美团&中科院&哈工大 :AMO-Bench —— 定义数学推理大语言模型新标尺。以原创性与IMO难度,树立精准评估。
文章目录
概要
本文介绍由美团LongCat团队联合中科院、哈工大等机构共同研发的AMO-Bench基准评测集。该基准包含50道IMO级别的原创数学难题,旨在解决当前大语言模型数学推理评估中存在的性能饱和、数据污染和评估低效三大挑战。实验结果表明,即使是当前最先进的大语言模型,在该基准上的最高准确率仅为52.4%,充分证明了其在区分模型数学推理能力方面的有效性。
论文链接: https://arxiv.org/pdf/2510.26768
官方网站:https://amo-bench.github.io/
仓库链接:https://github.com/meituan-longcat/AMO-Bench
数据集链接:https://huggingface.co/datasets/meituan-longcat/AMO-Bench
引言
当前,大语言模型在数学推理任务上展现出显著进展,但在面对需要深度策略性思维的复杂数学问题时仍存在明显局限。这一现象突显了现有评估基准的不足:传统数学竞赛题目已被大规模预训练数据覆盖,导致模型表现出现"饱和"现象,无法真实反映其推理能力。
针对这一挑战,文章提出了AMO-Bench基准评测集。该基准包含50道严格遵循国际数学奥林匹克竞赛标准的原创题目,通过四重质量审查机制确保题目的创新性和挑战性。实验证明,AMO-Bench能够有效区分当前最先进大语言模型的数学推理能力极限。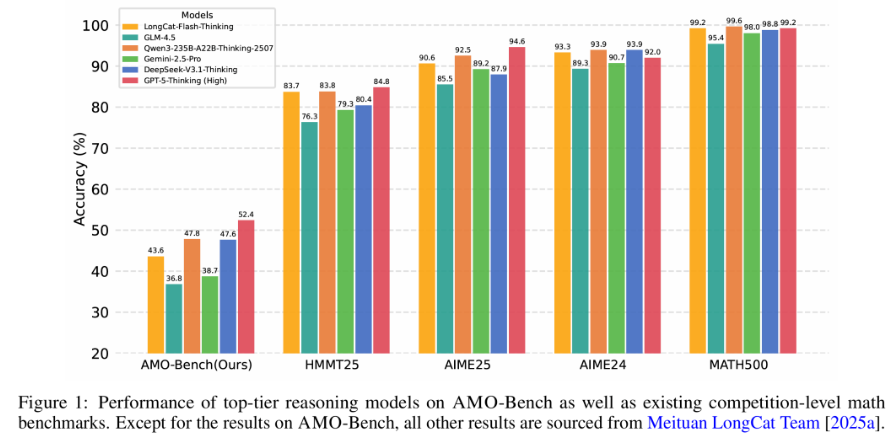
