40、Dify学习(一)--基础入门
在AI应用开发领域,Dify作为一款开源的低代码Agent开发框架,正迅速成为开发者和企业的首选工具。它不仅简化了AI应用的开发流程,还提供了完整的应用生命周期管理功能,让开发者能够专注于业务逻辑而非技术细节。Dify的核心优势在于其模块化设计和可视化界面,通过"知识库"、"工具"和"工作室"三大核心功能模块,构建了从基础聊天机器人到复杂工作流的完整解决方案。
Dify:一站式AI智能体开发平台全面解析
Dify 是一个开源的 AI 应用开发平台,核心目标是解决 LLM 应用开发的复杂性问题。该平台于 2023 年初发布,已迅速成为 GitHub 上热门项目之一(截至 2025 年,支持超过 180,000 名开发者)。它支持 Python 和其他语言的集成,适用于构建聊天机器人、AI 代理、工作流和知识管理系统。
Dify 采用模块化、开源架构,构建于 Docker 和 Kubernetes 等容器化技术之上,支持云端和自托管部署,用户可以通过拖拽界面构建应用。其核心是一个可视化低代码平台,集成 LLM、RAG 和代理框架。
一、Dify:重新定义AI应用开发
在AI应用开发领域,Dify作为一款开源的低代码Agent开发框架,正迅速成为开发者和企业的首选工具。它不仅简化了AI应用的开发流程,还提供了完整的应用生命周期管理功能,让开发者能够专注于业务逻辑而非技术细节。
Dify的核心优势在于其模块化设计和可视化界面,通过"知识库"、"工具"和"工作室"三大核心功能模块,构建了从基础聊天机器人到复杂工作流的完整解决方案。
二、Dify与主流竞品对比
1. 全面竞品对比
低代码开发工具借助可视化的界面和模块化的配置,开发者几乎无需编写代码即可完成智能体的搭建与部署,这就是所谓的低代码开发工具。目前较为主流的低代码 Agent 开发工具包括 Dify、Coze、n8n 和 LangFlow等。
| 功能/平台 | Dify | Coze | LangChain | Flowise | n8n | Zapier |
|---|---|---|---|---|---|---|
| 核心定位 | 一站式低代码AI应用开发平台 | 社交内容分发为主的AI Bot平台 | 代码框架 | 可视化LangChain工作流 | 通用工作流自动化 | 无代码自动化工具 |
| 部署方式 | 云服务+开源自托管 | 仅云服务 | 代码库 | 开源自托管 | 云服务+自托管 | 仅云服务 |
| 开源模式 | 开源核心+商业高级功能 | 闭源 | 完全开源 | 完全开源 | 部分开源 | 闭源 |
| 聊天助手 | ⭐⭐⭐⭐⭐ (完善) | ⭐⭐⭐⭐⭐ (核心) | ⭐⭐⭐⭐☆ (需代码) | ⭐⭐⭐⭐☆ (可视化) | ⭐⭐☆☆☆ (有限) | ⭐⭐☆☆☆ (基础) |
| 文本生成 | ⭐⭐⭐⭐⭐ (专业) | ⭐⭐⭐⭐☆ | ⭐⭐⭐⭐⭐ (灵活) | ⭐⭐⭐⭐☆ | ⭐⭐☆☆☆ | ⭐⭐☆☆☆ |
| Agent能力 | ⭐⭐⭐⭐⭐ (完善工具链) | ⭐⭐⭐⭐☆ | ⭐⭐⭐⭐⭐ (最灵活) | ⭐⭐⭐⭐☆ | ⭐⭐⭐☆☆ | ⭐⭐☆☆☆ |
