springAI+MyBatis-Plus 知识库智能处理系统(史上最全)
return ResponseEntity.internalServerError().body("删除失败: " + e.getMessage());log.info("生成嵌入向量成功,文本长度: {}, 向量维度: {}", text.length(), embedding.size());log.info("语义搜索完成,查询: {}, 返回结果数: {}", request.getQue
第一部分 项目概述与技术栈
1.项目整体架构图
2.技术栈明细
- Java 17 + Spring Boot 3.2.4
- Spring AI 0.8.1:处理 AI 相关功能
- MyBatis-Plus 3.5.4:数据库 ORM 框架
- MySQL 8.0+:数据存储
- Lombok:简化实体类开发
- Hutool:工具库
- Maven:项目管理
第二步:完整的项目结构
spring-ai-knowledge-base/
│
├── src/main/
│ ├── java/
│ │ └── com/
│ │ └── example/
│ │ └── knowledgebase/
│ │ ├── KnowledgeBaseApplication.java # 启动类
│ │ ├── config/
│ │ │ ├── MybatisPlusConfig.java # MyBatis-Plus 配置
│ │ │ └── WebConfig.java # Web配置
│ │ ├── controller/
│ │ │ ├── DocumentController.java # 文档处理控制器
│ │ │ └── SearchController.java # 搜索控制器
│ │ ├── entity/
│ │ │ └── DocumentChunk.java # 实体类
│ │ ├── mapper/
│ │ │ └── DocumentChunkMapper.java # MyBatis Mapper
│ │ ├── service/
│ │ │ ├── IDocumentService.java # 服务接口
│ │ │ ├── impl/
│ │ │ │ └── DocumentServiceImpl.java # 服务实现
│ │ │ ├── EmbeddingService.java # 嵌入服务
│ │ │ └── FileParseService.java # 文件解析服务
│ │ ├── dto/
│ │ │ ├── DocumentUploadDTO.java # 文档上传DTO
│ │ │ ├── SearchRequestDTO.java # 搜索请求DTO
│ │ │ └── SearchResultDTO.java # 搜索结果DTO
│ │ └── util/
│ │ ├── TextSplitter.java # 文本分块工具
│ │ └── VectorMathUtil.java # 向量计算工具
│ │
│ └── resources/
│ ├── application.yml # 主配置文件
│ ├── application-dev.yml # 开发环境配置
│ ├── application-prod.yml # 生产环境配置
│ ├── mapper/
│ │ └── DocumentChunkMapper.xml # MyBatis XML映射文件
│ └── static/
│ └── documents/ # 文档上传目录
│
├── pom.xml # Maven依赖配置
└── README.md # 项目说明文档
第三步:详细配置和代码实现
1. Maven 依赖配置 (pom.xml)
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>spring-ai-knowledge-base</artifactId>
<version>1.0.0</version>
<name>spring-ai-knowledge-base</name>
<description>基于Spring AI和MyBatis-Plus的知识库系统</description>
<properties>
<java.version>17</java.version>
<spring-ai.version>0.8.1</spring-ai.version>
<mybatis-plus.version>3.5.4.1</mybatis-plus.version>
<hutool.version>5.8.22</hutool.version>
</properties>
<dependencies>
<!-- Spring Boot 基础依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<!-- MyBatis-Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- 工具类 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
</dependency>
<!-- 文件处理 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.29</version>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories></project>
2. 配置文件 (application.yml)
# 主配置文件spring:
profiles:
active: dev # 默认使用开发环境配置
servlet:
multipart:
max-file-size: 10MB
max-request-size: 10MB
# MyBatis-Plus 配置mybatis-plus:
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: auto
logic-delete-field: deleted # 逻辑删除字段
logic-delete-value: 1
logic-not-delete-value: 0
# 日志配置logging:
level:
com.example.knowledgebase: debug
org.springframework.ai: debug
3. 开发环境配置 (application-dev.yml)
# 开发环境配置
spring:
datasource:
driver-class-name: com.mysql.cj.Driver
url: jdbc:mysql://localhost:3306/ai_knowledge_db?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
ai:
openai:
api-key: ${OPENAI_API_KEY:sk-your-api-key-here} # 建议使用环境变量
base-url: https://api.openai.com # 如果使用第三方代理,可修改此处
embedding:
model: text-embedding-3-small
dimensions: 1536
# 文件上传路径
file:
upload:
path: ./uploads/
4. 数据库实体类 (entity/DocumentChunk.java)
package com.example.knowledgebase.entity;
import com.baomidou.mybatisplus.annotation.*;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.experimental.Accessors;
import java.io.Serializable;
import java.time.LocalDateTime;
/**
* 文档分块实体类
*/
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("document_chunk")
public class DocumentChunk implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/**
* 文档名称
*/
@TableField("document_name")
private String documentName;
/**
* 文档类型 (txt, pdf, docx)
*/
@TableField("document_type")
private String documentType;
/**
* 分块内容
*/
@TableField("chunk_content")
private String chunkContent;
/**
* 分块索引 (同一文档中的第几个分块)
*/
@TableField("chunk_index")
private Integer chunkIndex;
/**
* 向量数据 (JSON数组格式)
*/
@TableField("embedding_vector")
private String embeddingVector;
/**
* 向量维度
*/
@TableField("vector_dimension")
private Integer vectorDimension;
/**
* 创建时间
*/
@TableField(value = "create_time", fill = FieldFill.INSERT)
private LocalDateTime createTime;
/**
* 更新时间
*/
@TableField(value = "update_time", fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
/**
* 逻辑删除 (0-未删除, 1-已删除)
*/
@TableField("deleted")
@TableLogic
private Integer deleted;
}
5. MyBatis Mapper 接口 (mapper/DocumentChunkMapper.java)
package com.example.knowledgebase.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.knowledgebase.entity.DocumentChunk;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import java.util.List;
import java.util.Map;
/**
* 文档分块 Mapper 接口
*/
@Mapper
public interface DocumentChunkMapper extends BaseMapper<DocumentChunk> {
/**
* 自定义SQL:向量相似度搜索
* 使用余弦相似度计算
*/
@Select({
"SELECT id, document_name, chunk_content, chunk_index, ",
"embedding_vector, vector_dimension, ",
"(",
" SELECT SUM(JSON_EXTRACT(dc.embedding_vector, CONCAT('$[', n-1, ']')) * ",
" JSON_EXTRACT(#{queryVector}, CONCAT('$[', n-1, ']')) ",
" FROM (",
" SELECT 1 AS n UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5",
" -- 这里需要根据实际向量维度生成序列,建议使用存储过程或程序计算",
" ) numbers",
" WHERE n <= #{dimension}",
") / (",
" SQRT((",
" SELECT SUM(POW(JSON_EXTRACT(dc.embedding_vector, CONCAT('$[', n-1, ']'), 2)) ",
" FROM (SELECT 1 AS n UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5) numbers",
" WHERE n <= #{dimension}",
" )) * ",
" SQRT((",
" SELECT SUM(POW(JSON_EXTRACT(#{queryVector}, CONCAT('$[', n-1, ']'), 2)) ",
" FROM (SELECT 1 AS n UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5) numbers",
