深度学习4大CNN全维度详解+实战代码(ResNet、DenseNet、EfficientNet、MobileNet),小白必看
想做手机APP、智能手表上的图像识别:选MobileNet;想在服务器上快速得到高精度结果:选EfficientNet;刚入门CNN,想理解深层网络原理:选ResNet;只有少量数据,想让模型充分利用特征:选DenseNet。ResNet、DenseNet、EfficientNet、MobileNet四大模型,分别从“深度扩展”“特征重用”“效率平衡”“轻量化”四个角度解决了传统CNN的痛点,构成
卷积神经网络(CNN)是计算机视觉的“基石模型”,但普通CNN随着深度增加会陷入梯度消失、参数量爆炸的困境。而ResNet、DenseNet、EfficientNet、MobileNet这4个“顶流模型”,凭借颠覆性创新解决了这些痛点,至今仍是工业界和科研界的核心工具。本文将用通俗案例拆解核心原理,搭配小白友好的实操项目,让你从“看不懂”到“上手跑通”,轻松掌握四大模型的精髓!

一、通俗案例:用生活场景理解四大模型的核心创新
在讲复杂原理前,先通过3个生活场景,让你秒懂每个模型的设计思路:
1. ResNet:“爬山走捷径”——残差连接打破梯度消失
普通CNN像“徒手爬山”,层数越多(山路越长),能量越少(梯度消失),爬到山顶(训练收敛)越来越难。ResNet的核心是“残差捷径”(Skip Connection),就像爬山时遇到陡峭路段,直接搭个“绳索”滑过去,不用硬扛:
- 主线(残差路径):继续爬山(提取复杂特征);
- 捷径(恒等映射):直接跳过部分山路(特征不经过复杂卷积,直接传递);
- 最终效果:能量(梯度)能通过捷径“回流”,深层网络也能轻松训练。
2. DenseNet:“多人协作搬砖”——密集连接重用特征
ResNet是“自己走捷径”,DenseNet则是“大家一起协作”。普通CNN的特征是“单向传递”(前一层只给后一层),DenseNet让每一层都接收所有前面层的特征,就像搬砖时,每个人都能用到其他人已经搬好的砖,不用重复劳动:
- 比如第5层不仅接收第4层的特征,还接收第1-3层的特征;
- 优势:特征重用率极高,参数量更少,泛化能力更强。
3. MobileNet:“高效分工干活”——深度可分离卷积压缩模型
普通CNN像“一个人干所有活”(用3×3卷积同时处理空间信息和通道信息),效率低、耗资源。MobileNet的“深度可分离卷积”像“分工合作”:
- 第一步(深度卷积):每个人只负责一个“专业领域”(每个通道单独用3×3卷积提取空间特征);
- 第二步(逐点卷积):专门有人协调汇总(用1×1卷积融合所有通道的特征);
- 优势:参数量和计算量仅为普通CNN的1/8~1/10,完美适配手机、嵌入式等移动端设备。
4. EfficientNet:“精准调参大师”——复合缩放平衡效率与性能
之前的模型要么“堆深度”(ResNet),要么“堆宽度”(MobileNet),都是“盲目调参”。EfficientNet像“精准调参大师”,通过复合缩放策略(同时调深度、宽度、分辨率),让模型在“参数量少”和“准确率高”之间达到完美平衡:
- 比如普通模型只把深度从10层加到20层,EfficientNet会同步把宽度从32通道加到64通道、输入分辨率从224×224加到448×448;
- 优势:用1/10的参数量,实现比传统模型更高的准确率。
二、核心原理详解:公式+结构,吃透四大模型
(一)ResNet:残差连接——让深层网络“活”起来
1. 核心创新:残差块(Residual Block)
ResNet的灵魂是“残差块”,通过“恒等映射捷径”跳过1~2个卷积层,解决梯度消失问题。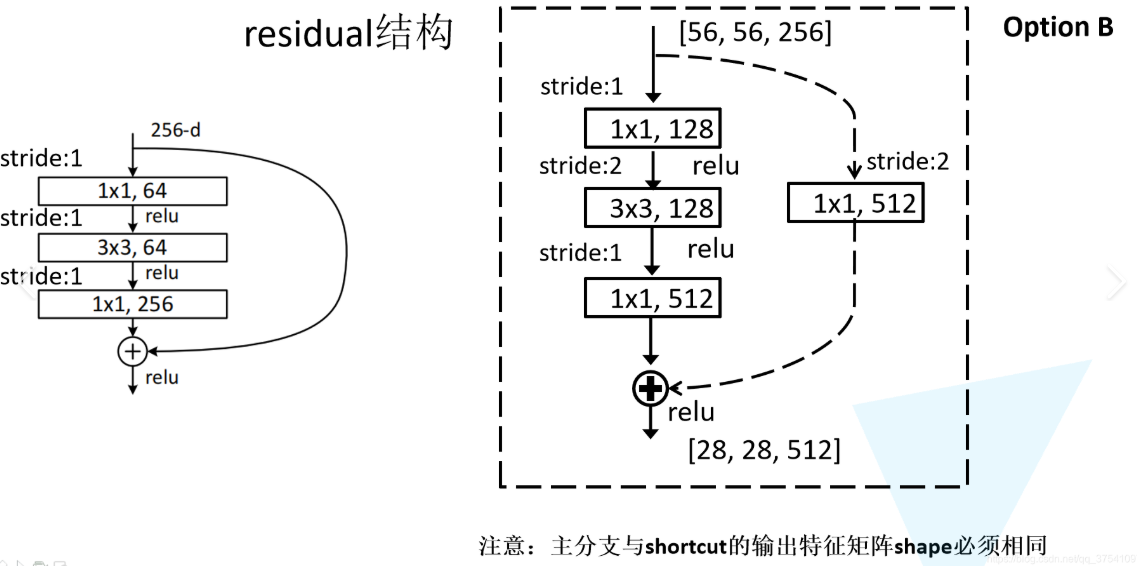
2. 数学公式(残差连接核心)
设某层的输入特征为 x x x,该层的映射函数(卷积+激活)为 F ( x ) F(x) F(x)(残差函数),则该层的输出 H ( x ) H(x) H(x) 为:
H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x
- 当 F ( x ) = 0 F(x)=0 F(x)=0 时, H ( x ) = x H(x)=x H(x)=x,即“恒等映射”,保证梯度能通过捷径直接传递;
- 训练目标变为学习“残差 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x”,比直接学习 H ( x ) H(x) H(x) 更容易收敛。
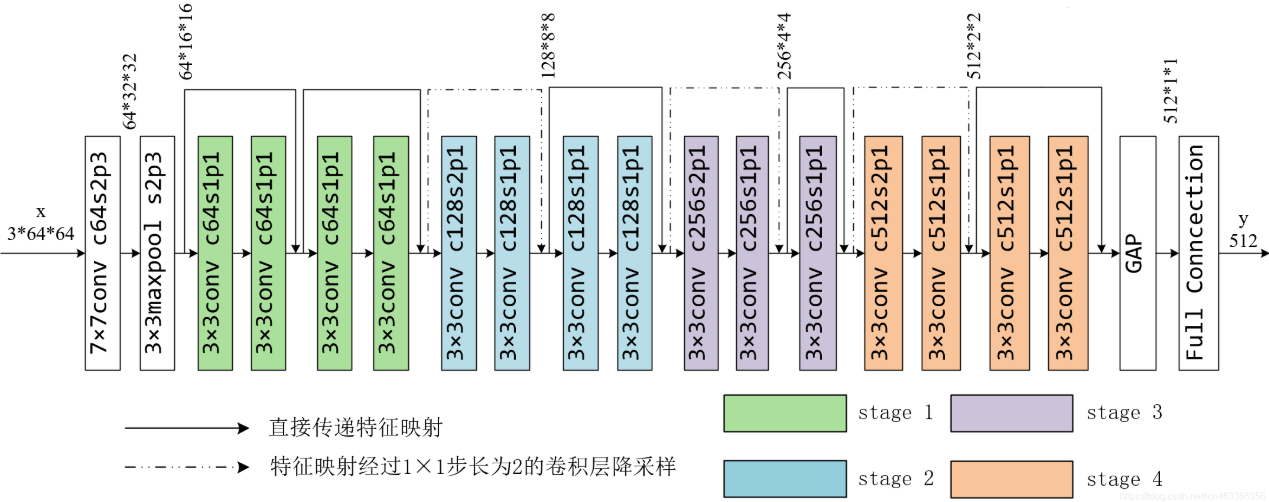
3. 网络结构简化版
ResNet的整体结构是“卷积层+多个残差块+全连接层”,以ResNet18为例(18层卷积层):
- 输入层:3×224×224(彩色图);
- Stem层:7×7卷积+MaxPool(下采样,减少尺寸);
- 残差块组:4组残差块(每组2个),每组内用步长=2的卷积下采样;
