AI大模型开发核心技术栈:2025年开发者必备指南
文章系统介绍了2025年AI大模型开发核心技术栈,包括基础框架(PyTorch、TensorFlow等)、训练微调(分布式训练、PEFT)、推理优化(FlashAttention、PagedAttention)及AI编程工具。技术呈现分层化、模块化和民主化趋势,降低AI开发门槛,赋予更多人创造智能的能力,帮助开发者将创意转化为现实,是AI开发者必备的"军火库"。
文章系统介绍了2025年AI大模型开发核心技术栈,包括基础框架(PyTorch、TensorFlow等)、训练微调(分布式训练、PEFT)、推理优化(FlashAttention、PagedAttention)及AI编程工具。技术呈现分层化、模块化和民主化趋势,降低AI开发门槛,赋予更多人创造智能的能力,帮助开发者将创意转化为现实,是AI开发者必备的"军火库"。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
构建未来智能的“开发者军火库”
在AI大模型技术浪潮席卷全球的背景下,开发者作为这场技术革命的核心推动力量,其手中的“军火库”——即AI大模型开发的核心技术栈——的演进与迭代,直接决定了创新的速度、应用的深度和生态的广度。2025年,AI开发技术栈经历了从“手工作坊”式的探索到“工业化”生产体系的深刻变革。这一体系,上承模型算法的创新,下接千行百业的应用落地,是连接理论与实践、驱动AI价值释放的关键枢纽。
本文将为开发者和AI从业者提供一份详尽的、面向2025年的AI大模型开发核心技术栈图谱。我们将系统性地梳理和解析构成这一技术栈的四大核心支柱:
基础开发框架:从深度学习的基石PyTorch、TensorFlow和JAX,到引爆应用层创新的AI Agent框架(如LangGraph, AutoGen),我们将剖析其技术演进和选型考量。
模型训练与微调技术:我们将深入探讨分布式训练的并行策略、参数高效微调(PEFT)的革命(特别是LoRA与QLoRA),为开发者在不同资源和场景下选择最优训练方案提供指南。
推理优化与部署技术:我们将揭示以vLLM和TensorRT-LLM为代表的高性能推理框架如何通过PagedAttention等技术实现吞吐量的飞跃,并系统介绍模型量化、算子融合等核心优化手段。
AI编程辅助工具:从GitHub Copilot到国产的通义灵码,我们将评测这些“AI结对程序员”如何重塑开发流程,提升代码生产力。
本文旨在通过对上述核心技术栈的全面解析,为开发者提供一个清晰的导航图,帮助他们理解各种工具的内在逻辑、适用场景与最佳实践,从而在构建下一代AI应用的征程中,能够“选对兵器,打赢战争”。
一、基础开发框架:奠定AI创新的基石
基础开发框架是AI技术栈的“操作系统”,它为上层算法的实现、模型的训练和应用的部署提供了底层的计算抽象和工具集。2025年,AI开发框架的版图呈现出清晰的“双层结构”:下层是以PyTorch、TensorFlow和JAX为代表的“深度学习基础框架”,它们是构建和训练神经网络的核心引擎;上层则是以LangChain、CrewAI、AutoGen等为代表的“AI Agent开发框架”,它们专注于编排和调度大模型的能力,是引爆应用层创新的催化剂。理解这两层框架的特点与分工,是开发者构建现代AI应用的第一步。
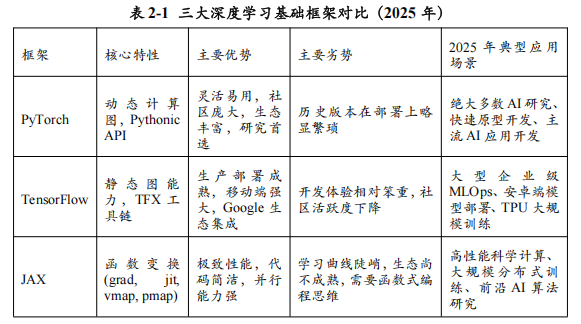
1.1 深度学习基础框架:三足鼎立,PyTorch王者地位稳固
深度学习基础框架是AI开发者的“主战武器”,它们直接决定了研究和开发的效率、灵活性与性能。经过多年的激烈竞争,2025年的市场格局已然清晰:PyTorch凭借其灵活性和强大的社区生态,在学术界和工业界都占据了绝对的主导地位;TensorFlow凭借其在生产部署和移动端上的优势,仍在特定领域保有一席之地;而JAX则以其高性能和独特的函数式编程范式,在顶尖研究和大规模计算领域异军突起,成为不可忽视的新生力量。
PyTorch:当之无愧的王者
由Meta AI研究院主导开发的PyTorch,在2025年已经成为绝大多数AI研究者和开发者的首选框架。根据Papers With Code等学术平台的统计数据,2024年至2025年间新发表的AI论文中,使用PyTorch实现的比例已经约70-80%,形成了事实上的“学术垄断”。其成功主要归功于以下几点:
动态计算图(Dynamic Computational Graph):这是PyTorch最核心的特性,也被称为“Define-by-Run”。计算图在代码实际运行时才被构建,这意味着开发者可以使用标准的Python控制流(如if语句、for循环)和调试工具(如pdb)来构建和调试模型。这种所见即所得的编程体验极大地降低了学习门槛,提高了开发和实验的效率。
简洁直观的API设计:PyTorch的API设计遵循“Pythonic”的哲学,与NumPy的接口高度相似,使得熟悉Python数据科学生态的开发者可以快速上手。其模块化的设计(如nn.Module, torch.optim)使得构建、训练和评估模型的过程非常自然和清晰。
强大的社区与生态系统:PyTorch拥有全球最活跃、最庞大的AI开发者社区。这不仅意味着海量的开源项目、预训练模型和第三方库(如Hugging Face Transformers, PyTorch Lightning, fast.ai),也意味着开发者在遇到问题时可以快速找到解决方案。Hugging Face生态与PyTorch的深度绑定,更是极大地推动了其在NLP领域的普及。
无缝的生产部署过渡:通过TorchScript(将动态图模型转换为静态图)和TorchServe(官方模型服务库),PyTorch弥补了早期在生产部署上的短板。特别是PyTorch 2.0版本后引入的torch.compile()功能,通过与Triton等先进编译器的集成,实现了“一次编写,处处加速”,在保持开发灵活性的同时,获得了接近静态图的推理性能,打通了从研究到生产的“最后一公里”。
TensorFlow:坚守工业界,专注生产部署
由Google开发的TensorFlow是历史上第一个被广泛采用的深度学习框架。尽管在灵活性和社区活跃度上逐渐被PyTorch超越,但凭借其在工业级生产部署和Google强大生态系统中的深厚根基,TensorFlow在2025年依然是许多大型企业和特定场景下的重要选择。
静态计算图(Static Computational Graph):TensorFlow 1.x时代的核心特性是“Define-and-Run”,即先定义完整的计算图,再执行。这种模式虽然开发和调试较为繁琐,但非常有利于进行图优化、跨平台部署和分布式训练。尽管TensorFlow 2.x引入了Eager Execution(类似于PyTorch的动态图模式)作为默认模式,但其骨子里仍然保留了强大的静态图能力,这使其在追求极致性能和稳定性的生产环境中备受青睐。
