SpringAI的使用超详细的解析——实现AI对话框功能
本文详细介绍了使用SpringAI实现AI对话框功能的步骤。首先讲解了两种调用AI大模型的方式:本地部署(通过Ollama管理工具)和远程调用(如阿里云百炼平台)。然后介绍了前端页面准备(基于Vue3组件)和后端服务配置(使用SpringBoot和SpringAI),包括数据库配置、API密钥设置等关键参数。文章还提供了完整的项目代码地址,适合开发者参考学习如何构建一个完整的AI对话系统。
SpringAI的使用超详细的解析——实现AI对话框功能
上个星期,本人学习了黑马的SpringAI教程以及阅读了其项目的前端代码之后,自己实现一个AI小项目。
这个项目放在了gitee上,地址是AI小项目,大家可以拉取代码学习。
接下了我将阐述总结的实现AI对话框功能的大致步骤。
第一步:大模型的准备
既然是实现AI对话框,那肯定需要准备AI大模型进行调用。
调用AI大模型有两种方法:-
- 本地部署,然后自己调用,但是有硬件限制,越好的大模型,需要更多的内存。
- 远程调用,通过平台提供的AI大模型的调用接口,进行调用,但是一般是需要收费的,当然用于个人学习的话也花不了几个钱。
本地部署
如果是本地部署的话,我们是部署deepseek,因为deepseek是开源的。
首先
我们需要下载一个Ollama的客户端,在官网提供了各种不同版本的Ollama,大家可以根据自己的需要下载。
官网地址是:https://ollama.com/
下载后双击即可安装(默认是安装在C盘)。
也可以指定安装路径,
命令行安装:
在OllamaSetup.exe所在目录打开cmd命令行,然后命令如下:
OllamaSetup.exe /DIR=你要安装的目录位置
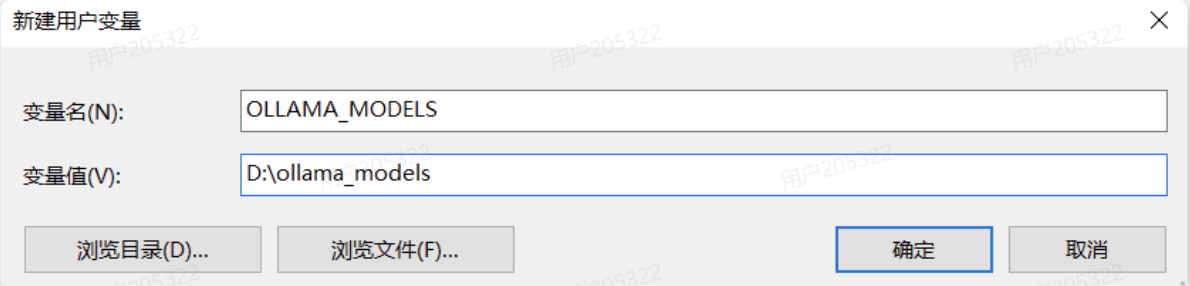
OK,安装完成后,还需要配置一个环境变量,更改Ollama下载和部署模型的位置。环境变量如下:
OLLAMA_MODELS=你想要保存模型的目录
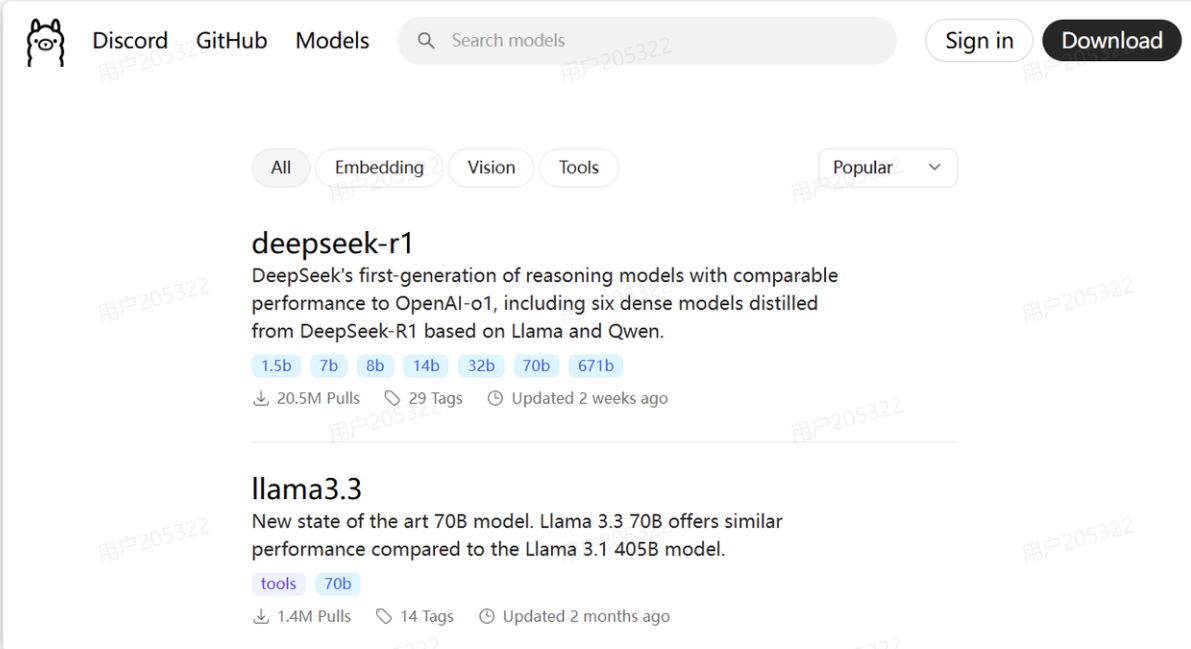
搜索并部署模型
ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型,我们可以在其官网上搜索自己需要的模型:
https://ollama.com/search
如图,目前热度排第一的就是deepseek-r1:
点击进入deepseek-r1页面,会发现deepseek-r1也有很多版本: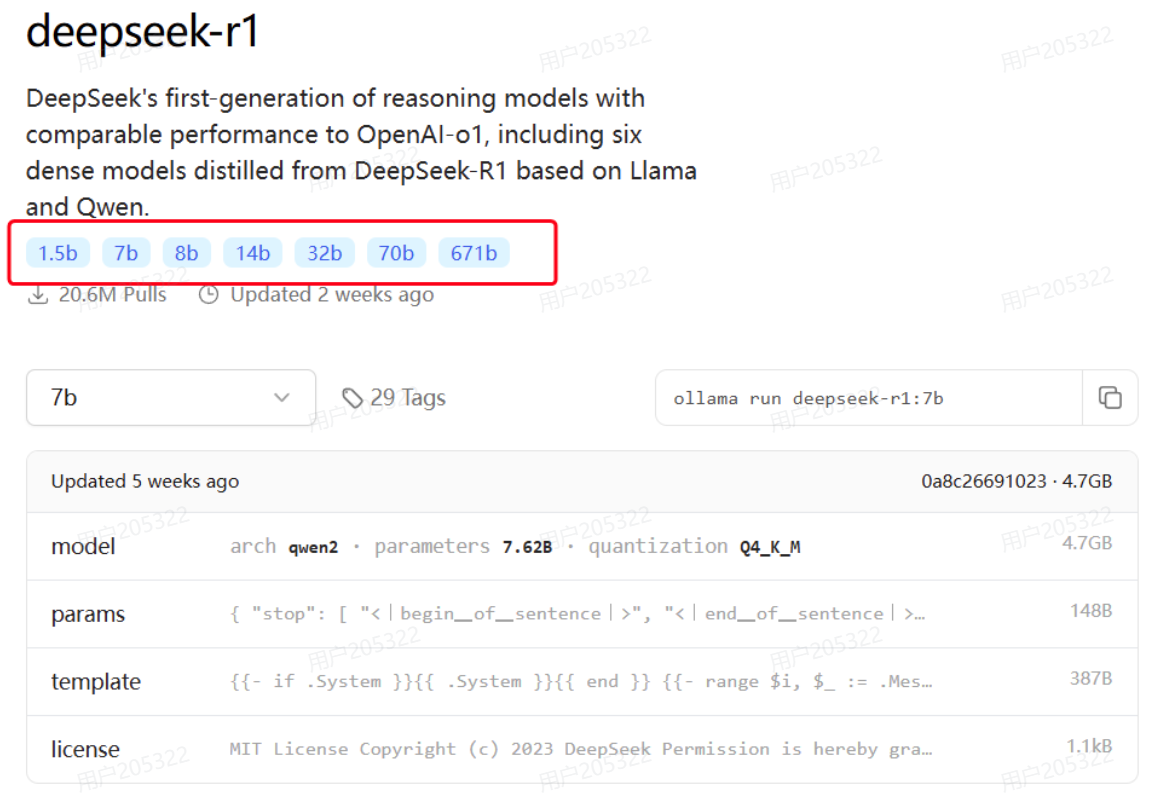
这些就是模型的参数大小,越大推理能力就越强,需要的算力也越高。671b版本就是最强的满血版deepseek-r1了。需要注意的是,Ollama提供的DeepSeek是量化压缩版本,对比官网的蒸馏版会更小,对显卡要求更低。对比如下: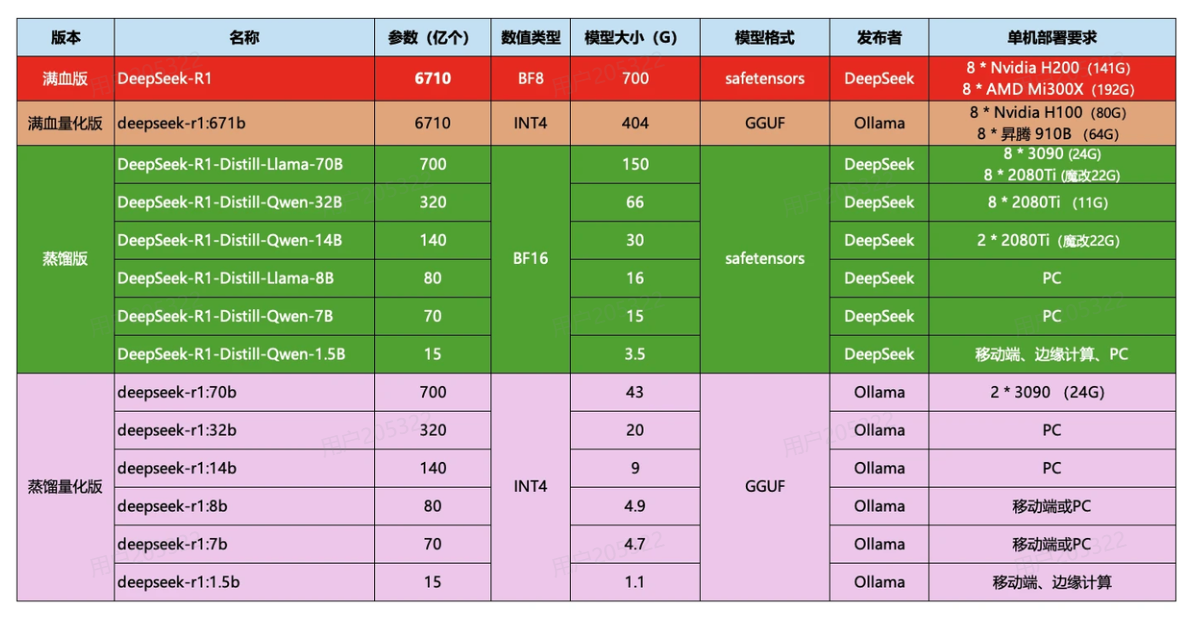
比如,我的电脑内存32G,显存是6G,选择部署的是7b的模型,当然8b也是可以的,差别不大,都是可以流畅运行的。
运行模型
选择自己合适的模型后,ollama会给出运行模型的命令: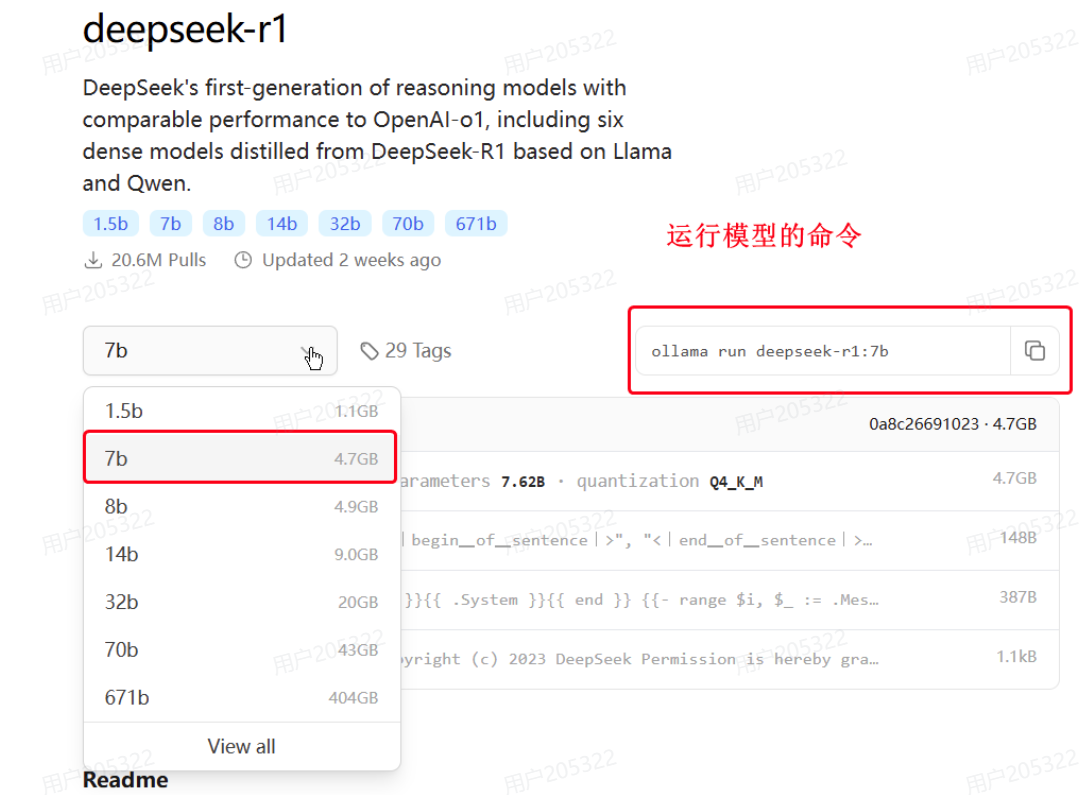
复制这个命令,然后打开一个cmd命令行,运行命令即可,然后你就可以跟本地模型聊天了: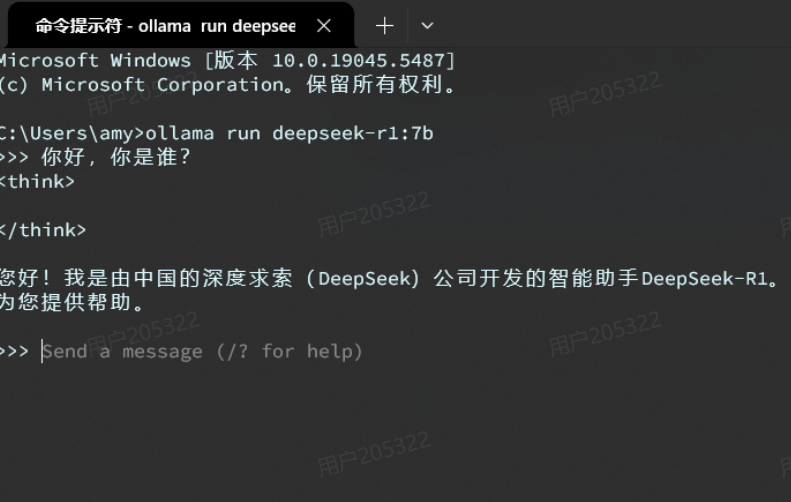
注意:
- 首次运行命令需要下载模型,根据模型大小不同下载时长在5分钟~1小时不等,请耐心等待下载完成。
- ollama控制台是一个封装好的AI对话产品,与ChatGPT类似,具备会话记忆功能。
远程调用
对于我们远程调用大模型,国内有很多平台,我使用的阿里云百炼平台,如果没有阿里云账号的伙伴需要先注册一个。
在网页进入阿里云之后搜索百炼,进入之后就是这样:
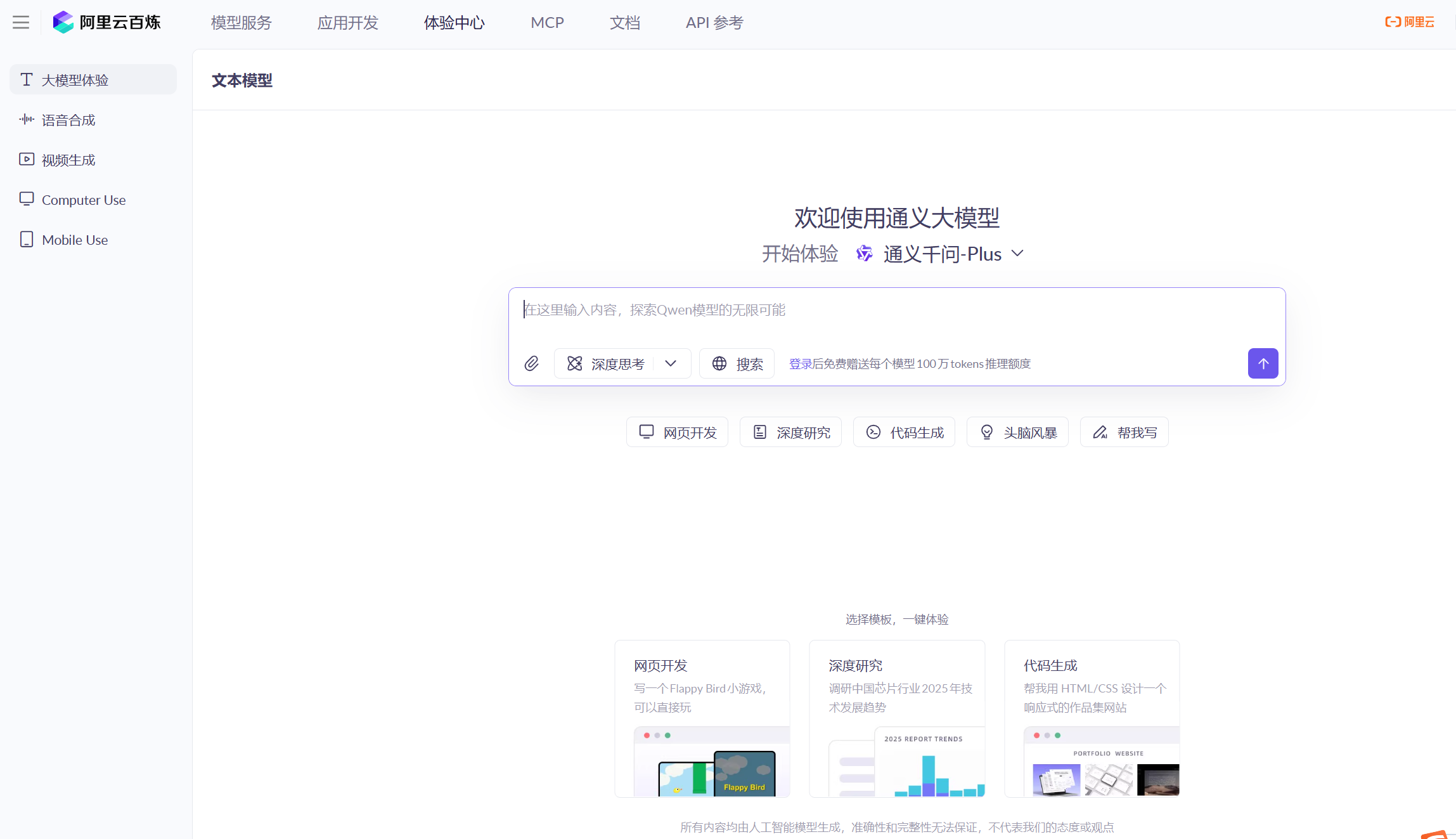
在模型服务中的模型广场中提供了很多模型,初始每个模型我们有100万token的调用额度,对于个人的学习完全的足够的。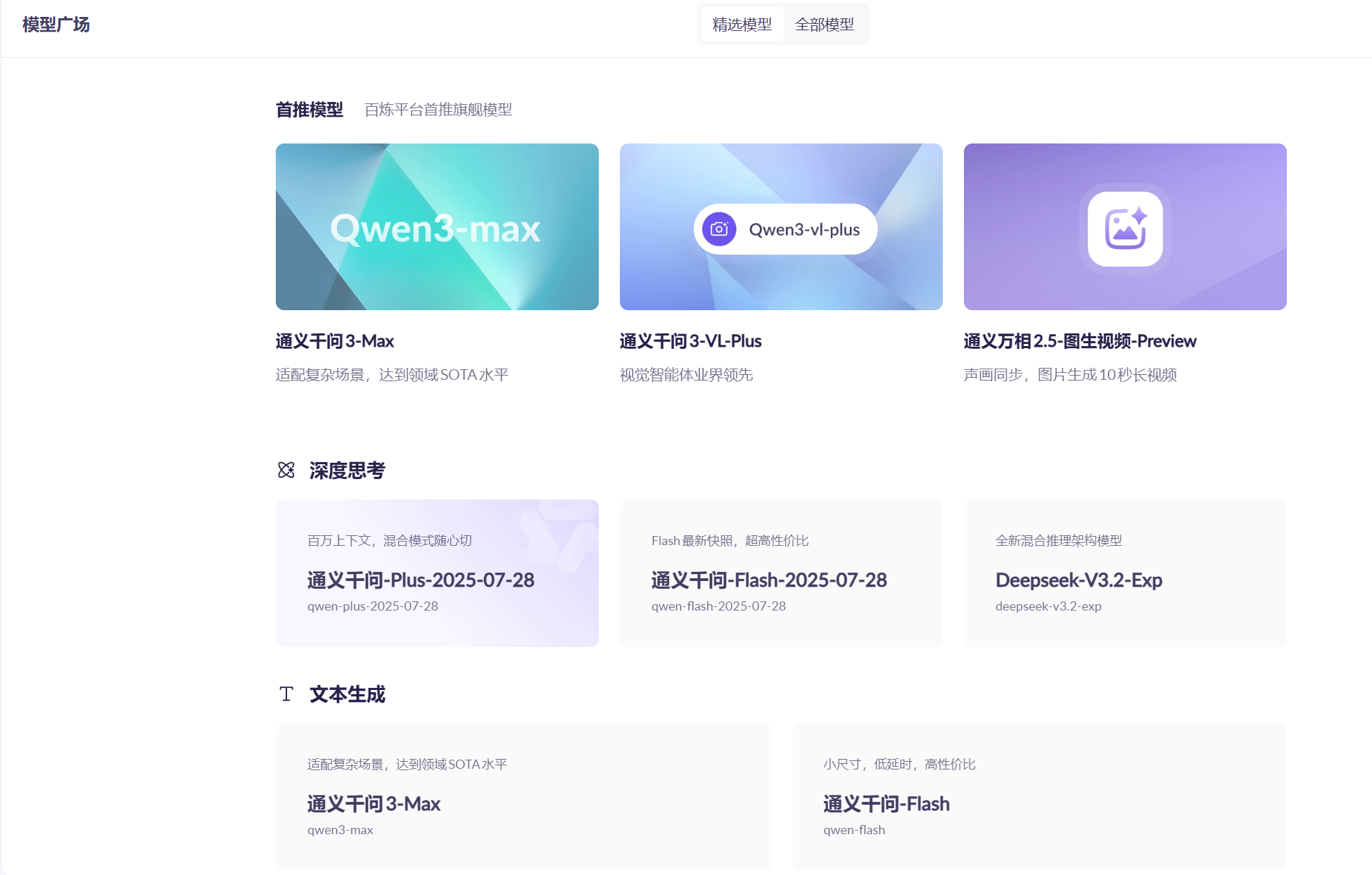
模型也有很多种类型,对于AI对话功能我们选择使用文本生成的模型就可以了。
无论是远程调用还是本地部署调用,我们调用的AI大模型暴露出来的接口,既然是接口,我们就需要遵循接口的调用规范,目前大多数大模型都遵循OpenAI的接口规范。
在调用接口之前,还需要先成生成好你的秘钥,在页面左下角的秘钥管理标签。
接口规范
我们以DeepSeek官方给出的文档为例:
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
# 1.初始化OpenAI客户端,要指定两个参数:api_key、base_url
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# 2.发送http请求到大模型,参数比较多