- 输出层:GlobalAvgPool+全连接层(分类任务)。
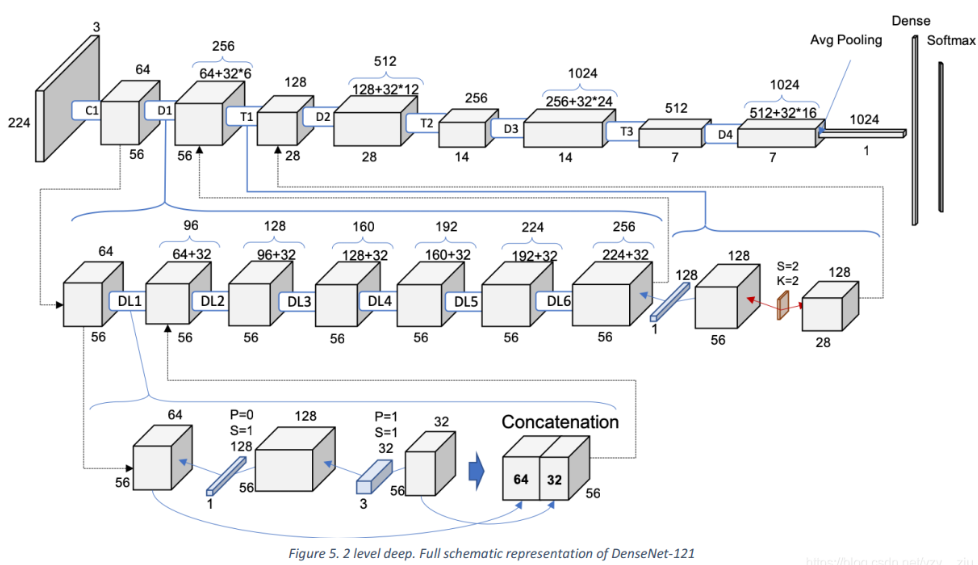
(二)DenseNet:密集连接——特征重用的“极致”
1. 核心创新:密集块(Dense Block)
DenseNet的核心是“密集连接”——第 l l l 层接收前 l − 1 l-1 l−1 层的所有输出作为输入,形成“特征图拼接”的密集网络。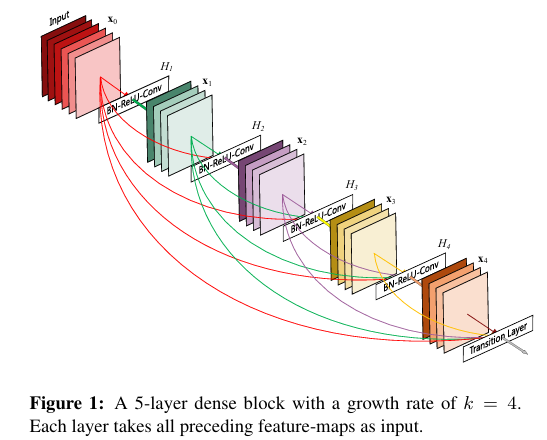
2. 数学公式(密集连接核心)
设第 i i i 层的输出特征为 x i x_i xi( i = 1 , 2 , . . . , l − 1 i=1,2,...,l-1 i=1,2,...,l−1),第 l l l 层的映射函数为 H l H_l Hl(卷积+BN+ReLU),则第 l l l 层的输出 x l x_l xl 为:
x l = H l ( [ x 1 , x 2 , . . . , x l − 1 ] ) x_l = H_l([x_1, x_2, ..., x_{l-1}]) xl=Hl([x1,x2,...,xl−1])
其中 [ x 1 , x 2 , . . . , x l − 1 ] [x_1, x_2, ..., x_{l-1}] [x1,x2,...,xl−1] 表示将前 l − 1 l-1 l−1 层的特征图在“通道维度”拼接(Concatenate)。
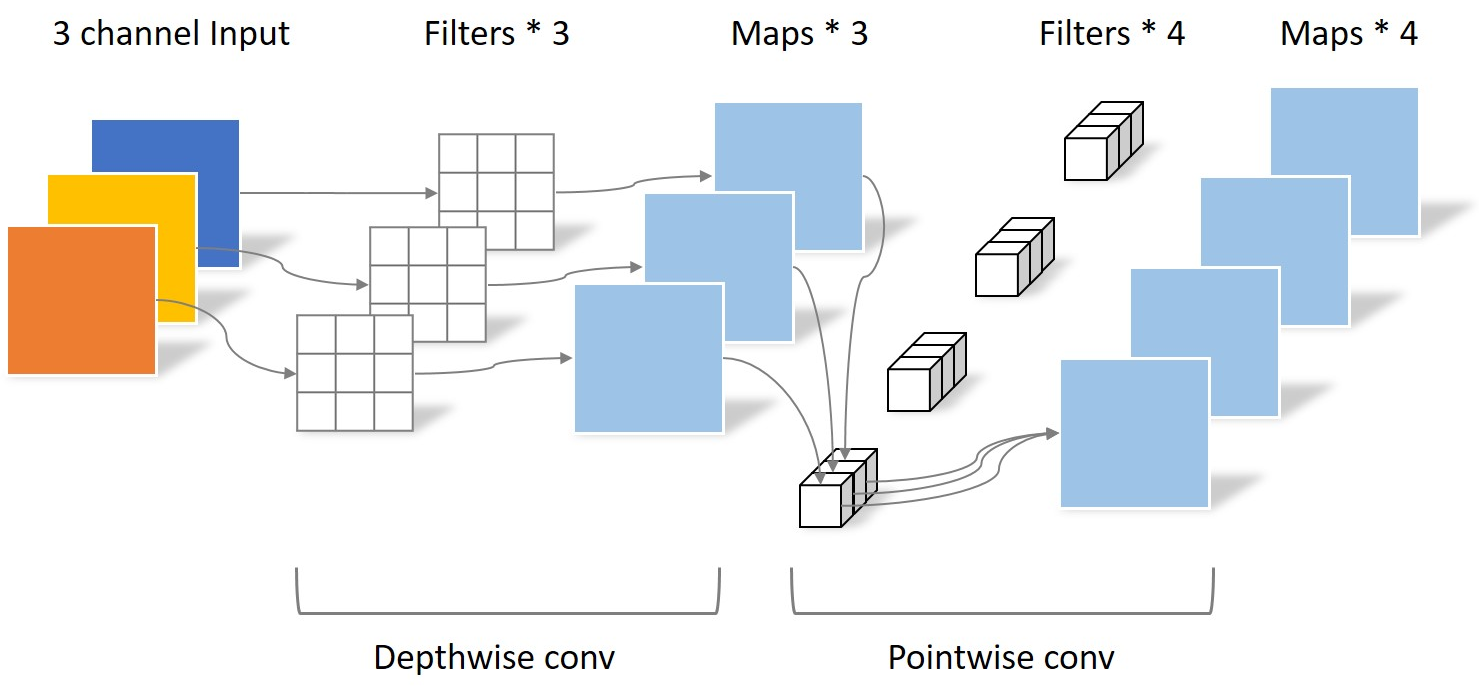
(三)MobileNet:深度可分离卷积——移动端的“效率王者”
1. 核心创新:深度可分离卷积(Depthwise Separable Convolution)
将普通3×3卷积拆分为“深度卷积”和“逐点卷积”,大幅减少参数量和计算量。
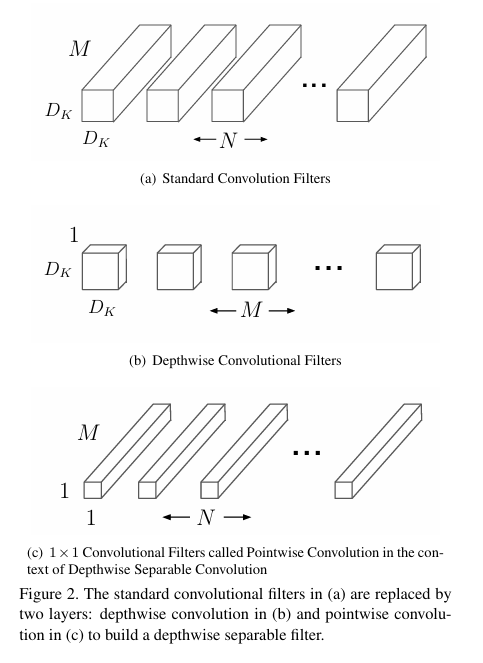
2. 数学公式(参数量对比)
- 普通3×3卷积:输入通道数 C i n C_{in} Cin,输出通道数 C o u t C_{out} Cout,参数量为 3 × 3 × C i n × C o u t 3×3×C_{in}×C_{out} 3×3×Cin×Cout;
- 深度可分离卷积:
- 深度卷积(Depthwise Conv):每个输入通道用1个3×3卷积,参数量为 3 × 3 × C i n 3×3×C_{in} 3×3×Cin;
- 逐点卷积(Pointwise Conv):用1×1卷积融合通道,参数量为 1 × 1 × C i n × C o u t 1×1×C_{in}×C_{out} 1×1×Cin×Cout;
- 总参数量: 3 × 3 × C i n + 1 × 1 × C i n × C o u t = C i n ( 9 + C o u t ) 3×3×C_{in} + 1×1×C_{in}×C_{out} = C_{in}(9 + C_{out}) 3×3×Cin+1×1×Cin×Cout=Cin(9+Cout);
- 参数量减少比例: C i n ( 9 + C o u t ) 9 C i n C o u t = 1 C o u t + 1 9 ≈ 1 8 ∼ 1 10 \frac{C_{in}(9 + C_{out})}{9C_{in}C_{out}} = \frac{1}{C_{out}} + \frac{1}{9} \approx \frac{1}{8} \sim \frac{1}{10} 9CinCoutCin(9+Cout)=Cout1+91≈81∼101(当 C o u t ≫ 1 C_{out} \gg 1 Cout≫1 时)。
3. 网络结构简化版
- 输入层:3×224×224;
- 深度可分离卷积块组:13个深度可分离卷积块(每个块=深度卷积+BN+ReLU+逐点卷积+BN+ReLU);
- 池化与输出:GlobalAvgPool+全连接层(输出类别数)。
(四)EfficientNet:复合缩放——效率与性能的“完美平衡”
1. 核心创新:复合缩放策略(Compound Scaling)
传统模型只缩放“深度”“宽度”“分辨率”中的一项,EfficientNet通过统一的缩放系数 ϕ \phi ϕ,同步缩放三项:
{ depth = α ϕ width = β ϕ resolution = γ ϕ \begin{cases} \text{depth} = \alpha^\phi \\ \text{width} = \beta^\phi \\ \text{resolution} = \gamma^\phi \end{cases} ⎩
⎨
⎧depth=αϕwidth=βϕresolution=γϕ
其中 α = 1.2 , β = 1.1 , γ = 1.15 \alpha=1.2, \beta=1.1, \gamma=1.15 α=1.2,β=1.1,γ=1.15(官方最优参数), ϕ \phi ϕ 为用户自定义缩放系数( ϕ = 0 \phi=0 ϕ=0 对应基础模型EfficientNet-B0, ϕ \phi ϕ 越大模型越强)。
