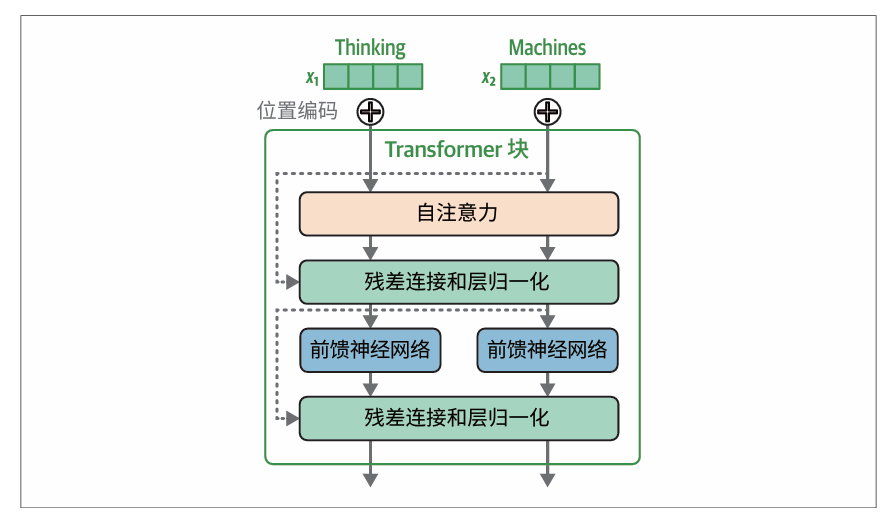
2024年的Transformer(如Llama 3)的Transformer块有一些新的改进,如预归一化(通过RMSNorm实现),以及通过分组查询注意力和旋转位置嵌入优化的注意力机制:
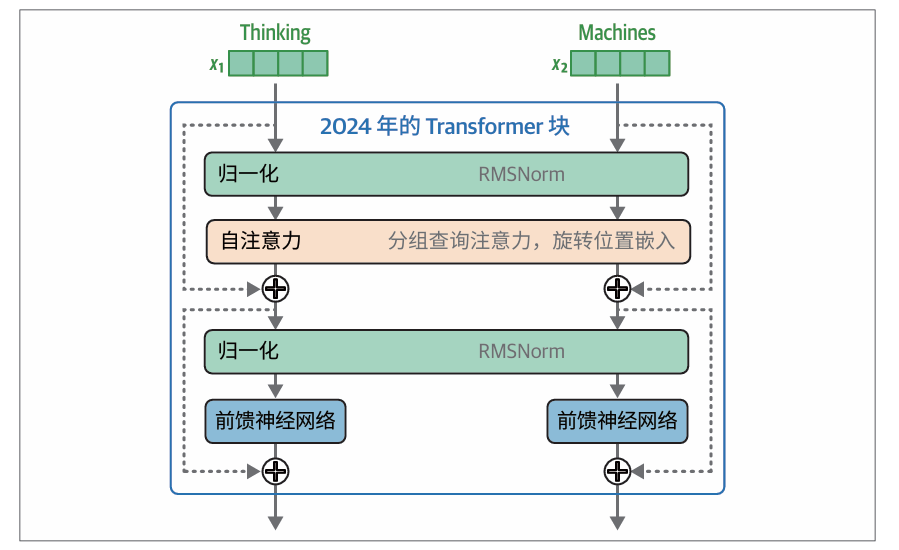
改进有:归一化发生在自注意力层和前馈神经网络层之前,这种方式可以减少所需的训练时间。以及使用RMSNorm,它比原始Transformer中使用的LayerNorm更简单、更高效。
位置嵌入:RoPE
位置嵌入自原始Transformer以来一直是关键组件。它们使模型能够跟踪序列/句子中词元/词的顺序,这是语言中不可或缺的信息来源。原始Transformer 论文和一些早期变体采用绝对位置嵌入,本质上是将第一个词元标记为位置1,第二个标记为位置2,以此类推。这些方法可以是静态的(使用几何函数生成位置向量)或可学习的(模型在训练过程中为它们赋值)。
当我们将模型扩展到更大的规模时,这些方法会带来一些挑战,这要求我们找到提高其效率的途径。举例来说,在训练长上下文模型时的一个挑战是,训练集中有很多文档的长度都远小于上下文长度。如果为一个只有10个词的短句分配整个4K的上下文空间,这显然是很低效的。因此在模型训练过程中,多个文档会被一同打包到每个训练批次的上下文中:

