Agent 开发者重大利好!Dify 知识库 RAG 升级 Knowledge pipeline
Dify知识库迎来重大升级,推出Knowledge Pipeline功能,为企业AI应用提供可视化、可编排的RAG数据处理基础设施。该升级解决了非结构化文件处理、数据处理黑盒问题,降低开发维护成本,并支持多种数据源接入。测试显示,新系统能有效解析图片PDF、表格等复杂文档信息,并支持多文档综合检索。用户可通过内置模板快速配置知识库流水线,选择适合的embedding和rerank模型,完成知识库部
Agent 开发者重大利好!Dify 知识库 RAG 升级 Knowledge pipeline
Dify 知识库9 月份迎来了一个非常重大的升级,Knowledge Pipeline !
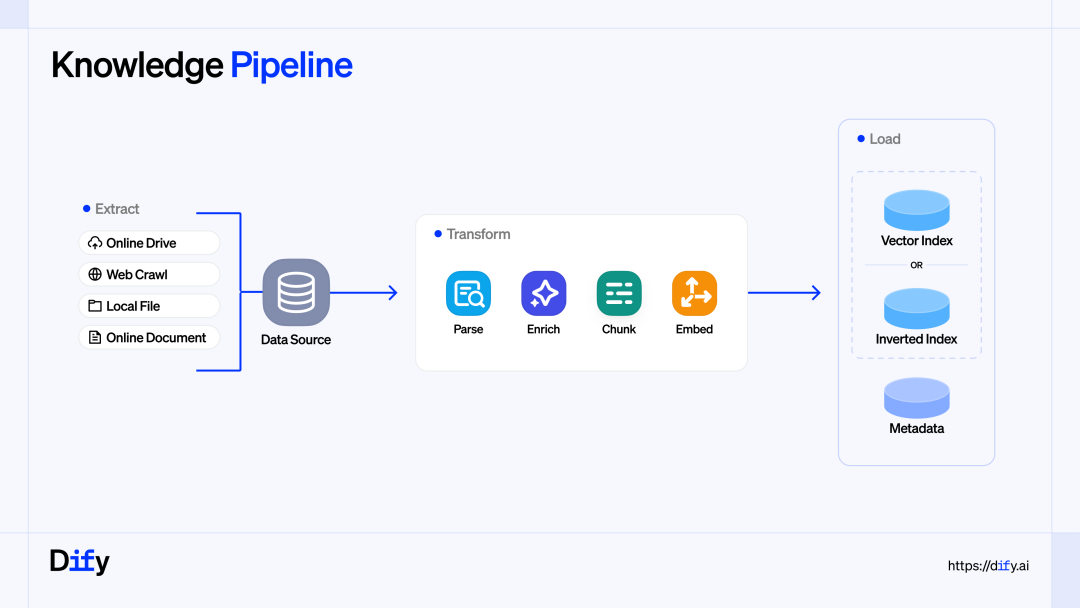
这次升级,给用户提供了一套可视化、可编排的 RAG 数据处理基础设施,从而系统性地解决了企业级 AI 应用落地的上下文工程(Context Engineering) 瓶颈。
其主要升级价值点有以下这些:
1-零散非结构化文件知识处理能力
大量业务数据分散在非结构化文件中,传统方法难以稳定地将这些分散、异构、持续更新的数据转化为 LLM 能可靠消费的上下文。Knowledge Pipeline 通过系统化设计与调优,成为实践 Context Engineering 的关键基础设施。
2-增强数据处理的掌控力,解决旧版 RAG黑盒问题
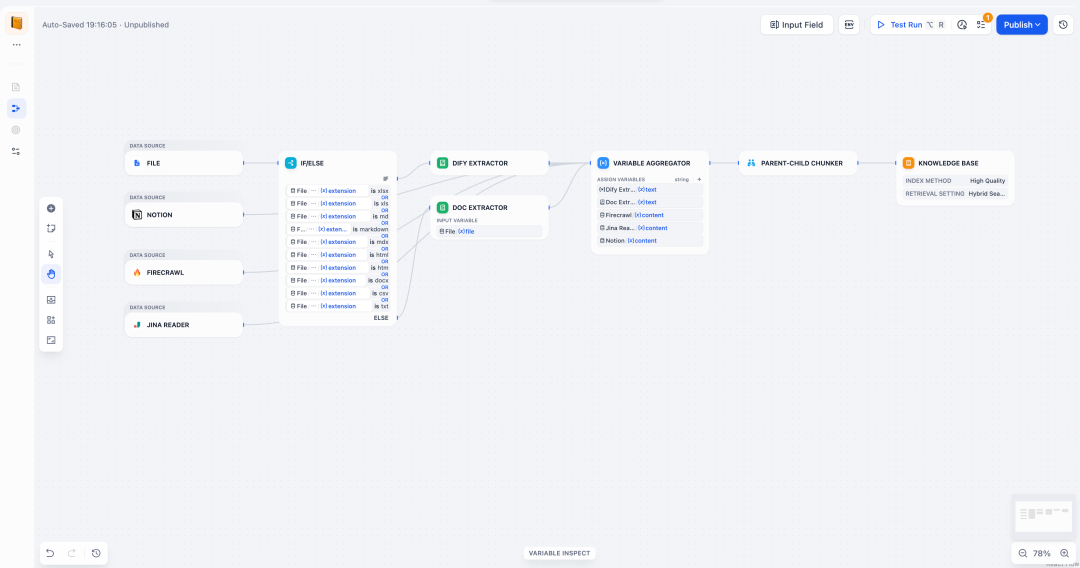
旧版 Dify 数据处理流程如同黑盒,问题难以定位。Knowledge Pipeline 提供了可观测的数据调试过程:
◦ 用户可以通过**测试运行(Test Run)功能对 Pipeline 逐节点执行,查看每一步的输入输出是否符合预期。
◦ 通过变量监视器(Variable Inspect)**实时观察中间变量和上下文,快速定位解析错误或分块异常等问题。
3-极大地降低开发与维护成本
• 价值: 将复杂的数据处理逻辑转化为可复用的资产,提高团队效率。
• 理由: 传统 RAG 项目多为一次性交付。Knowledge Pipeline 将数据处理做成可沉淀、可复用的能力,例如将合同审查或客服知识库的流程做成模板,供团队直接复制和调整,减少重复搭建和后期维护的工作量。
4-开放且灵活的集成能力
轻松接入各种数据源,并集成行业最优的 RAG 解决方案。
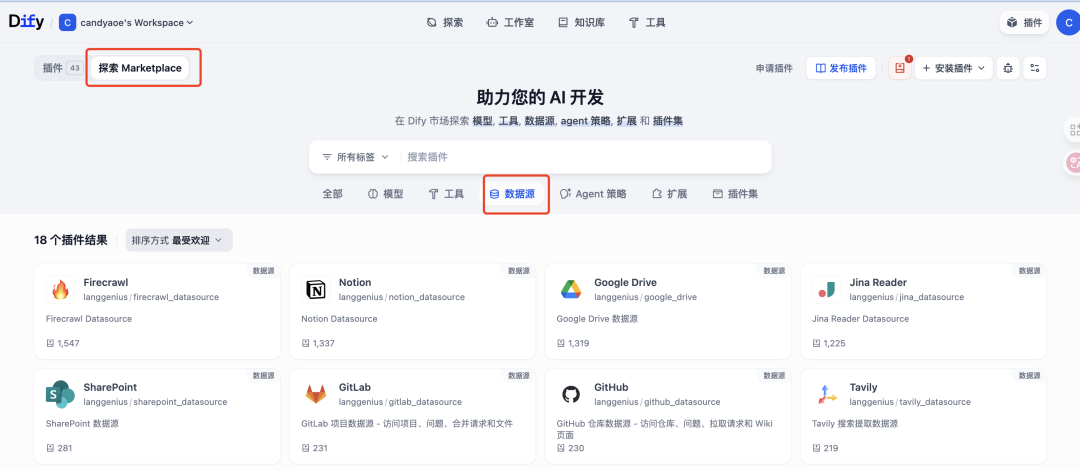
◦ 数据源突破: 引入了全新的 Data Source 插件类型,用户通过 Marketplace 插件即可一键接入主流数据源(如 Google Drive, Notion, Firecrawl 等),无需为每种数据源编写定制代码并维护认证逻辑。
◦ 模块化选择: 基于插件化架构,企业在数据处理的各个环节(如解析、结构化提取、向量库)都可以按需选型并随时替换,确保始终采用业界最优解。
5-连接业务需求和技术实现
• 价值: 让业务专家也能参与 AI 系统的优化。
• 理由: 通过可视化编排和实时调试,业务专家可以直接看到数据处理流程,并能上手排查检索问题,减少与技术团队反复沟通的成本,使技术团队能更专注于核心业务项目。

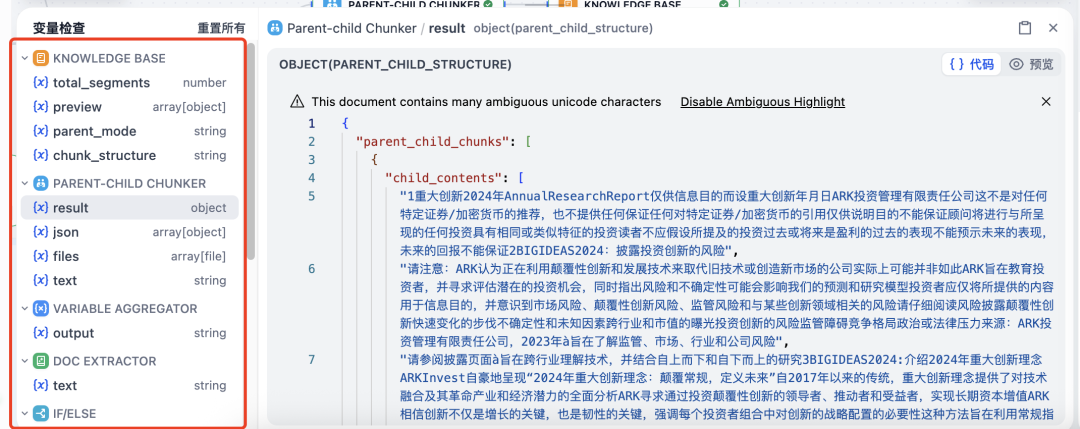
接下来,我测试了一些之前做 Agent 开发比较头疼的场景,比如 PDF 解析(图片类)、表格信息提取、数据图信息提取等,效果非常惊艳!