" WHERE n <= #{dimension}",
" ))",
") AS similarity_score",
"FROM document_chunk dc",
"WHERE dc.deleted = 0",
"ORDER BY similarity_score DESC",
"LIMIT #{limit}"
})
List<Map<String, Object>> findSimilarDocuments(
@Param("queryVector") String queryVector,
@Param("dimension") Integer dimension,
@Param("limit") Integer limit
);
/**
* 根据文档名称查询
*/
@Select("SELECT * FROM document_chunk WHERE document_name = #{documentName} AND deleted = 0")
List<DocumentChunk> selectByDocumentName(@Param("documentName") String documentName);
}
6. MyBatis XML 映射文件 (resources/mapper/DocumentChunkMapper.xml)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.knowledgebase.mapper.DocumentChunkMapper">
<!-- 通用查询映射结果 -->
<resultMap id="BaseResultMap" type="com.example.knowledgebase.entity.DocumentChunk">
<id column="id" property="id" />
<result column="document_name" property="documentName" />
<result column="document_type" property="documentType" />
<result column="chunk_content" property="chunkContent" />
<result column="chunk_index" property="chunkIndex" />
<result column="embedding_vector" property="embeddingVector" />
<result column="vector_dimension" property="vectorDimension" />
<result column="create_time" property="createTime" />
<result column="update_time" property="updateTime" />
<result column="deleted" property="deleted" />
</resultMap>
<!-- 更高效的向量相似度搜索(使用程序计算) -->
<select id="findSimilarDocuments" resultType="java.util.Map">
SELECT
id,
document_name as documentName,
chunk_content as chunkContent,
chunk_index as chunkIndex,
embedding_vector as embeddingVector
FROM document_chunk
WHERE deleted = 0
ORDER BY
-- 这里在实际生产环境中应该使用数据库的向量计算功能
-- MySQL 8.0 可以使用自定义函数或程序计算
id DESC
LIMIT #{limit}
</select>
</mapper>
7. 向量计算工具类 (util/VectorMathUtil.java)
package com.example.knowledgebase.util;
import cn.hutool.json.JSONUtil;
import lombok.experimental.UtilityClass;
import java.util.List;
/**
* 向量数学计算工具类
*/
@UtilityClass
public class VectorMathUtil {
/**
* 计算余弦相似度
*/
public static double cosineSimilarity(List<Double> vector1, List<Double> vector2) {
if (vector1.size() != vector2.size()) {
throw new IllegalArgumentException("Vectors must have the same dimension");
}
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0;
for (int i = 0; i < vector1.size(); i++) {
dotProduct += vector1.get(i) * vector2.get(i);
norm1 += Math.pow(vector1.get(i), 2);
norm2 += Math.pow(vector2.get(i), 2);
}
if (norm1 == 0 || norm2 == 0) {
return 0.0;
}
return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
}
/**
* JSON字符串转向量列表
*/
public static List<Double> jsonToVector(String jsonVector) {
return JSONUtil.toList(jsonVector, Double.class);
}
/**
* 向量列表转JSON字符串
*/
public static String vectorToJson(List<Double> vector) {
return JSONUtil.toJsonStr(vector);
}
}
8. 文本分块工具 (util/TextSplitter.java)
package com.example.knowledgebase.util;
import lombok.experimental.UtilityClass;
import java.util.ArrayList;
import java.util.List;
/**
* 文本分块工具类
*/
@UtilityClass
public class TextSplitter {
/**
* 按固定大小分块
*/
public static List<String> splitBySize(String text, int chunkSize, int overlap) {
List<String> chunks = new ArrayList<>();
if (text == null || text.isEmpty()) {
return chunks;
}
int start = 0;
while (start < text.length()) {
int end = Math.min(start + chunkSize, text.length());
// 确保不在单词中间分割
if (end < text.length()) {
while (end > start && !Character.isWhitespace(text.charAt(end - 1)) &&
end > start + chunkSize * 0.8) {
end--;
}
}
String chunk = text.substring(start, end).trim();
if (!chunk.isEmpty()) {
chunks.add(chunk);
}
// 移动起始位置,考虑重叠
start = end - overlap;
if (start < 0) start = 0;
}
return chunks;
}
/**
* 按句子分块(简单的句子分割)
*/
public static List<String> splitBySentences(String text, int sentencesPerChunk) {
List<String> chunks = new ArrayList<>();
if (text == null || text.isEmpty()) {
return chunks;
}
// 简单的句子分割(按标点符号)
String[] sentences = text.split("[.!?。!?]");
StringBuilder currentChunk = new StringBuilder();
int sentenceCount = 0;
for (String sentence : sentences) {
String trimmed = sentence.trim();
if (!trimmed.isEmpty()) {
if (currentChunk.length() > 0) {
currentChunk.append(". ");
}
currentChunk.append(trimmed);
sentenceCount++;
if (sentenceCount >= sentencesPerChunk) {
chunks.add(currentChunk.toString());
currentChunk = new StringBuilder();
sentenceCount = 0;
}
}
}
// 添加最后不满一个chunk的内容
if (currentChunk.length() > 0) {
chunks.add(currentChunk.toString());
}
return chunks;
}
}
9. 嵌入服务 (service/EmbeddingService.java)
package com.example.knowledgebase.service;
import com.example.knowledgebase.util.VectorMathUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 向量嵌入服务
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class EmbeddingService {
private final EmbeddingModel embeddingModel;
/**
* 为文本生成嵌入向量
*/
public List<Double> generateEmbedding(String text) {
try {
EmbeddingResponse response = embeddingModel.call(
new EmbeddingRequest(List.of(text), null)
);
List<Double> embedding = response.getResults().get(0).getOutput();
log.info("生成嵌入向量成功,文本长度: {}, 向量维度: {}", text.length(), embedding.size());
return embedding;
} catch (Exception e) {
log.error("生成嵌入向量失败: {}", e.getMessage(), e);
throw new RuntimeException("嵌入向量生成失败: " + e.getMessage(), e);
}
}
/**
* 批量生成嵌入向量
*/
public List<List<Double>> generateBatchEmbeddings(List<String> texts) {
try {
EmbeddingResponse response = embeddingModel.call(
new EmbeddingRequest(texts, null)
);
List<List<Double>> embeddings = response.getResults().stream()
.map(result -> result.getOutput())
.toList();
log.info("批量生成嵌入向量成功,文本数量: {}, 向量维度: {}", texts.size(),
embeddings.isEmpty() ? 0 : embeddings.get(0).size());
return embeddings;
} catch (Exception e) {
log.error("批量生成嵌入向量失败: {}", e.getMessage(), e);
throw new RuntimeException("批量嵌入向量生成失败: " + e.getMessage(), e);
