【AI大模型前沿】FLM-Audio:智源研究院开源的全双工音频对话大模型,开启自然流畅语音交互新时代
FLM-Audio 是一个具有革命性的音频对话大模型,它采用原生全双工架构,能够在每个时间步同时处理听觉、说话和独白通道的输入,从而实现低延迟、高自然度的全双工对话交互。该模型通过创新的自然独白和双重训练范式,有效解决了传统模型在语音对齐和交互流畅性上的难题,仅用约 100 万小时的音频数据就训练出了拥有 70 亿参数的强大模型,展现出卓越的鲁棒性和适应能力。
系列篇章💥
目录
前言
在人工智能飞速发展的当下,语音交互技术正逐渐渗透到我们生活的各个角落,从智能语音助手到在线教育平台,语音交互的便捷性和高效性为用户带来了全新的体验。然而,传统的语音交互模型往往存在响应延迟、无法实时打断等问题,限制了其在复杂场景下的应用。为了解决这一痛点,智源研究院联合 Spin Matrix 与新加坡南洋理工大学共同发布了 FLM-Audio,这是一个支持中文和英文的原生全双工音频对话大模型,它以其独特的技术架构和强大的功能,为语音交互领域带来了新的突破。
一、项目概述
FLM-Audio 是一个具有革命性的音频对话大模型,它采用原生全双工架构,能够在每个时间步同时处理听觉、说话和独白通道的输入,从而实现低延迟、高自然度的全双工对话交互。该模型通过创新的自然独白和双重训练范式,有效解决了传统模型在语音对齐和交互流畅性上的难题,仅用约 100 万小时的音频数据就训练出了拥有 70 亿参数的强大模型,展现出卓越的鲁棒性和适应能力。
二、核心功能
(一)全双工语音交互
FLM-Audio 实现了真正的“边听边说”,用户可以随时介入对话,模型也能即时暂停当前输出,理解新的指令或问题,并迅速作出回应。这种即时反馈机制带来了前所未有的流畅与自然,让用户仿佛在与真人对话,极大地提升了交互体验。
(二)多语种对话支持
无论是中文还是英文,FLM-Audio 都能轻松驾驭,为不同语言背景的用户提供无障碍的对话体验,满足了全球用户多样化的语言需求,拓宽了其应用场景。
(三)自然语音建模
模型采用“自然独白”的方式,模仿人类说话的节奏和韵律。结合“双重训练”策略,有效强化了语言理解与声学信号的对应关系,在保证低延迟的同时,也优化了语言建模的性能,使语音交互更加贴近人类的真实交流。
(四)低数据高效训练
仅需约 100 万小时的音频数据,便能训练出拥有 70 亿参数的强大模型。FLM-Audio 证明了在数据量并非决定性因素的情况下,通过优化训练方法和模型架构,依然能实现卓越的性能,尤其在嘈杂环境和频繁被打断的场景下,表现依然出色且自然。
(五)强鲁棒性
面对环境噪声或用户的突然打断,FLM-Audio 展现出惊人的适应能力。它能够迅速暂停正在进行的输出,准确捕捉并理解新的输入,并立即给出恰当的回应,确保对话的连续性和准确性,为用户提供了稳定可靠的交互保障。
(六)完全开源支持
FLM-Audio 的论文、模型权重以及源代码均已公开。这意味着研究人员和开发者可以轻松地在本地部署模型,并在此基础上进行二次开发和创新,极大地促进了其在学术研究和实际应用中的发展,为语音交互领域的技术进步提供了强大的动力。
三、技术揭秘
(一)原生全双工架构
