datawhale 组队学习 RAG技术全栈指南task3打卡
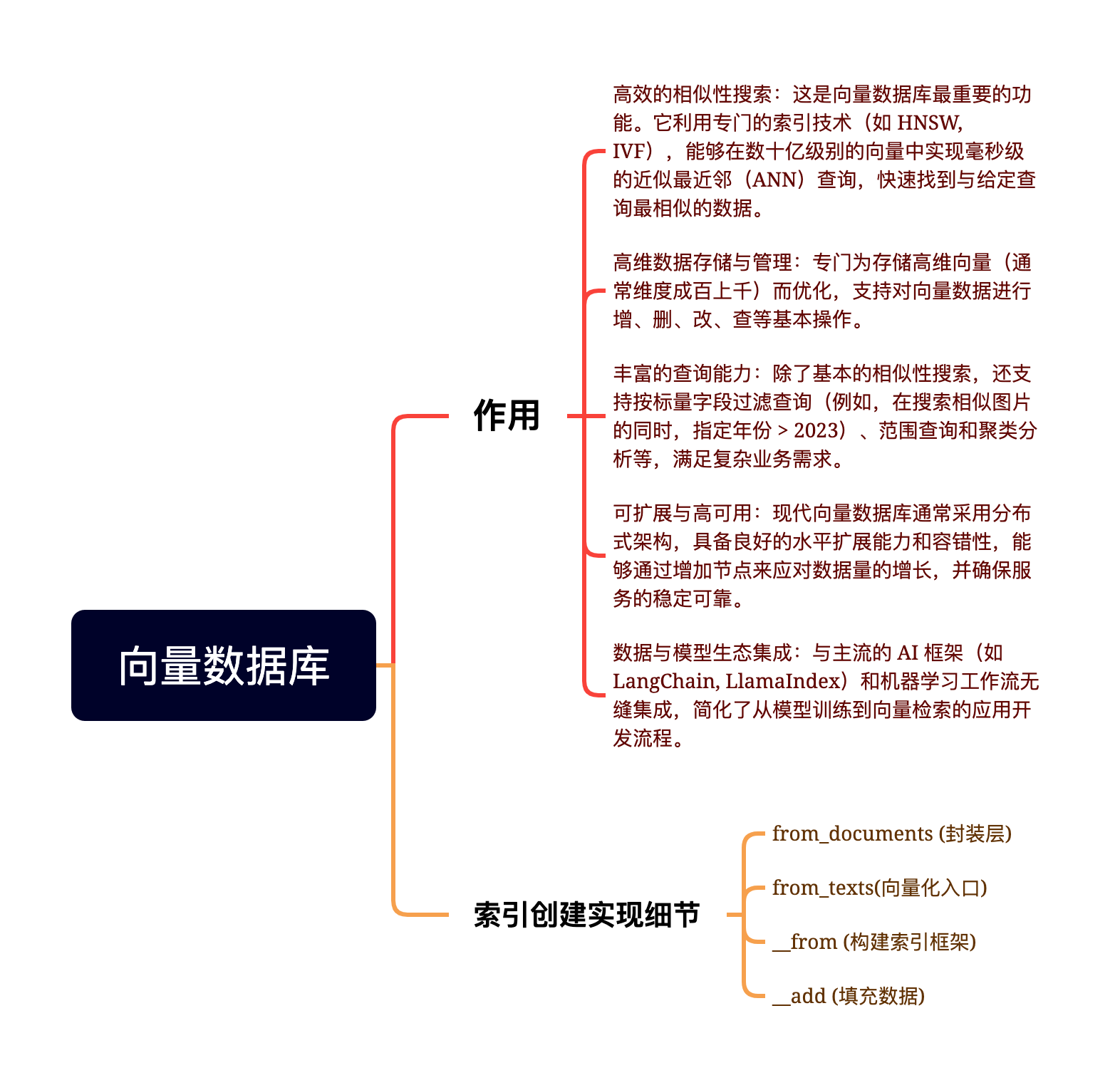
定位:开源、云原生、分布式的向量数据库。核心优势高扩展性:存储计算分离,轻松应对百亿级数据。高可用:生产级容灾能力。生态丰富:LF AI & Data 顶级项目,集成 LangChain、LlamaIndex 等。与 FAISS/Chroma 的区别:FAISS 是本地库,适合原型/小规模;Milvus 是独立的服务端软件,适合大规模生产环境。Milvus 是构建大规模 RAG 和多模态搜索系统的
Milvus 简介与定位
-
定位:开源、云原生、分布式的向量数据库。
-
核心优势:
-
高扩展性:存储计算分离,轻松应对百亿级数据。
-
高可用:生产级容灾能力。
-
生态丰富:LF AI & Data 顶级项目,集成 LangChain、LlamaIndex 等。
-
-
与 FAISS/Chroma 的区别:FAISS 是本地库,适合原型/小规模;Milvus 是独立的服务端软件,适合大规模生产环境。
二、 部署与架构
-
部署方式:推荐使用 Docker Compose 部署。
-
核心组件(启动时会包含三个容器):
-
milvus-standalone:核心服务。 -
milvus-etcd:负责元数据存储(Metadata Storage)。 -
milvus-minio:负责对象存储(Object Storage,存向量数据块)。
-
-
默认端口:19530。
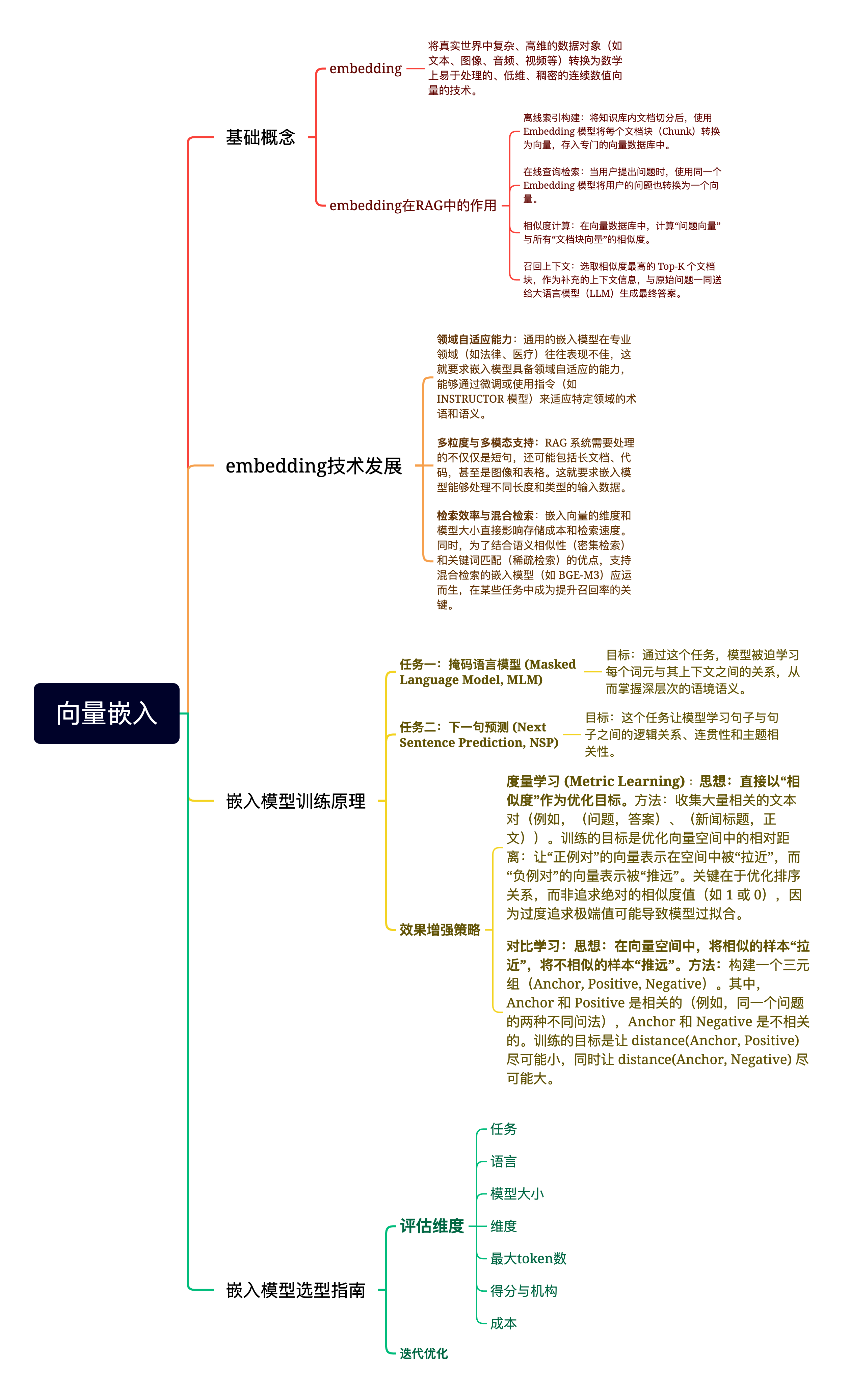
三、 核心概念(数据模型)
Milvus 的数据组织方式类似关系型数据库,但针对向量做了优化:
-
Collection (集合):类似于 SQL 中的 Table (表)。是数据的顶层容器。
-
Partition (分区):将数据物理隔离(如按年份分),检索时可指定分区以缩小范围,加速查询。
-
Schema (模式):定义表结构。
-