与在前向传播开始时添加的静态绝对嵌入不同,旋转位置嵌入是一种以捕获绝对和相对词元位置信息的方式来编码位置信息的方法,其思想的基础是嵌入空间中旋转的向量。在前向传播中,旋转位置嵌入是在注意力步骤中添加的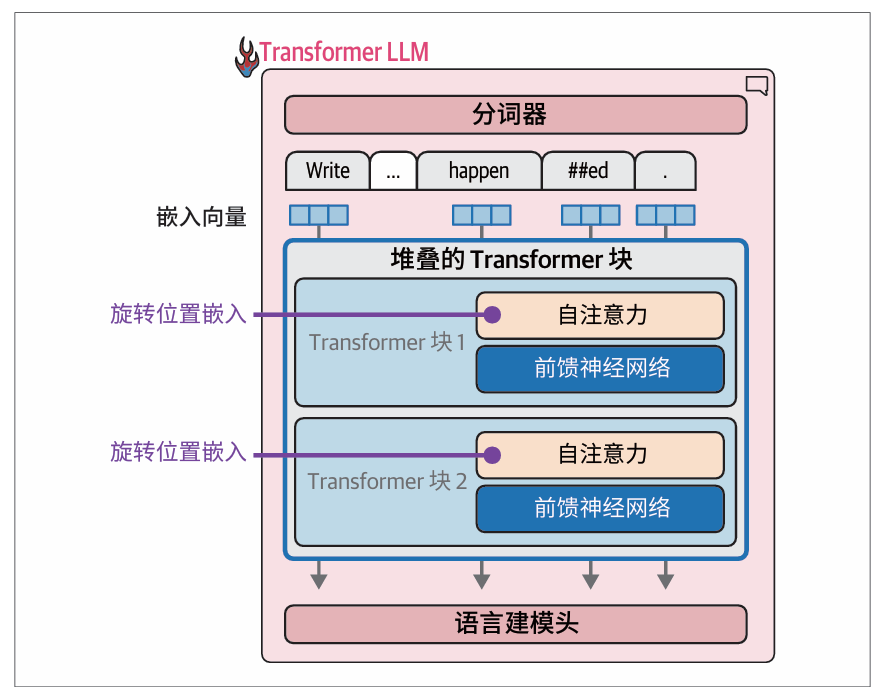
在注意力步骤中,我们特意把位置信息混合到查询矩阵和键矩阵中。这个混合过程发生在我们将查询向量和键矩阵相乘,进行相关性评分之前:
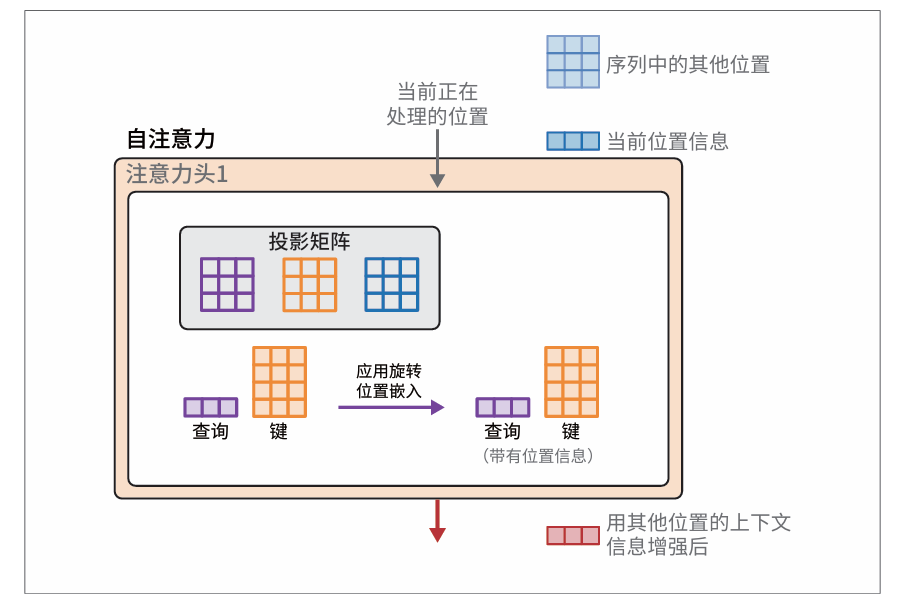
其它
Transformer架构也在不断适应LLM之外的领域。计算机视觉是一个有大量Transformer架构研究参与的领域(参见论文“Transformers in Vision: A Survey”和“A Survey on Vision Transformer”)。其他领域包括机器人技术(参见论文“Open X-Embodiment: Robotic Learning Datasets and RT-X Models”)和时间序列(参见论文“Transformers in Time Series: A Survey”)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)