response = client.chat.completions.create(
model="deepseek-chat", # 2.1.选择要访问的模型
messages=[ # 2.2.发送给大模型的消息
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False # 2.3.是否以流式返回结果
)
print(response.choices[0].message.content)
接口说明
- 请求方式:通常是POST,因为要传递JSON风格的参数
- 请求路径:与平台有关
- DeepSeek官方平台:https://api.deepseek.com
- 阿里云百炼平台:https://dashscope.aliyuncs.com/compatible-mode/v1
- 本地ollama部署的模型:http://localhost:11434
- 安全校验:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
- 请求参数:参数很多,比较常见的有:
- model:要访问的模型名称
- messages:发送给大模型的消息,是一个数组
- stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
- temperature:取值范围[0:2),代表大模型生成结果的随机性,越小随机性越低。DeepSeek-R1不支持
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
- role:消息对应的角色
- content:消息内容
其中消息的内容,也被称为提示词(Prompt),也就是发送给大模型的指令。
这里的role有三种:system,user,assitant
-
system: AI回答基于的背景,就是在AI回答问题之前,你提供给AI的设定,举一个例子,你对deepseek说:你是谁?,deepseek就会说它是deepseek,但是你提前设置一下,背景例如“你叫小黑,你是动漫《罗小黑战纪》中角色,请以小黑的语气回答问题。”,那么你去问deepseek,它就会说:我是小黑…。这个System就是可以在用户使用前提前设置好背景。
-
user: 用户提出的指令
-
assitant:AI大模型的回答
