SAC-Auto强化学习算法与应用实例(路径规划) 本项目是一个基于PyTorch实现的SAC...
在仓库的测试案例中,经过训练的智能体能在包含移动障碍物的场景里走出s型路线。有意思的是当遭遇突发障碍时,策略网络会突然增大动作熵值,表现出类似人类驾驶员的"犹豫"特性,这种动态不确定性调节正是SAC系列算法的精髓所在。支持算法在不同设备间转移,包括CPU和CUDA(GPU),以及存储和加载训练过程,便于算法的部署和迁移。提供了自定义Buffer的示例,包括存储、采样和状态转换的实现,为用户提供了灵
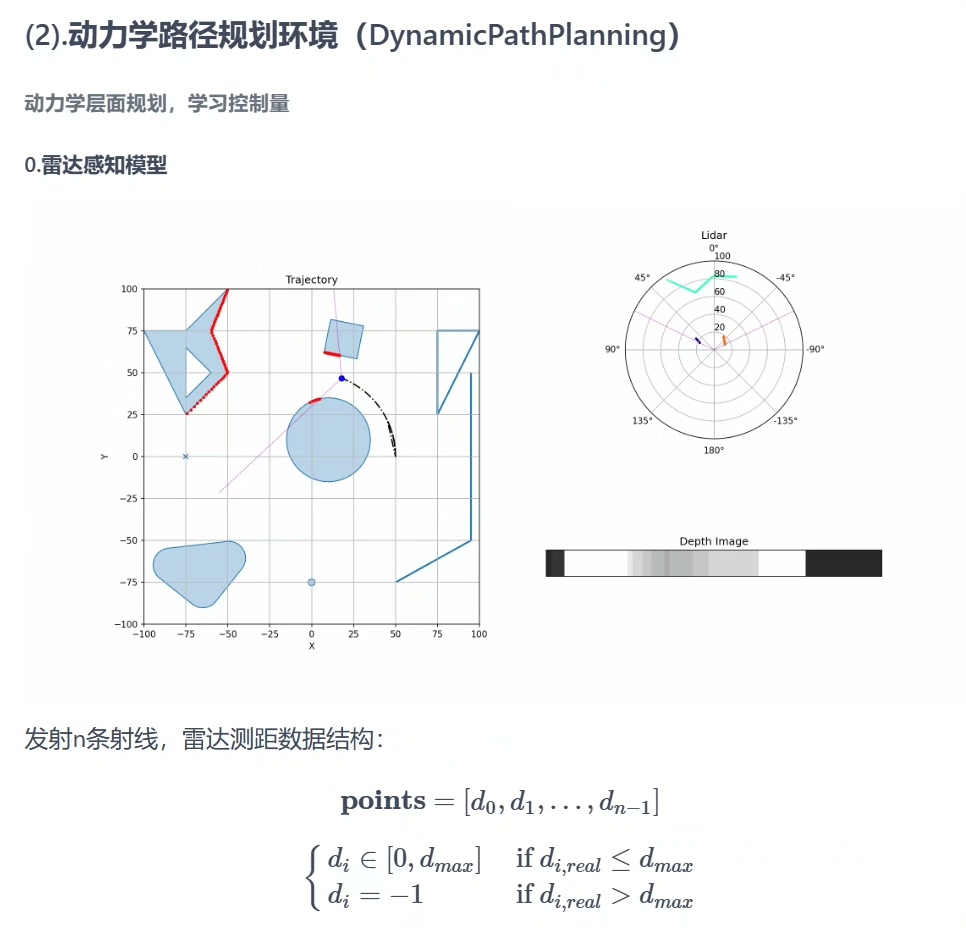
SAC-Auto强化学习算法与应用实例(路径规划) 本项目是一个基于PyTorch实现的SAC-Auto强化学习算法,专为路径规划任务设计 它支持高度自定义,包括策略模型部署、训练过程备份、多源观测融合和优先级经验回放(PER)等功能,以适应不同的应用场景和需求 核心模块概览: rl_typing.py:定义了强化学习所需的数据类型,为算法提供数据结构的支撑 sac_agent.py:包含了SAC-Auto算法的主体模块,是算法运行的核心 SAC_Agent模块详解: 提供了一系列接口,包括初始化、Torch设备切换、IO操作和训练交互,使得算法能够灵活地适应不同的运行环境和需求 支持算法在不同设备间转移,包括CPU和CUDA(GPU),以及存储和加载训练过程,便于算法的部署和迁移 提供了ONNX策略模型的部署能力,使得算法能够轻松集成到不同的生产环境中 SAC_Actor和SAC_Critic模块: 允许用户自定义观测Encoder、策略函数和Q函数,为算法提供了高度的自定义能力 提供了自定义神经网络的示例,包括编码器、策略网络和TwinQ函数,帮助用户快速理解和实现自定义网络 BaseBuffer模块: 提供了一个自定义的经验回放Buffer,支持PER等功能,增强了算法的稳定性和效率 提供了自定义Buffer的示例,包括存储、采样和状态转换的实现,为用户提供了灵活的数据管理方式 路径规划环境SAC应用示例: 包含了一个路径规划环境包path_plan_env,集成了激光雷达模拟、动作空间归一化、动力学路径规划和路径搜索环境 提供了环境接口和使用示例,包括支持老版和新版gym接口风格,使得算法能够轻松集成到不同的仿真环境中 环境接口: 提供了标准的gym接口,用于初始化环境和进行训练/测试交互,确保了算法的兼容性和易用性 路径搜索环境(StaticPathPlanning): 提供了几何层面的规划,能够直接寻找组成路径的点,适用于静态环境下的路径规划 动力学路径规划环境(DynamicPathPlanning): 提供了动力学层面的规划,学习控制量,适用于动态环境下的路径规划 包含了雷达感知模型和动力学模型,为算法提供了丰富的感知和控制能力 训练结果和仿真结果:
当机器人遇上复杂迷宫,传统路径规划算法总在转角处卡壳。今天咱们来聊聊强化学习里的"变形金刚"——SAC-Auto算法如何让智能体在动态环境中走出妖娆路线。这个基于PyTorch实现的框架,藏着不少工程师们喜闻乐见的黑科技。

先看这个让人会心一笑的设备切换魔法:
class SAC_Agent:
def to_device(self, device):
self.actor = self.actor.to(device)
self.critic = self.critic.to(device)
for opt in self.optimizers.values():
for param_group in opt.param_groups:
if 'params' in param_group:
param_group['params'] = [p.to(device) for p in param_group['params']]这段代码堪称硬件界的变色龙,能在CPU和GPU之间无缝切换。注意优化器参数的搬运操作,很多开源实现会漏掉这个细节,导致切换设备后出现幽灵参数问题。我们直接把优化器里的参数组打包带走,确保训练过程不"精分"。
动态观测编码器是应对复杂环境的关键武器:
class CustomEncoder(nn.Module):
def __init__(self, obs_dims):
super().__init__()
self.lidar_net = nn.Sequential(nn.Linear(obs_dims['lidar'], 64), nn.ReLU())
self.gps_net = nn.Sequential(nn.Linear(obs_dims['gps'], 32), nn.Tanh())
def forward(self, obs):
return torch.cat([
self.lidar_net(obs['lidar']),
self.gps_net(obs['gps'])
], dim=-1)这个编码器就像机器人的感官融合中枢,把激光雷达的360°扫描数据和GPS定位信息搅和在一起。有趣的是我们在雷达分支用ReLU激活,GPS分支却用Tanh——前者需要处理突发障碍物的剧烈信号,后者更适合处理归一化后的平稳位置数据。

优先级经验回放(PER)的实现藏着玄机:
class PERBuffer(BaseBuffer):
def _compute_priority(self, td_error):
return (torch.abs(td_error) + 1e-5).pow(self.alpha)
def sample(self, batch_size):
probs = self.priorities / self.priorities.sum()
