51c大模型~合集108
但如果我能戴上眼镜,或者只需要用手机对着爆胎的车,与潜在的应用程序协作,通过视觉引导或对话或两者的结合来指导我更换轮胎,这就是一个非常平凡的日常生活例子,真正打破了物理 3D 世界和数字 3D 世界的界限。因相比混合在一起的数千亿训练数据,上下文窗口的信息对于模型来说非常清晰,因此,上下文窗口的信息对于 Gemini 2.0 Flash Thinking 来说,就像你让把一张普通轿车的图片改成敞篷
我自己的原文哦~ https://blog.51cto.com/whaosoft/13159017
#AI智能体2小时击败人类
引爆贝叶斯推理革命!仅用10%数据训练秒杀大模型
只用10%数据,训练2小时,就能打造出最强AI智能体!
最近,Verses团队在AI领域投下了一枚重磅炸弹,他们自研的Genius智能体,创造了一个几乎不可能的奇迹——
只用10%数据,训练2小时,就能打造出最强AI智能体!
在经典游戏Pong中,Genius智能体多次达到完美的20分,一举超越了苦练数天的其他AI,和顶尖的人类玩家。
更让人惊掉下巴的是,它的规模只有SOTA模型IRIS的4%(缩小了96%),直接在搭载M1芯片的MacBook上就能跑。
,时长03:06
Genius在「状态好」时,甚至能削电脑一个「秃头」
这一项目的灵感,来自一个四年前的实验——科学家们培养的「盘中大脑」,用5分钟学会了玩Pong游戏。
这启发了科学家们思考,如果能够模仿大脑的工作方式,是不是就能创造出更聪明、更高效的AI。
恰在2023年,这个大胆的想法,在Nature论文中得到了证实。
而现在,Verses团队正将这种生物学的智慧,转化为现实。
研究团队表示,这标志着首个超高效贝叶斯智能体在复杂多维度游戏环境中,实现通用解决方案的重要里程碑。
打造最强AI智能体,LLM并非良策
目前,所谓的AI智能体,大多数实际上只是在大模型基础上,搭建的简单架构。
正如苹果研究团队,在去年10月arXiv论文中,直指现有的LLM,并不具备真正的逻辑推理能力。
它们更像是在「记忆」训练数据中,所见过的推理步骤。
论文地址:https://arxiv.org/pdf/2410.05229
实际上,这种局限性严重制约了AI智能体的实际应用潜力。
即便是OpenAI推理模型o1,尽管代表着技术发展的重要里程碑,但其本质仍是将BBF/EfficientZero(强化学习)和 IRIS(Transformer)两种方法结合到CoT推理计算中。
这种方法虽有创新,但其仍未触及智能体进化的核心痛点。
那么,什么才是真正的突破口?
Verses团队认为答案是,认知引擎。Genius就像是智能体的认知引擎。
它不仅提供了包括认知、推理、规划、学习和决策在内的执行功能,更重要的是赋予了智能体真正的主动性、好奇心和选择能力。
其中,主动性正是当前基于LLM构建的智能体,普遍缺失的的特质。
我们现在已经掌握了一种全新的「仿生方法」来实现通用机器智能,这种方法比上述两种方法(即使是结合在一起)都要明显更好、更快、更经济。
博客地址:https://www.verses.ai/blog/mastering-atari-games-with-natural-intelligence
1张A100,训练2小时
为了与SOTA的机器学习技术进行客观对比,在这些初始测试中,研究者选择了基于模型的IRIS系统。
该系统基于2017年突破性的Transformer架构。这种方案能够最快速地完成部署,从而将精力集中在推进自身研究上,而不是复制他人的工作。
值得一提的是,在Atari 100K测试中表现最优的两个系统——EfficientZero和BBF,都采用了深度强化学习技术,这与Deepmind的AlphaZero、AlphaGo和AlphaFold所使用的方法一脉相承。
研究者在2小时内,用1万步游戏数据分别训练了Geniu和IRIS(记为10k/2h)。
他们将Genius 10k/2h的性能与IRIS进行了对比,后者使用相同的1万步数据,但训练时间为2天(记为10k/2d)。
同时,他们还将Genius 10k/2h的性能与使用完整10万步数据训练的BBF和EfficientZero的公开结果进行了比较。
性能评估采用人类标准化得分(HNS)来衡量,其中HNS 1.0代表人类水平的表现,具体而言,相当于人类玩家在2小时练习时间后(约等于10万个样本)在「Pong」游戏中对战电脑时获得的14.6分平均成绩。
训练时间和模型规模
基于多次游戏运行采样的定性结果
与Transformer和深度强化学习不同,Genius无需依赖强大的GPU进行训练。然而,为确保比较的公平性,所有测试均在AWS云平台上使用同一张英伟达A100 GPU进行。
值得注意的是,无论训练时长如何,IRIS训练后的模型包含800万个参数,而Genius仅需35万个参数,模型体积减少了96%。
Pong游戏的定性分析
在Pong游戏中,IRIS 10k/2h的只会在角落里「抽搐」,而IRIS 10k/2d展现出一定的游戏能力,HNS在0.0到0.3之间。
相比之下,Genius在2小时1万步训练后(10k/2h),就能达到超过HNS 1.0的水平,并在多次测试中获得20分满分。(划到最右即可看到Genius如何从0比6落后一路实现反超)


从左到右滑动:IRIS 10k/2h,IRIS 10k/2d,Genius 10k/2h
下图展示了IRIS和Genius在各自训练条件下所能达到的最高HNS。
需要说明的是,Genius的得分仅为初步测试结果,尚未经过优化
鉴于IRIS 10k/2h未能展现有效的游戏能力,研究者主要展示了IRIS 10k/2d和Genius与电脑对战的质性测试样例。
这局比赛中,IRIS对阵电脑时以6:20落败,而Genius则以20:6的优势战胜了电脑对手。
下面这段视频,展示了Genius在学习「Pong」游戏过程中,在渐进式在线学习方面的卓越表现。
在1万步训练过程中,它依次取得了20:0、20:0、20:1、20:10、14:15的对战成绩。
特别是在第五局比赛中,当训练进行到接近9,000步时,尽管电脑以14:3大幅领先,但Genius随后展现出显著的学习能力,开始持续得分,直至训练步数耗尽。
,时长01:36
,时长01:36
Boxing游戏定性分析
在「Boxing」拳击游戏中,玩家控制白色角色,通过击打黑色对手角色来获取得分。
可以看到,只经过2小时训练的IRIS,开局就被电脑各种完虐;而在经过2天的训练之后,基本上可以和电脑「55开」了。
相比之下,Genius几乎从一直就处于领先,并在最后以86比63赢得了比赛。


从左到右滑动:IRIS 10k/2h,IRIS 10k/2d,Genius 10k/2h
Freeway游戏定性分析
在Freeway游戏测试中,玩家需要控制小鸡穿过马路,同时避开来自不同方向、以不同速度行驶的汽车。
测试结果显示,IRIS 10k/2h和IRIS 10k/2d模型均表现出随机性行为,始终未能成功穿越马路。
而Genius则展现出对游戏对象和动态系统的深入理解,能够持续且成功地在复杂车流中进行穿梭。
从左到右滑动:IRIS 10k/2h,IRIS 10k/2d,Genius 10k/2h
当然研究者也强调,虽然Atari 100k/10k、ARC-AGI能提供参考指标,但目前还没有一个单一的测试,能全面衡量AGI在认知、物理、社交和情感智能等各个维度上的表现。
同时,也需要警惕模型可能出现的过拟合现象,即为了在特定基准测试中取得高分而进行过度优化。这种情况下,就并不能说明模型的泛化能力、效率或在现实应用场景中的适用性。
因此,需要通过多样化的测试来衡量给定模型架构的适用性、可靠性、适应性、可持续性、可解释性、可扩展性以及其他能力。
怎么做到的?
之前Atari 100k挑战排行榜上的SOTA都是以数据为中心,计算复杂度很高的方法,如Transformer、神经网络、深度学习和强化学习。
然而,这些基于深度学习和大模型的AI系统都存在一个共同的弱点:它们大多是通过工程技术手段构建的,缺乏对智能本质的深刻理解。
Genius并非仅仅是对以往SOTA的渐进式改进。研究者应用了Karl Friston教授的自由能量原理、主动推断框架和贝叶斯推理架构。
Karl Friston近年来致力于自由能原理与主动推理的研究,该理论被认为是「自达尔文自然选择理论后最包罗万象的思想」,试图从物理、生物和心智的角度提供智能体感知和行动的统一规律,从第一性原理出发解释智能体更新认知、探索和改变世界的机制,对强化学习世界模型、通用AI等前沿方向具有重要启发意义。
自由能原理认为,所有可变的量,只要作为系统的一部分,都会为最小化自由能而变化。
主动推理框架基于自由能原理提供了一个建模感知、学习和决策的统一框架。将感知和行动都看作是推断的问题。
其核心观点是:生物体认知与行为底层都遵循着相同的规则,即感官观测的「意外」最小化。在这里,「意外」被用于衡量智能体当前的感官观测与偏好的感官观测之间的差异。
主动推理路线图
这些方法深深植根于生物智能背后的神经科学,它将智能系统视为预测引擎,而非仅仅被动式数据处理机器,这些系统能够通过测量预期与感知数据之间的差异来实现高效学习。
其核心目标是持续降低对环境的不确定性,具体方式是学习理解所观察现象背后隐藏的因果动态关系,从而更好地预测结果并选择最优行动。
主动推理的框架概览
这条运用神经科学方法和生物学可行技术来解决Atari问题的另类途径始于2022年。
当时,Friston教授带领Cortical Labs开发了一种「微型人类大脑」,并命名为DishBrain(培养皿大脑),这个「大脑」包含了大约80万个脑细胞,仅仅用了5分钟就学会了打「乒乓球」的游戏,而AI学会这一游戏需要花90分钟时间。
这一研究证明了神经元确实应用了自由能量原理并通过主动推断进行运作,并且即使是培养皿中的脑细胞也可以表现出内在的智能,并随着时间的推移改变行为。
论文地址:https://www.sciencedirect.com/science/article/pii/S0896627322008066
2023年,一篇发表在《自然》上的论文通过体外培养的大鼠皮层神经元网络进行因果推理,也证实了自由能原理的定量预测。
到了2024年初,研究者则更进一步,成功将这些在Dishbrain中展示的主动推断机制纯软件化地应用于乒乓球游戏。

主动推理及其对贝叶斯模型和算法的应用代表了一种根本不同的AI架构,从设计上讲,它比SOTA的ML方法更有效和高效。
如今Genius实现的,就是研究者此前开创的贝叶斯推理架构,它不仅提高了样本效率和持续学习能力,还能优雅地将先验知识与新数据结合。
这一突破带来了全新的先进机器智能方法,具有内在的可靠性、可解释性、可持续性、灵活性和可扩展性。
在统计学、机器学习和AI领域,贝叶斯推理因其在不确定性下的原则性概率推理方法而被视为一个强大而优雅的框架,但迄今为止,其巨大的计算需求一直限制着它在玩具问题之外的应用。
而Genius则代表了对这一障碍的超越,并提供了一个通用架构,使我们能够在此基础上构建众多高效的智能体,让它们能够学习并发展专业技能。
在不久的未来,也许我们再回首,就会发现这不仅标志着贝叶斯革命的开始,更代表着机器智能发展的自然方向。
如下图所示,虚线和渐变轨迹展现了智能体对已识别对象轨迹的概率预测——可能是球、高速行驶的汽车,或是拳击手的刺拳。
这些不确定性的量化,结合置信度的计算,首次展示了智能体的预测和决策过程如何实现可解释性。
这种系统的透明度和可审计性,与ML中不透明、难以解释且无法量化的内部处理过程形成了鲜明对比。
Genius智能体在三个经典游戏中的面向对象预测能力:图中的渐变点展示了智能体对游戏中物体当前位置及其未来轨迹的预测推理
从AlphaGo到Atari,AI智能体新标准
现代,游戏已成为衡量机器智能的有效基准。
1996年,IBM的深蓝击败了国际象棋大师加里·卡斯帕罗夫时,整个世界都为之震撼。
这是一个具有明确规则和离散状态空间的游戏。而深蓝的成功主要依赖于暴力计算,通过评估数百万种可能走法做出决策。
2016年,谷歌AlphaGo在围棋比赛中击败了李世石,成为另一个重要的里程碑。
要知道,围棋的可能棋盘配置数量比宇宙中的原子数量还要多。
AlphaGo展示了深度强化学习和蒙特卡洛树搜索的强大能力,标志着AI从暴力计算向具备模式识别和战略规划能力的重大跨越。
虽然AI在棋类游戏中取得了里程碑式的成就,但这些突破也仅局限于「静态规则」的世界。
它们并不能模拟现实世界中的复杂动态,而现实世界中变化是持续的,需要适应不断变化的条件甚至变化的规则。
由此,电子游戏已经成为测试智能的新标准,因为它们提供了受控的环境,其规则需要通过互动来学习,而成功的游戏过程需要战略规划。
Atari游戏已成为评估AI智能体建模和驾驭复杂动态系统能力的最佳评估标准。
2013年,DeepMind发布了一篇论文,阐述基于强化学习的模型DQN如何能以超越人类水平玩Atari游戏,但前提是需要数亿次环境交互来完成训练。
论文地址:https://arxiv.org/pdf/1312.5602
2020年,DeepMind发表了另一篇基于DRL的Agent57的论文,该系统在57个Atari游戏中超越了人类基准水平,但它需要训练近800亿帧。
论文地址:https://arxiv.org/pdf/2003.13350
为了推动更高效的解决方案,Atari 100k挑战赛应运而生。这一挑战将训练交互限制在100k次内,相当于2小时的游戏训练,就能获得类似的游戏能力。
直到2024年初,Verses团队创下新纪录——
展现了由Genius驱动的AI智能体如何能在Atari 100k挑战赛中,仅用原来1/10训练数据,匹配或超越最先进方法的表现。
不仅如此,它还显著减少了计算量,同时生成的模型大小仅为基于DRL或Transformer构建的顶级模型的一小部分。
如果用汽车来打比方,DQN和Agent57就像是耗油的悍马,Atari 100k的方法就像是节能的普锐斯,而Atari 10k就像是特斯拉,代表着一种高效的革新架构。
为什么Atari 100k很重要
Atari 100k基准测试的重要性,体现在哪里?
它旨在测试智能体在有限训练数据条件,下在三个关键领域的表现能力:交互性、泛化性和效率。
1. 交互性
交互性衡量了智能体在动态环境中学习和适应的能力,在这种环境中,智能体的行为直接影响最终结果。
在Atari游戏中,智能体必须实时行动、响应反馈并调整其行为以取得成功。这种能力正好反映了现实世界中适应性至关重要的场景。
2. 泛化性
泛化性则评估了智能体将学习到的策略,应用于具有不同规则和挑战的各种游戏的能力。
也就是确保智能体不会过拟合单一任务,而是能够在各种不同领域中都表现出色,展现真正的适应性。
3. 效率
效率主要关注智能体在有限数据和计算资源条件下快速学习有效策略的能力。
100k步骤的限制突显了高效学习的重要性——这对于现实世界中数据通常稀缺的应用场景来说尤为重要。
任何开发者都可以编写自定义程序,来解决游戏和逻辑谜题。而Deepmind的原始DQ 方法和Atari 100k都已证明,通过足够的人工干预和大量的数据与计算资源,传统机器学习可以被调整和拟合,以掌握像雅达利这样的游戏。
而Genius的亮点在于,它能够自主学习如何玩游戏,而且仅使用了Atari 100k 10%的数据量!
这,就让它跟现实世界中的问题更相关了。因为在现实场景中,数据往往是稀疏的、不完整的、带有噪声的,而且会实时变化。
广泛的商业应用前景
近来,行业的动态值得令人深思。
微软宣布计划重启三哩岛核电站,以支持其AI数据中心的发展规划
Meta计划在2024年底前部署相当于600,000块H100的算力(每块售价3万美元)
据估计,OpenAI o3单次任务的成本可能超过1,000美元
撇开不可靠性和不可解释性不谈,训练和运行这些超大规模过度参数化(overparameterized)模型的财务成本、能源消耗和碳排放,不仅在经济和环境上不可持续,更与生物智能的运作方式背道而驰。
要知道,人类大脑仅需要20瓦的能量就能完成复杂的认知任务,相当于一个普通灯泡的功率。
更令业界担忧的是,高质量训练数据正在耗尽。而使用合成数据作为替代方案,可能导致「模型崩溃」(model collapse),让模型性能逐渐退化。

模型崩溃:这组图像展示了当AI模型仅使用合成数据进行训练时可能出现的问题。从左到右可以观察到图像质量的持续劣化过程,清晰地展示了模型性能逐步降低的现象
构建有效(可靠)、可信(可解释)和高效(可持续)的 智能体,如果能够通过单一的可泛化(灵活)架构来实现,其影响可能将达到改变人类文明进程的规模。
未来AI发展方向,或许不应该是由少数科技巨头控制的几个庞大的模型,而是部署数万亿个低成本、超高效、专业化的自组织智能体。
它们可以在边缘计算端和云端协同运作,通过协调与合作,在从个体到集体的各个层面都遵循着一个共同的、表面上看似简单的内在目标——追求理解,即降低不确定性。
这种新型智能体特别适合处理那些具有持续变化、数据资源受限,同时要求更智能、更安全、更可持续的问题领域。
比如,在金融、医疗、风险分析、自动驾驶、机器人技术等多个领域,应用前景广阔。
这场关于AI未来的游戏,才刚刚开始。
参考资料:
https://www.verses.ai/blog/mastering-atari-games-with-natural-intelligence
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#GRPO-RM
GRPO-RM来了!将大模型强化学习利器GRPO成功迁移至表示学习,DINOv2迎来新增强
最近,强化学习在微调大语言模型(LLM)方面可以说是大放异彩,特别是像DeepSeek-R1这类模型中应用的GRPO(Group Relative Policy Optimization)算法,效果拔群。这就很自然地引出了一个有趣的问题:这么好用的方法,能从语言模型“跨界”到视觉模型吗?
今天和大家分享一篇很有意思的新工作,来自中国电信、西北工业大学、华为和香港大学的研究者们共同探索了这个问题。他们提出了GRPO-RM,成功地将GRPO这套强化学习框架应用到了视觉表征模型的后训练(post-training)中。
简单来说,GRPO-RM就是“为表征模型量身定做的GRPO”。这项工作不仅让DINOv2这类强大的视觉基础模型在图像分类和语义分割任务上获得了显著提升,也为我们开辟了一条用强化学习优化视觉模型的新路径。
- 论文标题: GRPO-RM: Fine-Tuning Representation Models via GRPO-Driven Reinforcement Learning
- 作者: Yanchen Xu, Ziheng Jiao, Hongyuan Zhang, Xuelong Li
- 机构: 中国电信人工智能研究院(TeleAI), 西北工业大学, 华为技术有限公司, 香港大学
- 论文地址: https://arxiv.org/abs/2511.15256
研究背景:当强化学习遇上视觉表征
在计算机视觉领域,像DINOv2这样的表征学习模型已经非常强大,它们能从海量数据中学会提取通用的视觉特征。但为了在具体的下游任务(比如分类或分割)上取得最佳效果,我们通常需要一个“后训练”阶段,对模型进行微调。
另一方面,在LLM领域,以GRPO为代表的强化学习微调方法已成为新宠。与传统的PPO(Proximal Policy Optimization)等方法不同,GRPO通过比较一组(Group)候选输出的相对优劣来进行策略优化,而不是依赖单个采样,这让训练过程更稳定、高效。
那么,挑战就来了:GRPO是为处理文本序列而生的,它依赖于对token序列的采样和概率计算。而视觉模型输出的是确定性的特征嵌入(embeddings),根本没有“token序列采样”这个概念。如何将GRPO的思想迁移过来,就是这篇论文要解决的核心难题。
GRPO-RM:如何为视觉模型定制一套强化学习流程?
作者们提出了一个非常巧妙的方案,解决了上述核心挑战,并为视觉表征学习量身打造了奖励函数。
核心思想:用“选择题”模拟“开放问答”
论文最大的亮点在于,它通过一个精巧的设计,为视觉模型创造了一个功能上等价于“token采样”的机制。
在LLM中,模型针对一个问题(prompt)生成多个不同的回答(token序列),形成一个“输出组”。而在GRPO-RM中,作者将下游任务转化成了一个“选择题”。
以图像分类为例:
- 问题 (Question): 输入一张图片。
- 回答候选集 (Output Set): 数据集中所有可能的类别标签(比如CIFAR-10就是10个类)。
- 模型输出: 模型不再是生成不确定的token,而是针对这张图片,为所有候选类别输出一个概率分布。
这样一来,我们就得到了一个概率化的“输出组”,完美地适配了GRPO框架所需要的基础。对于语义分割任务,原理也类似,只是输出变成了像素级别的类别概率。
上图清晰地展示了GRPO-RM的整体框架。它包含一个基础的编码器(如DINOv2)和一个任务相关的预测头。在训练时,会复制一个“旧模型”(图a中的θ_old),它不参与梯度更新,仅作为稳定的参考来计算优势(advantages)。整个流程通过最大化一个由奖励驱动的目标函数来优化模型参数,而这个目标函数正是GRPO的核心。
为视觉量身定制的奖励函数
既然是强化学习,就必须有奖励(Reward)。原始GRPO的奖励是为文本设计的,显然不适用于视觉任务。因此,作者设计了两个特别的奖励函数:
- 准确性奖励 (Accuracy Rewards): 这个很简单直接。如果模型对某个候选类别的判断是正确的,就给予一个正向奖励;如果是错误的,奖励就是0。这驱动模型去做出正确的预测。公式可以表达为:
其中是总类别数,是正确类别索引。 - 均匀性奖励 (Uniformity Rewards): 这是另一个精妙之处。除了要“猜对”,我们还希望模型输出的特征表示本身质量更高,分布更均匀,而不是挤在一起。均匀性奖励旨在抑制模型对错误类别产生过高的置信度。它的基本思想是,任何一个输出类别的概率越高,给它的均匀性奖励就越低(一个负值)。
这个简单的设计会鼓励模型在不确定时,倾向于给出一个更平坦的概率分布,从而避免“过拟合”到某些特征上,提升了模型的泛化能力。
最终的总奖励就是这两者之和:。
实验效果:更快、更好、更稳定
作者在DINOv2(ViT-S/14)模型上,针对图像分类和语义分割两大任务,在8个主流数据集上进行了广泛实验,充分验证了GRPO-RM的有效性。
图像分类与语义分割性能全面提升
实验结果显示,无论是在图像分类还是语义分割任务上,GRPO-RM相比标准的微调方法都取得了显著的性能提升。
在PASCAL-VOC、ADE20k和COCO-stuff等语义分割数据集上,GRPO-RM在像素准确率(Pixel Acc)、交并比(IoU)和平均交并比(mIoU)等指标上均优于基线。
在CIFAR-10/100、Tiny-ImageNet等分类数据集上,GRPO-RM同样带来了可观的准确率增益。例如,在Tiny-ImageNet上,准确率提升了超过7%,并且在多数数据集上标准差更小,说明训练过程更稳定。
从上面PASCAL-VOC数据集上的可视化结果也能直观地看到,GRPO-RM对图像细节的分割处理得比标准微调更加精细准确。
收敛速度更快
更有意思的是,GRPO-RM不仅效果好,收敛速度也快得多。从下面的训练损失曲线可以看出,无论是在分布内(ImageNet)还是分布外(Tiny-ImageNet)数据集上,GRPO-RM大约在20个epoch时损失就已接近收敛,而标准微调方法则需要更长的时间。
消融实验验证奖励函数的有效性
作者还通过消融实验证明了“均匀性奖励”的重要性。实验对比了三种设置:只用准确性奖励、使用GRPO-RM的均匀性奖励(Eq. 4)、以及使用另一个备选的均匀性奖励函数(Eq. 5)。
结果表明,加入了均匀性奖励后,模型性能有显著提升,尤其是在分布外数据集(如STL-10和Tiny-ImageNet)上。这也证明了均匀性奖励确实能提升模型的泛化能力。同时,论文中采用的Eq. (4)在性能和计算效率上都优于备选方案Eq. (5)。
关于计算开销,GRPO-RM相比标准微调确实会增加一些计算负担,但考虑到其带来的收敛速度和准确率提升,这种权衡是完全可以接受的。
总结
总的来说,这篇论文迈出了将LLM领域的先进强化学习经验迁移到视觉模型上的重要一步。通过巧妙地将分类任务改造为适配GRPO框架的“选择题”形式,并设计出与表征学习目标(对齐与均匀)相符的奖励函数,GRPO-RM开创了首个用于视觉表征模型后训练的强化学习方法。
这项工作不仅展示了GRPO算法的泛化潜力,也为如何进一步提升视觉基础模型的性能提供了一个全新的、有效的视角。
你觉得这个技术未来会用在哪些场景?一起来聊聊吧!
在这篇文章中通过强化学习的方式引导表征的分布,近期Yann Lecun 的一项工作也与此目标相关,xxx
....
#两院院士增选结果揭晓
周志华、刘云浩当选科学院院士
11 月 21 日上午,中国科学院、中国工程院公布了 2025 年院士增选结果,分别选举产生中国科学院院士 73 人,中国工程院院士 71 人。
两院院士是我国科学技术方面和工程科技领域的最高荣誉称号,本次增选后,我国院士队伍的结构进一步优化。其中,新当选的科学院院士平均年龄 57.2 岁,最小年龄 44 岁,最大年龄 66 岁,60 岁(含)以下的占 67.1%,女性科学家有 5 人当选。
本次增选后,我国现有中国科学院院士共 908 人,现有中国工程院院士共 1002 人。
值得关注的是,在本次增选中,有与人工智能领域相关的学者入选。
中国科学院院士
2025 年中国科学院选举产生了 73 名中国科学院院士和 27 名中国科学院外籍院士。
在这批当选者中,我们熟悉的计算机与人工智能领域的多位顶尖科研大牛也成功入选,彰显了中国在前沿科技方向上的持续突破与重视。
刘云浩 — 清华大学教授,研究计算机系统结构。
刘云浩,清华大学自动化系教授、博士生导师,清华大学全球创新学院院长,国家自然科学基金委杰出青年基金获得者, ACM Fellow,IEEE Fellow,CCF Fellow,ACM China 荣誉主席。
主要研究领域为物联网与工业互联网、室内定位与网络诊断、xx智能导航等。共发表重要学术期刊和会议论文 400 余篇,截至 2025 年 6 月,谷歌学术引用 48000 余次,SCI 他引 12000 余次,H-index105。获得国家自然科学二等奖,教育部自然科学一等奖,教育部技术发明一等奖,中国计算机学会自然科学一等奖,中国电子学会自然科学一等奖,ACM 主席奖,CCF 王选奖等奖项,获 ACM SenSys 2023 时间检验奖,多次获得 MobiCom,SenSys 等国际著名学术会议最佳论文奖。
刘云浩围绕互联网和万物互联开展研究。提出了 “万物相联万物生” 理念。设计和实现了最早的基于 RFID 的物联网室内定位系统 LANDMARC,是国际上对物联网体系结构进行探索的原型系统之一,该研究被写进多本经典教科书,成为很多高校研究生课程内容。此后进一步提出差分增强全息图方法,将基于 RFID 的定位精度提高到毫米级,目前仍保持定位精度的记录。刘云浩还创建了物联网可扩展性理论和物联网xx智能导航理论,发明了被动诊断等自组网技术,搭建了绿野千传(GreenOrbs/CitySee)系统,为大规模自组织物联网奠定了理论和实践基础。
周志华 — 南京大学教授,研究机器学习理论与方法。
周志华,男,江苏盐城人,1973 年 11 月出生,博士研究生毕业于南京大学,教授,博士生导师,南京大学副校长、计算机系主任兼人工智能学院院长,南京大学计算机软件新技术国家重点实验室常务副主任、机器学习与数据挖掘研究所(LAMDA)所长、人工智能教研室主任,英国工程技术学会会士,IEEE 高级会员,AAAI、ACM 会员。国家杰出青年科学基金获得者,国务院特殊津贴获得者。主要从事人工智能、机器学习、数据挖掘、模式识别等领域的研究工作。主持多项科研课题,在重要国际学术期刊和会议发表论文 80 余篇,获发明专利 11 项。
周志华长期从事人工智能核心的机器学习理论与方法研究,他完成的项目在面向多义性对象的机器学习理论与方法方面做出了原创性、引领性成果,引发了中国国内外同行开展跟随研究,相关技术已成功应用于大型企业和国家重大工程。
著有《机器学习》、《Ensemble Methods: Foundations and Algorithms》等,在领域内一流期刊会议发表论文两百余篇,被引用六万余次,主持国家重点研发计划项目等,十余项发明在重点企业应用实施,成果服务于国家重大任务,以第一完成人获国家自然科学二等奖 2 项(2013,2020)、教育部自然科学一等奖 3 项(2005,2011,2019)
完整名单如下:
信息技术科学部(11 人)