主键字段 (Primary Key):唯一标识 ID。
-
向量字段 (Vector Field):存储 Embedding(如 768 维浮点数组)。
-
标量字段 (Scalar Field):存储元数据(如图片路径、文章标题),用于过滤。
-
-
Entity (实体):类似于 SQL 中的 Row (行),即一条具体的数据。
-
Alias (别名):类似于指针或软链接。可以无缝切换指向的 Collection,实现零停机的数据更新(Blue-Green 部署)。
四、 索引技术 (Index) —— 速度的核心
为了在海量数据中毫秒级返回结果,Milvus 提供了多种索引算法(这也是你可能感兴趣的算法部分):
| 索引类型 | 原理简述 | 优点 | 缺点 | 适用场景 |
| FLAT | 暴力搜索 (Brute-force) | 100% 召回率,最准 | 慢,资源消耗大 | 数据少,要求极高精度 |
| IVF 系列 | 倒排索引 (聚类分桶) | 速度快,平衡 | 召回率非 100% | 通用场景,高吞吐 |
| HNSW | 基于图 (Hierarchical Graph) | 极快,目前最主流 | 内存占用大 | 追求低延迟 (实时推荐) |
| DiskANN | 基于磁盘的图索引 | 内存占用极低 | 延迟稍高 | 超大规模数据 (内存放不下) |
五、 检索功能 (Retrieval)
Milvus 不仅仅是查相似,还支持复杂的业务逻辑:
-
基础 ANN 检索:查 Top-K 近邻。
-
过滤检索 (Filtered Search):先用标量筛选(如
price < 500),再在结果中做向量检索。 -
范围检索 (Range Search):查找相似度在
0.8 ~ 0.9之间的所有结果(常用于风控、异常检测)。 -
多向量混合检索 (Hybrid Search):
-
同时检索“文本向量”和“图像向量”。
-
通过 Rerank (重排) 策略(如 WeightedRanker)融合结果,提升精准度。
-