| 工作流 | ⭐⭐⭐⭐⭐ (可视化) | ⭐⭐⭐☆☆ | ⭐⭐⭐⭐☆ (代码实现) | ⭐⭐⭐⭐⭐ (核心功能) | ⭐⭐⭐⭐⭐ (核心功能) | ⭐⭐⭐⭐⭐ (核心功能) |
| Chatflow | ⭐⭐⭐⭐⭐ (独特优势) | ⭐⭐⭐⭐☆ (Bot流程) | ⭐⭐⭐☆☆ (需自建) | ⭐⭐⭐☆☆ | ⭐⭐☆☆☆ | ❌ |
| 知识库 | ⭐⭐⭐⭐⭐ (RAG优化) | ⭐⭐⭐⭐☆ | ⭐⭐⭐⭐☆ (需配置) | ⭐⭐⭐⭐☆ | ⭐⭐☆☆☆ | ⭐⭐☆☆☆ |
| 多模态支持 | ⭐⭐⭐⭐☆ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐☆ | ⭐⭐⭐☆☆ | ⭐⭐☆☆☆ | ⭐⭐☆☆☆ |
| 学习曲线 | 中等 | 低 | 非常陡峭 | 中等 | 中等 | 低 |
| 企业级功能 | ⭐⭐⭐⭐☆ | ⭐⭐⭐☆☆ | ⭐⭐⭐☆☆ (需自建) | ⭐⭐⭐☆☆ | ⭐⭐⭐⭐☆ | ⭐⭐⭐⭐⭐ |
| 价格模型 | 免费云版+企业付费 | 免费+高级功能付费 | 免费 | 免费+企业支持 | 免费+云服务付费 | 订阅制 |
| 最佳适用 | 企业AI应用开发 | 社交媒体Bot | 开发者自定义AI应用 | 可视化AI流程 | 业务流程自动化 | SaaS工具集成 |
2. 竞品核心差异分析
Dify的独特优势:
- 全面性:唯一同时完美支持五种应用类型(聊天助手、Agent、文本生成、工作流、Chatflow)的平台
- 平衡性:在低代码与功能深度之间取得最佳平衡
- 知识库RAG优化:提供最先进的检索增强生成能力,包括混合检索(语义+关键词)与重排序
- 开源策略:核心功能开源,企业可自由定制,无厂商锁定风险
- 日志与标注系统:提供完整的应用运营与持续优化工具
Coze的优势与局限:
- 优势:字节生态整合,社交分发能力强,适合内容创作者
- 局限:闭源,企业级功能有限,不适合复杂业务系统集成
LangChain的定位:
- 优势:最灵活、功能最全面的代码框架,适合专业开发者
- 局限:陡峭的学习曲线,需要较强的编程能力,无内置UI
n8n/Flowise的侧重:
- 优势:在特定领域(工作流自动化/可视化AI流程)有深度优化
- 局限:AI能力作为辅助功能,不如Dify专业
3. 总结
Dify 是由开源社区主导开发的一款低代码 大模型应用与 Agent 开发框架,旨在帮助用户以更少的代码和更直观的方式构建、部署和管理基于大语言模型(LLM, Large Language Model)的智能应用。对于没有深厚编程经验的用户而言,Dify 提供了图形化的操作界面以及灵活的工作流设计工具,使其能够快速完成从模型调用、知识库管理到工具接入的全流程开发。
在整体定位上,Dify 既可以看作是一个 大模型应用开发平台,也可以看作是一个 低代码的 Agent 编排框架。它的核心价值体现在以下几个方面:
- 低门槛:通过可视化界面与简单配置,用户可以快速构建对话式应用或智能体,而无需编写大量复杂代码。
- 可扩展:支持主流的大语言模型(如 OpenAI、Anthropic、DeepSeek 等),同时允许用户自定义工具与外部 API,满足不同业务场景的扩展需求。
