拒绝“人工智障”:构建高可靠 AI Agent 任务规划(Planning)系统的核心路径
【摘要】解析从模糊意图到精准落地的全链路机制,揭秘感知、规划与反思闭环构建之道。
【摘要】解析从模糊意图到精准落地的全链路机制,揭秘感知、规划与反思闭环构建之道。

在当下的技术浪潮中,大模型(LLM)展现出的对话能力令人惊叹,但一旦涉及具体业务流程的执行,许多所谓的“智能体”立刻暴露出“人工智障”的一面。用户说“帮我处理下昨天的异常订单”,Agent 可能会胡乱回复一通安慰的话,或者机械地询问订单号,甚至直接调用错误的接口导致数据污染。
核心症结在于,从自然语言的“模糊意图”到计算机可执行的“确定性指令”之间,存在巨大的逻辑鸿沟。构建一个真正可用的 AI Agent,绝不是写几句 Prompt 那么简单。它本质上是一个复杂的系统工程,需要将 LLM 的概率性生成能力,约束在确定性的业务逻辑框架内。
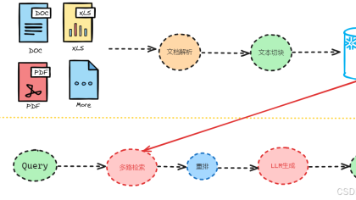
作为架构师,我们需要关注的焦点不再是模型参数有多大,而是如何构建一套稳健的任务规划(Planning)系统。这套系统需要具备全域感知能力、科学的任务拆解逻辑、实时的执行监控以及完善的人机协同机制。只有打通了“感知—规划—执行—反思”的闭环,Agent 才能从玩具变成生产力工具。
🧩 一、 全域感知:打破“文本框”的幻觉

很多开发者对 Agent 的理解还停留在“Chatbot + Tools”的层面,认为用户的输入仅仅是对话框里的文字。在真实的业务场景中,仅靠文本信息往往无法还原需求全貌,导致后续任务拆解方向性错误。
1.1 多模态数据的工程化融合
Agent 的“感官”必须延伸到业务系统的每一个角落。一个合格的企业级 Agent,其输入端应当是一个多源异构的数据聚合器。
我们需要处理的数据类型远超文本范畴:
-
非结构化交互数据:用户的语音指令、上传的图片(如设备报错截图)、历史对话记录。
-
结构化业务数据:ERP 中的订单状态、CRM 中的客户画像、WMS 中的实时库存。
-
时序传感数据:IoT 设备上报的温湿度、振动频率、服务器的 CPU 负载日志。
数据融合架构设计
在架构层面,我们需要在 Agent 前端部署一个上下文管理器(Context Manager)。它的职责不是简单地拼接字符串,而是进行数据的清洗、对齐和向量化。
|
数据源类型 |
处理策略 |
关键技术点 |
|---|---|---|
|
语音流 |
ASR + 情感分析 |
识别语调中的急迫感(如愤怒、焦急),作为任务优先级排序的依据。 |
|
业务日志 |
结构化提取 |
通过 SQL/API 预查询,将“昨天的订单”转化为具体的 |
|
环境感知 |
阈值触发 |
设定规则引擎,当温度 > 80℃ 时,自动将上下文标记为“紧急故障”。 |
例如,连锁超市的“库存预警 Agent”在接收到客服发来的“催货”语音时,后台会同步拉取该门店的实时库存水位和物流车辆的 GPS 位置。只有将这些多维数据融合,Agent 才能判断是“立即调货”还是“安抚客户”。
1.2 意图识别与参数提取的分离设计
初级开发者喜欢让 LLM 一次性输出意图和参数,这在复杂场景下极易出错。更稳健的做法是将**意图识别(Intent Recognition)和槽位填充(Slot Filling)**解耦。
第一步:意图分类(Classification)
先解决“要做什么”的问题。不要让 LLM 发散生成,而是让它在预定义的意图集合中做选择。对于高频场景,甚至可以先用轻量级的 BERT 模型或向量相似度检索(RAG)来匹配意图,既快又准。
第二步:关键参数提取(Extraction)
确定意图后,再针对该意图所需的 Schema 进行参数提取。这里需要引入**约束性解码(Constrained Decoding)**技术,强制 LLM 输出符合 JSON Schema 的格式,而不是自然语言。
json:
// 错误示例:让 LLM 自由发挥
"User": "帮我订明天去上海的票"
"Agent": "好的,已为您查询到..." // 缺乏关键信息,无法执行
