强化学习【page10】随机近似与梯度下降
目录:随机近似理论背景与动机Robbins- Monro(RM) algorithm 罗宾斯-蒙罗算法Robbins- Monro(RM) algorithmPython 例子Robbins- Monro(RM) algorithm收敛条件强化学习在大模型训练中的运用。
目录:
- 随机近似理论背景与动机
- Robbins- Monro(RM) algorithm 罗宾斯-蒙罗算法
- Robbins- Monro(RM) algorithm Python 例子
- Robbins- Monro(RM) algorithm 收敛条件
- 强化学习在大模型训练中的运用
一 随机近似理论背景与动机
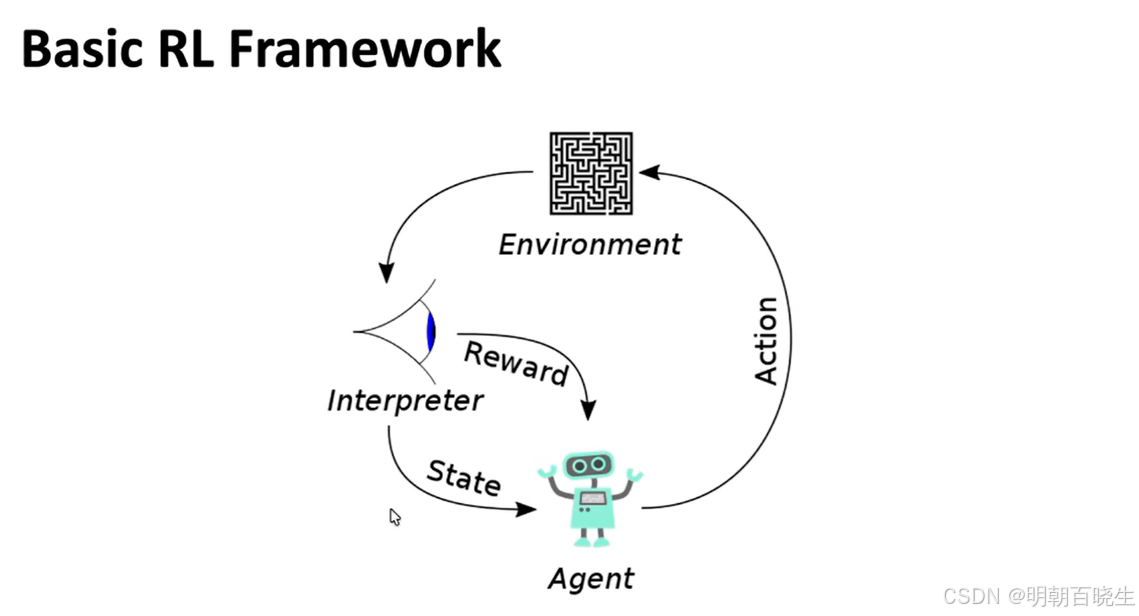
随机近似理论(Stochastic Approximation, SA)起源于20世纪40至50年代,由 Herbert Robbins 和 Sutton Monro 在1951年提出的随机逼近算法(Robbins-Monro算法)奠定了这一领域的基础。这一理论最初是为了解决无法直接观测的方程的根的问题,例如在无法精确测量噪声环境下的系统参数估计。其核心思想是通过带有噪声的观测数据,逐步逼近目标值或最优解。
1.1 增量式更新
在强化学习中,状态-动作值函数 Q(s,a)被定义为:从状态-动作对 (s,a) 开始,遵循策略 π所能获得的折扣累积回报的期望。该期望本身通常难以直接求解,但我们可以通过 Monte-Carlo 方法进行估计——只需采样大量从 (s,a) 出发的完整轨迹,并计算其实际回报的均值,即可逐步逼近真实的 Q(s,a)
实践中,主要有两种实现方式:
批处理模式:收集大量(例如 M 个)完整的 episode 后,集中计算所有样本的回报均值,并一次性更新 Q 函数。这种方法的缺点是数据利用效率低,策略更新延迟大,尤其在一些样本收集成本高昂(例如,每个 episode 代表一次完整实验或一个商业周期)的任务中,可能导致整个任务结束前策略都未能得到有效更新。
增量式更新:每完成一个 episode,立即利用该轨迹中包含的所有 (s, a) 样本进行 Q 函数更新。这种在线学习方式更高效、内存占用更小。其更新规则基于增量式计算均值的思想:
设为前 k 个样本的均值,即