}
}
/**
* 计算相似度
*/
public double calculateSimilarity(String text1, String text2) {
List<Double> embedding1 = generateEmbedding(text1);
List<Double> embedding2 = generateEmbedding(text2);
return VectorMathUtil.cosineSimilarity(embedding1, embedding2);
}
/**
* 向量转JSON字符串
*/
public String vectorToJson(List<Double> vector) {
return VectorMathUtil.vectorToJson(vector);
}
/**
* JSON字符串转向量
*/
public List<Double> jsonToVector(String json) {
return VectorMathUtil.jsonToVector(json);
}
}
10. 文件解析服务 (service/FileParseService.java)
package com.example.knowledgebase.service;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/**
* 文件解析服务
*/
@Slf4j
@Service
public class FileParseService {
/**
* 解析文本文件
*/
public String parseTextFile(MultipartFile file) throws IOException {
log.info("解析文本文件: {}", file.getOriginalFilename());
return new String(file.getBytes(), StandardCharsets.UTF_8);
}
/**
* 解析PDF文件
*/
public String parsePdfFile(MultipartFile file) throws IOException {
log.info("解析PDF文件: {}", file.getOriginalFilename());
try (PDDocument document = PDDocument.load(file.getInputStream())) {
PDFTextStripper stripper = new PDFTextStripper();
stripper.setSortByPosition(true);
String text = stripper.getText(document);
log.info("PDF解析成功,页数: {}, 文本长度: {}",
document.getNumberOfPages(), text.length());
return text;
} catch (Exception e) {
log.error("PDF解析失败: {}", e.getMessage(), e);
throw new IOException("PDF文件解析失败: " + e.getMessage(), e);
}
}
/**
* 根据文件类型解析文件
*/
public String parseFile(MultipartFile file) throws IOException {
String filename = file.getOriginalFilename().toLowerCase();
if (filename.endsWith(".txt")) {
return parseTextFile(file);
} else if (filename.endsWith(".pdf")) {
return parsePdfFile(file);
} else {
throw new IllegalArgumentException("不支持的文件类型: " + filename);
}
}
/**
* 获取文件类型
*/
public String getFileType(String filename) {
if (filename.toLowerCase().endsWith(".txt")) {
return "txt";
} else if (filename.toLowerCase().endsWith(".pdf")) {
return "pdf";
} else if (filename.toLowerCase().endsWith(".docx")) {
return "docx";
} else {
return "unknown";
}
}
}
11. 主业务服务接口和实现
由于篇幅限制,这里只展示核心部分,完整代码需要分多个文件。服务接口 (service/IDocumentService.java)
package com.example.knowledgebase.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.example.knowledgebase.entity.DocumentChunk;
import com.example.knowledgebase.dto.SearchRequestDTO;
import com.example.knowledgebase.dto.SearchResultDTO;
import org.springframework.web.multipart.MultipartFile;
import java.util.List;
public interface IDocumentService extends IService<DocumentChunk> {
boolean processAndStoreDocument(MultipartFile file);
List<SearchResultDTO> semanticSearch(SearchRequestDTO request);
boolean deleteDocument(String documentName);
}
服务实现 (service/impl/DocumentServiceImpl.java)
package com.example.knowledgebase.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.knowledgebase.dto.SearchRequestDTO;
import com.example.knowledgebase.dto.SearchResultDTO;
import com.example.knowledgebase.entity.DocumentChunk;
import com.example.knowledgebase.mapper.DocumentChunkMapper;
import com.example.knowledgebase.service.EmbeddingService;
import com.example.knowledgebase.service.FileParseService;
import com.example.knowledgebase.service.IDocumentService;
import com.example.knowledgebase.util.TextSplitter;
import com.example.knowledgebase.util.VectorMathUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
@Slf4j
@Service
@RequiredArgsConstructor
public class DocumentServiceImpl extends ServiceImpl<DocumentChunkMapper, DocumentChunk>
implements IDocumentService {
private final EmbeddingService embeddingService;
private final FileParseService fileParseService;
@Override
public boolean processAndStoreDocument(MultipartFile file) {
try {
String filename = file.getOriginalFilename();
log.info("开始处理文档: {}", filename);
// 1. 解析文件内容
String content = fileParseService.parseFile(file);
log.info("文档解析成功,内容长度: {}", content.length());
// 2. 文本分块
List<String> chunks = TextSplitter.splitBySize(content, 500, 50);
log.info("文本分块完成,块数量: {}", chunks.size());
// 3. 批量生成嵌入向量
List<List<Double>> embeddings = embeddingService.generateBatchEmbeddings(chunks);
// 4. 保存到数据库
List<DocumentChunk> documentChunks = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
DocumentChunk chunk = new DocumentChunk()
.setDocumentName(filename)
.setDocumentType(fileParseService.getFileType(filename))
.setChunkContent(chunks.get(i))
.setChunkIndex(i)
.setEmbeddingVector(embeddingService.vectorToJson(embeddings.get(i)))
.setVectorDimension(embeddings.get(i).size())
.setCreateTime(LocalDateTime.now())
.setUpdateTime(LocalDateTime.now())
.setDeleted(0);
documentChunks.add(chunk);
}
// 批量保存
boolean success = saveBatch(documentChunks);
log.info("文档处理完成: {}, 成功保存 {} 个分块", filename, documentChunks.size());
return success;
} catch (Exception e) {
log.error("文档处理失败: {}", e.getMessage(), e);
return false;
}
}
@Override
public List<SearchResultDTO> semanticSearch(SearchRequestDTO request) {
try {
// 1. 为查询文本生成向量
List<Double> queryVector = embeddingService.generateEmbedding(request.getQuery());
String queryVectorJson = embeddingService.vectorToJson(queryVector);
// 2. 获取所有文档块进行相似度计算(生产环境应使用向量数据库)
List<DocumentChunk> allChunks = baseMapper.selectList(
new LambdaQueryWrapper<DocumentChunk>().eq(DocumentChunk::getDeleted, 0)
);
// 3. 计算相似度并排序
List<SearchResultDTO> results = allChunks.stream()
.map(chunk -> {
List<Double> chunkVector = embeddingService.jsonToVector(chunk.getEmbeddingVector());
double similarity = VectorMathUtil.cosineSimilarity(queryVector, chunkVector);
return new SearchResultDTO()
.setDocumentName(chunk.getDocumentName())
.setChunkContent(chunk.getChunkContent())
.setChunkIndex(chunk.getChunkIndex())