完善的部署工具链(TensorFlow Extended - TFX):Google为TensorFlow打造了一套名为TFX的端到端机器学习平台,覆盖了从数据准备、模型训练、验证、部署到监控的全生命周期。其中的TensorFlow Serving在处理大规模、高并发的推理请求方面表现出色,而TensorFlow Lite则是在移动和嵌入式设备上部署AI模型的行业标准。这种“全家桶”式的解决方案对于需要标准化、可扩展和可维护的MLOps流程的大型企业具有很强的吸引力。
Google生态深度集成:作为Google的“亲儿子”,TensorFlow与Google Cloud Platform (GCP)、TPU硬件以及安卓生态系统深度集成,能够为使用这些平台和设备的开发者提供最优的性能和最便捷的开发体验。
JAX:高性能计算的**“核武器”**
同样由Google开发的JAX,是一个相对较新的框架,但它凭借其独特的设计理念和惊人的性能,在高性能计算(HPC)和前沿AI研究领域迅速崛起,被认为是PyTorch和TensorFlow未来最强有力的挑战者。
JAX的核心并非一个传统的深度学习框架,而是一个专注于高性能数值计算和大规模机器学习的Python库。其核心竞争力源于几个关键的函数变换:
grad:自动微分,JAX提供了强大且灵活的自动微分功能,可以对任意复杂的Python函数(包括循环、分支、递归)进行求导,支持高阶导数和复杂的梯度操作。
jit:即时编译,通过@jax.jit装饰器,JAX可以将Python函数编译成针对CPU、GPU或TPU优化的XLA(Accelerated Linear Algebra)代码,从而消除Python解释器的开销,获得接近原生代码的运行速度。
vmap:自动向量化,vmap可以自动地将一个处理单个数据点的函数,转换为能够并行处理一批(a batch of)数据的函数,而无需开发者手动修改函数来处理额外的批处理维度。这使得编写可批处理的代码变得异常简单和优雅。
pmap:自动并行化,pmap则可以将计算自动地并行到多个设备上(如多个GPU或TPU核心),是实现数据并行的利器。
JAX的函数式编程范式(函数无副作用)和这些强大的函数变换组合在一起,使得研究者可以用非常简洁和优雅的代码,实现极其复杂的、高性能的分布式训练。DeepMind等顶级研究机构已经将JAX作为其主要的内部研究框架,许多需要超大规模计算的前沿模型(如大规模Transformer、科学计算模型)都优先选择使用JAX实现。然而,JAX相对陡峭的学习曲线和尚在发展中的生态系统,也使其在普通开发者中的普及率暂时不及PyTorch。
对于中国的开发者而言,PyTorch无疑是当前进入AI领域的最佳选择,其丰富的中文教程和活跃的国内社区(如PyTorch中文网)也为学习提供了便利。同时,随着国产AI芯片生态的成熟,TensorFlow和PyTorch都在积极适配华为昇腾、寒武纪等国产硬件,而JAX的函数式和可编译特性也使其在适配新型AI硬件时具有独特的优势。
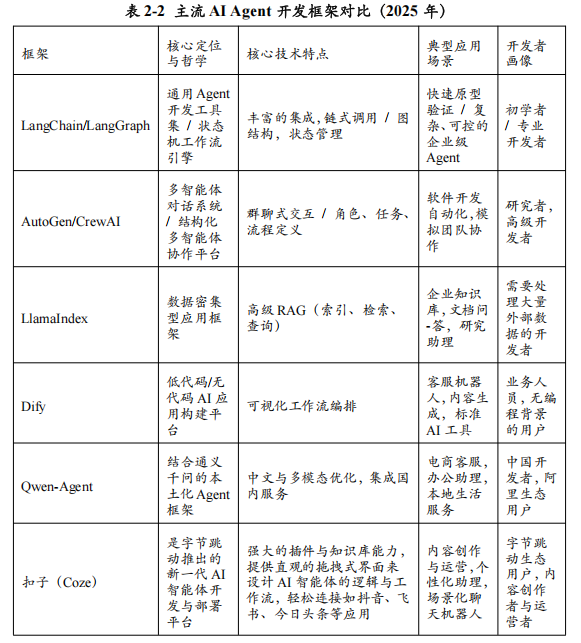
1.2 AI Agent开发框架:引爆应用创新的“编排层”
如果说深度学习基础框架是制造AI“大脑”即大模型本身的工厂,那么AI Agent开发框架就是为这个“大脑”安装“神经系统”和“四肢”的装配车间。它们不关心模型底层的数学原理,而是专注于一个更高层次的问题:如何有效地编排和调度大模型已经具备的各种能力(如语言理解、推理、代码生成),并将其与外部工具和数据源连接起来,以完成复杂、多步骤的任务。 2025年,Agent框架已经从早期LangChain“一家独大”的探索阶段,演变为一个百花齐放、更加成熟和细分的生态系统。这些框架共同构成了AI技术栈中至关重要的“编排层”(Orchestration Layer),是推动AI从“聊天机器人”走向“数字员工”的核心引擎。
演进趋势:从**“链式”调用到“图”与“多智能体”**协作
早期(2023-2024年)的Agent框架,以LangChain为代表,其核心思想是“链”(Chain)——将对大模型的多次调用与工具的使用像链条一样串联起来。例如,一个典型的ReAct(Reason+Act)流程就是“思考 -> 行动 -> 观察 -> 思考…”的线性循环。这种模式对于解决简单问题非常有效,但随着任务复杂度的提升,其局限性也日益凸显:
缺乏状态管理:线性链条难以维护复杂的上下文状态和记忆。
控制流僵化:难以实现复杂的条件分支、循环和并发。
可调试性差:一旦链条出错,很难定位到具体是哪个环节出了问题。
为了克服这些挑战,2025年的主流Agent框架不约而同地向两个方向演进:图(Graph)结构和多智能体(Multi-Agent)协作。
图结构:用“图”来代替“链”,将Agent的工作流建模为一个有向无环图(DAG)或状态机。图中的每个节点代表一个计算步骤(如调用大模型、执行工具、检索数据),而边则代表了节点之间的依赖关系和控制流。这种模式允许开发者构建任意复杂的、具有循环、分支和并发能力的Agent工作流,并提供了更好的可视化、调试和状态管理能力。LangChain的后续演进产品LangGraph就是这一趋势的典型代表。
多智能体协作:借鉴人类社会的分工协作模式,将一个复杂的任务分解给多个具有不同角色和专长的Agent来共同完成。例如,一个“软件开发项目”可以由“产品经理Agent”、“程序员Agent”和“测试工程师Agent”组成的团队来协作。这种模式不仅提升了解决复杂问题的能力,也使得Agent系统的行为更加可解释和可控。微软的AutoGen和CrewAI是这一方向的引领者。
主流Agent框架全景解析(2025年)
2025年,开发者面临着丰富的Agent框架选择,它们在设计哲学、核心能力和适用场景上各有侧重。
- LangChain & LangGraph:从“瑞士军刀”到“手术刀”
LangChain:作为最早普及的Agent框架,LangChain以其全面的功能和丰富的组件被称为“AI开发的瑞士军刀”。它提供了与数百种大模型、工具和数据源的集成,并封装了从Prompt模板、记忆管理到链式调用的各种标准组件。对于初学者和快速原型验证而言,LangChain依然是快速上手的首选。但其高度的封装和复杂的继承体系也使其在定制化和生产部署时显得较为笨重。
LangGraph:为了解决LangChain在复杂流程控制上的不足,其团队推出了LangGraph。LangGraph完全拥抱了“图”的思想,让开发者可以用显式的状态机来定义Agent的行为。这使得构建需要长期运行、具备自我修正能力、并且行为可追溯的复杂Agent成为可能。例如,一个需要与用户进行多轮交互、并根据反馈不断修改方案的旅行规划Agent,就非常适合用LangGraph来构建。LangGraph标志着LangChain生态从一个通用的工具集,向一个更专注于生产级、可控Agent工作流的“手术刀”式解决方案的演进。
- AutoGen & CrewAI:多智能体协作的双雄
AutoGen:由微软研究院推出的AutoGen,其核心是“可对话的”多智能体系统。它将Agent之间的交互建模为一场群聊。开发者可以定义多个具有不同系统提示(System Prompt)和工具集的Agent,并将它们放入一个“聊天室”中。当一个任务被提出后,一个“管理员Agent”会根据任务进展,自动选择下一个应该“发言”的Agent。这种模式非常适合模拟人类团队的工作流程,特别是在软件开发等需要多个角色(如产品经理、程序员、代码审查员)来回沟通的场景中表现出色。