- 知识库增强:内置文档上传与知识检索功能,支持通过检索增强生成(RAG)提升模型回答的准确性与专业性。
- 企业级应用场景:Dify 不仅适合个人开发者实验,还面向企业级部署,提供多用户管理、权限控制以及可观测性工具,帮助团队更好地在生产环境中落地大模型应用。
总体而言,Dify 项目的目标是降低大模型技术的使用门槛,让更多开发者和组织能够专注于业务逻辑和应用场景本身,而不是被底层的模型调用与工程实现所困扰。这使得 Dify 成为当前低代码 Agent 开发领域中颇具代表性和实用性的开源框架之一。
三、Dify核心功能模块详解
1. 知识库:智能体的"记忆"与"知识"
Dify的知识库功能是构建专业AI应用的基础。它允许用户上传和管理结构化知识,如PDF文档、Word文档、Excel表格等,并自动进行解析和向量化存储。
核心特点:
- 混合检索机制:结合语义检索与关键词检索,通过重排序模型(Rerank Model)优化结果
- 高级参数配置:可设置Top K(召回条目数)、Score阈值(最低相似度分数)等参数
- 文档切片策略:智能分段,保留上下文信息
- 引用与归因:自动追踪回答来源,提供文档名和页码/段落标识
使用场景:
- 企业知识库问答系统
- 课程资料智能助教
- 产品手册智能客服
示例:上传《人工智能导论》课程PDF后,用户提问"神经网络的结构是怎样的?",Dify会从知识库中检索相关内容,确保回答基于课程资料,而非凭空编造。
2. 工具:智能体的"手脚"与"能力"
Dify的"工具"功能为智能体提供了扩展能力,使其能够调用外部API、执行计算或访问特定服务。
核心特点:
- 预置常用工具(如天气查询、翻译API等)
- 自定义API工具配置,支持OpenAPI规范
- 工具调用参数设置与验证
- 工具执行结果处理与格式化
- 安全控制:API密钥管理与访问控制
使用场景:
- 天气查询智能助手
- 多语言翻译聊天机器人
- 电商平台价格比对助手
3. 工作室:智能体的"大脑"与"引擎"
Dify的"工作室"是其最强大的功能模块,包含以下子功能:
(1)聊天助手(Chatbot)—— 入门级对话应用
核心特点:无需复杂配置,通过提示词 + 知识库组合,快速搭建对话式助手
关键功能:支持多轮对话记忆、开场白自定义、预置问题引导、多模态交互(文本 + 图片)
适用场景:客服问答机器人、课程助教、个人知识助手、FAQ 解答工具
(2)Agent(智能体)—— 具备工具调用能力的 “执行者”
核心特点:在聊天助手基础上,新增工具调用权限,模型可自主决策是否调用外部工具完成任务
关键功能:工具选择自动化、任务拆解、多步骤执行、结果整合反馈
适用场景:智能办公助手(日程安排、邮件发送)、信息检索与整理、自动化任务处理(如数据查询 + 报表生成)
(3)文本生成助手(Text Generator)—— 结构化内容创作工具
核心特点:专注内容生成场景,支持自定义输入 / 输出格式,结果可控性强
关键功能:提示词模板配置、变量替换、输出格式标准化(如 Markdown、表格、代码块)
适用场景:广告文案撰写、文章生成、代码片段编写、翻译工具、简历优化
(4)工作流(Workflow)—— 多步骤任务自动化编排
