大模型:微调和提示工程
大模型LLM:最清晰解读提示工程(Prompt Engineering)-CSDN博客
一、LLM三阶段
|
阶段 |
核心目标 |
数据需求 |
关键活动/产出 |
角色类比 |
|---|---|---|---|---|
|
预训练 |
构建通用知识底座与基础能力 |
海量无标注数据(互联网文本、书籍等) |
无监督 / 自监督学习,掌握词汇的含义、句子的构造规则以及文本的基本信息和上下文,产出基座模型,拥有了普遍适用的预测能力。 |
通识教育,培养一个“博学的学生” |
|
微调 |
使模型适配特定任务或领域,优化其行为 |
少量高质量标注数据或人类反馈 |
通过监督微调、指令微调、基于人类反馈的强化学习等方法,对模型权重进行细微调整,产出领域/任务专家模型。 |
专业培训,将通才塑造成律师、医生等专家 |
|
应用(推理) |
利用训练好的模型解决实际问题 |
用户输入的提示词,有时结合外部知识库 |
模型根据输入生成文本、代码或答案,参数固定,不学习。 |
实际工作,专家利用所学知识产出成果 |
大模型的训练过程通常分为两大阶段:预训练和微调。
二、提示工程和微调的区分
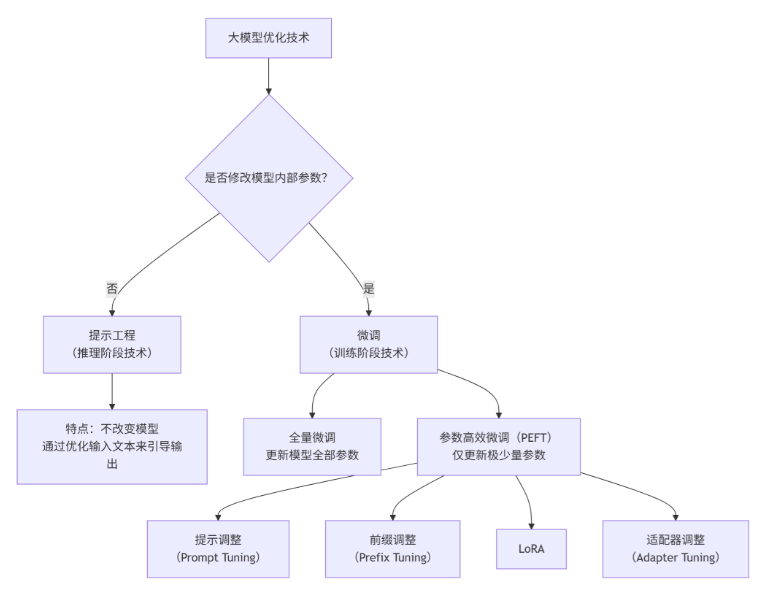
|
对比维度 |
提示工程 (Prompt Engineering) |
微调 (Fine-Tuning, 包括SFT) |
|---|---|---|
|
核心本质 |
使用模型的技巧(在考试时给考生递小纸条,提供解题思路和参考资料) |
训练/改造模型的方法(在考试前对考生进行专门的科目培训) |
|
应用阶段 |
推理/应用阶段 (Inference Time)。模型训练完成并部署后,每次用户提问时使用。 |
训练阶段 (Training Time)。在模型正式部署使用之前进行,是准备工作。 |
|
是否改变模型 |
不改变模型自身的任何参数或权重。 |
会改变模型的部分或全部参数,是永久性的。 |
|
关系 |
上下游协作:提示工程(如设计问答对)常被用来生成数据,这些数据随后可用于微调模型。 |
目标一致:两种技术的最终目标都是引导和激发大模型的能力,使其输出更符合我们的预期。 |
-
上下游协作关系:例如,要构建一个法律领域的专业模型,可以先利用提示工程技巧(如角色设定、复杂提问)让一个通用大模型生成大量高质量的“法律问答对”,这些生成出来的数据就可以作为微调所需的训练数据集。也就是说,提示工程可以作为微调的数据准备工具。
-
当我们收集成千上万个(指令,期望输出)样例,例如(“总结以下文字”, “……”),然后用这些数据去训练一个基础模型,这个过程叫做指令微调。经过指令微调的模型(比如ChatGPT),其遵循指令的能力会得到根本性的提升。
- 从可解释性分类,提示可分为:
- 硬提示:提示工程生成;
- 软提示:提示调整生成。
三、常见的微调几种类型
1. 按更新参数的规模划分
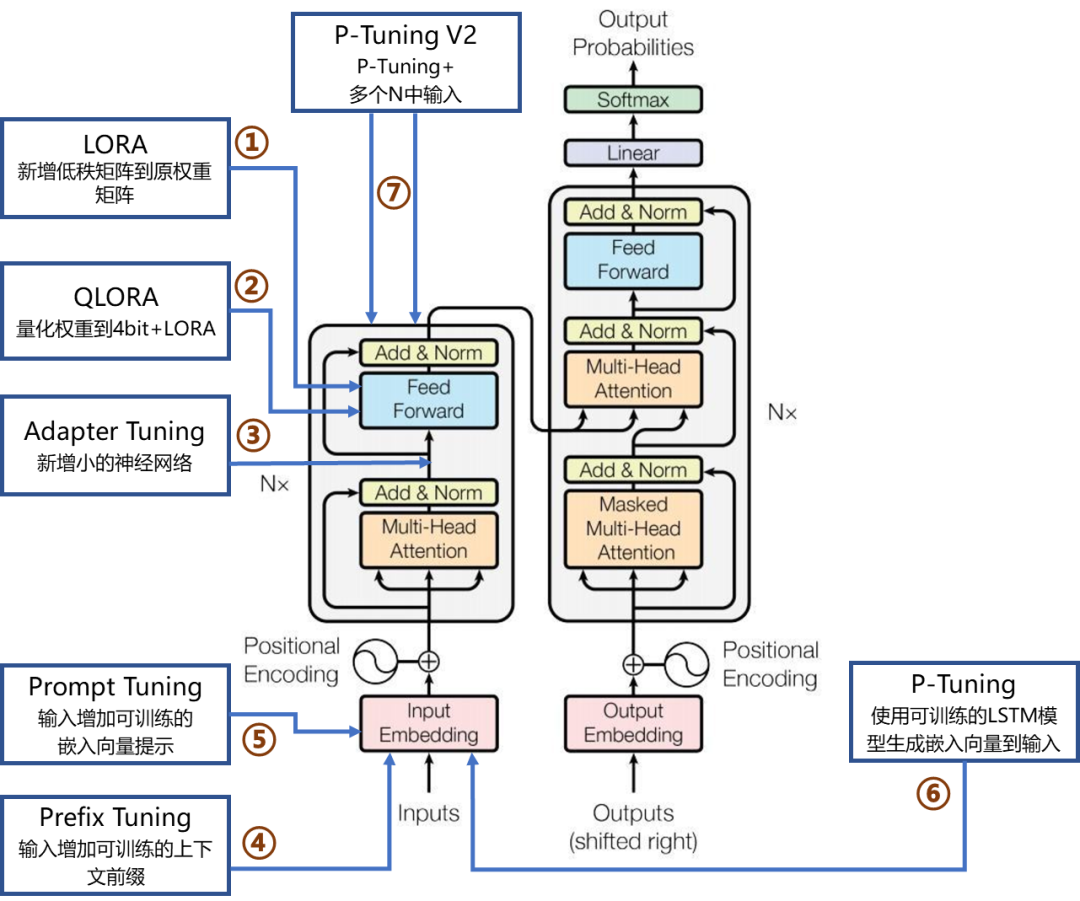
|
微调方法 |
核心原理 |
是否改变模型参数 |
作用层面/关键区别 |
训练成本 |
典型适用场景 |
|---|---|---|---|---|---|
