华为901B上微调Qwen14B和Qwen32B实录---训练准备篇
在上一篇 华为901B上微调Qwen14B和Qwen32B实录---环境篇-CSDN博客 中已经说到在华为910B上搭建训练环境的事情了,接下来就是做训练前的准备。其实无非就两个东西:1.数据 2.基模。数据方面如何构建高质量的训练数据是一个非常庞大的工作。我们就先简单从数据量,基模选择和npu机器如何匹配来聊一下这个问题。
机器---基模---数据量
1. 多大npu的机器决定你训练模型的大小的上限(一般情况下,用通用的方法下,不排除有一些另辟蹊径)
2.npu机器的选择和你选择的基模的大小决定了你的训练方式(小模型可能随便训,大一点必须想量化或者其他资源优化方法)
3.多大的模型有自己合适的数据量(几十万的数据用来训7B模型可能有点太多了)
华为901B上微调Qwen14B和Qwen32B实录---训练准备篇
第一步:评估机器的能力
在训练之前,我们一定会想的一件事是要训多大的模型,这个的出发点可能首先应该是你未来模型的使用场景,部署的算力资源。但是我们今天先抛开这些不说,纯粹从机器的角度。先假定现在场景对模型没有限制,我只是想知道自己的机器的能力上限。
比如我现在用的华为910B服务器,8*64G。打算做的是Lora微调训练,基模选择Qwen系列,我就拿7B,14B,32B,72B举例。
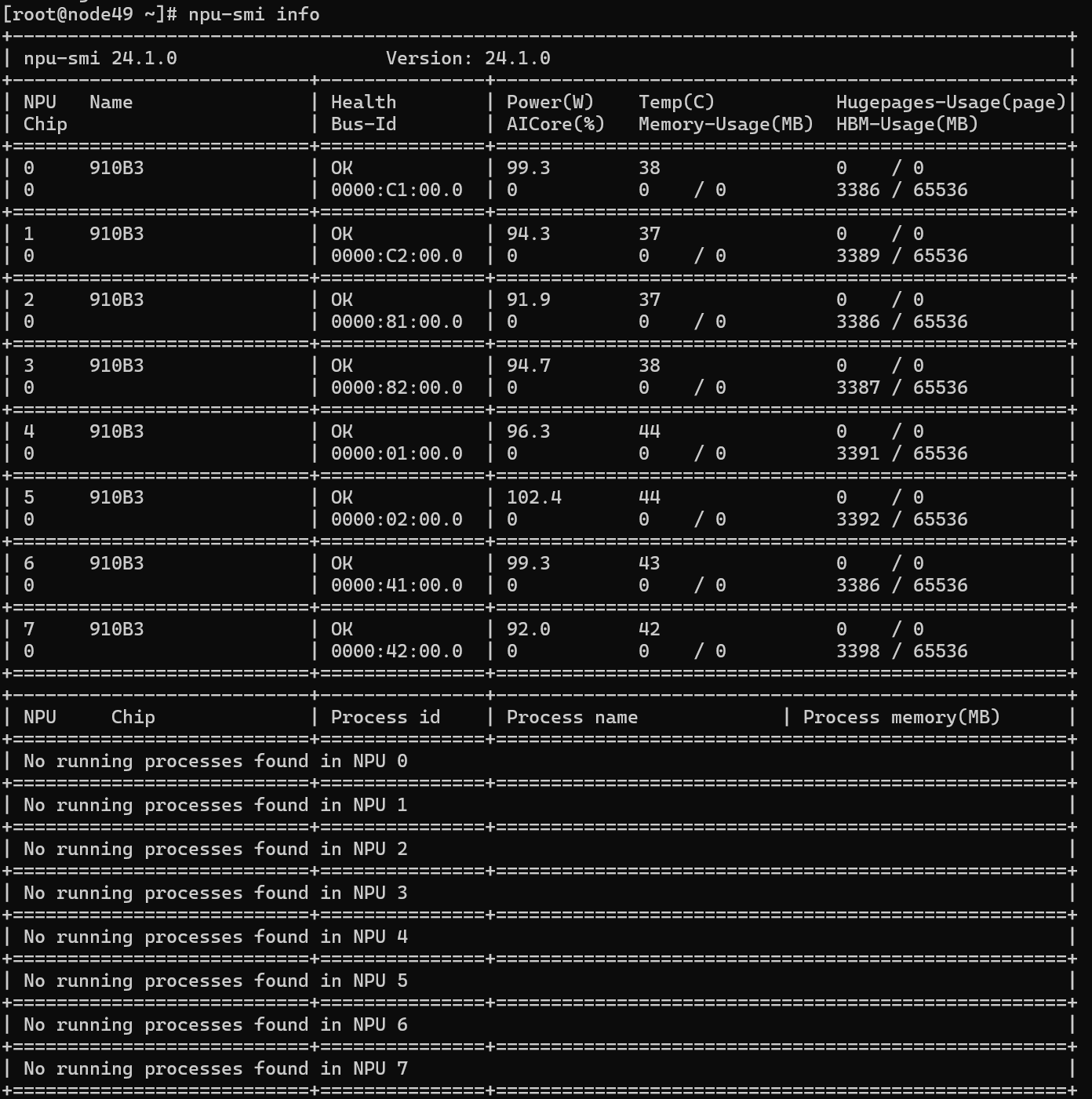
1.如果我选择最原始粗暴的训练方式,不加任何的优化,可能只能训14B的模型
因为每次训练的时候每张卡都把模型加载进去,占用了14*2=28G以上的显存(实际还有其他的开销)。所以用这种方式不可能训32B的模型了,因为32*2=64G还要再加上其他的占用已经超出了一张卡的符合。
这是我最原始的方式训14B时候的占用:
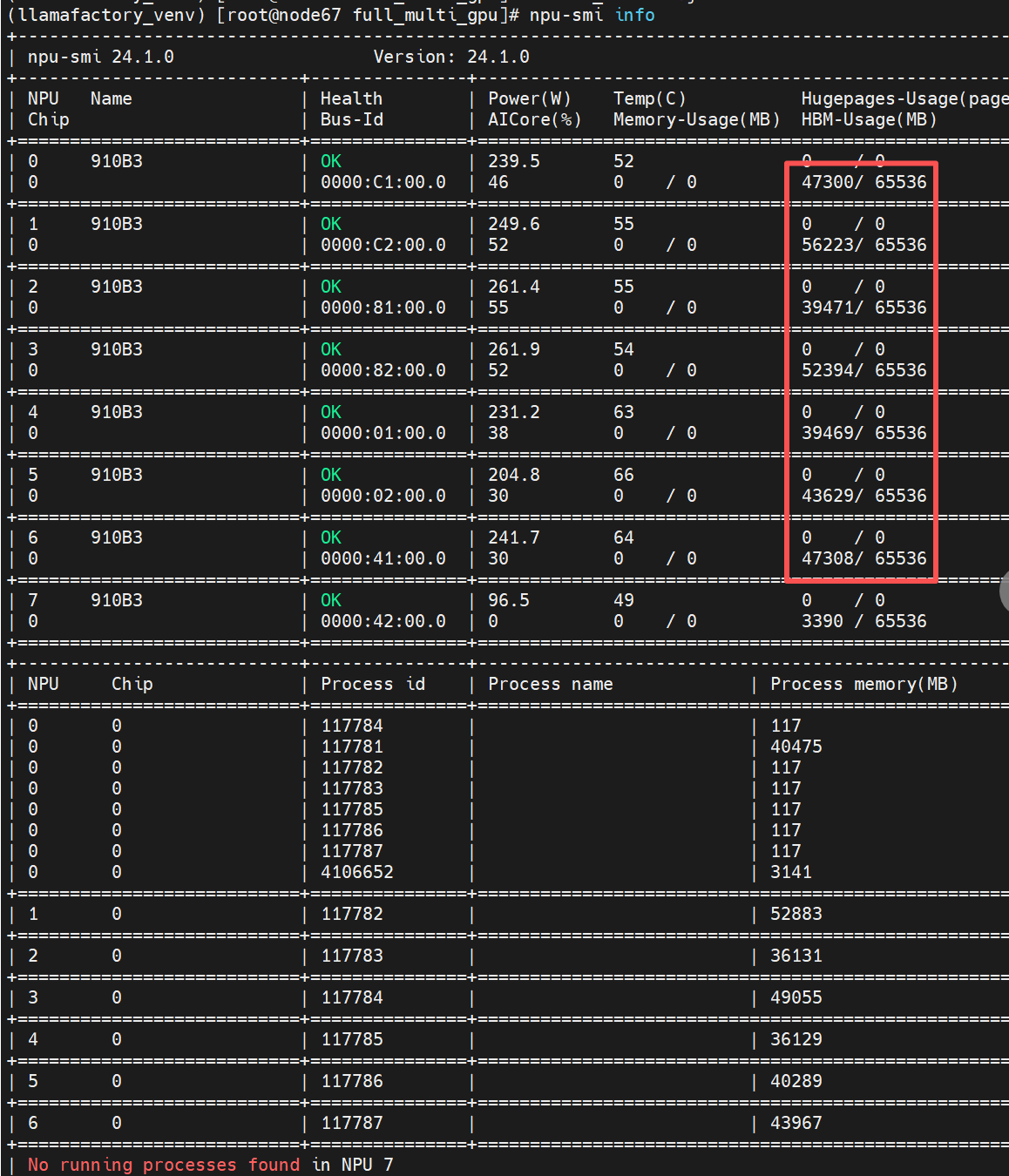
32B模型硬训的时候会报错
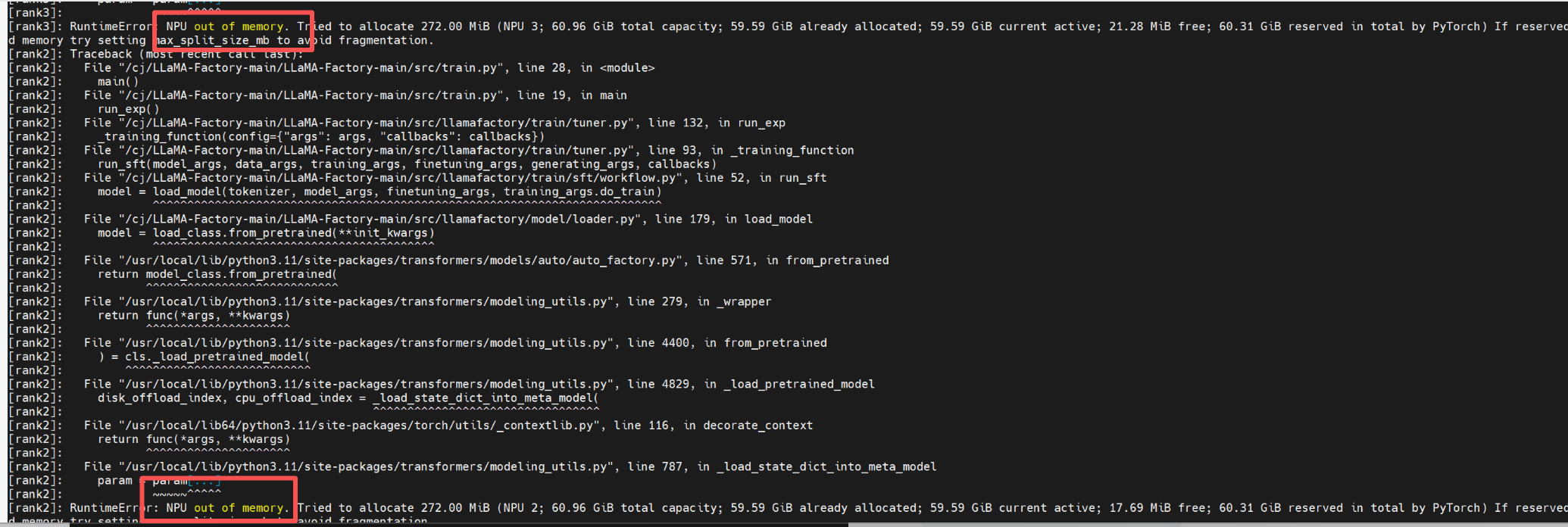
2. 如果使用量化或者deepseed内存优化,则又是不一样的了
量化的问题就姑且后面再说,因为华为的利器直接用llamafactory int4 int8设定去微调确实有问题