核心特点:可视化画布拖拽编排,支持多节点组合,实现复杂业务逻辑自动化
关键功能:节点类型丰富(模型调用、API 请求、逻辑判断、循环、变量赋值等)、流程分支控制、结果串联
适用场景:业务流程自动化(如审批流)、跨系统数据处理、报告生成(数据检索→分析→可视化输出)、批量任务执行
(5)Chatflow—— 对话与流程融合的 “进阶智能体”
核心特点:结合聊天助手的自然交互与工作流的复杂编排,支持通过对话触发自动化流程
关键功能:对话意图识别、流程分支触发、多轮对话与流程联动、结果实时反馈
适用场景:智能客服中心(咨询→问题分类→工单创建→反馈)、企业内部知识管理、跨系统综合智能体(如电商售后:咨询→订单查询→退款申请)
(6)Dify五种核心应用类型对比
| 功能维度 | 聊天助手 (Chatbot) | Agent (智能体) | 文本生成 (Text Generator) | 工作流 (Workflow) | Chatflow |
|---|---|---|---|---|---|
| 核心定位 | 基础对话型应用 | 具备工具调用能力的智能体 | 专业内容生成工具 | 多步骤任务编排引擎 | 对话+流程的融合体验 |
| 核心特点 | • 上手简单 • 依赖提示词和知识库 • 单轮/多轮对话支持 |
• 能调用外部工具 • 具备自主决策能力 • 可执行具体任务 |
• 专注内容生成 • 结果高度可控 • 输入/输出格式可定制 |
• 多步骤任务串联 • 逻辑清晰可编排 • 可视化流程设计 |
• 融合自然对话与工作流 • 对话可触发复杂流程 • 交互性与自动化兼具 |
| 复杂度 | ⭐☆☆☆☆ (入门级) | ⭐⭐⭐☆☆ (中等) | ⭐⭐☆☆☆ (初级-中级) | ⭐⭐⭐⭐☆ (高级) | ⭐⭐⭐⭐⭐ (最复杂) |
| 开发方式 | 配置提示词与知识库 | 配置工具+提示词 | 配置输入/输出模板+提示词 | 可视化工作流画布编排 | 对话设计+工作流触发器配置 |
| 典型应用场景 | • FAQ问答机器人 • 课程助教 • 企业内部知识助手 |
• 智能办公助理 • 信息检索与执行 • 数据查询与分析 |
• 文章写作 • 代码生成 • 文案优化与创作 |
• 业务流程自动化 • 企业审批流程 • 跨部门数据处理 |
• 智能客服中心 • 企业内部知识管理 • 跨系统综合智能体 |
| 数据流向 | 用户输入→LLM处理→直接输出 | 用户输入→LLM决策→调用工具→处理结果→输出 | 用户输入→按模板生成→结构化输出 | 多节点数据传递: 输入→节点1→节点2→…→最终输出 | 对话输入→触发条件判断→执行工作流→返回结果→继续对话 |
| 是否需要编程 | 几乎不需要 | 基础配置不需要,高级场景可能需要API知识 | 不需要 | 不需要,但需理解流程逻辑 | 不需要,但需理解对话与流程的衔接 |
| 知识库集成 | 主要依赖知识库 | 可结合知识库与工具 | 通常不依赖知识库 | 可在流程中加入知识库检索节点 | 支持知识库与工作流的结合 |
| 扩展性 | 低到中等 | 中等 | 低 | 高 | 最高 |