| 全量微调 | 调整模型所有权重参数 | 是 | 极高 | 数据量充足、计算资源丰富、追求极致性能的专业领域任务。 | |
|
Adapter Tuning |
在Transformer块的前馈网络层后新增小的神经网络模块 |
是 |
模型中间层(图中②处) |
低 |
快速适应新任务 |
|
LoRA |
向模型内部的权重矩阵(如Q、V)新增低秩矩阵进行增量更新 |
是 |
模型权重内部(图中①处) |
低 |
资源有限时微调 |
|
QLoRA |
先将模型权重量化至4bit,再应用LoRA进行微调 |
是 |
模型权重内部(基于LoRA,图中①处) |
极低 |
大模型低成本微调 |
|
Prompt Tuning |
在输入序列前增加可训练的嵌入向量作为软提示 |
是 |
输入表示层(图中③处) |
极低 |
简单任务适配 |
|
Prefix Tuning |
在输入序列前增加可训练的上下文前缀向量,影响注意力机制 |
是 |
注意力机制层(图中④、⑤、⑥处) |
低 |
特定任务定制 |
|
P-Tuning |
引入一个可训练的LSTM模型来动态生成提示向量并添加到输入中 |
是 |
输入层(通过模型动态生成提示,图中⑦处) |
低 |
文本生成任务 |
|
P-Tuning v2 |
在模型的多个层(而不仅仅是输入层)都添加可训练的前缀向量 |
是 |
模型深层/注意力机制(图中④、⑤、⑥处) |
低 |
复杂任务微调 |
-
全量微调 (Full Fine-tuning, FFT)
- 定义:对预训练模型中的所有参数进行更新和调整。
- 特点:模型适应性最强,能最大程度地拟合新数据。
- 缺点:计算资源消耗极大(需要巨大的显存),且容易出现灾难性遗忘(Catastrophic Forgetting),即模型在学习新知识时忘记了原本预训练的通用知识。
-
参数高效微调 (Parameter-Efficient Fine-tuning, PEFT)
- 定义:冻结预训练模型的大部分参数,仅更新或添加极少量(通常小于 1%)的可训练参数。
- 特点:训练速度快,显存占用极低,且模型效果通常能逼近全量微调。
- 主流技术:
- LoRA (Low-Rank Adaptation):目前最流行的技术。通过在原有权重矩阵旁增加低秩矩阵来模拟参数更新,推理时不增加额外延时。
- QLoRA:结合了量化(Quantization)技术的 LoRA,可以在消费级显卡上微调大模型。
- Adapter:在Transformer层之间插入小型的神经网络模块(Adapter layers)。
- P-Tuning / Prefix Tuning:在输入层或隐层添加可训练的“提示词向量”(Soft Prompts),不改变模型主体结构。
2. 按训练目标和数据形式划分
-
有监督微调 (Supervised Fine-tuning, SFT)
- 定义:使用标注好的输入-输出对(Prompt-Response)数据进行训练。
- 作用:教会模型“如何说话”或执行特定任务(如摘要、问答、分类)。这是目前让基座模型(Base Model)变成聊天模型(Chat Model)的第一步。
- 关键点:数据质量比数量更重要,通常用于指令微调。
-
