陈丹琦团队再出重磅!SLIM框架破解长程Agent上下文难题,ICLR 2026已投!
陈丹琦团队提出SLIM框架,破解长程智能体搜索的上下文管理难题。该研究针对现有框架因上下文溢出、工具预算耗尽等问题导致的性能下降,创新性地将检索拆分为独立搜索与浏览工具,并引入周期性轨迹总结机制。实验显示,SLIM在BrowseComp和HLE基准上分别达到56%和31%的准确率,超越开源基线8-4个百分点,同时减少4-6倍工具调用。该框架在o3、o4-mini和Claude-4-Sonnet等不
陈丹琦团队新研SLIM框架,破解长程智能体搜索“上下文困局”!当前主流框架常因上下文溢出、工具预算耗尽卡壳,该团队提出拆分“搜索-浏览”工具+周期性轨迹总结,让上下文更精简。以o3为基模,SLIM在BrowseComp达56%、HLE达31%,超开源基线8-4个百分点,工具调用还少4-6倍。跨o4-mini、Claude-4-Sonnet模型均稳优,还附自动化轨迹分析工具。这项ICLR2026 Under Review的研究,为长程搜索系统提供新范式。  相关论文代码有需要可自取可自取
相关论文代码有需要可自取可自取
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/PiGdhDl50fYqcOUDIzs2TA
https://mp.weixin.qq.com/s/PiGdhDl50fYqcOUDIzs2TA
1. 【导读】

论文基本信息
论文标题:LOST IN THE MAZE: OVERCOMING CONTEXT LIMITATIONS IN LONG-HORIZON AGENTIC SEARCH
作者:Howard Yen、Ashwin Paranjape、Mengzhou Xia、Thejas Venkatesh、Jack Hessels、Danqi Chen、Yuhao Zhang
作者机构:Princeton Language and Intelligence, Princeton University;Samaya AI
论文来源:ICLR2026 Under Review
论文链接:https://arxiv.org/abs/2510.18939v1
项目链接:https://github.com/howard-yen/SLIM
2. 【论文速读】