数学物理学部(14 人)

化学部(11 人)

生命科学和医学学部(13 人)

地学部(9 人)

技术科学部(15 人)

中国科学院外籍院士(27 人)

中国工程院院士
中国工程院 2025 年院士增选共选举产生 71 位院士以及 24 位外籍院士。
机械与运载工程学部(11 人)

信息与电子工程学部(9 人)

化工、冶金与材料工程学部(10 人)

能源与矿业工程学部(12 人)

土木、水利与建筑工程学部(7 人)

环境与轻纺工程学部(6 人)

农业学部(8 人)

医药卫生学部(8 人)

中国工程院外籍院士

参考链接:
https://www.cae.cn/cae/html/main/col1/2025-11/21/20251121085534713797145_1.html
https://www.cae.cn/cae/html/main/col1/2025-11/21/20251121085534697953434_1.html
https://yszx.casad.cas.cn/tzgg/202511/t20251120_5089431.html
....
#DTS(Decoding Tree Sketching)
无需训练、只优化解码策略,DTS框架让大模型推理准确率提升6%,推理长度缩短23%
专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作 DTS(Decoding Tree Sketching):一种即插即用的模型推理框架,依靠高不确定度分支推理和最先完成路径早停两个关键策略,以近似找到最短且正确的推理路径。
- 论文地址:https://arxiv.org/pdf/2511.00640
- 开源工程:https://github.com/ZichengXu/Decoding-Tree-Sketching
- Colab online demo: https://colab.research.google.com/github/ZichengXu/Decoding-Tree-Sketching/blob/main/notebooks/example_DeepSeek_R1_Distill_Qwen_1_5B.ipynb#scrollTo=oTrZL0i3UstX
在 AIME2024/2025 上,DTS 在 DeepSeek-R1-Distill-Qwen-7B/1.5B 上准确率平均提升 6%、平均推理长度下降约 23%,无尽重复率平均减少 10%。

- 核心洞见:推理链长度与正确率显著负相关;多次解码中最短的推理链往往最正确。
- 方法一句话:在「高熵」位置展开多分支并行解码;哪个分支最先生成终止符(<e>)就立刻停止,从而完成最短路径推理。
- 无需训练:不做 SFT/RL,不改模型权重,纯解码策略,即插即用。
- 实证结果:AIME24/25 上,7B/1.5B 模型准确率 +2%~+8%,平均长度 -17%~-29%,无尽重复率下降 5%~20%。
背景:推理大模型的「过度思考」问题
CoT / 多步推理让模型更会「想」,但也带来很重要的问题:越长越易偏离正确答案或陷入自我重复,正确率反而下降,如下图所示。现有方法多依赖额外训练(SFT/RL)或激进剪枝,落地成本高或稳定性不佳。DTS 开辟了一条全新的技术路线:不训练,只优化解码策略,把「想得又短又准」转变为解码中的搜索问题。

关键实证:最短那条,往往是对的
作者对 AIME24 上的题目做了密集采样:每题 100 次随机解码。结果非常直观:

- 选最短(每题从 100 条里挑最短):76.67% 准确率
- 选最长:10.00%
- 总体平均:51.03%
并且,长度与准确率呈明显负相关:样本点越靠右(越长),正确率越低。这直接催生了 DTS 的目标:以尽可能小的代价,逼近「最短且正确」的那条路径。
Decoding Tree Sketching(稀疏化接码树)
把推理过程看成一棵解码树:节点是已生成 token,路径是一次完整 CoT,叶子节点就是该 CoT 的终止符(<e>)。寻找最短的推理路径相当于搜索从根节点到最浅层的叶子节点的路径。在这个问题中,穷举搜索可以得到最理想的路径,但是这回造成树分支有指数爆炸的复杂度,因此不可行。DTS 的思路是:只在「关键 token」考虑多种可能的结果从而分支构造树结构,如图所示:

在高熵处产生分支
- 在解码过程中,DTS 计算下一个 token 分布的熵 H (v)。
- 若 H (v) ≥ τ(模型不确定):取 Top-K 候选,同时开 K 个分支;
- 若 H (v) < τ(模型很确定):沿单分支前进(常规解码)。
- τ 决定「分支的增长的速率」,K 控制「横向宽度」。τ→∞ 时退化为普通自回归解码。
核心思想:不确定才需要分支;确定时不分支,避免解码树乱枝蔓生。
最先完成即早停
- 任何分支一旦产生终止符(<e>),立即返回这条路径的推理过程和答案;
- 等价于在「稀疏化的解码树」上做 BFS 的最短路原则。
核心思想:把「短即优」的统计规律写进了停止准则。
实验:更准、少复读
QA 准确率提升
DTS 在 AIME2024 和 AIME2025 与传统自回归解码的对比:

结论: 稀疏化解码树 + 早停稳定提升模型最终回答的准确率。
有效抑制模型的「无尽复读」
统计「无法在最大长度内收敛、陷入循环」的比例:

结论:稀疏化解码树 + 早停让「自我复读」的路径被更短的完成路径代替。
一键复现结果
在 Colab 上试运行 DTS: https://colab.research.google.com/github/ZichengXu/Decoding-Tree-Sketching/blob/main/notebooks/example_DeepSeek_R1_Distill_Qwen_1_5B.ipynb
克隆 DTS 的开源项目,并且安装环境:

复现论文中的结果:

结论
DTS 以极低的工程成本,为推理型大模型提供了一种「更聪明」的思考方式。它不依赖后训练,不修改模型参数,仅通过稀疏化的解码树探索最短的推理路径,就能显著提高准确率、减少复读。这种「在不确定处分支、在确定处直行」的设计,使得大模型的推理过程更像人类的理性思考:在模糊时多想几步,在明确时迅速收敛。
DTS 的核心贡献在于:
- 提出一种全新的推理优化范式,把推理质量问题转化为解码搜索问题;
- 揭示推理链长度与准确率的统计规律,为未来的推理模型提供可量化的优化方向;
- 在实际基准上验证有效性与可迁移性,可直接用于主流推理模型。
从更长远的角度看,DTS 展示了一种轻量化的推理优化路线:让模型「想得更少但更准」。未来,类似的解码层优化有望与多步推理、校准与不确定性估计等方向结合,为 Large Reasoning Models 的高效与可靠推理开辟新的路径。
作者介绍
- 徐子程:Johns Hopkins University 一年级博士生,研究领域为 LLM alignment,以及 inference time scaling。
- 王冠楚:University of North Carolina at Charlotte 助理教授,研究领域为 LLM reasoning,AI 安全性以及 AI for healthcare。
- 楼修逸:Johns Hopkins University 硕士研究生,研究方向为 LLM alignment,以及强化学习。
- Yu-Neng Chuang:Rice University 五年级博士生,研究领域为,研究方向为 LLM reasoning,LLM post-training,以及 LLM Routing。
- Guangyao Zheng:Johns Hopkins University 四年级博士生,研究领域为 scalable,privacy-aware AI,以及 AI for healthcare。
- 刘子锐:University of Minnesota 助理教授,研究领域为 LLM efficiency,long-context ability,以及 reasoning。
- Vladimir Braverman:Johns Hopkins University 教授、计算机系副主任,带领团队专注于 Theoretical ML、Optimization、NLP,以及 digital health 等方向的研究。
....
#LimiX
别问树模型了!死磕结构化数据,清华团队把大模型表格理解推到极限
科幻作家刘慈欣在小说《超新星纪元》中描述了一个令人难忘的场景——几个十几岁的孩子被带到一个小山环绕的地方,他们的面前是一条单轨铁路,上面停着十一列载货火车,每列车有二十节车皮。这些车首尾相接成一个巨大的弧形,根本看不到尽头。这些车中,其中一列装的是味精,另外十列装的是盐。
「这么多的味精和盐够我们国家所有的公民吃多长时间?」带孩子们来的大人向他们提问。「一年?」「五年?」「十年?」没有一个孩子答对。最后的答案让他们目瞪口呆:「只够一天」。
这个场景之所以令人难忘,是因为它以一种非常具象的方式向我们展示了这个世界的运转多么难以被普通人准确感知。它的背后是海量的精确数字:负责供应盐和味精的部门需要算出每个周期要生产多少才能满足需求;负责生产的工厂要监控机器运转情况,从一堆精确却晦涩难懂的数字、代码中读出问题;而给机器供电的电力系统也要监测和变压器相关的一切数据,避免非计划停机带来高昂的抢修成本和难以估量的用户损失。
这个世界,就是以这样一种精确的方式运转着。那些数字就像我们每天呼吸的空气,你可能感觉不到它们的存在,但一旦它们出了问题,你的感知将会非常强烈。
也正因如此,这些数据的处理至关重要。由于这些数据往往以固定的行列格式组织,数据之间的结构关系是预先定义好的,因此也被称为「结构化数据」。可以说,我们在工业化社会体验到的几乎所有便利,背后都依赖着这些结构化数据的理解、处理与预测。
然而,在 AI 席卷一切的今天,处理这些最基础的数据,却成了最大的痛点。
我们寄希望于看似无所不能的 LLM 大模型。但现实很骨感:LLM 擅长写诗与编程,但却很难读懂一张简单的电子表格,因为 LLM 的建模方式(涉及到文本的模糊性)与结构化数据所要求的精确性存在巨大 gap,一直达不到生产要求。
这一现状也导致,整个行业都还在用已经存在了十几年的专用模型,每遇到一个新的数据集或者一个新任务可能就要重新训练一个。这就好比为了喝一杯新口味的咖啡,你必须重新造一台咖啡机。这种低效的生产方式与始终追求高效率、强泛化能力的 LLM 领域形成了鲜明对比,也成了阻碍产业发展的一大瓶颈。
这也是为什么,前段时间清华大学与稳准智能联合发布的 LimiX 系列模型让人眼前一亮。作为他们提出的「LDM(结构化数据大模型)」的重要成员,LimiX 做到了 LLM 没有做到的事情,把结构化数据的处理带入了大模型时代。这会改变整个工业 AI 的游戏规则,成为 LLM、xx智能之外通往 AGI 的另一大关键路径。


第一次,在结构化数据上
做到了「通用」!
为什么说 LimiX 的出现有着划时代的意义?
本质是因为,它第一次在结构化数据领域把「通用」这件事做成了!

参加过 Kaggle 的同学都知道,结构化数据领域有很多任务,比如分类、回归、缺失值填补、高维表征抽取、分布外泛化预测……比如根据年龄、舱位等级等乘客特征预测泰坦尼克号乘客是否幸存(分类),基于钻石的克拉重量、切工、颜色、净度等属性预测钻石售价的连续值(回归)等。当然,现实世界的问题远比这些复杂。
在过去的十几年里,解决这些问题主要依靠梯度提升树模型(比如 2014 年发布的 XGBoost、2017 年发布的 CatBoost 等)或 AutoML 集成模型(比如亚马逊在 2020 年提出的 AutoGluon)。就像我们前面所说的,这些模型都是专有模型,每次遇到新任务或新数据集都要重新训练。这和早就实现一个模型通吃各种任务的NLP领域相比,简直落后了不止一个版本!
当然,这些年,有不少研究者尝试将深度学习甚至基础模型思想引入结构化处理领域,像德国 Prior Labs 团队提出的 TabPFN、法国 INRIA 团队提出的 TabICL、加拿大 Layer 6 AI 团队提出的 TabDPT 等都是这一方向的代表。但这些工作都有个特点:它们本质上还是针对不同的任务分别去做专门的预训练,并没有做到真正的通用,而且对于高质量的缺失值填补等任务,很多方法还无法解决。
LimiX 模型(今年8月份发布的 LimiX-16M, LDM 系列的首款模型)是一个打破僵局的存在。它在性能上碾压前述基础模型,超越 XGBoost、CatBoost、AutoGluon 这样的传统专用模型更是不在话下。
- LimiX官网:https://www.limix.ai/
- 技术报告:https://arxiv.org/pdf/2509.03505
- HuggingFace链接:https://huggingface.co/stableai-org
更重要的是,它第一次做到了真正的通用,也就是一个模型,在不进行二次训练的情况下,就能用于分类、回归、缺失值填补、高维表征抽取、因果推断等多达 10 类任务。
简单来说,LimiX 不再像传统模型那样死记硬背某个特定表格的规则,而是通过学习海量数据,能够自主发现样本之间和变量之间的关系并适应不同类型的任务。这使得 LimiX 拥有了类似 GPT 的能力:一个模型,通吃所有任务。对于LLM领域的研究者来说,这个剧情应该很熟悉了,当年语言模型的突破,就是从「横扫xx项NLP记录」开始的。
同时,LimiX 在 benchmark 上的一路领先,也让我们看到了一些优秀 LLM 的来时路。
比如在一场分类任务的对决中,LimiX-16M 在 58.6% 的数据集上都取得了最优结果,断崖式领先。如果再加上其轻量级版本 LimiX-2M 的成绩,整个 LimiX 家族的胜率甚至可以达到 68.9%。

类似的情况也出现在回归任务的 PK 中。同样的,LimiX 的两个模型包揽了前两名,合在一起胜率能达到 62%。和其他模型相比,LimiX-16M 同样是断崖式领先。

此外,对于近期 Prior Labs 团队的挑战者 TabPFN 2.5,LimiX 成功守擂。可以看到,在涉及分类、回归的六项评测中,LimiX-16M 依然保持着绝对优势。

LimiX 还是一个数据填补神器:在现实数据中,经常会有「缺胳膊少腿」的空值。其它预测模型无法直接解决这个任务,而 LimiX 可以像填空一样,精准预测并补全这些缺失值,且无需额外训练。在所有缺失值插补算法中,LimiX 以绝对优势拿下了 SOTA。

不止是跑分王
现实也能打
有人可能说,跑分好看的模型多了,现实中不还是没一个能打的。
LimiX 还真不是这种情况。它具备惊人的稳健性,使其足以落地实际工业场景。我们了解到,LimiX 已经在一些实际工厂中化身「打工人」了。工厂的任务可不像 Kaggle 赛题那样经过简化处理,随便拿出来一个都千头万绪。
就拿最容易理解的食品生产为例。我们知道,很多食品在出厂之前要经过烘干,如果哪个参数没调好,我们买到手的食品就会出现提前变质等问题。以往,食品厂都是依赖事后检测,也就是先烘干,再测含水量,不合格就返工或报废。但如果能提前预测,成本不就打下来了?
这正是 LimiX 发挥作用的环节,它可以精准建模气流流速、燃烧器温度、设备蒸汽比例等工艺参数与产品含水量的复杂关系,使得预测值与真实值平均偏差不到9%,而且模型能解释92%的结果变化,可靠性极强。
类似的案例还有很多,比如在电力现货市场预测电价时,LimiX 可以将企业内部最优模型的误差从 46.93% MAPE 大幅降低到 25.27% MAPE;而在变压器运行状态诊断中,它能将运行状态诊断错误率降低 93.5%(相较于传统预测模型 XGBoost)。
所以,无论从跑分还是实际落地情况来看,LimiX 都是一个充满变革意味的模型。而且,这个模型不仅企业能用,普通研究者也能上手,因为 LimiX 团队最近开源了一个轻量级版本——LimiX-2M。
LimiX-2M
极小模型定义结构化数据理解极限
2M模型就能做结构化数据处理?
是的,LimiX-2M 虽然体积小,但性能却着实惊人:力压 TabPFN-v2 和 TabICL,超越集成学习框架 AutoGluon,仅次于其大哥 LimiX-16M。

更重要的是,它很小,你甚至能在智能戒指上运行它!
具体来说,它能通过分析戒指传感器收集到的结构化位置信息,识别出佩戴者的手势。这种应用具有非常巨大的想象空间。举个例子,通过与智能家居系统连接,我们可以手势控制家里的各式电器,比如像灭霸一样打个响指,就能开关家里的所有电灯。
当然,在比边缘设备性能更强的设备上,这个小模型的速度也会快得多。
举个例子,如果是处理 958 条、60 维特征的 IMU 数据,在 2 核 CPU、4G 内存的低算力环境(差不多就是个树莓派的配置)下,LimiX-2M 单样本 375 毫秒, 总耗时为 359 秒。相较之下,TabPFN-2.5 的总耗时为 1830 秒,比 LimiX-2M 慢 5 倍。而如果你有一台 RTX 5090,则单样本平均耗时仅 0.206 毫秒,总耗时也只有 197 毫秒,真的可以说是眨眼之间就完成了!
LimiX-2M 不止性能与速度兼备,而且也能轻松地低成本微调——你只需家用显卡就能有效微调它!推理快、门槛低的特点使 LimiX-2M 成为助力研究和应用落地的不二之选:即使是只有一张 4090 显卡的小型科研团队或创业公司,也可以在自己的场景中使用、微调 LimiX-2M,从而开展此前根本无法进行的前沿AI实验。
在量子化学领域,如何去评估小有机分子的一组量子力学性质(包括激发能、振子强度和跃迁概率等)对探索分子特性非常重要。但是目前,这些性质只能通过高精度的量子化学方法(如 TDDFT 或 CC2)计算得出,量子力学性质计算成本高昂且耗时。
通过使用 LimiX-2M 对各类量子力学性质进行预测,预测的拟合优度最高可达 0.711,显著超越 TabPfn-2.5(0.658),经过微调后更是达到了 0.815。这节省了大量的实验成本,允许相关研究人员快速进行高通量分子发现。这再次证明了该模型非常适合边缘设备应用以及科研场景。你不必像 LLM 研究者一样需要大量算力,只需一台日常用来玩游戏的电脑,就能轻松高效地进行实验。
11月 10 日正式发布后,LimiX-2M 在 ModelScope 上已经有超过 1200 次下载,在网上也收获了不少好评。

同时,LimiX 还发布了详细的应用指南(https://zhuanlan.zhihu.com/p/1973033408901964300),手把手教你如何将 LimiX 应用到自己的数据上。无需复杂的格式处理,只要简单的几行代码即可接入最前沿的结构化数据大模型。无论是纯 CPU 的简单尝鲜,还是单 GPU 的深度应用,还是多机多卡的极限推理,LimiX 都能 Handle!此外,LimiX 的社区非常活跃,GitHub 上的问题响应速度极快。
一场范式迁移正在发生
从 LimiX 系列模型中,我们能明显感觉到,一个新的时代真的来了。因为和以往不同,LimiX 所展现的绝对不是渐进式的改进,而是一种新的范式迁移。在 LimiX 技术报告中,研究团队甚至报告了 LDM 的 scaling laws。这进一步揭示了该领域正在迈入规模化驱动的新范式。想要更极致的性能?Just scale it!

