小红书团队X人大最新论文精读-DeepAgent:一个具备可扩展工具集的通用推理智能体
图 3:DeepAgent 框架概览。主推理模型能够自主地发现工具、执行动作,并折叠先前记忆,以结构化记忆重新开始——这一切都在统一的思维过程中完成。DeepAgent 通过 ToolPO 进行端到端训练,这是一种强化学习方法,利用工具模拟器来模拟大规模真实世界的工具 API,并通过精细化的优势归因,对最终任务成功以及中间工具调用的正确性进行奖励。如图 3 所示,DeepAgent 框架的整体架构
摘要
大型推理模型(Large Reasoning Models)已展现出强大的问题解决能力,但现实世界的任务往往需要借助外部工具并进行长时序交互。现有的智能体(agent)框架通常遵循预定义的工作流程,这限制了其自主性和对全局任务的完成能力。
本文提出 DeepAgent—— 一种端到端的深度推理智能体,能够在单一、连贯的推理过程中实现自主思考、工具发现与行动执行。针对长时序交互中多次工具调用与交互历史累积导致的上下文长度爆炸问题,本文提出了一种自主记忆折叠机制(autonomous memory folding mechanism),该机制将过去的交互压缩为结构化的情景记忆(episodic memory)、工作记忆(working memory)与工具记忆(tool memory),从而在保留关键信息的同时减少错误积累。
为了高效且稳定地教会模型使用通用工具,本文提出了一种端到端强化学习策略 —— ToolPO。该方法利用由大语言模型(LLM)模拟的 API 环境,并通过工具调用优势归因(tool-call advantage attribution),为工具调用相关的标记(tokens)分配细粒度的奖励信号。
在八个基准测试上进行的广泛实验(包括通用工具使用任务:ToolBench、API-Bank、TMDB、Spotify、ToolHop,以及下游应用:ALFWorld、WebShop、GAIA、HLE)表明,DeepAgent在带标注工具和开放集工具检索场景中均显著优于现有基线方法。
本研究迈出了实现更通用、更强大智能体以应对真实世界任务的重要一步。代码与演示可在以下地址获取:🔗 https://github.com/RUC-NLPIR/DeepAgent
1 引言
大型语言模型(Large Language Models, LLMs)的快速发展推动了基于LLM的智能体(agents)的诞生,这些智能体已在诸如网页信息检索、软件工程和个人助理等场景中得到广泛应用 [19, 39, 53]。现有的智能体框架主要依赖于预定义的工作流程,例如 ReAct [67] 和 Plan-and-Solve [54] 等方法,它们采用结构化的规划过程以及反复的“推理-行动-观察(Reason-Act-Observe)”循环,如图2(a) 所示。
虽然这些方法在较简单的任务中表现有效,但存在几个关键局限性: (1) 在执行步骤和整体流程中缺乏自主性; (2) 无法在任务执行过程中动态发现工具; (3) 无法实现交互记忆的自主管理; (4) 在对整个任务进行深度且连贯推理方面存在不足。
这些根本性问题严重限制了智能体应对真实世界复杂任务的能力,尤其是那些需要通用工具使用和长时序交互的任务。
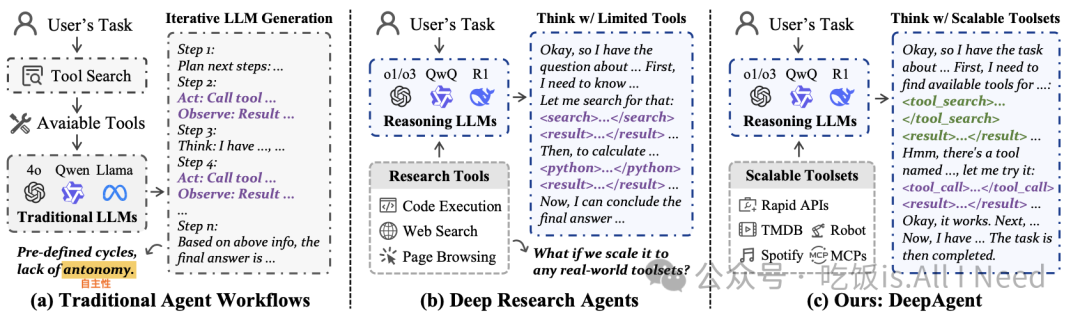
图2:智能体范式的比较:(a) 传统智能体—— 依赖预定义的工作流程; (b) 深度研究型智能体(Deep Research agents)—— 能够自主调用数量有限的工具;(c) 我们提出的 DeepAgent—— 一种完全自主的推理智能体,能够在连续的智能体推理过程中动态发现并调用有用的工具。
近期,大型推理模型(Large Reasoning Models, LRMs)的出现展现了通过逐步的“慢思考(slow thinking)”过程在数学、编程和科学推理等领域解决复杂问题的能力 [2, 28]。然而,许多现实世界任务仍然需要借助外部工具才能完成。尽管已有研究探索了在推理过程中整合工具使用的新范式,如 Search-o1 [25]、DeepResearcher [74] 和 ToRL [27],但这些方法通常局限于少量预定义工具(如网页搜索、页面浏览、代码执行等,如图2(b)所示),从而限制了它们在更复杂、开放场景中的适用性。