长程智能体搜索(long-horizon agentic search)需通过长轨迹迭代探索网络并整合多源信息,是深度研究系统等强大应用的基础。现有主流智能体搜索框架因上下文限制难以适配长轨迹任务,常出现累积冗长噪声内容、触及上下文窗口与工具预算上限或过早停止等问题。为此,研究提出SLIM(Simple Lightweight Information Management)框架,将检索拆分为独立的搜索与浏览工具,并定期总结轨迹,在保持上下文简洁的同时支持更长、更聚焦的搜索。在长程任务中,SLIM以显著更低的成本和更少的工具调用实现了与优秀开源基线相当的性能,为长程智能体搜索系统的研究提供了参考。
3.【长程搜索的“困境与呼唤”:从需求到挑战】
3.1 任务价值:长程智能体搜索是复杂应用的核心基础
长程智能体搜索需通过长轨迹迭代探索网络、整合多源信息,是深度研究系统(如OpenAI、Google等推出的相关工具)等复杂应用的关键支撑,能解决需大量信息收集与跨源推理的复杂任务,因此成为领域重点研究方向。
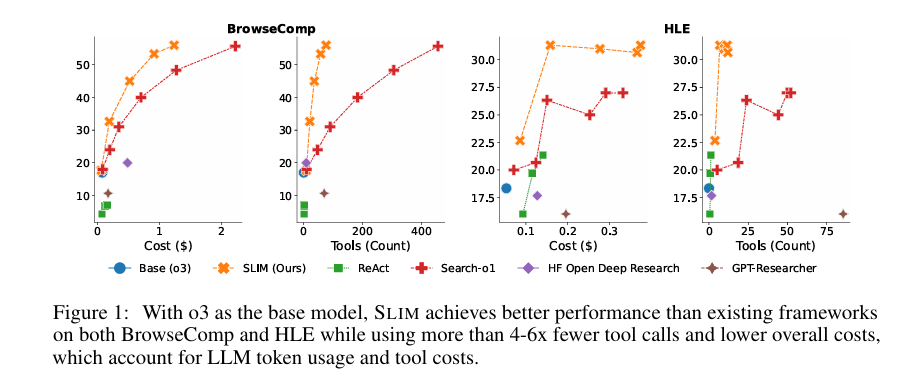
SLIM achieves better performance than existing frameworks
3.2 现有框架局限:多路径受阻于“上下文管理难题”
当前主流框架(如单智能体的REACT、SEARCH-O1,多智能体的HF-ODR、GPT-Researcher)在长轨迹任务中表现不佳:超50%样本失败,核心原因是上下文限制——要么累积噪声内容填满上下文窗口,要么耗尽工具预算,或因设计缺陷过早停止,无法有效完成长程信息收集。
3.3 任务特性差异:长程搜索与传统QA的“本质不同”
传统信息检索任务(如开放域问答)多为事实性问题,单源即可解答,依赖静态检索增强生成(RAG)系统仅需少数检索步骤;而长程搜索面对复杂查询,需大量工具调用收集信息、跨源推理合成答案,且常用网络作为语料库(含URL、标题、内容),存在搜索结果噪声多、爬取效率低等问题,传统工具设计难以适配。
4.【长程智能体搜索“说明书”:任务、数据与现有方案】
4.1 任务定义:拆解长程智能体搜索的核心要素
-
任务目标:给定查询、文档语料库,系统需执行一系列工具调用从中获取相关信息,输出最终答案,并与标注的真实答案对比验证。
-
工具设计:核心组件为工具函数,可将系统生成的任意输入映射为任意输出;多数系统受工具预算限制(即轨迹最大工具调用次数,每轮对应1次工具调用,部分架构支持并行调用但未被测试模型使用)。
-
上下文管理:需设计如何在多轮工具调用中管理基础LLM的输入上下文,且最终输出答案不计入工具预算。
-
语料与工具特性:长程任务常用网络作为语料库,单篇文档含URL、标题、内容;需通过搜索引擎获取相关网页列表,再经爬取操作获取完整内容(爬取过程存在速度慢、噪声多的问题)。
-