2. 网络结构简化版
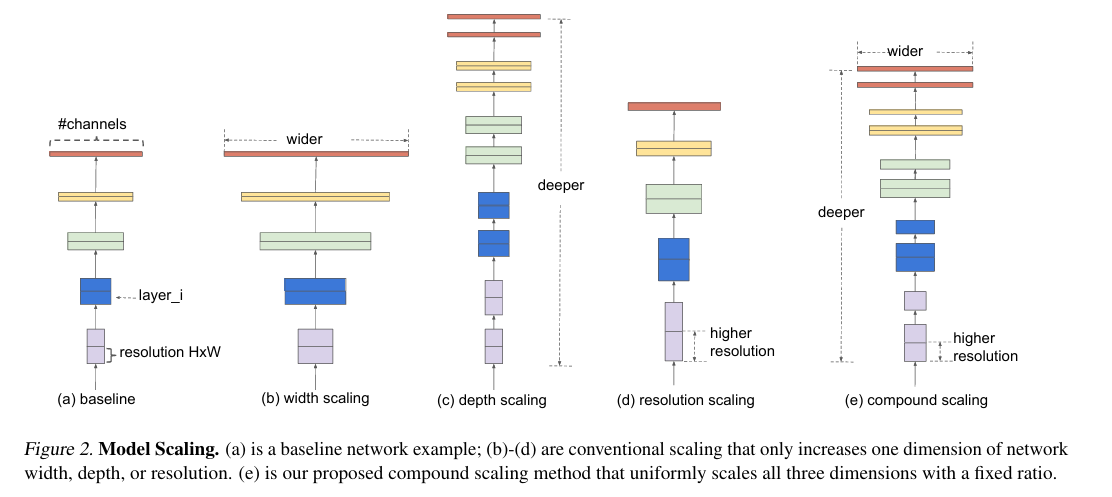
- 基础架构:基于MobileNet的深度可分离卷积;
- 创新模块:MBConv块(含挤压-激励SE模块,增强有用特征);
- 缩放逻辑:通过 ϕ \phi ϕ 同步增加深度(更多卷积层)、宽度(更多通道)、分辨率(更大输入尺寸)。
三、小白实操项目:四大模型Fashion-MNIST分类
项目目标
用ResNet、DenseNet、EfficientNet、MobileNet实现Fashion-MNIST服装分类(10类服装:T恤、裤子、外套等),自动下载数据集,对比四大模型的训练效果。
项目亮点
- 数据集自动下载:Fashion-MNIST(60k训练集+10k测试集,单通道28×28图像,小型数据集,服务器快速下载);
- 模型简化实现:保留核心模块,去掉复杂细节,小白也能看懂;
- 服务器友好:不依赖图形界面,结果图自动保存;
- 多维度对比:训练/验证准确率、损失曲线、测试准确率柱状图、混淆矩阵,全方位展示模型效果。
完整代码(Python+PyTorch)
# 1. 导入必要库(服务器环境设置,避免图形界面报错)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
import matplotlib.pyplot as plt
import numpy as np
from datetime import datetime
import os
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 服务器环境配置:禁用matplotlib显示,直接保存图片
plt.switch_backend('Agg')
plt.rcParams['font.size'] = 10
plt.rcParams['axes.grid'] = True
plt.rcParams['grid.alpha'] = 0.3
# 2. 配置超参数(小白可直接默认,无需修改)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
epochs = 10 # 训练轮次(小型数据集,10轮足够)
batch_size = 128
lr = 0.001
num_classes = 10 # Fashion-MNIST共10类
input_size = 28 # 输入图像尺寸28×28
# 3. 数据加载(自动下载Fashion-MNIST,预处理简单)
transform = transforms.Compose([
transforms.Resize((input_size, input_size)), # 统一尺寸
transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.5,), (0.5,)) # 归一化到[-1,1]
])
# 自动下载数据集
train_dataset = datasets.FashionMNIST(
root='./data', train=True, download=True, transform=transform
)
test_dataset = datasets.FashionMNIST(
root='./data', train=False, download=True, transform=transform
)
# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# 类别名称(英文,避免字体问题)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# 4. 四大模型简化实现(核心模块保留,小白易理解)
## 4.1 ResNet核心模块:残差块
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResBlock, self).__init__()
# 残差路径
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 捷径路径(当输入输出通道/尺寸不一致时,用1×1卷积调整)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
residual = self.shortcut(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual # 残差连接
out = self.relu(out)
return out
## 4.1 ResNet完整模型
class SimpleResNet(nn.Module):
def __init__(self, num_classes=10):
super(SimpleResNet, self).__init__()