CrewAI:CrewAI在多智能体协作的理念上与AutoGen类似,但提供了更高级、更结构化的协作模式。它明确引入了“角色”(Role)、“任务”(Task)和“流程”(Process)的概念。开发者可以为每个Agent清晰地定义其角色、目标和可使用的工具。CrewAI还内置了精细的流程控制机制(如顺序流程、层级流程),可以编排Agent的协作顺序。相比AutoGen的“自由聊天”,CrewAI更像是为Agent团队设定了一套严谨的“Scrum敏捷开发流程”,使其协作更高效、结果更可控。
- LlamaIndex:专注RAG,数据为王
与上述框架不同,LlamaIndex从创立之初就专注于一个核心问题:如何将大模型与私有数据或外部数据进行高效、可靠的连接,即检索增强生成(RAG)。它提供了一整套围绕RAG的、从数据摄取、索引构建、到高级检索策略的全生命周期工具。当其他框架还在将RAG作为Agent的一个“工具”时,LlamaIndex已经将RAG本身做成了一门“科学”。其核心优势在于:
高级数据索引:支持从简单的向量索引,到更复杂的树状索引、关键词索引、知识图谱索引等多种结构化索引,以适应不同的数据类型和查询需求。
高级检索策略:提供了从简单的Top-k检索,到更复杂的融合检索(Hybrid Search)、查询转换(Query Transformations)、后处理(Post-processing)等一系列高级策略,以提升检索结果的准确性和相关性。
查询引擎与Agent集成:LlamaIndex的查询引擎可以轻松地作为一个强大的工具,被集成到LangChain或CrewAI等其他Agent框架中,专门负责“数据检索和问答”这一环节。
对于任何需要构建企业知识库、文档问答、客户支持等数据密集型AI应用而言,LlamaIndex都是不可或缺的核心组件。
- Dify & PromptAppGPT:低代码/无代码的民主化浪潮
为了让非程序员也能参与到AI应用的创造中,一系列低代码/无代码平台应运而生,其中Dify和PromptAppGPT是杰出代表。
Dify:它提供了一个可视化的拖拽式界面,用户可以通过连接不同的节点(如“开始”、“大模型”、“知识库”、“代码执行”)来设计一个AI应用的工作流。Dify内置了完整的后端服务和运营管理功能,支持一键发布成可独立使用的Web应用。它极大地降低了构建标准AI应用(如客服机器人、内容生成工具)的技术门槛,特别适合企业内部的业务人员快速搭建满足其特定需求的AI工具。
PromptAppGPT:这是一个更加轻量级的、以Prompt为中心的快速开发框架。其核心思想是“用自然语言来编程”,开发者只需在一个YAML文件中,用结构化的提示语来描述Agent的目标、工具和工作流程,框架就能自动将其编译成一个可运行的Web应用。这种模式极大地提升了从想法到原型的开发速度。
中国本土框架的崛起:以Qwen-Agent为例
除了上述国际主流框架,中国的AI厂商也在积极布局Agent框架生态。阿里巴巴推出的Qwen-Agent就是一个典型。它与通义千问大模型深度集成,充分利用了Qwen系列在中文处理和多模态能力上的优势。同时,Qwen-Agent针对国内开发者常用的工具和服务(如钉钉、高德地图、阿里云服务)进行了预集成,为构建符合中国市场需求的Agent应用提供了便利。
还有来自字节跳动的扣子(Coze)商业化闭源平台则更为广泛的被使用,随后在2025年7月份进行了基础平台功能的开源。该平台与旗下豆包大模型深度打通,充分发挥了其在对话交互与场景化适配方面的技术积累。同时,Coze针对国内用户高频使用的平台和服务(如抖音、飞书、今日头条等)进行了原生适配,并提供丰富的插件生态,大大降低了构建符合中国市场使用习惯的AI智能体应用的门槛。
总而言之,2025年的AI Agent开发框架生态已经高度繁荣和分化。开发者在进行技术选型时,应从任务的复杂度、对流程控制的要求、是否涉及多智能体协作、以及对外部数据的依赖程度等多个维度进行综合考量。对于大多数开发者而言,通常需要组合使用这些框架——例如,使用CrewAI来定义多智能体协作流程,其中每个Agent内部使用LangGraph来管理其自身的状态,并调用LlamaIndex作为其强大的数据检索工具。掌握这些框架的组合与应用,是现代AI应用开发者的核心竞争力所在。
二、模型训练与微调技术:释放AI潜能的艺术
如果说基础框架是AI开发的“骨架”,那么模型训练与微调技术就是赋予其“血肉与灵魂”的工艺。正是这些技术,将海量的无结构数据转化为蕴含知识和智能的庞大参数网络,并使其能够适应千变万化的下游任务。2025年,随着模型规模迈入万亿参数时代,传统的训练方法已难以为继。为了应对“算力墙”、“内存墙”和“成本墙”带来的巨大挑战,一系列创新的训练与微调技术应运而生并迅速普及。分布式训练技术的发展使得训练万亿模型成为可能;参数高效微调(PEFT)技术则极大地降低了模型定制化的门槛;而混合精度与低比特训练技术,则在性能与成本之间取得了精妙的平衡。掌握这些技术,是AI开发者驾驭大模型、释放其全部潜能的关键所在。
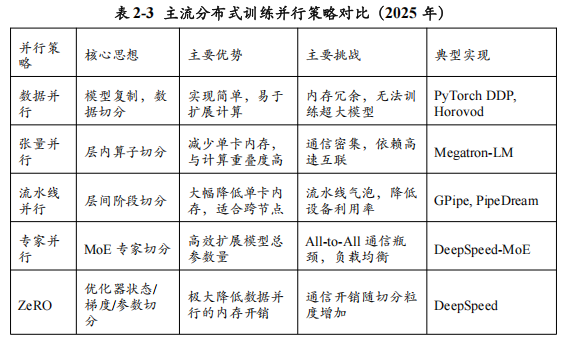
2.1 分布式训练:驾驭万亿参数模型的“合力之术”
训练一个万亿参数级别的大模型,其计算量和内存需求是任何单一计算设备(即便是最强大的GPU)都无法承受的。因此,分布式训练——即利用成百上千个GPU组成的计算集群来协同完成训练任务——成为了前沿大模型开发的唯一可行路径。这门被誉为“合力之术”的技术,其核心在于如何将庞大的模型和海量的数据巧妙地“切分”并分配到集群的各个计算节点上,同时最大限度地减少节点间通信所带来的开销。2025年,以数据并行、张量并行、流水线并行和专家并行(作为模型并行的一种高级形式)为核心的“3D+1D”混合并行策略,已成为业界训练超大规模模型的标准范式。
数据并行(Data Parallelism):最简单直接的扩展方式
数据并行是最基础、最易于理解的并行策略。其核心思想是“模型复制,数据切分”:
工作原理:将完整的模型复制到集群中的每一个GPU上。然后,将一个大的训练数据集(Batch)切分成多个小的子批次(Micro-batch),每个GPU独立地使用自己的子批次数据进行前向和后向计算,得到各自的梯度(Gradients)。最后,通过一个All-Reduce通信操作,将所有GPU上的梯度进行聚合(通常是求平均),并用聚合后的梯度来更新每个GPU上的模型副本,从而保证所有副本的参数保持同步。
优势:实现简单,几乎所有主流训练框架(如PyTorch的DistributedDataParallel, DDP)都提供了开箱即用的支持。在GPU显存足以容纳整个模型的前提下,它能够非常有效地扩展计算能力,加速训练过程。
劣势:内存冗余。每个GPU都需要存储一份完整的模型参数、梯度和优化器状态,这使得其内存开销巨大。当模型大到单个GPU无法容纳时,单纯的数据并行便无能为力。
张量并行(Tensor Parallelism):在矩阵乘法层面“劈开”模型