图1将几个主流大模型在AMO-Bench、MATH500和AIME24等多个数学基准上的表现进行了横向对比,结果清晰显示,所有模型在AMO-Bench上的准确率都远低于其他基准,这直观地证明了AMO-Bench作为一套全新的、极高难度的题目,成功打破了传统基准已出现的“性能饱和”局面,能够有效地区分和检验出模型真正的数学推理极限。
2 研究背景与动机
2.1 现有评估基准的局限性
当前数学推理评估主要面临三个核心问题:
性能饱和现象:在AIME、MATH等传统基准上,顶尖模型的表现已接近或超越人类平均水平,使得这些基准失去了区分不同模型能力的作用。
数据污染问题:公开可得的竞赛题目很可能已被纳入模型的训练数据,导致评估结果无法准确反映模型的真实推理能力。
评估效率低下:证明类题目需要专家人工评审,过程耗时且难以保证评分一致性,不利于大规模自动化评估。
2.2 AMO-Bench的设计目标
AMO-Bench旨在建立一个具有以下特征的数学推理基准:
- 高挑战性:题目难度达到IMO竞赛水平
- 原创性保证:所有题目均为首次发布
- 自动化评估:支持高效、客观的评分机制
- 全面覆盖:涵盖数学推理的主要领域
3 AMO-Bench基准构建
3.1 题目构建流程
AMO-Bench的构建采用四阶段质量控制流程: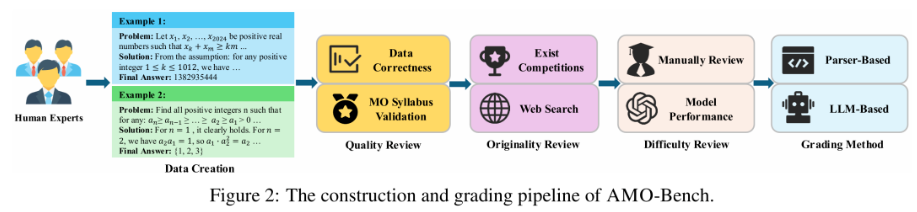
图2以流程图的形式,清晰地展示了AMO-Bench数据集从无到有的严谨构建过程,它经历了专家命题、质量审查、原创性审查和难度审查四重严格关卡。同时,它也展示了针对不同答案类型(如数值、集合、表达式等)所设计的自动化评分流程,体现了评估方法的高效与可靠。
阶段一:专家命题
- 由国际数学奥林匹克竞赛金牌得主和资深命题专家参与设计
- 每道题目配备详细的标准解答和推理路径说明
阶段二:质量审查
- 采用双盲评审机制,至少3位专家独立审核
- 确保题目表述无歧义,逻辑严密,符合IMO知识范围
阶段三:原创性验证
- 基于10-gram匹配技术与现有数据集进行相似度分析