.setSimilarityScore(similarity);
})
.sorted((a, b) -> Double.compare(b.getSimilarityScore(), a.getSimilarityScore()))
.limit(request.getTopK())
.collect(Collectors.toList());
log.info("语义搜索完成,查询: {}, 返回结果数: {}", request.getQuery(), results.size());
return results;
} catch (Exception e) {
log.error("语义搜索失败: {}", e.getMessage(), e);
return new ArrayList<>();
}
}
@Override
public boolean deleteDocument(String documentName) {
try {
// 逻辑删除
int affected = baseMapper.delete(
new LambdaQueryWrapper<DocumentChunk>()
.eq(DocumentChunk::getDocumentName, documentName)
);
log.info("删除文档: {}, 影响行数: {}", documentName, affected);
return affected > 0;
} catch (Exception e) {
log.error("删除文档失败: {}", e.getMessage(), e);
return false;
}
}
}
12. DTO 对象
文档上传DTO (dto/DocumentUploadDTO.java)
package com.example.knowledgebase.dto;
import lombok.Data;
import org.springframework.web.multipart.MultipartFile;
@Data
public class DocumentUploadDTO {
private MultipartFile file;
private String description;
}
搜索请求DTO (dto/SearchRequestDTO.java)
package com.example.knowledgebase.dto;
import lombok.Data;
@Data
public class SearchRequestDTO {
private String query;
private Integer topK = 5;
}
搜索结果DTO (dto/SearchResultDTO.java)
package com.example.knowledgebase.dto;
import lombok.Data;
import lombok.experimental.Accessors;
@Data
@Accessors(chain = true)
public class SearchResultDTO {
private String documentName;
private String chunkContent;
private Integer chunkIndex;
private Double similarityScore;
}
13. 控制器 (controller/DocumentController.java)
package com.example.knowledgebase.controller;
import com.example.knowledgebase.dto.DocumentUploadDTO;
import com.example.knowledgebase.dto.SearchRequestDTO;
import com.example.knowledgebase.dto.SearchResultDTO;
import com.example.knowledgebase.service.IDocumentService;
import lombok.RequiredArgsConstructor;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.util.List;
@RestController
@RequestMapping("/api/documents")
@RequiredArgsConstructor
public class DocumentController {
private final IDocumentService documentService;
@PostMapping("/upload")
public ResponseEntity<String> uploadDocument(@RequestParam("file") MultipartFile file) {
try {
if (file.isEmpty()) {
return ResponseEntity.badRequest().body("文件不能为空");
}
boolean success = documentService.processAndStoreDocument(file);
if (success) {
return ResponseEntity.ok("文档上传和处理成功");
} else {
return ResponseEntity.internalServerError().body("文档处理失败");
}
} catch (Exception e) {
return ResponseEntity.internalServerError().body("上传失败: " + e.getMessage());
}
}
@PostMapping("/search")
public ResponseEntity<List<SearchResultDTO>> semanticSearch(@RequestBody SearchRequestDTO request) {
try {
List<SearchResultDTO> results = documentService.semanticSearch(request);
return ResponseEntity.ok(results);
} catch (Exception e) {
return ResponseEntity.internalServerError().body(null);
}
}
@DeleteMapping("/{documentName}")
public ResponseEntity<String> deleteDocument(@PathVariable String documentName) {
try {
boolean success = documentService.deleteDocument(documentName);
if (success) {
return ResponseEntity.ok("文档删除成功");
} else {
return ResponseEntity.internalServerError().body("文档删除失败");
}
} catch (Exception e) {
return ResponseEntity.internalServerError().body("删除失败: " + e.getMessage());
}
}
}
14. 配置类 (config/MybatisPlusConfig.java)
package com.example.knowledgebase.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
/**
* 分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
15. 启动类 (KnowledgeBaseApplication.java)
package com.example.knowledgebase;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class KnowledgeBaseApplication {
public static void main(String[] args) {
SpringApplication.run(KnowledgeBaseApplication.class, args);
}
}
- 数据库初始化
创建数据库表 SQL 脚本:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS `ai_knowledge_db` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE `ai_knowledge_db`;
-- 创建文档分块表
CREATE TABLE IF NOT EXISTS `document_chunk` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`document_name` varchar(255) NOT NULL COMMENT '文档名称',
`document_type` varchar(50) DEFAULT 'txt' COMMENT '文档类型',
`chunk_content` text COMMENT '分块内容',
`chunk_index` int(11) DEFAULT 0 COMMENT '分块索引',
`embedding_vector` json COMMENT '嵌入向量(JSON数组)',
`vector_dimension` int(11) DEFAULT 1536 COMMENT '向量维度',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`deleted` tinyint(1) DEFAULT 0 COMMENT '逻辑删除(0-未删除,1-已删除)',
PRIMARY KEY (`id`),
KEY `idx_document_name` (`document_name`),
KEY `idx_create_time` (`create_time`),
KEY `idx_deleted` (`deleted`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='文档分块表';
-- 创建索引优化查询性能
CREATE INDEX idx_document_type ON document_chunk(document_type);
CREATE INDEX idx_vector_dimension ON document_chunk(vector_dimension);
- 运行和测试
1. 启动应用
mvn spring-boot:run
好的,基于您的要求,我将为您创建一个使用 Spring AI + MyBatis-Plus + MySQL 的完整知识库对接项目。这个版本会比之前的使用 JPA 的版本更加详细和实用。
项目:基于 Spring AI 和 MyBatis-Plus 的知识库智能处理系统
第一步:项目概述与技术栈
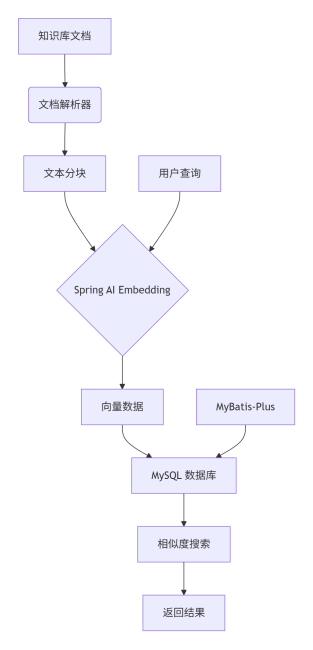
项目架构图
graph TD
A[知识库文档] --> B(文档解析器)
B --> C[文本分块]
C --> D{Spring AI Embedding}
D --> E[向量数据]
E --> F[MySQL 数据库]
G[用户查询] --> D
H[MyBatis-Plus] --> F
F --> I[相似度搜索]
I --> J[返回结果]
技术栈明细
- Java 17 + Spring Boot 3.2.4
- Spring AI 0.8.1:处理 AI 相关功能
- MyBatis-Plus 3.5.4:数据库 ORM 框架
- MySQL 8.0+:数据存储
- Lombok:简化实体类开发
- Hutool:工具库
- Maven:项目管理
第二步:完整的项目结构
spring-ai-knowledge-base/
│
├── src/main/
│ ├── java/
│ │ └── com/
│ │ └── example/
│ │ └── knowledgebase/
│ │ ├── KnowledgeBaseApplication.java # 启动类
│ │ ├── config/
│ │ │ ├── MybatisPlusConfig.java # MyBatis-Plus 配置
│ │ │ └── WebConfig.java # Web配置
│ │ ├── controller/
│ │ │ ├── DocumentController.java # 文档处理控制器
│ │ │ └── SearchController.java # 搜索控制器
│ │ ├── entity/