简单说一下我上传文件格式是 PDF,里面是纯图片模式。需要靠 OCR 解析提取信息。
这份PDF 文件并不是一个好的知识库资料,里面的文字和内容糊出天际。但是,它反而能很好的测试本次 Dify 升级的 Knowledge pipeline 的能力。

一、pipeline 测试效果
我们从简单到复杂,看一下本次的 PDF(图片) 文件的解析结果;
1-文字 OCR 解析能力
问题1:AI 提及次数在财报电话中翻了几倍?
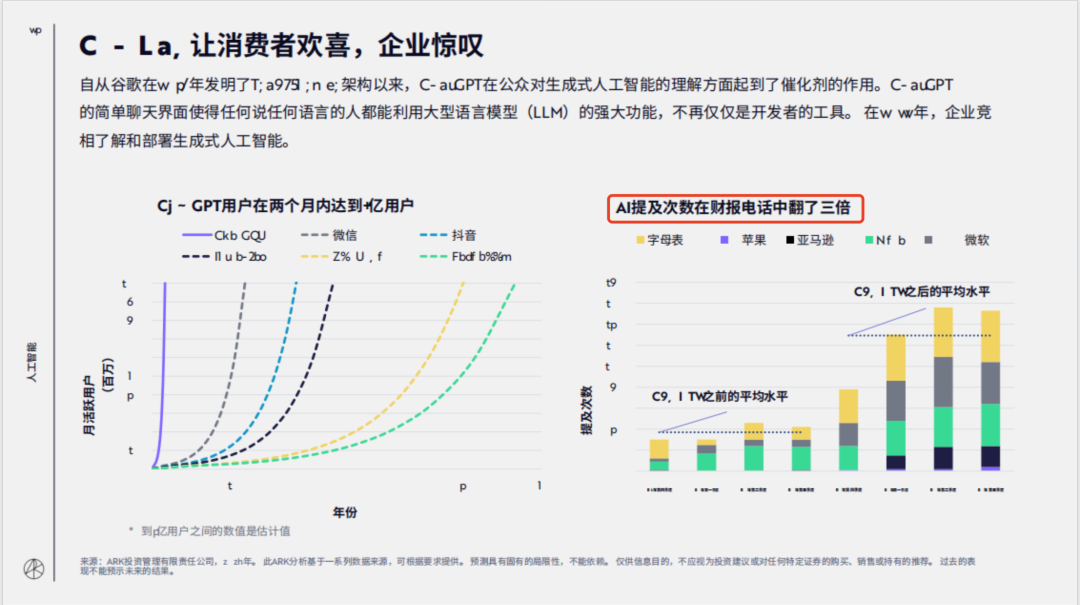
回答:可以看到,这个信息得到了良好的解析和回答。
2-非结构化布局信息识别和提取
问题2:HELM评估指标有哪些?
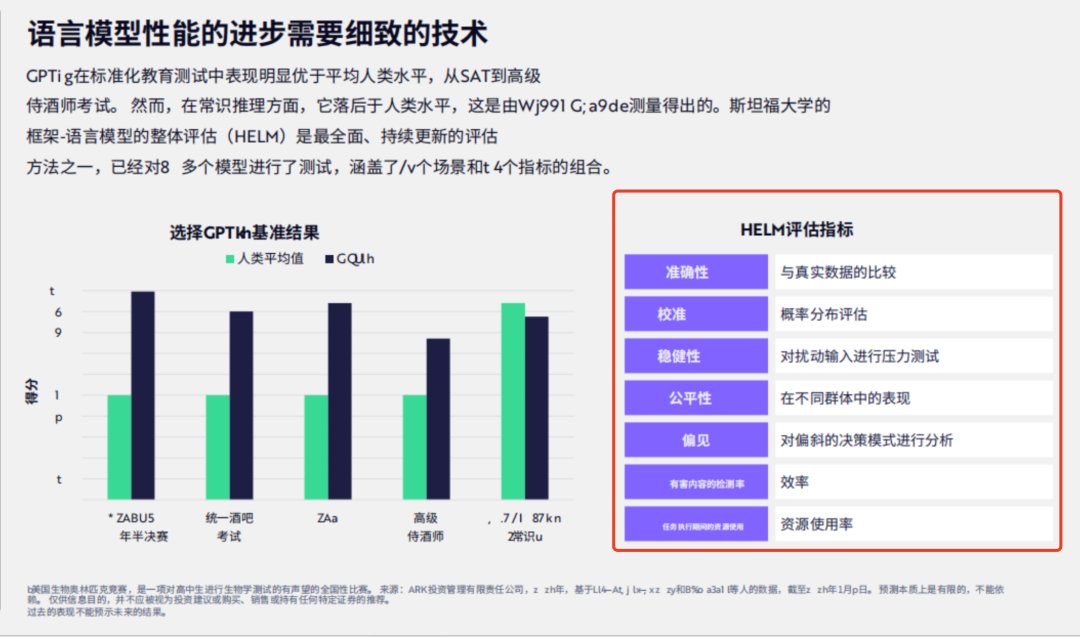
回答:可以看到,右侧的 HELM 评估指标,完整的得到识别和回答。

3-结构化表格信息提取
问题 3:为什么说比特币已成为机构投资组合中值得战略配置的独立资产类别?