为解决上述挑战,本文提出了 DeepAgent —— 一种端到端深度推理智能体,能够在单一、连贯的推理过程中动态检索并调用工具以完成整个任务。如图2(c)所示,DeepAgent通过自主思考、工具搜索与行动执行来运作。 这种范式摆脱了传统的、依赖预定义工具和任务规划的迭代式工作流,其中每个生成步骤仅关注当前的子目标。相反,DeepAgent在推理过程中始终保持对整个任务的全局视角,而不局限于对孤立操作的思考。工具不再提前检索,而是在需要时动态发现和调用,从而充分释放大型推理模型的自主潜能。
为了让DeepAgent在长时序交互中能稳健地探索新工具并在复杂环境中导航,我们为其引入了记忆管理能力。我们提出了自主记忆折叠(Autonomous Memory Folding)策略,使DeepAgent能够在推理过程中将其先前的思考与交互历史随时整合为结构化记忆模式,然后继续推理过程。这一机制不仅节省了token、提升了长时交互中的推理效率,还让智能体能“喘口气”——避免陷入错误的探索路径,并重新评估策略,从而提升整体成功率。
为减轻折叠过程中信息丢失的问题,我们提出了一种类脑记忆结构,包括情景记忆(episodic memory)、工作记忆(working memory)和工具记忆(tool memory),并通过可供智能体使用的数据结构化方案来确保压缩记忆的稳定性和实用性。
为了进一步提高DeepAgent掌握这些机制的能力,我们提出了ToolPO —— 一种针对通用工具使用的端到端强化学习(RL)训练方法。现有智能体在通用领域进行强化学习训练时面临两大挑战: (1) 依赖大量真实API进行训练,导致过程不稳定、执行缓慢且成本高。为此,我们利用LLM模拟API环境,显著提升训练的稳定性与效率; (2) 仅依赖最终结果的稀疏奖励信号难以保证中间工具调用的准确性。我们通过工具调用优势归因(tool-call advantage attribution)机制,精确地为负责正确工具调用的token分配细粒度的奖励信号,从而提供更有效的学习信号。
工具调用优势归因机制(Tool-Call Advantage Attribution) 的目标是: 精确地把奖励信号分配给负责正确工具调用的特定 tokens。
我们在多个基准测试上进行了广泛实验:
-
(1) 通用工具使用任务:包括 ToolBench、API-Bank、TMDB、Spotify 和 ToolHop,这些数据集的工具数量从数十个扩展到超过一万个;
-
(2) 下游应用任务:包括 ALFWorld、WebShop、GAIA 和 Humanity’s Last Exam (HLE),这些任务需要使用特定领域的工具集。
整体实验结果(见图1)表明,DeepAgent 在所有场景中均表现出优越的性能。
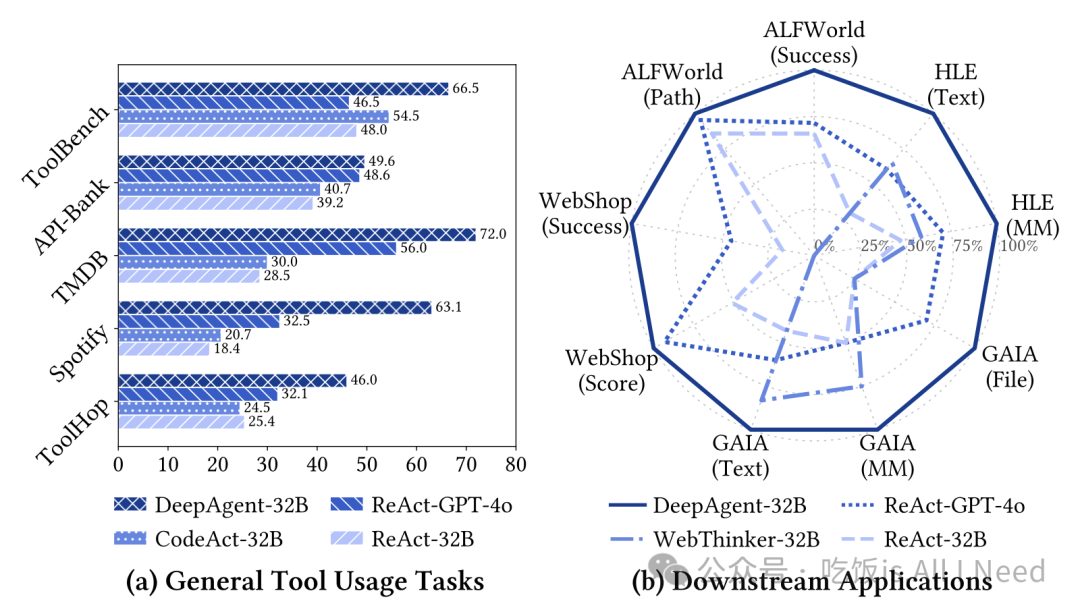
图1:在 (a) 通用工具使用任务和 (b) 下游应用任务上的整体性能表现(以最佳得分 100% 为基准)。
我们的主要贡献如下:
-
(1)提出 DeepAgent 框架: 我们提出了 DeepAgent —— 首个使推理模型能够在统一的推理过程中自主思考、发现工具并执行动作的智能体框架。该方法使大型推理模型(LRMs)能够利用任意规模的工具集,并推广到复杂的现实世界任务中。
-
(2)引入自主记忆折叠机制与类脑记忆设计: 我们提出了一种自主记忆折叠(autonomous memory folding)机制,并结合了受人脑启发的记忆结构设计。该机制使智能体在经历失败尝试后,能够“喘口气”,重新审视其探索策略,从而增强任务执行的灵活性与鲁棒性。
-
(3)提出通用工具使用的端到端强化学习方法: 我们设计了一种用于通用工具使用的端到端强化学习训练方法,在训练阶段确保大规模工具执行的稳定性与高效性,并在推理过程中提升工具调用的准确性。
-
(4)广泛实验验证与性能提升: 我们在八个基准任务上进行了广泛实验,结果表明 DeepAgent 在工具使用能力与真实任务适应性方面均显著优于现有方法。