| 最佳实践示例 | "请问退换货政策是什么?"→基于知识库回答退换货规则 | "帮我查询北京天气"→调用天气API→返回天气信息 | "生成一篇关于AI的博客文章"→按指定格式输出完整文章 | “客户投诉处理”: 接收投诉→分类→分派→跟踪→反馈→归档 | "我想请假"→触发请假流程→收集信息→提交审批→通知结果→继续对话 |
四、简单Demo:构建一个智能助教应用
让我们通过一个简单示例,快速体验Dify的核心功能:
前置工作
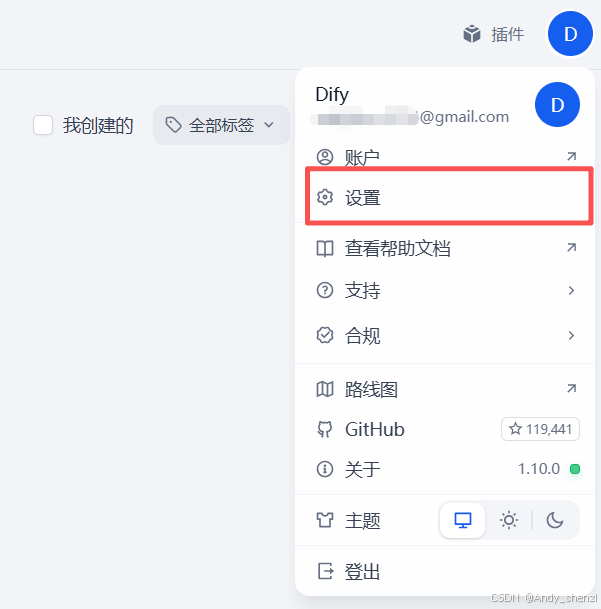
- 配置模型:
- 在账户 --》设置中选择模型供应商,选择相应的供应商,可以选择Openai,也可以是硅基流动这种代理商;需要配置相应的推理响应模型、词向量模型和Rerank模型等。
-
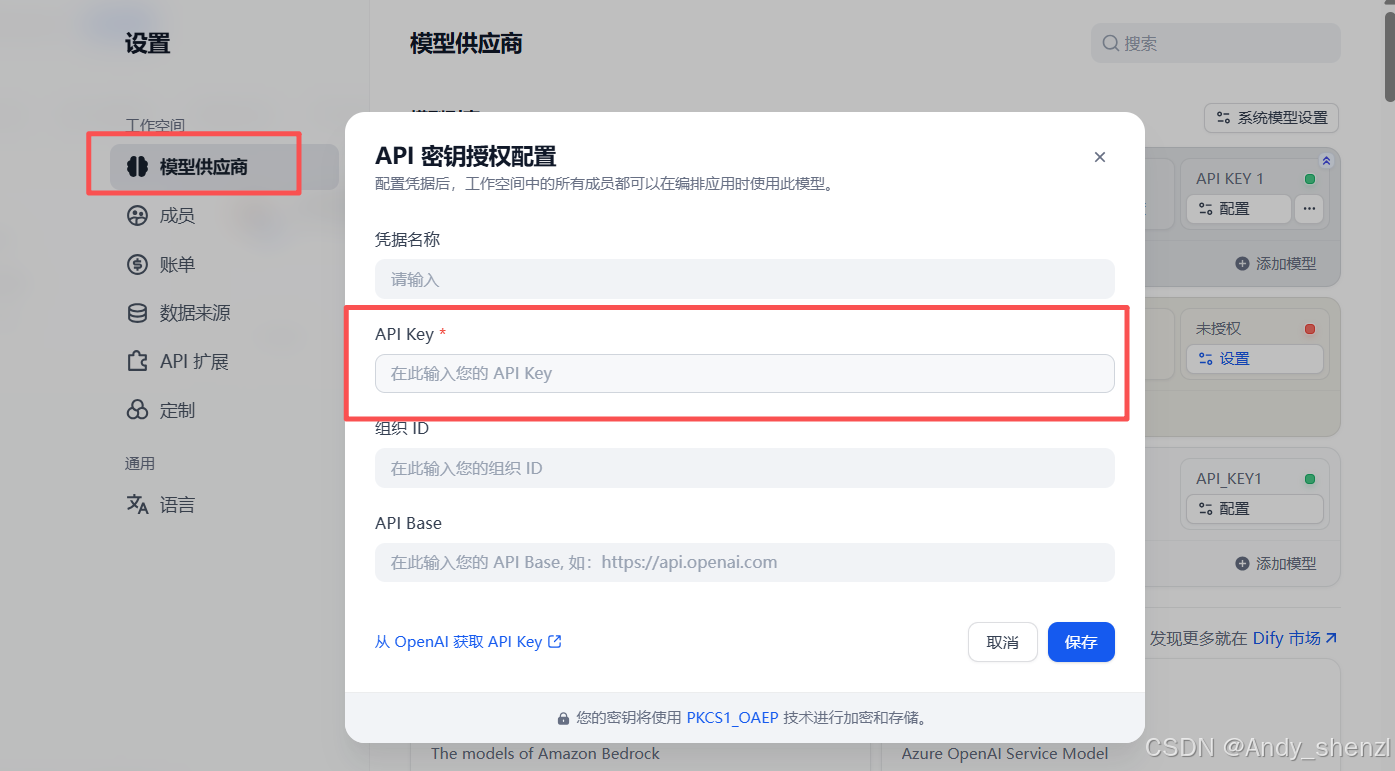
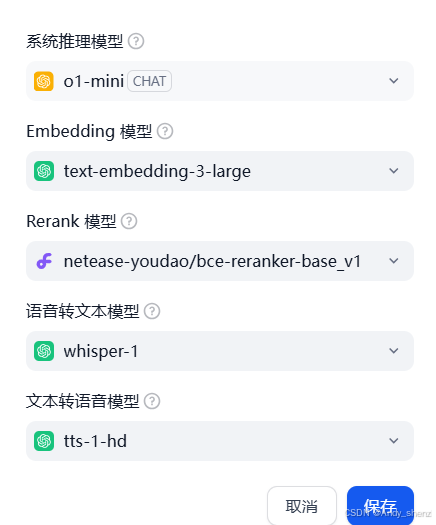
- 在账户 --》设置中选择模型供应商,选择相应的供应商,可以选择Openai,也可以是硅基流动这种代理商;需要配置相应的推理响应模型、词向量模型和Rerank模型等。
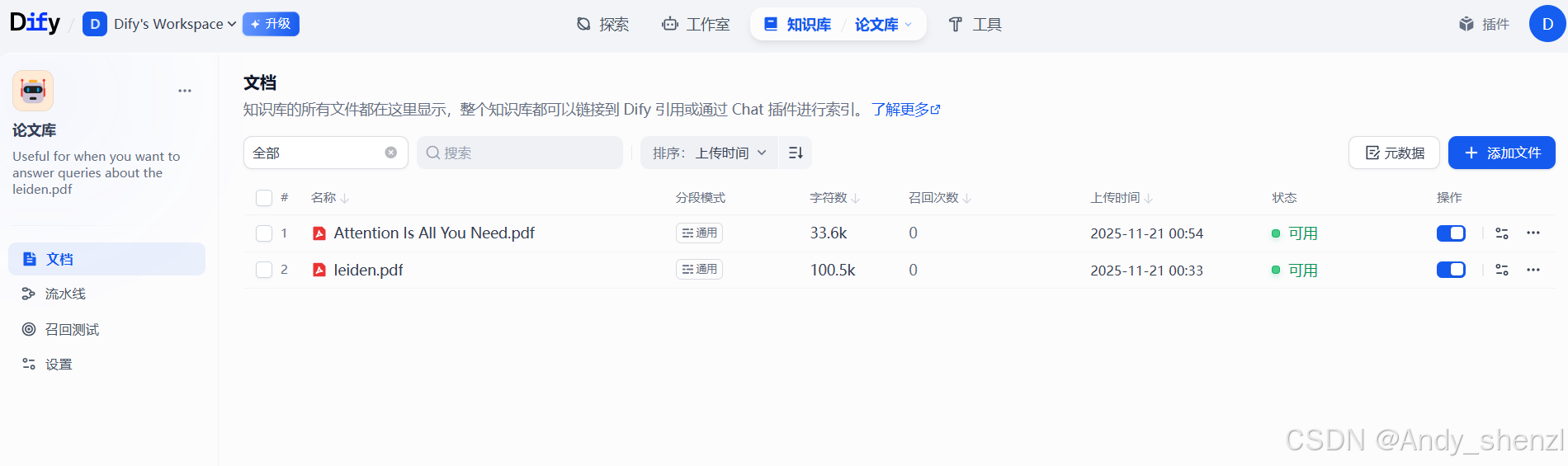
- 创建知识库
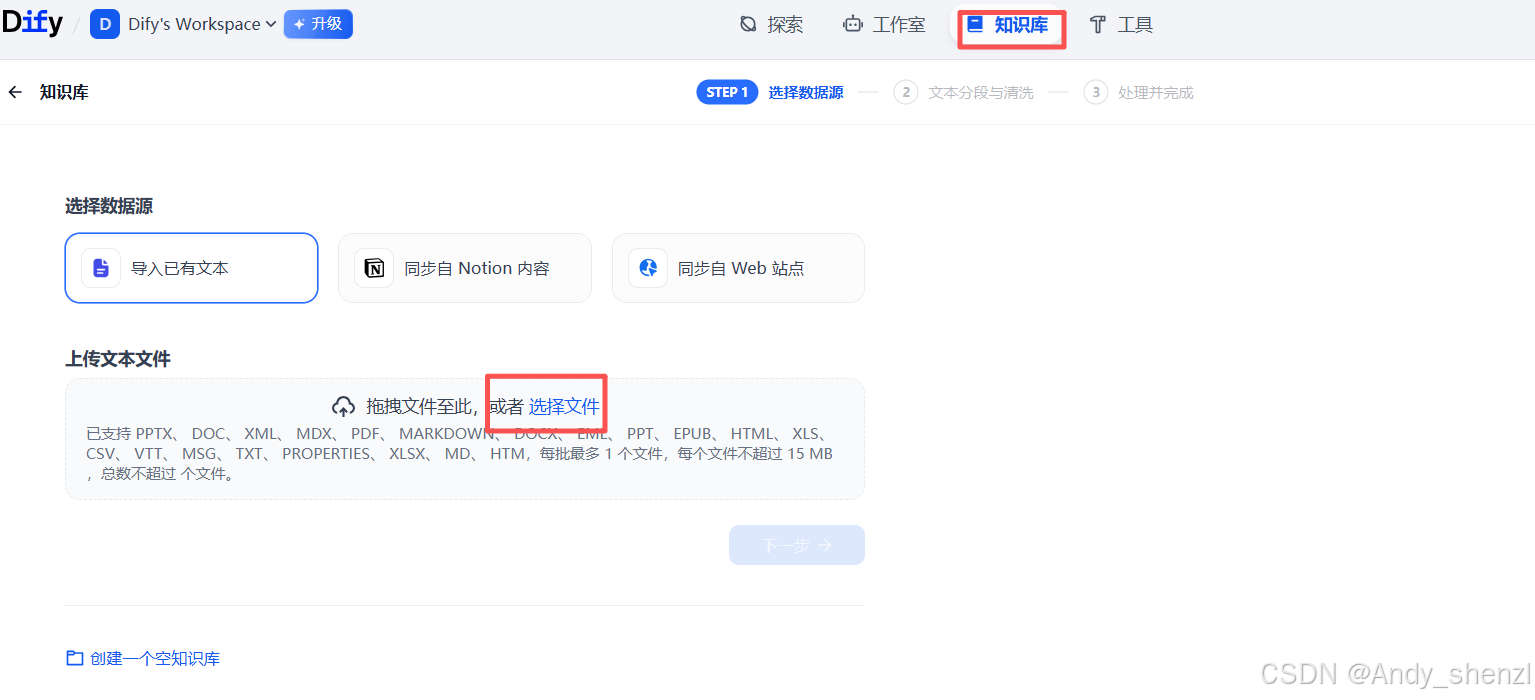
上传文档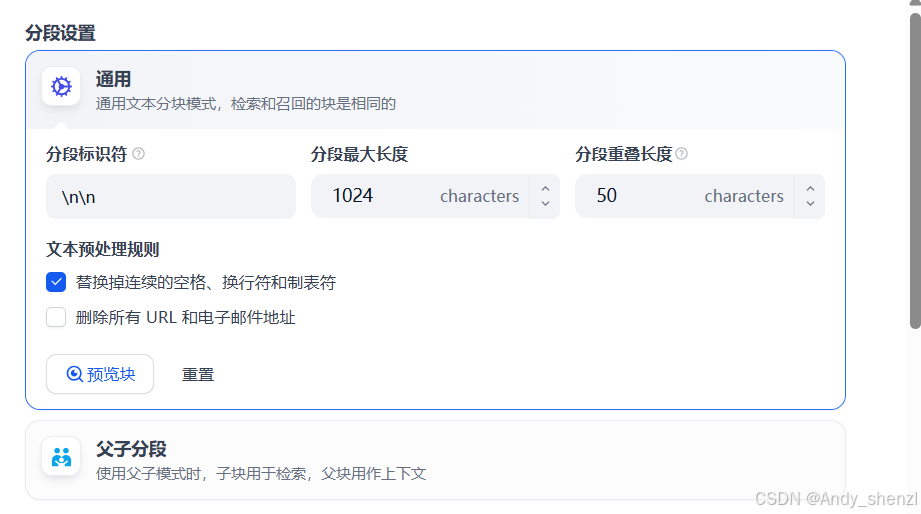
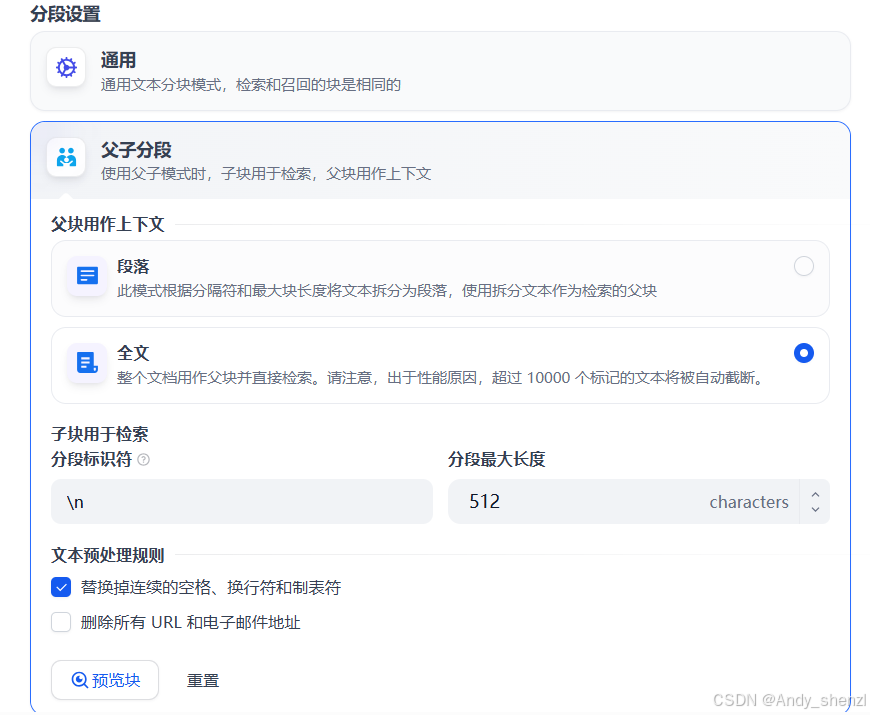
dify设置了两种分段方式,
- 通用模式:系统按照用户自定义的规则将内容拆分为独立的分段。当用户输入问题后,系统自动分析问题中的关键词,并计算关键词与知识库中各内容分段的相关度。根据相关度排序,选取最相关的内容分段并发送给 LLM,辅助其处理与更有效地回答。
- 父子模式:与通用模式相比,父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。其中,父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息;子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索。系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。你可以通过设置分隔符和最大长度来自定义父子区块的分段方式。
- 例如在 AI 智能客服场景下,用户输入的问题将定位至解决方案文档内某个具体的句子,随后将该句子所在的段落或章节,联同发送至 LLM,补全该问题的完整背景信息,给出更加精准的回答。
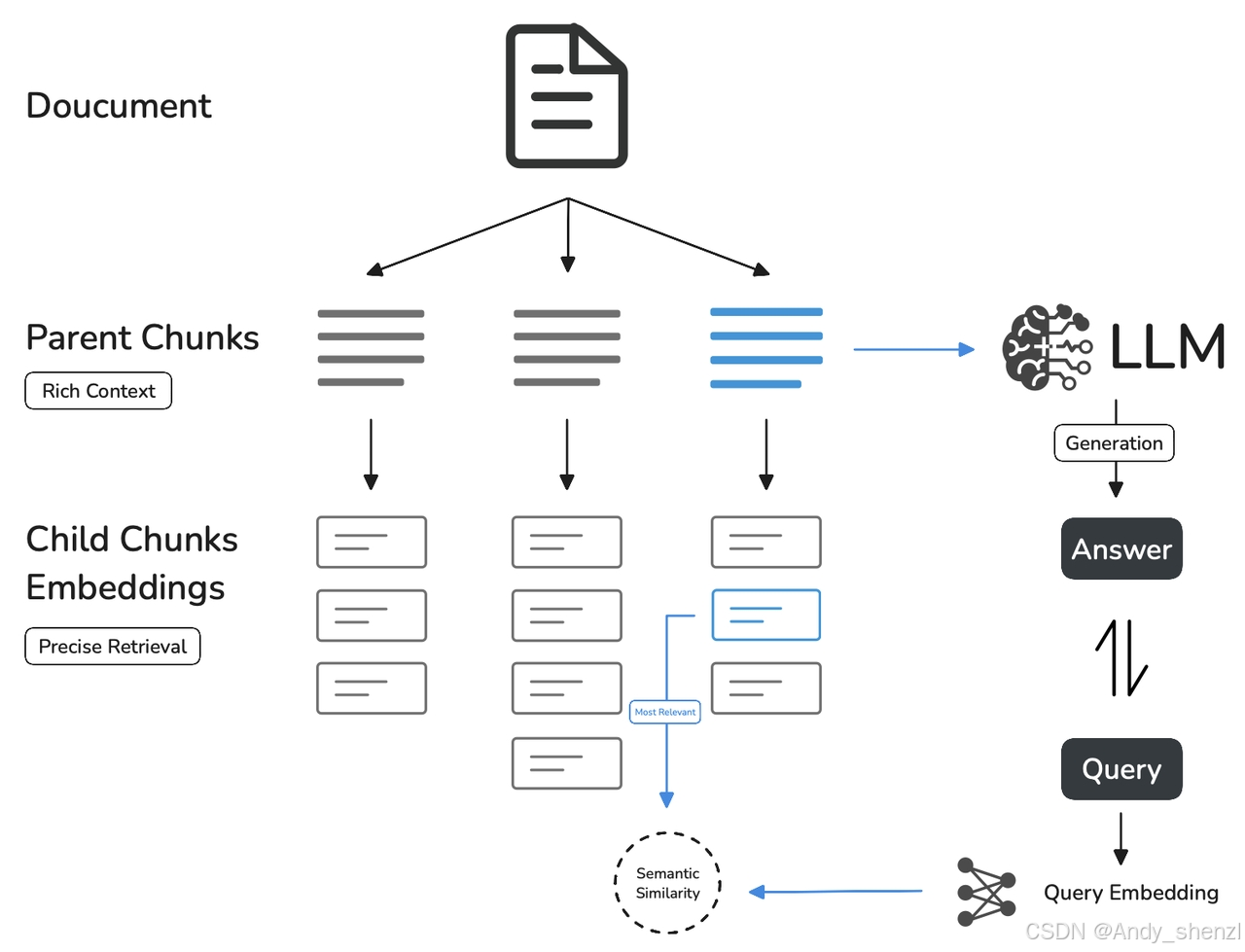
- 例如在 AI 智能客服场景下,用户输入的问题将定位至解决方案文档内某个具体的句子,随后将该句子所在的段落或章节,联同发送至 LLM,补全该问题的完整背景信息,给出更加精准的回答。
- 设置检索方式
- 索引方式
- 在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。对于检索到的区块,仅提供倒排索引方式选择最相关的区块