。当获得第 k+1 个样本
时,新的均值:
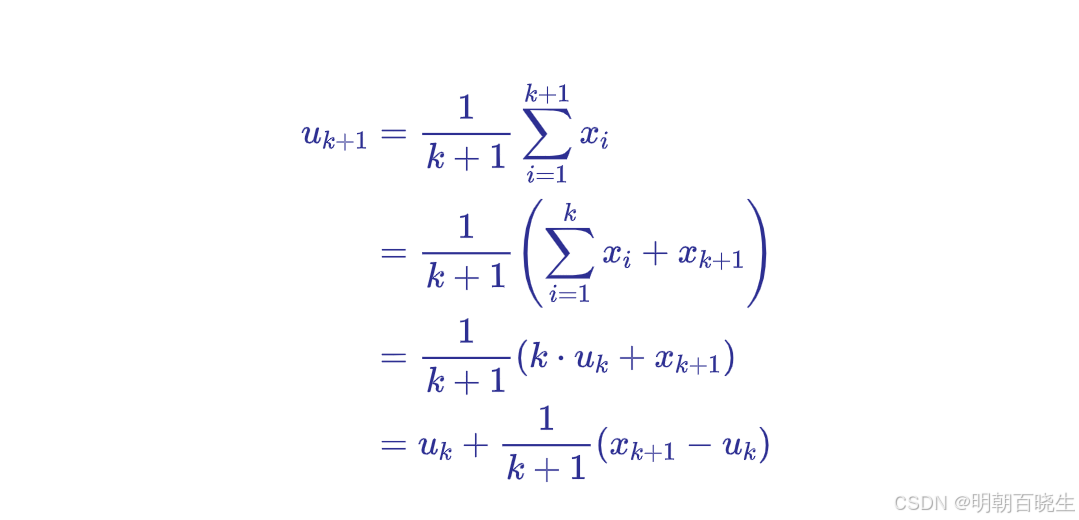
1.2 Stochastic Approximation, SA 理论
步长
通常有两种选择:
当
时,该更新等价于计算样本的算术平均值,能保证无偏估计。
当
意义下的一种随机梯度下降 (Stochastic Gradient Descent) 方法。这里面的Stochastic 是指对随机变量的采样
增量式 Monte-Carlo 方法因其在线学习特性、恒定内存开销以及坚实的理论收敛性保证,成为时序差分 (Temporal-Difference) 学习和 Actor-Critic 算法等重要方法的基础。
二 Robbins- Monro(RM) algorithm 罗宾斯-蒙罗算法
罗宾斯-蒙罗算法旨在解决这样一个问题:我们有一个函数,但我们无法直接获得它的值,只能通过实验得到带有噪声的观测值。我们的目标是找到这个函数的根(Root),即找到点
,使得
。
它是stochastic approximation 理论的一个开创性工作。通常处理的是g(w)表达式未知的情况,比如神经网络网络g(w)
2.1 计算步骤:
算法的思想非常直观,可以看作是带有噪声的牛顿迭代法。
猜测一个初始值
。
在当前位置
进行一次实验,观测到
。
根据观测结果,朝着根的方向更新我们的估计值。更新公式为:
重复步骤2和3。
这里的关键在于序列 {
},它被称为步长序列或增益序列。
完整的RM算法迭代公式:
2.2 应用场景
例1 在梯度下降算法的执行过程中,其核心目标之一是通过对目标函数进行迭代优化,来求解该目标函数的驻点(即梯度为零的点)
例2 , 可以通过转换为
求解
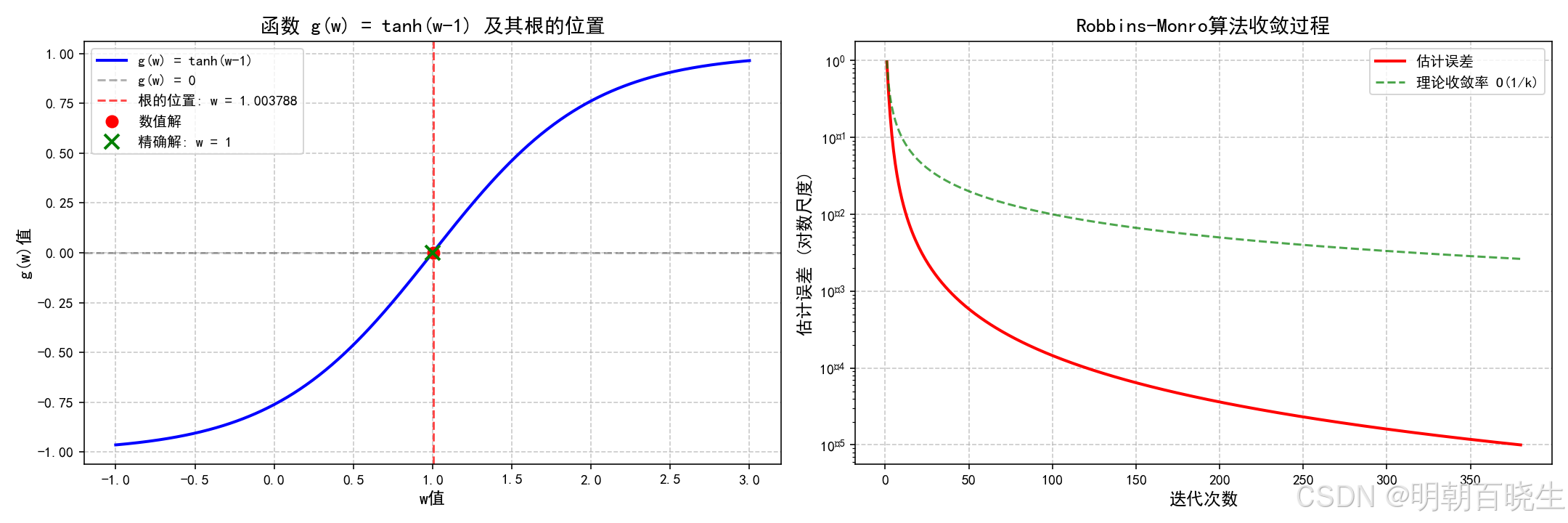
三、 Robbins- Monro(RM) algorithm Python 例子
其真实根为
-
参数设置:初始估计
,步长
,噪声
(无噪声情况)。
-
更新过程:根据RM算法,更新规则为
-
-
'''
robbins_monro 算法
作者:chengxf
'''
import matplotlib.pyplot as plt
import numpy as np
def compute_gw(w: float) -> float:
"""
计算函数 g(w) = tanh(w - 1) 的值。
参数:
w (float): 输入变量
返回:
float: 函数计算结果
"""
return np.tanh(w - 1)
def robbins_monro(initial_w: float, max_iterations: int = 10000) -> tuple:
"""
使用Robbins-Monro随机逼近算法求解方程 g(w) = 0 的根。
参数:
initial_w (float): 初始猜测值
max_iterations (int): 最大迭代次数,防止无限循环
返回:
tuple: (根的估计值, 迭代次数, 收敛历史)
"""
current_w = initial_w
iteration_count = 1
convergence_threshold = 1e-5 # 收敛判断阈值
# 记录收敛过程用于分析
convergence_history = {
'w_values': [current_w],
'g_values': [compute_gw(current_w)],
'errors': []
}
while iteration_count <= max_iterations:
current_gw = compute_gw(current_w)
# Robbins-Monro更新规则:w_{k+1} = w_k - (1/k) * g(w_k)
next_w = current_w - (1 / iteration_count) * current_gw
# 记录收敛过程
convergence_history['w_values'].append(next_w)
convergence_history['g_values'].append(compute_gw(next_w))
convergence_history['errors'].append(abs(next_w - current_w))
# 检查收敛条件
if abs(next_w - current_w) < convergence_threshold:
return next_w, iteration_count, convergence_history
current_w = next_w
iteration_count += 1