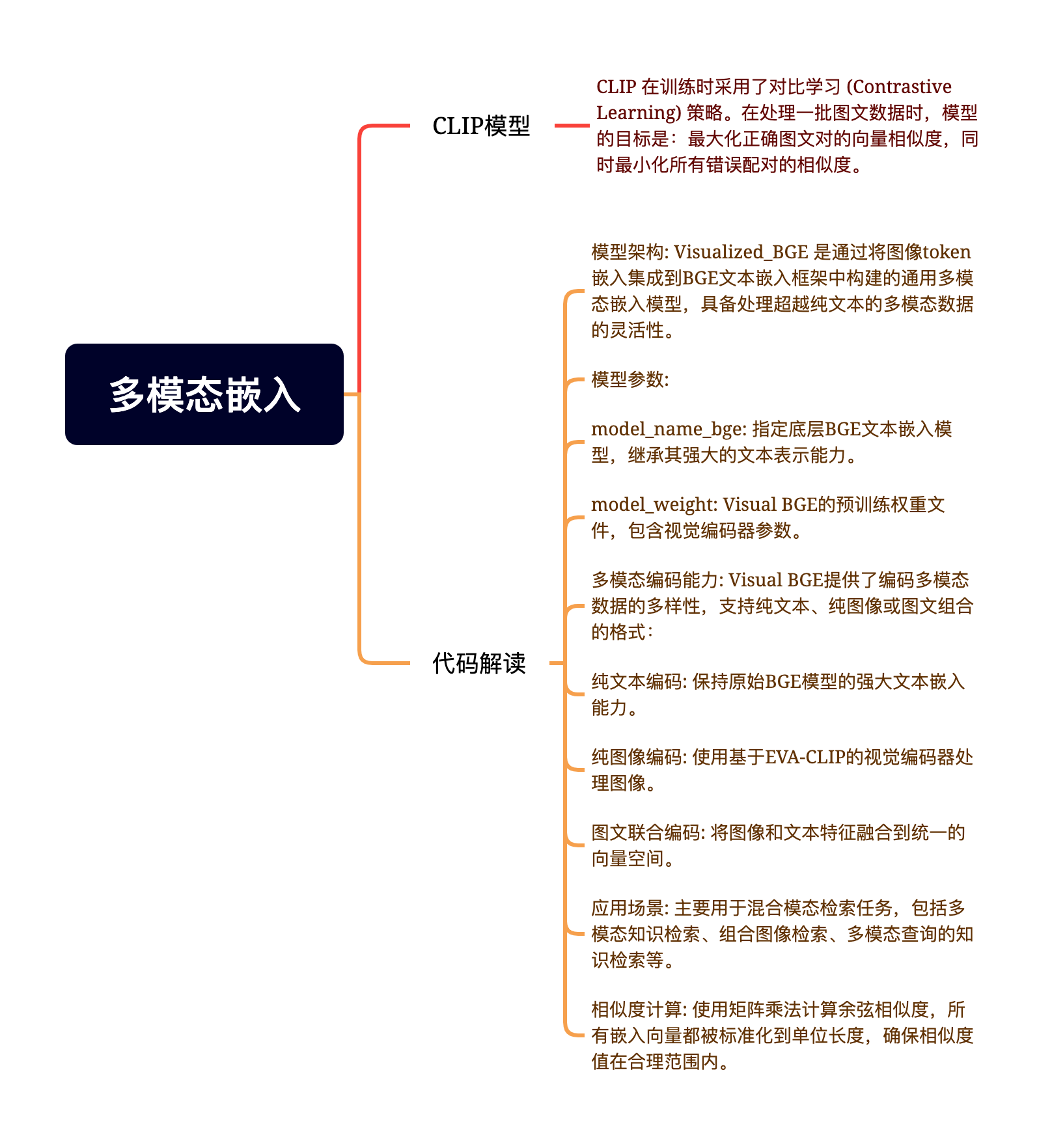
六、 多模态检索实战 (代码流程)
教程演示了如何结合 Visualized-BGE 模型和 Milvus 构建一个“图文检索”系统。
主要流程:
-
模型初始化:加载
Visualized-BGE用于将图片/文本转为向量。 -
创建 Collection:
-
定义 Schema:
id(Int64),vector(768维),image_path(String)。 -
create_collection(...)。
-
-
数据入库:
-
读取图片 $\rightarrow$ 编码为向量 $\rightarrow$
milvus_client.insert(...)。
-
-
创建索引:
-
选择 HNSW 索引,设置参数
M(最大连接数) 和efConstruction(构建深度)。 -
load_collection():注意,Milvus 搜索前必须将数据加载到内存。
-
-
执行检索:
-
用户输入:“一条龙” (文本) + [图片] (查询图)。
-
编码为
query_vector。 -
milvus_client.search(...):使用余弦相似度 (COSINE) 查找最近邻。
-
-
结果处理:返回 Top-K 的图片路径并可视化展示。
总结
Milvus 是构建大规模 RAG 和多模态搜索系统的基石。如果你在做机器视觉项目(如之前的 3D 重建数据管理),当需要根据特征向量(如 PointNet 提取的特征)快速检索相似模型或图片时,Milvus 是比传统数据库更合适的选择。
索引优化
一、 上下文扩展:句子窗口检索 (Sentence Window Retrieval)
1. 核心痛点
在 RAG 中存在一个经典的权衡(Trade-off):
-
切分过小:检索精准,但缺乏上下文,LLM 难以生成高质量答案。
-
切分过大:包含丰富上下文,但噪音多,检索相关性下降。
2. 解决方案:句子窗口检索