当模型巨大到单个GPU的显存无法容纳时,就需要将模型本身进行切分,张量并行就是其中一种“模型并行”(Model Parallelism)的策略。它作用于模型内部的单个算子(Operator),特别是Transformer模型中计算量最大的矩阵乘法(MatMul)。
工作原理:以一个Y = XA的矩阵乘法为例,可以将权重矩阵A按列切分成[A1, A2],分别放到两个GPU上。输入X被复制到两个GPU上,各自计算Y1 = XA1和Y2 = XA2。最后,通过一个All-Gather通信操作将Y1和Y2拼接成最终的结果Y = [Y1, Y2]。对于Transformer中的多头注意力机制(Multi-Head Attention),也可以将不同的“头”分配到不同的GPU上并行计算。NVIDIA开发的Megatron-LM框架是张量并行的经典实现。
优势:能够有效减少单个GPU上的内存占用,使得训练更大的模型成为可能。它将通信开销巧妙地隐藏在计算过程中。
劣势:通信开销巨大。由于在模型的前向和后向传播过程中都需要进行All-Reduce或All-Gather操作,张量并行对GPU之间的互联带宽要求极高,通常只适用于节点内(Intra-node)具有高速互联(如NVLink)的多个GPU之间,不适合跨网络节点使用。
流水线并行(Pipeline Parallelism):像工厂流水线一样组织模型层
流水线并行是另一种重要的模型并行策略,它将模型的不同层(Layers)分配到不同的GPU上,形成一条“计算流水线”。
工作原理:将一个大模型(如一个60层的Transformer)按顺序切分成多个阶段(Stages),例如,将1-15层放在GPU 0上(Stage 1),16-30层放在GPU 1上(Stage 2),以此类推。一个训练批次的数据被进一步切分成多个微批次(Micro-batches)。第一个微批次在Stage 1完成计算后,其输出被发送到Stage 2,同时Stage 1开始处理第二个微批次。通过这种方式,所有Stage可以像工厂流水线一样并行工作。
优势:极大地降低了单个GPU的内存占用,因为每个GPU只需存储模型的一部分层。其通信开销相对较低,只发生在相邻的Stage之间,因此非常适合跨网络节点(Inter-node)扩展。
劣势:存在“流水线气泡”(Pipeline Bubble)问题。在流水线的启动和排空阶段,部分GPU会处于空闲等待状态,造成计算资源的浪费。为了减小气泡,需要使用大量的微批次,但这又可能影响模型的收敛性。GPipe、PipeDream和PyTorch的PipelineParallel模块是其典型实现。
专家并行(Expert Parallelism):为MoE架构量身定制
随着混合专家(MoE)架构在2025年的普及,一种专门为其设计的、更高级的模型并行策略——专家并行——应运而生。
工作原理:在MoE模型中,巨大的参数量主要来自于大量的“专家”网络。专家并行的核心思想,就是将这些专家分布到集群中的不同GPU上。当一个Token需要由某个专家处理时,它会被通过网络路由到存储该专家的GPU上进行计算,计算完成后再将结果返回。这本质上是一种更动态、更稀疏的模型并行。
优势:能够以极高的效率扩展模型的总参数量,是训练万亿级MoE模型的关键技术。
劣势:对网络的All-to-All通信能力提出了极致的要求,因为每个Token都可能需要与集群中的任何一个专家进行通信。同时,动态的路由和负载均衡问题也为训练带来了新的复杂性。
混合并行:集大成者的**“3D+1D”**策略
在实践中,单一的并行策略往往无法满足训练超大规模模型的需求。因此,2025年的业界标准做法是采用“混合并行”策略,将上述多种并行方式组合起来,取长补短。一个典型的尖端训练系统(如微软的DeepSpeed或NVIDIA的Megatron-LM)通常采用如下的“3D+1D”混合策略:
节点内(Intra-node)采用张量并行:在一个服务器节点内部的8个GPU之间,利用高速的NVLink互联,进行张量并行,共同承载一个巨大的模型层。
节点间(Inter-node)采用流水线并行:在多个服务器节点之间,利用相对较慢的网络(如InfiniBand),进行流水线并行,将模型的不同阶段分布在不同节点上。
全局采用数据并行:在上述并行设置的基础上,将整个混合并行单元(例如,一个由32个GPU组成的、能够承载一个完整模型的单元)复制多份,进行数据并行,以进一步扩展计算规模。
在MoE模型中,额外叠加专家并行:将MoE层中的专家分布到全局所有的数据并行副本上。
此外,以ZeRO(Zero Redundancy Optimizer)为代表的内存优化技术,作为数据并行的“威力加强版”,也得到了广泛应用。ZeRO不仅切分数据,还巧妙地将模型参数、梯度和优化器状态这三部分巨大的内存开销,也切分并分布到数据并行的所有GPU上,从而使得每个GPU的内存负担都大幅降低。ZeRO-3阶段甚至可以做到让每个GPU上不存储完整的模型参数,实现了数据并行与模型并行某种程度上的统一。
对于开发者而言,虽然直接从零实现这些复杂的并行策略难度极高,但幸运的是,以微软的DeepSpeed和NVIDIA的Megatron-LM为代表的开源框架,已经将这些复杂的并行技术封装成了易于使用的接口。开发者只需在配置文件中进行简单的设置,就可以为自己的模型启用这些强大的混合并行能力。
在国产算力生态方面,寒武纪的分布式通信库(CNCL)针对大规模场景进行了专项优化,新增HDR/DBT等Allreduce通信算法,优先提升大规模条件下的通信带宽,对Alltoall操作进行深度优化,使其大规模扩展性达到与国际主流竞品相当的水平。特别是通过在Kernel支持RoCE网卡的RDMA操作(类IBGDA),显著优化了大规模专家并行场景下的ALL2ALL通信延迟,提升了MoE类模型推理任务的端到端吞吐。这些优化使得国产算力在支撑万卡级大模型训练时具备了与国际先进水平相当的通信性能。
掌握如何使用这些框架,并根据自己的硬件环境和模型特点来选择和组合最合适的并行策略,是每一位致力于大模型训练的AI工程师的必备技能。
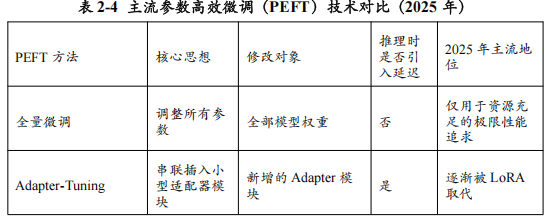
2.2 参数高效微调(PEFT):让大模型“飞入寻常百姓家”的革命
如果说分布式训练是少数巨头才能参与的“登月计划”,那么参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术,就是一场将大模型能力“民主化”、使其“飞入寻常百姓家”的深刻革命。在PEFT出现之前,让一个巨大的预训练模型去适应一个特定的下游任务,通常采用“全量微调”(Full Fine-tuning)的方式,即调整模型中所有的参数。这种方式不仅成本高昂(需要大量的GPU资源和时间),存储开销巨大(每个任务都需要存储一个完整的模型副本),还常常面临“灾难性遗忘”(Catastrophic Forgetting)的风险——模型在学习新任务的同时,可能会忘记在预训练阶段学到的通用知识。
PEFT的出现彻底改变了这一局面。其核心思想是:在微调过程中,冻结绝大部分预训练模型的参数(这些参数蕴含了宝贵的通用世界知识),只引入或修改一小部分(通常<1%)的额外参数来适应新任务。 这种“四两拨千斤”的策略,带来了革命性的优势:
极低的计算成本:由于可训练的参数量急剧减少,微调所需的计算资源和时间大幅降低,使得在单张消费级GPU上微调百亿级大模型成为可能。
极低的存储成本:对于每个下游任务,只需存储和分发那一小部分被修改的参数(通常只有几十兆字节),而非整个数十GB的模型副本。
避免灾难性遗忘:由于99%以上的原始模型参数被冻结,模型能够很好地保持其强大的泛化能力。
性能媲美全量微调:大量研究和实践证明,在许多任务上,精心设计的PEFT方法可以取得与全量微调相当甚至更好的性能。
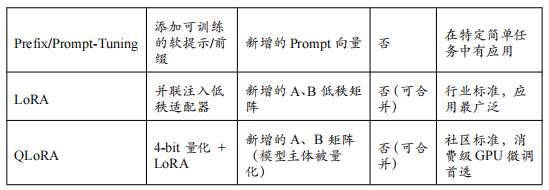
2025年,PEFT已经成为大模型定制化的主流范式。在众多PEFT方法中,以LoRA(Low-Rank Adaptation)及其变体QLoRA最为耀眼,它们凭借其出色的效果和普适性,成为了事实上的行业标准。
LoRA:在模型权重中注入“低秩之魂”
由微软研究员提出的LoRA,其背后有一个深刻的洞察:大型语言模型虽然参数维度极高,但它们在适应下游任务时,其权重的变化矩阵(即“微调后的权重”减去“原始权重”)本质上是“低秩”(Low-Rank)的。 这意味着这个巨大的变化矩阵,可以用两个小得多的矩阵相乘来近似表示。
基于此,LoRA的实现方式堪称优雅而高效:
冻结原始权重:在微调时,原始的预训练权重矩阵W(例如,Transformer中Attention层的查询Q或键K的权重矩阵)保持不变。
注入低秩适配器:在W旁边,并联一个“低秩适配器”(Low-Rank Adapter)。这个适配器由两个小矩阵A和B组成。A是一个随机初始化的高瘦矩阵,B是一个零初始化的矮胖矩阵。它们的秩(Rank, r)远小于原始权重的维度。
只训练适配器:在微调过程中,只训练矩阵A和B的参数,W始终被冻结。模型的总前向传播变为 h = Wx + BAx。
无缝合并部署:在推理部署时,可以将训练好的BA矩阵与原始的W矩阵直接相加,得到一个新的权重矩阵W’ = W + BA。这意味着LoRA在推理时不会引入任何额外的计算延迟,这是其相比其他PEFT方法(如Adapter-Tuning)的巨大优势。
LoRA的秩r是一个关键的超参数,它控制了适配器的容量。r越大,可训练的参数越多,模型的拟合能力越强,但计算和存储开销也相应增加。在实践中,r通常被设置为8、16或64这样的小值,就已经能在大多数任务上取得优异的效果。
QLoRA:将**“平民化”**推向极致
LoRA极大地降低了微调的计算成本,但它仍然需要将完整的模型加载到显存中进行前向和后向传播,对于百亿级模型,这依然需要数十GB的显存,超出了大多数消费级GPU的承受范围。为了解决这个“最后的堡垒”,华盛顿大学的研究者们在LoRA的基础上,结合了激进的量化技术,提出了QLoRA(Quantized LoRA),将大模型微调的“平民化”推向了极致。
QLoRA的核心创新在于“用4-bit的精度来存储和计算冻结的预训练模型,同时用16-bit的精度来训练LoRA适配器”,其关键技术包括:
4-bit NormalFloat (NF4) 量化:这是一种理论上信息最优的新的4-bit数据类型。研究者发现,对于呈正态分布的预训练模型权重,NF4相比传统的4-bit整数或浮点数量化方法,能够更好地保留信息,减少量化误差。
双重量化(Double Quantization):为了进一步节省内存,QLoRA对量化过程本身产生的“量化常数”(Quantization Constants)进行第二次量化,平均每个参数可以再节省约0.5比特的存储空间。
Paged Optimizers:利用NVIDIA统一内存(Unified Memory)的特性,将那些在GPU显存不足时可能导致程序崩溃的优化器状态(Optimizer States)自动地从GPU显存分页到CPU内存中,从而避免了OOM错误。
通过这套组合拳,QLoRA成功地将微调一个650亿参数模型(如LLaMA-65B)所需的显存从惊人的780GB降低到了仅48GB,使得在单张专业级GPU(如A100 80GB)上微调超大模型成为现实。更令人振奋的是,后续的开源社区实践进一步表明,通过QLoRA,在24GB显存的消费级显卡(如RTX 3090/4090)上微调70亿甚至130亿参数的模型也完全可行。
其他PEFT方法概览
除了LoRA家族,PEFT领域还存在其他几种重要的技术路线:
Adapter-Tuning:这是最早的PEFT思想之一。它在Transformer的每个块(Block)中串联地插入一个非常小的、被称为“适配器”(Adapter)的瓶颈状神经网络模块。微调时只训练这些适配器的参数。其缺点是在推理时会引入额外的计算延迟。
Prefix-Tuning & Prompt-Tuning:这类方法不改变模型本身的任何权重,而是在输入层或每一层的注意力机制前,添加一小段可训练的、连续的向量序列(即“软提示”或“前缀”)。通过只优化这些前缀向量,来引导模型的行为以适应下游任务。这种方法对模型的侵入性最小,但表达能力相对有限。
综上所述,以LoRA和QLoRA为代表的PEFT技术,已经成为2025年AI开发者进行模型定制化的必备技能。它们不仅极大地降低了技术和资源门槛,也催生了一个繁荣的开源模型微调社区。对于算泥社区这样的平台而言,提供对LoRA/QLoRA的一站式支持,包括便捷的训练脚本、预优化的环境和丰富的微调模型案例,将是服务广大AI开发者的核心价值所在。通过这些技术,无数中小企业和个人开发者得以站在巨人的肩膀上,用大模型解决自己领域内的具体问题,从而真正开启了AI应用的“寒武纪大爆发”。
三、推理优化与部署技术:从“能用”到“好用”的最后一公里
如果说模型训练是十年磨一剑的“铸剑”过程,那么推理优化与部署就是将这把“神剑”送上战场、使其能够大规模、低成本、高效率地“杀敌”的“出鞘”之术。一个未经优化的百亿参数大模型,其推理过程不仅速度缓慢(生成一个词可能需要数秒),而且对硬件资源(特别是显存)的消耗也极为惊人,这使得其在真实世界的应用中成本高昂、体验不佳。因此,推理优化与部署技术,成为了决定大模型能否从实验室走向千家万户、从“能用”变为“好用”的最后一公里,也是AI应用商业化成败的关键所在。
2025年,大模型推理面临的核心挑战,已从单纯的计算密集(Compute-bound)转变为更棘手的内存带宽密集(Memory-bound)。在自回归(Auto-regressive)的生成过程中,每生成一个Token,都需要将整个庞大的模型权重从显存中完整地读取一遍。相比于GPU强大的计算能力,显存的读写速度成为了严重的瓶颈。此外,如何高效地管理和利用显存,特别是存储每个请求上下文的键值缓存(KV Cache),以及如何在高并发场景下最大化GPU的吞吐量,都是推理优化需要解决的核心难题。
为了应对这些挑战,一个由算法、软件和硬件协同构成的、高度复杂的推理优化技术栈应运而生。本节将深入解析构成这一技术栈的两大核心部分:
关键优化技术:我们将剖析包括FlashAttention、PagedAttention、模型量化(Quantization)、KV缓存优化(MQA/GQA)和投机解码(Speculative Decoding)在内的核心算法与技术,揭示它们如何从根本上缓解内存带宽瓶颈和提升计算效率。