与传统QA的差异:传统QA任务查询简单、语料小(如Wikipedia),检索工具仅需调用1次即可返回全量文档及内容;而长程搜索需大量工具调用,传统“单次搜索+全量爬取”的工具设计易导致上下文过载,需更高效的工具接口。
4.2 数据集介绍:两大基准测试长程搜索能力
研究选取两类需长轨迹搜索、答案可验证的数据集,各随机抽样300个实例用于评估(因长程系统运行成本高):
-
BrowseComp(Wei et al., 2025):含难以获取信息的挑战性查询,核心测试系统“长轨迹 exhaustive 搜索网页、收集必要信息”的能力,所有查询经人工验证需在开放网页搜索超10分钟,对长程系统难度极高。
-
Humanity’s Last Exam(HLE; Phan et al., 2025):覆盖生物、数学、物理等多领域专业话题,需结合领域知识与推理,测试系统“利用网络获取信息辅助推理类问题”的能力,问题经领域专家审核,现有系统准确率普遍较低,研究仅使用其文本子集评估文本类系统。

4.3 现有方案梳理:四类主流框架的设计差异
通过工具数量、输入上下文管理、总结机制等维度,梳理当前四类典型长程智能体搜索框架,具体差异如下表(核心信息提炼):
| 框架 | 架构类型 | 工具数量 | 核心工具 | LLM上下文输入 | 总结机制 |
|---|---|---|---|---|---|
| REACT | 单智能体 | 1 | 检索(合并搜索+浏览) | 所有搜索结果 | 无 |
| SEARCH-O1 | 单智能体 | 1 | 检索(合并搜索+浏览) | 所有搜索结果 | 仅总结检索到的内容 |
| HF-ODR | 多智能体 | 11 | 搜索、浏览、Python等 | 筛选后的搜索结果 | 仅总结搜索智能体结果 |
| GPT-R | 多智能体 | 1 | 检索(合并搜索+浏览) | 所有搜索结果 | 仅总结检索到的内容 |
5.【破局长程搜索:旧框架困境与SLIM创新方案】
5.1 现有框架的三大核心失效模式
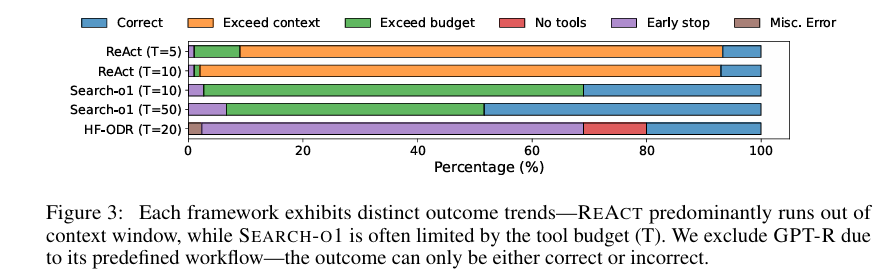
以BrowseComp为测试基准,现有主流框架在长轨迹任务中失败率超50%,核心失效模式源于上下文管理缺陷,具体表现为:
-
上下文窗口溢出:以REACT为代表,单次检索返回全量网页内容并拼接至上下文,长轨迹中易触发LLM上下文限制,被迫放弃工具调用仅依赖基础模型回答。
-
工具预算耗尽:以SEARCH-O1为代表,每轮检索需爬取所有搜索结果,即使仅少数结果相关,仍消耗大量工具调用与LLM tokens,导致预算快速耗尽,难以支撑长轨迹探索。
-
过早停止或工具闲置:以HF-ODR为代表,复杂的多智能体协作流程导致约10%轨迹未使用任何工具,且管理器智能体无法有效联动搜索智能体进行多轮探索,常提前终止任务。