以下是你提供内容的中文翻译(保持学术论文风格与原意一致):
2 相关工作
2.1 大型推理模型(Large Reasoning Models, LRMs)
大型推理模型(LRMs)[5, 16] 通过在生成最终响应之前采用逐步、缓慢思考(slow thinking)过程,在数学、科学和编程任务中展现出了显著的性能提升。现有研究探索了多种方法来引出模型的扩展链式思维(Chain-of-Thought, CoT)推理 [58],包括用于监督微调(Supervised Fine-Tuning, SFT)的数据合成 [33, 36, 69],以及端到端强化学习(Reinforcement Learning, RL)训练 [5, 14]。此外,大量研究聚焦于推理模型的优化策略,如先进的强化学习训练算法 [70, 73] 以及提高推理效率的方法 [3, 65]。
然而,仅依赖参数化知识的模型存在固有局限,无法与真实世界进行交互。近期研究开始探索工具增强型推理(tool-augmented reasoning)方法,包括 Search-o1 [25]、Search-R1 [18]、ToRL [27]、DeepResearcher [74] 和 SimpleTIR [63]。不过,这些方法通常仅支持有限的一组研究导向工具,例如网页搜索、页面浏览和代码执行,这限制了其在需要访问更丰富工具集的真实场景中的应用。
Tool-augmented reasoning approaches指的是让语言模型在推理或解决任务的过程中,能够主动调用外部工具(tools)来辅助思考或行动的方法。
简单说,这类方法不是只依赖模型参数中的“记忆”(即模型内部知识),而是让模型在思考过程中:
查询搜索引擎、数据库或文献;
运行代码;
调用计算器、API、翻译器;
访问网络或文件系统;
使用其他 AI 工具(如图像识别、数据分析工具)。
2.2 自主代理(Autonomous Agents)
基于大型语言模型(LLM)的自主代理能够通过调用外部工具与环境交互,从而完成现实世界任务 [7, 15, 21, 23, 30, 38, 41, 52, 53, 59, 72]。当前的代理方法,如 ReAct [67]、Plan-and-Solve [54]、Reflextion [45] 和 CodeAct [56],主要遵循预定义的工作流程与固定的执行模式。这种僵化的结构限制了其充分发挥高级推理模型的自主决策与深度推理能力。
最近的研究尝试通过数据合成与监督微调(SFT)[9, 48, 62] 以及强化学习(RL)训练框架 [4, 6, 8, 10, 11, 17, 22, 29, 31, 49, 57, 60],来训练 LLM 能够自主调用工具。然而,大多数现有方法依赖于预先选择和标注的工具集,这限制了其在现实世界中任务多变的适用性。现实任务高度多样化,需要访问无法预先确定的多样化工具集,这与新兴的模型上下文协议(Model Context Protocol, MCP)[13]范式的理念相契合。
尽管已有研究探索了工具检索机制 [37, 43, 55],但多数方法仅在初始阶段执行一次工具检索,并将检索到的工具纳入模型中,对任务执行过程中**动态工具发现(dynamic tool discovery)**的探索仍然有限。
因此,我们的目标是开发一种具备深度推理能力的代理系统,使其能够在可扩展的工具集内动态发现并调用有用工具,以应对更具普适性的真实世界任务。
3 方法论(Methodology)
在本节中,我们首先对自主智能体推理(autonomous agentic reasoning)任务进行形式化定义。随后,我们对 DeepAgent 框架进行详细概述。最后,我们将进一步阐述 DeepAgent 的核心组成部分,包括:
-
自主工具使用与记忆折叠(autonomous tool use and memory folding)机制,
-
类脑记忆结构(brain-inspired memory schema),
-
以及我们提出的端到端强化学习训练方法 ToolPO。
3.1 问题表述(Problem Formulation)