主流推理框架:我们将对以vLLM和TensorRT-LLM为代表的业界顶级推理引擎进行全景式扫描,分析它们如何将上述优化技术工程化、产品化,为开发者提供开箱即用的高性能推理服务。
3.1 关键优化技术:算法与工程的协奏曲
高性能推理的实现,是一场算法与底层硬件工程精妙配合的协奏曲。2025年,一系列关键技术的突破与普及,从根本上改变了大模型推理的效率和成本结构。
FlashAttention:重塑注意力计算,告别内存墙
标准的自注意力机制(Self-Attention)是Transformer模型的核心,但也是其主要的性能瓶颈之一。在计算过程中,它需要生成一个巨大的N x N(N为序列长度)的注意力得分矩阵(Attention Matrix),并将其写入和读出高带宽内存(HBM)。随着序列长度N的增加,这个矩阵的大小呈平方级增长,很快就会耗尽显存带宽,成为瓶颈。
由斯坦福大学研究者提出的FlashAttention,通过一种“IO感知”的算法设计,巧妙地解决了这个问题。其核心思想是避免将完整的注意力矩阵物化(materialize)到HBM中。
工作原理:FlashAttention将输入序列切分成多个小块(Tiles),并加载到GPU核心上速度极快的SRAM中。它在SRAM内部完成一小块注意力矩阵的计算、Softmax操作和与Value矩阵的乘积,然后只将最终的输出写回HBM。通过精巧的在线Softmax技巧,它可以在不看到完整注意力矩阵的情况下,正确地计算出最终结果。这个过程就像“流式处理”一样,极大地减少了对HBM的读写次数。
效果:FlashAttention将注意力计算的复杂度从O(N^2)的内存访问,降低到了O(N)。FlashAttention 2版本进一步优化了并行计算效率,相比标准注意力实现,可以带来数倍的端到端推理加速和显著的内存节省。到2025年,FlashAttention已成为所有主流推理框架的标配。
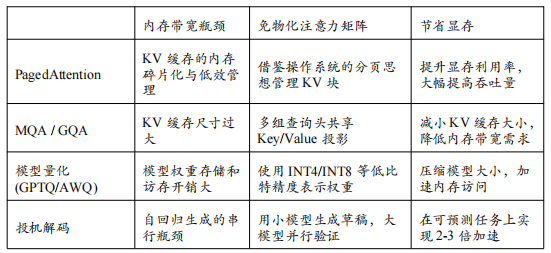
PagedAttention:像操作系统一样管理KV缓存
在多用户、高并发的推理服务中,对KV缓存(KV Cache)的管理是另一个巨大的挑战。每个用户的请求序列长度不同,导致其KV缓存大小也各不相同且动态变化。传统的实现方式是为每个请求预分配一块连续的显存空间来存储其KV缓存,这会导致严重的内存碎片化问题:
内部碎片:为请求预留了过多的空间,造成浪费。
外部碎片:虽然总的空闲显存很多,但没有一块足够大的连续空间来满足新请求,导致请求失败。
由vLLM团队首创的PagedAttention,借鉴了现代操作系统中“虚拟内存”和“分页”的思想,完美地解决了这一难题。
工作原理:PagedAttention将每个请求的KV缓存空间分割成固定大小的“块”(Blocks),这些块在物理显存中可以非连续存储。系统维护一个“块表”(Block Table),为每个请求记录其逻辑块到物理块的映射关系。当需要为序列扩展KV缓存时,只需分配新的物理块并更新块表即可,无需进行昂贵的内存拷贝和重排。更妙的是,对于多个请求之间共享的前缀(例如,多轮对话中的历史记录),PagedAttention可以实现块级别的内存共享,进一步节省显存。
效果:PagedAttention将显存利用率提升了数倍,使得在相同的硬件上,系统的吞吐量(每秒处理的Token数)可以提升2-4倍。这一技术是vLLM等现代推理框架取得极致吞-吐量的核心秘诀。
KV缓存优化:从架构层面**“瘦身”**
除了管理方式的优化,直接从模型架构层面减小KV缓存的大小,是另一种有效的优化路径。标准的多头注意力(Multi-Head Attention, MHA)为每个注意力头都配备了一套独立的Key和Value投影,这导致KV缓存的尺寸与头的数量成正比。
多查询注意力(Multi-Query Attention, MQA):MQA提出,让所有的注意力头共享同一套Key和Value投影。这样做虽然在理论上会损失一定的模型表达能力,但在实践中发现,对于大型模型而言,这种性能损失微乎其微,却可以极大地减小KV缓存的大小和生成每个Token时所需的内存带宽。
分组查询注意力(Grouped-Query Attention, GQA):GQA是MHA和MQA之间的一个折中方案。它将注意力头分成若干组,组内的头共享同一套Key和Value投影。例如,一个有32个头的模型,可以设置8个KV组,每4个查询头共享一套KV。GQA在模型性能和推理效率之间取得了更好的平衡,已成为2025年许多新发布模型(如Llama 2/3)的标配架构。
模型量化:用更少的比特表示更多的知识
模型量化是一种通过降低模型权重和/或激活值的数值精度,来压缩模型大小、减少内存占用和加速计算的技术。2025年,针对大模型的量化技术已经非常成熟,主流的“权重量化”(Weight-Only Quantization)方法可以在几乎不损失模型性能的前提下,将模型大小压缩2-4倍。
GPTQ (Generalized Post-Training Quantization):GPTQ是一种训练后量化方法,它通过逐层分析和量化权重,并对量化误差进行补偿,可以在4-bit精度下保持很好的模型性能。
AWQ (Activation-Aware Weight Quantization):AWQ观察到,并非所有权重对模型性能都同等重要。它通过分析激活值的分布,识别出那些对模型性能影响最大的“显著权重”(Salient Weights),并为它们保留更高的精度,而将其他权重进行更大力度的压缩。这种方法在极低比特(如3-bit甚至更低)的量化上表现出色。
SmoothQuant:这是一种“激活-权重”协同量化方法。它通过一个数学上等价的变换,将量化难度从激活值“平滑”地迁移一部分到权重上,使得两者都更容易被量化,从而在INT8量化等场景下获得更好的性能。
投机解码(Speculative Decoding):让“小模型”为“大模型”开路
投机解码是一种巧妙的加速技术,它利用一个小的、速度极快的“草稿模型”(Draft Model)来辅助大的“目标模型”(Target Model)进行生成。
工作原理:在生成每个Token时,首先用草稿模型快速地生成一小段候选序列(例如5个Tokens)。然后,将这5个候选Tokens一次性地输入到大的目标模型中,进行并行的验证。如果目标模型验证通过(即它自己本来也会生成这些Tokens),那么就一次性地接受这5个Tokens作为最终输出,相当于用一次大模型的计算换来了5个Tokens的生成,极大提升了速度。如果验证失败,则以目标模型的输出为准,并用它来指导草-稿模型的下一次生成。
适用场景:该技术在代码生成、续写等具有一定规律性和可预测性的任务上效果尤其显著,通常可以带来2-3倍的推理加速。Medusa等框架是其典型实现。

3.2 主流推理框架:工业级部署的“集大成者”
如果说上述优化技术是散落在各处的“神兵利器”,那么推理框架就是将它们系统性地整合、封装,并提供给开发者便捷调用接口的“武器库”和“兵工厂”。2025年,大模型推理框架的竞争格局已经高度集中,以vLLM和TensorRT-LLM为代表的开源与商业框架,凭借其卓越的性能和强大的生态,成为了绝大多数开发者和企业的首选。