值得注意的是:每次调用AI大模型的时候,我们不是仅仅将用户提出的指令返回,而是通过message数组将用户提出的指令一起拼接到message中,并将这个message发送给AI分析。
第二步:准备前端页面:
接下来这个步骤需要有一定的前端基础,特别是对vue3的使用。
我的项目中前端代码中有两个组件是使用AI对话框功能的,分别是AIChat.vue和ChatMessage.vue,
这个两个组件对于有vue3开发基础的人来说还是比较容易看懂的。当然如果没有使用过vue3也没有关系,
直接用我的项目运行就可以了。vue3项目的运行还是比较简单的,不会的伙伴可以先去网上搜。
第三步:准备后端服务
这里我们使用的java的Springboot和SpringAI,这个的配置是阿里云百炼平台调用AI接口的配置。
主要的配置如下:
spring:
application:
name: demo
datasource:
url: 数据库地址
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 密码
ai:
chat:
memory:
repository:
jdbc:
initialize-schema: always
openai:
api-key: 阿里云百炼的秘钥
base-url: https://dashscope.aliyuncs.com/compatible-mode
chat:
options:
model: 模型的名称
temperature: 0.7
这里需要引入数据库的配置是因为我们需要通过数据存储AI的历史对话信息。
依赖:
我这里使用SpringAI的依赖版本是1.10,JDK是17,SpringAI只支持17以上版本的JDK。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
OpenAI的配置类:
package com.energy.demo.config;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class OpenAIConfig {
//Open的客户端
@Bean
public ChatClient chatClient (ChatMemory chatMemory,OpenAiChatModel openAiChatModel) {
//AI的会话功能,在每次放回对话的时候,历史对话不会消失