- 结合网络搜索和专家判断,确保题目唯一性
阶段四:难度校准
- 人类专家确认题目难度达到IMO标准
- 要求至少两个顶级大语言模型在三次测试中均未能正确解答
3.2 题目分布与特征
AMO-Bench涵盖五个核心数学领域: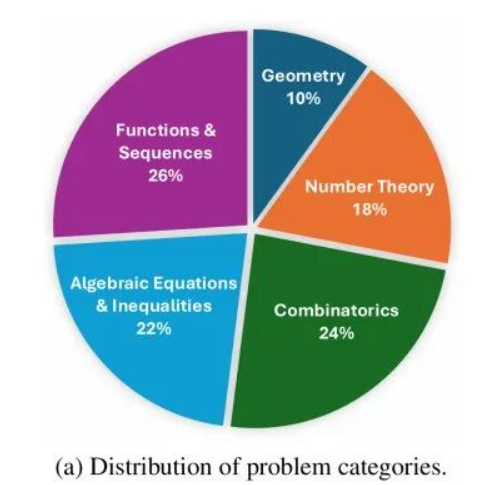
- 函数与数列(26%):13道题目,重点考察递推关系和高阶变换
- 组合数学(24%):12道题目,涵盖计数原理、图论和极值问题
- 代数方程与不等式(22%):11道题目,涉及高次方程和多元不等式
- 数论(18%):9道题目,聚焦同余理论和丢番图方程
- 几何(10%):5道题目,主要考察复杂几何构造
用DeepSeek-V3.1的tokenizer统计显示,AMO-Bench的人工解答平均token数远高于MATH500和AIME24。这意味着这些题目不仅需要更多推理步骤,更需要深层次的策略性思考,而非简单的模式匹配。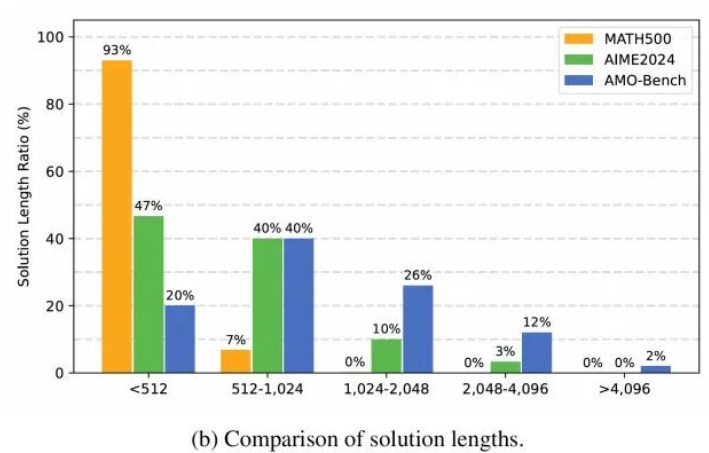
图3(b)图通过对比AMO-Bench与MATH500、AIME24数据集中人工解答的篇幅长度,从侧面印证了AMO-Bench的题目需要更复杂、更冗长的推理步骤,其解答长度远超传统基准。
3.3 评估方法论
针对不同类型的题目答案,设计了差异化的评分策略:
- 数值答案:采用语法解析器自动验证
- 集合答案:基于集合论原理进行自动化比对
- 表达式答案:通过多组赋值测试验证等价性
- 描述性答案:采用大语言模型辅助评分,基于多数投票原则
该评估方法的总体准确率达到99.2%,在保证效率的同时确保了评分的可靠性。
4 实验结果与分析
4.1 模型性能比较