5.2 SLIM框架的核心设计原则
SLIM(Simple Lightweight Information Management)以“精简上下文、高效工具调用”为核心,遵循两大原则:
-
提供简单灵活的工具接口,支持LLM按需探索,避免无效工具消耗;
-
最小化噪声信息输入,通过周期性总结维持上下文简洁,适配长轨迹搜索。
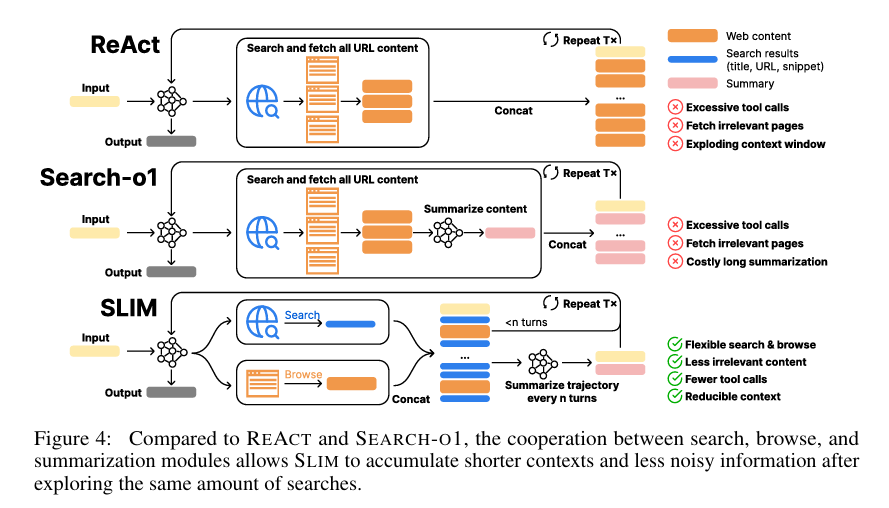
5.3 SLIM的三大核心组件
5.3.1 搜索工具(Search Tool)
-
功能:作为网络探索主入口,仅返回搜索引擎Top-k结果(含标题、URL、简短片段),不直接返回全量网页内容;
-
优势:相比传统“搜索+爬取”捆绑设计,避免上下文被噪声内容占用,减少无效工具调用。
5.3.2 浏览工具(Browse Tool)
-
功能:针对搜索结果中潜力页面深度挖掘,函数定义为,即从URL 对应的内容 中,筛选出与查询 最相关的片段;
-
优势:仅爬取并返回目标相关内容,大幅降低爬取成本与上下文冗余,效率优于“全页爬取”模式。
5.3.3 总结模块(Summarization Module)
-
功能:每经过 轮工具调用后,对整个对话轨迹进行总结,用摘要替换原始轨迹;
-
优势:区别于传统“单轮搜索结果总结”,实现全轨迹压缩,持续维持上下文简洁,支撑更长轨迹探索。
5.4 SLIM的工作流程
-
初始化:输入查询 ,初始化上下文 ,工具集为{搜索、浏览};
-
迭代探索:每轮由LLM自主选择调用搜索工具(获取潜力结果)或浏览工具(深挖目标页面),工具输出追加至上下文;
-
周期性总结:每 轮工具调用后,通过LLM对上下文总结压缩,替换原始轨迹;
-
终止输出:LLM判断信息足够时输出最终答案,或达到工具预算 时终止并生成答案。
6.【SLIM实战成绩单:性能、成本双优的长程搜索表现】
6.1 核心实验设置
-
基础模型:采用o3、o4-mini、Claude-4-Sonnet三类模型,覆盖不同规模与训练策略;
-
评估维度:包括任务得分(BrowseComp、HLE基准)、工具调用次数、token消耗、总成本(含LLM token与工具费用);
-
数据处理:每数据集随机抽样300个实例,排除缓存输入token计算成本(贴合实际系统缓存机制),结果取所有实例平均值。
6.2 以o3为基础模型的核心结果
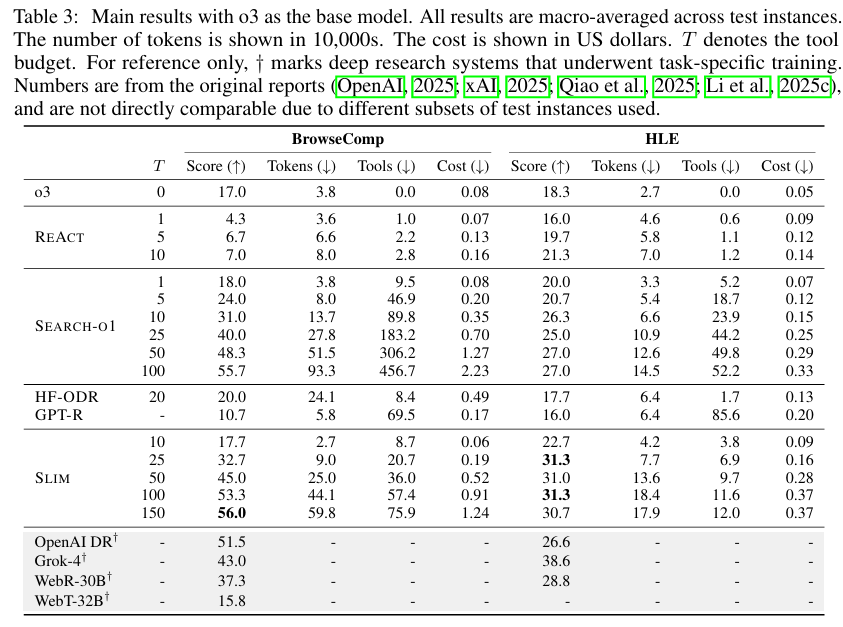
在相同成本预算下,SLIM显著优于开源基线,具体表现为:
-
任务得分:BrowseComp达56%、HLE达31%,分别比所有开源框架(如SEARCH-O1、HF-ODR)高出8和4个绝对百分点;