// 正确架构:Schema 驱动
{
"intent": "book_flight",
"slots": {
"destination": "Shanghai",
"date": "2023-10-27",
"origin": null // 识别到缺失
},
"missing_slots": ["origin"]
}
1.3 主动澄清与歧义消除机制
用户永远不会像程序员那样说话。他们会说“那个”、“以前那样”、“不行就换一个”。Agent 必须具备反思性追问的能力。
当检测到 missing_slots 不为空,或者意图置信度低于阈值(例如 0.7)时,系统应强制挂起当前任务,进入“澄清模式”。
-
基于上下文的推断:用户说“预算不超过 1000”,Agent 需回溯上一轮对话,确认是指“机票”还是“酒店”。
-
场景化追问:在售后界面听到“东西有问题”,Agent 不应询问“您想买什么”,而应优先通过 UI 引导用户选择“退货”或“换货”。
这种机制能有效防止 Agent 在信息不足的情况下“瞎猜”并执行错误操作,这是保障系统可靠性的第一道防线。
🛠️ 二、 核心规划:四种拆解范式的工程化落地
理解了需求,接下来就是 Agent 的大脑——规划层(Planning Layer)。这是将非结构化需求转化为可执行函数调用链的关键步骤。
在实战中,不存在一种万能的拆解方法。成熟的架构会根据任务的确定性和复杂度,动态路由到以下四种拆解范式。
2.1 自上而下(Top-Down):思维链(CoT)模式
适用场景:目标明确、逻辑线性、步骤之间存在强依赖关系的任务。例如:订机票、数据报表生成。
技术实现逻辑
这本质上是**思维链(Chain of Thought)**技术的工程化应用。我们需要在 System Prompt 中植入“分解—执行”的元指令。
Agent 会像剥洋葱一样,从最终目标倒推前置条件:
-
Goal: 订购北京到上海的机票。
-
Sub-task 1: 查询航班(依赖:日期、起降地)。
-
Sub-task 2: 筛选航班(依赖:用户偏好、价格)。
-
Sub-task 3: 锁定座位(依赖:航班号、乘客信息)。
-
Sub-task 4: 支付出票(依赖:支付渠道)。
工程难点:上下文窗口的限制。如果任务链过长,LLM 容易遗忘早期的约束条件。
解决方案:引入**暂存器(Scratchpad)**机制。每完成一个子任务,将关键输出(如 flight_id)写入独立的内存块,后续步骤只读取内存块,而非依赖长文本历史。
2.2 模板化拆解(SOP):标准作业程序的复用
适用场景:高频、高合规要求、容错率低的企业级流程。例如:员工入职办理、财务报销审批、贷款审核。
技术实现逻辑
对于这类场景,让 LLM 每次都重新推理步骤是极大的资源浪费,且伴随着巨大的合规风险。正确的做法是SOP(Standard Operating Procedure)实例化。
架构师需要预先定义好 XML 或 JSON 格式的任务模板库:
xml:
<template id="loan_approval">
<step id="1" tool="verify_identity" required="true" />
<step id="2" tool="check_credit_score" required="true" />
<step id="3" tool="calculate_limit" logic="script_v2" />
<step id="4" tool="human_review" condition="amount > 50000" />
</template>
当 Agent 识别到意图为“贷款申请”时,它不再进行生成式规划,而是直接加载该模板。LLM 的工作退化为“填空题”——将用户输入的信息填入模板的参数槽位中。
这种方法将 AI 的不确定性降到了最低,是 B 端业务落地的首选方案。
2.3 自下而上(Bottom-Up):信息归纳与聚合
适用场景:需求模糊、零散、探索性的任务。例如:“帮我分析一下为什么最近客户投诉变多了”、“给年轻人做一个短视频营销方案”。
