【AI】LLM三种架构对比
之所以会形成这三个阵营,是因为研究者们最初是针对不同类型的问题来设计模型的。但后来大家发现, Decoder-Only 架构通过其极其强大的“文字接龙”能力,意外地能够“模拟”其他两种架构的任务,并且在超大规模下表现出了惊人的通用性,因此成为了当今超大规模语言模型(LLM)的绝对主流。
·
三种架构的出现和流行,完全是由它们被设计用来解决的 核心任务 决定的。没有“最好”的架构,只有“最适合某个任务”的架构。
逐一分析,并用一个统一的类比:把模型看作一个“人”。
1. Encoder-Decoder 架构 (编码器-解码器)
- 比喻 : 一个专业的 同声传译 或 文章摘要员 。
- 工作流程 :
- Encoder (编码器) : 先完整地、一字不差地听完或读完一整段话(比如一篇英文新闻)。在听/读的过程中,它会反复思考,全面理解每个词在上下文中的意思,最终在脑海里形成一个对整段话的、不依赖于任何特定语言的 深度理解 。
- Decoder (解码器) : 然后,这位翻译员/摘要员看着自己脑海中的这个“深度理解”,开始用另一种语言(比如中文)或更精炼的语言,一个词一个词地把意思重新组织并表达出来。
- 核心任务 : 序列到序列 (Seq2Seq) 的转换任务。这类任务的特点是,输入序列和输出序列的长度、结构、甚至语言都可以完全不同。
- 典型应用 : 机器翻译 (英文 -> 中文)、文本摘要 (长文章 -> 短摘要)、对话问答 (问题 -> 答案)。
- 代表模型 : 原始的Transformer、T5、BART、MASS。
- 优势 :
- 最适合转换任务 : 由于编码器可以无限制地双向访问整个输入,它对输入的理解是最全面、最深刻的。这对于需要完整理解源信息才能准确转换的任务至关重要。
- 输入输出解耦 : 编码和生成是两个独立的阶段,结构清晰,易于针对性优化。
- 劣势 :
- 结构复杂,计算量大 : 需要维护两套独立的网络层(Encoder和Decoder),参数量和计算成本相对较高。
- 不适合纯粹的文本续写 : 如果只是想让模型根据一个短开头(比如“从前有座山”)写故事,那么强大的编码器部分就有点“杀鸡用牛刀”了,因为输入信息很简单,不需要那么复杂的理解过程。
2. Encoder-Only 架构 (纯编码器)
- 比喻 : 一个专业的 阅读理解或文本分类专家 。
- 工作流程 :
- 这位专家拿到一篇文章,从头到尾通读一遍,并且在读的时候,每个词都会联系所有其他的词来理解。比如,读到“bank”时,他会根据句子里的“river”或“money”来准确判断它是“河岸”还是“银行”。
- 读完后,他 不写新文章 ,而是直接给出一个结论,比如:“这篇文章的情感是积极的”、“这句话的主语是‘小明’”、“这个问题的答案在原文第三段第五行”。
- 核心任务 : 自然语言理解 (NLU) 。这类任务需要模型对文本有深刻的理解,但不需要生成新的、流畅的句子。