不同参数量模型的分类(左)、回归(右)损失函数随训练数据量的变化趋势。数据量增大时,损失值先快速降低后缓慢下降。

在不受数据集规模或计算预算限制的情况下,下游任务损失与性能随模型参数规模的变化。可以看到,多项性能指标均与模型参数数量 N 呈现明显的依赖关系。
对于大部分人来说,这场从传统专用模型到「LDM」通用模型的迁移可能很难感知。但无论是日常生活中稳定供应的生活必需品,还是背后庞大的工业体系,几乎所有决策都建立在结构化数据的预测与调度之上。而 LDM 正是在这个隐蔽但关键的层面上,重新定义智能的边界,其重要性完全不亚于现在被讨论最多的语言智能和xx智能。更准确地说,它和后两者是互补关系,都是通往 AGI 的关键步骤。
而且,正如清华大学长聘副教授崔鹏所强调的那样:将 AI 与工业场景深度结合,在我国具有格外突出的必要性。工业本身就是我国最具资源禀赋的领域,我们在工业数据的规模、覆盖面、质量,以及相关政策支持的力度上,都远远领先于其他国家。这意味着,一旦在这一领域形成新的技术范式,其落地深度与产业带动力将是全球范围内少有的。
从这个角度来看,LimiX 所取得的成果更加令人欣慰,它力压 Amazon AWS、INRIA 等一系列顶尖机构,在诸多性能测试上登顶。该模型的开源让中国在非结构化数据建模领域真正站到了世界前沿。
我们也期待国内团队把这一方向的边界推得更远。
....
#Souper-Model
Meta超级智能实验室又发论文,模型混一混,性能直接SOTA
模型也要学会取长补短。
大语言模型(LLM)在众多领域展现出卓越的能力,但它们的训练依然高度依赖算力和时间,需要庞大的计算资源以及精细的训练流程设计。
模型 Souping(Model Souping) ,即对同一架构的多个模型进行权重平均,形成一个新的、更强的模型。相比训练一个庞大的统一模型,souping 更轻量、成本更低,同时能够融合模型的互补能力。
然而,传统的模型 souping 方式通常采用简单的均匀平均,即把所有候选模型的参数直接做等权融合。
本文中,来自 Meta、伦敦大学学院机构的研究者提出类专家 Soup(Soup Of Category Experts, SoCE),这是一种基于模型 Souping 的系统化方法,它利用基准测试的类别构成来挑选最优模型候选,并通过非均匀加权平均来最大化整体性能。
与以往均匀平均方法不同,本文基于一个关键观察:不同基准类别之间的模型性能往往呈现弱相关性。因此,SoCE 能够为每个弱相关的类别簇挑选对应的专家模型,并通过优化的加权方式(而非统一权重)将它们组合起来。
实验结果表明,SoCE 大大提升了模型效果与稳健性,包括在多语言能力、工具调用、数学推理等任务上,并在 Berkeley Function Calling 排行榜上取得了 SOTA 成绩。
- 论文地址:https://arxiv.org/pdf/2511.13254
- 项目地址:https://github.com/facebookresearch/llm_souping?tab=readme-ov-file
- 论文标题:Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
方法介绍
SoCE 基于这样一个洞见:基准测试中不同类别的模型表现往往呈现高度异质的相关结构。不同模型在不同类别上展现出各自的专长,一些类别之间强相关,而另一些类别之间相关性较弱,甚至可能呈负相关。
研究者为了说明这一现象,他们选择分析 Berkeley Function Calling Leaderboard(BFCL)。BFCL 包含多种不同类型的函数调用任务,例如:多轮函数调用。这些任务分别测试模型不同方面的能力,因此非常适合用来观察类别间的能力相关性。
他们制作了一张相关性热力图(correlation heatmap),颜色越深代表相关性越强。

强相关(深绿色区域):多轮任务之间的相关性极高,介于 0.96 到 0.98 之间。这意味着一个模型如果在某个多轮任务上表现优秀,它通常在所有多轮相关场景中都能保持同样的优势。
弱相关甚至负相关(浅绿色区域):二者之间的相关性仅 0.07。这几乎意味着它们是两个完全不同的能力维度。一个模型即便在结构化的多轮场景中表现良好,也并不保证在真实用户采集的开放式函数调用任务中表现可靠。
SoCE 利用上述相关性模式,来有策略地选择并加权模型进行 souping(参数融合)。其核心思想是:为每个弱相关类别簇找到最擅长该类别的专家模型,并通过优化后的加权平均将它们融合,从而结合模型间互补的能力。
算法 1 对整个流程进行了形式化描述,包含四个关键步骤:
- 相关性分析:识别类别之间的弱相关(或不相关)类别对;
- 专家模型选择:根据性能排名,为每个类别挑选表现最好的专家模型;
- 权重优化:寻找能最大化整体性能的加权方案;
- 加权模型 souping:根据优化后的权重对模型进行加权融合,得到最终模型。
权重优化阶段,在一组统一的权重范围内进行搜索。具体而言,对每个模型的权重从 0.1 到 0.9,以 0.1 为步长,遍历所有可能的权重组合。

实验
作者进行了大量实验,以评估 SoCE 在多个维度上的有效性。
作者在 BFCL 基准上对两组模型进行了对比,分别是 700 亿参数和 80 亿参数的密集模型。
对于 70B 模型,他们从官方排行榜中筛选出 4 个候选模型,并在这些模型上应用了 SoCE 方法。结果显示,SoCE 在 BFCL 上取得了 80.68% 的准确率,创造了新的 SOTA,相比此前表现最佳的单模型 xLAM-2-70b-fc-r(78.56%)提升了 2.7%。
最佳模型配置由 xLAM-2-70b-fc-r、CoALM-70B 和 watt-tool-70B 组成,它们的最优权重分别为 0.5、0.2 和 0.3。
对于 8B 模型,SoCE 达到了 76.50% 的准确率,超越了此前 8B 模型 xLAM-2-8b-fc-r,相对提升达 5.7%。其最优权重配置为:
- xLAM-2-8b-fc-r:0.7
- ToolACE-2-8B:0.2
- watt-tool-8B:0.1
作者还进行了消融研究,结果都显示,无论是 70B 还是 8B,SoCE 的模型选择步骤都带来了性能提升。
表 2a 展示了模型在 MGSM(Multilingual Grade School Math)基准上的实验结果。SoCE 的表现优于所有候选模型以及平均 souping。

随后,作者在 MGSM、BFCL、FLORES-36 等多个基准上,对大量候选模型的 checkpoint 进行了系统的 model souping 实验与评估,并据此得出以下关键结论:
类别间线性相关性在模型 Souping 之后显著提升:如图 2 所示。

各类别整体性能稳定提升:例如,对于在 Llama-70B 基础上微调的 checkpoint,在 37 项模型 Souping 实验中的 35 项中,Soup 后的候选模型在 36 个类别中有超过 20 个类别的指标得分更高,并且在所有类别上的净性能增益均为正(见图 5)。

图 3a 和 3b 所示,SoCE 能够找到不同类别的专长模型,从而带来显著性能提升。

了解更多内容,请参考原论文。
....
#Neural B-frame Video Compression with Bi-directional Reference Harmonization
超越 VTM-RA!快手双向智能视频编码器BRHVC亮相NeurIPS2025
在视频编码领域,双向编码(RA 模式)一直是高效压缩的「秘密武器」,长期以来被广泛应用于点播、视频存储等场景。然而,在基于深度学习的智能视频编码中,这项技术也面临新的挑战:双向编码采用复杂的大跨度分层参考结构,这导致运动的精确处理变得困难,参考帧的价值利用也存在明显差异。双向智能视频编码的潜力远未被完全激发,仍有巨大的优化空间等待探索。
为破解上述难题,快手音视频技术团队提出了全新的双向智能视频编码方法 —— BRHVC。该方法不仅在压缩性能上显著超越业内最先进的端到端智能视频编码方案,也成功超越最新标准的 VTM-RA 编码。相关研究成果成功被人工智能领域顶级学术会议 NeurIPS 2025 录用。
- 论文标题:Neural B-frame Video Compression with Bi-directional Reference Harmonization
- 论文地址:https://arxiv.org/abs/2511.08938
视频编码(又称视频压缩)的核心价值在于破解海量视频数据与有限传输、存储资源之间的根本矛盾。未压缩的高清视频码率高达 1-3 Gbps,1 分钟 4K 视频占用近 20 GB 空间,这种数据量远超现有网络带宽和存储设备的承受能力。
对此,视频编码通过消除时空冗余、量化视觉不敏感信息,将视频码率压缩至 1/100~1/1000,使短视频、直播、视频会议、云游戏等应用成为可能。从经济角度看,视频编码技术每年为行业节省数万亿带宽成本,降低数据中心能耗,让用户能享受到低码率高质量的视频服务。
背景:
从低时延模式到双向模式的扩展
视频编码中的低时延模式(Low Delay, LD)采用单向 P 帧编码,仅参考前一帧进行前向预测编码。该方法延迟较小,更适用于直播场景,可以满足实时交互需求,但压缩效率偏低。双向模式(Random Access, RA)采用双向分层 B 帧编码,每个 B 帧可同时参考前后两帧,利用时域上的双向信息,在相同画质下可比低延迟模式节省 20+% 码率,是点播、存储等高画质场景首选。
目前端到端智能视频编码方法主要针对 LD 模式进行优化,在 RA 模式上的研究还不够深入。这是由于 RA 模式的参考帧顺序有着独特的设计,与 LD 模式和其他基于深度学习的视频任务存在本质区别,研发难度更大,进而约束了 RA 模式的性能。为进一步提高双向编码的压缩性能,研究团队基于以下两个任务痛点做出了改进:
长跨度帧的运动处理

该问题的根源在于 RA 编码结构(如右图)固有的时间维度放大效应。与 LD 模式固定 1 帧的参考跨度不同,RA 模式采用分层 B 帧结构,初始层级的帧间隔随层级指数级增长,最高可达 32 帧距离。这种长时距使得运动幅度与复杂度呈非线性激增。当物体在 32 帧间隔内持续移动时,其位移可能超过数百像素,同时伴随遮挡、形变、光照变化等复杂现象。现有光流网络(如 SpyNet)基于局部相关性假设,感受野受限于卷积核尺寸,面对大位移运动时极易陷入局部最优,导致运动场估计出现「断裂」或「漂移」。
不平衡的参考贡献问题

长跨度下两个参考帧的信息价值存在显著差异,如何有效利用参考帧的这一特性是一个关键问题。目前的方法没有显式建模出两个参考帧的重要性权重,即预先认为两帧具有同等的参考价值,这与很多现实情况相悖。
以上图为例,在编码当前帧(如上图 (b))的「号码牌」时,左边的帧由于遮挡而无法提供有效的参考信息,只有右边的帧有足够的参考价值。为了进一步定量分析这种不平衡的参考贡献问题,研究团队设计了专门实验:

用参考左右两帧的双向模型作为基准,用 BD-rate 表示相同质量下测试算法码率相对基准码率的增加比例(越小越好)。上图横坐标表示帧跨度,红色柱体表示只输入两个参考帧中较差的帧,绿色柱体表示只输入两个参考帧中较好的帧,灰色表示两者的 BD-rate 差值。从图中可以看到,在帧跨度较大(即 32 和 16)时,不平衡的参考贡献问题非常严重,这将极大影响后续帧的编码效率。
算法设计

整体框架如图所示,研究团队提出一种创新的双向智能视频编码框架 BRHVC(Bi-directional Reference Harmonization Video Compression),其中提出包括双向运动聚合(Bi-directional Motion Converge, BMC)和双向上下文融合(Bi-directional Contexual Fusion, BCF)两个模块,有效解决了上述长跨度帧的运动难处理问题和参考贡献不平衡问题,从而显著提升了压缩性能。
双向运动聚合(BMC)

BMC 模块针对长跨度运动估计难题,将光流网络生成的多尺度光流(原始、1/2 分辨率、1/4 分辨率)收敛至单一隐变量进行联合压缩,并引入双向参考帧间的互运动特征作为先验,动态适配不同帧类型的信息需求。这种设计突破过往光流压缩的局限,使网络在解码端能重构出覆盖更大感受野的准确运动场,显著提升大位移场景下的运动补偿精度。

BMC 的可视化效果如上图所示,图左半部分表示长跨度的参考,右半部分表示短跨度的参考,上半部分表示所提 BRHVC 用到的 BMC 模块,下半部分表示基准 Baseline 模型。可以看到,BMC 对多尺度光流进行单独生成和整体压缩,可以有效避免大跨度下光流生成时遇到的光流杂乱错误的情况。
双向上下文融合(BCF)

BCF 模块则针对不平衡参考贡献问题,在编码端通过计算当前帧与双向运动补偿结果在像素域的相似度差异,生成空间自适应权重图与偏置项,将参考特征在通道维度按重要性重新加权融合;解码端则利用熵解码后的潜变量重建权重信息,实现与编码端协同。

上图展示了权重特征在不同帧跨度上的区别。可以看到,BCF 处理得到的显式权重建模很好地解决了长跨度帧的遮挡问题,使得所提的 BRHVC 能够聚焦更多注意力在更有参考价值的区域上,从而提高压缩性能。
总之,BRHVC 的两个关键模块形成递进式优化 —— BMC 提供高质量多尺度运动表征,BCF 在此基础上实现智能信息筛选,最终使 BRHVC 在 HEVC 数据集上超越 VTM-RA 编码,成功实现双向智能视频编码对传统标准的超越,具有重要意义。
实验效果


研究团队使用了业内标准数据集 HEVC Class B 至 E、UVG 及 MCL-JCV,分辨率跨度从 240p 到 1080p,并遵循 Intra Period 为 32 的配置以公平评估。实验对比涵盖了 H.265 标准编码器 HM-16.5、最新标准的 H.266 编码器 VTM-17.0 的 LD/RA 模式、最新的低时延智能视频编码方法(如 DCVC-DC、DCVC-FM 等)以及双向智能编码方法 DCVC-B。
结果表明,在 HEVC 数据集上,BRHVC 相比于传统编码器 VTM-LDB 平均实现 32.0% 的码率节省,其中在 Class D 序列上增益高达 44.7%;同时,BRHVC 相比于传统编码器 VTM-RA 实现 1.1% 的码率节省,在编码效率上成功超越 VTM-RA。

研究团队对 BRHVC 的两个模块进行了消融实验,结果表明 BMC 和 BCF 两个模块有着较高的解码收益性价比,能够获得相对基准模型约 12.3% 的显著码率节省。
总结
本研究系统梳理并深入剖析了双向智能视频压缩面临的核心挑战,特别是长跨度帧的运动处理和不平衡参考贡献问题。尽管传统预测编码能够借助前后参考帧显著提高压缩效率,但在长跨度场景下,参考帧之间的信息价值往往呈现明显异质性,使得模型难以充分发挥双向预测的潜在优势。
针对这一瓶颈,快手研究团队提出了全新的 BRHVC 编码框架,通过引入双向运动融合(BMC)与双向上下文融合(BCF)两大关键创新模块,实现了对参考信息的自适应调和。得益于更精准的运动刻画和更均衡的参考融合机制,BRHVC 在压缩性能上超越最新传统标准 VTM-RA 编码器,取得了双向智能视频压缩领域的重要突破,也为未来智能视频编码的发展提供了新的方向。
....
#刚刚,特朗普联手奥特曼,狂砸5000亿美元启动AI「星际之门」
「如果以占 GDP 的比例来衡量,这一规模与阿波罗(登月)计划和曼哈顿(原子弹)计划相当。」
刚刚,在白宫新闻发布会上,特朗普和OpenAI CEO Sam Altman、软银CEO孙正义等人联合宣布了一个名为「星际之门」(Stargate Project)的人工智能项目。

图源:the Verge
星际之门是一家新成立的公司,计划在未来四年内投资 5000 亿美元,为 OpenAI 在美国建设新的人工智能基础设施。现在将立即投入 1000 亿美元。这一基础设施将确保美国在人工智能领域的领导地位,创造数十万个美国就业岗位,并为全球带来巨大的经济效益。

「星际之门」的名字可能取自同名科幻电影。在电影中,星际之门是一种圆环形的外星人设备。它允许人被远程传送到配对的宇宙级距离外的设备离去。
OpenAI 高级研究员 Noam Brown 评价说,「如果以占 GDP 的比例来衡量,这一规模与阿波罗(登月)计划和曼哈顿(原子弹)计划相当。」他还强调说,「这种规模的投资只有在科学论证被仔细审查,且人们相信它将会成功并带来彻底转变的时候才会发生。我同意现在正是合适的时机。」


星际之门项目的初始股权投资者包括软银(SoftBank)、OpenAI、甲骨文(Oracle)和 MGX。软银和 OpenAI 是星际之门项目的主要合作伙伴,软银负责财务责任,OpenAI 负责运营责任。孙正义(Masayoshi Son)将担任主席。
Arm、微软、英伟达、甲骨文和 OpenAI 是主要的初始技术合作伙伴。目前建设工作正在进行中,从得克萨斯州开始,他们正在评估美国各地的潜在场址以建设更多园区,同时他们正在敲定最终协议。
作为星际之门的一部分,甲骨文、英伟达和 OpenAI 将紧密合作,共同构建和运营这一计算系统。这一合作建立在 OpenAI 与英伟达自 2016 年以来的深度合作基础之上,同时也基于 OpenAI 与甲骨文之间较新的合作伙伴关系。
此外,这一项目也建立在 OpenAI 与微软现有合作的基础上。OpenAI 将继续增加对 Azure 的使用,同时与微软合作,利用这些额外的计算资源来训练领先的模型,并提供卓越的产品和服务。
所有人都期待继续构建和发展人工智能(AI)—— 特别是通用人工智能(AGI)—— 以造福全人类。他们相信,这一新举措是这一道路上的关键一步,并将使富有创造力的人们能够找到利用 AI 提升人类福祉的方法。
在官宣该计划的白宫新闻发布会上,Sam Altman 还发表了一段演讲:
在美国实现这一目标,我认为这将是这个时代最重要的事情。这里可以构建通用人工智能(AGI),创造数十万个就业机会,并在这里建立一个全新的产业,没有总统先生的支持,我们无法做到这一点。我很高兴我们能够实现这一目标。我认为这将是一个激动人心的项目,我们将能够实现现在所谈论的所有美好愿景。
非常感谢能够在美国实现这一目标。关于 AI 如何帮助我们解决各种问题,比如癌症研究和其他领域,还有许多问题需要探索。我认为我们可能会与一些领导者一起推动这一领域的进展。
但我相信,随着这项技术的进步,我们将看到疾病以前所未有的速度得到治愈。我们将惊讶于我们能够如此迅速地治愈各种癌症以及心脏病,并且这项技术将为提供高质量医疗保健的能力带来巨大影响,不仅降低成本,还能以极快的速度治愈疾病。我认为这将是这项技术所做的最重要的事情之一。
看到这个阵容和规模,不知道同样在建设超级数据中心,并且和 Sam Altman 有些不愉快经历的马斯克是什么感受。