技术实现逻辑
用户自己都不知道具体步骤,Agent 无法直接拆解。此时需要采用归纳推理策略。
-
信息收集阶段:Agent 先不急着行动,而是生成一系列查询动作。
-
查询近 7 天投诉日志。
-
提取高频关键词。
-
对比历史同期数据。
-
-
模式识别阶段:将收集到的碎片信息扔回给 LLM,要求其进行聚类分析。
-
发现 80% 的投诉集中在“物流延迟”。
-
-
任务生成阶段:基于归纳出的核心问题,反向生成执行计划。
-
生成任务:联系物流供应商 -> 优化发货路由 -> 发送安抚短信。
-
这种方式模拟了人类专家的“调研—诊断—处方”过程,是从混乱中建立秩序的关键。
2.4 经验驱动(Experience-Based):动态强化学习
适用场景:环境动态变化、规则极其复杂且难以穷举的场景。例如:供应链动态调度、IT 运维故障排查、游戏 AI。
技术实现逻辑
这是目前最前沿的方向,结合了**思维树(Tree of Thoughts, ToT)和强化学习(RL)**的思想。
Agent 维护一个经验库(Experience Memory),存储了历史上的成功路径和失败教训。
-
冷启动:Agent 尝试标准路径“重启服务”。
-
反馈循环:如果重启失败,Agent 检索经验库,发现“上次类似报错是因为磁盘满了”。
-
动态调整:Agent 放弃原计划,动态插入“清理磁盘日志”的步骤。
-
知识沉淀:任务完成后,将本次的“故障特征—解决路径”对写入向量数据库,供下次调用。
这种机制让 Agent 具备了“成长性”,随着使用次数的增加,其拆解任务的准确率会呈指数级上升。
⚙️ 三、 决策与工具编排:保证“拆得出”也“做得成”

拆解出任务只是第一步,如果无法落地执行,Agent 就成了“纸上谈兵”。这一层面的核心在于工具绑定(Tool Binding)与多智能体协作(Multi-Agent Collaboration)。
3.1 原子能力的标准化封装
Agent 调用的每一个工具(Tool)或 API,都必须经过严格的标准化封装。不要直接把原始的 Swagger 文档扔给 LLM,那会导致极高的错误率。
工具描述的艺术
我们需要为每个工具编写“说明书”,包含三个核心要素:
-
功能描述(Description):用自然语言清晰描述“这个工具能干什么,不能干什么”。
-
参数约束(Schema):明确参数类型、枚举值、是否必填。
-
副作用声明(Side Effects):明确该操作是否会修改数据(如写库、发邮件),这对于风控至关重要。
接口适配层
在 Agent 和业务系统之间,必须存在一个适配层(Adapter Layer)。
-
输入适配:将 LLM 生成的 JSON 转换成业务系统需要的 gRPC 或 REST 请求。
-
输出适配:业务接口往往返回几千行的 JSON,直接喂给 LLM 会撑爆 Context Window。适配层需要对返回结果进行裁剪,只保留关键字段(如
status,error_msg,result_summary)。
3.2 复杂任务的分治:多 Agent 协作模式
当任务复杂度超过单个 LLM 的推理极限时,单体 Agent 必然会产生幻觉。此时必须引入多智能体架构。
总控-分发模式(Manager-Worker)
-
总控 Agent(Planner):只负责拆解任务,不负责执行。它将大任务拆解为子任务,并分发给垂直领域的专家 Agent。
-
专家 Agent(Worker):
-
采购 Agent:专精于比价、下单、供应商管理。
-
物流 Agent:专精于路线规划、运单追踪。
-
财务 Agent:专精于预算审核、支付结算。
-
状态同步机制
多 Agent 协作最大的难点在于信息孤岛。我们需要构建一个共享黑板(Shared Blackboard)或消息总线。
当“采购 Agent”完成下单后,它不仅要向“总控”汇报,还要将订单信息写入共享黑板。“物流 Agent”订阅了黑板消息,一旦监测到新订单,自动触发发货流程。
这种解耦设计极大地提升了系统的稳定性和可维护性。某个环节出错,只会影响局部,而不会导致整个任务链崩溃。