3.2 DeepAgent 框架概述(Overview of the DeepAgent Framework)
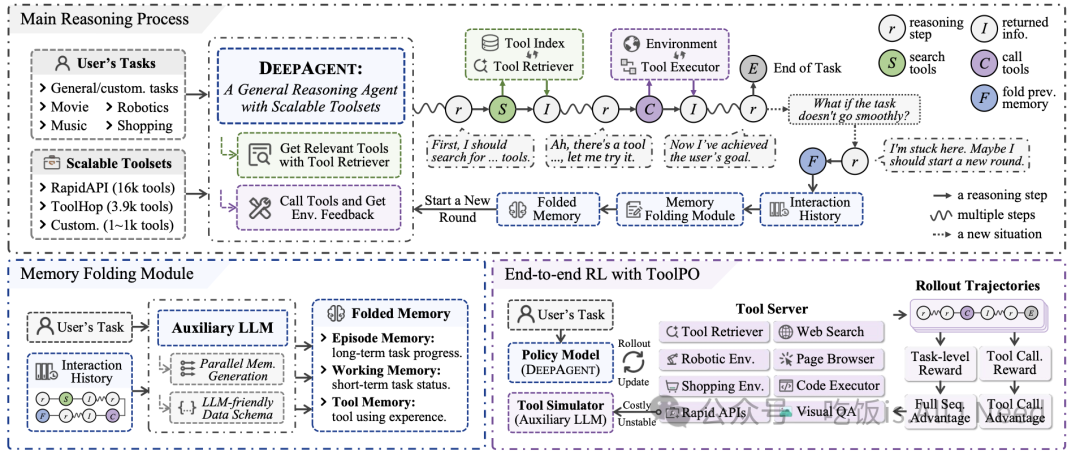
图 3:DeepAgent 框架概览。主推理模型能够自主地发现工具、执行动作,并折叠先前记忆,以结构化记忆重新开始——这一切都在统一的思维过程中完成。DeepAgent 通过 ToolPO 进行端到端训练,这是一种强化学习方法,利用工具模拟器来模拟大规模真实世界的工具 API,并通过精细化的优势归因,对最终任务成功以及中间工具调用的正确性进行奖励。
如图 3 所示,DeepAgent 框架的整体架构围绕一个主要的推理过程构建,并由若干辅助机制支撑,以确保系统的鲁棒性与高效性。
-
主要推理过程(Main Reasoning Process): DeepAgent 的核心是一个功能强大的大型推理模型(Large Reasoning Model, LRM),它驱动整个任务完成过程。在单一的思维流中,LRM 能够自主地对任务进行推理,动态发现所需工具、执行操作,并管理自身记忆。这种统一的方式不同于传统代理系统中僵化的工作流程,使得 LRM 能够在任务执行过程中保持全局视角。
-
辅助机制(Auxiliary Mechanisms): DeepAgent 配备了一个辅助大型语言模型(auxiliary LLM),用于处理与大规模工具集的复杂交互以及长历史记录的管理。该辅助模型通过以下方式提升系统的稳定性:
-
当检索到的工具文档过长时,进行过滤与摘要;
-
对工具调用返回的冗长信息进行去噪与压缩;
-
将长交互历史压缩为结构化记忆。
-
这种分工协作机制使主要的 LRM 能够专注于高层次的战略推理,从而显著提升整个系统的智能性与执行效率。
3.3 自主式工具检索与调用(Autonomous Tool Search and Calling)
DeepAgent 的主 LRM(大型推理模型)通过在连续推理过程中生成特定的文本提示来执行所有动作。这些动作随后会被系统拦截并执行。

3.4 自主式记忆折叠与类脑记忆结构Autonomous Memory Folding and Brain-Inspired Memory Schema

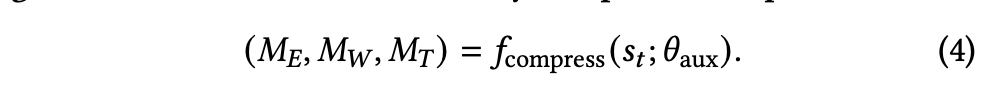
这些压缩后的情节记忆((M_E))、工作记忆((M_W))以及工具记忆((M_T))会替代原始的交互历史,使智能体能够以一种更新且更精炼的方式继续推进任务,同时避免陷入错误的探索路径。
受人类认知系统的启发,结构化记忆 (M_t) 由三种并行生成的不同组件组成:
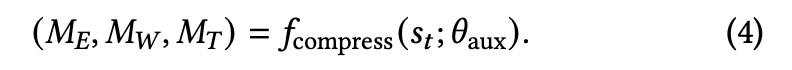
其中 (M_E)、(M_W)、(M_T) 分别表示情节记忆、工作记忆和工具记忆。
• 情节记忆(Episodic Memory, (M_E))
该组件作为任务的高层日志,记录关键事件、主要决策点以及子任务的完成情况。
它为智能体提供了关于整体任务结构及总体目标的长期上下文。
• 工作记忆(Working Memory, (M_W))
该组件包含最近的信息,例如当前子目标、遇到的障碍以及近期计划。
它是确保智能体在执行记忆折叠后仍能保持推理连续性的核心部分。
• 工具记忆(Tool Memory, (M_T))
该组件整合所有与工具相关的交互,包括使用过哪些工具、如何调用它们,以及它们的有效性。
这使智能体能够从经验中学习,改进其工具选择与使用策略。
为了确保压缩后的记忆稳定且易于被智能体解析,我们采用 JSON 格式的、智能体可使用的数据结构,而非无结构的自然语言。
这种结构化格式带来两个主要好处:
-
保持可控且可预测的结构;
-
减少在摘要长文本时可能出现的重要信息丢失。
数据结构的详细内容在附录 D 中提供。
3.5 使用 ToolPO 的端到端强化学习训练
我们使用 Tool Policy Optimization(ToolPO)对 DeepAgent 进行端到端训练,这是一种专门为通用工具使用型智能体设计的强化学习方法。
训练数据收集(Training Data Collection)