self.in_channels = 16
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
# 残差块组
self.layer1 = self._make_layer(16, 2, stride=1)
self.layer2 = self._make_layer(32, 2, stride=2)
self.layer3 = self._make_layer(64, 2, stride=2)
# 输出层
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64, num_classes)
def _make_layer(self, out_channels, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(ResBlock(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
## 4.2 DenseNet核心模块:密集块
class DenseBlock(nn.Module):
def __init__(self, in_channels, growth_rate, num_layers):
super(DenseBlock, self).__init__()
self.layers = []
for i in range(num_layers):
layer = nn.Sequential(
nn.BatchNorm2d(in_channels + i*growth_rate),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels + i*growth_rate, growth_rate, kernel_size=3, padding=1, bias=False)
)
self.layers.append(layer)
self.layers = nn.ModuleList(self.layers)
def forward(self, x):
features = [x]
for layer in self.layers:
new_features = layer(torch.cat(features, dim=1))
features.append(new_features)
return torch.cat(features, dim=1)
## 4.2 DenseNet完整模型
class SimpleDenseNet(nn.Module):
def __init__(self, num_classes=10, growth_rate=12, num_layers=[4,4,4]):
super(SimpleDenseNet, self).__init__()
self.in_channels = 16
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
# 密集块组+过渡层
self.dense_blocks = []
self.transition_layers = []
for i, layers in enumerate(num_layers):
self.dense_blocks.append(DenseBlock(self.in_channels, growth_rate, layers))
self.in_channels += layers * growth_rate
if i != len(num_layers)-1:
self.transition_layers.append(nn.Sequential(
nn.BatchNorm2d(self.in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(self.in_channels, self.in_channels//2, kernel_size=1, bias=False),
nn.AvgPool2d(kernel_size=2, stride=2)
))
self.in_channels = self.in_channels//2
self.dense_blocks = nn.ModuleList(self.dense_blocks)
self.transition_layers = nn.ModuleList(self.transition_layers)
# 输出层
self.bn_final = nn.BatchNorm2d(self.in_channels)
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(self.in_channels, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
