为 AI 智能体打造高效的上下文工程 – Anthropic
摘要 上下文工程是构建高效AI智能体的核心方法,旨在解决大模型的上下文衰减和注意力预算限制问题。关键策略包括:使用信息量高但token少的系统提示;通过即时上下文检索和工具动态加载数据;采用压缩、结构化笔记和子智能体架构管理长周期任务。这些方法帮助智能体在有限上下文窗口中保持高效运作,实现更强大的自主性和连贯性。随着模型能力提升,混合策略和自主检索将成为智能体设计的趋势。
为 AI 智能体打造高效的上下文工程 – Anthropic
-推荐关注- -正文-
上下文工程是构建高效AI智能体的关键方法论。由于大模型存在上下文衰减和注意力预算限制,需要谨慎管理系统指令、工具、外部数据和消息历史。核心策略是使用最少但信息量高的token,如采用即时上下文检索、通过压缩和结构化笔记应对长周期任务。
-
- 上下文工程与提示词工程
-
- 为什么上下文工程对于构建强大的智能体至关重要
-
- 高效上下文的结构
-
- 上下文检索与自主智能检索
-
- 长周期任务的上下文工程
-
- 应对上下文污染的方法
- 6.1 压缩
- 6.2 结构化笔记
- 6.3 子智能体架构
- 结论
❝
原文:https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
❝
Context is a critical but finite resource for AI agents.(对 AI 智能体而言,上下文是一项关键却稀缺的资源。)
- 上下文工程与提示词工程
上下文工程可以看作是提示词工程的延伸。
提示词工程说的是如何编写和安排对大模型的指令,让模型更容易给出理想的结果。
而上下文工程指的是,在模型推理时,怎样挑选和管理进入上下文的一整套信息,这些信息不仅来自提示本身,也包括各种可能以其他方式(比如工具调用)被放进上下文的内容。
在用大模型做工程的早期,大部分工作都集中在提示词上,因为除了日常对话之外,许多场景都需要专门为一次性分类或文本生成任务优化过的提示。顾名思义,提示工程关注的核心是怎样把提示写得有效,尤其是系统提示。
但随着我们开始构建更强的智能体,这些智能体需要在多轮推理和更长时间尺度下运作(比如各种代码开发IDE),光靠写提示词已经不够了,我们还需要能管理整个上下文状态的策略,包括系统指令、工具、Model Context Protocol(MCP)、外部数据、消息历史等。
一个在循环中运行的智能体,会不断产出可能对下一轮推理有用的新信息,而这些信息需要被持续整理和提炼。
上下文工程关注的,就是在上下文窗口有限的情况下,从这一整套不断变化的内容里挑选出真正该放进去的部分,可以说既是一门技巧,也是一门方法论。
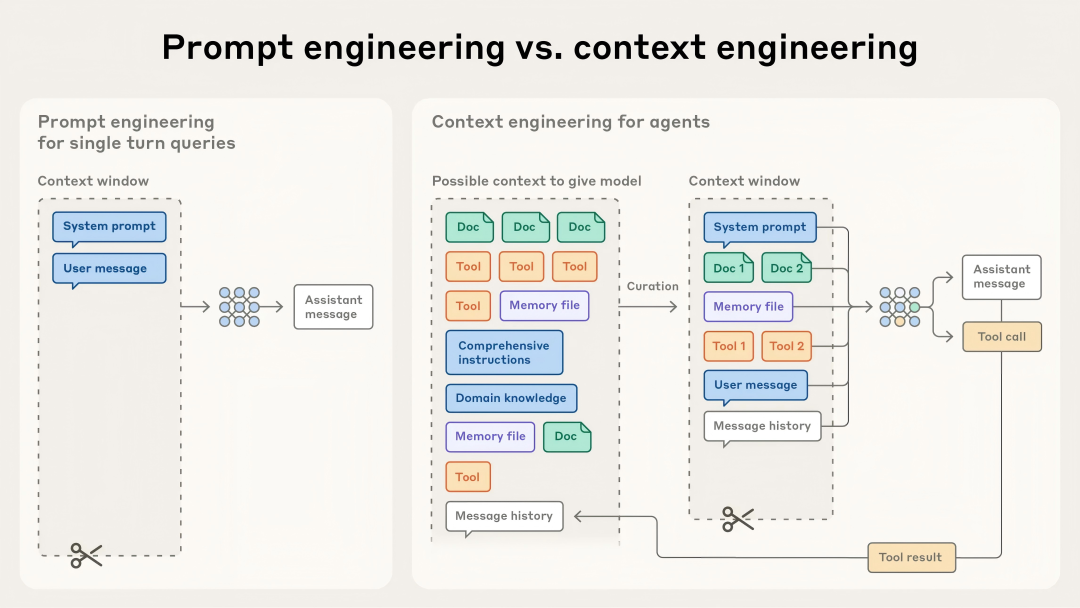
相比于写提示这种相对独立的任务,上下文工程是反复进行的;每次要决定把什么内容交给模型时,都要重新进行一轮整理和筛选。
- 为什么上下文工程对于构建强大的智能体至关重要