我们首先收集了一个覆盖四大类别的多样化训练数据集:
-
通用工具使用能力,使用 ToolBench [37],用于让模型具备广泛的工具使用能力。
-
真实世界交互能力,使用 ALFWorld [46]和 WebShop [66],提供与真实环境类似的任务。
-
深度研究能力(deep research skills),引入 WebDancer [59]和 WebShaperQA [50]的数据,以增强复杂研究和信息整合能力。
-
代码辅助的数学推理能力,使用 DeepMath [12],以提升基于代码的数学推理水平。
更多细节见附录 A.1。
工具模拟器(Tool Simulator)
训练一个与数千个真实 API 交互的智能体往往不切实际,因为真实 API 的不稳定性、延迟和成本都非常高。为了解决这一问题,我们开发了一个 基于 LLM的工具模拟器。该模拟器由辅助 LLM 驱动,能够模拟真实 API(如 RapidAPI)的响应。这种方式提供了一个稳定、高效且低成本的训练环境,使强化学习训练更加稳健。
全局与工具调用优势归因 Globaland Tool-Call Advantage Attribution.

这个目标函数会鼓励模型提高 “具有正相对优势的中间操作与端到端任务完成行为” 的概率,从而保证策略更新的稳定性与有效性。
4 实验设置(Experimental Settings)
4.1 任务与数据集(Tasks and Datasets)
我们在广泛的基准上进行了大量实验,涵盖通用工具使用以及下游应用。
通用工具使用(General Tool-Use)
这些基准包含范围广泛的工具数量,从几十到一万多个,非常适合用于评估不同方法的可扩展性。我们使用四种代表性的场景:
-
ToolBench [37],基于超过 16,000 个真实 API。我们使用其中的 G3 子集,该子集要求多步、多工具调用。
-
API-Bank [24],包含 314 条由人工标注的对话,涵盖 73 个 API 和 753 次 API 调用,用于评估规划、检索和调用能力。
-
RestBench [47],来自 TMDB 电影数据库(54 个工具,平均 2.3 次调用/问题)和 Spotify 音乐播放器(40 个工具,平均 2.6 次调用/问题)的任务场景,用于模拟典型的 REST 应用。
-
ToolHop [68],一个多跳推理数据集,包含 3,912 个本地可执行工具,每个任务需要 3 到 7 次连续工具调用。
对于这些任务,我们采用两种设置:
-
给定真实工具集(ground-truth tools)
-
给定完整工具集并启用工具检索能力
下游应用(Downstream Applications)
我们在多个需要领域专用工具集的下游应用中评估我们的方法。这些包括:
-
ALFWorld [46],一个基于文本的具身 AI 任务,智能体使用九种基本动作(如移动、拾取)完成目标。
-
WebShop [66],一个在线购物环境,智能体通过 “search” 和 “click” 的操作来满足用户的具体购买需求。
-
GAIA [32],一个复杂的信息检索基准。我们为智能体提供了网页搜索、页面浏览、视觉问答(VQA)、代码编译、文件读取等工具。
-
Humanity’s Last Exam(HLE)[35],一组极具挑战性的推理问题。我们为智能体提供代码、搜索、页面浏览和 VQA 工具。
这些基准测试智能体在复杂真实场景中执行长时规划和进行稳健交互的能力。对于这一类别的任务,我们为智能体提供特定任务的工具集。
4.2 基线方法(Baselines)
我们的基线包括:
(1)基于工作流的方式(Workflow-based Methods):
-
ReAct [67]:在“推理—行动—观察”循环中交替进行显式推理与环境动作。
-
CodeAct [56]:将动作表达为可在解释器中运行的 Python 代码。
-
Plan-and-Solve [54]:先生成高层计划,再逐步执行。
-
Reflexion [44]:在失败尝试后通过语言自反思提升学习效果。
-
AgentLM [71]:通过指令微调增强 LLM 的通用智能体能力。