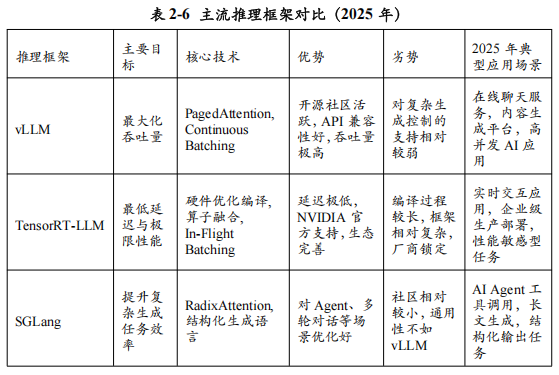
vLLM:为高吞吐量而生的开源王者
由加州大学伯克利分校的研究者们开源的vLLM项目,自诞生之日起就以其惊人的吞吐量表现震惊了整个AI社区。它的核心设计哲学是最大化GPU的利用率,在多用户、高并发的服务场景下,实现极致的吞吐量(Throughput)。
核心武器——PagedAttention:如前所述,PagedAttention是vLLM的“杀手锏”。通过像操作系统一样高效、无碎片地管理KV缓存,vLLM可以在相同的硬件上服务比其他框架多得多的并发请求,从而将总的吞吐量(每秒处理的Token数)提升数倍。
连续批处理(Continuous Batching):传统的批处理(Static Batching)需要等待批次中的所有请求都生成完毕后,才能开始处理下一批。而vLLM采用的连续批处理技术,可以在任何一个请求完成时,立刻将其从批次中移除,并动态地将新的等待请求加入进来。这使得GPU无需空闲等待,始终保持“满负荷”运转,极大地提升了利用率。
生态与易用性:vLLM提供了与OpenAI API兼容的接口,包括对主流大模型的适配,这意味着开发者可以将原来基于OpenAI API开发的应用,几乎无缝地迁移到由vLLM部署的私有化模型上。其简洁的Python API和活跃的社区支持,也使其成为了开源社区中最受欢迎的推理框架。
适用场景:vLLM是构建面向大量用户的在线服务(如聊天机器人、内容生成平台)的理想选择,其高吞吐量的特性可以显著降低单位Token的服务成本。
TensorRT-LLM:NVIDIA官方出品的“性能猛兽”
作为GPU领域的霸主,NVIDIA自然不会缺席推理优化这一关键战场。TensorRT-LLM是NVIDIA官方推出的、专门用于加速大模型在NVIDIA GPU上推理的开源库。它与vLLM的设计哲学略有不同,虽然也追求高吞吐量,但它更加关注在严苛延迟(Latency)要求下的极限性能,特别是单批次(Single-batch)或小批次(Small-batch)场景下的响应速度。
核心武器——深度硬件优化:TensorRT-LLM的本质是一个编译器。它将一个用PyTorch或TensorFlow定义的模型,编译成一个高度优化的TensorRT引擎。在这个过程中,它会进行一系列与硬件深度绑定的优化,包括:
算子融合(Operator Fusion):将多个独立的计算核(Kernel)融合成一个更大的核,减少Kernel启动开销和对HBM的读写。
自动精度选择:根据硬件支持和性能测试,为模型的不同部分自动选择最优的数值精度(FP16, INT8, FP8)。
硬件感知Kernel:使用NVIDIA工程师手写的、针对特定GPU架构(如Hopper, Ampere)高度优化的CUTLASS库中的计算Kernel。
In-Flight Batching:这是TensorRT-LLM对标vLLM连续批处理的实现,同样可以在请求级别动态地进行批处理,提升GPU利用率。
适用场景:对于需要极低响应延迟的企业级应用(如实时翻译、代码补全、金融风控),或者需要将模型性能压榨到极致的场景,TensorRT-LLM是当仁不让的选择。它与NVIDIA的Triton Inference Server和NIM(NVIDIA Inference Microservice)微服务生态深度集成,为企业提供了从模型优化到生产部署的端到端解决方案。
其他值得关注的框架
SGLang:这是一个专注于提升复杂生成任务(如长文生成、多轮对话、Agent工具调用)效率的框架。它提出了一种名为RadixAttention的创新技术,可以更高效地管理和共享不同请求之间高度重叠的KV缓存,在这些特定场景下可以取得比vLLM更高的吞吐量。
DeepSpeed-Inference:作为DeepSpeed训练框架的自然延伸,DeepSpeed-Inference提供了针对大规模模型(特别是稀疏MoE模型)的推理优化,支持张量并行等分布式推理技术。
在国产硬件适配方面,寒武纪也在持续优化vLLM推理引擎,完善混合精度低比特量化推理机制,支持W4A4以及MX-FP8/MX-FP4等新型数据类型,探索并支持Sparse Attention与Linear Attention等多种高效注意力机制。同时,寒武纪紧跟先进模型演进,支持Qwen-Omni等多模态融合模型、Hunyuan3D等3D生成模型、CosyVoice等语音生成模型,确保技术栈的先进性与完备性。通过持续开展对DeepSeek、Qwen、Hunyuan等系列最新开源模型的极致性能优化,并专项攻坚长序列与超低解码延时等场景,寒武纪在国产算力上实现了与主流GPU相当的推理性能。
对于开发者而言,选择哪个推理框架取决于其具体的应用场景和性能目标。一个常见的模式是:在开发和实验阶段,使用vLLM快速部署和迭代,享受其易用性和高吞吐量带来的成本效益;在产品正式上线、对延迟和稳定性有极致要求的生产环境中,则投入资源使用TensorRT-LLM进行深度优化和编译,以获得最佳性能。而算泥社区这样的平台,通过提供对这些主流推理框架的预集成和一键部署功能,可以帮助开发者屏蔽底层的复杂性,根据业务需求灵活选择和切换最优的推理方案,从而加速AI应用的落地进程。
四、AI编程辅助工具:开发流程的“智能副驾”
在AI重塑千行百业的同时,软件开发这一古老而核心的行业自身,也正在被AI以前所未有的深度进行着重构。AI编程辅助工具,常被开发者亲切地称为“AI结对程序员”或“智能副驾”,已经从早期的“高级自动补全”进化为深度融入开发全流程的、不可或缺的生产力伙伴。它们不仅能够在你编写代码时实时提供精准的建议、补全整段的函数,还能理解你的项目上下文、回答技术问题、生成单元测试、解释遗留代码、甚至直接通过自然语言指令完成整个功能的开发。2025年,是否熟练地使用AI编程工具,已成为衡量一个开发者效率和竞争力的重要标准。
这场变革的背后,是大型语言模型(特别是代码大模型,Code LLMs)能力的飞跃。通过在数万亿行高质量开源代码上的预训练,这些模型学习到了丰富的编程语言知识、算法模式、API用法和开发最佳实践。它们不再是简单的模式匹配,而是具备了真正的“代码理解”和“代码生成”能力。
4.1 主流AI编程工具矩阵:从“辅助”到“原生”
2025年的AI编程工具市场,呈现出两大主流形态:一类是作为插件(Plugin)嵌入到VS Code、JetBrains等主流IDE中的“辅助型”工具;另一类则是将AI能力作为核心、重新设计整个编辑器交互体验的“AI原生(AI-Native)”代码编辑器。
**“辅助型”**工具:无缝集成,赋能现有工作流
这类工具的优势在于它们可以无缝地集成到开发者已经熟悉的开发环境中,学习成本低,上手快。
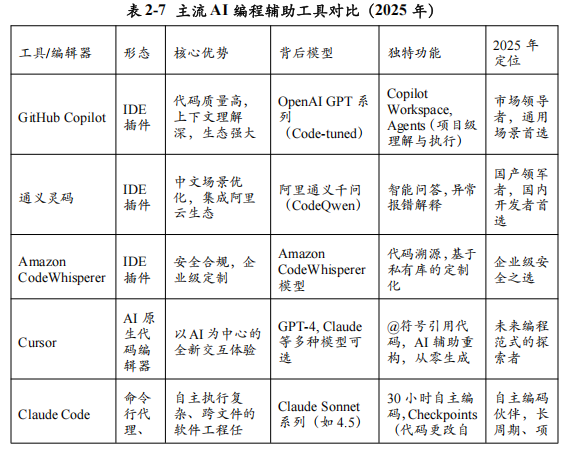