参考链接:https://openai.com/index/announcing-the-stargate-project/
....
#语言之外,另一半的智能还有待实现
「除了语言,我们还有另外一半智能,这部分非常深刻,就是我们做事的能力。」
「在 AI 之间加一个 G 以强调其通用性,我是尊重这个想法的。从制造能够思考和帮助人们做出决策的机器的角度来看,AI 或 AGI 对我来说是同样的事情。」
「《龙猫》是我最喜欢的电影之一,这部电影虽然简单却又如此深刻。」
最近,斯坦福大学教授李飞飞接受了硅谷著名投资人 Reid Hoffman 和 Aria Finger 的联合播客专访。
,时长37:15
视频链接:https://www.youtube.com/watch?v=0jMgskLxw3s
在这场对话中,李飞飞主要探讨了以下主题:
ImageNet 的灵感源于难以避开模型的过拟合问题,李飞飞意识到与其苦心改进模型,不如用数据驱动。
探究智能的本质,李飞飞认为智能分为说话的能力和做事能力,与之对应的是语言智能和空间智能,语言是人类的语言,而 3D 是自然的语言。而拥有空间智能的 AI,将做到人类从未做到的事:真正地打破物理世界和数字世界的界限。
在 AI 发展中,需要尊重一些源自「旧石器时代」的核心原则:首先是人类的主体能动性,像「AI 将治愈癌症」这类把 AI 置于主语的表述,容易忽视人是使用技术的主体;二是重视人类的基本需求,包括对健康、生产力和社会认同的普遍追求。
对于人类和 AI 技术安全的关系,李飞飞认为首先要考虑的是,我们应该基于科学,而不是科幻。对于 AI 治理,精力应集中在应用层面设置护栏上,也就是人类受到影响的地方,而不是阻止上游开发。
李飞飞认为只有当拥有正面的生态系统时,才会有正面的 AI 未来,这需要服务于公众福祉的公共部门参与。其分为两种形式:一是推动基础研究和创新,从医疗到教育;二是人才,需要教育越来越多的年轻人和公众了解这项技术。
以下为访谈内容的文字记录:
ImageNet 的起源:人们都只关注模型,而不关注数据
主持人:是什么给了你 ImageNet 的想法?
李飞飞:很难确定具体的某一刻,但这个想法主要形成于 2006 年左右。当时我正在深入研究使用机器学习算法来理解图像中的物体。无论我怎么研究,都无法避开机器学习模型中过拟合这个数学概念。这种情况发生在模型复杂度与使用的数据不太匹配时,特别是当数据的复杂性和数量无法有效驱动模型时。
当然,并不是所有模型都是一样的。我们现在知道神经网络模型具有更高的容量和表示能力。撇开这些专业术语不谈,数据和模型之间确实存在相互作用。但我发现,人们都只关注模型,而不关注数据。这就是我产生洞见的时刻我们不能只关注模型,或者用错误的方式看待问题,我们需要关注数据,用数据来驱动模型。
当时我刚到普林斯顿担任教职,接触到了一个叫 WordNet 的项目。虽然 WordNet 与计算机视觉无关,但它提供了一种很好的组织世界概念的方式。我很喜欢这个名字,一件事接着一件事,ImageNet 就这样诞生了。因为我深信需要大数据和视觉世界的多样化表示,所以开始了这个项目。
解锁智能最重要的另一半:空间智能
主持人:从你 AI 职业生涯中期的 ImageNet 到现在的 World Labs,你能谈谈 World Labs 的理念是什么?你们正在构建什么?你正在建设的东西是我们要去哪里以及如何理解这一点的关键部分,无论是 World Labs 本身还是 AI 的趋势。
李飞飞:是的,这是我们喜欢讨论的话题技术将何去何从。在 ImageNet 之后,我一直在执着地思考一个问题:什么是智能?我们如何让机器产生智能?对我来说,这实际上可以归结为两个简单的方面。如果我们观察人类智能:
第一个方面是我们说话的能力 —— 我们使用语言交流作为工具来交谈、组织知识和沟通。但还有另外一半智能,这部分非常深刻,就是我们做事的能力。比如煎蛋卷、去远足、与朋友相处并享受彼此的陪伴这些都远远超出了我们所说的语言范畴。就像我们能够舒适地坐在对方面前,拿着啤酒罐聊天,这些都是智能的一部分。
这部分智能实际上植根于我们理解我们所生活的 3D 世界的能力感知它,并将其转化为一系列理解、推理和预测,使我们能够在其中行动。在我看来,这种能力被称为空间智能,这是像人类这样的智能生物所具有的基本能力,也就是处理 3D 空间的能力。
ImageNet 之所以诞生,是因为我在寻求为 2D 图像中的像素添加标签。对人类来说,2D 图像是 3D 世界的投影。所以你可以看到,这只是理解我们所生活的更完整的视觉世界的一小步,但这一小步很关键。因为无论是对人类、动物还是机器来说,理解和标记这些图像中的物体都是重要的第一步。
现在,过去了 15 年,我认为我们已经准备好迎接一个更大的挑战。这几乎是一个本垒打式的追求 —— 解锁智能最重要的另一半,也就是空间智能的问题。让空间智能特别有趣的是,它实际上有两个方面:一个是物理的 3D 世界,另一个是数字的 3D 世界。我们以前从未真正能够在两者之间生活,但现在空间智能可以成为一种统一的技术,既可以理解 3D 实体世界,也可以理解数字 3D 世界。
空间智能将如何改变物理世界和数字世界?
主持人:回想一下,如果回到 1880 年,马车和未铺砌的道路,那是一个完全不同的世界。但如果回到 1980 年,好吧,人们开的车不同了,但他们住在相同的建筑里,仍然在开车,现实世界的机制基本上是一样的。你认为这「另一半智能」会在未来几十年改变这一点吗?我们会看到实体世界发生像过去几年数字世界那样的巨大转变吗?
李飞飞:我认为会的。我认为现实和数字之间的界限将开始模糊。举个例子,我想象自己在高速公路上开车,如果爆胎了,尽管我是个技术专家,我可能还是会遇到困难。但如果我能戴上眼镜,或者只需要用手机对着爆胎的车,与潜在的应用程序协作,通过视觉引导或对话或两者的结合来指导我更换轮胎,这就是一个非常平凡的日常生活例子,真正打破了物理 3D 世界和数字 3D 世界的界限。这种技术赋能人类的景象,无论是更换轮胎还是进行心脏手术,对我来说都非常令人兴奋。
大语言模型和大世界模型有什么区别?
主持人:你说你经常使用大语言模型来学习,我觉得这很鼓舞人心。我的孩子们总是说「哦,我数学很好,不需要再学习了」,我可以告诉他们「看,李飞飞也在使用大语言模型学习」。我想你还有一些要说的。在谈到大世界模型与大语言模型时,你如何向人们解释这种区别?你认为这在未来会如何发展?
李飞飞:从根本上说,就像我说的,一个是关于说话,另一个是关于看和做事。所以它们是非常不同的模态。大语言模型的基本单位是字母或词,而在我们的世界模型中,基本单位是像素或体素。它们是非常不同的语言。我几乎觉得语言是人类的语言,而 3D 是自然的语言。我们真的想要达到这样一个点:AI 算法能让人们与像素世界互动,无论是虚拟的还是物理的。
旧石器时代的情感、中世纪的制度以及技术的作用
主持人:你的回答让我想起你引用过的社会生物学家爱德华・威尔逊的话:「我们有旧石器时代的情感,中世纪的制度,和神一样的技术,这非常危险。」考虑到你刚才谈到的关于推理、自然语言、人们的教育,你如何扭转这种局面?在 AI 时代,人类面临什么机遇?
李飞飞:我仍然相信这句话,正因如此,你和我还有我们的朋友才创立了以人为中心的 AI 研究所。如果要我反转这个局面,我会反过来说这句话:人类有能力创造上帝一样的技术,这样我们就能改善我们的中世纪制度,超越我们旧石器时代的情感,或者将这些情感引导到创造力、生产力和善意上来。
在 AI 的发展中,尊重人的主体能动性
主持人:在构建技术以帮助我们实现抱负方面,你认为关键是什么?是关注同理心?是以人为中心和互动的共生关系?在让技术和 AI 帮助我们实现更好的自我方面,你会把什么作为下一步?
李飞飞:我能理解为什么你同时主修人文科学,你身上体现了哲学和技术的结合。我同意,而且你知道,我们之前几乎把「旧石器时代」当作负面词使用,但它实际上不是负面词,它是一个很中性的词。人类的情感或者我们对自我的认识深深植根于进化,植根于我们的 DNA 中,我们无法改变这一点。世界之所以同时美丽又混乱,正是因为这个原因。
在思考技术与人类关系的未来时,我认为我们需要尊重这一点。我们需要尊重一些最基本的、真正的旧石器时代根源。技术发展需要尊重几个方面,我们越尊重这些,就会做得越好:
首先是尊重人类的主体能动性。我认为 AI 公共传播中的一个问题是,我们经常把 AI 作为句子的主语,好像我们在剥夺人类的主体能动性。比如说「AI 将治愈癌症」,我有时也会犯这个错误,但事实是人类将使用 AI 来治愈癌症,不是 AI 在治愈癌症,也不是 AI 将解决核聚变问题。事实是人类科学家和工程师将使用 AI 作为工具来解决核聚变。更危险的说法是「AI 将夺走你的工作」。我认为我们真的需要认识到,这项技术有更多机会创造机会和工作,赋能人类主体能动性,这是我关心的一个非常重要的第一性原理。
第二个重要的第一性原理是尊重每个人:每个人都想健康,都想有生产力,都想成为受人尊重的社会成员。无论我们如何发展或使用 AI,我们都不能忽视这一点。忽视这一点是危险的,是适得其反的。我认为仅这两点就对指导我们开发这项技术至关重要。
谈论这些深深植根于这样一个信念:任何技术、任何创新的意义都在于对人类有益。这就是人类文明的轨迹每次我们创造一个工具,我们都想用这个工具来做好事。当然,这是一把双刃剑,我们可能会误用工具,会有坏人使用工具。所以即使看到技术和工具的阴暗面,它也推动我们更加努力地让它变得更好,让它更以人为本。这确实是以人为本 AI 研究所的基本原则。在斯坦福,你和我还有我们的朋友都将 AI 视为如此强大的工具,它是一个文明性的工具,我们最好尽早围绕它建立一个框架,将人类和人类利益置于其中心。以人为中心的 AI 最关键的方面之一,也是我认为应该指导每个公司、每个开发者的,就是赋能人们的理念。
AI 治理应该集中在应用层面,而不是阻止上游开发
主持人:你在 AI 领域工作了这么长时间,担任过许多不同的职务。我感觉有些人现在才开始了解 AI。你如何看待当前的 AI 创新时刻,无论是就我们所处的位置,还是开发者面临的挑战来说?你认为要达到解决这些问题的下一个层次,我们需要做什么?
李飞飞:这确实是一个非凡的时刻。我认为这绝对是一场革命的转折点,原因在于应用 ——AI 现在可以被人们和企业日常使用,而且早期 AI 先驱在职业生涯早期阶段设想的许多梦想已经实现或即将实现。比如,公众熟知的图灵测试基本上是一个已解决的问题。图灵测试本身我不会说是智能的终极测试,但它曾是一个如此困难的标准,是一个合理的衡量标准,现在已经解决了。再比如自动驾驶汽车,虽然还没有完全解决,但比 2006 年时已经解决得多得多。
所以我认为,因为这些模型的力量已经产品化到人们和企业手中,这是 AI 革命的一个非凡阶段。但我也清楚地意识到,我们生活在硅谷泡沫中,因为我认为整个全球人口仍在逐步了解 AI 的现状,但我们确实看到了未来和未来的发展方向。
主持人:是的,AI 可能是一个巨型的人类能力放大器,可能带来巨大的积极影响,但我们也确实需要担心负面后果。我们需要引导它朝着正确的方向发展。从发展的视角来看,你认为我们需要做什么来确保 AI 的发展是积极的?
李飞飞:说实话,我认为我们可以做很多事,我认为我们应该昨天就开始做,现在还不晚,我们应该真正致力于此。
第一件事是我认为我们应该基于科学,而不是科幻。关于 AI 导致人类灭绝或 AI 带来世界和平的说法,都有太多炒作和言论,这两种观点都更像是科幻而不是科学。所以当我们思考如何处理 AI 政策、AI 治理时,基于数据、基于科学事实、基于科学方法是非常重要的。
其次,我真的相信,就像许多其他技术和工具一样,我们应该将治理精力集中在应用层面设置护栏上,也就是人类受到影响的地方,而不是阻止上游开发。想想汽车早期,它并不是很安全,没有安全带,一开始甚至没有车门,没有速度限制等等。然后我们确实有了教训,付出了人命的代价,但发生的事情不是让福特和通用汽车关闭工厂,而是为安全带、速度限制等创建了监管框架。
今天的 AI 类似,它是一个深具赋能性的技术,但也带来危害。所以我们应该关注的是,当 AI 应用于医疗时,我们如何更新 FDA 监管措施;当 AI 应用于金融时,我们如何设置监管护栏。应用是我们应该集中治理精力的地方。
最后但同样重要的是,我们需要理解,只有当拥有正面的生态系统时,才会有正面的 AI 未来。而这个生态系统需要私营部门。我认为私营部门(无论是大公司还是创业企业)很重要,但我们也需要公共部门。因为公共部门服务于公众福祉(public goods)。
在我看来,公共福祉有两种形式:一种是那些由好奇心驱动的创新和新知识 —— 无论是使用 AI 研究核聚变,还是使用 AI 治愈疾病,使用 AI 赋能我们的教师。所有这些不同的想法,很多都来自公共部门。ImageNet 就来自公共部门。
另一种形式的公共福祉是人才,我们需要教育越来越多的年轻人和公众了解这项技术,公共部门在 K12 到高等教育方面承担了社会教育责任的主要部分。这些是我非常关心的 AI 治理和政策的不同方面。
一些鼓舞人心的消息:有人在用 AI 评估农村社区的水质
主持人:我认为你也应该强调一下 AI for All,也就是要确保 AI 不是学术大佬们的专利,而是可以造福所有人。请谈谈 AI for All 以及它的使命和贡献是什么。
李飞飞:AI for All 是一个非营利组织,我与我的前学生和同事共同创立,其使命是为来自不同背景的 K12 学生提供机会,通过大学暑期项目和实习接触 AI。这个想法是试图实现 AI 的公共教育福祉 —— 我们知道 AI 将改变世界,但谁将改变 AI?我们希望更多样化的群体能来受到启发,使用这项技术,为各种伟大的事业开发这项技术。
我们一直专注于女性和来自农村、城市内或其他历史上代表性不足的社区和背景的学生,让他们参与这些暑期项目。看到这些年轻人使用 AI 或学习 AI,改进救护车调度算法、使用 AI 评估农村社区的水质,真是太鼓舞人心了!这个事情的规模依然很小,但我希望它能继续发展,因为让更多样化的人参与到 AI 中来这个目标非常重要。
AI 在革新医疗保健服务方面的潜力
主持人:你在医疗保健领域也做了研究。我觉得人们应该更多关注 AI 如何提升医疗水平。能谈谈你在这方面的工作和对未来的展望吗?
李飞飞:是的,正如我在书中所写,我对 AI 在医疗领域的应用充满热情。医疗保健是一个以人为本的领域,涵盖从基础生物科学、药物研发、临床诊断到公共卫生等多个方面。令人振奋的是,AI 在这个体系的每个环节都能发挥重要作用。
我特别关注医疗服务这个领域,因为这里最能体现人与人之间的互助。目前我们面临护士人力短缺的问题,他们工作繁重,流失率高。数据显示,护士每个班次要走四英里以上来取药和设备,在一个班次中,护士可能要完成多达 150 至 180 个不同的任务。同时,我们有病人从病床上摔下来,因为他们缺乏足够的照顾。对病情严重患者的分诊存在很多问题,更不用说独居老年人,面临痴呆恶化等诸多风险。
过去十多年,我一直在研究如何用智能摄像头技术帮助医护人员。这种非接触式的系统可以监测病床上病人的动作预防跌倒,追踪居家老人的行为和生活状况,甚至在手术室帮助护士清点器械避免遗留体内。我们将这种技术称为 NBA 智能,目标是协助医护人员提供更优质的照护服务。
AGI 到底是什么意思?
主持人:现在 AGI 这个词经常被提到,我记得你可能在某处说过你甚至不确定 AGI 是什么意思,因为显然很多人对它有自己的理解,就像是罗夏测试。请谈谈为什么会有这样的 AGI 讨论,它应该意味着什么,如何让这个讨论更理性,而不是一堆零散的呼喊 ——「它很棒」、「它很可怕」、「它会摧毁所有工作」、「它会帮助全人类」。
李飞飞:我知道,这既是一个最有趣但也令人沮丧的对话。我真的不知道 AGI 是什么意思。我想这个词来自大约 10 年前,那时候 AI 刚开始成熟,商业界对此开始产生兴趣。在 AI 之间加一个 G 以强调其通用性,我是尊重这个想法的。比如,现在的自动驾驶汽车就比仅能检测树木的相机要通用得多。这两者之间的差异是真实存在的。
如果回溯历史,回到 AI 的奠基者约翰・麦卡锡和马文・明斯基,回到他们从 1956 年夏天开始的梦想和希望,你会发现这其实就是他们的梦想 —— 制造能够思考和帮助人们做出决策的机器。而我们想的是解决检测树木这种极其狭窄的 AI 任务。
AI 这个领域就是为了创造思考机器。所以从这个角度来看,我们分享着同样的梦想、同样的科学好奇心、同样的追求 —— 让机器可以执行极其智能的任务。
所以从这个角度来看,AI 或 AGI 对我来说是同样的事情。
人际互动的价值:李飞飞与数学老师
主持人:我感觉最近的进步正在让我们更加接近这种 AI。我们可以通过日常对话让 AI 完成各种不同的任务。也就说所谓的智能体(Agent)。你认为这个发展方向如何?在未来几年里,智能体 AI 会像一些人说的那样改变一切吗?
李飞飞:自然语言能帮助人们搜索、构思、学习,是非常强大的工具。我自己也会使用 LLM 来帮助理解某些概念、阅读论文、探索我不知道的东西。最让我兴奋的是看到人们和孩子们将其用作提高自己学习的工具。
我确实想保持专注。保持人们的自我主动性很重要,这就需要为他们提供学习和赋能的好工具。我认为随着工具愈渐强大,我们将看到越来越多的协作能力,允许人类使用这些工具更精确地做事。我会很高兴看到这些发生。
主持人:我认为这不仅很重要,而且也是正确的事情。但也有人会担忧这些 AI 会取代人与人之间的互动,而我们知道社交很重要 —— 不管是对于教学,还是对于社区和同理心。您在自己的书《我看到的世界》中讲述了一个关于数学老师的故事,也涉及到了人际互动的重要性。你能多分享一些这方面的见解吗?
李飞飞:作为一个移民孩子,15 岁来到新泽西州,在不会说英语的情况下进入了一所公立高中。那是我旅程的开始。我非常幸运,很快就遇到了一个数学老师,萨贝拉先生。他以那种真正尊重和无条件的支持对待我。他不仅是我的数学老师,而且在我作为新移民的艰难青少年时期成为了我的朋友。我们的友谊一直持续。
他教育我的方式并不是通过言语。他从来没告诉我:飞飞,AI 要掌控世界了,听我的,去做以人为本的 AI(human-centered AI)。我想这个词从来没出现在我们的对话中。他是通过行动告诉我:我们社会和生活的意义在于我们为彼此所做的积极的事情,以及我们持有的信仰和我们追求的信标。通过他的行动,我开始认识到尊重和帮助他人是一件美好的事情,即使那是一个不会说英语、不知道自己在新国家做什么的迷茫孩子。我认为那种慷慨、善良和同情心是人类的核心。对我来说,从他那里学到的最重要的东西就是「以人为本」。
主持人:真是一个美好的故事。说到这里,有什么电影、歌曲或书籍能让你对未来充满希望吗?
李飞飞:《龙猫》是我最喜欢的电影之一。看到你的动作,仿佛已经能听到《龙猫》的主题曲了。但是我唱得不好,我就不唱了。这部电影虽然简单却又如此深刻。我还可以用陪孩子作为借口看这部电影,但说实话,我才不是因为孩子喜欢看呢!我就是喜欢看这部电影。
技术进步带来的红利必须共享
主持人:那么飞飞,你希望人们更经常问你什么问题呢?
李飞飞:我希望人们多问我如何用 AI 来帮助人类。关于这个话题我可以聊上几个小时,谈到这个我就能想到很多在斯坦福,或者遍布世界各地的优秀同事都为这方面做贡献。他们的具体研究我可能不太了解,但我很乐意通过他们的工作,来指明可供探索的方向。
主持人:没错。现在有很多人在做令人惊叹的事情,我们需要激励更多的人同行。在你的行业之外,有没有看到哪些让人激动的进展呢?
李飞飞:人文学科对能源的关注让我感到鼓舞。这好像再次证明,谈论其他话题,我的思维总会自然而然地回到 AI。就连 AI 的发展也面临着能源这个非常现实的问题,对吧?我认为环境的变化,以及为全球关系实现能源民主化都非常关键。而且我们不能永远依赖化石燃料。因此,许多能源领域的进展和全球性运动都令人兴奋。
主持人:最后一个问题,如果一切都对人类有利,你认为未来 15 年会朝着怎样的方式发展?实现那个目标的第一步是什么?
李飞飞:我希望未来 15 年能看到全球知识、福祉和生产力的整体提升,尤其是实现共同繁荣。之所以特别强调「共同」二字,是因为作为一个技术乐观主义者,我深信技术能帮助人类发现新知识、推动创新、提升福祉。历史一次又一次教会我们:技术进步带来的红利必须共享,我们要让这些技术福祉真正惠及每一个人。
参考链接:https://www.youtube.com/watch?v=0jMgskLxw3s
https://x.com/reidhoffman/status/1879531513752248565
....
#满血版Gemini 2.0又一次登上Chatbot Arena榜首
1M长上下文
就在国内各家大模型厂商趁年底疯狂卷的时候,太平洋的另一端也没闲着。
就在今天,谷歌发布了 Gemini 2.0 Flash Thinking 推理模型的加强版,并再次登顶 Chatbot Arena 排行榜。

谷歌 AI 掌门人 Jeff Dean 亲发贺信:「我们在此实验性更新中引入了 1M 长的上下文,以便对长篇文本(如多篇研究论文或大量数据集)进行更深入的分析。经过不断迭代,提高可靠性,减少模型思想和最终答案之间的矛盾。」

试用链接:https://aistudio.google.com/prompts/new_chat
让我们回忆一下:2024 年 12 月 20 日,横空出世的 Gemini 2.0 Flash Thinking,曾让 OpenAI 的十二连发黯然失色。
Gemini 2.0 Flash Thinking 基于 Gemini 2.0 Flash,只是其经过专门训练,可使用思维(thoughts)来增强其推理能力。发布之初,这款大模型就登顶了 Chatbot Arena 排行榜。
在技术上,Gemini 2.0 Flash Thinking 主要有两点突破:可处理高达 1M token 的长上下文理解;能在多轮对话和推理中自我纠错。
Gemini 2.0 Flash Thinking 的一大亮点是会明确展示其思考过程。比如在 Jeff Dean 当时展示的一个 demo 中,模型解答了一个物理问题并解释了自己的推理过程,整个过程耗时 1 分多钟。
而另外一位研究者表示,Gemini-2.0-Flash-Thinking-Exp-01-21 这款最新模型的实际体验比 Jeff Dean 描述的还要快。

再看 Gemini 2.0 Flash Thinking 的成绩,那也是相当亮眼,和前两代 Gemini 1.5 Pro 002、Gemini 2.0 Flash EXP 相比,Gemini 2.0 Flash Thinking 在 AIME2024(数学能力测试)、GPQA Diamond(科学能力测试)和 MMMU(多模态推理能力)进步迅速,特别是数学成绩,提升了 54%。

从折线图来看,即使是比较对象是一个月前的自己,也取得了显著的提升。

与此同时,在 AGI House 举办的活动中,Jeff Dean 和研究科学家 Mostafa Dehghani 透露了更多 Gemini 2.0 Flash Thinking 和 Gemini 2.0 的细节。
进入 Gemini 2.0 Flash Thinking 的互动界面,可以发现谷歌把 Gemini 系列所有模型都放在了这个称为「Google AI Studio」的界面。
从左侧的菜单来看,我们可以在这里一站式地获得 API 密钥、创建提示词、访问实时对话、开发 APP。平台还提供了模型调优、资源库管理、Drive 访问集成等进阶功能,并配备了提示词库、API 文档、开发者论坛等支持资源。
但这个界面上的功能就像「集市」一样分散,藏得比较深的功能入口似乎并不用户友好,也缺乏介绍模型能力的文档。Jeff Dean 对此表示,当模型不再是实验版而是正式发布时,谷歌将提供完整的技术报告,他们现在的主要目标是让用户试用,再根据更多反馈改善。

Gemini 2.0 Flash Thinking 的互动界面
此外,谷歌的开发理念更偏向「全面均衡」。「我们不希望模型在某些领域特别突出,而其他领域表现欠佳 —— 比如在读 X 射线时表现出色,但解读核磁共振时却很糟糕。」Jeff Dean 补充道:「我们的目标是打造一个真正有实力的通用模型,能够完成用户期待的各类任务。这需要持续改进:我们会收集用户反馈,了解模型在哪些方面做得好,哪些方面做得不够好。然后,获取更多人们关心的数据来提升,确保模型在各个方向都有进步,而不是局限在某个小范围内 —— 虽然在数学等特定领域,有时也会进行专门优化。」
Gemini 2.0 Flash Thinking 主推的亮点是超长的上下文窗口。不过,众所周知,很多具备长上下文窗口能力的 AI 模型都有个通病:聊着聊着就「变傻」了,说的话前言不搭后语,或者就直接「摆烂」,跳过上下文中的大段信息。
Jeff Dean 表示,Gemini 2.0 Flash Thinking 真正能做到在对话过程中保持连贯的思维,并灵活运用之前积累的信息来完成当前的任务。因相比混合在一起的数千亿训练数据,上下文窗口的信息对于模型来说非常清晰,因此,上下文窗口的信息对于 Gemini 2.0 Flash Thinking 来说,就像你让把一张普通轿车的图片改成敞篷车一样,模型能准确理解每个像素,然后一步步完成修改。
而从下面这个 demo 来看,Gemini 2.0 理解多模态的能力已经跃升了一个台阶。它可以根据语音提示,实时改变这三个小圆的排布,排成一行放在界面顶部,或者排列成一个雪人。更夸张的是,Gemini 2.0 对语音、视觉和动作的融会贯通已经达到了你说想要紫色的圆,它知道要把红色和蓝色的圆重叠在一起调色的境地。
,时长01:16
想要如此精准地理解网页界面的布局和内容,需要强大的边框识别能力。Jeff Dean 揭秘,这来自 Project Mariner。Project Mariner 是一个研究性的实验项目,旨在探索人类将如何与 AI 智能体互动,第一步就是让 AI 理解并操作网页浏览器。
Project Mariner 的能力类似于 Claude 的「computer use」,可以实时访问用户的屏幕,理解浏览器中图像的含义。
传送门:https://deepmind.google/technologies/project-mariner/
当被问及 Gemini 系列模型是否要向更多模态进发时,Jeff Dean 的回答是:目前谷歌正在瞄准 3D 数据,而且已经有了很好的结果。
看来谷歌还攒了不少存货,下一个突破会在哪个领域?让我们拭目以待。
参考链接:
https://x.com/rohanpaul_ai/status/1881858428399722948
https://x.com/demishassabis/status/1881844417746632910
https://deepmind.google/technologies/gemini/flash-thinking/
https://x.com/agihouse_org/status/1881506816393380041
....
#OmniManip
化解机器人的「幻觉」:北大发布OmniManip,VLM结合双闭环系统,3D理解能力大幅提升
本文的作者均来自北京大学与智元机器人联合实验室,通讯作者为北京大学计算机学院助理教授董豪。目前团队研究方向覆盖智能机器人的泛化操纵、xx导航和感知自主决策。团队持续开放联合实习生岗位,提供充足的机器人本体和计算资源。
近年来视觉语⾔基础模型(Vision Language Models, VLMs)在多模态理解和⾼层次常识推理上⼤放异彩,如何将其应⽤于机器⼈以实现通⽤操作是xx智能领域的⼀个核⼼问题。这⼀⽬标的实现受两⼤关键挑战制约:
1. VLM 缺少精确的 3D 理解能⼒:通过对⽐学习范式训练、仅以 2D 图像 / ⽂本作为输⼊的 VLM 的天然局限;
2. ⽆法输出低层次动作:将 VLM 在机器⼈数据上进⾏微调以得到视觉 - 语⾔ - 动作(VLA)模型是⼀种有前景的解决⽅案,但⽬前仍受到数据收集成本和泛化能⼒的限制。
,时长00:39
针对上述难题,北⼤携⼿智元机器⼈团队提出了 OmniManip 架构,基于以对象为中⼼的 3D 交互基元,将 VLM 的高层次推理能力转化为机器⼈的低层次高精度动作。
针对⼤模型幻觉问题和真实环境操作的不确定性,OmniManip 创新性地引⼊了 VLM 规划和机器⼈执⾏的双闭环系统设计,实现了操作性能的显著突破。
实验结果表明,OmniManip 作为⼀种免训练的开放词汇操作⽅法,在各种机器⼈操作任务中具备强⼤的零样本泛化能⼒。
项⽬主⻚与论⽂已上线,代码与测试平台即将开源。
- 主⻚地址:https://omnimanip.github.io
- 论⽂地址:https://arxiv.org/abs/2501.03841
技术⽅案解析
⽅法概述
OmniManip 的关键设计包括:
- 基于 VLM 的任务解析:利⽤ VLM 强⼤的常识推理能⼒,将任务分解为多个结构化阶段(Stages),每个阶段明确指定了主动物体(Active)、被动物体(Passive)和动作类型(Action)。
- 以物体为中⼼的交互基元作为空间约束:通过 3D 基座模型⽣成任务相关物体的 3D 模型和规范化空间(canonical space),使 VLM 能够直接在该空间中采样 3D 交互基元,作为 Action 的空间约束,从⽽优化求解出 Active 物体在 Passive 物体规范坐标系下的⽬标交互姿态。
- 闭环 VLM 规划:将⽬标交互姿态下的 Active/Passive 物体渲染成图像,由 VLM 评估与重采样,实现 VLM 对⾃身规划结果的闭环调整。
- 闭环机器⼈执⾏:通过物体 6D 姿态跟踪器实时更新 Active/Passive 物体的位姿,转换为机械臂末端执⾏器的操作轨迹,实现闭环执⾏。

以物体为中⼼的交互基元

物体的交互基元通过其在标准空间中的交互点和⽅向来表征。交互点 p∈R3 表示物体上关键的交互位置,⽽交互⽅向 v∈R3 代表与任务相关的主要轴。这两者共同构成交互基元 O={p,v},封装了满⾜任务约束所需的基本⼏何和功能属性。这些标准交互基元相对于其标准空间定义,能够在不同场景中保持⼀致,实现更通⽤和可重⽤的操作策略。
对于通⽤物体的交互点提取,OmniManip 利⽤视觉语⾔模型(VLM)在原图(当部件可⻅且实体存在时)或在正交视图中渲染的 3D ⽹格(当部件不可⻅或实体不存在时)上进⾏定位。
与 CoPa 和 ReKep 等⽅法不同,OmniManip 直接让 VLM 进⾏ grounding,不会受限于不稳定的 part 分割或聚类结果。
在交互⽅向的采样⽅⾯,由于物体的规范化空间通过 Omni6DPose 锚定,轴的⽅向与语义对⻬,该团队让 VLM 直接对物体标准空间的轴进⾏语义描述,并根据操作任务进⾏匹配度排序,以获得交互⽅向的候选。
双闭环系统设计
李⻜⻜团队的⼯作 ReKep 通过关键点跟踪巧妙地实现了机械臂的闭环执⾏,但其 VLM 规划过程是开环的。OmniManip 则更进⼀步,得益于以物体为中⼼的设计理念,⾸次在 VLM 规划和机械臂执⾏层⾯实现了双闭环系统:
闭环规划:在实验中,VLM 推理很容易出现幻觉,导致错误的规划结果(尤其是在涉及 3D 旋转的任务中,如倒⽔、插笔)。OmniManip 赋予 VLM 闭环规划能⼒,通过渲染物体的三维模型,帮助 VLM 「脑补」出规划结果后的物体样貌,再判断其合理性。
这⼀功能赋予了 VLM 空间反思能⼒,使其能够在测试时进⾏推理,类似于 OpenAI 的 O1,⼤⼤提⾼了操作成功率。为了保持框架的简洁性,研究团队没有设计复杂的测试时推理流程,仅作⼀轮校验就已明显提⾼了 VLM 的规划准确率。
,时长00:11
闭环执⾏:OmniManip 提取的交互基元位于物体的规范空间中,只需引⼊⼀个 6D 位姿跟踪器即可轻松实现闭环操作。与 ReKep 使⽤的关键点跟踪器相⽐,基于物体的 6D 位姿跟踪⽅式更为稳定,并对遮挡具有更强的鲁棒性。(缺点则是不如关键点灵活、⽆法建模柔性物体操作。)
,时长00:23
实验结果
强⼤的开放词汇操作性能
在 12 个真机短程任务上,OmniManip 均展现出卓越的性能。

双闭环系统设计为 OmniManip 带来了约 17% 的性能提升,这证明了 RRC 在有效减少⼤模型幻觉影响⽅⾯的作⽤。
交互基元的鲁棒性
VLM 需要基于交互基元对机器⼈操作进⾏规划,如果交互基元本身存在问题,VLM 就会陷⼊「巧妇难为⽆⽶之炊」的困境。因此,可靠的交互基元⾄关重要。以往的⽅法通常是让 VLM 直接在相机拍摄的 2D 图像上采样交互基元,然后通过相机的内外参数转换到 3D 空间。
然⽽,由于 2D 图像存在空间歧义,采样效果对相机视⻆、图像纹理和部件形状等因素极为敏感(例如,当相机平视杯⼦时,之前的⽅法只能对准杯⼦的侧壁、⽽不是开⼝)。⽽ OmniManip 则是在物体的 3D 规范空间中进⾏采样,能够轻松克服 2D 图像的局限性,实现可靠的 3D 交互基元提取。

强⼤的拓展性与潜⼒
OmniManip 能够与 high-level 任务规划器结合,实现⻓程任务操作
,时长00:42
,时长01:22
作为⼀种以物体为中⼼的算法,OmniManip 与机械臂本体解耦,能够零成本迁移⾄不同形态的本体(例如双臂⼈形机器⼈)。
,时长00:41
OmniManip 具有强⼤的通⽤泛化能⼒,不受特定场景和物体限制。团队已将其应⽤于数字资产⾃动标注 / 合成管道,实现⼤规模的机器⼈轨迹⾃动采集。该研究团队即将开源⾼质量的泛化操作⼤规模数据集和对应的仿真评测基准,敬请期待!
,时长00:09
....
#OS-Genesis
OS-Genesis来了,自动收集和标注Agent数据,高效且多样
共同一作孙秋实是香港大学的博士生,此前在新加坡国立大学获得硕士学位,研究方向包括 LLM Agents 和神经代码智能等领域。共同一作金川杨是约翰霍普金斯大学的博士生,此前以专业第一名毕业于纽约大学,其开发的心智能力测试 MMToM-QA 荣获 ACL 2024 杰出论文奖。本文的 Shanghai AI Lab 吴志勇团队此前已发布了 OS-Copilot、OS-Atlas、SeeClick等同系列成果。
- 论文题目:OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
- 项目地址:https://qiushisun.github.io/OS-Genesis-Home/
- 研究机构:上海人工智能实验室,香港大学,上海交通大学,约翰霍普金斯大学,牛津大学,香港科技大学
1 背景与动机
有效的 Digital Agents 必须拥有两个能力:(1)Planning 能力,即任务规划能力,能将用户给定的(高阶)指令分步划分为子目标(2)Action 能力,即根据当前目标,执行相应的动作。
在构建高质量的 GUI agent 时,GUI 轨迹数据能最有效地让 agent 学习如何完成任务,其数据稀缺性是当前 digital agent 领域最关键挑战之一。以下是一个典型的 GUI 轨迹数据示例,它包括以下部分:
- 高阶指令:明确规定任务目标,例如 “将 Broccoli 应用中的‘Avocado Toast with Egg’标记为收藏”。
- 低阶指令:分解为具体的操作步骤,例如 “点击‘Avocado Toast with Egg’以查看更多选项”。
- 动作:与低阶指令相关的具体操作,如 “CLICK [Avocado Toast with Egg]”。
- 状态:包括执行动作前后的可视化和文本化表示,例如屏幕截图和 GUI 的 a11ytree 结构。

