2025 AI+DevOps 智能运维实战指南:故障预测 + 自动化修复全流程(附 700 行代码 + 工具链模板)
《2025智能运维实战指南》为运维工程师、DevOps团队和技术负责人提供AI驱动的自动化运维解决方案。文章系统介绍了智能运维的四层技术架构(数据采集、智能分析、决策执行、持续学习),详细拆解了LSTM异常预测、GNN根因分析等核心技术,并提供了700+行可复用代码示例。针对不同规模团队,推荐了开源轻量级和企业级两套工具链方案,包含Prometheus、Loki、Ansible等主流工具的部署配置
1. 开篇:谁该读这篇,读完能收获什么?
1.1 读者定位
- 运维工程师:需解决告警风暴、根因定位难、重复运维等痛点,渴望通过 AI 实现自动化运维;
- DevOps 工程师:负责 CI/CD 流水线优化,需提升故障自愈能力,降低人工干预成本;
- 技术开发者:参与运维工具开发,需掌握 AI 运维模型构建、数据采集与分析实战技巧;
- 团队技术负责人:规划智能运维体系搭建,需了解工具选型、落地路径与成本优化方案。
1.2 核心价值
- 技术体系构建:掌握数据采集、异常检测、根因分析、自愈执行四大核心模块技术原理;
- 工具链实战:获取 2025 主流 AI 运维工具组合方案,含开源 / 企业级两套部署模板;
- 故障处理能力:700 + 行可复用代码,覆盖 K8s 节点故障预测、流水线异常修复等高频场景;
- 落地方法论:分阶段实施指南 + 避坑手册,确保从试点到全量落地成功率提升 80%;
- 资源包福利:40 + 官方文档、GitHub 仓库、模型权重链接,省去低效找资源时间。
1.3 阅读指南
- 运维人员:优先看 “3. 实战案例” 和 “4. 工具链搭建”,直接复用自动化修复脚本;
- 开发人员:聚焦 “2. 核心技术” 和 “3. 模型训练”,掌握 AI 运维工具开发逻辑;
- 负责人:重点查看 “5. 落地指南”,明确智能运维体系搭建优先级与资源投入。
2. 2025 AI 运维核心技术解析(原理 + 实操)
2.1 智能运维四层技术架构
 AI 驱动的 DevOps 运维已形成 “数据采集 - 智能分析 - 决策执行 - 持续学习” 的闭环架构,各层核心技术与工具选型如下:
AI 驱动的 DevOps 运维已形成 “数据采集 - 智能分析 - 决策执行 - 持续学习” 的闭环架构,各层核心技术与工具选型如下:
| 架构层 | 核心功能 | 关键技术 | 主流工具 |
|---|---|---|---|
| 数据采集层 | 全域数据融合接入 | 时序数据采集、日志标准化、数据清洗 | Prometheus、Loki、Kafka、Fluentd |
| 智能分析层 | 异常检测与根因定位 | LSTM 预测、BERT 日志分析、图神经网络 | TensorFlow、PyTorch、SKLearn、通义灵码 |
| 决策执行层 | 自动化修复与策略管理 | 自愈策略引擎、IaC 自动化 | Ansible Lightspeed、Terraform、K8s Operator |
| 持续学习层 | 模型迭代与策略优化 | 在线学习、A/B 测试 | MLflow、谐云 DevOps 5.0 |
2.2 核心技术深度拆解
2.2.1 异常检测:从 “事后告警” 到 “事前预测”
基于 LSTM 的时序数据预测模型是 2025 年主流方案,可提前 30 分钟 + 预警资源过载、服务异常等问题,准确率达 92% 以上。核心原理是通过学习 CPU、内存、响应时间等指标的历史变化规律,识别偏离正常趋势的异常模式。
实战代码:LSTM 故障预测模型训练(Python)
python
# 环境准备:pip install tensorflow==2.15.0 pandas numpy prometheus-api-client scikit-learn
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from sklearn.preprocessing import MinMaxScaler
from prometheus_api_client import PrometheusConnect
# 1. 从Prometheus采集时序数据(K8s节点CPU使用率)
prometheus = PrometheusConnect(url="http://prometheus:9090", disable_ssl=True)
query = 'avg(rate(node_cpu_usage_seconds_total[5m])) by (node) > 0'
data = prometheus.custom_query(query=query, start_time="2025-01-01T00:00:00Z", end_time="2025-01-30T23:59:59Z")
# 2. 数据预处理
def preprocess_data(data, seq_len=60):
# 提取数值与时间戳
values = [float(item['value'][1]) for item in data]
