【Kafka 生产实战】如何判断消费组是否落后?Consumer Lag 全面解析 + 监控 + 实战案例
fetch.min.bytes / fetch.max.bytes:单次拉取数据大小上限。未消费的消息数量 = LOG-END-OFFSET - CURRENT-OFFSET。如果消费组一直落后,旧数据会在消费之前就被 Kafka 根据保留策略清理掉,max.poll.interval.ms:处理时间上限,避免误判为“挂掉”说明这几个 Topic 的消费组已经完全追上消息,运行正常。max.pol
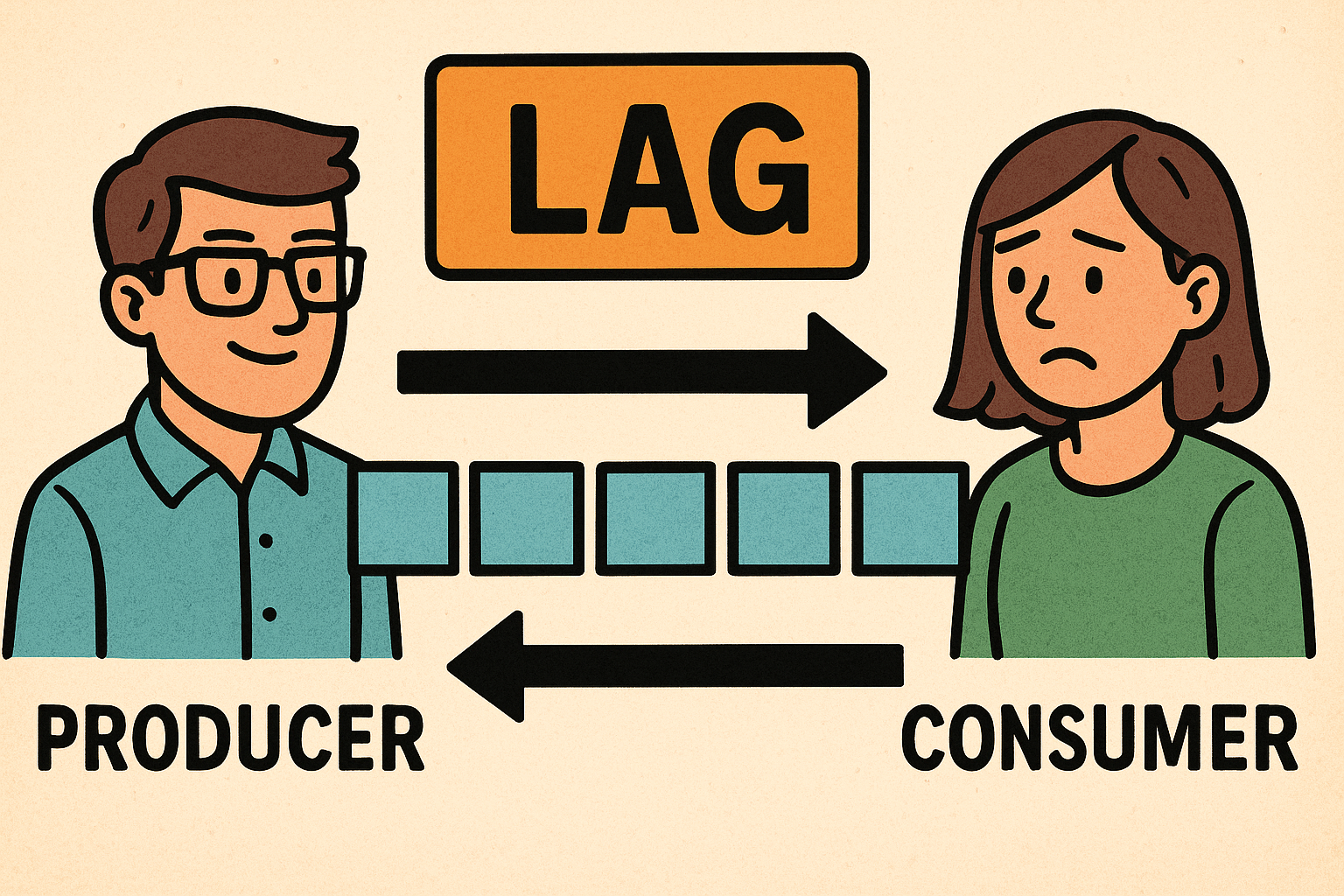
在使用 Kafka + 微服务消费模型 时,最常见的问题之一就是:
消费组是否落后?Consumer lag 到底多少算异常?
本文将讲清楚:
-
什么是消费者落后(Consumer Lag)
-
如何查看消费组是否正常
-
LAG 阈值怎么判断
-
一个经过“泛化处理”的真实案例分析
一、什么是 Consumer Lag?
Kafka 的消费模型本质上是:
生产者写入消息 → 消费者读取消息如果消费者速度跟不上生产者,就会出现积压,称为 Consumer Lag。
Kafka 用两组 Offset 来衡量:
|
名称 |
说明 |
|---|---|
|
CURRENT-OFFSET |
消费者已经消费到的位置 |
|
LOG-END-OFFSET |
Topic 当前最新消息的位置 |
|
LAG |
未消费的消息数量 = LOG-END-OFFSET - CURRENT-OFFSET |
LAG 越大 → 消费延迟越严重。
二、如何查看消费组是否落后?
Kafka 自带工具:
kafka-consumer-groups.sh \
--bootstrap-server broker1:9092 \
--describe \
--group email-sync-consumer三、泛化后的真实案例:如何判断消费是否正常?