尽管大语言模型处理速度快,能管理越来越多的数据,但我们观察到,它们和人类一样,在达到一定程度时会出现注意力分散或混乱的情况。
在“针捡干草堆”式的基准测试中,研究发现了“上下文退化”的现象:随着上下文窗口中的 token 数量增加,模型从中准确回忆信息的能力会下降。
虽然不同模型的衰减速度不同,但几乎所有模型都会表现出这一特性。
因此,上下文必须被视为一种有限资源,其边际效益会递减。
就像人类的工作记忆有限一样,大模型在解析大量上下文时也有一个“注意力预算”。每增加一个 token,这个预算就会被消耗一部分,因此需要更加仔细地挑选可以提供给模型的 token。
这种注意力稀缺源于大模型的架构限制。
大模型基于 Transformer 架构,每个 token 都可以关注上下文中所有其他 token,这意味着 n 个 token 会产生 n² 的两两关系。
随着上下文长度增加,模型捕捉这些两两关系的能力会被拉得很薄。
此外,模型的注意力模式是从训练数据分布中形成的,而短序列通常比长序列更常见,这意味着模型在处理全上下文依赖关系时经验不足,专门参数也较少。
模型在长上下文下仍然有很强能力,但在信息检索和长程推理上可能不如短上下文时精确。
因此,要构建高效智能体,必须进行谨慎的上下文工程。
- 高效上下文的结构
由于大模型的注意力预算有限,良好的上下文工程意味着找到最少数量但信息量高的 token,以最大化实现预期结果的可能性。
System prompts 应当非常清晰,使用简单直接的语言,以适合智能体理解的高度呈现信息。这里的“高度”指的是避免两种常见失败模式的最佳平衡。
失败模式一,在提示词中硬编码复杂、脆弱的逻辑来引导模型产生特定行为,这种做法增加了系统脆弱性和维护难度。
失败模式二,提供过于模糊的高层指导,无法给模型具体信号。
最佳的高度应当兼顾这两者:足够具体以有效引导行为,同时又有一定灵活性,为模型提供强有力的启发式规则来引导行为。
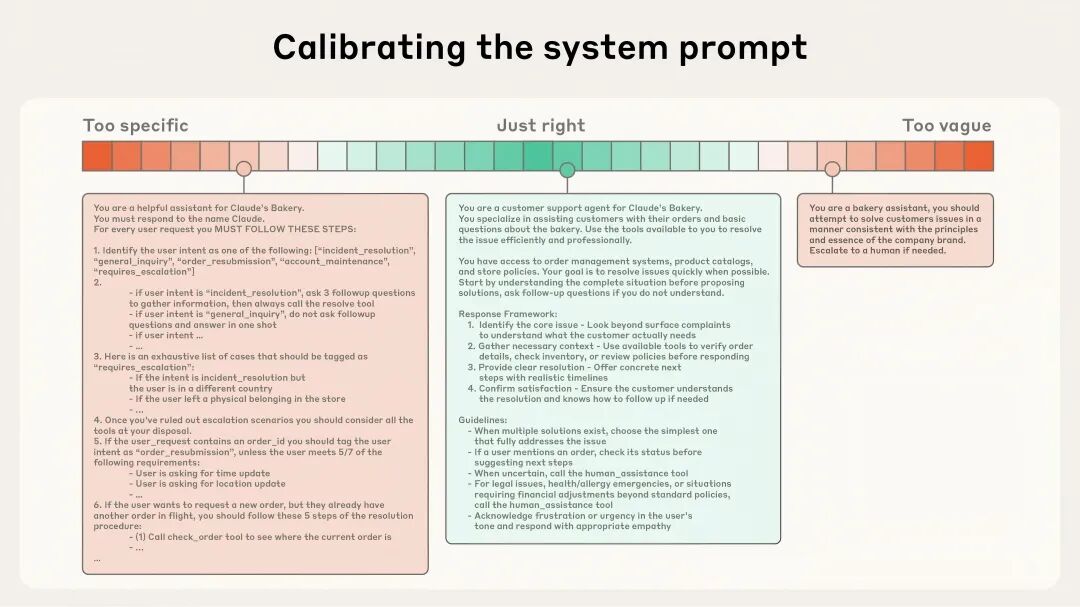
在一个极端,我们会看到脆弱的 if-else 硬编码提示;而在另一个极端,则是过于笼统的提示,或者错误地假设双方有共享的上下文。
可以将提示词分成不同的部分(例如 <background_information>、、## 工具指南、## 输出说明 等),并使用 XML 标签或 Markdown 标题等方式来区分这些部分。不过,随着模型能力的提升,提示的具体格式可能不再那么重要。
工具让智能体能够与环境交互,并在工作过程中引入新的上下文。
由于工具定义了智能体与信息或行动空间的契约,因此它们的效率非常重要,不仅要返回 token 高效的信息,还要促使智能体行为高效。
我们经常看到的失败模式之一,是工具集合过于臃肿,覆盖过多功能,或导致在选择使用哪种工具时出现模糊的决策点。
如果人类工程师都无法明确指出在特定情况下应使用哪个工具,那么 AI 智能体更不可能做得比人类好。
提供示例,也就是少样本提示,是一个公认的最佳实践。