🛡️ 四、 实时保障与偏差纠正:构建“反思”闭环
在 Agent 执行任务的过程中,唯一不变的就是“变化”。网络超时、库存不足、用户改主意,这些都是常态。如果没有实时监控和纠偏机制,Agent 就是一颗定时炸弹。
4.1 可观测性体系(Observability)的建立
我们需要像监控微服务一样监控 Agent。除了常规的延迟和吞吐量,还需要关注 Agent 特有的指标:
-
任务完成率(Success Rate):最终目标达成的比例。
-
步骤遵循率(Adherence Rate):实际执行路径与 SOP 模板的重合度。
-
幻觉率(Hallucination Rate):调用了不存在的工具或捏造了参数的次数。
-
人机接管率(Takeover Rate):用户因不满意而转人工的比例。
这些指标应当实时展示在 DashBoard 上,作为优化 Prompt 和微调模型的依据。
4.2 动态重规划(Re-Planning)机制
当执行过程中遇到异常(Exception)或负反馈(Negative Feedback)时,Agent 必须触发重规划流程。
场景推演:
-
原计划:查库存 -> 锁定库存 -> 支付。
-
执行异常:在“锁定库存”步骤,API 返回“库存不足”。
-
错误做法:Agent 机械重试,或者直接报错退出。
-
正确做法(重规划):
-
捕获错误码
INSUFFICIENT_STOCK。 -
Agent 暂停当前 Pipeline。
-
读取上下文,发现用户需求是“急用”。
-
生成新计划:查询临近门店库存 -> 申请调货 -> 修改发货地 -> 支付。
-
这种**自我修正(Self-Correction)**能力,是区分“脚本”和“智能体”的分水岭。
4.3 需求变更的自适应处理
用户在任务执行中途变更需求是极高频的场景。
用户:“帮我订周三的票……哎等等,周三我有事,改周五吧。”
如果 Agent 继续执行周三的订票流程,就是严重的体验事故。
系统需要具备中断与状态回滚能力:
-
监听层:实时分析用户的新指令,检测到“意图变更”信号。
-
控制层:立即向执行器发送
SIGINT信号,终止正在进行的 API 调用。 -
数据层:回滚已锁定的资源(如释放座位)。
-
规划层:保留用户的身份信息(复用),仅更新时间参数,重新生成任务链。
👮 五、 人机协同与风控:最后的安全防线

无论 AI 多么智能,在涉及资金、隐私、物理世界操作(如控制机械臂)等高风险领域,绝对不能让 AI “裸奔”。
5.1 风险分级与审批流
我们需要建立一套风险控制矩阵。
|
风险等级 |
操作示例 |
介入策略 |
|---|---|---|
|
低风险 |
查询天气、搜索文档 |
全自动:Agent 自主决策执行。 |
|
中风险 |
发送邮件、修改非关键配置 |
事后通知:Agent 执行后发送通知给人类。 |
|
高风险 |
大额转账、删除数据库、停机 |
人机协同(HITL):Agent 生成方案,暂停挂起,等待人工点击“确认”后方可执行。 |
5.2 异常模式熔断
除了针对特定操作的风控,还需要针对行为模式的风控。
如果一个 Agent 在 1 分钟内连续调用了 50 次“查询用户信息”接口,或者尝试访问其权限范围之外的数据,风控系统应立即触发熔断机制,强制下线该 Agent 实例,并报警给安全团队。
5.3 隐性知识的沉淀
人机协同不仅是为了风控,更是为了教学。
当 Agent 遇到搞不定的复杂情况转交给人工处理时,系统应自动记录人工的操作步骤。
例如,人工客服在处理“特殊退款”时,先查了 A 系统,又打了 B 电话,最后在 C 系统录入。
这些操作日志经过脱敏和结构化处理后,可以作为微调数据(Fine-tuning Data)或少样本提示(Few-shot Prompts)喂回给 Agent。
下一次,Agent 就能学会这个“特殊流程”。这就是从人工兜底到 AI 进化的闭环。
🚀 六、 典型场景实战复盘
为了更直观地理解上述理论,我们来看三个不同领域的实战案例。
6.1 航旅预订:并行规划与事务一致性