# 如果达到最大迭代次数仍未收敛
print(f"警告: 在 {max_iterations} 次迭代后仍未完全收敛")
return current_w, iteration_count - 1, convergence_history
def plot_function_and_root(w_root: float, convergence_history: dict) -> None:
"""
绘制函数图像并标记根的位置。
参数:
w_root (float): 找到的根的位置
convergence_history (dict): 收敛过程记录
"""
# 创建更密集的采样点以获得平滑曲线
w_range = np.linspace(-1, 3, 500)
g_values = compute_gw(w_range)
# 创建图形和坐标轴
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# 左侧子图:函数曲线和根的位置
ax1.plot(w_range, g_values, 'b-', linewidth=2, label='g(w) = tanh(w-1)')
ax1.axhline(y=0, color='k', linestyle='--', alpha=0.3, label='g(w) = 0')
ax1.axvline(x=w_root, color='r', linestyle='--', alpha=0.7,
label=f'根的位置: w = {w_root:.6f}')
ax1.plot(w_root, 0, 'ro', markersize=8, label='数值解')
ax1.plot(1, 0, 'gx', markersize=10, markeredgewidth=2,
label='精确解: w = 1')
ax1.set_xlabel('w值', fontsize=12)
ax1.set_ylabel('g(w)值', fontsize=12)
ax1.set_title('函数 g(w) = tanh(w-1) 及其根的位置', fontsize=14)
ax1.grid(True, linestyle='--', alpha=0.7)
ax1.legend()