基于人类反馈的强化学习 (RLHF)
- 定义:引入奖励模型 (Reward Model),利用强化学习算法(如 PPO)来优化模型。
- 作用:让模型的输出更符合人类的价值观、偏好和安全标准(即对齐 Alignment)。
- 流程:SFT -> 训练奖励模型 -> PPO 强化学习。
-
直接偏好优化 (Direct Preference Optimization, DPO)
- 定义:一种较新的技术,跳过了显式的奖励模型建模步骤,直接利用偏好数据(A优于B)优化模型。
- 特点:比 RLHF 更稳定、更简单、计算开销更小,目前正在逐渐取代传统的 RLHF 流程。
-
无监督/自监督微调 (Unsupervised Fine-tuning)
- 定义:使用未标注的文本数据进行训练,通常形式与预训练类似(Next Token Prediction)。
- 作用:通常用于领域适应,即让模型熟悉某个特定领域(如医学、法律)的术语和行文风格。也常被称为持续预训练 (Continued Pre-training)。
3. 按应用场景划分
-
指令微调 (Instruction Tuning)
- 目标:增强模型遵循用户指令的能力。
- 数据:包含各种类型的任务指令(如“请把这段话翻译成英文”、“解释量子力学”)。
- 结果:模型泛化能力增强,能处理没见过的任务。
-
领域微调 (Domain Adaptation)
- 目标:注入特定行业的知识。
- 场景:金融大模型、医疗大模型、代码大模型。
- 注意:通常需要混合通用数据以防止能力退化。
-
对齐微调 (Alignment Tuning)
- 目标:确保模型有用、诚实且无害 (Helpful, Honest, Harmless - 3H原则)。
- 手段:通常通过 RLHF 或 DPO 实现
4.组合应用
| 你的现状与需求 | 推荐组合 | 难度系数 |
|---|---|---|
| 没钱/没卡,只是想让模型听话 | SFT + QLoRA | ⭐⭐ (入门) |
| 有一定资源,追求应用效果 | SFT + LoRA | ⭐⭐ (标准) |
| 行业术语太多,模型根本不懂 | 持续预训练 + SFT | ⭐⭐⭐⭐ (进阶) |
| 不仅要懂,还要回答得讨喜/安全 | SFT + DPO | ⭐⭐⭐⭐⭐ (专家) |
四、提示工程和提示微调的区别
|
对比维度 |
提示工程 |
提示微调 |
|---|---|---|
|
技术本质 |
一种与模型交互的“沟通技巧” |
一种训练模型的“微调方法” |
|
是否改变模型 |
完全不改变模型内部的任何参数(权重) |
需要训练并改变模型。它向模型中添加了一组可训练的“软提示”向量(如图中“作用层面”所示),并更新这些向量。 |
|
操作对象 |
模型的输入文本(即我们写的提示词) |
模型的参数(即那些“软提示”向量) |
|
所属阶段 |
推理/应用阶段:模型训练好后,每次使用时进行 |
训练阶段:在模型部署前进行,是准备工作的一部分 |
|
成本与数据 |
成本极低,无需训练,无需额外数据 |
需要计算资源进行训练,通常需要一定量的任务数据 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)