for i in range(len(self.dense_blocks)):
out = self.dense_blocks[i](out)
if i < len(self.transition_layers):
out = self.transition_layers[i](out)
out = self.bn_final(out)
out = self.relu(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
## 4.3 MobileNet核心模块:深度可分离卷积
class DepthwiseConv(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(DepthwiseConv, self).__init__()
# 深度卷积:每个通道单独卷积
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels, bias=False)
# 逐点卷积:融合通道
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(in_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.depthwise(x)
out = self.bn1(out)
out = self.relu(out)
out = self.pointwise(out)
out = self.bn2(out)
out = self.relu(out)
return out
## 4.3 MobileNet完整模型
class SimpleMobileNet(nn.Module):
def __init__(self, num_classes=10):
super(SimpleMobileNet, self).__init__()
self.features = nn.Sequential(
# 初始卷积层
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
# 深度可分离卷积块组
DepthwiseConv(32, 64, stride=1),
DepthwiseConv(64, 128, stride=2),
DepthwiseConv(128, 128, stride=1),
DepthwiseConv(128, 256, stride=2),
DepthwiseConv(256, 256, stride=1),
)
# 输出层
self.avg_pool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(256, num_classes)
def forward(self, x):
out = self.features(x)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
## 4.4 EfficientNet(直接使用torchvision简化版,无需手动实现复杂缩放)
class SimpleEfficientNet(nn.Module):
def __init__(self, num_classes=10):
super(SimpleEfficientNet, self).__init__()
# 加载预训练的EfficientNet-B0(小型版本,适合小数据集)
self.base_model = models.efficientnet_b0(pretrained=False)
# 适配单通道输入(EfficientNet默认输入3通道)
self.base_model.features[0][0] = nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1, bias=False)
# 替换输出层(适配10类分类)
num_ftrs = self.base_model.classifier[1].in_features
self.base_model.classifier[1] = nn.Linear(num_ftrs, num_classes)
def forward(self, x):
return self.base_model(x)
# 5. 训练与验证函数(小白友好,封装完整)
def train_model(model, train_loader, test_loader, criterion, optimizer, epochs, model_name):
# 记录训练历史
history = {
'train_loss': [], 'train_acc': [],
'val_loss': [], 'val_acc': []
}
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0.0