该策略的核心思想是:“为检索精确性而索引小块,为生成质量而检索大块”。
-
工作流程:
-
索引阶段 (Indexing):
-
将文档切分为单个句子作为节点(Node)。
-
关键点:在每个节点的元数据(Metadata)中,存储该句子前后 $N$ 个句子的完整文本(即“窗口”)。
-
只对单一句子进行向量化索引。
-
-
检索阶段 (Retrieval):
-
使用用户的 Query 去搜索最相似的单一句子(保证了高精准度)。
-
-
后处理阶段 (Post-Processing):
-
使用
MetadataReplacementPostProcessor。 -
在送给 LLM 之前,将检索到的“单一句子”替换为元数据中存储的**“完整窗口文本”**。
-
-
生成阶段 (Generation):
-
LLM 接收到的是包含丰富上下文的文本块,从而生成连贯、详尽的答案。
-
-
-
效果对比:
-
相比常规检索,句子窗口检索生成的答案更像是一个综述,包含更多细节和背景,减少了断章取义的风险。
-
二、 结构化索引:递归检索 (Recursive Retrieval)
1. 核心痛点
当面对大规模文档集(如数百个 PDF 或 Excel 表格)时,传统的扁平化向量搜索效率低下,容易被不相关的文档干扰。
2. 解决方案:结构化索引 + 路由
利用元数据(Metadata)将非结构化的向量搜索与结构化的数据筛选结合起来。
3. 场景案例:多表格 Excel 检索
假设有一个包含多个年份工作表(Sheet)的 Excel 文件(如 1994年, 2002年...)。
方法 A:基于 PandasQueryEngine 的递归检索 (功能强大但有风险)
-
原理:
-
为每个 Sheet 创建一个独立的
PandasQueryEngine(能将自然语言转为 Pandas 代码)。 -
创建一个顶层索引,包含指向各个 Sheet 的摘要节点 (IndexNode)。
-
递归流程:
-
