【MLLM】全模态Omni模型(持续更新)
meituan开源全模态大模型:https://github.com/meituan-longcat/LongCat-Flash-Omni。基于稀疏专家架构的全模态训练 Ming-flash-omni-Preview 将 Ling-flash-2.0 稀疏 MoE 架构拓展到全模态大模型,基于 Ming-lite-omni 提出的模态级路由实现对各模态分布和路由策略建模,实现各模态的 “大容量、小
note
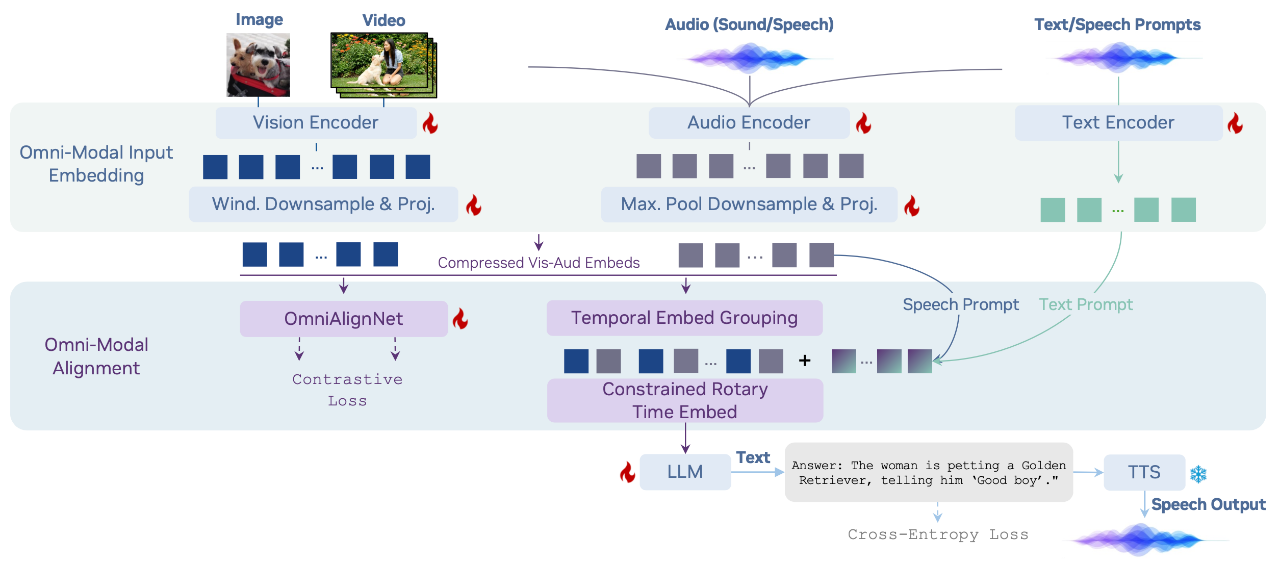
- OmniVinci使用OmniAlignNet:跨模态语义对齐网络。Temporal Embedding Grouping (TEG):时间嵌入分组机制
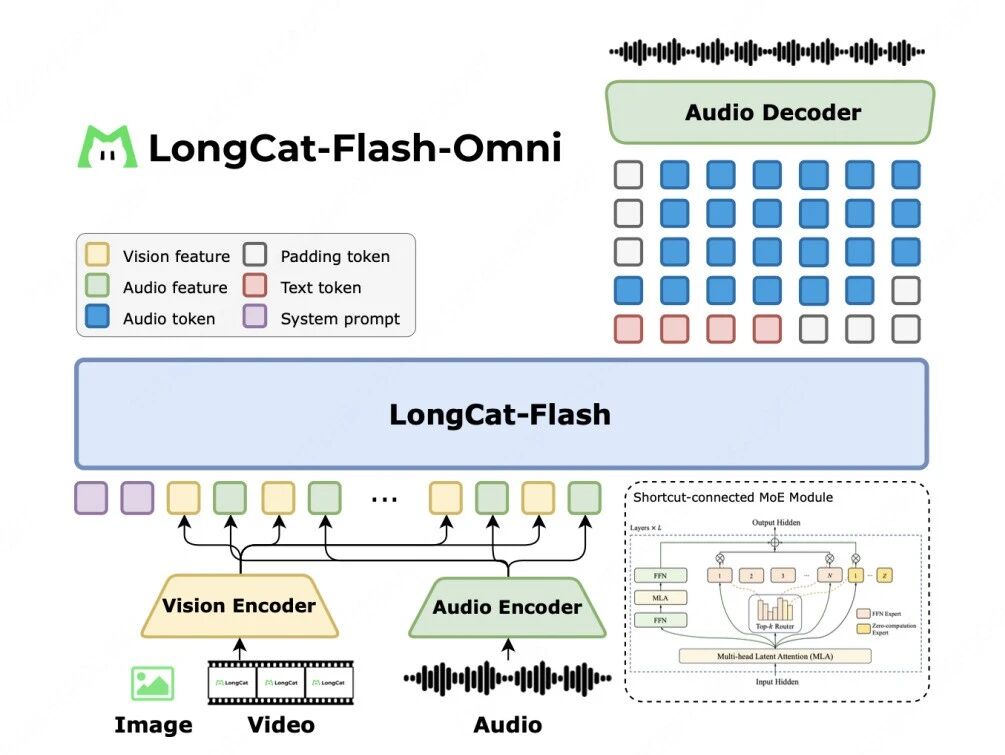
- LongCat-Flash-Omni 以 LongCat-Flash 系列的高效架构设计为基础( Shortcut-Connected MoE,含零计算专家),同时创新性集成了高效多模态感知模块与语音重建模块。即便在总参数 5600 亿(激活参数 270 亿)的庞大参数规模下,仍实现了低延迟的实时音视频交互能力。
- Ming-flash-omni-Preview模型基于稀疏专家架构的全模态训练 Ming-flash-omni-Preview 将 Ling-flash-2.0 稀疏 MoE 架构拓展到全模态大模型,基于 Ming-lite-omni 提出的模态级路由实现对各模态分布和路由策略建模,实现各模态的 “大容量、小激活”。通过在 Attention 层引入 VideoRoPE,强化对长视频的时空建模,提升视频交互能力。