(2)在推理过程中实现自主工具使用的方法(Autonomous Tool Usage within Reasoning):
-
WebThinker [26]:在推理过程中交织网页搜索和深度网页探索。
-
HiRA [20]:提出分层式智能体结构,包含元规划器分解任务、协调器分发子任务,以及具有双通道记忆的执行器。
-
OpenAIDeep Research [34]:基于推理模型的智能体系统。
4.3 实现细节(Implementation Details)
我们使用 QwQ-32B [51]作为 DeepAgent 的主干模型(backbone),并使用 Qwen2.5-32B-Instruct [40]作为辅助模型(auxiliary model)。文本生成设置:最大长度 81,920 tokens,temperature=0.7,top_p=0.8,top_k=20,repetition penalty=1.05。Web 搜索使用 Google Serper API;网页浏览使用 Jina Reader API。VQA 工具基于 Qwen2.5-VL-32B-Instruct [1]。工具检索使用 bge-large-en-v1.5 [61]。训练包含 100 步 ToolPO:batch size = 64;λ₁ = λ₂ = 1;rollout size K = 8;最大序列长度 = 32,768
更多细节见附录 C。所有实验在 64 张 NVIDIA H20-141GB GPU上完成。
5 实验结果(Experimental Results)
5.1 通用工具使用任务的主要结果(MainResults on General Tool Usage Tasks)
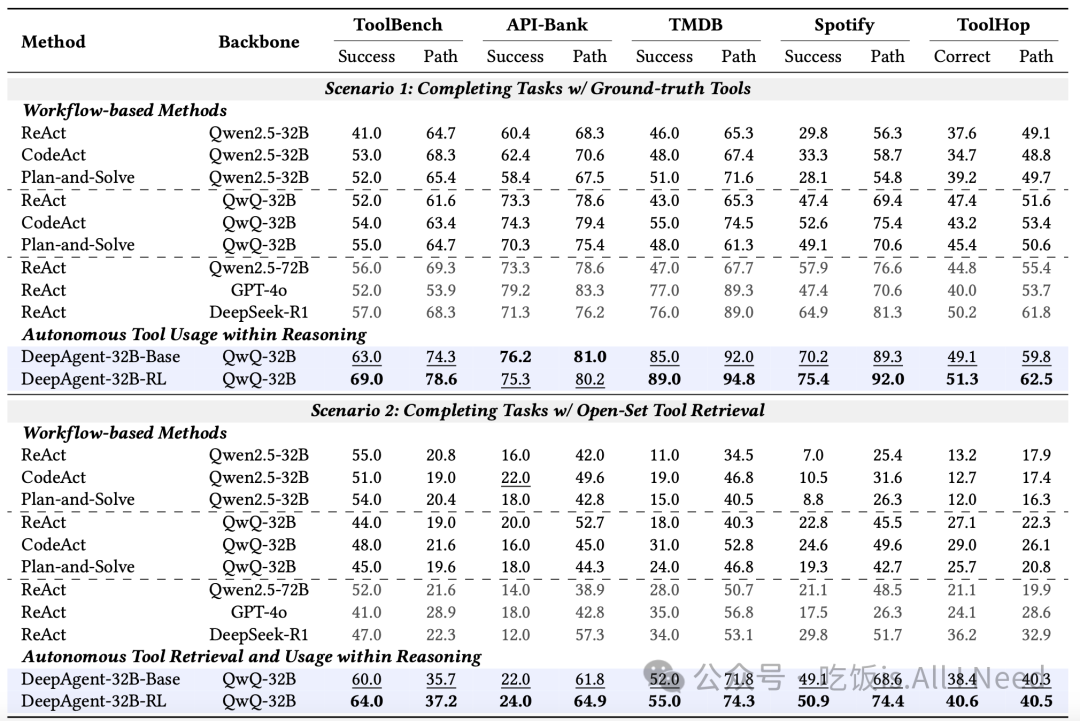
表 1:通用工具使用任务的主要结果
该表涵盖了既包含标注工具场景,也包含在大规模工具集中进行开放式工具检索的场景。我们对所有任务均报告 Pass@1指标。对于 32B 模型,最佳结果以黑体表示,次优结果以下划线表示。来自更大模型或闭源模型的结果以 灰色显示,作为参考。
表 1 展示了通用工具使用任务的实验结果,带来了以下几个关键观察:
(1)DeepAgent 的端到端推理优于基于工作流的方法。
DeepAgent 的整体式智能体推理过程持续优于僵化、预定义的工作流。
例如,在标注工具(labeled-tool)任务上:
-
DeepAgent-32B-RL在TMDB 上达到 89.0%成功率,Spotify 上达到 75.4%
-
显著超过最强 32B 基线模型的 55.0%和 52.6%
这强调了整体化智能体推理相对于固定动作循环的优势。
(2)DeepAgent 在开放集(open-set)场景中保持强鲁棒性。
这一优势在开放集场景中更为突出,因为此时动态发现工具至关重要。在 ToolBench 和 ToolHop 上,DeepAgent-32B-RL分别取得:ToolBench:64.0%,ToolHop:40.6%,远高于各自的最强基线:54.0%和29.0%
这表明 DeepAgent 在推理过程中根据需要动态发现工具的策略更加鲁棒且具有更强的可扩展性,特别是在真实的开放集环境中。
(3)ToolPO 训练进一步提升了工具使用能力。
我们提出的 ToolPO 强化学习策略带来了显著额外提升。训练后的 DeepAgent-32B-RL模型:在 ToolBench 上提升最多 6.0%,在 Spotify(labeled)上提升 5.2%
这验证了 ToolPO 策略的有效性,该策略利用 基于 LLM的工具模拟器与 细粒度优势归因(fine-grained advantage attribution)实现稳定高效的训练。
5.2 下游应用的主要结果
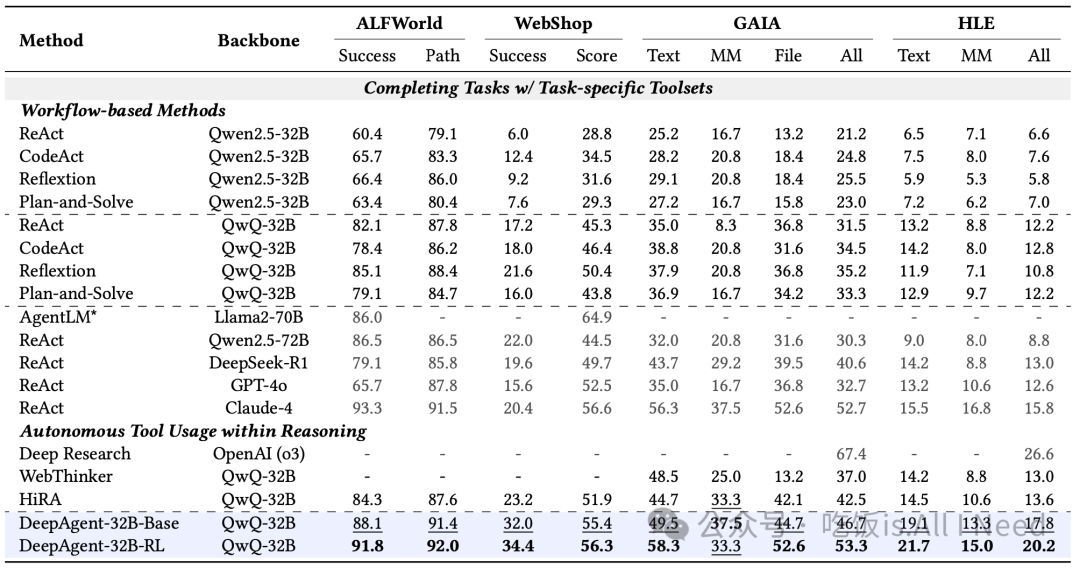
表 2:下游任务应用的主要结果,涵盖具身智能(ALFWorld)、在线购物(WebShop)、通用 AI 助手(GAIA)以及 Humanity’s Last Exam(HLE)。我们在所有任务中报告 Pass@1 指标。对于 32B 规模的模型,最优结果以黑体表示,第二名以下划线表示。来自更大规模或闭源模型的结果以灰色展示,供参考。
