2026,多模态大模型将走向何方?
2025年顶会趋势显示多模态大模型技术迎来爆发期。VERITAS通过融合视觉先验和LMMs评估优化数据质量,提升模型性能;DRIFT方法在梯度空间迁移推理知识,增强MLLMs能力;UniFilter利用合成数据训练分类器筛选高质量多模态数据;UniFusion采用冻结VLM作为统一编码器,通过LAP机制改善图像生成对齐效果。这些方法在各自领域均取得显著性能提升,推动多模态技术向更高效、更精准方向发
从 CVPR、ICLR 到 AAAI,2025 年顶会趋势已清晰释放信号:多模态大模型领域正迈入新一轮技术爆发期。作为当前技术核心,多模态大型语言模型(MLLMs)并非单一模态的升级,而是将大型语言模型的自然语言处理能力,与视觉、音频等多模态数据的理解、生成能力深度融合。
1.VERITAS: Leveraging Vision Priors and Expert Fusion to Improve Multimodal Data
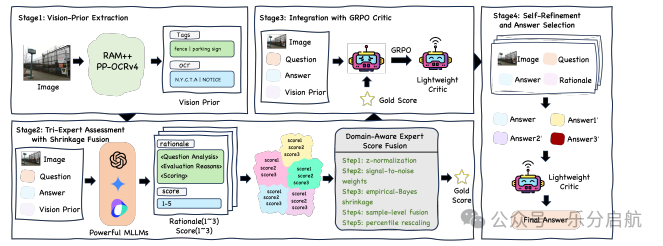
【要点】VERITAS通过整合视觉先验和多种先进的多模态模型,并结合统计方法,提高了监督微调数据的质量,从而优化了大型多模态模型的性能。
【方法】VERITAS采用视觉识别模型RAM++和OCR系统PP-OCRv4提取视觉先验,并结合三种LMMs(GPT-4o, Gemini-2.5-Pro, Doubao-1.5-pro)对原始答案进行评估,使用统计融合生成高置信度的一致性评分作为地面真实值,进而通过Group Relative Policy Optimization训练轻量级评判模型。
【实验】在六个多模态基准上的实验表明,使用VERITAS处理的数据进行微调的模型,其性能始终优于使用原始数据的模型,特别是在文本丰富和细粒度推理任务中。该评判模型表现出与最先进LMMs相当的增强能力,同时显著提高了效率。
2.Directional Reasoning Injection for Fine-Tuning MLLMs
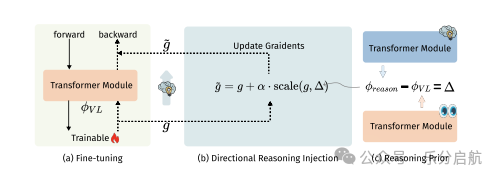
【要点】本文提出了一种轻量级的Directional Reasoning Injection方法(DRIFT),通过在梯度空间中转移推理知识来优化多模态大语言模型(MLLMs)的推理能力,实现了高效的知识迁移和性能提升。
【方法】DRIFT通过预计算推理先验(即推理模型与多模态模型之间的参数空间差异),并在多模态微调过程中使用该先验来偏置梯度,从而在不破坏多模态对齐的情况下实现推理知识的迁移。
【实验】本文在MathVista和MathVerse等多个多模态推理基准数据集上进行了实验,结果表明DRIFT相较于简单合并和监督微调方法能够一致地提升推理性能,同时成本远低于训练密集型方法。
3.Train a Unified Multimodal Data Quality Classifier with Synthetic Data
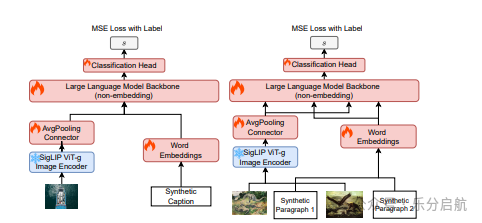
【要点】本文提出了一种基于合成数据的统一多模态数据质量分类器UniFilter,用于筛选高质量图像-文本标题和交错数据,提升了多模态大型语言模型的性能。
【方法】作者采用半合成方法,利用现成的原始图像和生成的四个质量级别的对应文本,创建样本分数对,用于训练UniFilter模型。
【实验】作者使用UniFilter对DataComp标题数据集和OBELICS图像-文本交错数据集进行了高质量数据筛选,实验结果表明,在经过筛选的数据上预训练的多模态大型语言模型表现出更强大的零样本推理和上下文学习能力,并在经过视觉监督微调后在多个基准测试上取得了更强的性能。
4.UniFusion: Vision-Language Model as Unified Encoder in Image Generation

【要点】提出UniFusion模型,利用冻结的大型视觉语言模型(VLM)作为统一的多模态编码器,通过Layerwise Attention Pooling(LAP)机制提高图像生成中的文本-图像对齐和视觉信息传递效率。
【方法】采用Layerwise Attention Pooling(LAP)机制从冻结的VLM中提取文本和视觉token的高级语义和低级细节,以调节扩散生成模型。
【实验】通过实验验证了UniFusion在文本-图像对齐方面的优越性,并提出了VERIFI方法,使用VLM在模型内部提示重写时生成的文本token来调节扩散transformer(DiT)。实验使用的数据集未明确提及,但结果显示模型在编辑任务上的微调不仅提升了生成时的文本-图像对齐,还展现了强大的泛化能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)