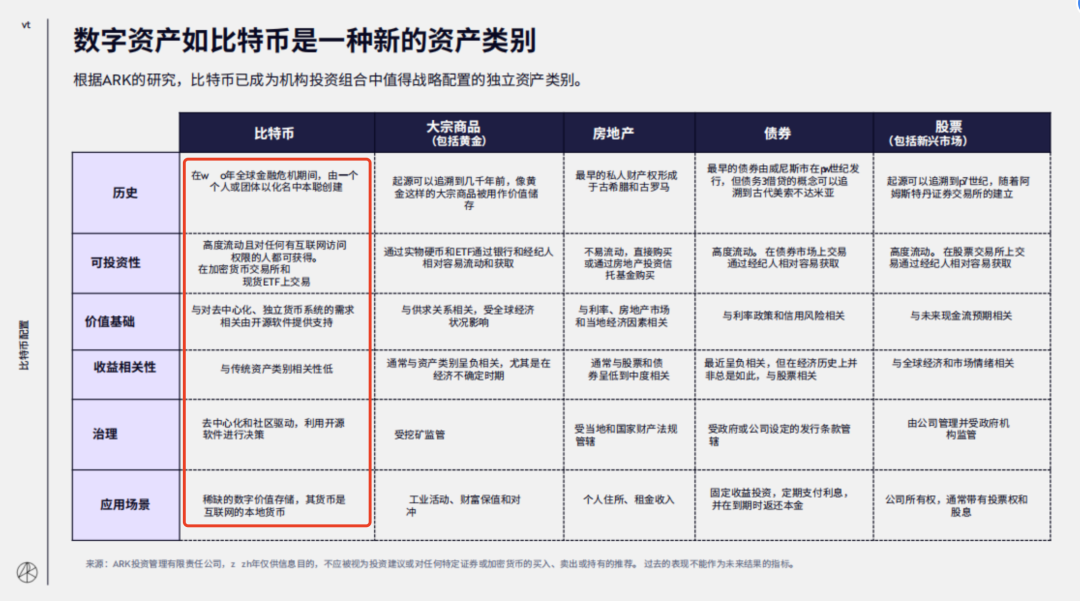
回答:结果比较长,我只把部分回答内容拿出来了。可以看到,答案里已经融合了整个表格的观点,再由大模型进行融合输出。

4-多文档不同类型召回识别
这次,难度再升级一下。我配置了其他的数据结构类型的信息来源。

问题4:介绍一下移动APP—AARRR
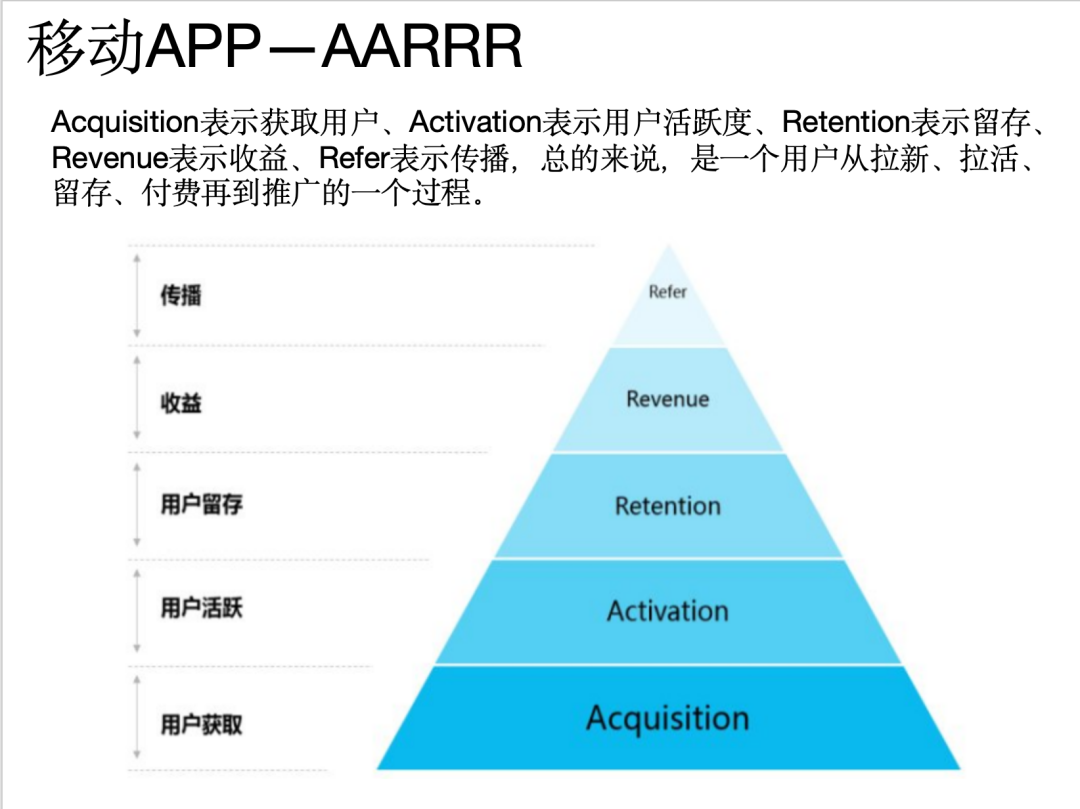
回答:OK,结果非常满意。

问题5:详细说明收入类指标
文档《案例6:app业务指标体系建设(21页 PPT).pptx》相关片段:
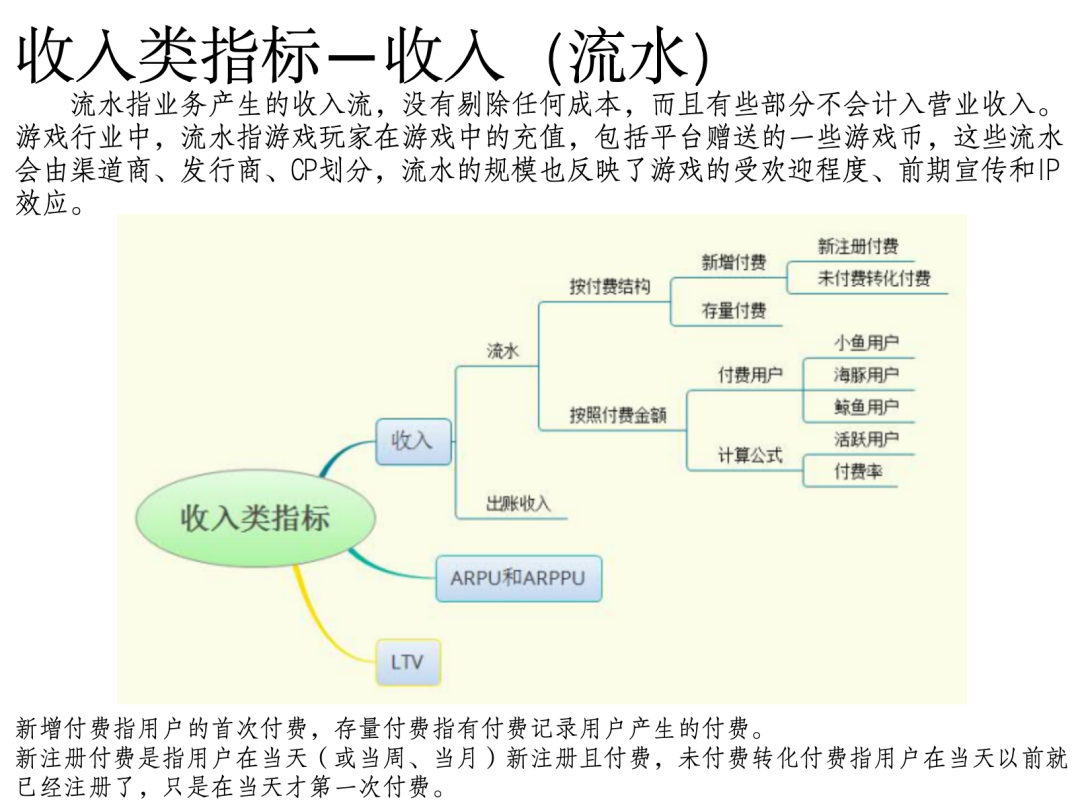
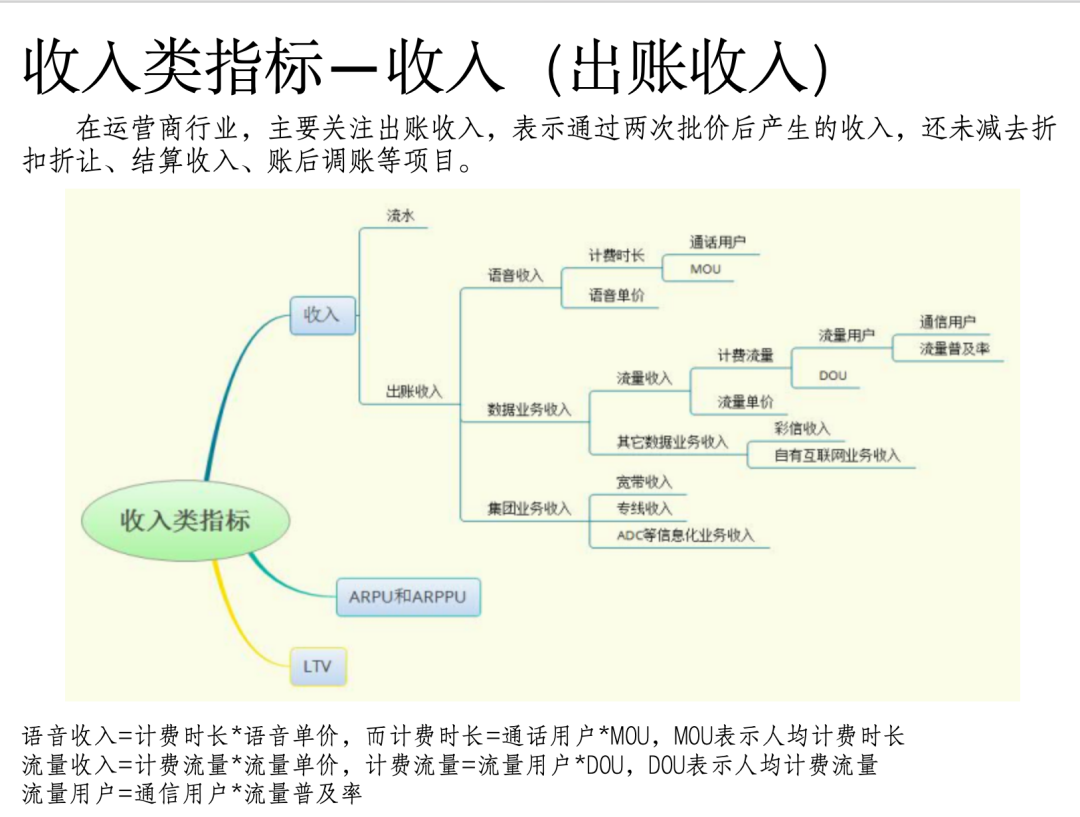
文档《案例7:美团数据指标体系搭建实战.docx》片段:
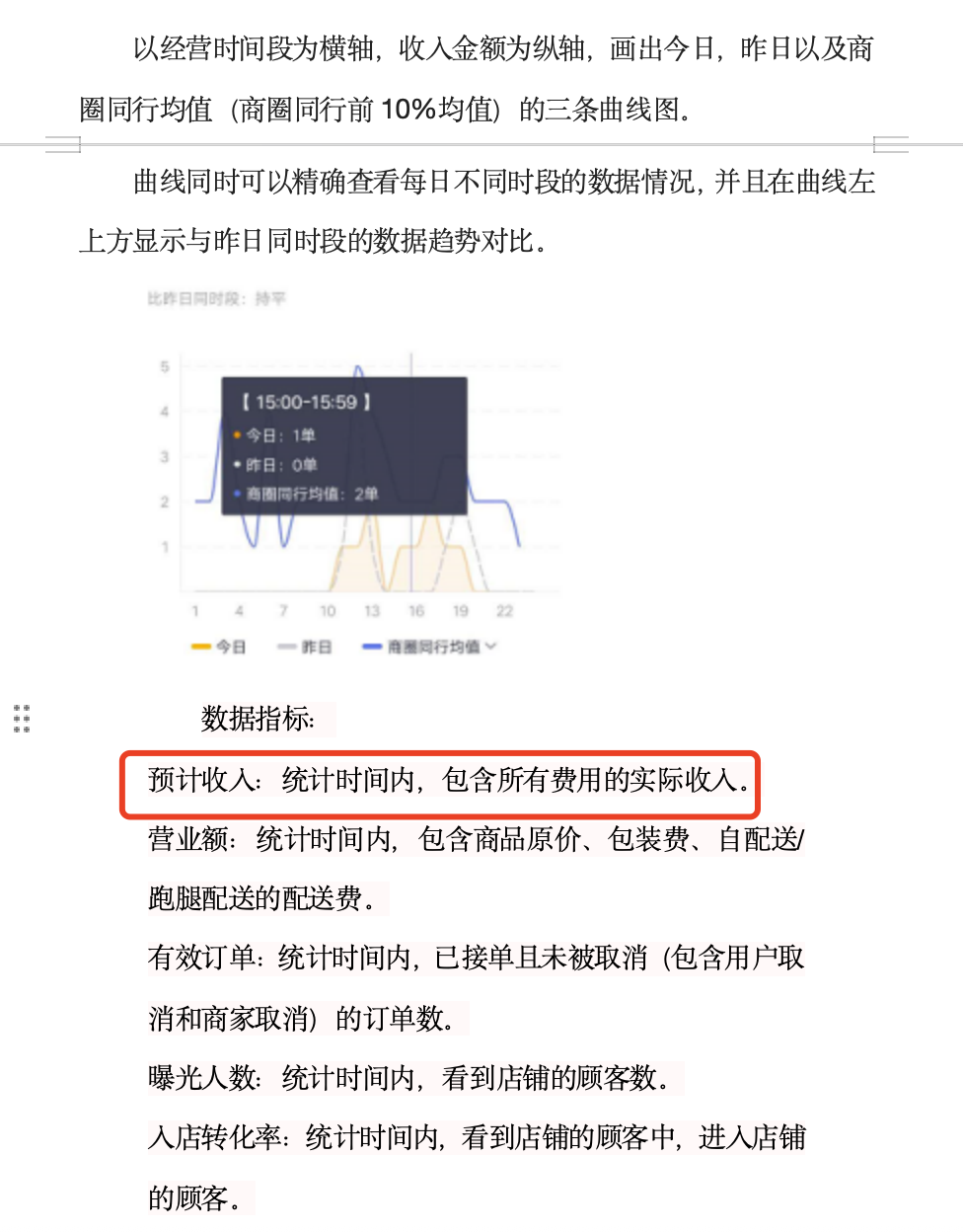
回答:能够综合两个文档内容进行解答。

二、pipeline 配置速通方法
Dify 本次升级在系统里添加了多种类型的模板。
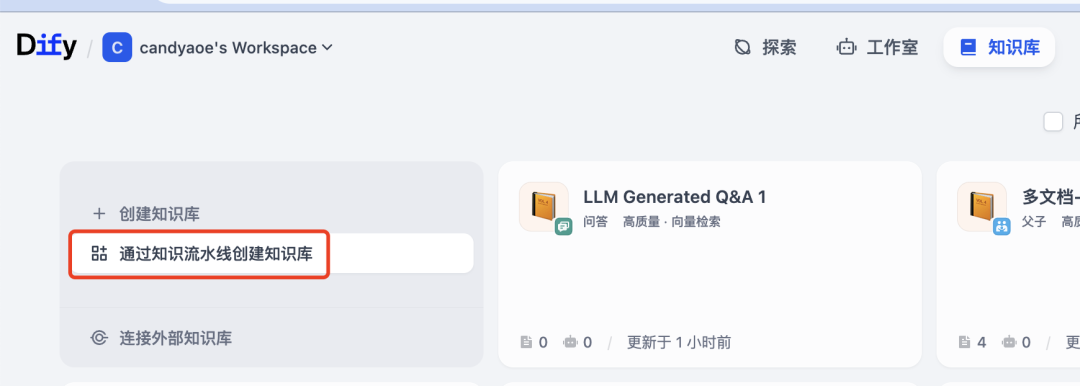