表 2 展示了在下游应用上的实验结果,这些任务要求智能体在复杂环境中处理长时间跨度的交互。
(1)自主推理范式整体上优于基于工作流的方法。在复杂应用任务中,将工具使用融入连续推理的方式,持续优于僵化、预定义的工作流方法。在 GAIA 任务上,无论是 DeepAgent-32B-Base(46.7)还是 HiRA(42.5),都显著超越了最好的基于工作流的方法 CodeAct(34.5)。类似地,在 WebShop 上,DeepAgent-32B-Base(32.0)也大幅超过 CodeAct(18.0)。这表明,对于长时间交互任务,实现更出色的任务完成需要深度的智能体推理能力。
(2)DeepAgent 在多种应用任务上表现卓越。DeepAgent 在 32B 规模的模型中达到了当前最优性能。在 GAIA 中,DeepAgent-32B-RL 得分 53.3,而 HiRA 为 42.5;在 ALFWorld 中,DeepAgent 达到 91.8% 的成功率,而 HiRA 为 84.3%。这种性能优势源于 DeepAgent 在推理中无缝整合行动,实现了具备自主记忆折叠(autonomous memory folding)的端到端执行,而这些优势是受制于工作流的方法无法具备的。
(3)ToolPO 训练进一步提升了下游应用性能。ToolPO 训练在 base 模型基础上提供了持续提升。DeepAgent-32B-RL 将 GAIA 得分从 46.7 提升至 53.3(+6.6),将 ALFWorld 的成功率从 88.1% 提升到 91.8%(+3.7)。这说明 ToolPO 可以有效增强模型在复杂任务中的推理和工具使用能力。
5.3 训练动态分析
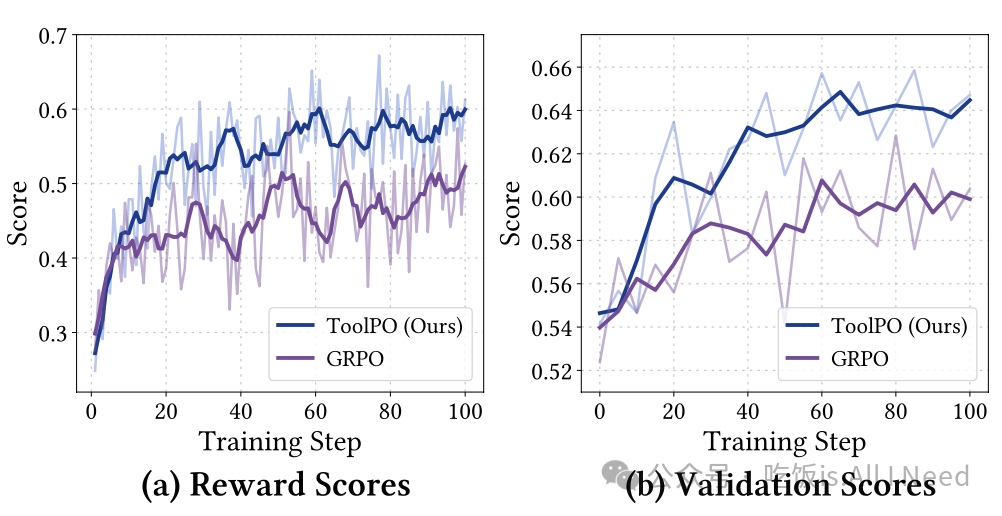
图 4:训练动态的可视化,包括 (a) 各训练步骤的奖励分数,以及 (b) 各训练步骤的验证分数。
图 4 展示了 DeepAgent 的训练动态,包括训练过程中的奖励分数和验证分数随训练步数的变化。如图所示,
(1)使用 ToolPO 训练的 DeepAgent,在奖励上限和验证分数上均高于常用的 GRPO。
(2)此外,训练奖励的波动也比 GRPO 更小,表现出更好的训练稳定性。
这说明:利用工具模拟器而非直接使用不稳定的真实 API 来进行训练,并结合对工具调用过程的监督,可以使工具使用能力的训练更加稳定和有效。
5.4 消融实验(Ablation Studies)
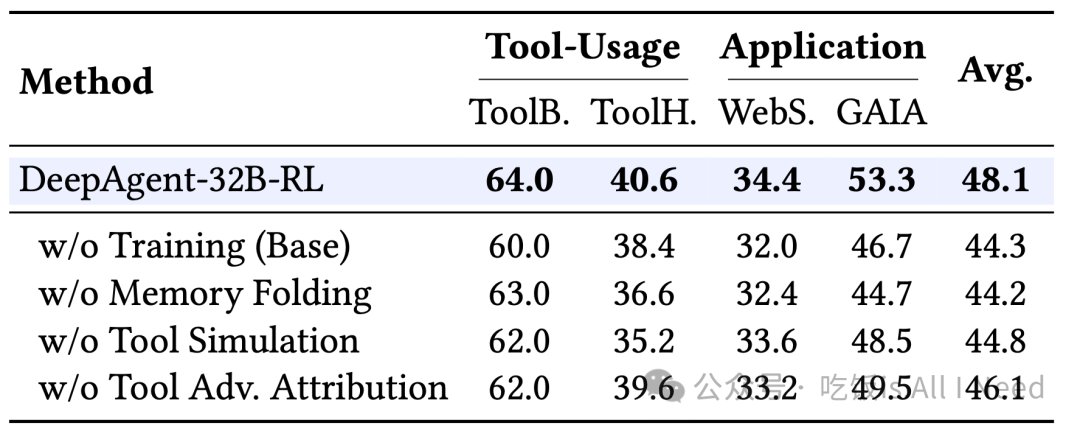
表 3:DeepAgent 各组件的消融实验,其中最佳结果以黑体显示。
我们在表 3 中进行了消融实验,以验证 DeepAgent 各个组件的有效性。
(1) ToolPO 训练的重要性:移除 ToolPO 训练(即 Base 模型)会导致最显著的性能下降(从 48.1 降至 44.3)。这表明我们提出的端到端强化学习方法在增强工具使用能力与复杂任务完成方面起着核心作用。
(2) Memory Folding 的有效性:移除 memory folding 同样会造成明显的性能降低(平均分降至 44.2),尤其是在长周期任务 GAIA 上(从 53.3 降至 44.7)。这证明自主 Memory Folding 机制——允许 agent “喘口气”重新规划——对长期交互的稳健性至关重要。
(3) 训练策略的贡献:移除工具模拟器或工具调用的优势归因都会导致性能下降。这说明工具模拟器提供了更稳定的训练环境,而细粒度优势归因提供了更精确的学习信号。
5.5 工具检索策略的有效性(Effectiveness of Tool Retrieval Strategies)
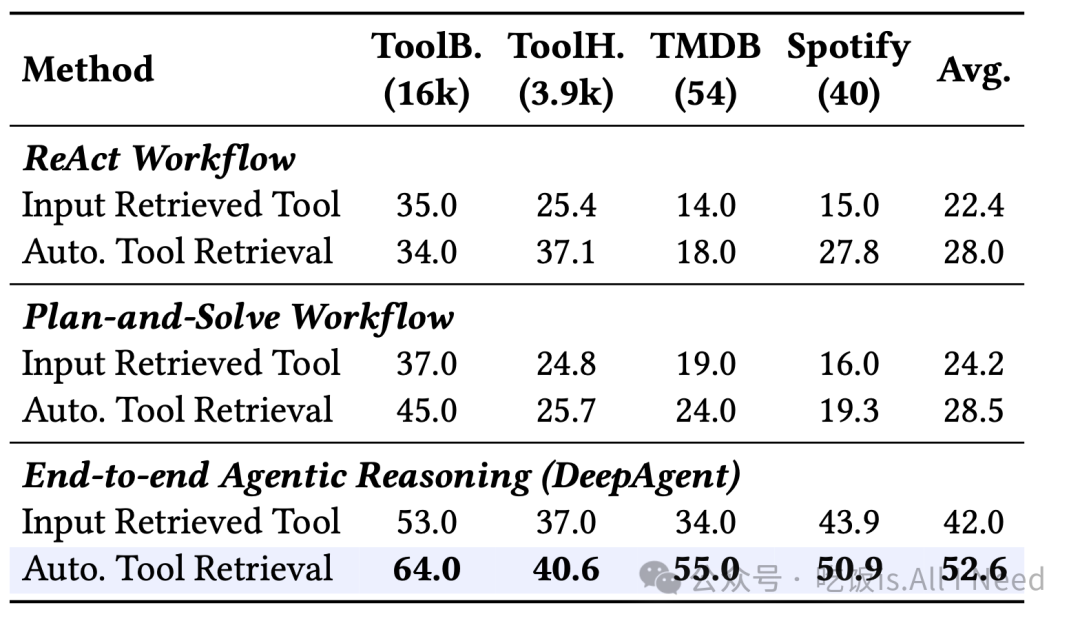
表 4:在开放集场景中,与预检索工具方法相比,自主工具检索策略有效性的分析。括号中的数字表示工具集规模。
为了比较预检索工具与任务执行过程中自主发现工具两种方式,我们进行了如表 4 所示的实验。