train_correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播+优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计损失和准确率
train_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
train_correct += (predicted == labels).sum().item()
# 计算训练集平均损失和准确率
avg_train_loss = train_loss / total
train_acc = train_correct / total
history['train_loss'].append(avg_train_loss)
history['train_acc'].append(train_acc)
# 验证阶段
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
all_preds = []
all_labels = []
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
# 统计损失和准确率
val_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
# 记录预测结果(用于混淆矩阵)
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# 计算验证集平均损失和准确率
avg_val_loss = val_loss / val_total
val_acc = val_correct / val_total
history['val_loss'].append(avg_val_loss)
history['val_acc'].append(val_acc)
# 打印训练日志
print(f'Epoch [{epoch+1}/{epochs}] | {model_name} | '
f'Train Loss: {avg_train_loss:.4f} | Train Acc: {train_acc:.4f} | '
f'Val Loss: {avg_val_loss:.4f} | Val Acc: {val_acc:.4f}')
# 保存模型
torch.save(model.state_dict(), f'{model_name}_fashion_mnist.pth')
print(f'{model_name} saved to {model_name}_fashion_mnist.pth')
return history, np.array(all_preds), np.array(all_labels)
# 6. 初始化模型并训练(四大模型同时训练对比)
models_dict = {
'ResNet': SimpleResNet(num_classes=num_classes).to(device),
'DenseNet': SimpleDenseNet(num_classes=num_classes).to(device),
'MobileNet': SimpleMobileNet(num_classes=num_classes).to(device),
'EfficientNet': SimpleEfficientNet(num_classes=num_classes).to(device)
}
# 记录所有模型的训练历史、预测结果
history_dict = {}
preds_dict = {}
labels_dict = {}
test_accs = {}
# 遍历训练每个模型
for name, model in models_dict.items():
print(f"\n{'='*60} Training {name} {'='*60}")
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 训练模型
history, preds, labels = train_model(
model=model,
train_loader=train_loader,
test_loader=test_loader,
criterion=criterion,
optimizer=optimizer,
epochs=epochs,
model_name=name
)
# 保存结果
history_dict[name] = history
preds_dict[name] = preds
labels_dict[name] = labels
test_accs[name] = history['val_acc'][-1] # 测试准确率取最后一轮验证集准确率
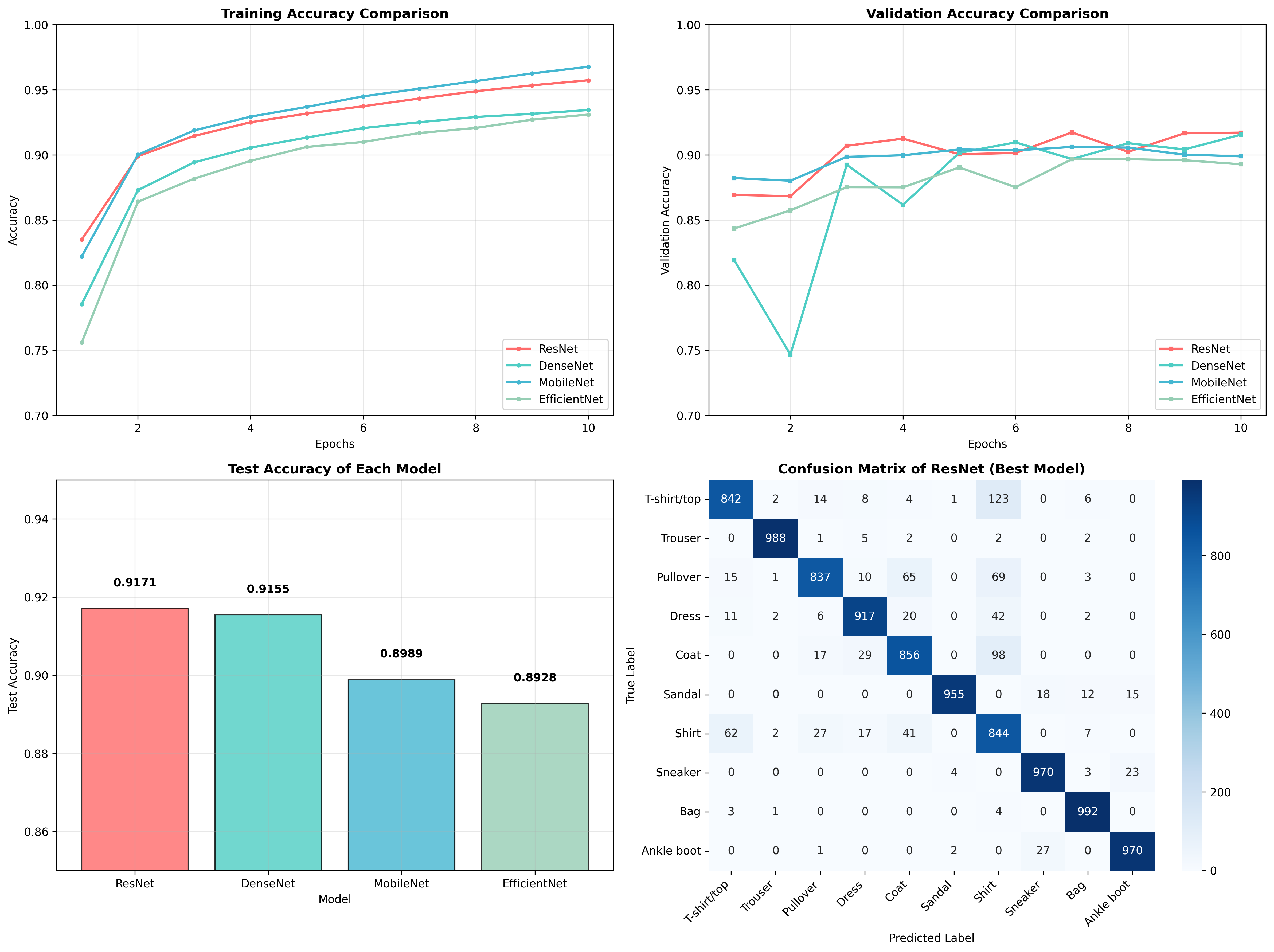
# 7. 生成多维度对比结果图(2×2子图,服务器自动保存)
fig, axes = plt.subplots(2, 2, figsize=(16, 12))