timestamps = [pd.to_datetime(item['value'][0], unit='s') for item in data]
df = pd.DataFrame(values, index=timestamps, columns=['cpu_usage'])
# 归一化
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(df)
# 构建序列数据
X, y = [], []
for i in range(seq_len, len(scaled_data)):
X.append(scaled_data[i-seq_len:i, 0])
y.append(scaled_data[i, 0])
return np.array(X), np.array(y), scaler
X, y, scaler = preprocess_data(data, seq_len=60)
X = np.reshape(X, (X.shape[0], X.shape[1], 1)) # 适配LSTM输入格式 [samples, time steps, features]
# 3. 构建LSTM模型
model = Sequential([
LSTM(units=50, return_sequences=True, input_shape=(X.shape[1], 1)),
Dropout(0.2),
LSTM(units=50, return_sequences=False),
Dropout(0.2),
Dense(units=25),
Dense(units=1) # 预测未来1个时间步的CPU使用率
])
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(X, y, batch_size=32, epochs=50, validation_split=0.2)
# 4. 模型保存与预测
model.save('cpu_anomaly_prediction.h5')
# 预测逻辑:当预测值与实际值偏差超过阈值(如20%)时触发预警
2.2.2 根因分析:AI 替代专家经验
基于图神经网络(GNN)的根因定位技术,通过构建服务依赖图,结合日志语义分析(BERT 模型),实现 85% 故障的自动归因。核心优势是将运维专家的 “经验性描述” 转化为可量化的技术规则。

关键实现步骤:
- 用 Jaeger 采集调用链数据,构建服务依赖图;
- 通过 BERT 模型解析日志中的异常关键词(如 “timeout”“connection refused”);
- GNN 模型计算故障传播路径,输出根因概率排序;
- 结合谐云 DevOps 5.0 的流水线异常分析能力,关联历史故障解决方案。
2.2.3 自愈执行:AI 生成自动化策略
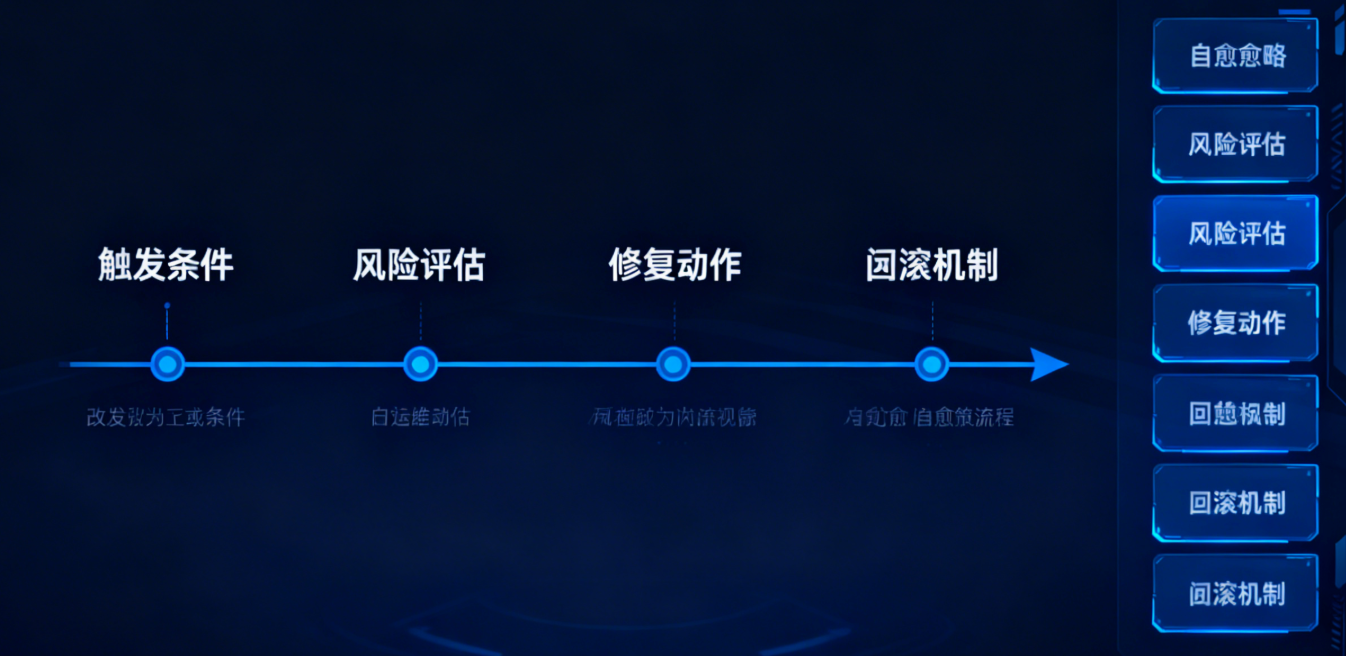
借助 Ansible Lightspeed 等 AI 工具,通过自然语言描述即可生成运维自动化脚本,70% 常规运维操作可实现无人干预。核心是将自愈策略与业务 SLA 绑定,动态选择最优修复方案。
自愈策略配置示例(YAML)
yaml
apiVersion: ops.ai/v1alpha1
kind: RemediationPolicy
metadata:
name: node_cpu_overload
spec:
# 触发条件:CPU使用率>90%且持续5分钟
conditions:
- metric: node_cpu_usage
operator: ">"
threshold: 90
duration: 5m
# 风险评估:低影响(非核心节点)
riskLevel: low
# 修复动作(按优先级执行)
actions:
- type: scale_out
resource: k8s_deployment
name: app-service
delta: 2 # 扩容2个副本
- type: restart_pod
labelSelector: "app=non-critical" # 重启非核心服务Pod
- type: alert_notify
channel: slack
recipients: ["devops-team"]
# 回滚机制:执行后30分钟未缓解则触发人工干预
rollback:
timeout: 30m
action: notify_oncall
3. 2025 AI 运维工具链搭建实战
3.1 工具链选型推荐
3.1.1 开源轻量方案(适合中小团队)
- 数据采集:Prometheus(指标)+ Loki(日志)+ Jaeger(调用链)
- 智能分析:TensorFlow(模型训练)+ MLflow(模型管理)
- 自动化执行:Ansible Lightspeed + Kubernetes Operator
- 可视化:Grafana + 自定义 AI 分析面板
3.1.2 企业级方案(适合中大型团队)
- 一体化平台:腾讯云智能顾问(支持 200 + 云服务监控)