用户需求:“订下周三广州到成都的机票,再订机场附近含早餐、距离不超过3公里的酒店。”
拆解与执行要点:
-
感知:识别出复合意图
[book_flight, book_hotel]。提取公共参数(时间:下周三,地点:成都)。 -
规划:采用并行拆解。
-
线程 A(机票 Agent):查航班 -> 选航班。
-
线程 B(酒店 Agent):基于机场坐标做 GIS 检索(<3km) -> 筛选含早 -> 比价。
-
-
约束处理:酒店的时间依赖于航班的到达时间。因此,线程 B 必须等待线程 A 确定航班落地时间后,才能最终锁定入住日期。
-
事务性:在支付环节,必须向用户展示“机酒打包方案”,用户确认后,原子性地提交两个订单。如果酒店预订失败,机票也应提示用户是否继续。
6.2 工业设备维护:时效性与多源数据
用户需求:“工厂机床有异响,明天要生产,得赶紧修。”
拆解与执行要点:
-
感知:关键词“异响”(故障特征)、“明天生产”(高优先级)、“赶紧”(时效要求)。
-
规划:采用经验驱动拆解。
-
调用“故障诊断 Agent”,分析声纹数据,初步判定为“主轴轴承磨损”。
-
调用“库存 Agent”,查询轴承备件。
-
分支判断:
-
若有库存 -> 生成维修工单 -> 调度维修工。
-
若无库存 -> 触发“紧急采购流程” -> 预估到货时间 -> 调整明日生产计划。
-
-
-
风控:修改生产计划属于高风险操作,Agent 生成建议方案后,推送给厂长手机端等待审批。
6.3 客户服务:非标流程的合规化
用户需求:“上周买的衣服不合适想退,找不到订单号了,退款要快点,我急用。”
拆解与执行要点:
-
感知:意图“退货”。难点:缺失
order_id,有情感诉求“急用”。 -
规划:采用动态归纳拆解。
-
补全信息:插入步骤“反查订单”。调用 CRM 接口,通过用户手机号 + “上周” + “衣服”模糊检索订单。
-
流程变体:识别到“急用”,在生成退款单时,自动标记
priority=HIGH。 -
合规检查:检查订单是否满足“7天无理由”。
-
-
执行:展示检索到的订单供用户确认 -> 发起退货 -> 触发极速退款通道。
🧩 七、 进阶技术:让 Agent 更聪明的算法与架构

在掌握了基础的拆解范式后,为了应对更极端的业务挑战,我们需要引入一些进阶的算法思想和架构模式。这些技术点往往是区分普通 Agent 和高级 Agent 的分水岭。
7.1 动态思维树(ToT)的代码实现逻辑
前文提到了思维树(Tree of Thoughts),这在解决需要“探索”和“回溯”的复杂任务时极其有效。不同于思维链(CoT)的一条道走到黑,ToT 允许 Agent 在每一步生成多个可能的解决方案,并自我评估,选择最优路径继续,甚至在发现死胡同后回退。
伪代码实现逻辑
我们可以用 Python 的类结构来模拟这个过程:
python:
class ThoughtNode:
def init(self, state, parent=None):
self.state = state # 当前任务状态
self.parent = parent
self.children = []
self.score = 0.0 # 自我评估得分
def evaluate(self, llm_evaluator):
"""调用LLM评估当前状态的可行性"""
self.score = llm_evaluator.score(self.state)
class ToTAgent:
def solve(self, initial_problem):
root = ThoughtNode(initial_problem)
frontier = [root] # 待探索的节点集合
while frontier:
# 1. 扩展:对当前最优节点生成多个可能的下一步
current_node = self.select_best(frontier)
if self.is_goal(current_node):
return self.trace_back(current_node)