FLM-Audio 采用原生全双工架构,在骨干模型的每个自回归步中,同时合并听觉、说话和独白通道的输入。这种架构设计避免了传统时分复用方案的高响应延迟问题,使得模型能够在同一时间步处理语音输入和输出,实现了真正的全双工交互。
(二)自然独白训练
传统的语音对齐方法依赖于逐词对齐,这不仅增加了预处理成本,还可能导致级联错误,并可能损害大型预训练模型的语言能力。FLM-Audio 引入了“自然独白”概念,采用连续 token 序列来表示文本独白,而非词级别的碎片化对齐。这种方法模仿了人类在对话中先形成连贯的内部独白,再进行语音表达的认知行为,有效解决了异步对齐问题,提升了语音交互的自然度和准确性。
(三)双重训练范式
为了进一步强化语言与声学语义的对齐,FLM-Audio 提出了“双重训练范式”。在不同的训练阶段中,自然独白会交替地领先或落后于音频流。这种训练方式使得模型能够在训练过程中更好地学习语言与声学信号之间的对应关系,提高了模型对语音内容的理解和生成能力,为全双工交互提供了坚实的技术基础。
(四)小数据高效训练
在训练过程中,FLM-Audio 仅使用了约 100 万小时的音频数据,相较于其他需要海量数据的模型,其数据量大幅减少。然而,通过优化训练方法和模型架构,FLM-Audio 依然能够实现卓越的性能。这种小数据高效训练的方式不仅降低了训练成本,还提高了模型的泛化能力和适应性,使其能够在不同的场景下表现出色。
四、性能表现
(一)音频理解
FLM-Audio 在音频理解任务上的表现尤为出色。通过自动语音识别(ASR)和语音问答(Spoken QA)两项任务的评测,FLM-Audio 在中文 ASR(Fleurs-zh)上优于非全双工架构的 Qwen2-Audio;在均使用原生全双工架构的前提下,FLM-Audio 使用更少的后训练数据在 LibriSpeech-clean 上显著优于 Moshi,印证了自然独白和双训练的优势。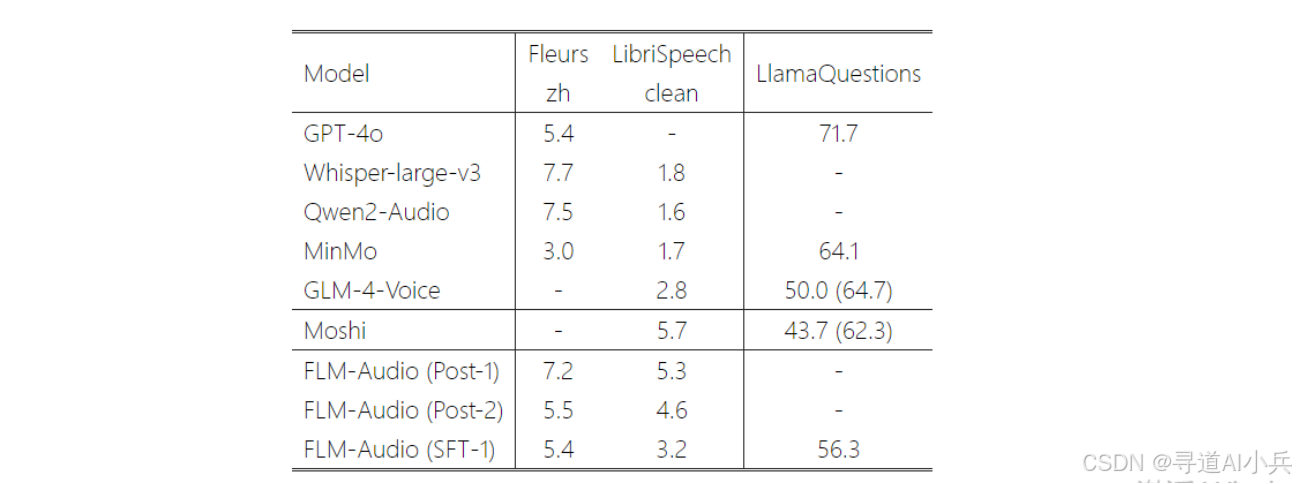
(二)音频生成
在音频生成方面,FLM-Audio 的表现也毫不逊色。其 TTS 的词错率(WER)与 Seed-TTS 等专业模型接近,生成的语音自然流畅,发音准确,能够为用户提供高质量的语音交互体验。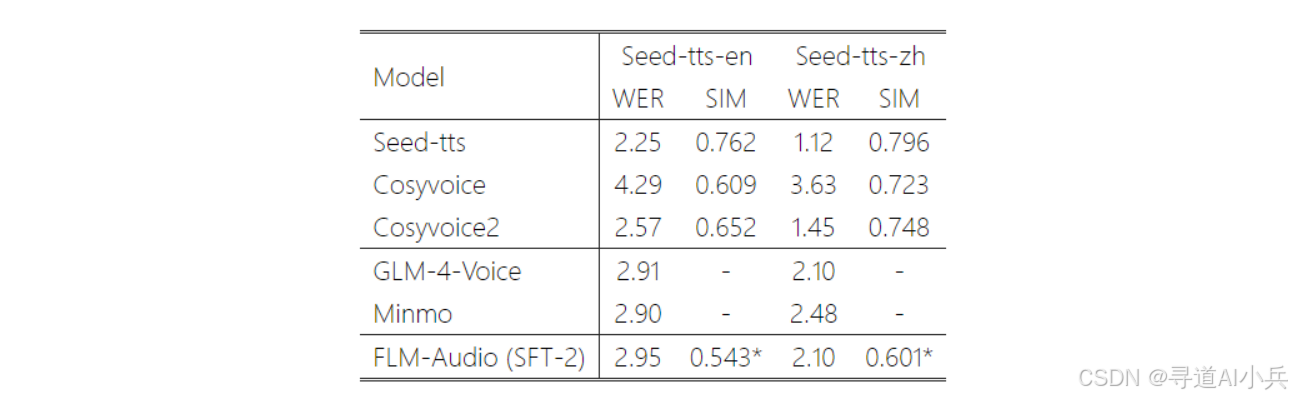
(三)全双工对话
在全双工对话任务中,FLM-Audio 的表现更是令人瞩目。其文本内容质量接近 Qwen2.5-Omni,但在流畅度和响应速度上更具优势。模型能够在 0.5 秒内停止当前输出并响应新输入,实现了真正的全双工交互能力,为用户提供了接近真人对话的交互体验。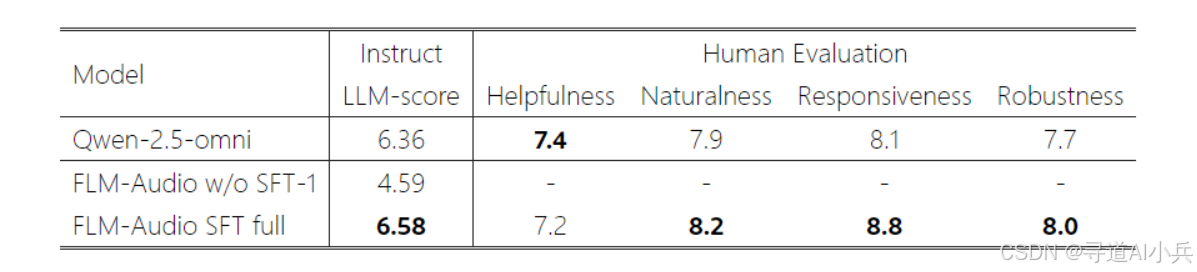
五、应用场景
(一)在线教育
FLM-Audio 可以作为在线教育平台的 AI 助教,实时回答学生的问题,提供个性化的指导和反馈。其全双工语音交互能力使得教学过程更加自然流畅,学生可以随时打断并提出问题,AI 助教能够即时回应,提高了教学效率和学生的参与度。
(二)游戏与虚拟现实(VR)
在游戏和虚拟现实领域,FLM-Audio 能够为 NPC 提供更加自然、智能的语音交互能力。NPC 可以实现不间断、可打断的自然语音互动,增强游戏的沉浸感和真实感,为玩家带来全新的游戏体验。
(三)智能客服