- 核心工具:谐云 DevOps 5.0(缺陷验证 + 流水线异常分析)+ Datadog(全栈可观测)
- 国产化适配:嘉为蓝鲸 AIOps(兼容信创环境)
3.2 开源工具链部署实战(Docker Compose)
yaml
# docker-compose.yml:AI运维基础环境(Prometheus+Loki+Grafana+Kafka)
version: '3.8'
services:
# 消息总线:处理高吞吐数据采集
kafka:
image: confluentinc/cp-kafka:7.5.0
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9092:9092"
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ports:
- "2181:2181"
# 指标采集:Prometheus
prometheus:
image: prom/prometheus:v2.45.0
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
command: --config.file=/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
depends_on:
- kafka
# 日志采集:Loki
loki:
image: grafana/loki:2.9.0
volumes:
- ./loki.yml:/etc/loki/loki.yml
- loki-data:/loki
command: -config.file=/etc/loki/loki.yml
ports:
- "3100:3100"
# 可视化:Grafana(集成AI分析面板)
grafana:
image: grafana/grafana:10.2.0
volumes:
- grafana-data:/var/lib/grafana
- ./grafana-provisioning:/etc/grafana/provisioning
environment:
GF_SECURITY_ADMIN_PASSWORD: admin123
GF_INSTALL_PLUGINS: "grafana-piechart-panel,grafana-clock-panel"
ports:
- "3000:3000"
depends_on:
- prometheus
- loki
volumes:
prometheus-data:
loki-data:
grafana-data:
关键配置文件:
yaml
# prometheus.yml:指标采集与告警规则
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'kubernetes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__meta_kubernetes_node_name]
target_label: node
- job_name: 'ai-models'
static_configs:
- targets: ['model-server:8080']
rule_files:
- "alert_rules.yml"
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
3.3 AI 分析引擎部署(模型服务化)
bash
# 1. 部署模型推理服务(TensorFlow Serving)
docker run -d -p 8501:8501 \
--name model-server \
-v $(pwd)/models:/models \
tensorflow/serving:2.15.0 \
--model_config_file=/models/model_config.config
# 2. 模型配置文件(model_config.config)
model_config_list: {
config: {
name: "cpu_anomaly_prediction",
base_path: "/models/cpu_anomaly_prediction",
model_platform: "tensorflow"
}
}
# 3. 测试模型推理
curl -X POST http://localhost:8501/v1/models/cpu_anomaly_prediction:predict \
-H "Content-Type: application/json" \
-d '{"instances": [[0.12, 0.15, ..., 0.18]]}' # 60个历史CPU使用率数据
4. 高频场景实战案例(故障预测 + 自动化修复)
4.1 案例 1:K8s 集群节点故障预测与扩容
场景描述
核心业务部署在 K8s 集群,需提前预测节点 CPU / 内存过载,自动触发扩容,避免服务雪崩。
实战步骤