│ │ │ └── DocumentChunk.java # 实体类
│ │ ├── mapper/
│ │ │ └── DocumentChunkMapper.java # MyBatis Mapper
│ │ ├── service/
│ │ │ ├── IDocumentService.java # 服务接口
│ │ │ ├── impl/
│ │ │ │ └── DocumentServiceImpl.java # 服务实现
│ │ │ ├── EmbeddingService.java # 嵌入服务
│ │ │ └── FileParseService.java # 文件解析服务
│ │ ├── dto/
│ │ │ ├── DocumentUploadDTO.java # 文档上传DTO
│ │ │ ├── SearchRequestDTO.java # 搜索请求DTO
│ │ │ └── SearchResultDTO.java # 搜索结果DTO
│ │ └── util/
│ │ ├── TextSplitter.java # 文本分块工具
│ │ └── VectorMathUtil.java # 向量计算工具
│ │
│ └── resources/
│ ├── application.yml # 主配置文件
│ ├── application-dev.yml # 开发环境配置
│ ├── application-prod.yml # 生产环境配置
│ ├── mapper/
│ │ └── DocumentChunkMapper.xml # MyBatis XML映射文件
│ └── static/
│ └── documents/ # 文档上传目录
│
├── pom.xml # Maven依赖配置
└── README.md # 项目说明文档
第三步:详细配置和代码实现
1. Maven 依赖配置 (pom.xml)
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>spring-ai-knowledge-base</artifactId>
<version>1.0.0</version>
<name>spring-ai-knowledge-base</name>
<description>基于Spring AI和MyBatis-Plus的知识库系统</description>
<properties>
<java.version>17</java.version>
<spring-ai.version>0.8.1</spring-ai.version>
<mybatis-plus.version>3.5.4.1</mybatis-plus.version>
<hutool.version>5.8.22</hutool.version>
</properties>
<dependencies>
<!-- Spring Boot 基础依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<!-- MyBatis-Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- 工具类 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
</dependency>
<!-- 文件处理 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.29</version>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories></project>
2. 配置文件 (application.yml)
# 主配置文件spring:
profiles:
active: dev # 默认使用开发环境配置
servlet:
multipart:
max-file-size: 10MB
max-request-size: 10MB
# MyBatis-Plus 配置mybatis-plus:
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: auto
logic-delete-field: deleted # 逻辑删除字段
logic-delete-value: 1
logic-not-delete-value: 0
# 日志配置logging:
level:
com.example.knowledgebase: debug
org.springframework.ai: debug
3. 开发环境配置 (application-dev.yml)
# 开发环境配置spring:
datasource:
driver-class-name: com.mysql.cj.Driver
url: jdbc:mysql://localhost:3306/ai_knowledge_db?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
ai:
openai:
api-key: ${OPENAI_API_KEY:sk-your-api-key-here} # 建议使用环境变量
base-url: https://api.openai.com # 如果使用第三方代理,可修改此处
embedding:
model: text-embedding-3-small
dimensions: 1536
# 文件上传路径file:
upload:
path: ./uploads/
4. 数据库实体类 (entity/DocumentChunk.java)
package com.example.knowledgebase.entity;
import com.baomidou.mybatisplus.annotation.*;import lombok.Data;import lombok.EqualsAndHashCode;import lombok.experimental.Accessors;
import java.io.Serializable;import java.time.LocalDateTime;
/**
* 文档分块实体类
*/@Data@EqualsAndHashCode(callSuper = false)@Accessors(chain = true)@TableName("document_chunk")public class DocumentChunk implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/**
* 文档名称
*/
@TableField("document_name")
private String documentName;
/**
* 文档类型 (txt, pdf, docx)
*/
@TableField("document_type")
private String documentType;
/**
* 分块内容
*/
@TableField("chunk_content")
private String chunkContent;
/**
* 分块索引 (同一文档中的第几个分块)
*/
@TableField("chunk_index")
private Integer chunkIndex;
/**
* 向量数据 (JSON数组格式)
*/
@TableField("embedding_vector")
private String embeddingVector;
/**
* 向量维度
*/
@TableField("vector_dimension")
private Integer vectorDimension;
/**
* 创建时间
*/
@TableField(value = "create_time", fill = FieldFill.INSERT)
private LocalDateTime createTime;
/**
* 更新时间
*/
@TableField(value = "update_time", fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
/**
* 逻辑删除 (0-未删除, 1-已删除)
*/
@TableField("deleted")
@TableLogic
private Integer deleted;
}
5. MyBatis Mapper 接口 (mapper/DocumentChunkMapper.java)
package com.example.knowledgebase.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;import com.example.knowledgebase.entity.DocumentChunk;import org.apache.ibatis.annotations.Mapper;import org.apache.ibatis.annotations.Param;import org.apache.ibatis.annotations.Select;
import java.util.List;import java.util.Map;
/**
* 文档分块 Mapper 接口
*/@Mapperpublic interface DocumentChunkMapper extends BaseMapper<DocumentChunk> {
/**
* 自定义SQL:向量相似度搜索
* 使用余弦相似度计算
*/
@Select({
"SELECT id, document_name, chunk_content, chunk_index, ",
"embedding_vector, vector_dimension, ",
"(",
" SELECT SUM(JSON_EXTRACT(dc.embedding_vector, CONCAT('$[', n-1, ']')) * ",
" JSON_EXTRACT(#{queryVector}, CONCAT('$[', n-1, ']')) ",
" FROM (",
" SELECT 1 AS n UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5",
" -- 这里需要根据实际向量维度生成序列,建议使用存储过程或程序计算",
" ) numbers",
" WHERE n <= #{dimension}",
") / (",
" SQRT((",
" SELECT SUM(POW(JSON_EXTRACT(dc.embedding_vector, CONCAT('$[', n-1, ']'), 2)) ",
" FROM (SELECT 1 AS n UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5) numbers",
" WHERE n <= #{dimension}",
" )) * ",
" SQRT((",
" SELECT SUM(POW(JSON_EXTRACT(#{queryVector}, CONCAT('$[', n-1, ']'), 2)) ",
" FROM (SELECT 1 AS n UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5) numbers",
" WHERE n <= #{dimension}",
" ))",
") AS similarity_score",
"FROM document_chunk dc",
"WHERE dc.deleted = 0",
"ORDER BY similarity_score DESC",
"LIMIT #{limit}"
})
List<Map<String, Object>> findSimilarDocuments(
@Param("queryVector") String queryVector,
@Param("dimension") Integer dimension,
@Param("limit") Integer limit
);
/**
* 根据文档名称查询
*/
@Select("SELECT * FROM document_chunk WHERE document_name = #{documentName} AND deleted = 0")
List<DocumentChunk> selectByDocumentName(@Param("documentName") String documentName);
}
6. MyBatis XML 映射文件 (resources/mapper/DocumentChunkMapper.xml)
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.example.knowledgebase.mapper.DocumentChunkMapper">