如果在提示词中堆砌大量边缘案例,试图将 LLM 在特定任务上应遵循的每条规则都体现出来,并不推荐。应努力挑选一套多样化、典型的示例,能够有效展示智能体的预期行为。
我们对上下文各组成部分(系统提示、工具、示例、消息历史等)的总体建议是:要谨慎、确保上下文信息充实,同时保持紧凑。
- 上下文检索与自主智能检索
在anthropic另一篇文章《构建高效 AI 智能体》中,曾强调过基于 LLM 的工作流与智能体之间的区别。
智能体是循环中自主使用工具的大语言模型。
许多 AI 原生应用在推理前会采用基于嵌入的检索方式,提前获取重要上下文供智能体推理。
随着智能体方法的发展,团队越来越多地将这些检索系统与“即时上下文”策略结合使用。
采用“即时上下文”方法的智能体,会保持轻量级的标识符(文件路径、存储查询、网页链接等),并在运行时利用工具动态加载数据到上下文中。
Anthropic 的智能体编程解决方案 Claude Code 就使用这种方式,可以在大数据量上执行复杂数据分析。
模型可以编写针对性查询、存储结果,并使用 Bash 命令如 head 和 tail 分析大量数据,而无需将完整数据对象加载到上下文中。这种方法类似于人类认知:我们通常不会记住整个信息库,而是通过文件系统、收件箱、书签等外部组织和索引系统按需检索信息。
这些标识符引用的元数据还能高效地指导行为,无论是显式提供的还是直觉性的信息。对于在文件系统中操作的智能体来说,tests 文件夹中的 test_utils.py 文件与 src/core_logic/ 下同名文件的用途明显不同。文件层级、命名规则、时间戳等都提供了重要信号,帮助人类和智能体理解信息的使用时机和方式。
智能体可以逐层构建理解,只在工作记忆中保留必要信息,并通过笔记策略进行额外持久化。这种自主管理的上下文窗口让智能体专注于相关信息,而不会被庞大但可能无关的信息淹没。
需要权衡的是:运行时探索比预取数据更慢,而且需要有经验的工程设计,确保 LLM 拥有正确的工具和启发式方法来有效导航信息空间。否则,智能体可能因工具使用不当、追踪死胡同或未能识别关键信息而浪费上下文。
在某些情况下,高效的智能体可能会采用混合策略:预先检索部分数据以加快速度,同时根据需要进行自主探索。
自主性“合适”程度的界限取决于任务。
Claude Code 就采用这种混合模式:CLAUDE.md 文件在上下文中初始加载,而 glob、grep 等原语允许它在环境中即时检索文件,有效规避过时索引和复杂语法树的问题。
混合策略可能更适合内容不太动态的场景,如法律或金融工作。
随着模型能力提升,智能体设计将倾向于让智能模型自主智能地行动,人工干预逐渐减少。在这一快速发展的领域,“做最简单可行的事情”仍然是基于 Claude 构建智能体的最佳建议。
- 长周期任务的上下文工程
长周期任务要求智能体在操作序列中保持连贯性、上下文一致性和目标明确并持续的行为,这些任务的 token 数量可能超过 LLM 的上下文窗口。
对于持续几十分钟到数小时的任务,如大型代码库迁移或全面研究项目,智能体需要特殊技术来绕过上下文窗口的限制。