现有的轨迹数据采集方法通常依赖于人工监督或基于预定义任务(Task-Driven)的合成数据生成。这些方法在实际应用中存在以下局限性:
人工采集的过高成本:人工标注轨迹数据需要大量的人力资源,不仅需要手动设计高阶指令,还需逐步记录每一步操作。这使得数据收集过程成本高昂且效率低下。
合成数据的局限性:基于模型生成的轨迹数据虽然可以缓解人工标注的成本问题,但通常依赖于预定义的高阶任务。这种方法不仅限制了生成数据的多样性,还容易导致与真实环境的差距。特别是在中间步骤出错或任务目标 / 环境不匹配时,生成的轨迹可能是不完整或不连贯的。
因此,如何在成本可控的情况下,有效地构建 GUI Agents 轨迹是一个非常重要的课题。在此动机下,本文提出了 OS-Genesis:一套无需人工监督的高质量 GUI 数据合成框架。
2 OS-Genesis
OS-Genesis 的核心思想是:通过先探索性地交互 GUI 环境,捕捉每一步动作及其前后状态变化。

然后基于这些变化逆向生成高质量的低阶指令(Low-level instruction,比如’点击 Calendar APP’),再根据环境导出一个高阶指令(High-level instruction,比如’添加日程:看推文’)。随后,让模型执行这一合成的指令,此过程完全摆脱了人工干预和任务预定义的限制,实现了 GUI 轨迹数据生成的高效性和多样性。本文可以为构建通用的 GUI agent 提供新的思路,其具体方法如下所示。
2-1 反向任务合成
反向任务合成(Reverse Task Synthesis)是 OS-Genesis 的核心,它帮助我们在构建 GUI 轨迹数据时摆脱需要人工 / 机器预定义任务的局限。其流程如下所示:

动作记录与状态捕捉
在没有预定义任务的情况下,OS-Genesis 通过在 GUI 环境中系统性地执行基本动作(例如 CLICK、TYPE、SCROLL 等),生成大量的三元组数据 ⟨状态前,动作,状态后⟩,即 ⟨spre, action, spost⟩。这些三元组记录了每个动作对环境状态的影响,为后续的任务合成提供了原始数据。
低阶指令生成
利用 GPT-4o 模型,将每个三元组 ⟨spre, action, spost⟩ 转化为描述具体操作的低阶指令(Low-level Instruction)。例如,若动作 CLICK 使某菜单展开,低阶指令可能为 “点击下拉菜单以显示选项”。
高阶任务生成
在低阶指令的基础上,OS-Genesis 进一步生成高阶指令(High-level Instruction)。高阶指令通过结合低阶步骤和当前 GUI 环境,描述了一个更为抽象且目标明确的任务,例如 “配置应用程序设置”。这种从低阶到高阶的逐步生成方法不仅确保了指令的逻辑一致性,还能最大化利用 GUI 环境中的动态特性。
通过上述反向任务合成,OS-Genesis 可以在没有人工干预的情况下构建多样化、语义丰富的任务集合,显著提升了数据生成的效率和质量。
2-2 轨迹构建与奖励模型
反向任务合成生成的高阶指令随后被用作探索 GUI 环境的起点,进一步构建完整的轨迹数据(Trajectory)。为了确保生成轨迹的质量,OS-Genesis 引入了一个奖励模型(Trajectory Reward Model, TRM),对生成的轨迹进行质量评估和筛选。以下是轨迹构建与奖励模型的详细流程:
轨迹执行
利用反向任务合成生成的高阶指令,GUI agent 会执行一系列动作以完成任务。每条轨迹由以下内容组成:高阶指令、低阶指令、动作序列以及状态(包含截图和 a11ytree)。
轨迹奖励模型(Trajectory Reward Model)
为避免低质量或不完整轨迹对模型训练的负面影响,OS-Genesis 使用 TRM 对每条轨迹分配一个奖励分数。奖励分数基于以下两个指标:
- 完成度(Completion):衡量轨迹是否成功完成高阶任务,包括每个步骤的正确性和逻辑连贯性。
- 一致性(Coherence):评估轨迹的逻辑性,确保动作序列能够高效地实现任务目标。
奖励驱动的数据筛选
根据奖励分数,轨迹数据会被优先用于模型训练。与传统的二元过滤方法(即抛弃执行失败的任务)不同,TRM 允许部分不完整但具有探索价值的轨迹保留在数据集中,从而最大化地利用生成的数据。

通过结合反向任务合成和奖励模型,OS-Genesis 实现了从任务生成到轨迹构建的端到端流程。实验结果表明,OS-Genesis 生成的数据在质量和多样性上均显著优于现有方法,为构建通用 GUI agent 提供了可靠的数据支持。
3 实验
为了验证 OS-Genesis 在动态环境中生成高质量轨迹数据的能力,本文在动态环境上进行了实验。对于 Mobile 场景选择了 AndroidWorld 和 AndroidControl,对于 Web 场景则使用了 WebArena 作为测评基准。在这些复杂的环境中,作者测试用 OS-Genesis 合成数据训练的 agent 表现相对传统方法效果如何。
3-1 模型与基线
VLMs. 作者在实验中选择了代表性的 VLSs 作为 GUI agent 的基础模型,以便全面评估 OS-Genesis 生成的数据在不同模型上的的影响:
- InternVL2-4B/8B:一种支持高分辨率动态输入的开源 VLM,主要用于视觉任务。其扩展版本 InternVL2-8B 具有更大的模型容量。
- Qwen2-VL-7B-Instruct:一种多模态模型,具备一定的 GUI 交互能力,专为指令执行任务优化。
此外,作者还额外添加了 GPT-4o 作为一个强 baseline,来比较我们所训练的开源模型和商业模型之间的差距。
Baselinse. 所有的 baseline 接受的状态信息均为 Screenshots + a11ytree
- Zero-Shot:直接使用未经过额外训练的模型完成任务。这种方法用于评估模型的原始能力。
- Task-Driven:利用预定义任务和固定策略生成数据,广泛应用于传统数据生成流程。
- Self-Instruct:在 Task-Driven 的基础上,引入自我指令生成机制来扩展任务的和覆盖范围。
3-2 Mobile
在 AndroidWorld(In-domain 实验)中,OS-Genesis 生成的数据显著提升了 GUI agents 的任务成功率,从基线的 9.82% 提升至 17.41%,几乎翻倍。尤其是在任务规划和复杂操作中,OS-Genesis 的数据展现了更强的适应性和泛化能力。

在 AndroidControl 中(OOD 实验),OS-Genesis 生成的轨迹在高阶和低阶任务中均表现出色,特别是在高阶任务中,其规划能力提升尤为明显。此外,OS-Genesis 在未见过的应用场景下表现出了较强的泛化能力,验证了其生成数据的高质量和多样性。
3-3 Web
OS-Genesis 在 WebArena 中的表现也显著优于基线方法。对于复杂的交互式网页任务(如 GitLab 和 Reddit),本工作的 agent 相比 Task-Driven 方法提升了约 50%。在多个动态网页场景中,通过 OS-Genesis 生成的数据,agent 表现出了更高的多样性和泛化能力,特别是在需要多步操作的任务中,其生成轨迹更符合逻辑和用户意图。

4 分析
本项工作对合成轨迹的质量进行了详尽的分析,特别是将 OS-Genesis 生成的数据与人工标注(Human-annotated)数据进行了对比,以全面评估其在实际应用中的可行性和有效性。
4-1 高阶指令对比
作者首先比较了 OS-Genesis 生成的高阶指令与人工编写的高阶指令在任务执行中的效果。实验基于 AndroidWorld 的 500 个人工标注轨高阶任务,采用 GPT-4o 探索其对应轨迹,并用这些轨迹训练基于 InternVL2-8B 和 Qwen2-VL-7B。为保证公平性,OS-Genesis 和各 baseline 的轨迹数量保持一致。
结果分析
在任务成功率上,OS-Genesis 生成的高阶指令显著优于人工编写的指令。这主要归因于以下两点:
- 动态环境适配性:人工编写的任务往往难以与复杂环境完全匹配,而 OS-Genesis 通过反向任务合成生成的指令能够自适应 GUI 动态特性,更符合环境需求。
- 逐步生成策略:OS-Genesis 从低阶指令逐步构建高阶指令,确保了指令的逻辑连贯性和可执行性,而人工编写的高阶指令有时会因缺乏细节而导致轨迹不完整。

4-2 轨迹数据对比
为了进一步验证轨迹质量,作者探讨了 OS-Genesis 生成的完整轨迹与人工标注(Human-annotated)轨迹在 GUI agent 训练中的差异。作者从 AndroidControl 的训练集中选取了 1,000 条众包标注的轨迹进行训练并对比。正如图下,OS-Genesis 显著缩小了合成轨迹与人工标注轨迹之间的性能差距。
这种提升在高阶任务中尤为显著,表明基于 OS-Genesis 轨迹训练的 agent 在任务规划和问题解决方面表现更接近于人类操作方式。从平均任务成功率来看,将人工标注数据视为 gold standard,OS-Genesis 数据的性能保留率超过了 80%。

5 总结与展望
本项工作提出了 OS-Genesis,为有效构建 GUI Agents 提供了全新的视角。通过引入一种全新的交互驱动合成方法,OS-Genesis 成功克服了以往数据收集中构建(1)有意义且(2)多样化的 GUI 任务的关键瓶颈。在多个挑战性的 online 基准测试中,作者证明了 OS-Genesis 生成的数据在构建 GUI agents 的规划和动作能力上实现了突破。此外,OS-Genesis 生成的轨迹数据展现出了更高的多样性,并显著缩小了合成数据与人工标注数据之间的质量差距。OS-Genesis 为生成高质量 GUI agents 训练轨迹数据提供了一个有前景的方向,使研究领域在实现数字世界自动化的道路上更进一步!
....
#可灵视频生成可控性为什么这么好
可灵,视频生成领域的佼佼者,近来动作不断。继发布可灵 1.6 后,又公开了多项研究揭示视频生成的洞察与前沿探索 ——《快手可灵凭什么频繁刷屏?揭秘背后三项重要研究》。可灵近一年来的多次迭代展现出惊人的技术进步,让我们看到了 AI 创作的无限可能,也让我们思考视频生成技术面临的挑战。
视频作为一种时空连续的媒介,对时间维度的连贯性有很高的要求。模型需要确保视频中的每一帧画面都能自然衔接,包括物体运动、光照变化等细节都需要符合现实世界的规律。另一个挑战是用户意图在视频中的精确表达。当创作者想要实现特定的视觉效果时,仅依靠文本描述往往难以准确传达他们的创作意图。这两个挑战直接导致了视频生成的“抽卡率”高,用户难以一次性获得符合预期的生成结果。
针对这些挑战,一个核心解决思路是:通过多模态的用户意图输入来提升视频生成的可控性,从而提升成功率。可灵团队沿着这一思路,在四个控制方向上做了代表性的探索:
- 三维空间控制:之前的视频生成往往局限于单一视角,难以满足复杂叙事需求。为此,团队研究了 SynCamMaster ,实现了高质量的多机位同步视频生成。让创作者能像专业导演一样,通过多角度镜头切换来讲述故事。
- 运动轨迹控制:3DTrajMaster 让创作者能在三维空间中直观地规划和精确地控制物体运动轨迹,让用户轻松实现复杂的动态效果。
- 内容风格控制:StyleMaster 确保了生成视频在保持时间连贯性的同时,能够统一呈现特定的艺术风格,为创作者提供了更丰富的艺术表现手法。
- 交互控制:GameFactory 使用少量 MineCraft 动作数据就能实现交互式游戏体验。结合视频生成的开放域生成,展示了视频生成技术在游戏创作中的广阔应用前景。
这一系列研究成果充分展现了可灵在视频生成领域的系统性探索。通过更好地理解和整合多模态用户意图,降低生成“抽卡率”,可灵正在逐步实现让 AI 视频创作更加精确、可控且易用的目的。
多机位同步视频生成 ——SynCamMaster
Sora、可灵等视频生成模型令人惊艳的性能表现使得创作者仅依靠 AI 就能够创作出好的视频。然而,我们所常见的大荧幕上的电影通常是由多个摄像机同步拍摄后再剪辑而成的,导演可以根据人物情绪变化或故事情节发展切换镜头,以达到更好的视觉效果。例如,在拍摄两人交谈的场景时,镜头通常根据说话人在两人间切换,并在交谈结束后切换到对整个场景拍摄的镜头。而如今的视频生成模型均无法实现 “多机位同步” 视频生成,限制了 AI 影视制作的能力。
近期,可灵研究团队在 “多视角同步视频生成” 领域做出了首次尝试,推出了基于文本的 “多视角同步” 视频生成模型 SynCamMaster,该模型可以根据用户提供的文字描述和相机位姿信息,生成时序同步的多段不同视角视频。
,时长00:31
SynCamMaster 支持多种相机视角变化,例如改变相机方位角、俯仰角、距离远近等,在 AI 影视制作、虚拟拍摄等场景有较强的应用价值。此外、该工作提出了多视角同步视频数据集 SynCamVideo-Dataset 用于多视角视频生成的研究。
- 论文标题:SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints
- 项目主页:https://jianhongbai.github.io/SynCamMaster
- 代码:https://github.com/KwaiVGI/SynCamMaster
- 论文:https://arxiv.org/abs/2412.07760
1. SynCamMaster 效果展示:支持多种相机视角变化
a) 相机方位角变化

b) 相机俯仰角变化

c) 相机远近变化

d) 相机方位角、俯仰角同时变化

可以观察到,SynCamMaster 可以根据用户输入的文本描述及相机位姿生成多段时序同步视频,在保证同步性的同时支持大幅度的视角变化。
2. SynCamMaster 的方法和创新点
如下图所示,SynCamMaster 基于预训练的 “文本 - 视频” 生成模型,在每个 Transformer Block 中插入两个新组件:
- 相机编码器:将归一化的相机外部参数投影到嵌入空间;
- 多视角同步模块:在相机相对位姿的指导下进行多视角特征融合。
在训练时只更新新组件参数,预训练的文本 - 视频生成模型保持冻结状态。
SynCamMaster 的主要创新点为:
- SynCamMaster 率先实现了多机位真实世界视频生成。设计了一种即插即用的 “多视角同步” 模块以实现任意视角下的同步视频生成。
- 提出了一种多种数据混合的训练范式,以克服多机位视频数据的稀缺性并使得模型具备较好的泛化能力。并公开了多视角同步视频数据集 SynCamVideo-Dataset 用于多视角视频生成的研究。
3. 训练数据集:SynCamVideo 数据集
数据收集过程。图(a),从镜头运动的视频中采样视频帧以构造 “多视角图像数据”,示例图像来自 DL3DV-10K;图(b),通过 Unreal Engine 5 渲染的 “多视角视频数据”;图(c),利用通用视频数据作为正则化。

SynCamVideo 数据集是使用 Unreal Engine 5 渲染的多摄像机同步视频数据集。它包含 1,000 个不同的场景,每个场景由 36 个摄像机拍摄,总计 36,000 个视频。SynCamVideo 以 50 种不同的动物为 “主要拍摄对象”, 20 个不同地点作为背景。在每个场景中,从 50 种动物中选择 1-2 个拍摄对象并沿着预定义的轨迹移动,背景从 20 个位置中随机选择,36 个摄像机同时记录拍摄对象的运动。渲染场景示例如下:

每个场景中的摄像机都放置在距离场景中心 3.5m - 9m 的半球形表面上。为了最小化渲染视频与真实世界视频的域偏移,研究者将每个摄像机的仰角限制在 0°- 45° 之间,方位角限制在 0°- 360° 之间。每个摄像头都在上述约束条件下随机采样,而不是在各个场景中使用相同的摄像头位置。上图显示了一个示例,其中红星表示场景的中心点(略高于地面),视频由同步相机渲染,以捕捉主要拍摄对象(在本例中是一只山羊和一只熊)的运动。
4. SynCamMaster 实验结果

上图中研究者将 SynCamMaster 与最先进的方法进行了比较。研究者使用 SynCamMaster 合成多视角图像(M.V. 图像)作为基线方法的参考图像(以蓝色框表示)。据观察,基线方法无法生成多视角同步视频。例如,蓝色巴士可能在一个镜头中停留在原地,在另一个镜头中向前移动。而 SynCamMaster 可以合成符合相机姿势和文本提示的视图对齐视频。更多结果请访问项目主页(https://jianhongbai.github.io/SynCamMaster)查看。
5. 总结
在本文中,研究者提出了 SynCamMaster ,一种基于文本和相机位姿的 “多视角同步” 视频生成模型,该模型可以根据用户提供的文字描述和相机位姿信息,生成符合文本描述的时序同步的多段不同视角视频。SynCamMaster 支持多种相机视角变化,例如改变相机方位角、俯仰角、距离远近等。此外、研究者还提供了多视角同步视频数据集 SynCamVideo-Dataset 用于多视角视频生成的研究。
精准控制视频中物体的 3D 轨迹 ——3DTrajMaster
除了多机位同步生成,虚拟拍摄的真正落地亟需精准的物体可控性。试想一下,如果我们可以精准控制视频中每个主体的 3D 时空位置,那么就可以拍摄出针对物体的定制化特效,进一步促进 AI 电影的进展。
可灵研究团队提出了 3DTrajMaster 的多物体 3D 位姿可控的视频生成模型。该方法通过逐主体相对应的 3D 轨迹控制视频生成中多个主体在 3D 空间中的运动,相比与传统在 2D 空间的表征 (边界框、点轨迹等) 是一种更本真的物体运动建模方式。这里的 3D 轨迹指可控制 6 个自由度,即控制主体的 3D 位置和朝向。

- 论文标题:3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
- 项目主页:http://fuxiao0719.github.io/projects/3dtrajmaster
- 代码:https://github.com/KwaiVGI/3DTrajMaster
- 论文:https://arxiv.org/pdf/2412.07759
1. 3DTrajMaster 性能展示
以下展示了 3DTrajMaster 的广泛特征:
(1) 泛化到多种主体:包括人、动物、机器人、飞机、汽车,甚至抽象的火焰、云雾等。
(2) 泛化到多样的背景:如下所示可以将一只考拉以相同的 3D 轨迹生成在城市、森林、沙漠、海滩、冰川、洞穴等不同的场景中。
(3) 生成复杂的 3D 轨迹:支持多个主体的 3D 遮挡、180 度 / 连续 90 度的转弯、大角度的变向、原地转圈等
(4) 精细化控制物体细节:可改变人的穿着、发型、身材、性别、佩戴等,也可以改变其它物体 (如动物、车) 的整体定性描述
2. 3DTrajMaster 方法介绍

3DTrajMaster 的训练涵盖两个阶段。首先,它通过训练 LoRA (具体为基模型的自注意力、跨注意力和线性映射层) 作为域自适应器来减轻训练数据集(通过 UE 引擎采集的运动轨迹 - 视频 pair)带来的负面影响。
其次,该方法选择了一种通用的方法在 2D 空间自注意力层之后插入 object injector 来插入成对的文本实体提示和 3D 轨迹。具体而言,实体通过文本编码器被投影到隐空间向量中,并利用可学习的位姿编码器投影成和 3D VAE 编码后对齐的位姿序列,然后与实体嵌入融合形成实体和轨迹的对应关系。这种对应关系嵌入与视频隐空间向量相连接,并被馈送到门控自注意力层进行进一步的运动融合。最后,修改后的隐向量返回到 DiT 块中的剩余层中。
在推理阶段,该方法将退火采样策略融入了 DDIM 采样:在较为初始的推理过程步骤中,主体和相对应的轨迹插入模型中以确定总体的多物体运动轨迹,而在后续阶段它们被舍弃,模型退回到最基础的文生视频过程。
3. UE 渲染的标注物体 6DoF 位姿的数据集合 360°-Motion

