《openGauss 借力 AI 技术,实现数据库性能高效突破》
openGauss数据库通过AI技术实现智能运维与优化,主要包括:1)参数自调优(X-Tuner框架),可动态优化300+核心参数,某银行案例显示性能提升25%;2)慢SQL智能诊断(SQLDiag框架),电商案例中优化后响应时间从800ms降至120ms;3)智能监控预测,支持200+指标监控和提前预警。此外,还提供自适应索引推荐、库内AI计算引擎等功能,支持70+算法并实现"数据不离

一、智能运维 AI 自治能力
openGauss 通过 AI 技术实现运维自动化与问题预判,大幅降低 DBA 依赖,核心功能包括:
1. 参数自调优(X-Tuner 框架)
原理:基于强化学习和启发式算法,对内存分配、IO 优化等领域的 300+ 核心参数进行动态调整。支持秒级参数建议生成与问题定位,同时具备故障安全退出机制,避免对业务造成影响。
案例:某国有银行核心交易系统采用 X-Tuner 框架后,在峰值交易量提升 30% 的场景下,通过自动优化 shared_buffers、work_mem 等参数,将交易响应时间从 200ms 降至 150ms,性能提升 25%。
部署代码示例:
# 本地部署参数调优任务
xtuner tune --db-host 192.168.1.100 --db-port 5432 --db-user opengauss --db-name core_db --target-performance tps=5000
# 查看调优报告
xtuner report --task-id 202505101230 --format html --output /opt/xtuner_reports/
相关案例代码:
class DBParamManager:
def __init__(self, db_conn: Dict):
self.db_conn = db_conn
def get_current_params(self) -> Dict:
"""获取当前数据库关键参数"""
conn = psycopg2.connect(**self.db_conn)
with conn.cursor() as cur:
cur.execute("""
SELECT name, setting FROM pg_settings
WHERE name IN ('shared_buffers', 'work_mem', 'effective_cache_size',
'maintenance_work_mem', 'max_connections', 'checkpoint_completion_target')
""")
params = {row[0]: row[1] for row in cur.fetchall()}
conn.close()
return params
def apply_optimized_params(self, optimized_params: Dict):
"""应用优化后的参数"""
print(f"\n=== 应用优化参数 ===")
conn = psycopg2.connect(**self.db_conn)
conn.autocommit = True
try:
with conn.cursor() as cur:
for param, value in optimized_params.items():
# 使用 ALTER SYSTEM 修改参数(永久生效,需重启数据库)
cur.execute(f"ALTER SYSTEM SET {param} = %s", (value,))
print(f"设置 {param} = {value}")
# 重新加载配置(部分参数无需重启,立即生效)
cur.execute("SELECT pg_reload_conf()")
print("参数应用完成,已重载配置")
except Exception as e:
print(f"参数应用失败:{e}")
raise
finally:
conn.close()
灵活部署:支持本地物理机、虚拟机及远程云服务器部署,适配企业混合 IT 架构。
2. 慢 SQL 智能诊断与优化
技术优势:基于 SQL 向量化与时序预测算法(SQLDiag 框架),无需执行计划即可识别 OLTP/OLAP 全场景慢 SQL。5.1.0 版本通过 SRT_1~SRT15 细粒度阶段统计,将未知时间耗时控制在 10% 以内,根因分析准确率提升 35%。
