【RL】Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
提出了监督强化学习(SRL)框架,通过将专家解决方案分解为可管理的步骤并提供密集的序列相似度奖励,显著提高了LLMs在复杂推理任务上的性能。实验结果表明,SRL不仅在数学推理和软件工程任务上优于基线方法,还能与RLVR结合形成强大的课程学习策略。SRL作为一种稳健且通用的技术,能够解锁模型从具有挑战性的多步问题中学习的能力,为训练更强大、更多功能的AI代理奠定了基础。SRL巧妙地融合了SFT和RL
note
- 提出了监督强化学习(SRL)框架,通过将专家解决方案分解为可管理的步骤并提供密集的序列相似度奖励,显著提高了LLMs在复杂推理任务上的性能。
- 实验结果表明,SRL不仅在数学推理和软件工程任务上优于基线方法,还能与RLVR结合形成强大的课程学习策略。SRL作为一种稳健且通用的技术,能够解锁模型从具有挑战性的多步问题中学习的能力,为训练更强大、更多功能的AI代理奠定了基础。
- SRL巧妙地融合了SFT和RL(hard reasoning problem难学会)的优点,它不再是僵硬地模仿整个轨迹,也不是盲目地等待最终结果。相反,它将复杂的解题过程分解为一系列逻辑“动作”,并在每一步都将模型的动作与专家的动作进行比较,根据“相似度”给予平滑、密集的奖励。
- 奖励仅根据逻辑动作 y step k ′ \mathbf{y}_{\text{step}_{k}}^{\prime} ystepk′计算,而不考虑内部独白 y think ′ \mathbf{y}_{\text{think}}^{\prime} ythink′。这给了模型极大的灵活性,可以发展出自己的内部推理风格,只要其外部行为与专家策略保持一致即可
文章目录
一、问题背景
论文:Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
- 研究问题:这篇文章要解决的问题是大型语言模型(LLMs)在处理需要多步推理的问题时表现不佳。具体来说,小规模开源模型在使用可验证奖励的强化学习(RLVR)时,即使尝试多次也难以采样到正确答案;而监督微调(SFT)则容易导致过拟合长展示。
- 研究难点:该问题的研究难点包括:在训练数据中难以找到正确解决方案的轨迹,尤其是在需要复杂多步推理的任务中;直接惩罚所有错误输出会导致训练不稳定,阻碍进展。
- 相关工作:该问题的研究相关工作有:SFT通过专家演示进行模仿学习,但其严格的逐词模仿限制了模型的泛化能力;基于结果的RL方法依赖于最终答案的正确性,但在难以找到正确解决方案的情况下效果不佳。
1、SFT和RLVR回顾
1、监督微调
定义:给定一个数据集 D = { ( x ( i ) , y ( i ) ) } D = \{(x^{(i)},y^{(i)})\} D={(x(i),y(i))},其中 x x x 是输入, y y y 是期望的输出。
目标:最小化负对数似然损失,使模型学会生成与 y y y 完全一致的输出。
损失函数:
L SFT ( θ ) = − ∑ i = 1 N log p θ ( y ( i ) ∣ x ( i ) ) L_{\text{SFT}}(\theta)=-\sum_{i=1}^{N} \log p_{\theta}\left(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}\right) LSFT(θ)=−i=1∑Nlogpθ(y(i)∣x(i))
2、强化学习
研究重点:近期的研究主要集中在基于可验证奖励的强化学习。
方法示例:以群体相对策略优化为例,说明其采样机制和目标函数。
GRPO 方法流程:
- 采样机制:为每个输入 x x x 从旧策略 θ old \theta_{\text{old}} θold 中采样 G G G 个响应轨迹 { o i } \{o_i\} {oi}。
- 目标函数:
E [ 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( p θ ( o i , t ∣ x , o i , < t ) p θ old ( o i , t ∣ x , o i , < t ) A i , t , clip ( p θ ( o i , t ∣ x , o i , < t ) p θ old ( o i , t ∣ x , o i , < t ) , 1 − ϵ , 1 + ϵ ) A i , t ) ] − β D KL [ p θ ∥ p ref ] \mathbb{E}\left[\frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min \left(\frac{p_{\theta}(o_{i,t} \mid \mathbf{x}, o_{i,<t})}{p_{\theta_{\text{old}}}(o_{i,t} \mid \mathbf{x}, o_{i,<t})} A_{i,t}, \operatorname{clip}\left(\frac{p_{\theta}(o_{i,t} \mid \mathbf{x}, o_{i,<t})}{p_{\theta_{\text{old}}}(o_{i,t} \mid \mathbf{x}, o_{i,<t})}, 1-\epsilon, 1+\epsilon\right) A_{i,t}\right)\right]-\beta \mathbb{D}_{\text{KL}}[p_{\theta} \| p_{\text{ref}}] E G1i=1∑G∣oi∣1t=1∑∣oi∣min(pθold(oi,t∣x,oi,<t)pθ(oi,t∣x,oi,<t)Ai,t,clip(pθold(oi,t∣x,oi,<t)pθ(oi,t∣x,oi,<t),1−ϵ,1+ϵ)Ai,t) −βDKL[pθ∥pref]
概念说明:
- 优势函数 A i , t A_{i,t} Ai,t:基于群体水平归一化的奖励
- 策略梯度消失问题:当一个批次中所有采样的回答都正确或都错误时, A i , t A_{i,t} Ai,t 变为零,导致策略梯度消失,模型无法更新
- 解决方案:通常需要动态采样来确保批次内奖励存在差异
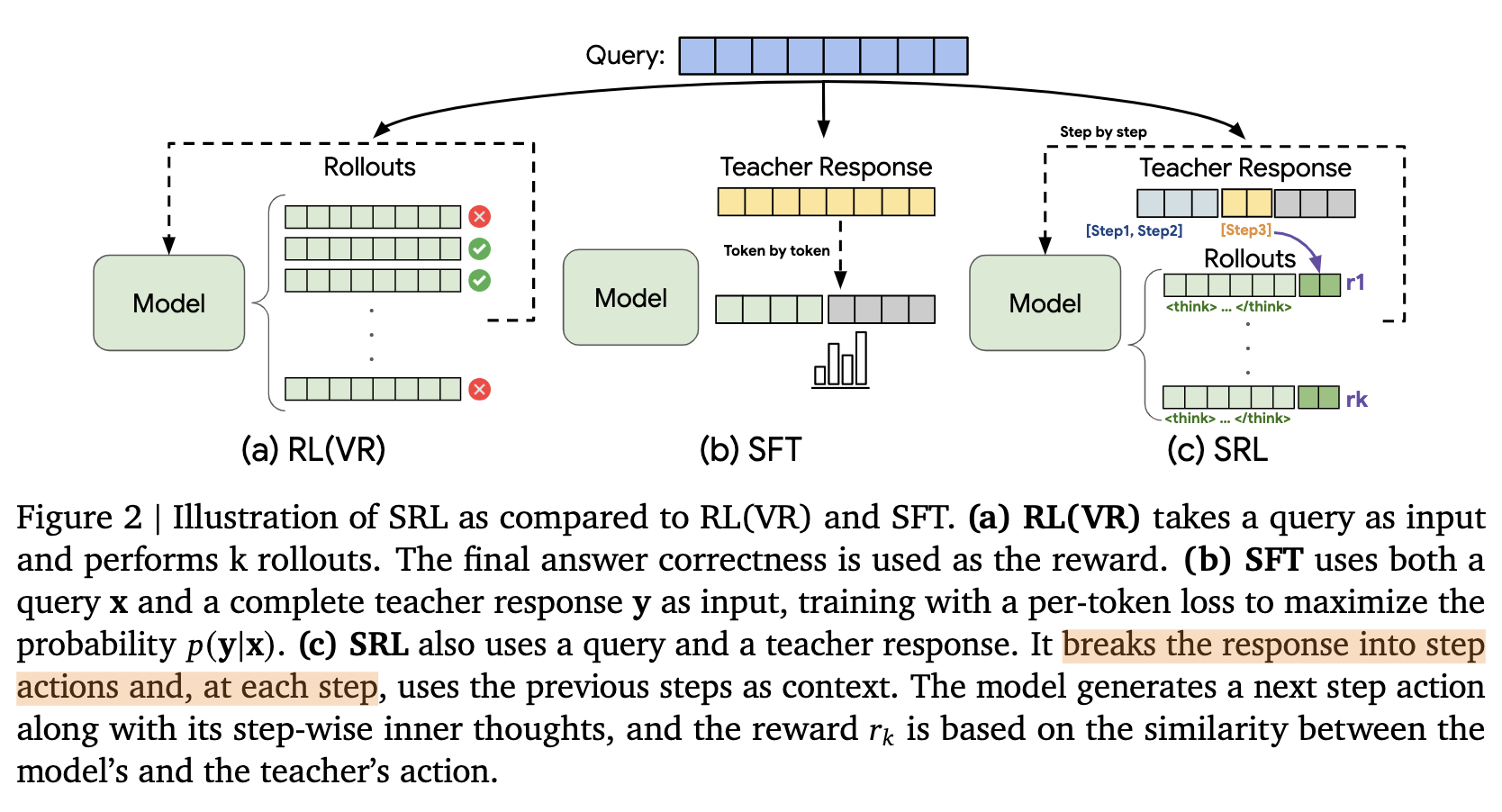