- 在高质量模式下,使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息;使得用户问题与文本之间的匹配能够更加精准。将内容块向量化并录入至数据库后,需要通过有效的检索方式调取与用户问题相匹配的内容块。高质量模式提供向量检索、全文检索和混合检索三种检索设置。
- embedding模型:根据模型设置进行选择
- 检索方式:在高质量索引方式下,Dify 提供向量检索、全文检索与混合检索设置:
向量检索:向量化用户输入的问题并生成查询文本的数学向量,比较查询向量与知识库内对应的文本向量间的距离,寻找相邻的分段内容。向量检索设置:
Rerank 模型: 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由向量检索召回的内容分段,以优化排序结果。帮助 LLM 获取更加精确的内容,辅助其提升输出的质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
TopK: 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
Score 阈值: 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。全文检索: 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。混合检索: 同时执行全文检索和向量检索,或 Rerank 模型,从查询结果中选择匹配用户问题的最佳结果。允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。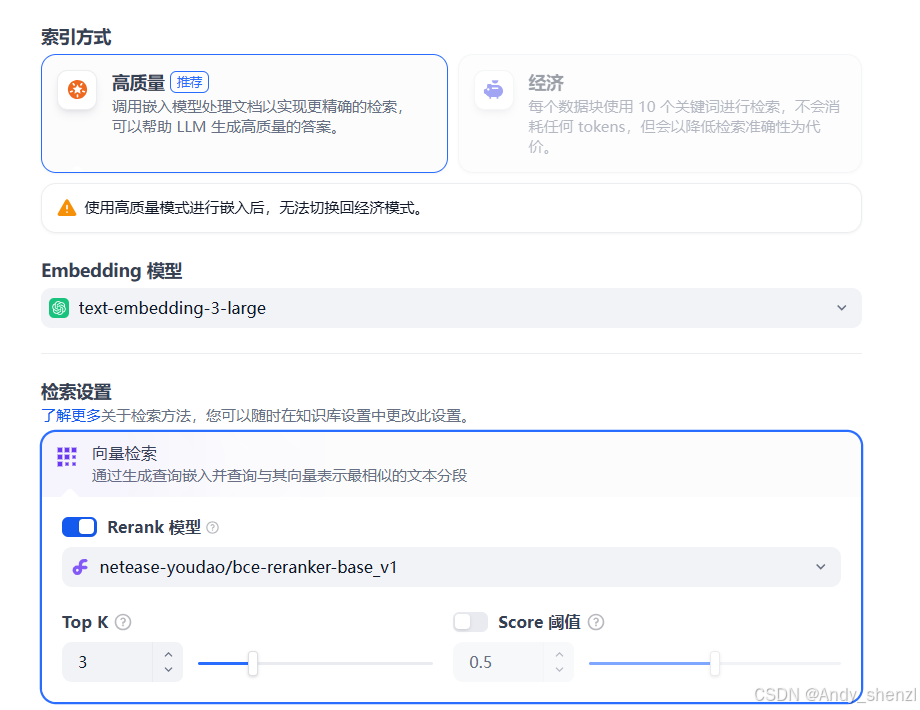
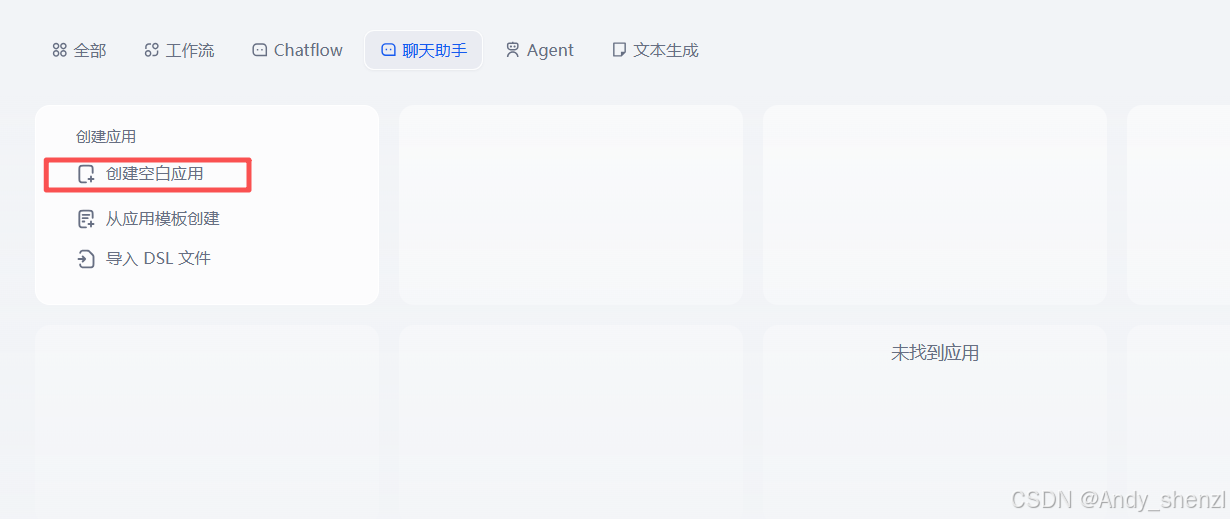
步骤1:创建应用
- 登录Dify云服务(https://cloud.dify.ai/)
- 点击"新建应用",选择"聊天助手"类型
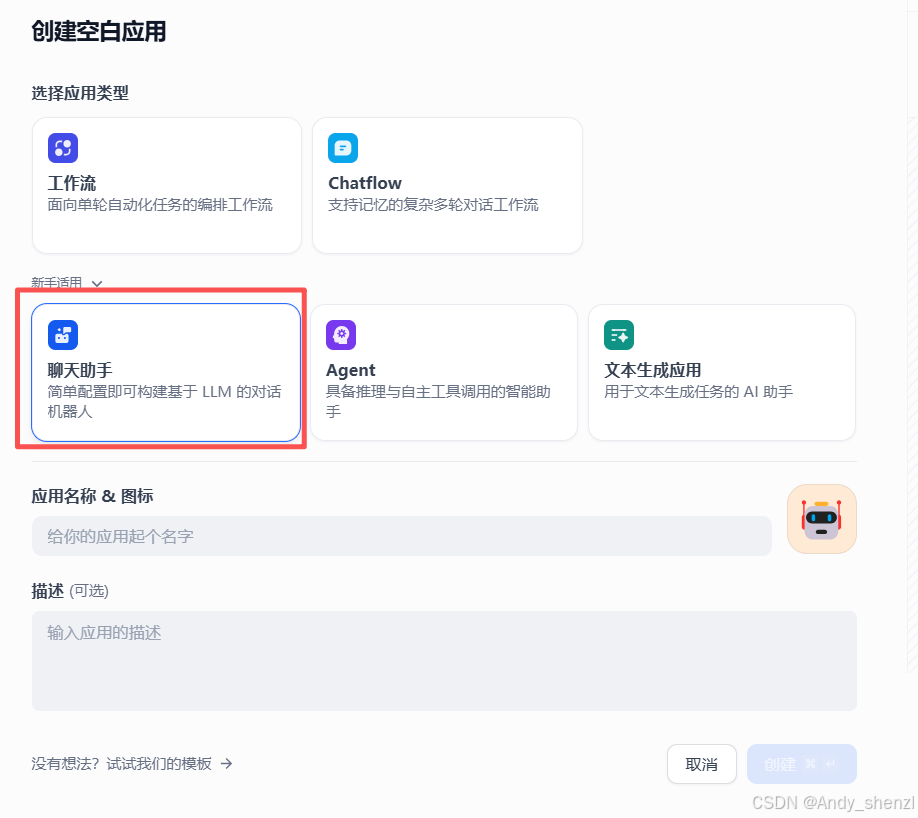
- 应用名称设为"论文解读助手"
步骤2:配置提示词
在"系统提示词"区域设置:
你是一位专业的学术研究助手,专注于帮助用户理解和分析学术论文。你的任务是基于用户上传的论文《{{paper_title}}》提供准确、专业的解读。
回答要求:
1)必须严格基于论文内容作答,不得虚构论文中不存在的信息
2)对于论文中的专业术语,首次出现时需提供简明解释
3)回答需结构清晰,先概括核心观点,再展开详细分析
4)对于复杂概念,使用类比或实例帮助理解
5)如问题涉及论文外的知识,明确区分"论文中提到"和"额外背景知识"
6)在回答末尾提供【引用】,标明所引用的章节、图表或页码
7)如果问题不明确,先请求澄清具体关注点
步骤3:设置变量
在"变量"区域添加paper_title变量,设置为必填项。
步骤4:连接知识库
- 点击"知识库"选项,选择创建的知识库
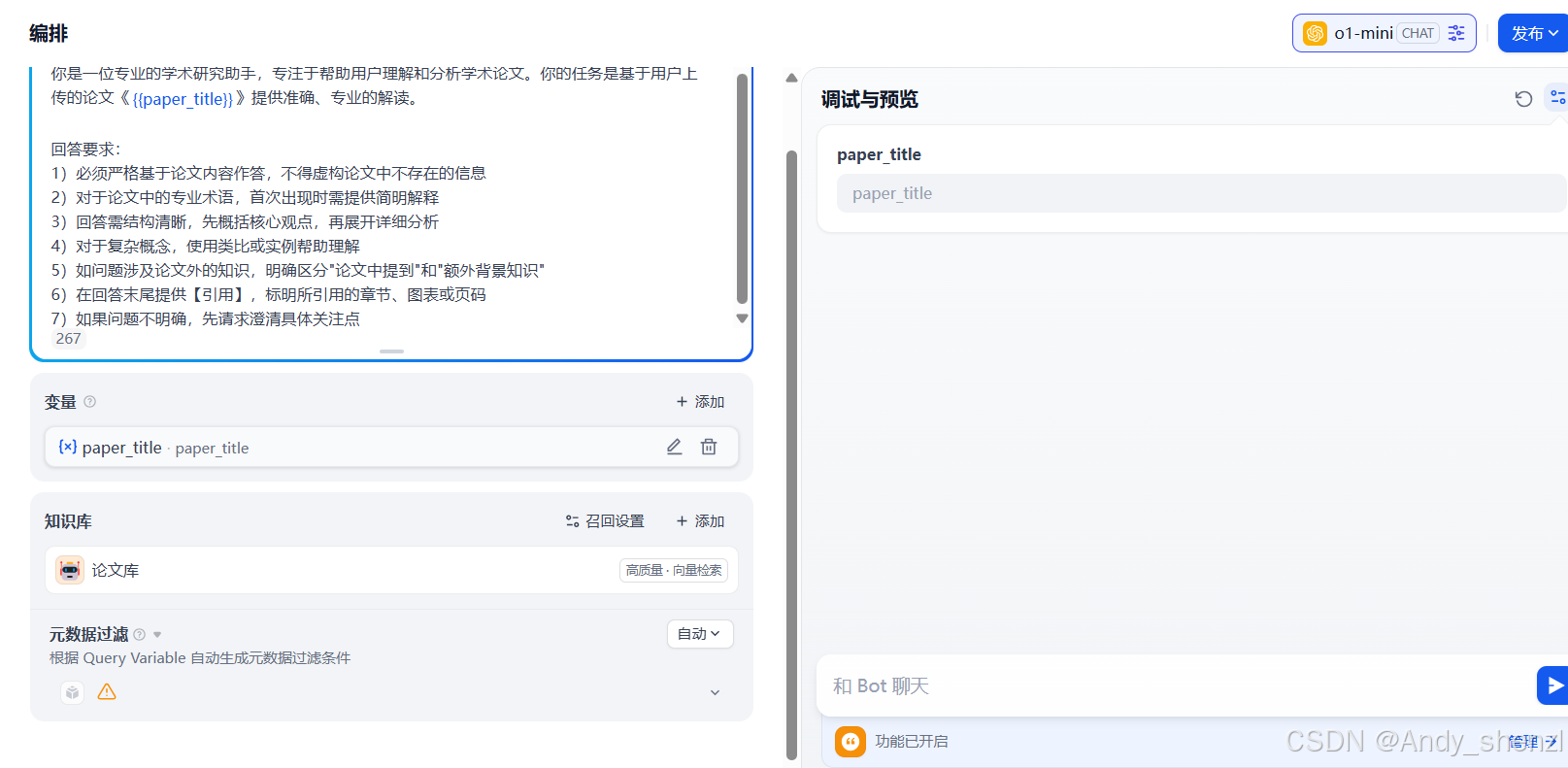
步骤5:测试应用
- 在测试界面输入问题:“解释下位置编码?”