MessageChatMemoryAdvisor build = MessageChatMemoryAdvisor.builder((chatMemory)).build();
return ChatClient.builder(openAiChatModel)
.defaultSystem("你是一个能减排查询系统软件中的智能助手,你的名字是小立,你的职责是为用户答疑解惑,请以温和的语气回答问题。")
.defaultAdvisors(
new SimpleLoggerAdvisor(),
build
)
.build();
}
//ChatMemory的配置类
@Bean
public ChatMemory chatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(20) // 设置每个会话窗口保留最近20条消息
.build();
}
}
持久化层(AI历史对话):
package com.energy.demo.reposity;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.messages.Message;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CopyOnWriteArrayList;
@Component
public class MemoryRepositoryImpl implements ChatMemoryRepository {
// 使用线程安全的Map来存储对话历史
// key: conversationId, value: 该对话的消息列表
private final Map<String, List<Message>> conversationStore = new ConcurrentHashMap<>();
private final Map<String, List<String>> typeListMap = new ConcurrentHashMap<>();
public List<String> getChatIdsByType(String type){
return typeListMap.getOrDefault(type,new ArrayList<>());
}
//主要是这三个方法的使用,save(),getTypeList(),clearAll()
public void save(String type,String chatId){
List<String> list = typeListMap.computeIfAbsent(type, k -> new ArrayList<>());
if(!list.contains(chatId)){
list.add(chatId);
}
}
public List<String> getTypeList(String type){
return typeListMap.getOrDefault(type, List.of());
}
// 添加一个清空所有对话的方法
public void clearAll() {
conversationStore.clear();
}
@Override
public List<String> findConversationIds() {
// 返回所有存在的对话ID
return new ArrayList<>(conversationStore.keySet());
}
@Override
public List<Message> findByConversationId(String conversationId) {
// 根据对话ID查找消息列表,如果不存在则返回空列表
return conversationStore.getOrDefault(conversationId, new ArrayList<>());
}
@Override
public void saveAll(String conversationId, List<Message> messages) {
// 保存或更新指定对话的消息列表
// 使用CopyOnWriteArrayList保证线程安全
conversationStore.put(conversationId, new CopyOnWriteArrayList<>(messages));
}
@Override
public void deleteByConversationId(String conversationId) {
// 删除指定对话的所有消息
conversationStore.remove(conversationId);
}
// 可选:添加一个获取所有对话统计信息的方法
public Map<String, Integer> getConversationStats() {