一、OmniVinci模型
论文标题:OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM
项目地址:https://github.com/NVlabs/OmniVinci
论文地址:https://arxiv.org/abs/2510.15870
开源模型:https://huggingface.co/nvidia/omnivinci
机构:nvidia
OmniVinci 在多项常用多模态基准测试榜单中取得了显著优势,包括视频 - 音频跨模态理解任务(DailyOmni +19.05),音频理解 (MMAR + 1.7),和视频理解 (Video-MME +3.9)。
Omnibench评测集效果: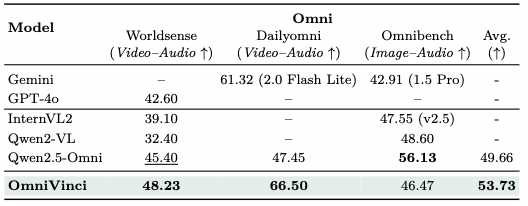
使用GRPO有一定收益(但收益不大):
二、LongCat-Flash-Omni模型
meituan开源全模态大模型:https://github.com/meituan-longcat/LongCat-Flash-Omni。LongCat-Flash-Omni 以 LongCat-Flash 系列的高效架构设计为基础( Shortcut-Connected MoE,含零计算专家),同时创新性集成了高效多模态感知模块与语音重建模块。即便在总参数 5600 亿(激活参数 270 亿)的庞大参数规模下,仍实现了低延迟的实时音视频交互能力。