- 预期输出:
在《Attention is all you need》中,**位置编码(Positional Encoding)** 是Transformer模型的关键组成部分,用于为输入序列中的每个词提供位置信息。由于Transformer的自注意力机制本身不包含序列顺序信息,位置编码通过注入位置相关的向量,使模型能够理解词在序列中的相对或绝对位置。
### 核心原理
- **目的**:弥补自注意力机制对输入序列顺序的“无视”,确保模型能处理序列数据(如语言)中的位置依赖关系。
- **方法**:将位置编码向量与词嵌入向量相加,作为编码器的输入。论文使用**正弦和余弦函数**生成位置编码,公式如下:
\[
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
\]
\[
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
\]
其中:
- \(pos\):词在序列中的位置(从0开始)。
- \(i\):维度索引(从0到\(d_{\text{model}}/2-1\))。
- \(d_{\text{model}}\):词嵌入的维度(论文中为512)。
### 关键特性
1. **确定性函数**:无需学习参数,通过数学公式直接计算,节省模型容量。
2. **相对位置感知**:正弦函数的周期性使模型能轻松学习相对位置偏移(例如,位置\(pos+k\)的编码可由位置\(pos\)的编码线性表示)。
3. **泛化性**:支持处理比训练时更长的序列,因为函数可扩展到任意位置。