下面是一个经过脱敏/泛化处理后的 --describe 输出示例:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
email-sync-consumer email_channel_a 0 423 423 0 consumer-email-1-... /10.0.0.10 consumer-email-1
email-sync-consumer email_channel_b 0 518 518 0 consumer-email-2-... /10.0.0.10 consumer-email-2
email-sync-consumer email_channel_c 0 9 9 0 consumer-email-3-... /10.0.0.10 consumer-email-3
email-sync-consumer email_test_topic 0 45 45 0 consumer-email-4-... /10.0.0.10 consumer-email-4
email-sync-consumer email_multipart_storage 0 74847825 75828162 980337 consumer-email-5-... /10.0.0.10 consumer-email-5前四行都是:
LAG = 0说明这几个 Topic 的消费组已经完全追上消息,运行正常。
但是最后一个 Topic:
TOPIC = email_multipart_storage
CURRENT = 74,847,825
LOG-END = 75,828,162
LAG = 980,337 (≈ 98 万条)✅ 结论:这个 Topic 对应的消费存在明显积压,属于“消费者落后”的典型情况。
四、LAG 多少算正常?多少算异常?
经验上可以粗略分级(不同业务可以微调):
|
LAG 数量 |
危险等级 |
含义 |
|---|---|---|
|
0 ~ 1,000 |
正常 |
高实时 |
|
1,000 ~ 10,000 |
轻微 |
业务通常可接受 |
|
10,000 ~ 100,000 |
Warning |
消费速度开始跟不上 |
|
100,000 ~ 500,000 |
High |
消费延迟明显,需要排查 |
|
> 500,000 |
严重延迟 |
消费者处理不过来,会持续积压 |
|
> 1,000,000 |
灾难级 |
可能造成数据丢失或系统异常 |
在上面的例子中,email_multipart_storage 的 LAG ≈ 98 万,已经非常接近灾难级别。
五、消费组落后会带来什么问题?
1. 数据延迟,实时性明显下降
假设消费者每秒能稳定处理 500 条消息:
980,337 / 500 ≈ 1960 秒 ≈ 30 分钟延迟如果每秒只能处理 100 条:
980,337 / 100 ≈ 9803 秒 ≈ 2.7 小时延迟这对实时系统几乎不可接受。
2. Topic 有清理策略时,可能直接丢数据
很多生产环境会配置类似:
retention.bytes = 8GB
retention.ms = 3 days如果消费组一直落后,旧数据会在消费之前就被 Kafka 根据保留策略清理掉,这部分数据就永远无法被下游处理。
3. 消费者不稳定:频繁 rebalance、OOM、异常退出
大面积积压可能导致:
-
consumer poll 超时
-
心跳不及时导致 rebalance
-
单条消息过大造成内存不足
-
异常日志不断刷屏
最终让延迟进一步恶化。
六、如何快速判断“延迟是在变好,还是在变坏”?
1)重复执行
--describe
,看 LAG 的趋势
kafka-consumer-groups.sh \
--bootstrap-server broker1:9092 \
--describe \
--group email-sync-consumer-
如果 LAG 越来越大 → 消费速度 < 生产速度
-
如果 LAG 逐渐下降 → 消费者正在追平数据
2)结合消费者日志和系统指标
-
查看应用日志是否有异常(超时、反序列化错误、DB 写入失败等)
-
查看消费者所在机器 CPU/内存/网络是否已经打满
七、如何缓解或解决消费组落后问题?
✔ 方案一:提升消费者处理能力(首选)
-
优化业务逻辑:减少不必要的外部调用、磁盘 IO
-
批量处理(例如合并多条消息一起写数据库)
-
使用线程池并发处理
-
迁移到更高配置机器
✔ 方案二:增加分区 + 扩容消费者实例
注意:一个分区同一时间只会被同一个消费组内的一个 consumer 消费。
想通过多实例提升吞吐,需要:
-
提高 Topic 分区数(如从 1 提到 4、8 等)
-
多个消费者实例挂在同一个消费组,分摊不同分区
✔ 方案三:调优消费者参数
常见可调参数包括:
-
max.poll.records:一次拉取的最大消息数
-
fetch.min.bytes / fetch.max.bytes:单次拉取数据大小上限
-
fetch.max.wait.ms:拉取等待时间
-
max.poll.interval.ms:处理时间上限,避免误判为“挂掉”
八、如何用 Zabbix 监控消费组是否落后?
可以通过脚本定期采集某个消费组在某个 Topic 上的 LAG:
示例脚本(伪代码):
#!/bin/bash
GROUP=$1
TOPIC=$2
kafka-consumer-groups.sh \
--bootstrap-server broker1:9092 \
--describe \
--group "$GROUP" \
| grep "$TOPIC" \
| awk '{print $6}' # 第 6 列是 LAG建议的触发阈值:
|
级别 |
触发条件示例 |
|---|---|
|
Warning |
LAG > 100000 |
|
High |
LAG > 300000 |
|
Disaster |
LAG > 500000 或 LAG 持续上升一段时间 |
配合 Zabbix 的趋势(5 分钟内 max > min)还能监控“是否持续变差”。
九、总结
本文通过一个已经脱敏的真实输出,展示了如何判断:
-
一个消费组是否落后
-
LAG 大小如何评估风险
-
LAG 高时会带来的业务影响
-
几种缓解和解决方案
-
如何用 Zabbix 对 LAG 做持续监控
核心结论:
-
LAG ≈ 0 是目标状态
-
LAG 上十万 就已经值得关注
-
LAG 上百万 必须立刻排查和处理
你可以根据自己业务的吞吐量和实时性要求,微调阈值,但思路是一致的:持续监控 LAG,并关注它的趋势,而不是只看某一瞬间的数值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)