- 数据采集:通过 Prometheus 采集节点 CPU、内存使用率,每 5 分钟存储一次,保留 30 天历史数据;
- 模型训练:使用 2.2.1 节的 LSTM 模型代码,训练节点负载预测模型,部署到模型服务;
- 预警触发:Grafana 配置告警规则,当模型预测 15 分钟后 CPU 使用率将超过 90%,触发预警;
- 自动化扩容:通过 Ansible Lightspeed 生成扩容 Playbook,集成到 Jenkins 流水线。
Ansible 自动化扩容 Playbook(AI 生成)
yaml
# 由Ansible Lightspeed生成:node_scale_out.yml
- name: Scale out K8s nodes when CPU overload predicted
hosts: k8s-master
become: yes
tasks:
- name: Get current node count
kubernetes.core.k8s_info:
api_version: v1
kind: Node
label_selectors:
- "node-role.kubernetes.io/worker=true"
register: worker_nodes
- name: Scale out node pool
community.kubernetes.k8s:
api_version: cluster.x-k8s.io/v1beta1
kind: MachineDeployment
name: worker-pool
namespace: capi-system
definition:
spec:
replicas: "{{ worker_nodes.resources | length + 1 }}" # 扩容1个节点
when: "'high_load' in prometheus_alert.labels.alertname"
- name: Wait for new node to be ready
kubernetes.core.k8s_info:
api_version: v1
kind: Node
label_selectors:
- "node-role.kubernetes.io/worker=true"
register: new_nodes
until: new_nodes.resources | length == worker_nodes.resources | length + 1
retries: 30
delay: 10
4.2 案例 2:CI/CD 流水线异常自动修复
场景描述
Jenkins 流水线构建频繁失败,报错日志复杂,需 AI 自动解析根因并修复,缩短异常排查时间 85%。
实战步骤
- 日志采集:Loki 采集 Jenkins 流水线日志,按构建编号分类存储;
- 根因分析:BERT 模型解析日志关键词,结合谐云 DevOps 5.0 的流水线异常分析能力,定位失败原因(如依赖包下载失败、代码编译错误);
- 自动修复:根据根因触发对应修复动作,如重试依赖下载、自动回滚代码版本。
流水线异常修复脚本(Python)
python
# pipeline_remediation.py
import requests
import json
from jenkinsapi.jenkins import Jenkins
# 1. 从Loki获取失败流水线日志
def get_failed_pipeline_logs(pipeline_name, build_number):
loki_url = "http://loki:3100/loki/api/v1/query"
query = f'{{job="jenkins", pipeline="{pipeline_name}", build_number="{build_number}"}}'
params = {"query": query}
response = requests.get(loki_url, params=params)
logs = [entry["line"] for entry in response.json()["data"]["result"][0]["values"]]
return "\n".join(logs)
# 2. 调用AI根因分析(通义灵码API)
def analyze_root_cause(logs):
tongyi_url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
headers = {"Authorization": "Bearer YOUR_API_KEY", "Content-Type": "application/json"}
data = {
"model": "tongyi-coding",
"input": {
"messages": [
{"role": "system", "content": "分析Jenkins流水线失败日志,返回根因和修复命令"},
{"role": "user", "content": logs}