FLM-Audio 的低延迟对话能力和强鲁棒性使其成为智能客服领域的理想选择。它可以快速响应用户的问题,减少用户的等待时间,同时对噪声和用户打断具有较强的适应能力,能够提供准确、高效的服务,提升用户体验。
(四)智能陪伴
FLM-Audio 可以作为智能陪伴机器人,为用户提供更加接近真人的语音互动。它能够理解用户的情感和需求,提供贴心的陪伴和关怀,增强用户的生活幸福感。
(五)语音助手
在智能家居、智能办公等场景中,FLM-Audio 可以作为语音助手,为用户提供便捷的语音交互体验。用户可以通过语音指令控制家电、查询信息、安排日程等,FLM-Audio 能够实时响应并执行用户的指令,提高生活和工作的效率。
(六)会议辅助
在多人会议中,FLM-Audio 可以实时翻译、记录和互动,帮助与会者更好地理解和参与会议。它能够实时处理语音输入,提供准确的翻译和记录,同时支持与会者之间的实时交流和互动,提高会议效率。
六、快速使用
(一)克隆代码
克隆github仓库代码
git clone https://github.com/cofe-ai/flm-audio.git
cd flm-audio
(二)运行服务器
在部署 FLM-Audio 之前,需要先运行服务器。可以通过以下命令安装依赖并启动服务器:
pip install -r requirements-server.txt
python -m flmaudio.server --port 8990
(三)启动 Web UI
启动服务器后,可以使用 Web UI 来与 FLM-Audio 进行交互。运行以下命令安装依赖并启动 Web UI:
pip install -r requirements-clientgui.txt
python -m flmaudio.client_gradio --url http://localhost:8990
(四)启动 CLI
除了 Web UI,还可以通过命令行界面(CLI)与 FLM-Audio 进行交互。运行以下命令安装依赖并启动 CLI:
pip install -r requirements-clientcli.txt
python -m flmaudio.client --url http://localhost:8990
通过以上步骤,用户可以快速部署 FLM-Audio 并开始体验其强大的全双工语音交互功能。
七、结语
FLM-Audio 作为智源研究院联合 Spin Matrix 与新加坡南洋理工大学共同发布的原生全双工音频对话大模型,以其创新的技术架构和强大的功能,为语音交互领域带来了新的突破。它不仅实现了低延迟、高自然度的全双工对话交互,还通过自然独白和双重训练范式,解决了传统模型在语音对齐和交互流畅性上的难题。FLM-Audio 的开源特性也为研究人员和开发者提供了广阔的创新空间,相信它将在未来的发展中展现出更大的潜力,为语音交互技术的进步做出重要贡献。
项目地址
- GitHub 仓库:https://github.com/cofe-ai/flm-audio
- Hugging Face 模型库:https://huggingface.co/CofeAI/FLM-Audio
- 技术论文:https://arxiv.org/pdf/2509.02521

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)