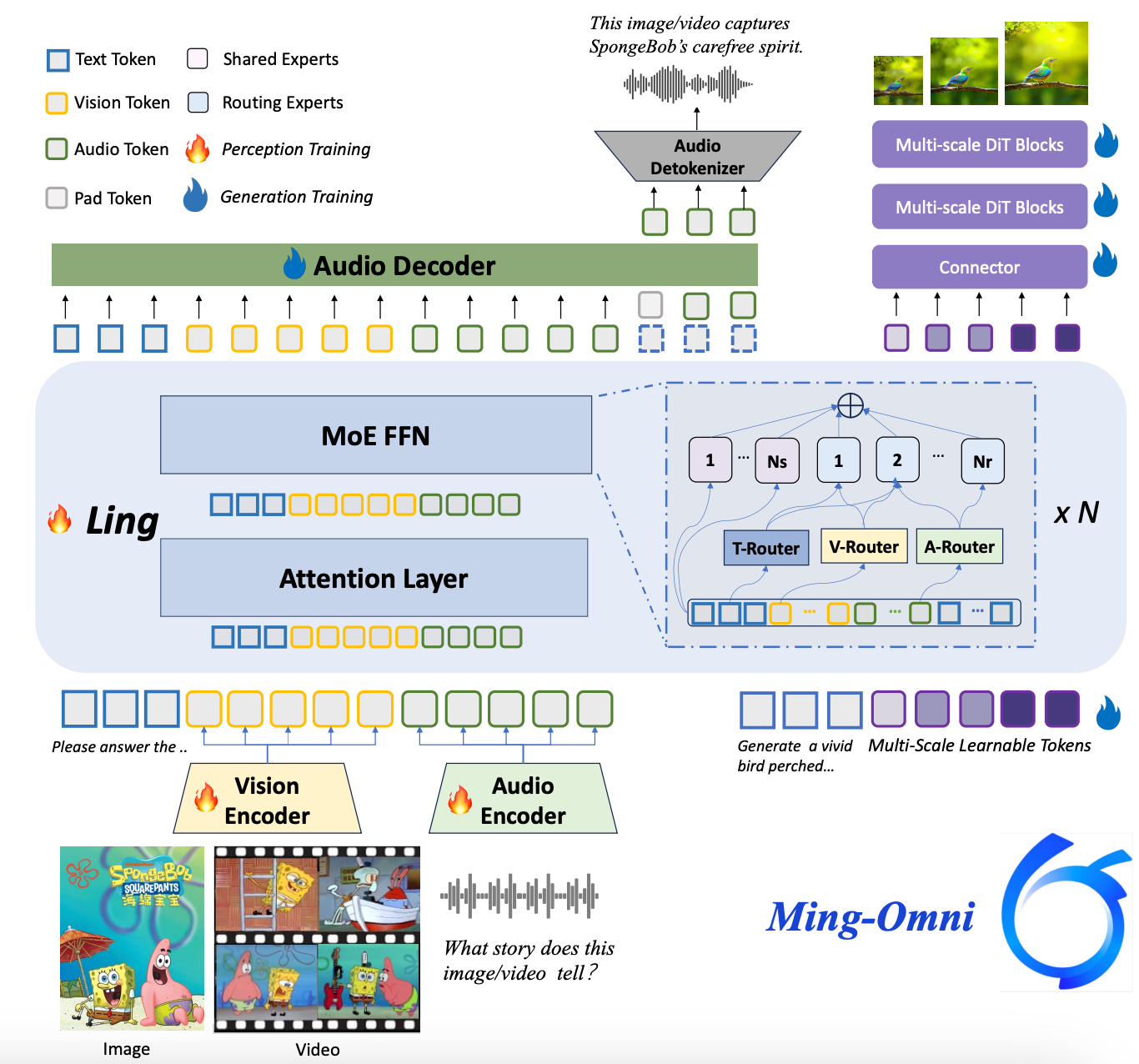
三、Ming-flash-omni-Preview模型
GitHub: https://github.com/inclusionAI/Ming
HuggingFace: https://huggingface.co/inclusionAI/Ming-flash-omni-Preview
ModelScope:https://www.modelscope.cn/models/inclusionAI/Ming-flash-omni-Preview
基于稀疏专家架构的全模态训练 Ming-flash-omni-Preview 将 Ling-flash-2.0 稀疏 MoE 架构拓展到全模态大模型,基于 Ming-lite-omni 提出的模态级路由实现对各模态分布和路由策略建模,实现各模态的 “大容量、小激活”。通过在 Attention 层引入 VideoRoPE,强化对长视频的时空建模,提升视频交互能力。 另外在训练策略上:
- 稳定稀疏训练:使用混合专家平衡方案(结合辅助负载均衡损失与路由器偏置更新),确保稀疏 MoE 架构下全模态训练的均匀激活和收敛性;
- 上下文感知的 ASR 训练范式:语音训练任务上以任务 / 领域信息输入作为解码条件,显著提高专有名词识别和转录一致性。同时引入高质量方言等训练语料,实现对湖南话、闽南话、粤语等 15 种中国方言的识别准确率显著提升。
Reference

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)