possible_steps = self.llm_generator.generate_steps(current_node.state, n=3)
# 2. 评估:对每个新步骤打分
for step in possible_steps:
child = ThoughtNode(step, parent=current_node)
child.evaluate(self.llm_evaluator)
# 剪枝:如果得分太低,直接丢弃
if child.score > 0.6:
current_node.children.append(child)
frontier.append(child)
# 3. 移除已探索节点
frontier.remove(current_node)
return "No solution found"
应用场景:
比如在代码生成 Agent 中,用户要求“写一个贪吃蛇游戏”。
-
路径 A:使用 Pygame 库(得分 0.9,继续)。
-
路径 B:使用 Tkinter 库(得分 0.7,备选)。
-
路径 C:使用 C++ 编写并通过 Python 调用(得分 0.3,剪枝,太复杂且易错)。
Agent 会优先沿着路径 A 拆解任务。如果在安装 Pygame 依赖时发现环境不支持,它会自动回溯,切换到路径 B 继续尝试。这种机制极大地提高了任务的成功率。
7.2 记忆机制(Memory)的工程化设计
一个优秀的 Agent 必须“记性好”。记忆不仅仅是把历史对话塞进 Prompt,它需要分层设计。
记忆分层架构
|
记忆类型 |
存储介质 |
生命周期 |
作用 |
|---|---|---|---|
|
短期记忆 (Short-term) |
短期记忆 (Short-term) |
内存 / Redis |
保持多轮对话的上下文连贯性,如“上一步查到的航班号”。 |
|
长期记忆 (Long-term) |
向量数据库 (Vector DB) |
永久 |
存储用户偏好(如“不吃辣”)、历史成功案例、企业知识库。 |
|
工作记忆 (Working) |
Scratchpad (临时变量) |
任务执行期 |
存储当前任务链的中间状态,如 |
检索增强生成(RAG)在规划中的应用
在拆解任务时,Agent 应先查询长期记忆。
例如,用户说“帮我写周报”。
-
检索:Agent 去向量库检索该用户过去 5 次的周报。
-
学习:发现用户习惯用“本周工作、下周计划、风险点”的三段式结构。
-
规划:基于这个结构拆解任务,而不是使用通用的周报模板。
这种“千人千面”的任务拆解,完全依赖于记忆系统的构建。
7.3 提示词工程(Prompt Engineering)的高级模式
在 System Prompt 中,我们需要显式地定义 Agent 的思考框架。单纯说“你是一个助手”是不够的,我们需要使用 ReAct (Reasoning + Acting) 模式。
ReAct Prompt 模板示例
你是一个专业的任务拆解专家。对于用户的请求,你必须严格遵守以下格式进行回复:
Question: <用户输入>
Thought: <思考当前需要做什么,分析依赖关系>
Action: <调用工具,格式为 ToolName(param=value)>
Observation: <工具返回的结果>
... (重复 Thought/Action/Observation 直到任务完成)
Final Answer: <给用户的最终回复>示例:
Question: 查一下北京明天的天气,如果是雨天,帮我买一把伞送到公司。
Thought: 我需要先查询天气,根据结果决定是否买伞。
Action: WeatherAPI(city="Beijing", date="tomorrow")
Observation: {"weather": "Heavy Rain", "temp": "15C"}
Thought: 天气是大雨,满足买伞条件。我需要查询电商平台的雨伞。
Action: ShoppingAPI(keyword="umbrella", sort="sales")
...