案例:电商平台在大促前通过 SQLDiag 检测到一条商品搜索慢 SQL,系统自动定位到 “未使用联合索引” 及 “子查询嵌套过深” 两个根因,并生成优化建议。优化后,搜索接口响应时间从 800ms 降至 120ms,支撑了大促期间 流量的平稳运行。
相关代码:
def simulate_high_concurrency(self, optimized: bool = False, concurrency: int = 100) -> float:
"""模拟高并发场景"""
import threading
import queue
result_queue = queue.Queue()
category_id = 5 # 固定测试分类 5
min_price = 200.0
max_price = 800.0
def worker():
"""并发工作线程"""
try:
if optimized:
_, exec_time = self.search_products_optimized(category_id, min_price, max_price)
else:
_, exec_time = self.search_products_slow(category_id, min_price, max_price)
result_queue.put(exec_time)
except Exception as e:
result_queue.put(None)
print(f"\n=== 模拟并发请求({concurrency} 个并发)===")
threads = []
start_time = time.time()
# 启动并发线程
for _ in range(concurrency):
t = threading.Thread(target=worker)
t.start()
threads.append(t)
# 等待所有线程完成
for t in threads:
t.join()
# 统计结果
total_time = (time.time() - start_time) * 1000
valid_exec_times = [t for t in list(result_queue.queue) if t is not None]
avg_exec_time = sum(valid_exec_times) / len(valid_exec_times) if valid_exec_times else 0
print(f"并发完成时间: {total_time:.2f}ms")
print(f"平均响应时间: {avg_exec_time:.2f}ms")
print(f"成功请求数: {len(valid_exec_times)}/{concurrency}")
return avg_exec_time诊断代码示例:
-- 开启慢 SQL 诊断
SELECT opengauss_ai.sql_diag_enable(threshold_time=1000); -- 诊断执行时间超1000ms的SQL
-- 查看诊断结果
SELECT sql_id, total_time, top_issue, optimize_suggestion
FROM opengauss_ai.sql_diag_result
WHERE diagnose_time >= '2025-05-10 00:00:00';
3. 智能监控与异常预测
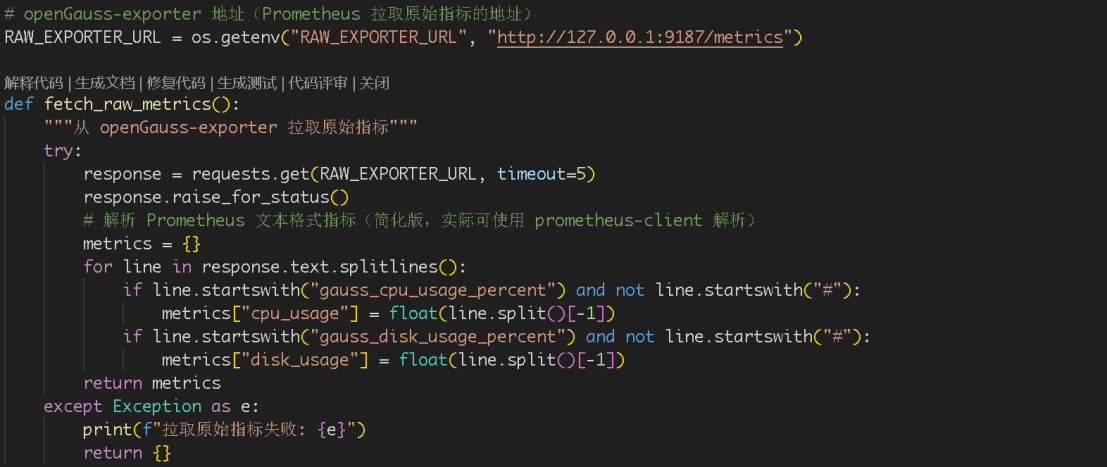
监控能力:支持 200+ 数据库指标全量采集,包括 wal_buffer 访问次数、满溢耗时、锁等待次数等关键维度,通过 LSTM 时序模型预测资源走势,提前 15-30 分钟预警性能瓶颈。

监控配置:
-- 创建 wal_buffer 监控规则
INSERT INTO opengauss_ai.monitor_rules (
rule_name, metric_name, threshold_type, threshold_value, alert_level
) VALUES (
'wal_buffer_overflow_warning',
'wal_buffer_overflow_count',
'hourly_increase',
10,
'warning'
);
-- 查看异常预警
SELECT alert_time, metric_name, current_value, alert_message