### 类比理解
想象给一列单词每个贴上一个“位置标签”,就像在书中给每行编号。这些标签通过正弦波形式的“波动”编码位置,使模型能区分“猫追老鼠”和“老鼠追猫”的顺序差异。
### 额外背景知识
- 论文对比了学习式位置编码(如通过训练得到),但发现正弦编码在翻译任务中效果相当且更具泛化性。
- 后续研究(如BERT)常使用可学习的位置编码,但本论文坚持使用正弦/余弦函数。
【引用】论文第3.5节“Positional Encoding”,及第5页公式。
步骤6:发布
-
点击发布:
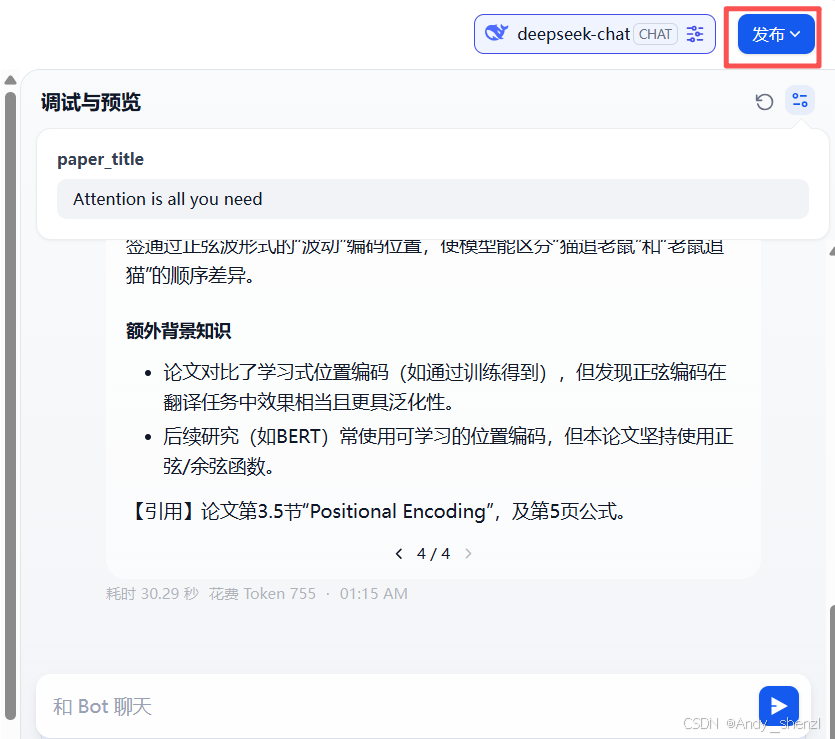
-
工作区开启新页面进行交互
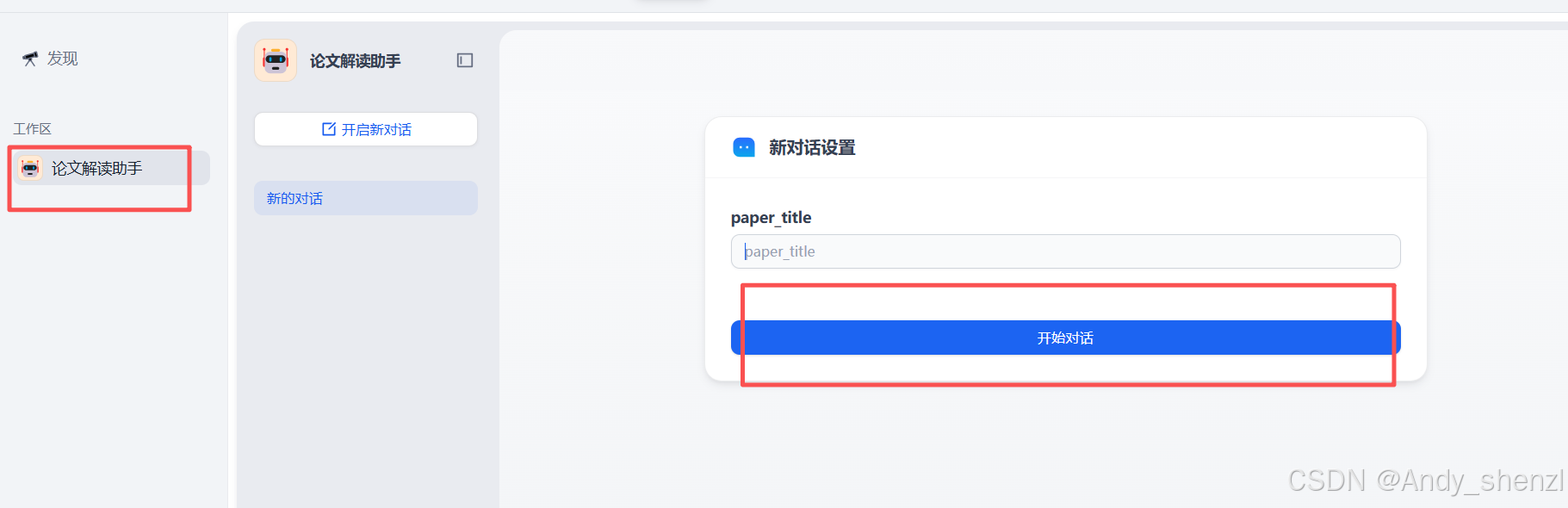
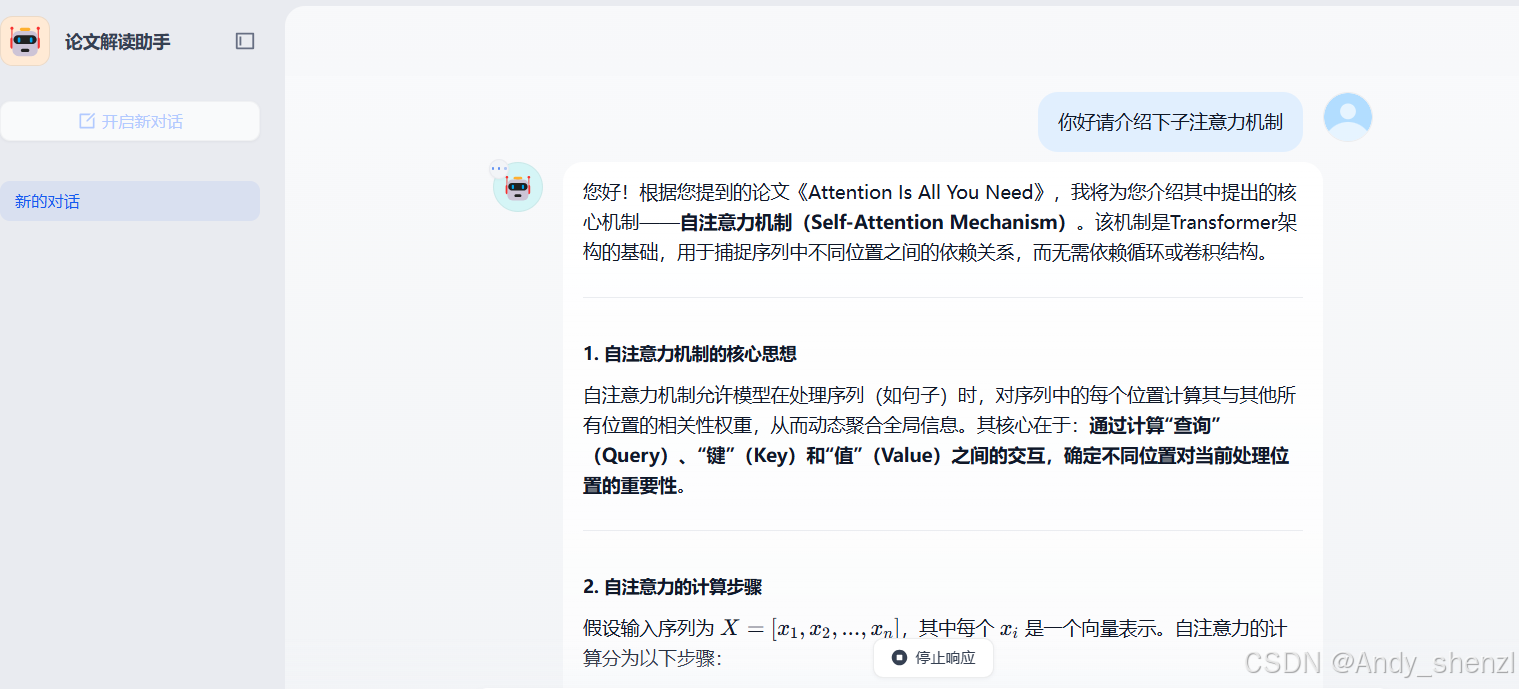
-
API
-
查看应用日志,检查用户交互
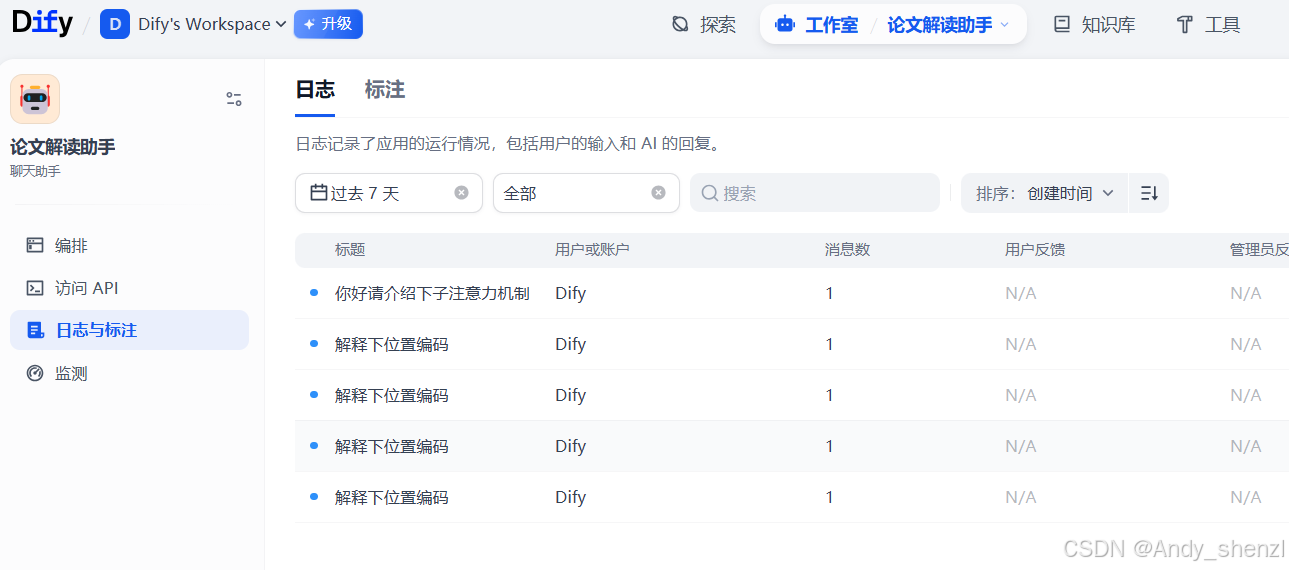
-
可对该对话进行标注,标记更优回答
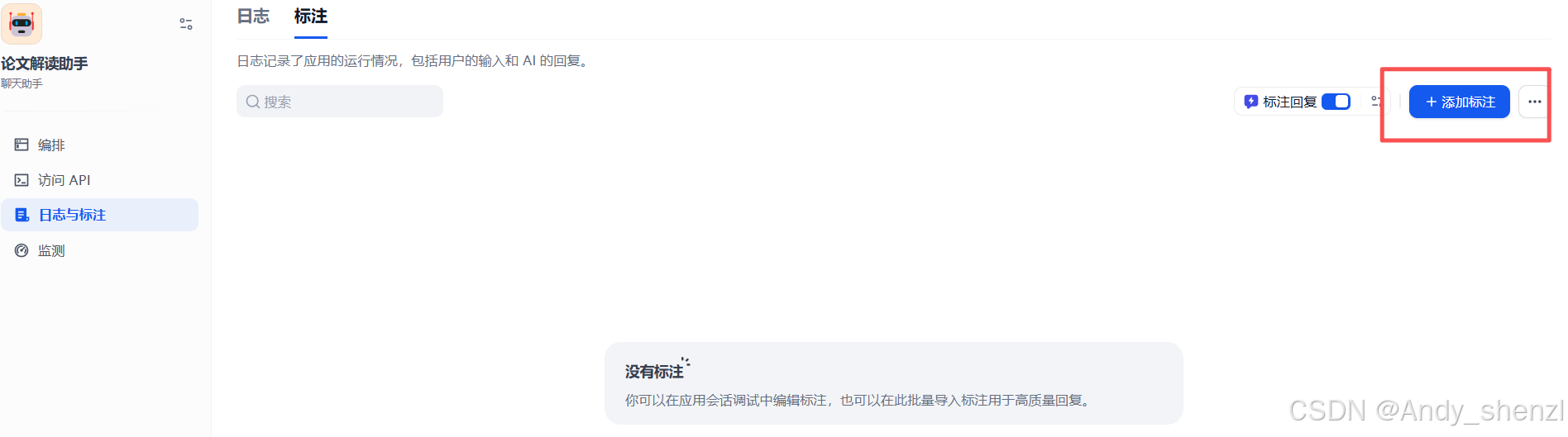
-
监测
五、为什么选择Dify?
- 全面覆盖:唯一同时完美支持聊天助手、Agent、文本生成、工作流、Chatflow五种应用类型的低代码平台
- 开源优先:核心功能开源,无厂商锁定,企业可自由定制
- 渐进式学习:从简单聊天助手到复杂Chatflow,学习曲线平缓
- 企业级能力:提供完整的日志、标注、运营分析功能
- RAG优化:最先进的知识库检索与增强生成技术
- 灵活部署:支持云服务和自托管,满足不同安全需求

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)