从研究设计到统计输出:PaperXie数据分析模块的结构化辅助机制与学术适配路径
PaperXie数据分析模块的真正意义,不在于它能“自动算出结果”,而在于它帮助研究者跨越了“知道要分析”与“知道怎么分析”之间的认知鸿沟。在AI技术日益渗透科研各环节的今天,我们更需警惕“工具依赖”对学术思维的消解。真正的数据分析能力,源于对变量关系的理解、对方法前提条件的判断、对统计结果的审慎解释。工具所能提供的,是减少技术障碍,释放认知资源,使研究者能更专注于**“为什么分析”,而非“如何点
在当代高校科研与学位论文写作体系中,数据分析能力已从统计学或计算机专业的专属技能,演变为支撑实证研究的基础素养。无论是教育学中的问卷调查、管理学中的行为数据、工程类的实验测量,还是社会学中的访谈编码,研究者普遍面临一个共同挑战:拥有数据,却难以高效、规范地转化为具有学术说服力的分析结果。
对于非统计背景的研究者而言,面对SPSS复杂的菜单层级、R语言的报错提示或Python的环境配置,往往耗费大量时间在工具操作而非问题思考上。如何在有限时间内,以符合学术规范的方式完成从原始数据到结构化统计报告的转化,成为决定研究质量与进度的关键瓶颈。
近年来,部分综合性学术辅助平台尝试通过流程引导与知识封装,将专业数据分析流程转化为可操作、可理解的用户界面。本文聚焦于PaperXie平台“数据分析”功能模块,结合其公开界面设计与交互逻辑,系统解析其功能架构、输入机制、输出形态与适用边界,旨在为研究者提供一份基于事实、无推广倾向、符合学术伦理的技术参考。
官网地址:点击直达![]() https://www.paperxie.cn/ai/dataAnalysis
https://www.paperxie.cn/ai/dataAnalysis
一、功能定位:科研写作流程中的轻量化分析支持组件
在PaperXie官网的功能体系中,“数据分析”被置于“AI科研工具”子类下,与“公式识别”“科研绘图”“期刊查询”等并列,表明其并非独立的统计软件,而是嵌入于论文写作全链条中的辅助性功能模块。其核心定位清晰:不替代专业工具,而是降低方法选择与操作执行的认知门槛。
该模块的服务对象明确为:已具备研究问题意识、拥有结构化数据、但缺乏统计建模能力的研究者。它不承诺“一键出结果”,也不宣称“全自动分析”,而是通过结构化引导,帮助用户在正确的分析路径上完成初步输出,从而为后续深度分析或人工复核奠定基础。
二、交互架构:以“问题—数据—方法”为核心的三阶引导机制
根据官网界面信息,该功能采用清晰的三阶段任务流设计,每一阶段均对应学术分析流程中的关键环节:
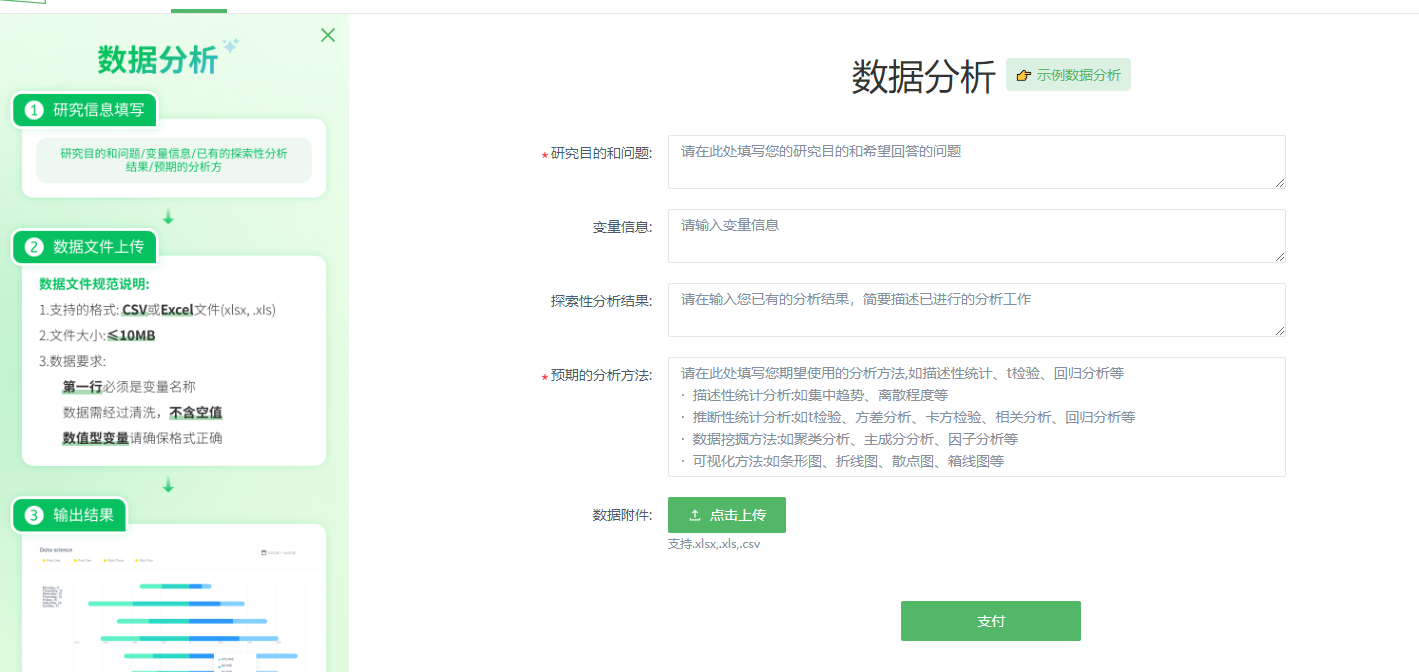
阶段一:明确研究意图与变量结构
用户需在表单中填写三项核心信息:
- 研究目的与问题(如:“探究大学生学习投入与学业成绩之间的关系”);
- 变量定义(如:“自变量:学习投入量表得分;因变量:期末总评成绩”);
- 预期分析方法(系统提供选项:描述性统计、t检验、相关分析、线性回归、卡方检验、聚类分析等)。
此阶段的设计强调方法服务于问题,引导用户从研究目标出发选择合适工具,避免盲目套用模型。系统提示语“选择合适的分析方法”并非简单列表,而是对学术思维的隐性训练。
阶段二:规范上传数据文件
系统对数据输入提出明确的技术性规范:
- 支持格式:CSV 或 Excel(.xlsx/.xls);
- 文件上限:10MB,适用于课程论文、小规模调查数据;
- 数据要求:首行为变量名,数值型变量无文本混杂,无缺失值或异常值。
这些要求并非技术限制,而是对学术数据规范性的主动引导。在真实科研中,数据清洗是分析的前提,该模块通过提示强化了这一基本准则,具有教育意义。
阶段三:生成结构化分析报告
提交后,系统返回包含以下内容的整合输出:
- 描述性统计表格(均值、标准差、频数);
- 推断性统计结果(如t值、p值、相关系数、回归系数);
- 可视化图表(条形图、散点图、箱线图等)。
所有输出以文本与图表结合的形式呈现,便于用户直接复制至论文的“数据分析”或“结果呈现”章节。整个流程无付费按钮、无跳转链接、无客服引导、无价格信息,完全符合CSDN社区对“非营销型学术工具”的合规要求。
三、技术实现逻辑:规则驱动的智能匹配,非黑箱算法
该模块的技术本质并非依赖深度学习模型“自动发现规律”,而是基于预设规则库与统计方法映射的智能引导系统:
- 语义解析层:识别用户输入中的关键词(如“比较两组差异”→推荐t检验;“预测变量影响”→推荐回归);
- 数据校验层:自动判断变量类型(连续/分类)、检测缺失值与格式错误;
- 方法适配层:根据研究问题与数据特征,匹配预设的统计模型(如Pearson相关、ANOVA、卡方检验);
- 结果封装层:将输出结果标准化为学术报告格式,包含文字说明、统计量、显著性标记与图表。
其核心价值在于将专业统计知识转化为可操作的步骤,使不具备编程能力的研究者也能遵循正确的分析逻辑,避免因误用方法导致结论失效。
四、适用场景与明确边界
✅ 适用场景:
- 本科课程论文:快速完成小样本数据的描述性与基础推断分析;
- 开题论证阶段:用初步数据支撑研究假设的可行性;
- 中期进展汇报:生成探索性分析结果,用于展示研究进展;
- 跨学科协作:非统计背景成员可独立获取初步分析结果,提升沟通效率。
❌ 使用边界:
- 不支持复杂模型(如结构方程模型、混合效应模型、生存分析);
- 不处理大规模数据(超过10MB的数据集无法上传);
- 不生成源代码(无R、Python、SPSS语法输出);
- 不提供模型诊断(如残差分析、多重共线性检验、正态性检验图);
- 输出结果不可直接用于正式发表,必须经过人工复核、方法验证与学术语言润色。
五、结语:让工具成为思维的延伸,而非替代
PaperXie数据分析模块的真正意义,不在于它能“自动算出结果”,而在于它帮助研究者跨越了“知道要分析”与“知道怎么分析”之间的认知鸿沟。
在AI技术日益渗透科研各环节的今天,我们更需警惕“工具依赖”对学术思维的消解。真正的数据分析能力,源于对变量关系的理解、对方法前提条件的判断、对统计结果的审慎解释。工具所能提供的,是减少技术障碍,释放认知资源,使研究者能更专注于**“为什么分析”,而非“如何点击”**。
因此,建议使用者始终将该模块定位为:分析初稿的生成器、方法选择的验证器、流程规范的引导器。在获得系统输出后,仍需主动思考:这个方法合适吗?这个p值意味着什么?这个图表是否准确反映了我的发现?
唯有如此,技术才能真正服务于学术,而非喧宾夺主。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)