高质量的训练数据对于模型的训练至关重要,但是目前从通用的视频数据中标注物体的 6DoF 位姿数据非常困难:
- 较低的物体多样性和质量:高质量并成对的主体和轨迹大多受限于人和自动驾驶车辆,不同数据集在 3D 空间的分布差异非常大,而且主体可能过于冗余。在一些数据集中,人的分布占了大量的比重,会导致域外的主体泛化问题。
- 2低质量 / 失败的位姿估计:对于非刚性物体的运动 6D 物体,只有人通过 SMPL 模型被广泛地研究。目前仍然缺乏通用的 6DoF 位姿估计器。
为了解决这个问题,可灵研究团队通过 UE 平台构建了合成的 360°-Motion 数据集。如下图所示,团队首先收集了 70 个可驱动运动的人和动物 3D 资产,并进一步用 GPT-4V 给资产打上相应的文本标注。然后,研究团队采用了 GPT 生成复杂的多物体运动轨迹 (含 3D 位置和朝向,在 5×5 平方米的运动平台上),涵盖 96 个运动轨迹模版。其次,研究团队收集了 9 个 3D UE 平台 (涵盖城市、沙漠、森林和 5 个投影到 3D 空间的 HDRIs),并将 3D 资产与生成的 3D 轨迹组合放置在 UE 平台中。最后安置 12 个相机环绕拍摄多物体的运动,获得 54,000 组训练视频数据。
4. 3DTrajMaster 效果对比
相比 SOTA 的基准 Direct-a-Video、MotionCtrl、Tora 等,3DTrajMaster 可以在 3D 空间进一步控制物体的位置和朝向,同时它可以学到多主体和相对应的 3D 轨迹对应关系,而这是之前 2D 运动表征的方法普遍缺失的。当多物体在 3D 空间中存在运动的遮挡,这个难点会变得更加突出。
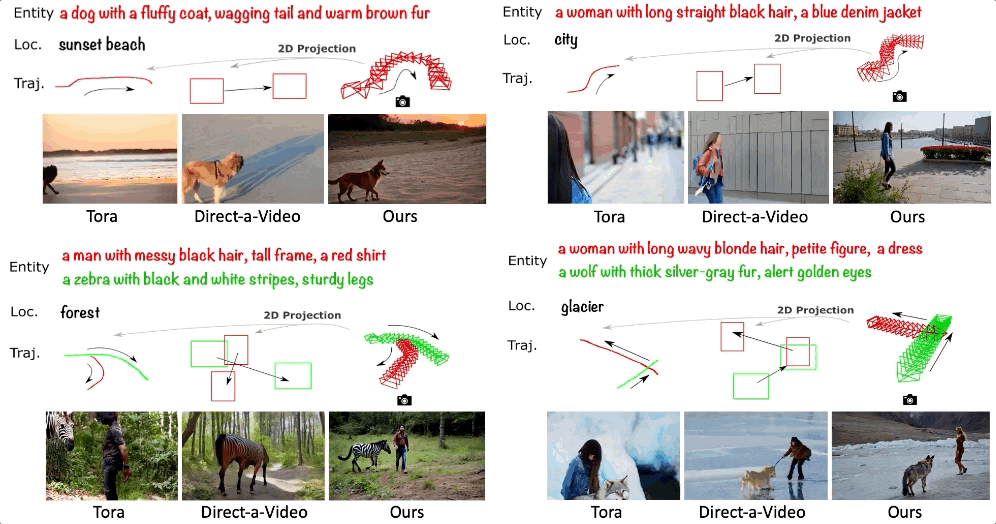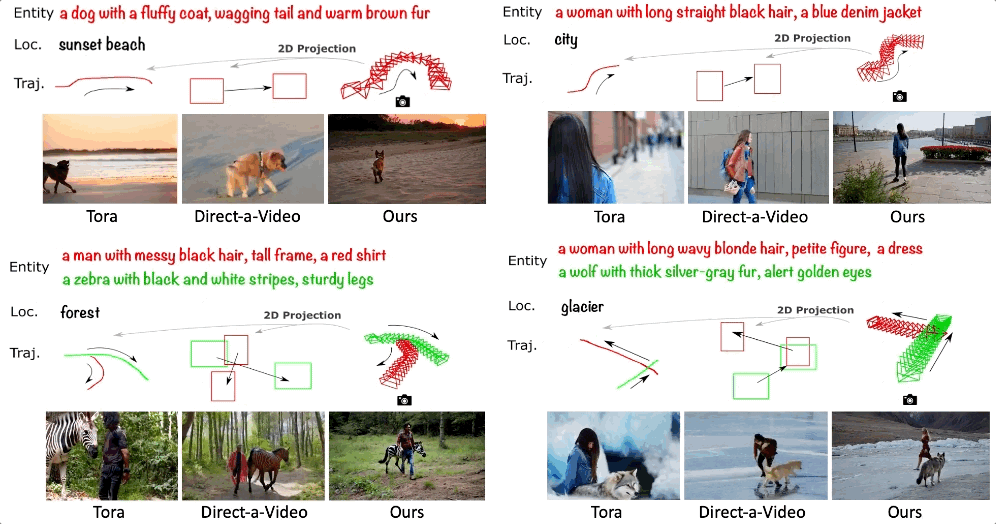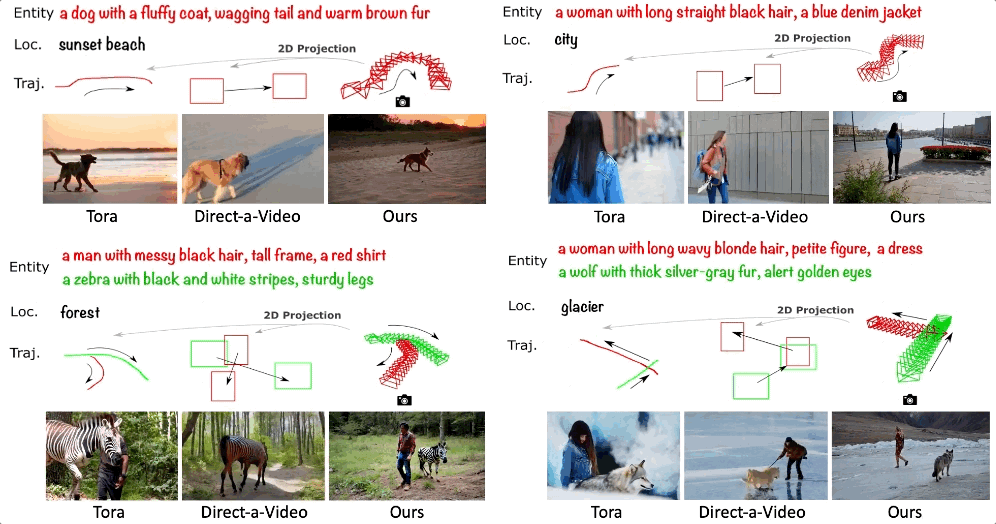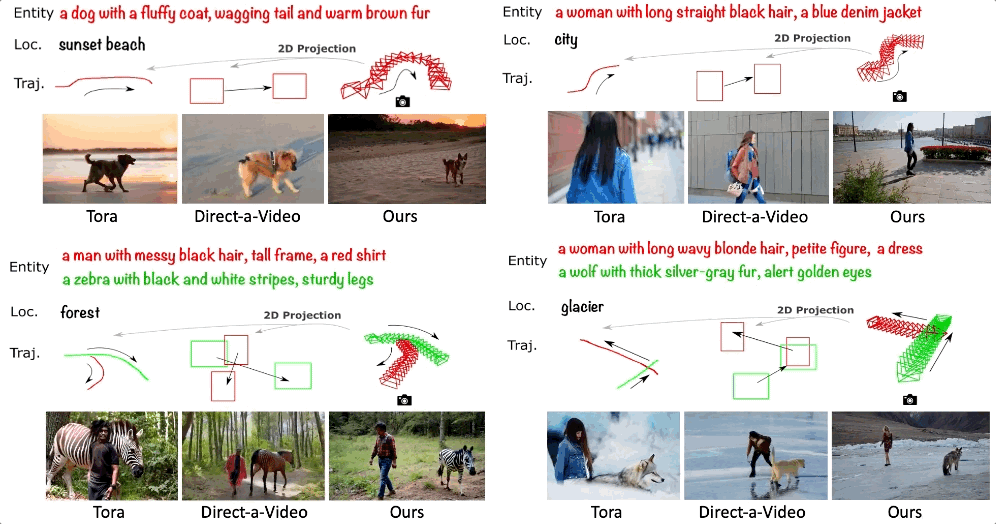
相比逐场景优化的 TC4D,3DTrajMaster 这种 feed-forward 的方法可以实现 700× 的提速,并且具有更高质量的现实画质和渲染更多样的背景。
5. 总结与未来展望
3DTrajMaster 展示了强大的视频生成和 3D 交互的可能性。在未来,更复杂的运动表征 (如人跳舞、挥舞手等局部运动,一个男人举起一只狗等交互运动) 也可以通过类似的 structured 运动表征进行建模,其中核心的是构建高质量的运动表征数据。同时,更加复杂的文本提示词输入和更多的主体输入也是可以进一步改进的点,这些都将为高质量可控的虚拟视频拍摄打下基础。
独特的视频艺术风格呈现 ——StyleMaster
创作者们不再满足于简单的视频生成,而是追求更具艺术性和个性化的创作表达。风格控制其能够赋予视频独特的艺术气质。然而,现有的视频风格化方法面临着两个主要挑战:难以准确提取和迁移参考图像的风格特征,以及在视频风格转换时出现时序不连贯、内容难以保持的问题,这严重限制了 AI 视频艺术创作的表现力。
StyleMaster,通过进一步提升参考图像中的风格和内容的解耦能力来提升生成视频中的风格准确度,引入内容控制模块以及运动提升模块来改善内容一致性与时序稳定性。
,时长00:41
- 论文标题:StyleMaster: Stylize Your Video with Artistic Generation and Translation
- 论文链接:https://arxiv.org/abs/2412.07744
- 项目主页:https://zixuan-ye.github.io/stylemaster/
- 代码仓库:https://github.com/KwaiVGI/StyleMaster
1. StyleMaster 效果展示
以下展示了 StyleMaster 的多方面性能。
视频风格迁移:给定任意源视频,StyleMaster 能在内容保持良好的前提下根据提供的风格参考图将其转换至对应风格。并且在时序上保持良好的一致性和流畅度。

风格化视频生成:给定文字 prompt 和风格图像,StyleMaster 能生成风格准确、文本对齐的高质量视频。并且,对于不同的 prompt 和风格图都具有良好的泛化性。
,时长00:05
相同风格,不同 prompt 效果:
相同 prompt,不同风格图效果:
图像风格迁移:与其他图像风格迁移方法相比,StyleMaster 能够更好地对齐参考图中的风格,例如使用诺贝尔获奖图风格对人物风格化时,StyleMaster 能更好地将图片转变为线条风,而不是保留过多细节,仅仅改变图像的颜色。

2. StyleMaster 方法介绍
自动化风格配对数据集构建


StyleMaster 提出创新解决方案来完成风格数据集的自动构建。通过 model illusion(模型幻觉)技术,预训练的文生图模型可自动生成配对数据。具体通过预定义的物体列表和风格描述列表,随机选择风格和物体生成配对图像。由于生成的配对图像本质是像素重排,能完美保证风格一致性,且完全自动化。

双重特征提取机制
- 全局风格提取:基于对比学习与幻觉数据集的提取器。使用 CLIP 提取初始图像特征,通过 MLP 投影层转换为全局风格表示。采用三元组损失函数训练,将同对图像作为正样本,其他图像作为负样本。
- 局部纹理保持:提取 CLIP patch 特征,通过计算与文本提示的相似度,选择相似度较低的 patch 作为纹理特征。通过 Q-Former 结构处理,更新查询 token 并整合特征,既保留局部纹理信息,又避免内容泄露。
优化与控制
- 动态质量优化:使用 MotionAdapter 的时序注意力模块,通过调节 α 参数控制动态效果。α=0 保持原始效果,α=1 生成静态视频,α=-1 增强动态范围。
- 精确内容控制:采用 gray tile ControlNet 设计,移除颜色信息避免对风格迁移的干扰。复制一半 vanilla DiT 块作为控制层,与风格 DiT 模块特征相加,确保内容和风格平衡。
交互式视频游戏生成 ——GameFactory
视频模型在视频生成和物理模拟中的潜力使其成为未来游戏引擎的有力候选者。AI 驱动的引擎能够通过自动化生成游戏内容,显著减少传统开发中的工作量。然而,现有研究多局限于过拟合特定游戏(如《DOOM》、《Minecraft》、《Super Mario Bros》等),限制了模型创建全新游戏场景的能力,同时高昂的动作标注数据成本进一步增加了实现泛化的难度。因此,提升场景泛化能力成为生成式游戏引擎发展的关键方向。
为解决这一挑战,可灵研究团队提出了 GameFactory 框架。通过结合少量 Minecraft 的高质量动作标注数据与预训练视频生成模型,GameFactory 探索了一条基于在开放域非标注视频数据上预训练的经济可行路径。
该方法能够将从小规模标注数据集中学习到的物理控制知识泛化到开放域场景,不仅显著提升了场景泛化能力,还为解决xx智能、自动驾驶等复杂领域的问题带来了更多可能。
其核心创新包括多阶段解耦训练策略,将游戏风格学习与动作控制学习分离,避免生成内容受特定风格限制;自回归生成机制,支持无限长的动作可控视频生成,满足持续游戏的实际需求;以及开源高质量数据集 GF-Minecraft,有效克服传统标注数据中的人类偏差,为未来的研究提供了坚实基础。
,时长01:14
- 论文标题:GameFactory: Creating New Games with Generative Interactive Videos
- 项目主页:https://vvictoryuki.github.io/gamefactory
- 代码:https://github.com/KwaiVGI/GameFactory
- 论文:https://arxiv.org/abs/2501.08325
- GF-Minecraft 训练数据集: https://huggingface.co/datasets/KwaiVGI/GameFactory-Dataset
1. GameFactory 效果展示
以下展示 GameFactory 的效果:
(1)开放域的可控游戏视频生成能力。如下所示,利用预训练视频大模型的强大生成先验,GameFactory 将能够生成训练时没有见过的游戏场景,并泛化游戏动作的控制能力。
,时长00:05
(2)无限长可控游戏视频的生成能力。如下所示,展示了 GameFactory 通过自回归的方式生成几十秒可控游戏长视频的效果。
,时长00:21
2. GameFactory 方法介绍
下图展示了 GameFactory 的设计思想,如何利用预训练的大型视频生成模型与动作控制模块生成新游戏。蓝色上半部分展示了通过海量无标注开放领域数据预训练的大型视频生成模型,具备强大的开放领域视频生成能力,提供丰富的生成基础;绿色下半部分则展示了从少量标注的游戏动作数据中训练出的动作控制模块如何与预训练模型结合,生成受动作控制的动态内容。通过将两者有机结合,GameFactory 能够实现从视频生成到动作控制的泛化,最终支持创建新游戏及其他受控场景的开发。

下图展示的是动作控制模块,其是视频生成模型实现互动性的关键设计。
如图中(a)部分所示,通过与 Transformer 结构的深度结合,让模型具备响应用户输入的能力。如图中(b)部分所示,模块针对连续的鼠标信号和离散的键盘指令设计了不同的处理机制。此外如图(c)中所示,模块引入了动作分组机制,解决了动作信号与潜在特征在时间粒度上的不匹配问题,同时设计了了滑动窗口机制捕捉延迟动作对多帧画面的影响。
通过这一架构,视频生成模型不仅能生成高质量内容,还能动态响应用户指令,为互动式视频和游戏生成带来新的可能。

下图展示了一个分阶段的训练策略,旨在实现动作控制与开放领域内容生成的有效结合。
- Phase #0 通过在开放领域数据上预训练视频生成模型,为模型提供可泛化的生成能力;
- Phase #1 使用游戏数据进行 LoRA 微调,学习特定的游戏风格;
- Phase #2 在固定模型其他部分的情况下,训练动作控制模块,实现与风格无关的动作响应能力;
- Phase #3 通过推理结合动作控制模块和预训练模型,生成受动作信号控制的开放领域视频内容。
这种设计将风格学习与动作控制分离,不仅保留了开放领域的生成能力,还通过动作控制模块实现了场景泛化和用户指令的响应,充分展示了模型的灵活性和适应性。

下图展示了自回归视频生成的过程,包括训练阶段和推理阶段。在训练阶段(左图),模型使用前面若干帧作为条件帧,预测后续的帧。条件帧的数量是随机选定的,损失函数专注于预测噪声帧的部分,从而优化模型的生成能力。在推理阶段(右图),模型通过自回归的方式逐帧生成视频内容,每次使用历史视频的潜在特征作为条件,逐步生成新的帧。这样的设计保证了训练时的多样性和推理时生成内容的连贯性,能够生成高质量、动态一致的视频内容。

3. GF-Minecraft 数据集
GF-Minecraft 数据集的设计充分考虑了动作可控视频生成的核心需求,具有以下显著特点。
首先,数据集通过可自定义的动作序列实现了低成本的大规模数据采集,同时确保动作序列具有随机性和多样性,从而覆盖了低概率但关键的动作组合。
其次,Minecraft 平台的多样化开放世界环境以及丰富的动作空间为捕捉场景物理动态提供了理想条件。
为了增强多样性,数据采集预设了三种生物群落(森林、平原、沙漠)、三种天气状态(晴天、下雨、雷暴)和六种时间段(如日出、正午、午夜),生成了超过 2,000 个视频片段,每个片段包含 2,000 帧,并配有由 MiniCPM-V 多模态语言模型生成的文本描述。这些设计使得该数据集能够有效支持动作可控和场景泛化的视频生成模型训练,尤其在多样性和场景描述的精细度上提供了极大优势。下面是一个数据标注的示例:

4. 未来展望
展望未来,可灵研究团队提出的 GameFactory 不仅是一个用于创建新游戏的工具,更是一个具有广泛应用潜力的通用世界模型。该模型能够将从小规模标注数据集中学到的物理知识泛化到开放领域场景,解决包括自动驾驶和xx智能等领域中的关键挑战,这些领域同样面临缺乏大规模动作标注数据集的问题。
在本文中,研究团队通过 GameFactory 提出了一种利用生成式交互视频来创建新游戏的框架,填补了现有研究在场景泛化能力上的重要空白。然而,生成式游戏引擎的研究仍面临诸多挑战,例如关卡和玩法的多样性设计、玩家反馈系统、游戏内对象的操控、长上下文记忆,以及实时游戏生成等复杂问题。GameFactory 是可灵在这一领域迈出的第一步,未来将继续努力,向实现一个全面的生成式游戏引擎目标迈进。
结语
视频生成本身时空建模难度高,准确体现用户意图在视频中是一项巨大的挑战,这些挑战导致视频生成的 “抽卡率” 较高。为了应对这些问题,核心思路是通过多模态的用户意图输入来提升视频生成的可控性和精确性。可灵在三维空间控制(SynCamMaster)、运动轨迹控制(3DTrajMaster)和内容风格控制(StyleMaster)三个方向上进行了具有代表性的探索。此外,通过多轮次的多模态用户意图交互(GameFactory),展示了视频生成技术在游戏创作等领域的广阔应用前景。这些技术通过更好地理解和整合多模态用户意图来降低视频生成的 “抽卡率”。
可灵正在用技术创新推动着视频生成领域走向更远的未来。在这个充满无限可能的领域,期待看到更多令人欣喜的发展,让 AI 创作的边界不断拓展,让创作者能够更自由地表达他们的想象力;让视频生成能够为更多领域带来新探索的可能性。
欢迎大家在可灵 AI 平台体验最新最强的视频生成技术:https://klingai.kuaishou.com/。欢迎大家关注可灵 AI 研究的最新进展,一起思考、探索视频生成的新前景。xxxxxxxxxxx,共同创造未来的视频生成!
....
#回顾 LLM 领域的一些热词
本文回顾了2024年LLM领域的一些热门词汇和相关技术,包括MoE、Agent/Agentic、Sora、GraphRAG、GPT-4o、o1、ORM、PRM、Self-Play、Self-Rewarding等,并对其背景、应用及未来趋势进行了简要分析和调侃,展现了这些技术在LLM发展中的作用和影响。
以下热词并不局限于24年,也没有囊括完24年,看看有没有你很眼熟的呢[ MoE,Agent/Agentic,Sora,GraphRAG,GPT-4o,o1,ORM,PRM,test-time compute,Inference Scaling Laws,MCTS,Self-Play,Self-Rewarding,RFT,PPO,DPO,GRPO ......]
叠下甲:
“中文”字段取最常见的中文叫法,若没有就是硬翻;
“相关”字段为其相关的同类,不一定全;
“出处”取互联网搜到的,不一定准;
“胡侃”字段权当看个乐子,一家之言;
欢迎评论区给出意见,接下来开始
MoE
全称:Mixture-of-Experts
中文:混合专家(模型)
出处:最早这个概念是 Hinton 老爷子在1991年发表的《Adaptive Mixtures of Local Experts》[1] 中提出,然后在23年3月 GPT-4 发布后火了一把,因为黑客的小道消息传其使用了 MoE 架构,之后23年12月 Mistral AI 发布了首个开源的 MoE 架构模型 Mixtral-8x7B [2],接着24年1月 DeepSeek 发布了国内首个开源的 MoE 架构模型 DeepSeekMoE [3]。
胡侃:2024年模型上以 DeepSeekMoE 开头,以为 MoE 架构会在24年大放异彩,但中途被 o1 截胡,不过在年尾 DeepSeek-V3 [4] 还是挽了下 MoE 的尊。但是 V3 这么大,下载量截止目前已经有155K [5] 了,大家都这么富裕了吗?
Agentic
中文:智能体化
出处:说 Agentic 肯定要先说 Agent,这个词很早就有了,但在 LLM 领域最早认为是 OpenAI 在23年6月的一篇博客中《LLM Powered Autonomous Agents》[6] 对 LLM 中的 Agent 进行了一个较为综合的定义,之后 OpenAI 在23年12月份发布的《Practices for Governing Agentic AI Systems》 [7] 提到了 Agentic 这个词。
胡侃:2024 应用上以 Agent/Agentic 开头,以为24年将会遍地开花,但在24年的结尾来看水花不大,不过 Anthropic 在24年结尾的 《Building effective agents》[8] 写的真实在。目前大家的 Agent 大部分本质就是 Workflow + Prompt,但汇报还是得用“Agent”讲故事。
Sora
出处:24年2月OpenAI发布的视频生成模型。
相关:24年6月快手可灵,7月智谱清影,8月 MiniMax video-01,9月字节 PixelDance 和 Seaweed 。
胡侃:24年尾巴上了,终于可以掏钱体验 Sora 了,体验之后发现和年初吹的牛皮差的有点距离呀!
GraphRAG
中文:图检索增强生成
出处:微软在24年4月于《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》[9] 中提出。
相关:RAG 这个概念最早是由 Meta 在20年于《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》[10]中提出,目前各种 RAG 层出不穷,不在此叙述了。
胡侃:当前 RAG 已经成为了一种解决 LLM 知识时效性差、幻觉、领域专业性欠缺等问题的范式,24年 RAG 方向的工作依然很火热,毕竟能真实应用落地,LLM 落地的一根大拐杖。但 Graph 的方式是不是 RAG 的正确打开方式呢?
GPT-4o
出处:24年5月 OpenAI 发布的多模态模型。
相关:24年7月阶跃 Step-1.5V,9月 Meta Llama 3.2 ,9月 Mistral AI Pixtral 12B,10月阿里 Qwen2-VL,10月百川 Baichuan-Omni。
胡侃:4o 三模端到端,但24年来看多模态依然前路漫漫,未来的 AGI 一定是多模态的,但现在的 AGI 还是文本的。
o1
出处:24年9月 OpenAI 发布的推理模型。
相关:24年11月阿里 QwQ-32B-Preview,11月 DeepSeek-R1-Lite,11月月暗 k0-math,12月智谱 GLM-Zero-Preview
胡侃:2024 真神降临!
接下来是和 o1 相关的热词,毕竟下半年大家都在研究 o1
ORM;PRM
全称:Outcome-supervised Reward Model;Process-supervised Reward Model
中文:结果监督奖励模型;过程监督奖励模型
出处:早在23年5月 OpenAI 的《Let's Verify Step by Step》[11]就提出了。
胡侃:o1 横空出世后,大家都在解密他,PRM 应该是其核心的一个方法,大家开始训 PRM 了,但 OpenAI 有800K 的标注数据,虽然开源了,但没开源的有多少呢?
train-time compute;test-time compute
中文:训练时计算量;测试时计算量
出处:24年9月份 OpenAI 的《Learning to reason with LLMs》[12] 博客中提到。
胡侃:结合原文看
We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute)
时间长才会真的强。
Inference Scaling Laws/Test-Time Scaling
中文:推理扩展定律
出处:o1 发布后, Scaling Laws 的推理版本,准确的出处说不太清,这篇 Paper 实验做的不错《Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for LLM Problem-Solving》[13]
胡侃:开启一个新的阶段,老黄这张图不错
三个阶段
MCTS
全称:Monte Carlo Tree Search
中文:蒙特卡洛树搜索
出处:最早是 2006 年的《Bandit based Monte - Carlo Planning》[14] 提出
胡侃:o1 到底用没用?
猜测的 o1 推理范式:SA,MR,DC,SR,CI,EC
全称中文:
系统分析Systematic Analysis(SA)
方法重用Method Reuse(MR)
分而治之Divide and Conquer(DC)
自我改进Self-Refinement(SR)
上下文识别Context Identification (CI)
强化约束Emphasizing Constraints(EC)
出处:一篇研究 o1 的 Paper 猜测的 o1 推理范式 《 A COMPARATIVE STUDY ON REASONING PATTERNS OF OPENAI’S O1 MODEL》[15]
胡侃:你 Close 你的,我研究我的。
接下来是几个"self"
Self-Play
中文:自博弈
出处:第一次热是2016年AlphaGo大战李世石后,这次随着 o1 又热了起来,Self-Play 本身是正统RL里面的一个概念,24年8月份这篇综述不错《A Survey on Self-play Methods in Reinforcement Learning》[16]
胡侃:NLP 出身搞 LLM 的,接受正统 RL 的洗礼吧,下面缺一个卖 RL 课的广告...
Self-Rewarding
中文:自我奖励
出处:24年1月 Meta 在《Self-Rewarding Language Models》[17] 提到。
胡侃:就是不用人工来标数据了,让 LLM-as-a-Judge,但是感觉路漫漫。
Self-Correct/Correction
中文:自我纠错
出处:这个概念 LLM 出现后就有了,结合 RL 的24年9月 DeepMind 在《Training Language Models to Self-Correct via Reinforcement Learning》中提到[18]
胡侃:在o1发布的8天后, DeepMind 甩出了这篇 Paper,但声量似乎有点少。
Self-Refine
中文:自我优化
出处:一般指23年3月卡内基梅隆大学的这篇《Self-refine: Iterative refinement with self-feedback》[19]
胡侃:成为了众多 Paper 中的一个 Baseline。
Self-Reflection
中文:自我反思
出处:这个提到的比较多,贴几篇不错的
《Self-Reflection in LLM Agents: Effects on Problem-Solving Performance》[20];
《Self-RAG: Learning to Retrieve, Generate and Critique through Self-Reflection》[21];
《Towards Mitigating Hallucination in Large Language Models via Self-Reflection》[22]
胡侃:什么是人类的反思,什么是 LLM 的反思?
Self-Consistency
中文:自我一致性
出处:一般指23年Google的这篇《Self-Consistency Improves Chain of Thought Reasoning in Language Models》[23]
胡侃:期待更多实用的 ”self“,毕竟人类喜欢低耗能的事情,不喜欢自己动(洗数据)
RFT
全称:Reinforcement Fine-Tuning
中文:强化微调
出处:OpenAI 的 12 Days 第二天直播提出的,这是直播的视频[24],这是申请单[25]。
注意和字节 ReFT 的区别(所以到底有区别吗),OpenAI 的官方简称是RFT
Today, we're excited to introduce a new way of model customization for our O1 series: reinforcement fine-tuning, or RFT for short.
ReFT
全称:Reinforced Fine-Tuning
中文:强化微调
出处:24年1月字节在《ReFT: Reasoning with Reinforced Fine-Tuning》[26]提出
胡侃:从 OpenAI 目前披露出的消息,应该和字节的 ReFT 原理差的不是特别多,不过 OpenAI 概念的神,PPO~RFT,Reward Model ~ Verifier。但如果在专业领域,答案固定且 Verifier 也比较好定义的任务上,真的需要 “dozens of data” 就能够非常有效的话,想想还是挺期待的。不要再像 Sora 一样拖到 25 年底才能体验吧...
下面是几个"O"
PPO
全称:Proximal Policy Optimization
中文:近端策略优化
出处:2017年 OpenAI 在这篇《Proximal Policy Optimization Algorithms》[27]提出。
胡侃:以下 O 的老祖宗。
DPO
全称:Direct Preference Optimization
中文:直接偏好优化
出处:23年斯坦福在这篇《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》[28]提出。
胡侃:你的出现让中小作坊大喜!
GRPO
全称:Group Relative Policy Optimization
出处:DeepSeek 在24年2月《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》[29] 中提出。
胡侃:优雅实用高效
几个比较常见且已经有实现的"O"
ORPO
全称:Odds Ratio Preference Optimization
出处:KAIST AI 在24年3月份《ORPO: Monolithic Preference Optimization without Reference Model》[30]提出。
KTO
全称:Kahneman-Tversky Optimization
出处:24年2月份的《KTO: Model Alignment as Prospect Theoretic Optimization》[31] 提出
SimPO
全称:Simple Preference Optimization
出处:24年5月份的《SimPO: Simple Preference Optimization with a Reference-Free Reward》[32]提出
RLOO
全称:Reinforce Leave-One-Out
出处:Cohere For AI 在24年2月份的《Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs》[3] 提出
2024 结束,2025 的 GPT-5 ,o3 又将会掀起什么大风大浪呢?风浪越大鱼越贵!
参考
- https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf
- https://arxiv.org/pdf/2401.04088
- https://arxiv.org/pdf/2401.06066
- https://arxiv.org/pdf/2412.19437
- https://huggingface.co/deepseek-ai/DeepSeek-V3
- https://lilianweng.github.io/posts/2023-06-23-agent/
- https://cdn.openai.com/papers/practices-for-governing-agentic-ai-systems.pdf
- https://www.anthropic.com/research/building-effective-agents
- https://arxiv.org/pdf/2404.16130
- https://arxiv.org/abs/2005.11401
- https://arxiv.org/pdf/2305.20050
- https://openai.com/index/learning-to-reason-with-llms/
- https://arxiv.org/pdf/2408.00724
- http://ggp.stanford.edu/readings/uct.pdf
- https://arxiv.org/pdf/2410.13639
- https://arxiv.org/pdf/2408.01072
- https://arxiv.org/pdf/2401.10020
- https://arxiv.org/pdf/2409.12917
- https://arxiv.org/pdf/2303.17651
- https://arxiv.org/pdf/2405.06682
- https://arxiv.org/pdf/2310.11511
- https://arxiv.org/pdf/2310.06271
- https://arxiv.org/pdf/2203.11171
- https://www.youtube.com/watch?v=yCIYS9fx56U
- https://openai.com/form/rft-research-program/
- https://arxiv.org/pdf/2401.08967
- https://arxiv.org/pdf/1707.06347
- https://arxiv.org/pdf/2305.18290
- https://arxiv.org/pdf/2402.03300
- https://arxiv.org/pdf/2403.07691
- https://arxiv.org/pdf/2402.01306
- https://arxiv.org/pdf/2405.14734
- https://arxiv.org/pdf/2402.14740
....
#大模型LLM-微调经验分享&总结
本文总结了作者在ChatGLM-6B模型微调的经验,并汇总了目前开源项目&数据。
大型语言模型横行,之前非常焦虑,现在全面拥抱。目前也有很多开源项目进行大模型微调等,笔者也做了一阵子大模型了,特此来介绍一下ChatGLM-6B模型微调经验,并汇总了一下目前开源项目&数据。笔者与很多人微调结论不同,本人在采用单指令上进行模型微调,发现模型微调之后,「并没有出现灾难性遗忘现象」。
项目地址:https://github.com/liucongg/ChatGLM-Finetuning
ChatGLM-6B模型微调
模型越大对显卡的要求越高,目前主流对大模型进行微调方法有三种:Freeze方法、P-Tuning方法和Lora方法。笔者也通过这三种方法,在信息抽取任务上,对ChatGLM-6B大模型进行模型微调。为了防止大模型的数据泄露,采用一个领域比赛数据集-汽车工业故障模式关系抽取(https://www.datafountain.cn/competitions/584),随机抽取50条作为测试集。
详细代码见上面的GitHub链接,并且也被ChatGLM官方收录。
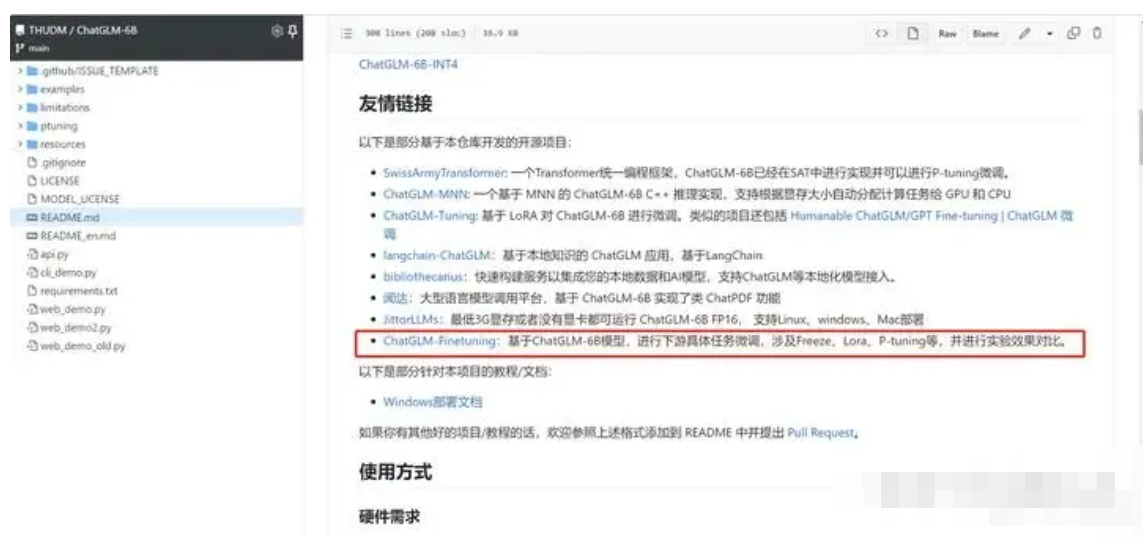
Freeze方法
Freeze方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行TP或PP操作,就可以对大模型进行训练。
微调代码,见finetuning_freeze.py,核心部分如下:
for name, param in model.named_parameters():
if not any(nd in name for nd in ["layers.27", "layers.26", "layers.25", "layers.24", "layers.23"]):
param.requires_grad = False针对模型不同层进行修改,可以自行修改。训练代码均采用DeepSpeed进行训练,可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text等,可根据自己的任务配置。
CUDA_VISIBLE_DEVICES=0 deepspeed finetuning_freeze.py --num_train_epochs 5 --train_batch_size 2三元组抽取的推理代码,见predict_freeze.py,其他任务可以根据自己的评价标准进行推理预测。
PT方法
PT方法,即P-Tuning方法,参考ChatGLM官方代码(https://github.com/THUDM/ChatGLM-6B/blob/main/ptuning/README.md) ,是一种针对于大模型的soft-prompt方法。
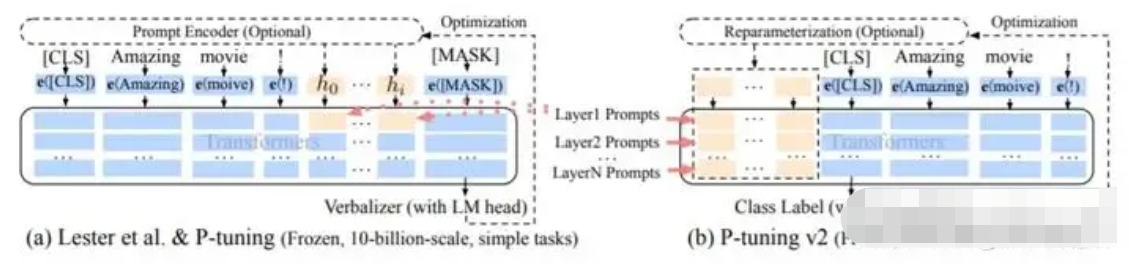
- P-Tuning(https://arxiv.org/abs/2103.10385),仅对大模型的Embedding加入新的参数。
- P-Tuning-V2(https://arxiv.org/abs/2110.07602),将大模型的Embedding和每一层前都加上新的参数。
微调代码,见finetuning_pt.py,核心部分如下:
config = ChatGLMConfig.from_pretrained(args.model_dir)
config.pre_seq_len = args.pre_seq_len
config.prefix_projection = args.prefix_projection
model = ChatGLMForConditionalGeneration.from_pretrained(args.model_dir, cnotallow=config)
for name, param in model.named_parameters():
if not any(nd in name for nd in ["prefix_encoder"]):
param.requires_grad = False当prefix_projection为True时,为P-Tuning-V2方法,在大模型的Embedding和每一层前都加上新的参数;为False时,为P-Tuning方法,仅在大模型的Embedding上新的参数。
可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text、pre_seq_len、prompt_text等, 可根据自己的任务配置。
CUDA_VISIBLE_DEVICES=0 deepspeed finetuning_pt.py --num_train_epochs 5 --train_batch_size 2 --pre_seq_len 16三元组抽取的推理代码,见predict_pt.py,其他任务可以根据自己的评价标准进行推理预测。
Lora方法
Lora方法,即在大型语言模型上对指定参数增加额外的低秩矩阵,并在模型训练过程中,仅训练而外增加的参数。当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量很小,达到仅训练很小的参数,就能获取较好的结果。
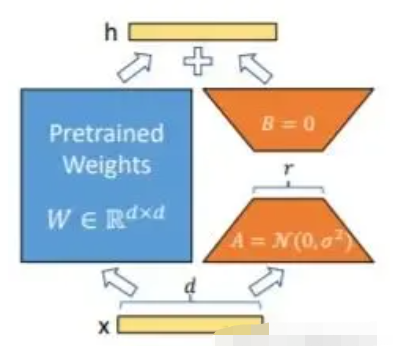
- Lora论文:https://arxiv.org/abs/2106.09685
- 官方代码:https://github.com/microsoft/LoRA
- HuggingFace封装的peft库:https://github.com/huggingface/peft
微调代码,见finetuning_lora.py,核心部分如下:
model = ChatGLMForConditionalGeneration.from_pretrained(args.model_dir)
config = LoraConfig(r=args.lora_r,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
inference_mode=False,
)
model = get_peft_model(model, config)可设置参数包含train_path、model_dir、num_train_epochs、train_batch_size、gradient_accumulation_steps、output_dir、prompt_text、lora_r等,可根据自己的任务配置。
CUDA_VISIBLE_DEVICES=0 deepspeed finetuning_lora.py --num_train_epochs 5 --train_batch_size 2 --lora_r 8三元组抽取的推理代码,见predict_lora.py,其他任务可以根据自己的评价标准进行推理预测。
注意:对于结果需要保持一致的任务(即关掉dropout,解码关掉do_sample),需要保存模型的adapter_config.json文件中,inference_mode参数修改成false,并将模型执行model.eval()操作。主要原因是chatglm模型代码中,没有采用Conv1D函数。
三元组抽取实验结果
- 模型训练时,最大长度为768,Batch大小为2,训练轮数为5,fp16训练,采用DeepSpeed的Zero-1训练;
- PT为官方的P-Tuning V2训练方法,PT-Only-Embedding表示仅对Embedding进行soft-prompt,Freeze仅训练模型后五层参数,Lora采用低秩矩阵方法训练,秩为8;
- 由于之前训练PT在48G-A40显卡上会出现OOM,因此之前进行PT实验时对模型开启了gradient_checkpointing_enable,使得模型显存占用变小,但训练时长增加。
- 训练示例:
prompt_text:你现在是一个信息抽取模型,请你帮我抽取出关系内容为\"性能故障\", \"部件故障\", \"组成\"和 \"检测工具\"的相关三元组,三元组内部用\"_\"连接,三元组之间用\\n分割。文本:
输入:故障现象:发动机水温高,风扇始终是低速转动,高速档不工作,开空调尤其如此。
输出:发动机_部件故障_水温高\n风扇_部件故障_低速转动时间换空间,可用很好的解决显卡的资源问题,简单玩玩还可以,如果想要模型达到最优效果或可用快速看到效果,还不如租张A100卡,快速实验,推理阶段再用自己的小破卡。
笔者找到一家新的算力平台-揽睿星舟,单张A100仅要6.4元/小时,我翻了一圈,算是便宜的了(反正比AutoDL便宜一点,便宜一点是一点吧)。
下面实验结果均是在租的80G-A100上进行的实验,与Github里用的A40的实验结果会有些差异,主要在训练时长(纯训练速度,剔除模型保存的时间)。说实话,真的要训练一个大模型,多个A100是必不可少的,可以减少很多模型并行的操作,效果上也更好把控一些。
|
微调方法 |
PT-Only-Embedding |
PT |
Freeze |
Lora |
|
显卡占用 |
37G |
56G |
24G |
39G |
|
总参数 |
6.259B |
7.211B |
6.255B |
6.259B |
|
可训练参数占比 |
0.0586% |
13.26% |
16.10% |
0.0586% |
|
训练耗时 |
20min |
52min |
46min |
25min |
|
测试结果F1 |
0.0 |
0.6283 |
0.5675 |
0.5359 |
结果分析:
- 效果为PT>Freeze>Lora>PT-Only-Embedding;
- 速度为PT-Only-Embedding>Lora>Freeze>PT;
- PT-Only-Embedding效果很不理想,发现在训练时,最后的loss仅能收敛到2.几,而其他机制可以收敛到0.几。分析原因为,输出内容形式与原有语言模型任务相差很大,仅增加额外Embedding参数,不足以改变复杂的下游任务;
- PT方法占用显存更大,因为也增加了很多而外参数;
- 测试耗时,采用float16进行模型推理,由于其他方法均增加了额外参数,因此其他方法的推理耗时会比Freeze方法要高。当然由于是生成模型,所以生成的长度也会影响耗时;
- 模型在指定任务上微调之后,并没有丧失原有能力,例如生成“帮我写个快排算法”,依然可以生成-快排代码;
- 由于大模型微调都采用大量instruction进行模型训练,仅采用单一的指令进行微调时,对原来其他的指令影响不大,因此并没导致原来模型的能力丧失;
- 上面测试仅代表个人测试结果。
很多同学在微调后出现了灾难性遗忘现象,但我这边并没有出现,对“翻译任务”、“代码任务”、“问答任务”进行测试,采用freeze模型,可以用test_forgetting.py进行测试,具体测试效果如下:
- 翻译任务

- 代码任务

- 问答任务

后面会把生成任务、分类任务做完,请持续关注Github,会定期更新。(太忙了,会抓紧时间更新,并且官方代码也在持续更新,如遇到代码代码调不通的情况,请及时联系我,我在github也给出了我的代码版本和模型版本)
中文开源大模型&项目
虽然出来很多大模型,但Open的&中文可直接使用的并不多,下面对中文开源大模型、数据集和项目进行一下汇总。
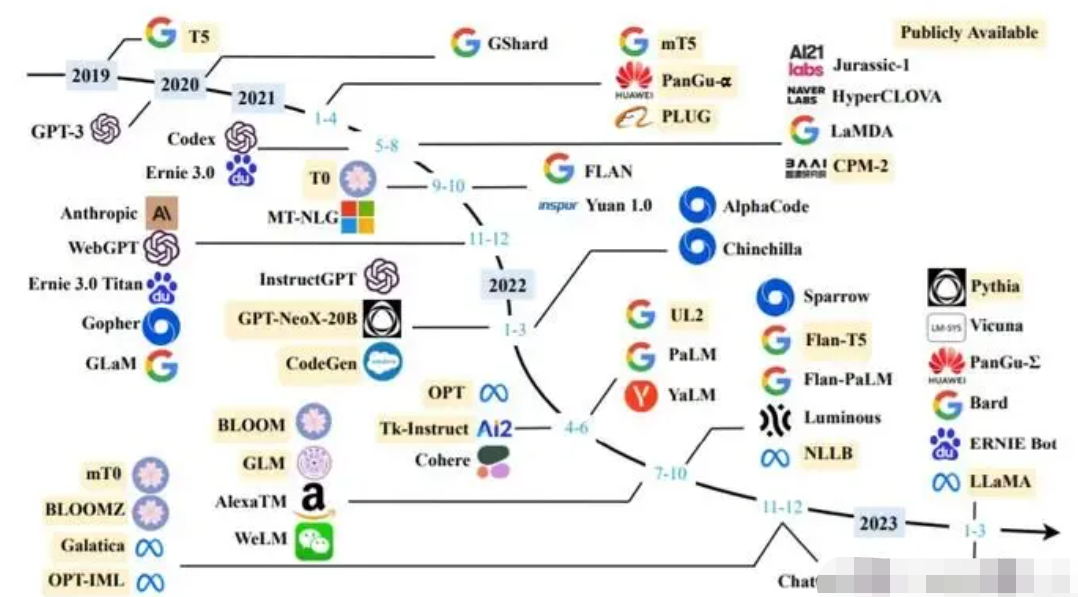
中文开源大模型
直接可微调,无需指令增量训练:
- ChatGLM-6B:https://huggingface.co/THUDM/chatglm-6b
- ChatYuan-large-v2:https://huggingface.co/ClueAI/ChatYuan-large-v2
原始模型多语言or英文,需要中文指令数据集增量训练:
- BloomZ:https://huggingface.co/bigscience/bloomz
- LLama:https://github.com/facebookresearch/llama
- Flan-T5:https://huggingface.co/google/flan-t5-xxl
- OPT:https://huggingface.co/facebook/opt-66b
中文开源指令数据
下面中文指令集,大多数从Alpaca翻译而来,请看下面项目中data目录。目前通过ChatGPT或者GPT4作为廉价标注工为自己的数据进行数据标注一个不错的思路。
- [1]:https://github.com/LC1332/Chinese-alpaca-lora
- [2]:https://github.com/hikariming/alpaca_chinese_dataset
- [3]:https://github.com/carbonz0/alpaca-chinese-dataset
- [4]:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
- [5]:https://github.com/LianjiaTech/BELLE
- [6]:https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
开源项目
总结下面较火的开源项目:
- BELLE:https://github.com/LianjiaTech/BELLE
- ChatGLM:https://github.com/THUDM/ChatGLM-6B
- Luotuo-Chinese-LLM:https://github.com/LC1332/Luotuo-Chinese-LLM
- stanford_alpaca:https://github.com/tatsu-lab/stanford_alpaca
总结
目前各大厂的大模型陆陆续续放出,堪称百家争鸣!个人玩家也是全面拥抱,想尽一切办法来训练微调大模型。只愿大家以后可以实现“大模型”自由。愿再无“model-as-a-service”。
....
#多重可控插帧视频生成编辑
Adobe这个大一统模型做到了,效果惊艳
本文一作 Maham Tanveer 是 Simon Fraser University 的在读博士生,主要研究方向为艺术视觉生成和创作,此前在 ICCV 发表过艺术字体的生成工作。师从 Hao (Richard) Zhang, IEEE Fellow, Distinguished Professor, 并担任 SIGGRAPH 2025 Paper Chair. 本文尾作 Nanxuan (Cherry) Zhao 在 Adobe Research 担任 Research Scientist, 研究方向为多模态可控生成和编辑,有丰富的交叉方向研究经历(图形学 + 图像 + 人机交互),致力于开发可以让用户更高效进行设计创作的算法和工具。
继 Firefly 视频大模型公布后,Adobe 的研究者在如何更好的控制视频的生成和编辑进行了更深入的研究。近日,Adobe 提出了一个统一模型,除了传统的根据图片生成动画的功能(image animation)外,同时支持各种模态的控制,包括关键帧 (keyframes)、运动轨迹 (sparse trajectory)、掩码(mask)、引导像素(guiding pixels)、文本等。
,时长00:04
论文中的 demo 让人眼前一亮,下面一起来看看模型的效果:
1. 运动轨迹 (sparse trajectory)

通过提供简单的轨迹笔画,小熊栩栩如生地动起来了。
2. 掩码(Mask)

MotionBridge 不仅可以控制物体的运动,如图所示,将简单的运动笔画和 mask 结合起来,模型也可以轻松控制镜头视角。

如上所示的 mask 描绘了变动(dynamic)区域,同样 mask 也可以指定不动的(static,红色)区域。描绘出整座桃林围着城堡旋转的景象。

让我们看看同样的图像和运动轨迹,不同 mask 作用下的结果吧。
3. 引导像素 (guiding pixels)
通过将想要的像素区域粘贴在指定帧的指定位置,就可以进行更精准的像素控制。如:船在指定时间 “航行” 到指定位置。


4. 关键帧 (keyframes)
提供关键帧,模型可以在关键帧之间生成中间帧,实现场景的平滑切换。在视频内容创作、动画制作、视频合成等方面都有至关重要的作用,例如长视频合成 / 生成。除了可以生成有别于以往插帧方法更丰富困难的动作,还可以自然和多种模态控制结合。
通过运动轨迹控制,三个小球可以自由在彭罗斯阶梯分别滚动。



加上 mask,操控飞船左右摆动也不在话下,连洒下来的光也追随移动
动静结合,万圣节装扮的动图也可以多种多样:
当采用同一帧作为首位帧,还可以产生循环播放的奇妙效果:
当然,卡通视频也不在话下:

也可以进行视角转化:
不单单可以进行新视频的生成和创作,MotionBridge 还可以改善图生视频或者文生视频的效果,减少歧义并增加视频复杂度和可控性。
除此之外,最常用的文本交互也是支持的。
更多的结果和应用,请参考官方视频。
技术概览
如今,已经有很多模型可以进行图生视频的创作,但生成的结果往往缺少可控性,用户要进行很多次的试错才能得到满意的结果。本文提出了一个名为 MotionBridge 的算法集成了多种可控信号,方便用户生成或者编辑现有的视频。不同于以往工作,MotionBridge 以插帧作为基本框架构建模型。即模型可以通过输入 1~n 张关键帧来生成对应视频,补全帧与帧之间的流畅过度。这个建模方式自然的保留了原本图生视频(image to video)的能力,同时提供了更高的可控性和视频生成质量。
然而,传统的插帧方法还具有一定的局限性,传统方法一般分为运动估计和运动补偿两个步骤,但当输入帧之间的时间或空间间隔增大时,运动估计和补偿的难度呈指数级上升。这是因为要生成逼真的中间帧,就必须填补输入帧之间缺失的信息,而这往往需要合成全新的内容,这对于传统方法而言是一个巨大的挑战。
尽管近年来视频生成模型取得了显著进展,为插帧技术带来了新的可能性,但这些技术仍然存在不足。一方面,许多模型难以生成复杂的大动作,无法满足创作者对于丰富场景变化的需求;另一方面,即使能够生成高质量的视频,却常常缺乏对中间帧细节的精细控制,导致最终生成的视频与创作者的创意设想存在偏差。
因此,为了解决以上的难题,MotionBridge 第一次进行了统一多模态可控插帧视频模型的尝试。
相比于图生视频,可控插帧视频任务的复杂度更高。以运动轨迹控制为例,视频插帧不仅需要服从指定轨迹,还需要丝滑过度并在指定帧结束。即使轨迹不完整,模型也需要根据关键帧推测,往往生成的动作比图生视频更为复杂。而进行多模态控制会进一步提升问题难度。

为了确保模型的生成能力,MotionBridge 的设计基于 DiT 的模型架构并且具有普适性(backbone-agnostic)可以适用于任何形式的 DiT 架构。
技术要点
1. 分类编码控制信号:为了减少控制信号融合时的歧义,MotionBridge 将控制分为内容控制(如掩码和引导像素)和运动控制(如轨迹)两类,通过双分支嵌入器分别计算所需特征,再引导去噪过程。这样的设计能更精准地处理不同类型的控制信息。
2. 运动轨迹表征:用简单且准确的交互表征方式进行视频运动的控制颇具挑战。该模型提出一种生成器,它能从光流合成轨迹,并将其转换为稀疏 RGB 点,作为模型训练时的运动表示,有效提升了运动控制的准确性。

3. 空间内容控制表征:MotionBridge 不仅有传统的轨迹控制,还增加了掩码和引导像素等空间内容控制。用户可以指定想要移动或保持静止的区域,进一步降低生成过程中的歧义,提供更灵活的创作条件。
4. 训练策略:面对多模态控制,常规训练效果不佳。MotionBridge 采用 curriculum learning 策略,先给模型输入更密集、简单的控制,再逐渐过渡到更稀疏、高级的控制,确保模型能平稳学习各种控制方式。
对比实验
1. 与 SOTA 的算法相比,MotionBridge 在没有额外控制的干预下,可以生成更真实高质量的图片细节。并且证实了在不同 DiT 架构下的普适性。


2. 消融研究
a. 对于算法提出的分类编码融合(dual-branch)和 curriculum learning,文中也进行了实验。可以看出其设计对于模型理解轨迹控制输入以及视频生成质量起到了至关重要的作用。

b. 掩码(mask)的作用:定性实验表明在一些情况下,mask 的使用可以让模型更容易感知到主体,并且让用户可以以尽量少的交互达到想要的效果。比如当只有一个运动轨迹时,因为过于稀疏,狐狸的跳起空间有限。当额外将 mask 输入,狐狸的跳跃便更加连贯自然。而用户也不需要像之前的工作一样提供过多的轨迹笔画反复调试。

更多技术细节,对比实验请参考原文:https://motionbridge.github.io/static/motionbridge_paper.pdf
视频:https://motionbridge.github.io/static/motionbridge_1.mp4
....
#OSCAR让操作系统交互实现自然语言「自由」
本文作者王晓强,加拿大蒙特利尔大学(Université de Montréal)和 Mila 人工智能研究所博士生,师从刘邦教授。博士期间的主要研究方向为自然语言处理,重点关注大语言模型的能力评估及其在智能体中的应用。目前已在自然语言处理领域的顶级会议 ACL、EMNLP 等发表多篇论文。
在人工智能的宏大发展蓝图里,通用人工智能(AGI)堪称研究者们梦寐以求的 「圣杯」,其终极目标是打造出像人类一样拥有广泛且灵活智能的系统,能够理解、学习并胜任几乎所有任务。在迈向这个目标的征程中,实现人工智能与数字世界的高效交互至关重要,而桌面任务 UI 自动化更是其中的关键赛道。
想象一下,未来我们只需轻松说出指令,电脑就能自动完成各种复杂操作,繁琐的手动操作成为历史,工作效率大幅提升,这样的场景是不是很令人期待?
去年,Anthropic 发布的 Computer use 为 AI 在桌面操作领域带来了新突破。它允许开发者通过 API,让 Claude 像人类一样操作计算机,极大拓展了 AI 在桌面操作领域的应用场景。
今年一月份,OpenAI 重磅推出的 Computer Using Agent(CUA)也备受瞩目,其赋能的 Operator 凭借 GPT-4o 的视觉能力,能够 「看懂」网站并与之交互,还可在 ChatGPT 界面自动执行多种常规浏览器任务。
与它们采用商用 API 不同,今天要给大家介绍一个来自加拿大蒙特利尔大学和 Mila 研究所的研究团队的开源解决方案 ——OSCAR(Operating System Control via state-Aware reasoning and Re-planning)。
OSCAR 不仅实现了桌面任务 UI 自动化,还在多个操作系统环境(桌面 Windows、Ubuntu 和智能手机 Android)完成了泛化与验证。目前,该研究已被 AI 领域顶级会议 ICLR 录用。下面,就让我们深入了解一下它的创新之处。