<!-- 通用查询映射结果 -->
<resultMap id="BaseResultMap" type="com.example.knowledgebase.entity.DocumentChunk">
<id column="id" property="id" />
<result column="document_name" property="documentName" />
<result column="document_type" property="documentType" />
<result column="chunk_content" property="chunkContent" />
<result column="chunk_index" property="chunkIndex" />
<result column="embedding_vector" property="embeddingVector" />
<result column="vector_dimension" property="vectorDimension" />
<result column="create_time" property="createTime" />
<result column="update_time" property="updateTime" />
<result column="deleted" property="deleted" />
</resultMap>
<!-- 更高效的向量相似度搜索(使用程序计算) -->
<select id="findSimilarDocuments" resultType="java.util.Map">
SELECT
id,
document_name as documentName,
chunk_content as chunkContent,
chunk_index as chunkIndex,
embedding_vector as embeddingVector
FROM document_chunk
WHERE deleted = 0
ORDER BY
-- 这里在实际生产环境中应该使用数据库的向量计算功能
-- MySQL 8.0 可以使用自定义函数或程序计算
id DESC
LIMIT #{limit}
</select>
</mapper>
7. 向量计算工具类 (util/VectorMathUtil.java)
package com.example.knowledgebase.util;
import cn.hutool.json.JSONUtil;import lombok.experimental.UtilityClass;import java.util.List;
/**
* 向量数学计算工具类
*/@UtilityClasspublic class VectorMathUtil {
/**
* 计算余弦相似度
*/
public static double cosineSimilarity(List<Double> vector1, List<Double> vector2) {
if (vector1.size() != vector2.size()) {
throw new IllegalArgumentException("Vectors must have the same dimension");
}
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0;
for (int i = 0; i < vector1.size(); i++) {
dotProduct += vector1.get(i) * vector2.get(i);
norm1 += Math.pow(vector1.get(i), 2);
norm2 += Math.pow(vector2.get(i), 2);
}
if (norm1 == 0 || norm2 == 0) {
return 0.0;
}
return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
}
/**
* JSON字符串转向量列表
*/
public static List<Double> jsonToVector(String jsonVector) {
return JSONUtil.toList(jsonVector, Double.class);
}
/**
* 向量列表转JSON字符串
*/
public static String vectorToJson(List<Double> vector) {
return JSONUtil.toJsonStr(vector);
}
}
8. 文本分块工具 (util/TextSplitter.java)
package com.example.knowledgebase.util;
import lombok.experimental.UtilityClass;import java.util.ArrayList;import java.util.List;
/**
* 文本分块工具类
*/@UtilityClasspublic class TextSplitter {
/**
* 按固定大小分块
*/
public static List<String> splitBySize(String text, int chunkSize, int overlap) {
List<String> chunks = new ArrayList<>();
if (text == null || text.isEmpty()) {
return chunks;
}
int start = 0;
while (start < text.length()) {
int end = Math.min(start + chunkSize, text.length());
// 确保不在单词中间分割
if (end < text.length()) {
while (end > start && !Character.isWhitespace(text.charAt(end - 1)) &&
end > start + chunkSize * 0.8) {
end--;
}
}
String chunk = text.substring(start, end).trim();
if (!chunk.isEmpty()) {
chunks.add(chunk);
}
// 移动起始位置,考虑重叠
start = end - overlap;
if (start < 0) start = 0;
}
return chunks;
}
/**
* 按句子分块(简单的句子分割)
*/
public static List<String> splitBySentences(String text, int sentencesPerChunk) {
List<String> chunks = new ArrayList<>();
if (text == null || text.isEmpty()) {
return chunks;
}
// 简单的句子分割(按标点符号)
String[] sentences = text.split("[.!?。!?]");
StringBuilder currentChunk = new StringBuilder();
int sentenceCount = 0;
for (String sentence : sentences) {
String trimmed = sentence.trim();
if (!trimmed.isEmpty()) {
if (currentChunk.length() > 0) {
currentChunk.append(". ");
}
currentChunk.append(trimmed);
sentenceCount++;
if (sentenceCount >= sentencesPerChunk) {
chunks.add(currentChunk.toString());
currentChunk = new StringBuilder();
sentenceCount = 0;
}
}
}
// 添加最后不满一个chunk的内容
if (currentChunk.length() > 0) {
chunks.add(currentChunk.toString());
}
return chunks;
}
}
9. 嵌入服务 (service/EmbeddingService.java)
package com.example.knowledgebase.service;
import com.example.knowledgebase.util.VectorMathUtil;import lombok.RequiredArgsConstructor;import lombok.extern.slf4j.Slf4j;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.embedding.EmbeddingRequest;import org.springframework.ai.embedding.EmbeddingResponse;import org.springframework.stereotype.Service;
import java.util.List;
/**
* 向量嵌入服务
*/@Slf4j@Service@RequiredArgsConstructorpublic class EmbeddingService {
private final EmbeddingModel embeddingModel;
/**
* 为文本生成嵌入向量
*/
public List<Double> generateEmbedding(String text) {
try {
EmbeddingResponse response = embeddingModel.call(
new EmbeddingRequest(List.of(text), null)
);
List<Double> embedding = response.getResults().get(0).getOutput();
log.info("生成嵌入向量成功,文本长度: {}, 向量维度: {}", text.length(), embedding.size());
return embedding;
} catch (Exception e) {
log.error("生成嵌入向量失败: {}", e.getMessage(), e);
throw new RuntimeException("嵌入向量生成失败: " + e.getMessage(), e);
}
}
/**
* 批量生成嵌入向量
*/
public List<List<Double>> generateBatchEmbeddings(List<String> texts) {
try {
EmbeddingResponse response = embeddingModel.call(
new EmbeddingRequest(texts, null)
);
List<List<Double>> embeddings = response.getResults().stream()
.map(result -> result.getOutput())
.toList();
log.info("批量生成嵌入向量成功,文本数量: {}, 向量维度: {}", texts.size(),
embeddings.isEmpty() ? 0 : embeddings.get(0).size());
return embeddings;
} catch (Exception e) {
log.error("批量生成嵌入向量失败: {}", e.getMessage(), e);
throw new RuntimeException("批量嵌入向量生成失败: " + e.getMessage(), e);
}
}
/**
* 计算相似度
*/
public double calculateSimilarity(String text1, String text2) {
List<Double> embedding1 = generateEmbedding(text1);
List<Double> embedding2 = generateEmbedding(text2);
return VectorMathUtil.cosineSimilarity(embedding1, embedding2);
}
/**
* 向量转JSON字符串
*/
public String vectorToJson(List<Double> vector) {
return VectorMathUtil.vectorToJson(vector);
}
/**
* JSON字符串转向量
*/
public List<Double> jsonToVector(String json) {