FROM opengauss_ai.alert_log
WHERE alert_level = 'warning' AND alert_time >= now() - interval '1 hour';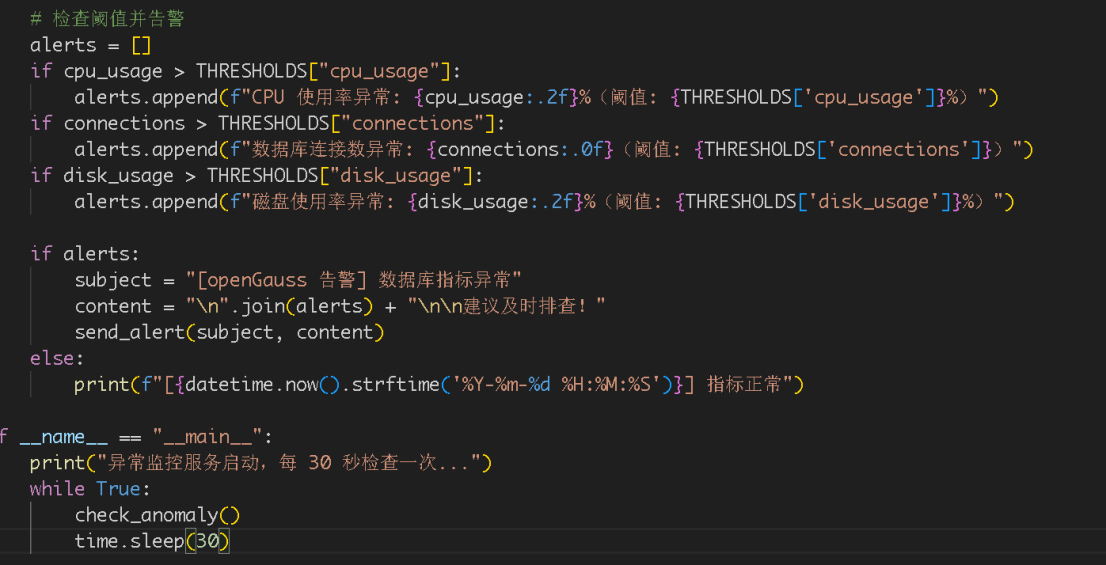
二、 智能查询优化AI 驱动的执行效率跃升

1. 自适应索引推荐
技术亮点:支持单条 SQL 最优索引推荐与 Workload 级索引集合生成,结合虚拟索引技术,可在不占用存储资源的情况下验证索引效果,降低试错成本。
索引代码:
-- 为单条SQL推荐索引
SELECT opengauss_ai.recommend_index(
sql_text => 'SELECT * FROM orders WHERE recipient_area = ''Beijing'' AND order_time >= ''2025-05-01'''
);
-- 创建虚拟索引验证效果
CREATE VIRTUAL INDEX idx_orders_area_time ON orders (recipient_area, order_time);
-- 查看虚拟索引性能测试报告
SELECT * FROM opengauss_ai.virtual_index_perf WHERE index_name = 'idx_orders_area_time';2. 深度学习驱动的代价预测
技术突破:智能优化器采用在线深度学习模型,实现查询计划片段级性能预测。准确率较 PostgreSQL 原生模型提升 40%,95 分位数准确率提升 3e5 倍,支持模型与数据库隔离部署,避免资源侵占。
模型部署代码示例:
# 部署独立的代价预测模型服务
docker run -d -p 8080:8080 --name og_cost_model opengauss/ai-cost-model:5.1.0
# 配置数据库连接模型服务
gs_guc set -N all -I all -c "ai_cost_model_url = 'https://192.168.1.200:8080/predict'"
# 验证模型效果
EXPLAIN ANALYZE SELECT user_id, count(*)
FROM user_behavior
WHERE behavior_time BETWEEN '2025-05-01' AND '2025-05-07'
GROUP BY user_id;三、AI 架构与算法生态融合
openGauss 从 2.1.0 版本起引入 DB4AI 能力,实现 “数据存储 - 模型训练 - 推理” 的栈内一体化,大幅降低 AI 应用开发门槛。
1. 库内 AI 计算引擎
优势:原生集成 AI 算子与执行计划,支持通过 SQL 直接调用模型训练与预测功能,无需编写 Python/R 算法代码,实现 “数据不离库” 的安全计算。
SQL 调用 AI 示例:
-- 1. 创建模型(逻辑回归算法)
CREATE MODEL customer_risk_model
USING logistic_regression
FEATURES age, income, policy_amount, claim_history
TARGET risk_level -- 目标变量:风险等级(低/中/高)
FROM insurance.policies
WHERE policy_date >= '2024-01-01';
-- 2. 模型训练
TRAIN MODEL customer_risk_model;
-- 3. 预测新客户风险
SELECT customer_id,
opengauss_ai.predict(customer_risk_model, age, income, policy_amount, claim_history) AS predicted_risk
FROM insurance.new_customers;2. 算法生态增强
生态覆盖:兼容 MADlib 生态,支持 70+ 基础算法,性能较 PostgreSQL 部署提升 3-5 倍;新增 XGBoost、GBDT、Prophet 等高级算法,强化时序预测、梯度提升能力。3.0.0 版本针对金融风控、用户画像场景优化算法性能。
时序预测代码示例(这里以30天为例,可以自己动态修改):
-- 1. 创建时序预测模型
CREATE MODEL transaction_forecast
USING prophet