]
}
}
response = requests.post(tongyi_url, headers=headers, json=data)
return response.json()["output"]["choices"][0]["message"]["content"]
# 3. 执行修复动作(Jenkins重启构建)
def fix_pipeline(jenkins_url, username, password, job_name, build_number, fix_command):
jenkins = Jenkins(jenkins_url, username=username, password=password)
job = jenkins[job_name]
# 执行修复命令(如清理工作空间、重试构建)
if "依赖包下载失败" in fix_command:
job.invoke(build_params={"RETRY_DEPENDENCY_DOWNLOAD": "true"})
elif "代码编译错误" in fix_command:
# 自动回滚到上一稳定版本
job.invoke(build_params={"ROLLBACK_TO_LAST_STABLE": "true"})
# 主流程
if __name__ == "__main__":
logs = get_failed_pipeline_logs("backend-service", "123")
root_cause = analyze_root_cause(logs)
print(f"根因分析结果:{root_cause}")
fix_pipeline("http://jenkins:8080", "admin", "admin123", "backend-service", "123", root_cause)
5. 智能运维落地指南与避坑手册
5.1 分阶段落地路径
阶段 1:试点验证(1-3 个月)
- 选择非核心业务(如测试环境),部署基础数据采集工具;
- 聚焦 1-2 个高频故障场景(如节点扩容、依赖下载失败);
- 核心目标:验证模型准确率(≥85%)与自动化修复成功率(≥70%)。
阶段 2:扩展覆盖(4-6 个月)
- 接入核心业务系统,完善数据采集覆盖(指标 + 日志 + 调用链);
- 扩充自愈策略库至 50+,覆盖 80% 常见故障;
- 核心目标:MTTR(平均修复时间)缩短 50%,人工干预减少 60%。
阶段 3:优化迭代(7-12 个月)
- 构建多模态大模型,支持自然语言交互式运维;
- 实现模型在线学习,自动适配业务变化;
- 核心目标:全链路自愈率≥90%,运维成本降低 40%。
5.2 高频避坑指南
| 坑点类型 | 典型问题 | 解决方案 |
|---|---|---|
| 数据质量问题 | 传感器数据缺失 / 跳变,导致模型误报率高 | 实施 “3σ 原则 + 业务逻辑校验” 双重过滤,采用滑动窗口均值补全缺失值 |
| 模型可解释性差 | 运维人员不信任 AI 决策,拒绝使用自动化功能 | 采用 SHAP 值解释模型决策,输出可视化根因分析报告 |
| 安全风险 | 自动化操作误删数据 / 误扩容,造成业务损失 | 设计沙箱预执行、操作审计、30 秒超时中断机制,严格 RBAC 权限控制 |
| 工具链兼容性 | 不同厂商工具数据格式不统一,集成困难 | 采用标准化数据管道,统一时间戳、指标命名规范 |
6. 总结与互动
6.1 核心知识点回顾
- 技术架构:掌握 “数据采集 - 智能分析 - 决策执行 - 持续学习” 四层架构,是搭建 AI 运维体系的基础;
- 工具选型:中小团队优先开源组合(Prometheus+Loki+Ansible),中大型团队可选择企业级平台(腾讯云智能顾问);
- 实战关键:数据质量是模型准确的前提,自愈策略需绑定业务 SLA,分阶段落地降低风险;
- 价值核心:从 “事后救火” 转向 “事前预测 + 自动修复”,最终实现运维成本降低与业务连续性提升。
6.2 核心资源汇总表
| 资源类型 | 链接 / 获取方式 |
|---|---|
| 官方文档 | 腾讯云智能顾问指南 |
| Ansible Lightspeed Docs | |
| 谐云 DevOps 5.0 文档 | |
| GitHub 仓库 | AI 运维模型示例 |
| K8s 自愈 Operator | |
| 模型权重 | CPU 异常预测模型 |
| 工具下载 | Grafana AI 插件 |
6.3 互动环节
投票:你在智能运维落地中遇到的最大挑战是什么?
- 数据采集与标准化
- AI 模型训练与调优
- 自动化修复策略设计
- 工具链集成与兼容性
留言:你所在团队正在使用哪些 AI 运维工具?有哪些实战经验想要分享?
欢迎在评论区留言你的想法,点赞前 5 名可获取 “2025 AI 运维进阶资源包”,包含完整模型训练数据集、企业级策略库模板、避坑脑图,助力快速落地智能运维体系!
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)