return VectorMathUtil.jsonToVector(json);
}
}
10. 文件解析服务 (service/FileParseService.java)
package com.example.knowledgebase.service;
import lombok.extern.slf4j.Slf4j;import org.apache.pdfbox.pdmodel.PDDocument;import org.apache.pdfbox.text.PDFTextStripper;import org.springframework.stereotype.Service;import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;import java.nio.charset.StandardCharsets;
/**
* 文件解析服务
*/@Slf4j@Servicepublic class FileParseService {
/**
* 解析文本文件
*/
public String parseTextFile(MultipartFile file) throws IOException {
log.info("解析文本文件: {}", file.getOriginalFilename());
return new String(file.getBytes(), StandardCharsets.UTF_8);
}
/**
* 解析PDF文件
*/
public String parsePdfFile(MultipartFile file) throws IOException {
log.info("解析PDF文件: {}", file.getOriginalFilename());
try (PDDocument document = PDDocument.load(file.getInputStream())) {
PDFTextStripper stripper = new PDFTextStripper();
stripper.setSortByPosition(true);
String text = stripper.getText(document);
log.info("PDF解析成功,页数: {}, 文本长度: {}",
document.getNumberOfPages(), text.length());
return text;
} catch (Exception e) {
log.error("PDF解析失败: {}", e.getMessage(), e);
throw new IOException("PDF文件解析失败: " + e.getMessage(), e);
}
}
/**
* 根据文件类型解析文件
*/
public String parseFile(MultipartFile file) throws IOException {
String filename = file.getOriginalFilename().toLowerCase();
if (filename.endsWith(".txt")) {
return parseTextFile(file);
} else if (filename.endsWith(".pdf")) {
return parsePdfFile(file);
} else {
throw new IllegalArgumentException("不支持的文件类型: " + filename);
}
}
/**
* 获取文件类型
*/
public String getFileType(String filename) {
if (filename.toLowerCase().endsWith(".txt")) {
return "txt";
} else if (filename.toLowerCase().endsWith(".pdf")) {
return "pdf";
} else if (filename.toLowerCase().endsWith(".docx")) {
return "docx";
} else {
return "unknown";
}
}
}
11. 主业务服务接口和实现
由于篇幅限制,这里只展示核心部分,完整代码需要分多个文件。服务接口 (service/IDocumentService.java)
package com.example.knowledgebase.service;
import com.baomidou.mybatisplus.extension.service.IService;import com.example.knowledgebase.entity.DocumentChunk;import com.example.knowledgebase.dto.SearchRequestDTO;import com.example.knowledgebase.dto.SearchResultDTO;import org.springframework.web.multipart.MultipartFile;
import java.util.List;
public interface IDocumentService extends IService<DocumentChunk> {
boolean processAndStoreDocument(MultipartFile file);
List<SearchResultDTO> semanticSearch(SearchRequestDTO request);
boolean deleteDocument(String documentName);
}
服务实现 (service/impl/DocumentServiceImpl.java)
package com.example.knowledgebase.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import com.example.knowledgebase.dto.SearchRequestDTO;import com.example.knowledgebase.dto.SearchResultDTO;import com.example.knowledgebase.entity.DocumentChunk;import com.example.knowledgebase.mapper.DocumentChunkMapper;import com.example.knowledgebase.service.EmbeddingService;import com.example.knowledgebase.service.FileParseService;import com.example.knowledgebase.service.IDocumentService;import com.example.knowledgebase.util.TextSplitter;import com.example.knowledgebase.util.VectorMathUtil;import lombok.RequiredArgsConstructor;import lombok.extern.slf4j.Slf4j;import org.springframework.stereotype.Service;import org.springframework.web.multipart.MultipartFile;
import java.time.LocalDateTime;import java.util.ArrayList;import java.util.List;import java.util.stream.Collectors;
@Slf4j@Service@RequiredArgsConstructorpublic class DocumentServiceImpl extends ServiceImpl<DocumentChunkMapper, DocumentChunk>
implements IDocumentService {
private final EmbeddingService embeddingService;
private final FileParseService fileParseService;
@Override
public boolean processAndStoreDocument(MultipartFile file) {
try {
String filename = file.getOriginalFilename();
log.info("开始处理文档: {}", filename);
// 1. 解析文件内容
String content = fileParseService.parseFile(file);
log.info("文档解析成功,内容长度: {}", content.length());
// 2. 文本分块
List<String> chunks = TextSplitter.splitBySize(content, 500, 50);
log.info("文本分块完成,块数量: {}", chunks.size());
// 3. 批量生成嵌入向量
List<List<Double>> embeddings = embeddingService.generateBatchEmbeddings(chunks);
// 4. 保存到数据库
List<DocumentChunk> documentChunks = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
DocumentChunk chunk = new DocumentChunk()
.setDocumentName(filename)
.setDocumentType(fileParseService.getFileType(filename))
.setChunkContent(chunks.get(i))
.setChunkIndex(i)
.setEmbeddingVector(embeddingService.vectorToJson(embeddings.get(i)))
.setVectorDimension(embeddings.get(i).size())
.setCreateTime(LocalDateTime.now())
.setUpdateTime(LocalDateTime.now())
.setDeleted(0);
documentChunks.add(chunk);
}
// 批量保存
boolean success = saveBatch(documentChunks);
log.info("文档处理完成: {}, 成功保存 {} 个分块", filename, documentChunks.size());
return success;
} catch (Exception e) {
log.error("文档处理失败: {}", e.getMessage(), e);
return false;
}
}
@Override
public List<SearchResultDTO> semanticSearch(SearchRequestDTO request) {
try {
// 1. 为查询文本生成向量
List<Double> queryVector = embeddingService.generateEmbedding(request.getQuery());
String queryVectorJson = embeddingService.vectorToJson(queryVector);
// 2. 获取所有文档块进行相似度计算(生产环境应使用向量数据库)
List<DocumentChunk> allChunks = baseMapper.selectList(
new LambdaQueryWrapper<DocumentChunk>().eq(DocumentChunk::getDeleted, 0)
);
// 3. 计算相似度并排序
List<SearchResultDTO> results = allChunks.stream()
.map(chunk -> {
List<Double> chunkVector = embeddingService.jsonToVector(chunk.getEmbeddingVector());
double similarity = VectorMathUtil.cosineSimilarity(queryVector, chunkVector);
return new SearchResultDTO()
.setDocumentName(chunk.getDocumentName())
.setChunkContent(chunk.getChunkContent())