GitHub Copilot:由GitHub、OpenAI和微软联手打造的Copilot,是当之无愧的市场领导者。凭借其背后强大的GPT系列模型(特别是针对代码微调的版本)和对海量GitHub公开代码的“学习”,Copilot在代码补全的质量和上下文理解的深度上长期保持领先。2025年的Copilot已经远不止是代码补全,其Copilot Chat功能已经深度集成到IDE中,开发者可以直接在编辑器中通过对话的方式,要求它解释代码、生成文档、寻找Bug、甚至重构整个文件。其“Workspace”和“Agents”等新功能,使其具备了理解整个项目代码库、并自主执行如“添加一个新API端点”等多文件修改任务的能力。
通义灵码(Tongyi Lingma):由阿里云推出的通义灵码,是国产AI编程助手的杰出代表。它依托于阿里巴巴自研的通义千问大模型(特别是其代码模型CodeQwen),在中文编程场景(如中文注释、中文文档生成)和阿里云生态的集成上具有天然优势。通义灵码同样提供了行级/函数级代码补全、自然语言生成代码、单元测试生成、代码解释等全方位的辅助功能,并且针对国内开发者的网络环境和使用习惯进行了优化,是国内开发者替代Copilot的首选。
Amazon CodeWhisperer:由AWS推出的CodeWhisperer,其核心竞争力在于安全和企业级定制。它在训练时过滤掉了与开源许可证冲突的代码,并提供了代码溯源功能,可以清晰地标出生成的代码片段来自哪个开源项目,帮助企业规避潜在的法律风险。此外,CodeWhisperer for Enterprise允许企业使用自己的私有代码库来对模型进行定制化微调,使其能够生成更符合企业内部编码规范和业务逻辑的代码。
Claude Code:作为由Anthropic打造的智能编程助手,Claude Code凭借其背后强大的Claude系列模型(特别是经过代码专项优化的版本)以及对海量优质开源代码的深度学习,正迅速成为最受开发者欢迎的工具。Claude Code不仅在代码补全的准确性和上下文感知的敏锐度上表现出色,更以其对代码安全性与可靠性的深度关注而独树一帜。2025年的Claude Code已进化成为一个全能的编程伙伴,其深度集成的对话界面让开发者能够直接在IDE中通过自然交互,请求其解释复杂逻辑、生成测试用例、定位潜在漏洞,甚至对代码结构进行系统性优化。其“项目级理解”与“渐进式变更”等创新功能,使其能够精准把握整个代码库的架构脉络,并可靠地执行如“为模块添加新的数据校验逻辑”等涉及多文件协作的复杂任务,重新定义了人机协作的编程体验。
**“AI原生”**编辑器:颠覆交互,以对话为中心
与插件不同,AI原生编辑器认为,大模型的出现将从根本上改变人与代码的交互方式。它们不再以“文件”和“文本编辑”为中心,而是以“对话”和“意图”为中心,将AI作为交互的一等公民来重新设计整个IDE。
Cursor是这一领域的开创者和引领者。它在VS Code的开源内核基础上,构建了一个全新的、以AI为核心的编程环境。在Cursor中,开发者可以:
@符号引用代码:在聊天框中,用@符号可以轻松地引用项目中的任何文件或代码片段,让AI精准地理解你的意图。例如,你可以说:“@file1.py中的这个函数逻辑有问题,请参考@file2.js中的实现方式帮我重构它。”
AI辅助重构:选中一段代码,直接用自然语言描述你的修改意图,AI会自动生成修改后的代码差异(Diff),供你一键接受或继续修改。
从零生成项目:通过对话,让AI帮助你从零开始构建一个新项目的脚手架,包括目录结构、配置文件和基础代码。
Cursor的出现,标志着软件开发正在从“人写代码,AI辅助”的模式,向“人提出意图,AI实现代码”的模式转变,这可能是对软件开发流程更深远的颠覆。
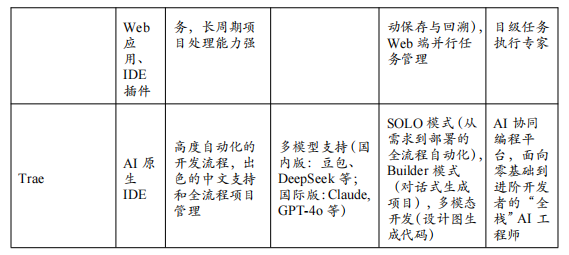
字节跳动 Trae:作为字节跳动旗下火山引擎推出的智能编程助手,Trae凭借字节跳动在超大规模代码库上的深厚技术积淀以及对现代开发流程的深刻洞察,展现出强大的市场竞争力。依托于字节自研的先进代码大模型以及对海量内部工程实践的高效学习,Trae在代码生成的质量和对中文开发语境的理解上具有独特优势。如今的Trae已构建起一个覆盖开发全周期的智能平台,其深度定制的IDE插件允许开发者通过便捷的聊天交互,完成代码审查、性能调优、依赖迁移等复杂操作。其“智能代码库导航”和“端到端任务执行”等核心能力,使其能够系统性地理解项目上下文,并自动完成如“实现一个完整的用户登录功能”这类需要前后端联动的开发任务,极大地提升了研发效率与代码质量,成为团队提效的关键推动力。
4.2 AI编程工具的未来:从“副驾”到“领航员”
展望未来,AI编程工具的发展将呈现两大趋势:
更深度的项目理解:未来的AI将不再局限于当前文件,而是能够理解整个代码仓库、依赖关系、构建脚本、甚至CI/CD流水线。它将能够像一个资深架构师一样,为你提供更高层次的设计建议,并自主地完成跨越多个文件和模块的复杂任务。
更强的自主性(AI Agent for SWE):以Devin项目为代表的“AI软件工程师”虽然在2025年尚未完全成熟,但它指明了最终的方向——一个能够独立理解需求文档、进行技术选型、编写代码、调试、直至最终部署的全自主AI Agent。到那时,人类开发者的角色将更多地转向上游的需求分析、产品设计和最终决策,而将具体的编码实现工作交给AI来完成。
对于今天的开发者而言,积极拥抱和学习使用这些AI编程工具,不仅是提升个人生产力的捷径,更是适应未来软件开发新范式的必然要求。它们正在将开发者从繁琐、重复的编码劳动中解放出来,让我们可以更专注于创造性的思考和更高层次的系统设计,这无疑是整个软件工程领域的一场深刻的福音。
结论:拥抱技术栈,构建智能未来
本文系统性地梳理了2025年AI大模型开发的核心技术栈,从奠定基石的深度学习框架,到引爆应用创新的Agent编排层;从驾驭万亿参数的分布式训练,到实现普惠AI的参数高效微调;从追求极致性能的推理优化,到重塑开发流程的AI编程工具。这一整套“开发者军火库”,共同构成了当前AI技术革命的引擎室。
我们看到,整个技术栈呈现出清晰的分层化、模块化和民主化趋势:
分层化:底层的基础框架(PyTorch/JAX)专注于计算效率,上层的Agent框架(LangGraph/CrewAI)专注于能力编排,分工明确,协同工作。
模块化:无论是PEFT(LoRA)、推理优化(PagedAttention)还是AI编程工具,都以可插拔、可组合的模块形式出现,开发者可以根据需求灵活选用,构建定制化的技术栈。
民主化:QLoRA让个人开发者也能微调百亿模型,vLLM让中小企业也能部署高并发服务,Dify让业务人员也能构建AI应用。技术的发展正在以前所未有的速度降低AI的门槛,将创造智能的能力赋予更广泛的人群。
对于算泥社区的开发者而言,深刻理解并熟练掌握这一技术栈,是抓住时代机遇、将创意转化为现实的核心能力。平台的核心价值,就在于将这些复杂、前沿的技术进行整合、封装和优化,以一站式、低门槛的方式提供给开发者,让他们不必在环境配置、依赖管理和底层优化上耗费心力,而能专注于模型微调、应用逻辑和业务创新本身。通过拥抱这个日新月异的技术栈,中国的开发者社区必将在全球AI创新的浪潮中,贡献出独特而重要的力量。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)