indices = np.random.choice(len(self), batch_size, p=probs)
weights = (len(self) * probs[indices]) ** (-self.beta)
return self._encode_sample(indices), indices, weights这里的优先级计算不是简单的绝对值,而是加了个0.00001的保底值,防止某些经验被永久遗忘。权重计算时那个(len(self)*probs)^-beta的骚操作,其实是在做重要性采样修正,避免高优先级样本主导训练过程。
来看动态规划环境里的一段动作空间处理:
class DynamicPathPlanning(gym.Env):
def _normalize_action(self, action):
steering = 2 * (action[0] - 0.5) # 映射到[-1,1]
throttle = action[1] * self.max_throttle
return np.array([steering, throttle])这个归一化操作暴露了工程师的小心机:把[0,1]区间的输出掰成对称的[-1,1]转向控制。油门处理更直接,直接用乘法保留原始比例。注意这里没有用更复杂的缩放方式,毕竟强化学习对动作空间的敏感度比我们想象的要糙得多。
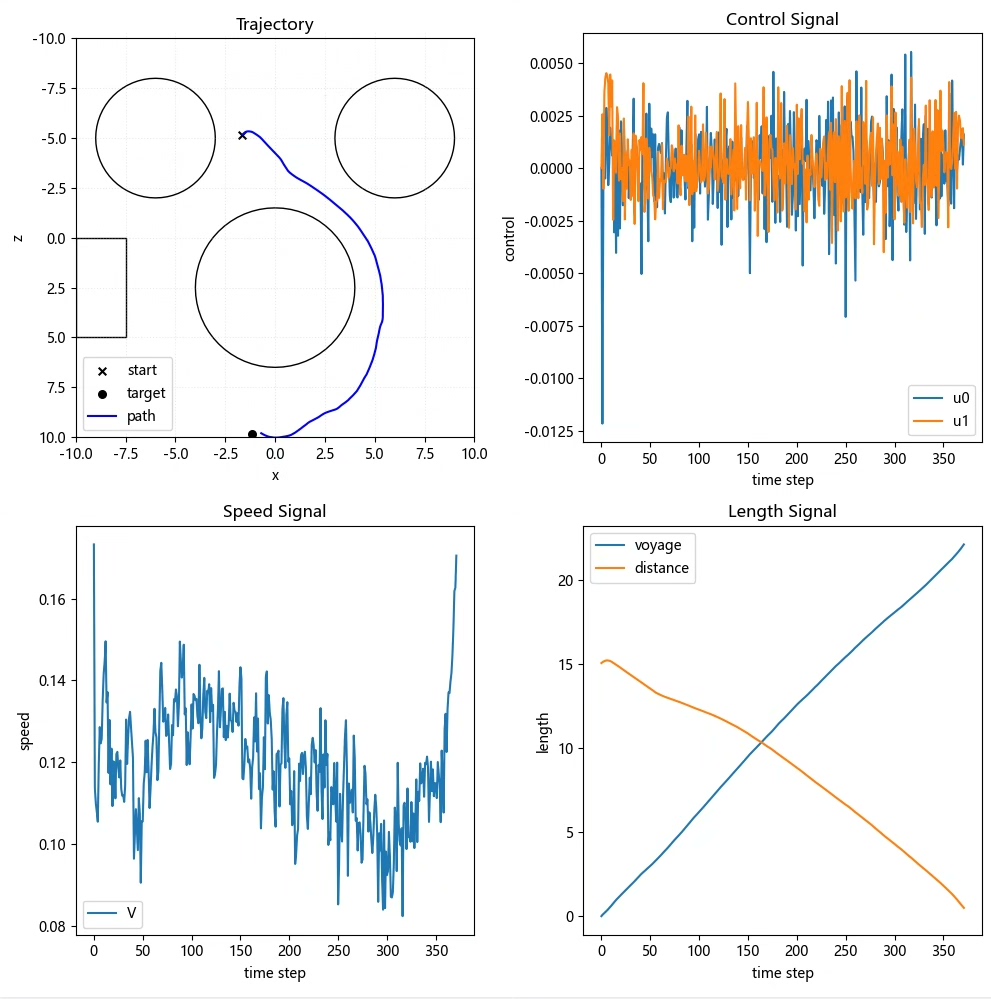
最后展示一个训练循环中的彩蛋:
for episode in range(1000):
obs = env.reset()
while not done:
action = agent.sample_action(obs) # 带探索的动作采样
next_obs, reward, done, _ = env.step(action)
buffer.store(obs, action, reward, next_obs, done)
if len(buffer) >= batch_size:
batch = buffer.sample(batch_size)
agent.update(batch) # 这里藏着策略熵的自动调节魔法这个训练循环看似平平无奇,但注意sample_action方法里内置的探索策略——SAC-Auto会自动根据当前策略的不确定性调整探索强度。当算法越来越自信时,探索幅度会自然衰减,这种自适应的特性比硬编码的ε-greedy高明得多。
在仓库的测试案例中,经过训练的智能体能在包含移动障碍物的场景里走出s型路线。有意思的是当遭遇突发障碍时,策略网络会突然增大动作熵值,表现出类似人类驾驶员的"犹豫"特性,这种动态不确定性调节正是SAC系列算法的精髓所在。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)