基于动作的问题构建:给定一个专家的正确解题轨迹y,首先将其分解为一个动作序列 y = {y_step_n}。这里的“动作”是领域无关的,在数学推理中可以是一个代数变换,在软件工程中可以是一个命令行操作。
分步训练数据构建:利用强大的教师模型生成解题轨迹。对于一个包含N个步骤的完整解,可以构建出N-1个部分轨迹。对于第k步,创建一个新的输入提示 x_step_k = [x, y_step_1, …, y_step_k-1],模型的任务是预测下一步 y_step_k。这个过程将一个专家解题范例转化为了一个丰富的训练实例集,教会模型如何从不同的中间状态正确地前进。
二、研究方法
1、算法流程
提出了监督强化学习(SRL)框架,用于解决LLMs在多步推理问题上的不足。具体来说,
1、动作分解:首先,将专家解决方案分解为一系列逻辑动作,每个动作代表一个有意义的决策步骤。
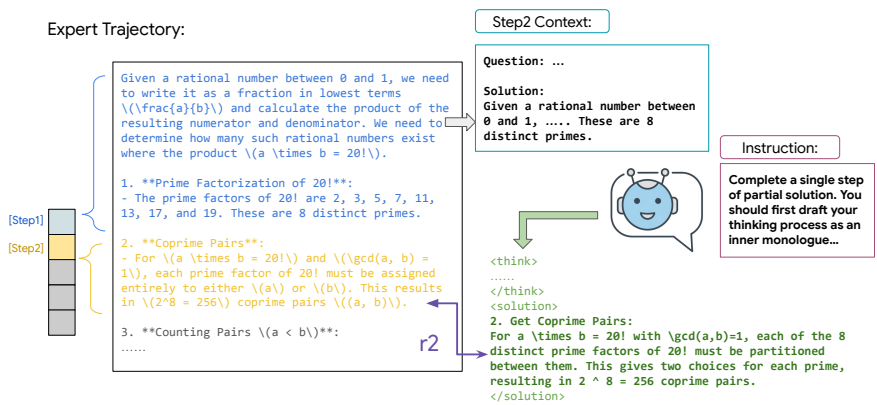
2、逐步训练数据构建:利用强大的教师模型生成解决方案轨迹,从完整解决方案中构建部分轨迹。对于每一步,创建一个新的输入提示,模型的任务是预测下一步。
3、序列相似度奖励:在训练过程中,模型生成内部独白和后续动作,并根据生成的逻辑动作与专家动作的相似度提供密集奖励。奖励函数定义为 R ( y step k ′ , y step k ) = 2 M T R\left(y_{\text {step }_k}^{\prime}, y_{\text {step }_k}\right)=\frac{2 M}{T} R(ystep k′,ystep k)=T2M
其中,T是两个序列的总元素数,M是匹配元素的数量。
4、动态采样:为了提高训练效率,对样本进行动态采样,过滤掉那些奖励方差接近零的样本,确保每个样本都能提供有意义的学习信号。
2、奖励函数
带内部独白的学习与序列相似度奖励:给定一个包含问题和部分解的上下文 x step k \mathbf{x}_{\text{step}_{k}} xstepk,策略模型 p θ p_{\theta} pθ 被提示生成后续步骤,其输出包含两部分:
- 内部独白 y think ′ \mathbf{y}_{\text{think}}^{\prime} ythink′(被
<think>标签包裹) - 逻辑动作 y step k ′ \mathbf{y}_{\text{step}_{k}}^{\prime} ystepk′
模型的生成过程可以表示为:
y ′ ∼ p θ ( ⋅ ∣ x step k ) = [ y think ′ , y step k ′ ] \mathbf{y}' \sim p_{\theta}(\cdot|\mathbf{x}_{\text{step}_{k}}) = [\mathbf{y}_{\text{think}}^{\prime}, \mathbf{y}_{\text{step}_{k}}^{\prime}] y′∼pθ(⋅∣xstepk)=[ythink′,ystepk′]
奖励函数设计:
奖励函数 R ( y step k ′ , y step k ) R(\mathbf{y}_{\text{step}_{k}}^{\prime}, \mathbf{y}_{\text{step}_{k}}) R(ystepk′,ystepk)衡量生成动作与专家动作之间的序列相似度,计算公式为: R = 2 M T R = \frac{2M}{T} R=T2M
其中:
- T T T (Total elements):两个序列的元素总数
- M M M (Matched elements):两个序列中所有非重叠匹配块中的元素总数
在实践中,作者使用 Python 的 difflib.SequenceMatcher 来计算这个相似度。如果生成的输出不符合格式要求,则给予 -1 的惩罚。
最终的奖励函数为:
r ( y step k ′ , y step k ) = { R ( y step k ′ , y step k ) if y ′ 遵循格式要求 − 1 otherwise r(\mathbf{y}_{\text{step}_{k}}^{\prime}, \mathbf{y}_{\text{step}_{k}}) = \begin{cases} R(\mathbf{y}_{\text{step}_{k}}^{\prime}, \mathbf{y}_{\text{step}_{k}}) & \text{if } \mathbf{y}' \text{ 遵循格式要求} \\ -1 & \text{otherwise} \end{cases} r(ystepk′,ystepk)={R(ystepk′,ystepk)−1if y′ 遵循格式要求otherwise
训练优化:策略模型 p θ p_{\theta} pθ 使用这个奖励信号和 GRPO 目标函数进行优化。
关键创新:奖励仅根据逻辑动作 y step k ′ \mathbf{y}_{\text{step}_{k}}^{\prime} ystepk′计算,而不考虑内部独白 y think ′ \mathbf{y}_{\text{think}}^{\prime} ythink′。 这给了模型极大的灵活性,可以发展出自己的内部推理风格,只要其外部行为与专家策略保持一致即可。
三、实验设计
- 数据收集:使用s1K-1.1数据集进行微调,该数据集包含1000个多样且具有挑战性的数学问题,每个问题都配有详细的推理轨迹和最终解决方案。
- 基线方法:对比了SFT、RLVR和SRL等多种方法。SFT基于完整的推理轨迹或最终解决方案进行微调;RLVR使用GRPO算法,分别在基模型和SFT后应用;SRL作为独立技术和顺序配置进行评估。
- 评估设置:在四个竞赛级数学推理基准上进行评估,包括AMC23、AIME24、AIME25和Minerva Math。评估协议严格遵循Qwen2.5-Math的设置,报告贪婪采样的准确性。
作者提供了SFT、GRPO和SRL的超参数设置。值得注意的是,GRPO的批次大小(128)小于SRL(512),因为在难题上,基于最终答案正确性的过滤率很高,较小的批次大小有助于避免重复采样并获得更好的性能。
四、结果分析
1、实验分析