通过强制 Agent 输出 Thought 字段,我们实际上是在强迫模型进行“慢思考”,这能显著减少逻辑跳跃错误。
📉 八、 避坑指南:那些年我们踩过的 Agent 研发大坑
在实际落地过程中,有无数的细节可能导致项目失败。以下是基于血泪经验总结的避坑指南。
8.1 避免“大包大揽”的上帝 Agent
误区:试图做一个全能 Agent,既能写代码,又能订外卖,还能修电脑。
后果:Prompt 过长,注意力分散,指令遵循能力直线下降,甚至出现严重的幻觉。
对策:专人专事(Specialization)。
将大 Agent 拆分为多个小 Agent。
-
CodingAgent:只加载编程相关的 Prompt 和工具。 -
LifeAgent:只加载生活服务类的工具。 -
RouterAgent:作为入口,只负责分发任务,不负责具体执行。
8.2 警惕 JSON 格式不稳定的噩梦
误区:认为 LLM 每次都能完美输出标准的 JSON。
后果:LLM 经常会少写一个括号,或者在 JSON 里写注释,导致解析器崩溃。
对策:
-
鲁棒的解析器:使用
json_repair等库,能自动修复轻微的格式错误。 -
重试机制:解析失败时,将错误信息(如
JSONDecodeError: Expecting value)喂回给 LLM,让它自己修正(Self-Correction)。通常重试 1 次就能解决问题。 -
使用 Function Calling:OpenAI 等模型原生的 Function Calling 功能比纯 Prompt 生成 JSON 稳定得多,应优先使用。
8.3 别忽视了“无解”的情况
误区:假设所有任务都是可完成的。
后果:用户问“如何制造原子弹”,Agent 还在努力拆解步骤,最后触发安全拦截,或者一本正经地胡说八道。
对策:在规划阶段引入可行性评估。
如果意图识别为非法、违规或超出能力范围(如“帮我预测下期彩票”),Agent 应直接拒绝,而不是尝试拆解。
Prompt 中应加入指令:“如果你无法完成任务,或任务缺乏必要条件且无法通过追问获取,请直接回复无法处理,并说明原因。”
🔮 九、 未来展望:Agent 的进化方向

AI Agent 技术正处于爆发前夜,未来的演进方向将更加激动人心。
9.1 从“被动响应”到“主动服务”
目前的 Agent 大多是等待用户发指令。未来的 Agent 将具备主动性(Proactivity)。
-
场景:Agent 监控到服务器 CPU 持续飙高。
-
行动:它不需要运维人员下令,而是主动分析日志,发现是某个进程死锁,然后主动弹窗给管理员:“检测到异常进程,建议重启服务,是否执行?”
9.2 端侧 Agent 的崛起
随着手机和 PC 算力的提升,轻量级模型(如 7B、3B 参数)将直接运行在端侧。
-
隐私保护:处理个人相册、聊天记录时,数据不出端。
-
零延迟:无需网络请求,操作系统的响应速度极快。
-
系统级控制:Agent 将深度集成到 OS 中,直接操作 GUI,真正实现“动口不动手”。
9.3 群体智能(Swarm Intelligence)
不是几个 Agent 协作,而是成百上千个微型 Agent 像蚁群一样工作。
-
软件开发:100 个 Coding Agent 同时修改 100 个文件,进行大规模重构。
-
网络安全:成千上万个 Security Agent 模拟黑客攻击,进行全方位的渗透测试。
📝 十、 总结与行动建议
构建一个高可靠的 AI Agent 任务规划系统,是一场从“不确定性”向“确定性”的远征。
我们回顾一下核心路径:
-
感知层:用多模态融合和意图分离,确保“听得懂”。
-
规划层:用 CoT、SOP、ToT 等算法,确保“想得清”。
-
执行层:用工具封装和多 Agent 协作,确保“干得动”。
-
保障层:用可观测性和人机协同,确保“不出事”。
给开发者的行动建议:
-
不要迷信模型能力:GPT-4 也不是万能的。多花时间在数据清洗、Prompt 优化和流程编排上,这些工程化工作的 ROI 远高于频繁更换模型。
-
从垂直场景切入:不要一开始就做通用助理。先做一个“完美的请假助手”或“无敌的 SQL 生成器”,跑通闭环后再扩展。
-
重视数据闭环:上线不是结束,而是开始。收集用户的真实交互数据(特别是失败案例),清洗后用于微调模型,这是建立技术壁垒的唯一途径。
AI Agent 的时代已经到来,希望每一位架构师和开发者都能在这场变革中,构建出真正改变世界的智能系统。
📢💻 【省心锐评】
别让 Agent 裸奔,给它装上“记忆”的硬盘、“反思”的镜子和“风控”的刹车,它才能在业务的高速公路上安全驾驶。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献356条内容
已为社区贡献356条内容

所有评论(0)