.setChunkIndex(chunk.getChunkIndex())
.setSimilarityScore(similarity);
})
.sorted((a, b) -> Double.compare(b.getSimilarityScore(), a.getSimilarityScore()))
.limit(request.getTopK())
.collect(Collectors.toList());
log.info("语义搜索完成,查询: {}, 返回结果数: {}", request.getQuery(), results.size());
return results;
} catch (Exception e) {
log.error("语义搜索失败: {}", e.getMessage(), e);
return new ArrayList<>();
}
}
@Override
public boolean deleteDocument(String documentName) {
try {
// 逻辑删除
int affected = baseMapper.delete(
new LambdaQueryWrapper<DocumentChunk>()
.eq(DocumentChunk::getDocumentName, documentName)
);
log.info("删除文档: {}, 影响行数: {}", documentName, affected);
return affected > 0;
} catch (Exception e) {
log.error("删除文档失败: {}", e.getMessage(), e);
return false;
}
}
}
12. DTO 对象
文档上传DTO (dto/DocumentUploadDTO.java)
package com.example.knowledgebase.dto;
import lombok.Data;import org.springframework.web.multipart.MultipartFile;
@Datapublic class DocumentUploadDTO {
private MultipartFile file;
private String description;
}
搜索请求DTO (dto/SearchRequestDTO.java)
package com.example.knowledgebase.dto;
import lombok.Data;
@Datapublic class SearchRequestDTO {
private String query;
private Integer topK = 5;
}
搜索结果DTO (dto/SearchResultDTO.java)
package com.example.knowledgebase.dto;
import lombok.Data;import lombok.experimental.Accessors;
@Data@Accessors(chain = true)public class SearchResultDTO {
private String documentName;
private String chunkContent;
private Integer chunkIndex;
private Double similarityScore;
}
13. 控制器 (controller/DocumentController.java)
package com.example.knowledgebase.controller;
import com.example.knowledgebase.dto.DocumentUploadDTO;import com.example.knowledgebase.dto.SearchRequestDTO;import com.example.knowledgebase.dto.SearchResultDTO;import com.example.knowledgebase.service.IDocumentService;import lombok.RequiredArgsConstructor;import org.springframework.http.ResponseEntity;import org.springframework.web.bind.annotation.*;import org.springframework.web.multipart.MultipartFile;
import java.util.List;
@RestController@RequestMapping("/api/documents")@RequiredArgsConstructorpublic class DocumentController {
private final IDocumentService documentService;
@PostMapping("/upload")
public ResponseEntity<String> uploadDocument(@RequestParam("file") MultipartFile file) {
try {
if (file.isEmpty()) {
return ResponseEntity.badRequest().body("文件不能为空");
}
boolean success = documentService.processAndStoreDocument(file);
if (success) {
return ResponseEntity.ok("文档上传和处理成功");
} else {
return ResponseEntity.internalServerError().body("文档处理失败");
}
} catch (Exception e) {
return ResponseEntity.internalServerError().body("上传失败: " + e.getMessage());
}
}
@PostMapping("/search")
public ResponseEntity<List<SearchResultDTO>> semanticSearch(@RequestBody SearchRequestDTO request) {
try {
List<SearchResultDTO> results = documentService.semanticSearch(request);
return ResponseEntity.ok(results);
} catch (Exception e) {
return ResponseEntity.internalServerError().body(null);
}
}
@DeleteMapping("/{documentName}")
public ResponseEntity<String> deleteDocument(@PathVariable String documentName) {
try {
boolean success = documentService.deleteDocument(documentName);
if (success) {
return ResponseEntity.ok("文档删除成功");
} else {
return ResponseEntity.internalServerError().body("文档删除失败");
}
} catch (Exception e) {
return ResponseEntity.internalServerError().body("删除失败: " + e.getMessage());
}
}
}
14. 配置类 (config/MybatisPlusConfig.java)
package com.example.knowledgebase.config;
import com.baomidou.mybatisplus.annotation.DbType;import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;
@Configurationpublic class MybatisPlusConfig {
/**
* 分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
15. 启动类 (KnowledgeBaseApplication.java)
package com.example.knowledgebase;
import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplicationpublic class KnowledgeBaseApplication {
public static void main(String[] args) {
SpringApplication.run(KnowledgeBaseApplication.class, args);
}
}
第四步:数据库初始化
创建数据库表 SQL 脚本:
-- 创建数据库CREATE DATABASE IF NOT EXISTS `ai_knowledge_db` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE `ai_knowledge_db`;
-- 创建文档分块表CREATE TABLE IF NOT EXISTS `document_chunk` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`document_name` varchar(255) NOT NULL COMMENT '文档名称',
`document_type` varchar(50) DEFAULT 'txt' COMMENT '文档类型',
`chunk_content` text COMMENT '分块内容',
`chunk_index` int(11) DEFAULT 0 COMMENT '分块索引',
`embedding_vector` json COMMENT '嵌入向量(JSON数组)',
`vector_dimension` int(11) DEFAULT 1536 COMMENT '向量维度',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`deleted` tinyint(1) DEFAULT 0 COMMENT '逻辑删除(0-未删除,1-已删除)',
PRIMARY KEY (`id`),
KEY `idx_document_name` (`document_name`),
KEY `idx_create_time` (`create_time`),
KEY `idx_deleted` (`deleted`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='文档分块表';
-- 创建索引优化查询性能CREATE INDEX idx_document_type ON document_chunk(document_type);CREATE INDEX idx_vector_dimension ON document_chunk(vector_dimension);
第五步:运行和测试
1. 启动应用
mvn spring-boot:run
2. API 测试示例
curl -X POST -F "file=@/path/to/your/document.pdf" http://localhost:8080/api/documents/upload
语义搜索:
curl -X POST http://localhost:8080/api/documents/search \
-H "Content-Type: application/json" \
-d '{"query": "什么是人工智能", "topK": 5}'
删除文档:
curl -X DELETE http://localhost:8080/api/documents/document.pdf
第六步:生产环境优化建议
- 向量数据库:生产环境建议使用专业的向量数据库(如 Milvus、Pinecone、Weaviate)
- 异步处理:大文件处理应使用消息队列异步处理
- 缓存优化:使用 Redis 缓存常用查询结果
- 监控告警:集成 Spring Boot Actuator 进行监控
- 安全加固:添加 API 认证和权限控制
这个完整项目提供了从文件上传、文本处理、向量化到语义搜索的完整解决方案,使用了 MyBatis-Plus 进行高效的数据持久化操作。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 46
46 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)