数学推理:SRL在AMC23、AIME24、AIME25和Minerva Math上的平均准确率分别提高了3.0%、3.7%和3.7%。SRL→RLVR的组合方法进一步提高了性能,平均准确率达到36.4%。
动态采样的影响:动态采样显著提高了SRL的性能,过滤掉奖励方差接近零的样本后,模型在AMC23、AIME24、AIME25和Minerva Math上的平均准确率分别提高了2.3%、3.3%、3.7%和2.9%。
指导粒度的解耦:细粒度的逐步指导比整体序列相似度奖励更有效。多步分解方法在挑战性训练数据上表现优异,平均准确率为36.4%,而整体序列相似度奖励的平均准确率为34.9%。
软件工程代理推理:在SWE-Bench数据集上,SRL方法的解决率达到14.8%,比基线SWE-Gym-7B提高了74%。在端到端评估中,SRL方法的性能翻倍。
SRL在软件工程(SWE)任务上的图示:
2、消融实验1:不同奖励函数和密度的模型性能
为了验证SRL成功的关键是分步指导,作者设计了对比实验:
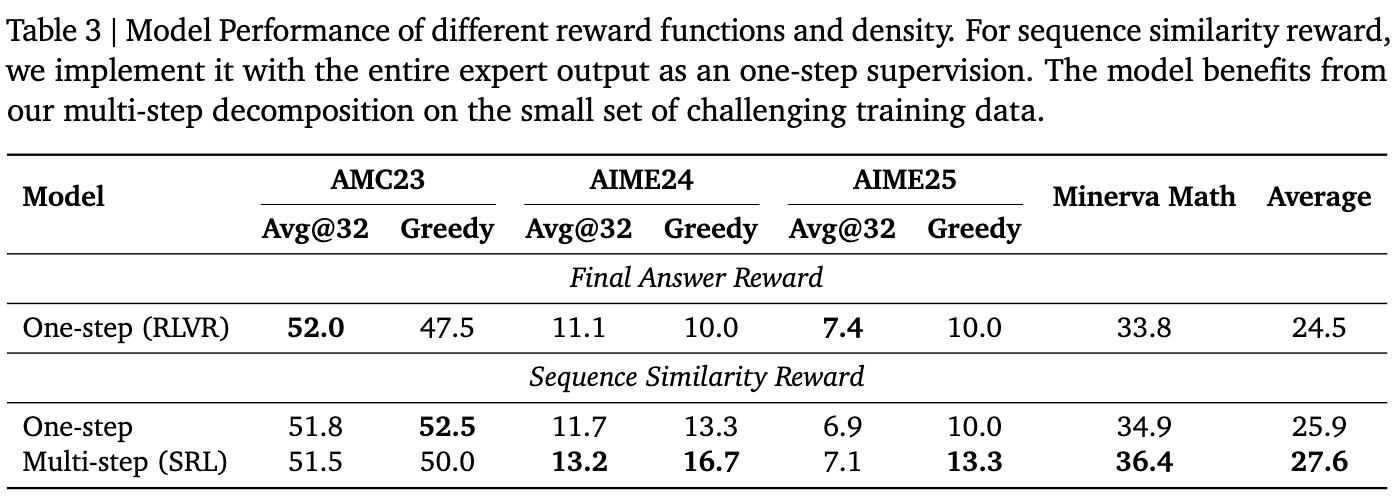
1、最终答案奖励 (RLVR):仅在最终答案正确时给予奖励。
2、整体序列相似度奖励:模型一次性生成完整解,然后将其与完整的专家轨迹比较相似度。
3、多步序列相似度奖励 (SRL):本文提出的方法。
结果清晰地表明,虽然整体相似度奖励也能带来一些提升,但细粒度的、分步的指导(SRL) 带来了最显著的性能飞跃。
五、论文评价
1、优点与创新
提出了监督强化学习(SRL)框架,将问题解决重新表述为生成一系列逻辑“动作”的序列决策过程。
SRL在每一步提供基于模型预测动作与专家动作相似度的奖励信号,提供了更丰富、更细粒度的学习信号。
通过详细的分析,展示了粒度指导对SRL奖励及其对模型行为的影响,诱导出灵活且复杂的推理模式。
SRL显著优于传统的SFT和RLVR方法,特别是在数学推理和软件工程任务中表现出色。
SRL与RLVR结合使用时,能够实现强大的课程学习策略,进一步提升了模型的学习效果。
SRL框架不仅适用于数学推理任务,还能有效推广到软件工程任务,证明了其作为一个稳健且通用的训练框架的潜力。
2、不足与反思
论文指出,SRL的有效性根本上取决于学生模型对任务的初始熟练度以及逐步数据和回滚样本的质量。如果学生模型在任务上没有建立足够的基线能力,或者逐步数据和回滚样本的质量不高,SRL的效果可能会受到影响。
论文提到,尽管SRL在数学推理和软件工程任务中表现出色,但其性能提升是否可以简单地归因于推理长度的增加,还需要进一步研究。
六、实践经验
作者最后指出,SRL的有效性取决于两个前提:
1、学生模型的初始能力:学生模型必须具备基本的指令遵循能力,以确保初始的rollouts是与任务相关且格式正确的。
2、数据质量:尽管分步分解降低了任务难度,但分解后的数据必须能让策略模型有一定概率获得较好的奖励。
Reference
[1] Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
[2] SFT过拟合,RL奖励稀疏?谷歌提出SRL新范式,让小模型也能深度思考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)