用户提问 $\rightarrow$ 顶层检索找到对应的年份节点 $\rightarrow$ 路由到该年份的 Pandas 引擎 $\rightarrow$ 引擎生成代码并执行 $\rightarrow$ 返回结果。
-
-
-
⚠️ 安全警告:
PandasQueryEngine依赖 LLM 生成 Python 代码并使用eval()执行。在没有沙箱隔离的生产环境中,存在极高的任意代码执行风险 (RCE),强烈不建议直接在生产环境使用。
方法 B:分离式路由与过滤 (更安全的替代方案)
为了避免执行代码,可以采用“先路由,后过滤”的策略:
-
摘要索引 (Router):建立一个轻量级索引,只存每个表格的简介(如“这是1994年的数据”)。
-
内容索引 (Content):建立一个包含所有实际数据的索引,每条数据都打上标签(如
sheet_name: 1994)。 -
执行流程:
-
Step 1:用户提问 $\rightarrow$ 搜摘要索引 $\rightarrow$ 确定目标是
1994。 -
Step 2:搜内容索引 $\rightarrow$ 附加元数据过滤器 (
filter: sheet_name == 1994) $\rightarrow$ 获取精准答案。
-
三、 核心观点:关于框架的学习
文章最后特别强调了一个学习理念:
-
不要局限于框架:LangChain 和 LlamaIndex 是好工具,但它们只是“桥梁”。
-
原理重于调用:理解底层的“句子窗口”或“递归检索”思想,比学会调用 API 更重要。
-
拥抱灵活性:框架有局限性(如 Pandas 引擎的安全问题)。只有理解原理,你才能拆解框架,用底层模块构建出更安全、更符合业务需求的系统。
总结
这一节通过 LlamaIndex 的两个高级技巧,展示了 RAG 优化的两个主要方向:
-
纵向优化(单文档):通过句子窗口,在不牺牲检索精度的前提下扩展上下文。
-
横向优化(多文档):通过递归检索和元数据过滤,解决大规模知识库的精准定位问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)