# 右侧子图:收敛过程
iterations = range(1, len(convergence_history['w_values']))
ax2.semilogy(iterations, convergence_history['errors'],
'r-', linewidth=2, label='估计误差')
ax2.semilogy(iterations, [1/k for k in iterations],
'g--', alpha=0.7, label='理论收敛率 O(1/k)')
ax2.set_xlabel('迭代次数', fontsize=12)
ax2.set_ylabel('估计误差 (对数尺度)', fontsize=12)
ax2.set_title('Robbins-Monro算法收敛过程', fontsize=14)
ax2.grid(True, linestyle='--', alpha=0.7)
ax2.legend()
plt.tight_layout()
plt.savefig('function_root_analysis.png', dpi=300, bbox_inches='tight')
plt.show()
def main() -> None:
"""
主函数:执行Robbins-Monro算法并可视化结果。
"""
# 算法参数设置
initial_guess = 3.0 # 初始猜测值
print("=" * 50)
# 执行Robbins-Monro算法
final_w, iterations, history = robbins_monro(initial_guess)
# 输出结果
print(f"初始猜测: w₀ = {initial_guess}")
print(f"最终估计: w = {final_w:.8f}")
print(f"迭代次数: {iterations}")
print(f"函数值: g(w) = {compute_gw(final_w):.2e}")
print(f"与精确解(w=1)的误差: {abs(final_w - 1):.2e}")
# 可视化结果
plot_function_and_root(final_w, history)
if __name__ == "__main__":