- 论文题目:OSCAR: Operating System Control via State-Aware Reasoning and Re-Planning
- 论文链接:https://arxiv.org/abs/2410.18963
操作系统 UI 交互自动化面临的挑战:
动态自适应难题
基于多模态大型语言模型(MLLM)的智能体(Agent)在复杂任务自动化领域表现出色,广泛应用于网络浏览、游戏、软件开发等场景,但不同应用的观察和动作空间差异极大,导致智能体通用性差,难以适应复杂工作流。
此外,以往的 UI 交互智能体多在静态离线的环境中开发,靠视觉问答和预设动作路径操作,缺乏操作系统实时反馈,任务失败时无法动态自适应。在现实应用中,实时反馈和自适应调整对适应新的 UI 环境至关重要,比如 「打开某文件并打印」 有多种操作路径,可通过开始菜单搜索,也能直接导航路径,但传统智能体难以应对这种多样性。
具体构建通用 UI 交互智能体面临以下挑战:
- 统一控制接口难题:智能体需熟练运用鼠标、键盘等标准输入方式,精准理解视觉信息并转化为指令,在不同应用中稳定高效操作。
- UI 定位困境:智能体要能解读屏幕信息,精准识别各类元素,如网页搜索时准确找到搜索框并正确交互,对其理解和定位能力要求高。
- 新 UI 探索与重规划挑战:智能体需像人类面对陌生软件一样,具备动态探索和调整计划的能力,能处理软件崩溃等意外,依据反馈优化策略。
OSCAR 的独特设计:
灵活状态机与动态重规划的巧妙结合
为解决上述难题,研究团队推出 OSCAR。它以代码为核心控制方式,与动态操作系统环境自主交互,创新点如下:
- 状态机架构:OSCAR 采用状态机模式,通过 [Init](初始化)、[Observe](观察)、[Plan](规划)、[Execute](执行)、[Verify](验证)等状态循环,处理任务各环节。遇到问题时利用实时反馈重新规划,比传统方式效率更高、适应性更强。

OSCAR 状态机
- 视觉和语义双重 UI 定位:OSCAR 利用 Set-of-Mark(SoM)提示技术和可访问性(A11Y)树生成视觉提示,精准定位 UI 元素;同时添加描述性标签进行语义定位,便于把握 UI 布局,灵活操作元素。

OSCAR 视觉和语义双重 UI 定位
- 任务驱动重新规划:受计划 - 解决提示(plan-and-solve)启发,OSCAR 将用户指令分解为子任务并逐步生成动作。收到负面反馈时,针对特定子任务重新规划,避免整体重规划,提高效率并防止错误传播。
- 基于代码的动作:OSCAR 借助生成的语义定位信息,利用元素 ID 或坐标引用交互元素,通过 PyAutoGUI 库生成控制代码,精确控制操作系统。

OSCAR 任务分解与重规划
OSCAR 实验验证:
UI 理解、定位和动态导航能力的实力认证
研究人员在 GAIA、OSWorld、AndroidWorld 等多个真实世界工作流自动化基准测评数据集中对 OSCAR 进行了评估,这些基准涵盖了不同难度和类型的任务,包括简单操作、复杂多步骤任务以及跨多种应用的任务。
1. 基准测评成绩突出:在 GAIA 基准测试中,OSCAR 在所有工作流复杂程度级别上都表现最佳。尤其是在最复杂的 Level 3 任务上,成功率达到 13.5%,几乎是之前最先进方法的两倍。在 OSWorld 和 AndroidWorld 基准测评中,OSCAR 同样超越其他智能体,展现出强大的适应性。

6a. GAIA 基准测评

6b. OSWorld 基准测评

6c. AndroidWorld 基准测评
OSCAR 在基准测评 GAIA, OSWorld 和 AndroidWorld 中取得最好水平
2. 规划效率优势显著:

在成功案例中,OSCAR 成功案例所需重新规划次数更少,而且每次重新规划的步骤更高效

在失败案例中,OSCAR 在错误完成(FC)、达到步骤限制(RSL)和无效动作(IA)这些情况中的重新规划冗余度(RR)明显低于其他智能体系统
结语:开启操作系统交互新时代
OSCAR 作为通用智能体,凭借灵活的状态机和动态的重新规划能力,在桌面和智能手机操作系统任务中展现出强大的适应性和有效性。它为自动化工作流提供了高效通用的解决方案,有望成为提升动态操作系统环境生产力的有力工具,让操作系统交互变得更加便捷、高效、易访问。而且,凭借其开源特性,未来 OSCAR 还将在众多开发者的共同努力下不断进化,持续助力通用人工智能与数字世界实现完美交互。
....
#o3-mini 碾压DeepSeek R1?
一条python程序引发近400万围观
AI 圈的头条被 DeepSeek 承包了十几天,昨天,OpenAI 终于坐不住了,推出了全新推理模型系列 o3-mini。不仅首次向免费用户开放了推理模型,而且相比之前的 o1 系列,成本更是降低了 15 倍之多。
OpenAI 也称这是其推理模型系列中最新、最具成本效益的模型:

刚刚上线,已经有网友迫不及待的拿它和席卷整个大模型圈的国产大模型 DeepSeek R1 进行对比了。
前段时间,AI 社区开始沉迷用 DeepSeek R1 和其他(推理)模型比拼这个任务:「编写一个 Python 脚本,让一个球在某个形状内弹跳。让该形状缓慢旋转,并确保球停留在形状内。」
这种模拟弹跳球的测试是一个经典的编程挑战。它相当于一个碰撞检测算法,需要模型去识别两个物体(例如一个球和一个形状的侧面)何时发生碰撞。编写不当的算法会出现明显的物理错误。
在 DeepSeek R1 席卷国内外热搜,微软、英伟达、亚马逊等美国云计算平台争先恐后引进 R1 的同时,R1 也在这个任务中完成了对 OpenAI o1 pro 的碾压。
再看 Claude 3.5 Sonnet 和谷歌的 Gemini 1.5 Pro 的生成结果,DeepSeek 旗下的开源模型高出的确实不只是一个 level。
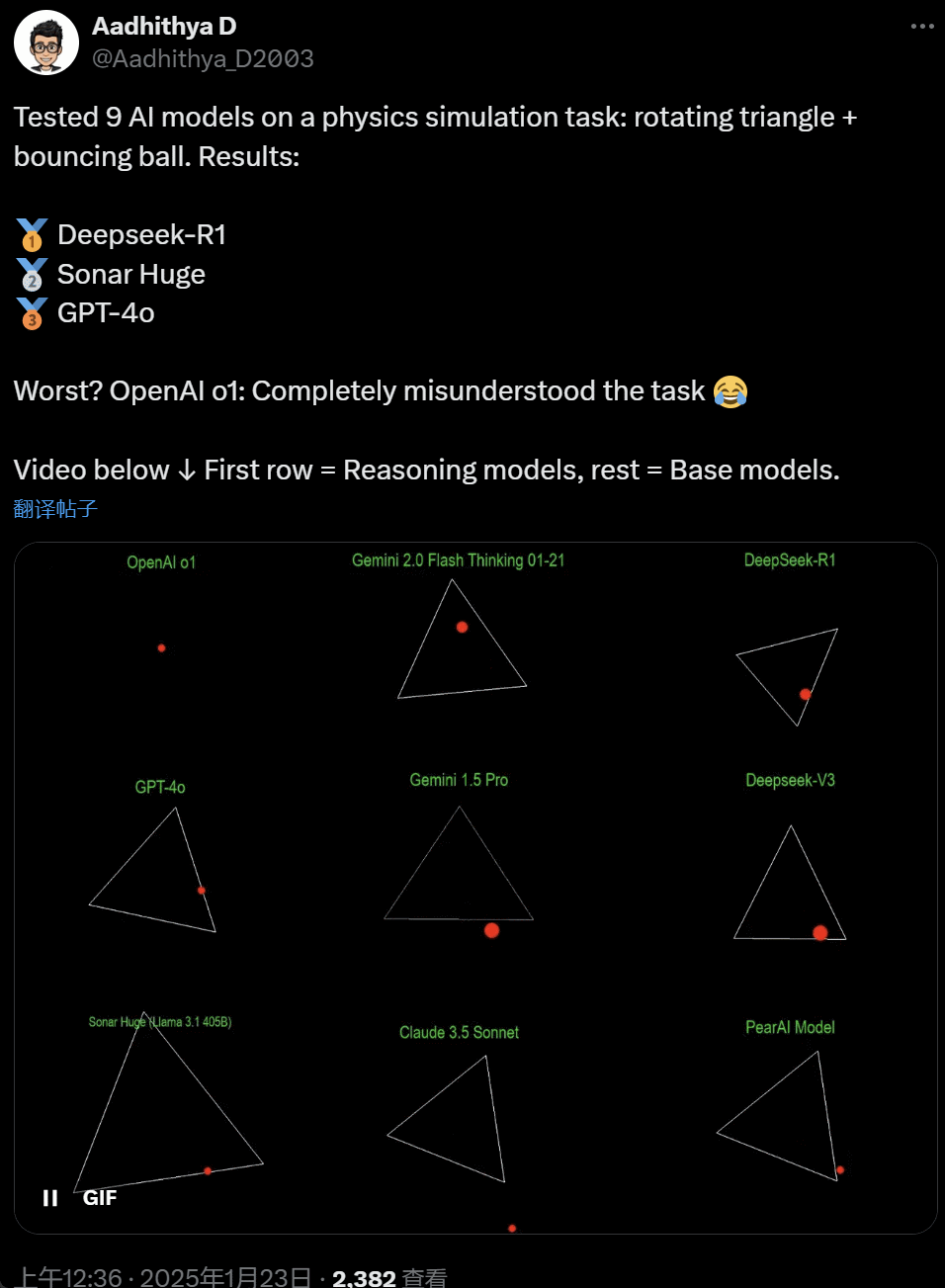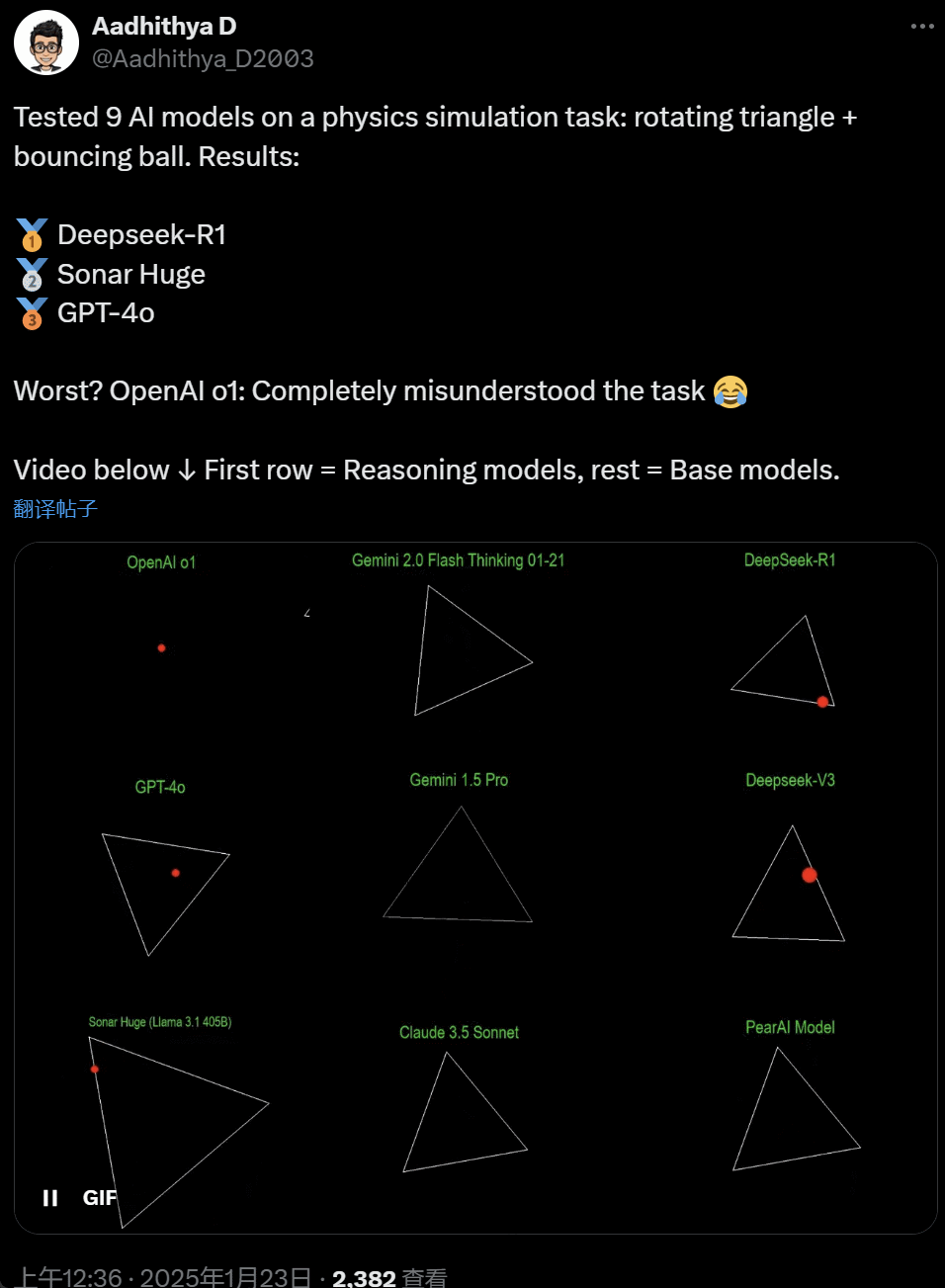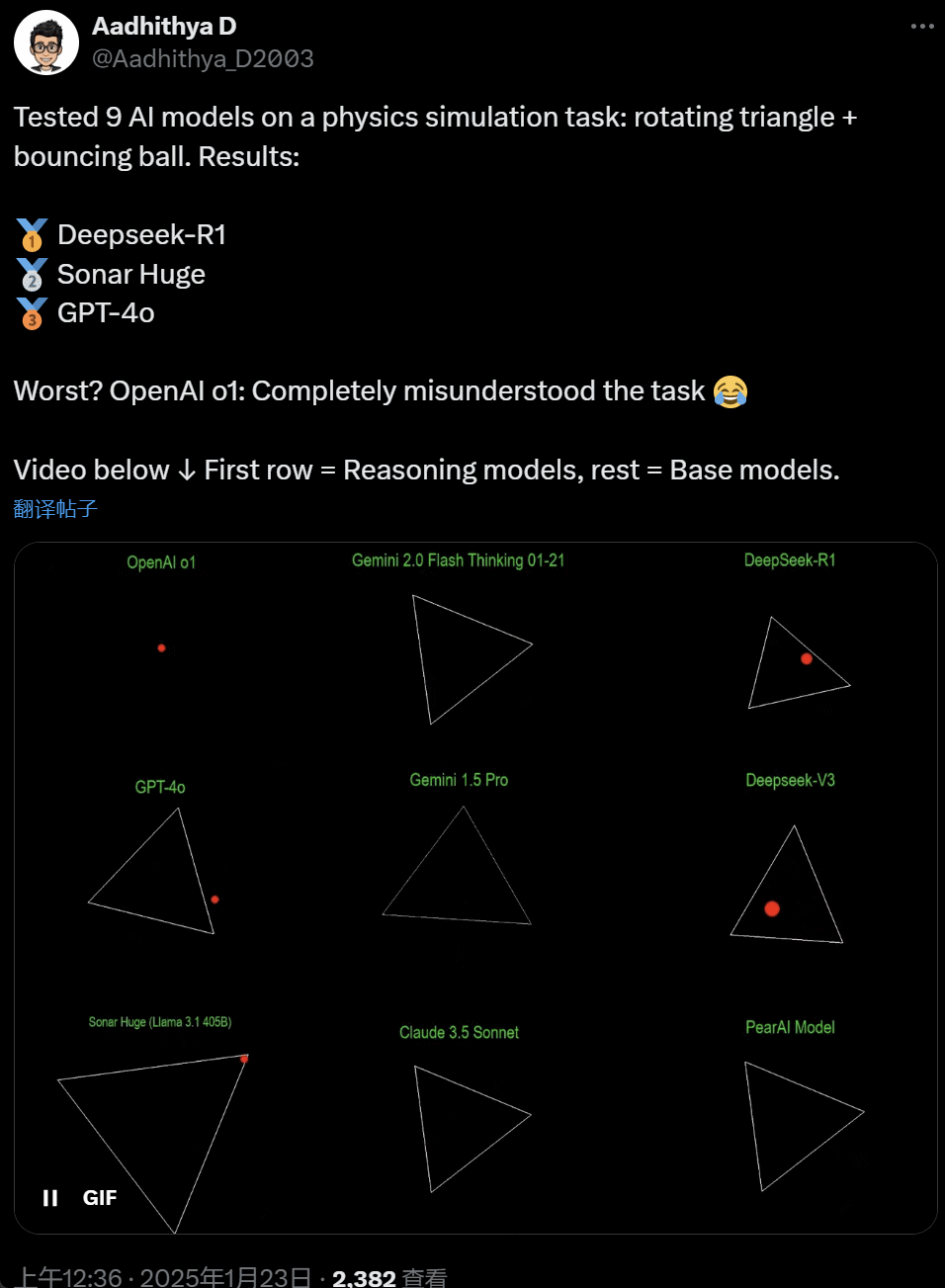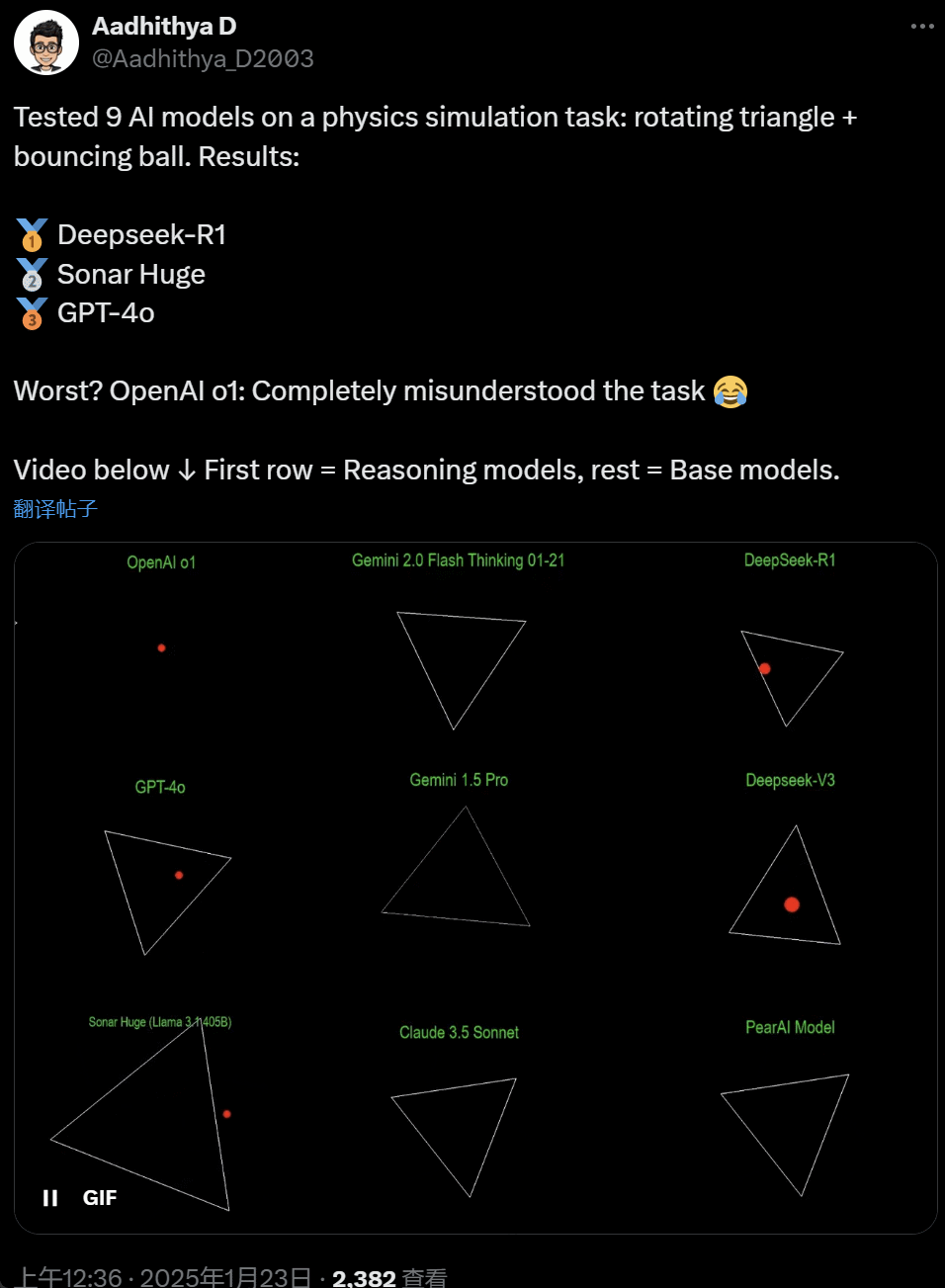
然而,在 o3-mini 上线后,剧情似乎一夜反转了,比如这个帖子宣称 OpenAI o3-mini 碾压了 DeepSeek R1。目前已引发近 400 万网友围观。

该开发者用的 prompt 是:"write a Python program that shows a ball bouncing inside a spinning hexagon. The ball should be affected by gravity and friction, and it must bounce off the rotating walls realistically"
也就是分别让 o3-mini 和 DeepSeek R1 写一个球在旋转的六边形内弹跳的 python 程序,小球跳动的过程中要遵循重力和摩擦力的影响。最后的展示效果如下:

从效果来看,o3-mini 把碰撞、弹跳效果展示的更好。从对重力和摩擦力的理解来看,DeepSeek R1 版本的小球似乎有点压不住牛顿的棺材板了,完全不受重力控制。
这并非个案,@hyperbolic_labs 联合创始人 Yuchen Jin 在此之前也发现了这个问题,他分别向 DeepSeek R1 和 o3-mini 输入了提示词:write a python script of a ball bouncing inside a tesseract(编写一个 Python 脚本,模拟一个球在四维超立方体内部弹跳)。
四维超立方体的每个顶点与四条棱相邻,每条棱则连接两个立方体。四维空间内的几何图形超出了人类的直观感知范围,所以听着这些描述,我们可能很难想象出一个四维超立方体长什么样子。
而 o3mini 不仅展现出了稳定的几何结构,小球在四维空间内弹跳的运动轨迹也较为灵活,有撞到立方体侧面的打击感。
再来看 DeepSeek R1 这边,它对四维超立方体的形状理解似乎还不够深入透彻。同时,小球在其中的运动轨迹也显得有些诡异,有一种「飘忽不定」的感觉。
据 Yuchen Jin 称,他试了很多次,所有用 DeepSeek R1 尝试都比一次性的 o3-mini 要差,比如下面这次就剩下球了。

xxx也亲测了一把,同样是 Pass@1 测试,DeepSeek R1 这次是既有球又有几何外框了,甚至小球还会变换颜色色,遗憾的是,它把四维超立方体简化成了三维空间坐标轴。
o3-mini 的表现则有些「买家秀」的意味,明明和 Yuchen Jin 输入的是完全一样的提示词,为什么 o3-mini 就不会了?得不到如上所示的「卖家秀」了呢?
看来,在生成小球在几何外框内跳动的程序这方面,DeepSeek R1 并不是完全是 o3-mini 的手下败将。
AIGC 从业者 @myapdx 用了一个更加复杂的同类提示词来测试 o3-mini 和 DeepSeek R1:编写一个 p5.js 脚本,模拟 100 个彩色小球在一个球体内部弹跳。每个小球都应留下一条逐渐消失的轨迹,显示其最近的路径。容器球体应缓慢旋转。请确保实现适当的碰撞检测,使小球保持在球体内部。
o3-mini 的效果是这样的:
提示词里的这么多项要求:在球体内部弹跳、留下逐渐消失的轨迹、容器缓慢旋转......o3-mini 都完美满足。
而 DeepSeek R1 的效果,好像也没差到哪里去:
至于为什么会出现这样的差异,Yuchen Jin 和 @myapdx 都在帖子中提到,这个任务对模型如何理解真实世界的物理规律有所反应。模型需要综合自己对语言、几何、物理和编程的理解,方能得出最后的模拟结果。从前两轮的结果看来,o3-mini 有可能是物理学得最好的大模型。
与此同时,OpenAI 也在昨天的发布博客中强调过,在博士极科学问题方面 o3-mini-low 的表现优于 o1-mini。o3-mini-high 的表现与 o1 相当,在博士级生物学、化学和物理问题上都有显著进步。
对人类来说,理解小球跳动时的重力和摩擦力并不算困难,但在大语言模型领域,这种对物体物理状态的「世界模型」理解能力,直到最近才真正突破。
还有网友猜测,DeepSeek R1 的程序有时只有一个球,会不会是它想得太多了?
不知是否有读者亲自体验过?欢迎讨论。

参考链接:
https://x.com/flavioAd/status/1885449107436679394
https://x.com/iamRezaSayar/status/1885760491466997791
https://x.com/Yuchenj_UW/status/1885416559029740007
https://x.com/Yuchenj_UW/status/1885472365309833382
....

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 52
52 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)