- 典型应用 : 情感分析、命名实体识别、句子关系判断、为搜索引擎理解查询意图。
- 代表模型 : BERT (及其所有变体,如RoBERTa, ALBERT)。
- 优势 :
- 理解能力极强 : 由于其纯粹的 双向注意力机制 ,它在理解上下文、消除歧义方面的能力是三者中最强的。
- 高效 : 结构相对简单,非常适合做分类、提取等“判别式”任务。
- 劣势 :
- 不具备生成能力 : 这是它的“天生残疾”。它无法自然地写出连贯的句子,因为它没有解码器那样的自回归生成机制。它是一个“分析师”,不是一个“作家”。
3. Decoder-Only 架构 (纯解码器)
- 比喻 : 一个才思敏捷的**“文字接龙”大师 或 创意作家**。
- 工作流程 :
- 你给他一个开头,比如“很久很久以前,在一个遥远的星系……”。
- 他看着这个开头,脑子里只想着一件事:“ 下一个最可能的词是什么? ” 他可能会想出“里”。
- 然后,他看着“很久很久以前,在一个遥远的星系里”,再问自己:“下一个最可能的词是什么?” 他可能会想出“有”。
- 他不断地重复这个“看上文 -> 预测下一个词”的过程,最终写出了一整篇故事。
- 核心任务 : 自然语言生成 (NLG) 。这类任务的核心是根据给定的上文,生成连贯、合理的下文。
- 典型应用 : 所有你现在看到的通用大语言模型! 包括聊天对话、写代码、写邮件、写故事、角色扮演等。
- 代表模型 : GPT系列 (GPT-3, GPT-4) 、LLaMA、PaLM等。这是目前最主流的LLM架构。
- 优势 :
- 生成能力极强 : 整个架构就是为“文字接龙”而生,非常擅长各类开放式的生成任务。
- 任务形式统一 : 它巧妙地把很多任务都统一转换成了“文本续写”任务。
- 翻译:“请把‘你好’翻译成英文:” -> 模型续写出 “Hello”。
- 问答:“中国的首都是哪里?” -> 模型续写出 “北京”。
- 涌现能力 (Emergent Abilities) : 当模型规模大到一定程度时,这种简单的结构反而涌现出了强大的推理、零样本/少样本学习能力,这是它如今一统江湖的关键。
- 劣D势 :
- 理论上理解能力非双向 : 它的注意力机制是单向的(只能看前面的词),所以在理论上,对输入提示(Prompt)的理解不如Encoder的双向机制那么“彻底”。但实践证明,当模型规模足够大时,它在处理上文时已经能形成足够深刻的理解,这个弱点在很大程度上被弥补了。
总结
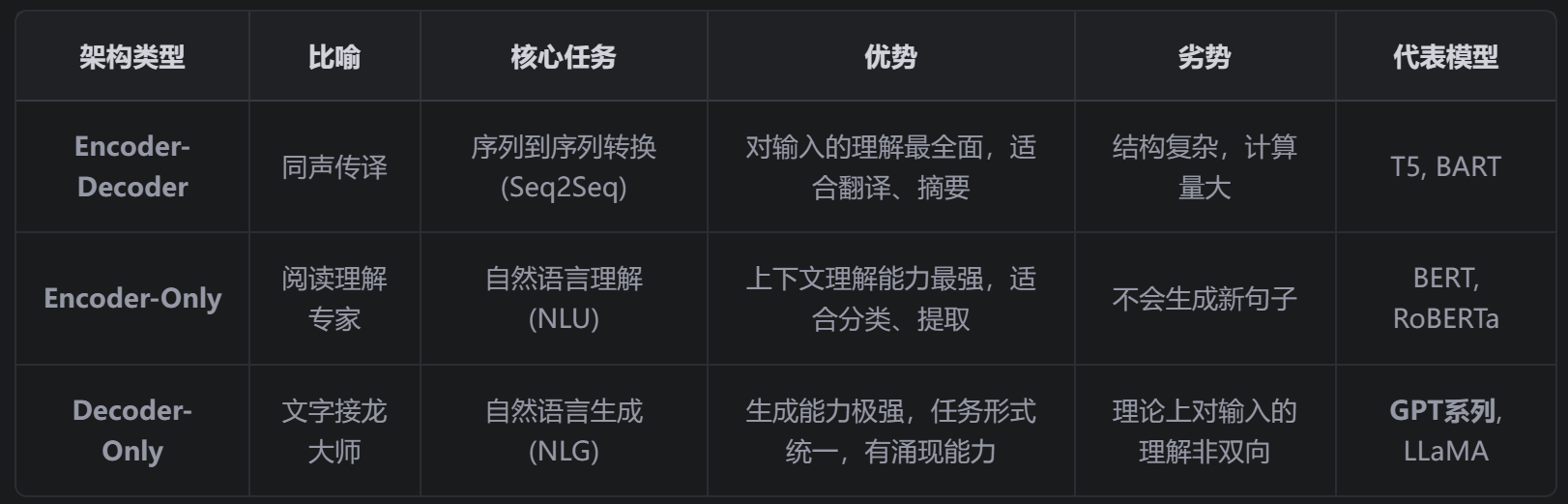
之所以会形成这三个阵营,是因为研究者们最初是针对不同类型的问题来设计模型的。但后来大家发现, Decoder-Only 架构通过其极其强大的“文字接龙”能力,意外地能够“模拟”其他两种架构的任务,并且在超大规模下表现出了惊人的通用性,因此成为了当今超大规模语言模型(LLM)的绝对主流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)