main()四 Robbins- Monro(RM) algorithm 收敛性证明
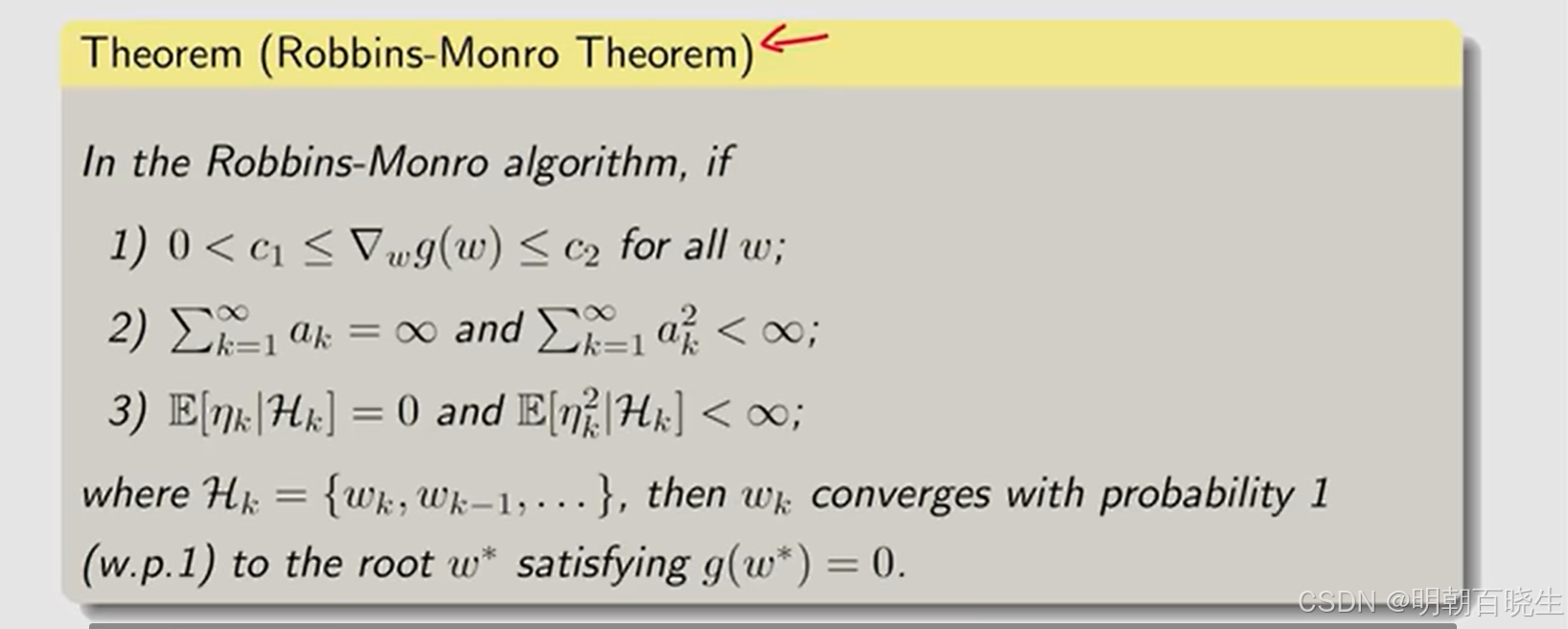
梯度要求(条件1)
函数 g是连续且单调递增的,确保方程 g(w)=0 存在唯一解 w∗。此外,g 应满足 Lipschitz 连续性条件,即存在常数 L<∞ 使得 ∣g(w)−g(w′)∣≤L∣w−w′∣ 对于所有 w,w′成立。这保证了 g 的变化率有界(即“梯度”不会无穷大),从而避免更新步长过大导致发散。
系数要求(条件2):

(表明系数为
最终趋近于0,保证函数收敛)
说明:
我们知道
,则
当
则
所以当
( 表明系数为
(表明初始点
可以随意选)
根据
把左边所有的项相加对消得到
当
,可以趋近无穷大
我们在Monte-Carlo 里面策略迭代时候,使用的
就满足该条件
实际项目中


测量误差要求 (条件3):
测量误差的数学期望为0, 测量误差的方差有界
测量误差(噪声)序列 {ϵk}{ϵk} 必须满足:
-
(条件期望为零,这表示噪声是无偏的。
-
(条件方差有界),这表示噪声的波动受控
五 强化学习在大模型训练中的运用
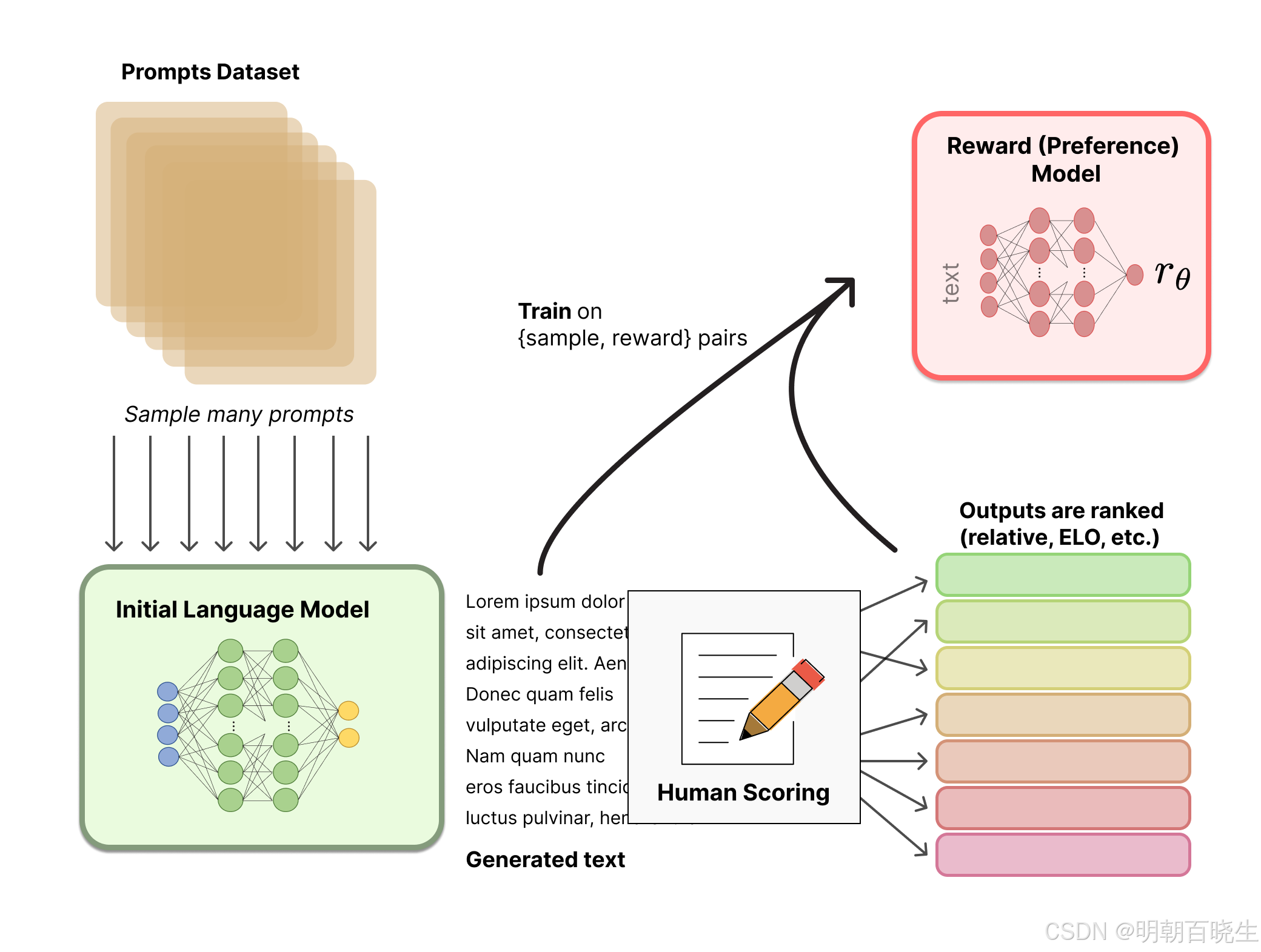
随着大语言模型在自然语言处理领域取得革命性进展,其训练范式已从初期的自监督预训练,扩展到包含人类反馈的精细对齐阶段。在这一演进过程中,强化学习(Reinforcement Learning, RL) 已脱颖而出,成为塑造大模型行为、提升其与人类价值观对齐能力的核心技术。本简介将重点探讨RL在大模型训练中的应用,特别是其在提升模型泛化能力方面的贡献,并深入分析训练过程中必须面对的关键挑战与核心监控指标。
1 RL在大模型中的应用核心:从模仿到对齐
RL在大模型中的应用,最典型和成功的范例是基于人类反馈的强化学习(RLHF)。其核心思想是:将大模型视为一个智能体(Agent),其生成的每一段文本视为一个动作(Action),而人类的偏好(无论是来自标注员还是通过模型学习)则构成了奖励信号(Reward)。通过RL优化,模型学习生成那些能获得更高奖励(即更符合人类偏好)的文本。
RL的关键贡献在于赋予大模型强大的泛化能力。传统的监督微调教会模型“如何完成一个已知任务”,而RL则训练模型去“判断什么样的输出是好的”,从而能够在未见过的任务和多样化场景中,自主地生成高质量、有帮助且无害的回应。这使得模型不再仅仅是“信息复读机”,而成为一个能够进行创造性思考并与复杂、开放世界交互的智能系统。