(1) 按需动态发现工具具有更好的性能与可扩展性:在推理过程中自主检索工具的方式在所有框架上都优于预检索工具,证明按需工具访问在开放集环境中更具优势。性能提升在大型工具集上最为明显,如 ToolBench(16k 工具)和 ToolHop(3.9k 工具),表明其在真实世界任务中的强大扩展能力。
(2) DeepAgent 与动态检索具有更强的协同效应:在动态工具检索的配合下,我们的框架取得了远超其他方法的最佳结果,平均得分 52.6,而最佳工作流方法仅为 28.5。这说明 DeepAgent 的架构与动态工具发现天然契合。
5.6 动作限制的扩展性分析(Scaling Analysis of Action Limits)
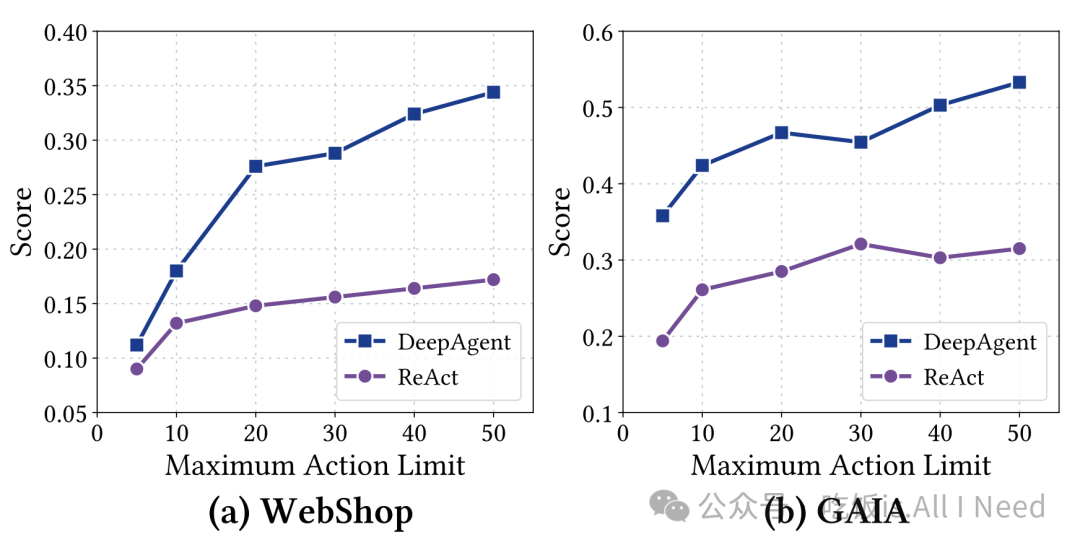
图 5:在 WebShop 和 GAIA 数据集上,随着最大可用动作数量限制的变化,性能的可扩展性分析。
图 5 展示了在不同最大动作限制下,DeepAgent 与 ReAct 在 WebShop 和 GAIA 数据集上的表现。结果揭示了以下关键洞察:
(1) DeepAgent 在所有动作限制下都显著优于 ReAct:证明其在复杂任务中的更高效性。
(2) 对于两个 agent,当允许的最大动作数增加时,性能普遍提升:这表明复杂任务从更长的交互周期中受益,有利于更充分的探索与推理。
(3) DeepAgent 展现出更强的可扩展性:随着动作限制增加,DeepAgent 与 ReAct 的性能差距不断扩大,尤其是在 WebShop 上。持续增长的优势说明 DeepAgent 更擅长战略性地选择有效且任务相关的动作,避免 ReAct 中常见的无效步骤,从而限制了后者的扩展能力。
5.7 不同基础模型上的泛化能力(Generalization Across Different Backbones)
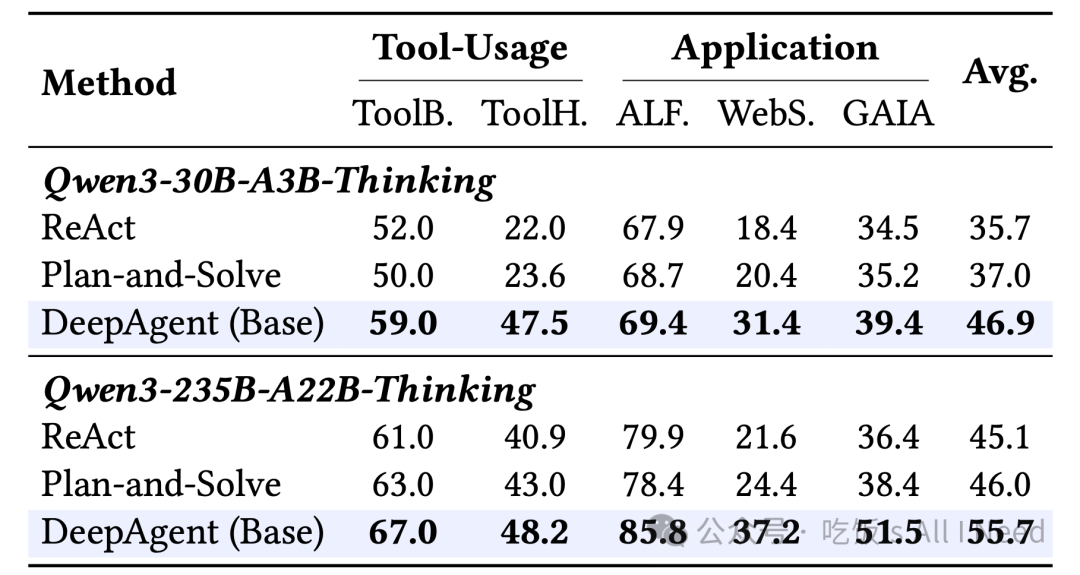
表 5:使用不同推理模型骨干(包括 30B 和 235B 参数的 MoE 模型)时的性能对比。
表 5 展示了在不同基础大规模推理模型(backbone LRM)下,DeepAgent 的性能,包括 Qwen3-30B-A3B-Thinking 与 Qwen3-235B-A22B-Thinking [64]。主要发现如下:
(1) DeepAgent 在所有基础模型下都显著优于基于工作流的方法。
无论是使用 30B 模型还是 235B MoE(Mixture-of-Experts)推理模型作为基础,DeepAgent 都持续保持对 ReAct 和 Plan-and-Solve 的明显性能优势。这证明了 DeepAgent 的 agentic reasoning(代理式推理)方法具有良好的泛化能力,与具体的基础模型无关。
(2) DeepAgent 能够随着更大的模型规模进一步提升性能。
尽管所有方法在将 backbone 从 30B 规模扩展到 235B 时都受益,但 DeepAgent 在复杂应用任务上获得了最大的绝对性能提升。这表明 DeepAgent 的架构能够有效利用更强大的基础模型,进一步增强其推理和任务完成能力。
6 结论
在这项工作中,我们提出了 DeepAgent——一个将思考、工具发现与执行统一到单一流程中的端到端推理智能体。
为了实现稳健的长时交互,我们设计了 自主记忆折叠机制(autonomous memory folding),将交互历史压缩为结构化记忆,使智能体能够“喘口气”,重新审视并调整其策略。
我们还引入了 ToolPO,一种端到端强化学习方法,通过 LLM模拟 API来实现稳定训练,并通过细粒度优势归因(fine-grained advantage attribution)对工具调用进行精确的信用分配。
在大量通用工具使用任务和下游应用中的实验结果表明:
DeepAgent 在各种基线智能体上均取得了显著性能提升,特别是在需要在大规模工具集中进行动态工具发现的开放集场景中表现尤为突出。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)