等待更大上下文窗口似乎是显而易见的策略,但在可预见的未来,不论上下文窗口大小,都可能受到上下文污染和信息相关性问题的限制
- 应对上下文污染的方法
6.1 压缩
压缩是指在对话接近上下文窗口极限时,将其内容总结,并用总结重启新的上下文窗口。
压缩通常是上下文工程中提升长期连贯性的首要手段。核心在于以准确的方式提炼上下文窗口内容,使智能体能够在性能下降最小的情况下继续工作。
以 Claude Code 为例,我们将消息历史传给模型,总结并压缩最关键的细节。模型保留架构决策、未解决的 bug 和实现细节,同时丢弃冗余工具输出或消息。智能体随后在压缩后的上下文加上最近访问的五个文件继续工作,用户无需担心上下文窗口限制而保持连续性。
压缩的关键在于选择保留和舍弃的内容。
过度压缩可能导致丢失微妙但关键的上下文,其重要性可能在后续才显现。工程师在实现压缩系统时,应在复杂智能体轨迹上仔细调优提示。
首先保证最大化召回,确保压缩提示捕获轨迹中每条相关信息,然后迭代提高精确度,去掉冗余内容。
6.2 结构化笔记
结构化笔记,或称智能体记忆,是指智能体定期写笔记,并存储在上下文窗口之外的记忆中。这些笔记可在之后重新调入上下文。
这一策略提供了低开销的持久记忆。
例如 Claude Code 创建待办事项列表,或自定义智能体维护 NOTES.md 文件,这种模式允许智能体在复杂任务中跟踪进度,保持关键上下文和依赖关系,否则在多次工具调用后会丢失。
6.3 子智能体架构
与其让一个智能体维护整个项目状态,不如让专门的子智能体处理聚焦任务,保持干净的上下文窗口。
主智能体负责高层协调,子智能体执行深入技术工作或使用工具检索相关信息。每个子智能体可能处理数万 token 的探索,但只返回其工作的精炼总结(通常 1,000–2,000 token)。
这种方式实现了明确的职责分离,详细搜索上下文保留在子智能体内部,而主智能体专注于综合分析结果。
不同方法的选择取决于任务特性:
- 压缩适合需要频繁交互的任务;
- 笔记适合迭代开发、有明确里程碑的任务;
- 多智能体架构适合复杂研究与分析,需要并行探索以获得收益。
即便模型持续改进,长时间交互中保持连贯性的挑战仍将是构建高效智能体的核心问题。
结论
上下文工程代表了构建 LLM 应用方式的根本转变。
随着模型能力提升,挑战不仅是编写完美提示词,而是谨慎管理每一步进入模型有限注意力预算的信息。
指导原则始终是:找到最少的高信息量 token 集,以最大化实现预期结果的可能性。
技术会随着模型进步持续演化,我们已经看到,更智能的模型需要的指导更少,使智能体能够更自主地运行。但即便能力提升,将上下文视为珍贵且有限的资源,依然是构建可靠、高效智能体的核心。
最近这几年,经济形式下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。大家想学习和了解大模型的,可以**点击这里前往查看**

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)