我这次配置的 pipeline 用的是 Dify 内置的模板,选择知识库->通过知识库流水线创建知识库->Parent-child-HQ
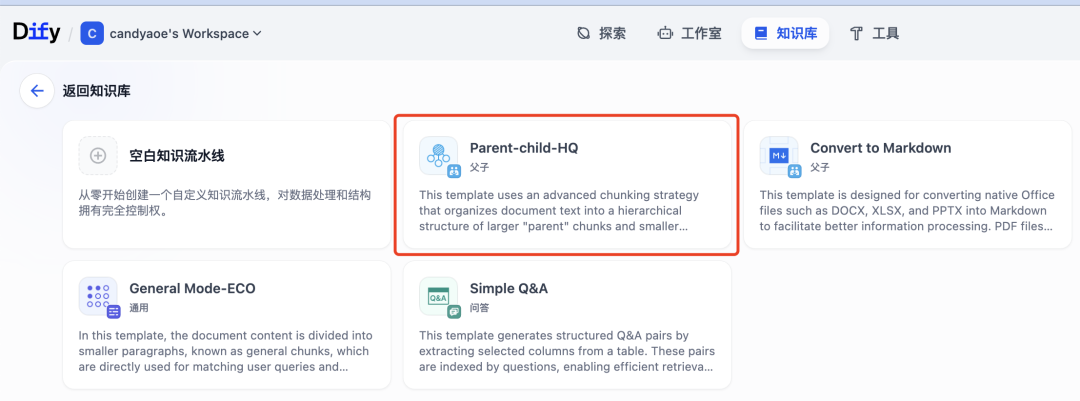
下面是这个模板的工作流详情。唯一需要调整的是在最后一个节点:Knowledge Base,需要切换你所使用的 embedding 和 Rerank模型。
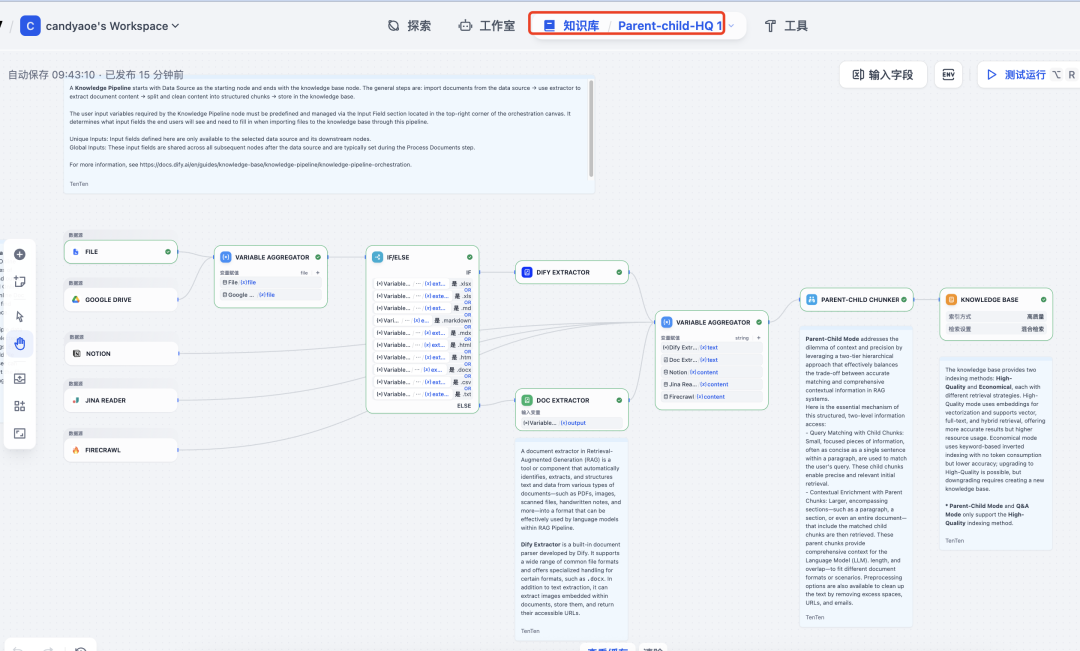
embedding 模型更换,我使用的是硅基流动的 BAAI/beg-m3。
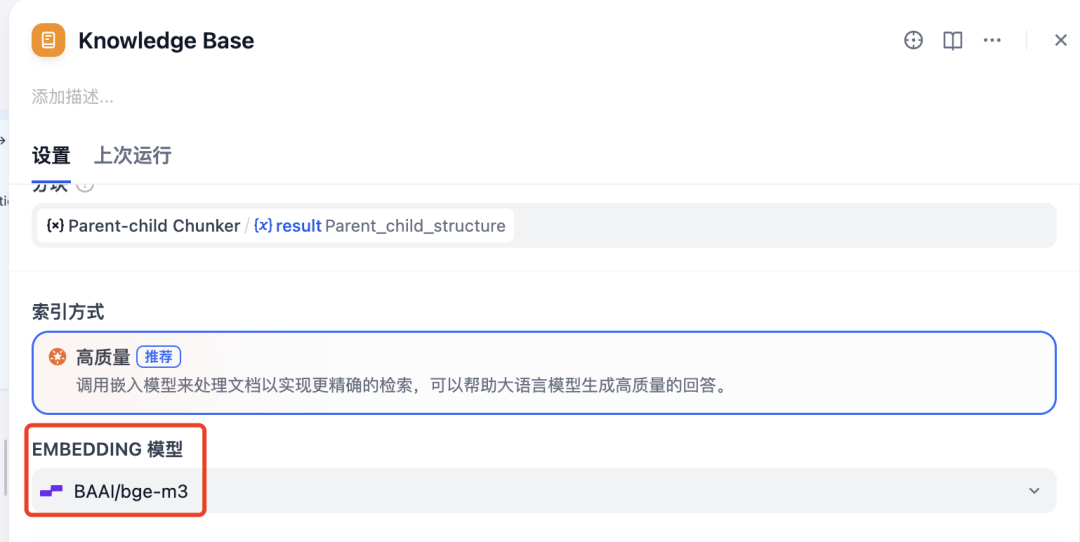
Rerank 模型切换,同样的也是硅基流动的,BAAI/beg-reranker-v2-m3模型。
然后,选择测试运行,上传测试文档。
测试通过后,点击发布,一个完整的 KnowledgePipeline 就发布完成了。
但是,这个时候还不能使用这个知识库,我们需要到“文档”界面,通过“添加文件”,完成解析知识后,才可以在工作流中,配置该知识库。

以上是本次 Dify Knowledge pipeline 的简单测试和快速配置指引。
如果大家对本次升级的其他内容感兴趣,欢迎评论区留言。
最近这几年,经济形式下行,IT行业面临经济周期波动与AI产业结构调整的双重压力,很多人都迫于无奈,要么被裁,要么被降薪,苦不堪言。但我想说的是一个行业下行那必然会有上行行业,目前AI大模型的趋势就很不错,大家应该也经常听说大模型,也知道这是趋势,但苦于没有入门的契机,现在他来了,我在本平台找到了一个非常适合新手学习大模型的资源。大家想学习和了解大模型的,可以**点击这里前往查看**

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 37
37 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)