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4']
model_names = list(models_dict.keys())
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# 子图1:训练准确率对比
ax1 = axes[0, 0]
for i, (name, history) in enumerate(history_dict.items()):
ax1.plot(range(1, epochs+1), history['train_acc'],
label=name, color=colors[i], linewidth=2, marker='o', markersize=3)
ax1.set_title('Training Accuracy Comparison', fontweight='bold')
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Accuracy')
ax1.legend(loc='lower right')
ax1.set_ylim(0.7, 1.0)
# 子图2:验证准确率对比
ax2 = axes[0, 1]
for i, (name, history) in enumerate(history_dict.items()):
ax2.plot(range(1, epochs+1), history['val_acc'],
label=name, color=colors[i], linewidth=2, marker='s', markersize=3)
ax2.set_title('Validation Accuracy Comparison', fontweight='bold')
ax2.set_xlabel('Epochs')
ax2.set_ylabel('Validation Accuracy')
ax2.legend(loc='lower right')
ax2.set_ylim(0.7, 1.0)
# 子图3:测试准确率柱状图
ax3 = axes[1, 0]
acc_values = [test_accs[name] for name in model_names]
bars = ax3.bar(model_names, acc_values, color=colors, alpha=0.8, edgecolor='black', linewidth=1)
for bar, acc in zip(bars, acc_values):
height = bar.get_height()
ax3.text(bar.get_x() + bar.get_width()/2., height + 0.005,
f'{acc:.4f}', ha='center', va='bottom', fontweight='bold')
ax3.set_title('Test Accuracy of Each Model', fontweight='bold')
ax3.set_xlabel('Model')
ax3.set_ylabel('Test Accuracy')
ax3.set_ylim(0.85, 0.95)
ax3.grid(True, axis='y', alpha=0.3)
# 子图4:最佳模型的混淆矩阵(展示分类细节)
ax4 = axes[1, 1]
best_model_name = max(test_accs, key=test_accs.get)
best_preds = preds_dict[best_model_name]
best_labels = labels_dict[best_model_name]
cm = confusion_matrix(best_labels, best_preds)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=ax4,
xticklabels=class_names, yticklabels=class_names)
ax4.set_title(f'Confusion Matrix of {best_model_name} (Best Model)', fontweight='bold')
ax4.set_xlabel('Predicted Label')
ax4.set_ylabel('True Label')
plt.xticks(rotation=45, ha='right')
# 保存结果图
save_path = f'cnn_models_comparison_{timestamp}.png'
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight', facecolor='white')