TIME_COLUMN trade_date
TARGET_COLUMN amount
FROM finance.daily_transactions
WHERE trade_date BETWEEN '2024-01-01' AND '2025-04-30'
PARAMETERS (periods=30, seasonality_mode='multiplicative');
-- 2. 训练模型
TRAIN MODEL transaction_forecast;
-- 3. 查看预测结果
SELECT forecast_date, predicted_amount, lower_bound, upper_bound
FROM opengauss_ai.predict_model(transaction_forecast);四、向量数据库融合AI 应用的存储与检索底座
通过 openGauss+DataVec 一体化方案,实现结构化数据与向量数据的统一管理,为大 模型应用提供高效存储与检索能力。
高性能向量检索
基于鲲鹏 CPU 的 NEON/SVE 指令集实现 SIMD 加速,通过 DataVec 向量检索引擎,实现 “关键词 + 语义” 混合检索
向量操作代码示例:
-- 1. 创建向量表(存储文档向量与元数据)
CREATE TABLE doc_vectors (
doc_id INT PRIMARY KEY,
doc_title TEXT,
doc_content TEXT,
vec FLOAT[] -- 768维BERT向量
);
-- 2. 创建向量索引
CREATE INDEX idx_doc_vec ON doc_vectors USING datavec (vec)
WITH (metric='cosine', index_type='ivf_pq', nlist=1000, m=16);
-- 3. 向量检索(语义相似查询)
SELECT doc_id, doc_title,
opengauss_ai.vector_similarity(vec, '{0.12, 0.34, ..., 0.78}'::FLOAT[]) AS similarity
FROM doc_vectors
ORDER BY similarity DESC
LIMIT 10;五、 核心对比
|
版本号 |
核心AI特性 |
关键价值 |
|
1.1.0 |
1. 初步集成 AI 基础能力2. 支持参数调优功能3. 支持单条 SQL 索引推荐 |
奠定智能运维基础,初步降低 DBA 对参数调整、索引设计的人工依赖 |
|
2.1.0 |
1. 引入 DB4AI 架构2. 实现 SQL 直接调用 AI 模型3. 支持 20 + 基础算法 |
打破 “数据 - 算法” 割裂壁垒,降低 AI 应用开发门槛,无需额外编写 Python/R 算法代码 |
|
3.0.0 |
1. 算法库扩展至 70+2. 新增 XGBoost、Prophet 等高级算法3. 强化金融、互联网场景适配 |
丰富 AI 算法生态,提升复杂场景(如时序预测、梯度提升)处理能力,适配核心行业需求 |
|
5.1.0 |
1. 优化慢 SQL 根因分析逻辑2. 整合 DBMind 可视化界面3. 提升 AI 功能自动化与精细化程度 |
提升慢 SQL 问题定位效率,通过可视化降低 AI 功能使用门槛,实现 AI 运维更智能、更精细 |
在早期的 1.1.0 版本中,openGauss 已初步集成基础 AI 能力,具备参数调优与索引推荐功能。演进至 5.1.0 版本时,针对慢 SQL 的根因分析效能显著提升,同时完成DBMind 界面的深度整合,促使 AI 功能在精细化与自动化程度上实现进阶,这些 AI 特性使 openGauss 不仅是传统数据库,更成为支撑 AI 应用的 “数据 + 算力” 底座。
六、展望未来

在 AI 与数据库技术深度融合的趋势下,openGauss 的实践已经给出了清晰的答案。X-Tuner 框架带来的智能调优能力,不仅让数据库性能摆脱了传统手动优化的局限,更实实在在减轻了 DBA 的运维压力,让技术团队能把精力放在更核心的业务创新上。
从相关系统的落地效果来看,这种智能化升级不是空谈,而是能直接转化为业务效率的提升、用户体验的优化。未来,随着技术的持续打磨,openGauss 必然会在更多行业场景中发挥价值,用更省心的运维、更强劲的性能,为企业数字化转型保驾护航。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)