2、 RL训练过程中的核心挑战与关键原则
尽管RL潜力巨大,但其训练过程极具技巧性且充满挑战。成功的RL应用必须严格遵循两个关键原则:
-
避免不可扩展的任务:大模型的训练需要处理海量数据和巨大的计算图。任何依赖于人工密集型、无法批量处理或计算复杂度呈指数级增长的方法,在大规模场景下都是不可持续的。因此,RL策略(如PPO)和奖励模型的设计必须满足可扩展性要求,确保训练流程能够高效、稳定地运行在分布式计算集群上。
-
防范奖励函数操纵:这是RL领域经典的难题,在大模型背景下尤为突出。由于奖励函数通常由一个相对较小的奖励模型来近似,优化过程可能会“钻空子”,产生一些在奖励模型上得分很高、但实际质量低劣或无意义的输出(例如,在文本末尾重复添加某些讨好性的短语)。这不仅会损害模型性能,还可能导致训练崩溃。因此,需要精心设计奖励函数(如结合多个奖励信号、施加KL散度惩罚以约束策略模型不要偏离初始模型太远),并持续监控以防止此类行为。
3 训练状态的重要监控指标:模型输出的熵 H(x)
在大模型的RL训练阶段,模型输出的熵 H(x) 是一个至关重要的、用于实时监测模型训练状态的指标。
-
熵的含义:在信息论中,熵衡量了随机变量的不确定性。对于语言模型,它反映了模型在给定上下文后,对下一个词元预测的“自信程度”。高熵意味着模型认为很多词元都有可能出现,输出分布较为平坦;低熵则意味着模型非常确信下一个词是某个或某几个特定的选项,输出分布非常尖锐。
-
监控价值:
-
训练稳定性:在RL训练初期,熵通常会下降,因为模型正在学习如何生成更高奖励的输出,其行为变得更加确定。然而,如果熵值急剧下降至接近零,可能是一个危险信号,表明模型可能发生了模式崩溃 或正在实施奖励操纵,即它找到了一个极窄的、能骗取高奖励的“作弊”输出模式,而丧失了生成多样性的能力。
-
探索与利用的平衡:保持适度的熵值对于模型维持一定的探索能力至关重要,这有助于它发现更优的生成策略,避免陷入局部最优解。
-
因此,密切监控 H(x) 的变化曲线,是确保RL训练健康、稳定进行的关键手段。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)