Map<String, Integer> stats = new ConcurrentHashMap<>();
conversationStore.forEach((conversationId, messages) -> {
stats.put(conversationId, messages.size());
});
return stats;
}
}
相关controller:
注意 :Flux这个是java提供的流式输出的字符串
package com.energy.demo.controller;
import com.energy.demo.reposity.MemoryRepositoryImpl;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
@RequestMapping("/ai")
@RestController
public class AIChatController {
@Resource
public ChatClient chatClient;
@Resource
public MemoryRepositoryImpl chatMemoryRepository;
@GetMapping(value = "/generate",produces = "text/html;charset=utf-8")
public Flux<String> generate(@RequestParam(value = "message", defaultValue = "你是谁?") String message){
//将用户信息发送给AI大模型并返回结果
Flux<String> content = chatClient.prompt()
.user(message).stream().content();
return content;
}
@PostMapping(value = "/chat",produces = "text/html;charset=utf-8")
public Flux<String> chat(String prompt,String chatId){
chatMemoryRepository.save("chat",chatId);
Flux<String> content = chatClient.prompt()
.user(prompt)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))//将数据添加到指定的会话的message数组中,然后在发送给AI大模型
.stream().content();
return content;
}
}
package com.energy.demo.controller;
import com.energy.demo.domain.vo.MessageVO;
import com.energy.demo.reposity.MemoryRepositoryImpl;
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.Message;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.stream.Collectors;
@RequiredArgsConstructor
@RestController
@RequestMapping("/ai/history")
public class HistoryController {
private final MemoryRepositoryImpl chatMemoryRepository;
private final ChatMemory chatMemory;
@GetMapping("/{type}")
public List<String> getChatIds(@PathVariable String type){
return chatMemoryRepository.getChatIdsByType(type);
}
@GetMapping("/{type}/{chatId}")
public List<MessageVO> getHistory(@PathVariable String type, @PathVariable String chatId){
List<Message> messages = chatMemory.get(chatId);
return messages.stream().map(MessageVO::new).collect(Collectors.toList());
}
}
最后实现的效果是:
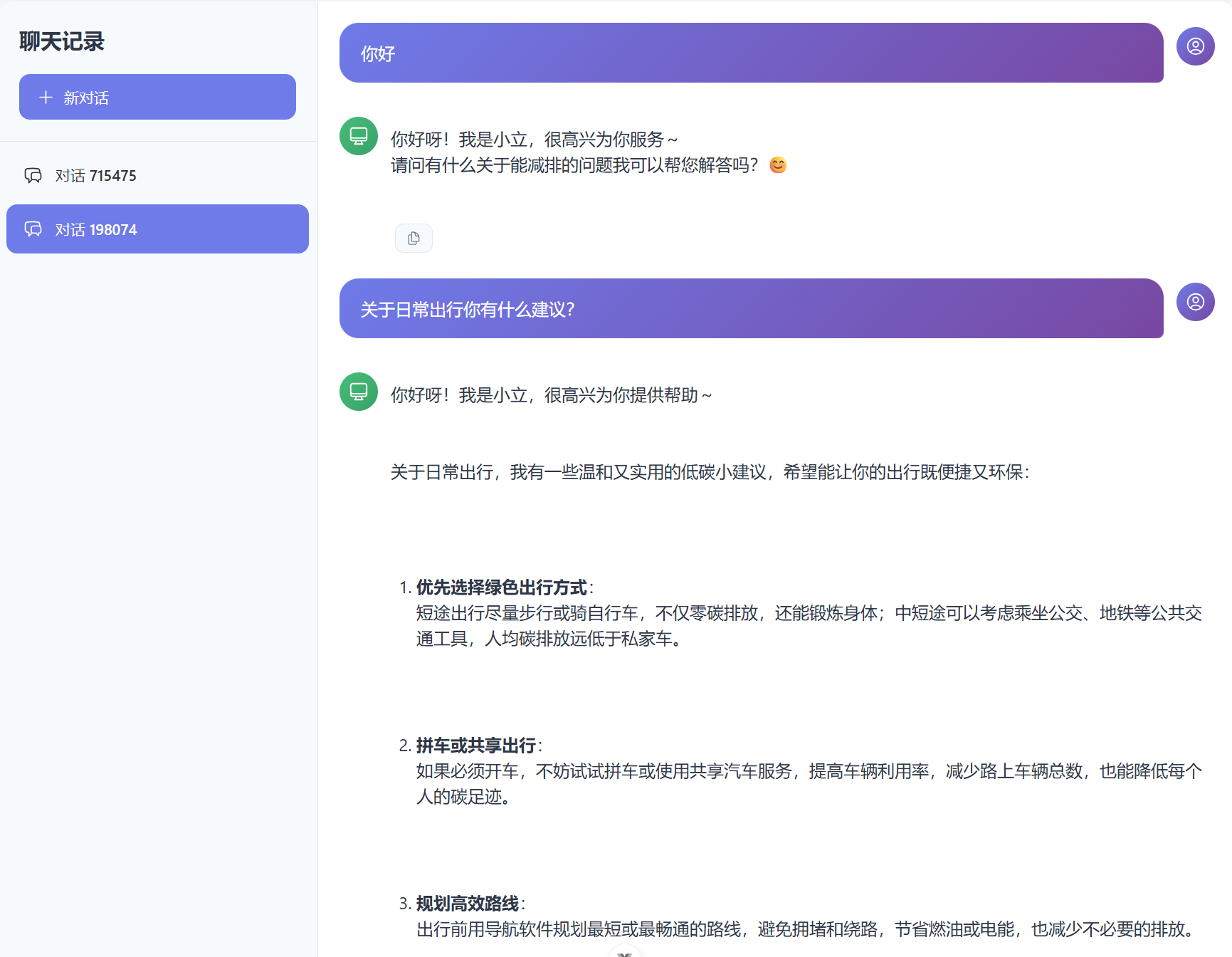
这里我没有实现文件上传的功能,只有聊天的功能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)