但是deepspeed却是利器,简单介绍一下:DeepSpeed 是由微软开发的一个开源、高效的深度学习优化库,它通过内存优化和并行技术,解决在有限硬件资源下,训练和运行参数量远超单个GPU显存容量的大模型这一根本性挑战。
核心技术:ZeRO(零冗余优化器),这是 DeepSeed 的灵魂。它通过智能地分区 模型的三大状态(优化器状态、梯度、模型参数),而非简单地在每个GPU上复制完整模型,从根本上消除了数据冗余。
ZeRO 的三个阶段(核心思想):
ZeRO-1: 仅对优化器状态进行分区。大幅减少内存,通信量小。
ZeRO-2: 分区优化器状态 + 梯度。内存节省更多,通信量略有增加。
ZeRO-3: 分区优化器状态 + 梯度 + 模型参数。内存节省达到极致,实现了“用多张小显存卡拼成一张大显存卡”的效果,是训练万亿参数模型的关键。
所以现在可能有这样的结果
8卡总内存: 512GB DeepSpeed ZeRO-3有效内存: 512GB × 内存复用系数 ≈ 1.5-2TB等效
说人话,就是可以训32B,72B,甚至极限可能是120B的模型,当然我们现在不考虑这些情况,就只要知道训32B是错错有余就行了。下面就是我加了deepseed之后训练32B时候npu的状态:
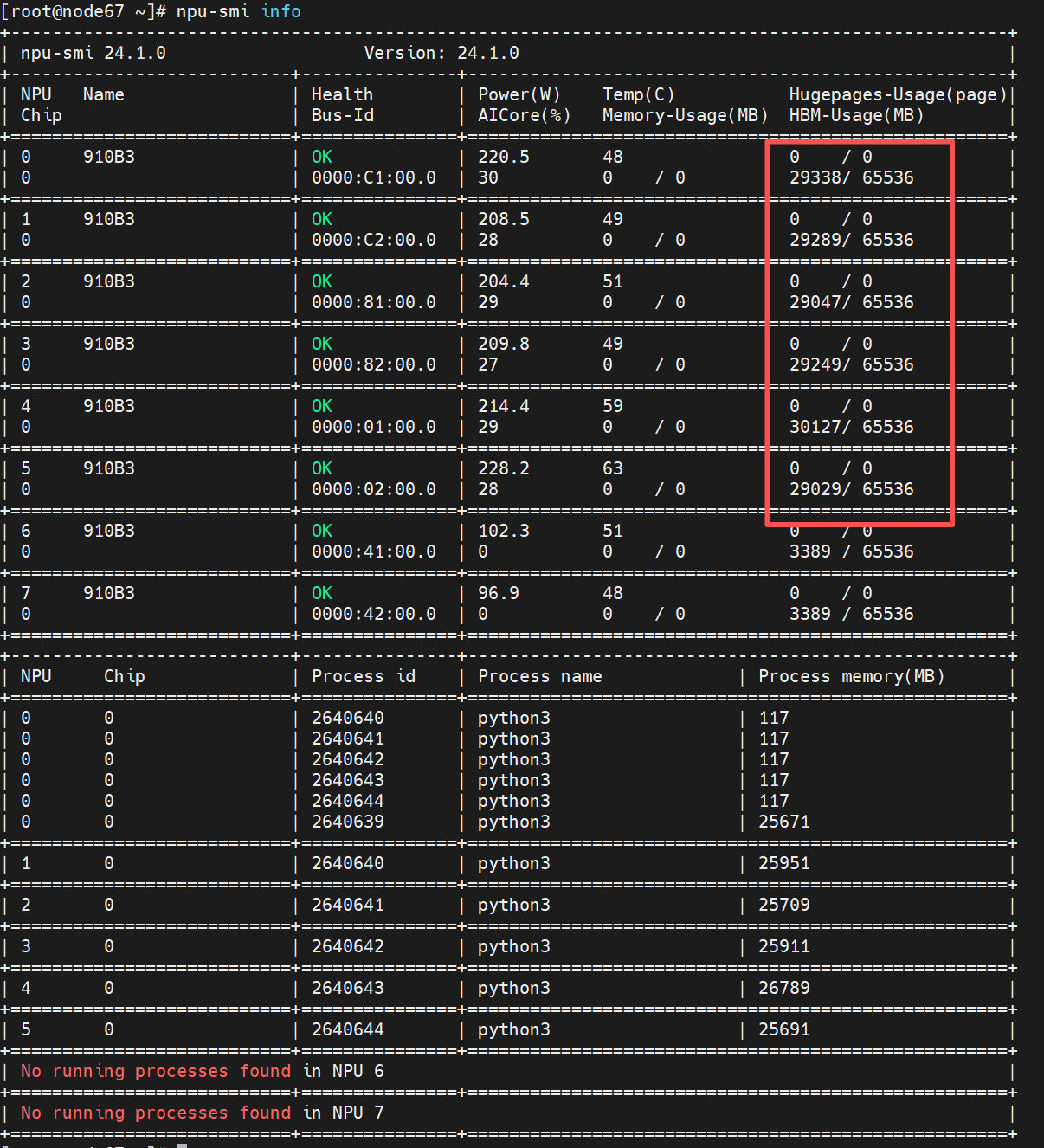
可以看出对npu毫无压力很宽松。
deepseep其实已经在llamafactory的框架里面了,你只要找到路径加到配置文件里面就行
比如我这里的:

这个路径你在你自己的llamafactory文件夹里面找到路径放进去就行,跟我这里的肯定不一样哈。
不过基本上就是LLaMA-Factory-main/examples/deepspeed/ds_z3_config.json这样的路径
注意使用绝对路径哈
第一步总之啰啰嗦嗦就是知道了在之前想的7B,14B,32B,72B这几个都是能训的,接下来就看自己有多少数据了
第二步:训练数据有多少
这个其实真的各有各的不同,也不是说为了训个大一点的模型就对原有的少量的样本做无脑的扩充,反正提高训练数据质量肯定是永远的追求。太重复的数据容易造成过拟合。
但是比如你有10万的高质量数据,用来训练7B的模型感觉还是有点浪费了。
7B小模型小模型易饱和,32B大模型能更好地利用数据。
因为模型训练数据量到了一定程度,有边际效用递减的效应。
如果你的资源不大,只能训7B模型,而且训练样本也很多,那你可以专攻20000条左右训练样本,就已经可以达到最佳效果点。如果你生成样本能力有限,那你花大精力攻5000左右的高质量样本也能有一定的训练效果。
但是如果像现在,有64G*8卡,资源很充足,7B-72B的模型都能训,而且你生成样本的能力充足,那你可以考虑更多的样本,对于14B来说40000条左右高质量,32B来说80000条左右高质量,72B来说150000条高质量是比较合适的
总结一下:
7B模型易饱和,重质量轻数量,推荐样本数量20000条
14B是个效果与效率比较平衡的模型,推荐样本量40000条
32B能较好利用更多数据,推荐样本数量80000条
72B大容量,需要更多数据激活,推荐样本数量150000条
但是最关键的一点:努力提高数据质量
拥有准确、一致、多样、平衡、有代表性的训练数据集是永恒的追求
总结:
一句话总结,进行一次合理的训练之前,除了业务需求之外,要平衡资源---模型---数据量三者之间的需求和关系,选择一个最佳方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)