-
效率优势:工具调用量仅为SEARCH-O1的15%-25%(即减少4-6倍),且在BrowseComp上支持150轮探索,成本低于SEARCH-O1 50轮设置,同时性能更高;
-
对比细节:SEARCH-O1需50轮、1.27美元成本才达BrowseComp 48.3分,而SLIM 150轮仅1.24美元即达56分,成本相近但性能提升显著。
6.3 跨模型泛化性结果
SLIM在不同基础模型上均保持优势,验证设计通用性:
-
o4-mini模型:BrowseComp最高达37%(150轮),HLE达26.7%(100轮),工具调用量仅为SEARCH-O1的10%左右,成本降低超50%;
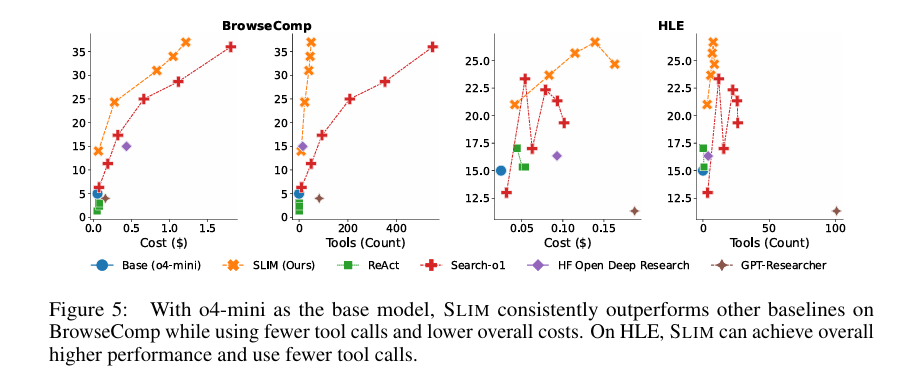
-
Claude-4-Sonnet模型:在BrowseComp和HLE上均优于REACT、SEARCH-O1等基线,且HF-ODR仅在该模型上表现接近SLIM(因工程化提示适配),进一步凸显SLIM设计的普适性。
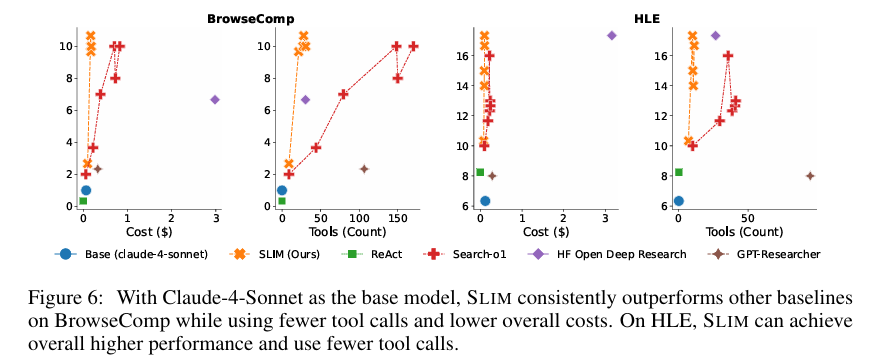
6.4 与专有系统的参考对比
虽因测试子集不同无法直接对标,但SLIM与专有深度研究系统表现接近:
-
OpenAI DR在BrowseComp得51.5%,SLIM以o3为模型达56%,超出4.5个百分点;
-
Grok-4在HLE得38.6%,SLIM达31%,差距较小,且SLIM为开源框架,成本与工具调用效率更具优势。
7.【长程搜索新范式:SLIM的突破与未来方向】
本研究针对长程智能体搜索中现有框架受上下文限制(溢出、预算耗尽、过早停止)的核心问题,提出SLIM框架——通过拆分“搜索-浏览”工具、周期性轨迹总结,实现了更低成本(减少4-6倍工具调用)与更高性能(BrowseComp 56%、HLE 31%,超开源基线8-4个百分点),且在o3、o4-mini、Claude-4-Sonnet跨模型测试中表现稳定;同时发布自动化轨迹分析 pipeline 与错误分类体系,发现SLIM幻觉现象更少。未来可进一步优化SLIM的高弃权率与答案忽略问题,也希望其工具设计与分析方法为长程智能体搜索系统的发展提供参考。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/PiGdhDl50fYqcOUDIzs2TA
https://mp.weixin.qq.com/s/PiGdhDl50fYqcOUDIzs2TA

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)