print(f"\nResult figure saved to: {os.path.abspath(save_path)}")
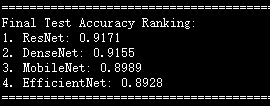
# 8. 打印最终排名
print("\n" + "="*80)
print("Final Test Accuracy Ranking:")
sorted_ranking = sorted(test_accs.items(), key=lambda x: x[1], reverse=True)
for rank, (name, acc) in enumerate(sorted_ranking, 1):
print(f"{rank}. {name}: {acc:.4f}")
print("="*80)
代码运行步骤(小白直接抄)
- 环境准备:确保安装了PyTorch、torchvision、matplotlib、seaborn、scikit-learn(执行
pip install torch torchvision matplotlib seaborn scikit-learn); - 新建
train.py文件,复制上面的代码; - 执行命令:
python train.py; - 等待运行完成:自动下载数据集→训练四大模型→保存模型文件→生成对比结果图。
服务器运行注意事项
- 无需图形界面:代码已设置
plt.switch_backend('Agg'),直接保存图片,不弹出窗口; - 运行时间:10轮训练;
- 结果文件:生成4个模型的
.pth权重文件和1个cnn_models_comparison_xxx.png对比图。 - 实验结果:因本项目只做demo入门教学使用,因此仅训练10个epoch,如有结果不符合预期,请大家谅解~
四、四大模型优缺点与适用场景(表格对比)
| 模型 | 核心优势 | 主要缺点 | 参数量(相对值) | 计算量(相对值) | 适用场景 |
|---|---|---|---|---|---|
| ResNet | 梯度稳定,深度易扩展,泛化能力强 | 特征重用效率一般,参数量中等 | 1.0(基准) | 1.0(基准) | 通用场景(图像分类、目标检测、分割)、科研入门 |
| DenseNet | 特征重用极致,参数量少,小数据集效果好 | 内存占用高(特征拼接),训练速度慢 | 0.6 | 0.8 | 小数据集任务、需要强特征表达的场景(医学图像) |
| MobileNet | 参数量极少,计算量低,推理速度快 | 准确率略低于其他模型,复杂场景表现一般 | 0.1 | 0.08 | 移动端/嵌入式设备(手机APP、智能硬件) |
| EfficientNet | 准确率最高,效率与性能平衡最优 | 模型结构复杂,训练成本略高 | 0.8 | 0.5 | 云端推理、追求高精度+高效率的场景(电商图像分类) |
通俗总结
- 想做手机APP、智能手表上的图像识别:选MobileNet;
- 想在服务器上快速得到高精度结果:选EfficientNet;
- 刚入门CNN,想理解深层网络原理:选ResNet;
- 只有少量数据,想让模型充分利用特征:选DenseNet。
五、与类似算法对比
| 对比维度 | 四大模型(ResNet/DenseNet等) | 传统CNN(LeNet/AlexNet/VGG) |
|---|---|---|
| 深度能力 | 支持100+层,梯度稳定 | 深度≤30层,易梯度消失 |
| 参数量 | 高效(MobileNet/EfficientNet)或中等(ResNet) | 庞大(VGG参数量是MobileNet的10倍+) |
| 计算效率 | 高(深度可分离卷积、复合缩放) | 低(全卷积,无优化) |
| 适用场景 | 移动端、云端、小数据、大数据全覆盖 | 仅适用于服务器端、大数据场景 |
| 工业界应用 | 广泛(手机相机、电商、自动驾驶) | 逐渐淘汰,仅用于教学 |
六、总结
ResNet、DenseNet、EfficientNet、MobileNet四大模型,分别从“深度扩展”“特征重用”“效率平衡”“轻量化”四个角度解决了传统CNN的痛点,构成了现代计算机视觉的“核心工具箱”。本文通过通俗案例拆解原理,搭配自动下载数据集、小白友好的实操项目,让你无需复杂配置就能跑通对比实验。
如果是刚入门,建议先从ResNet入手,理解残差连接的核心;如果是实际项目,根据“是否需要移动端部署”“数据量大小”“准确率要求”选择模型——移动端选MobileNet,高精度选EfficientNet,小数据选DenseNet,通用场景选ResNet。
赶紧运行代码,看看四大模型在Fashion-MNIST上的表现吧!
我整理了ResNet、DenseNet、EfficientNet、MobileNet这几个模型算法的论文及其代码例程,感兴趣的自取,希望能帮到你!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)