文章在26个主流大语言模型上进行了全面评估,包括OpenAI、Google、Anthropic、DeepSeek、Qwen和GLM等系列模型。采用AVG@32(32次采样平均)作为主要评估指标,结果显示:
- 最佳表现模型GPT-5-Thinking(High)的准确率为52.4%
- 开源模型Qwen3-235B-A22B-Thinking-2507达到47.8%的准确率
- 多数模型的准确率低于40%,部分非推理专用模型不足10%
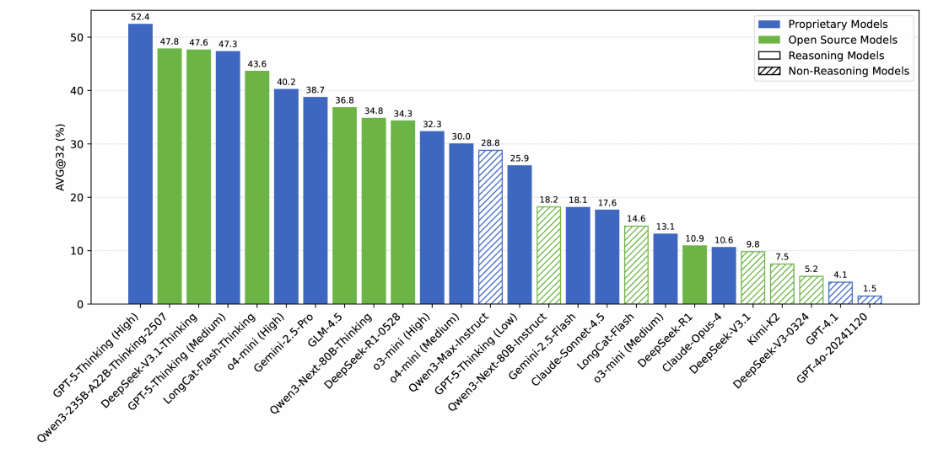
图4汇总了26个主流大模型在AMO-Bench上的评测结果,可以看到即使是表现最好的GPT-5-Thinking模型,其准确率也刚过50%,而绝大多数模型的得分低于40%,这一结果表明:它们在面对顶级奥数难题时依然存在巨大挑战。
4.2 关键发现
4.2.1 输出长度与性能相关性
研究发现,模型性能与输出token数量呈现显著正相关:
- 第一梯队模型(准确率>40%)的平均输出长度超过35K tokens
- GPT-5-Thinking在AMO-Bench上的平均输出长度(37K tokens)是其在AIME25上(7K tokens)的5倍以上
这一现象表明,复杂数学问题需要模型构建更长的推理链条,进行更深层次的思考。
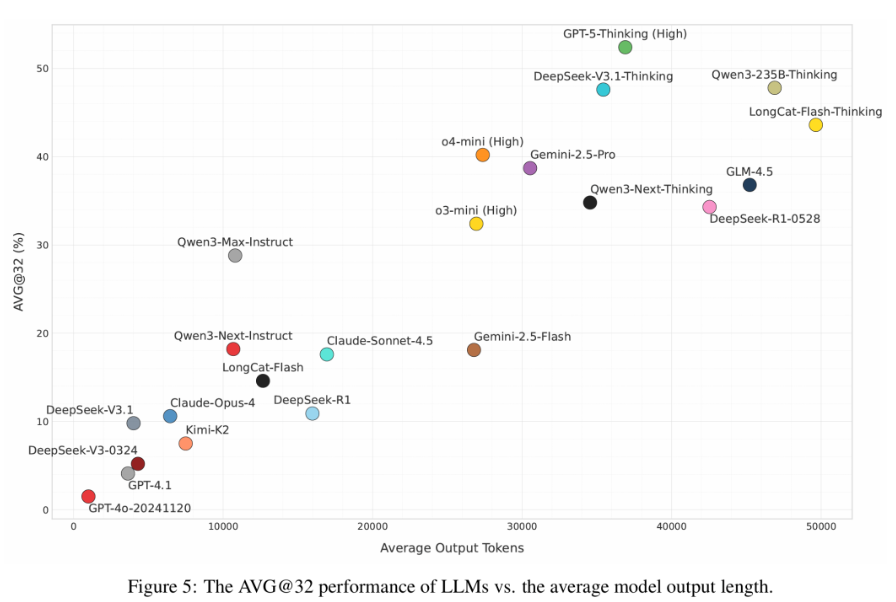
图5揭示了模型在AMO-Bench上的性能与其平均输出长度之间的强正相关关系,即表现越好的模型,在解题时“说的话”或“写的推理步骤”也越多,这说明解决高难度题目需要模型进行更深入、更耗时的“思考”,输出长度因而成为衡量其推理努力程度的一个关键指标。
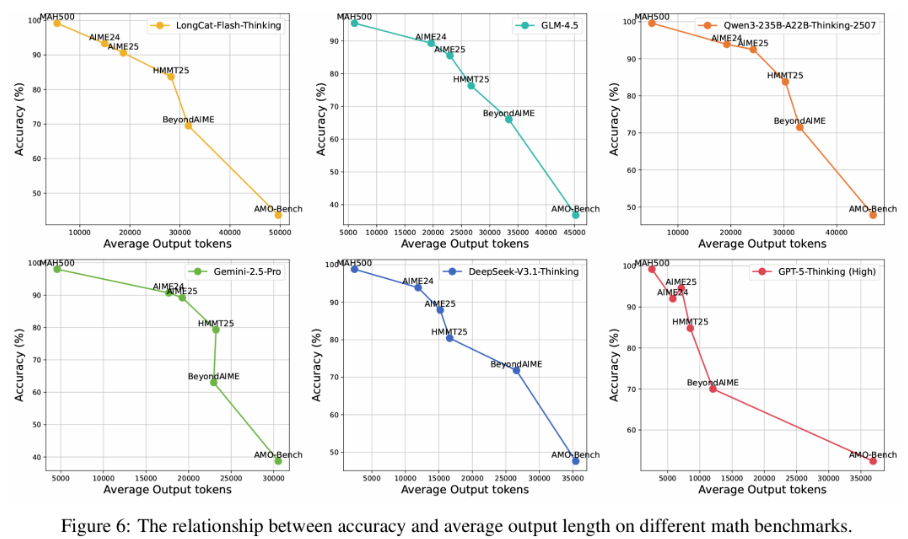
图6将不同数学基准(如AIME24, MATH500, AMO-Bench)的模型平均准确率和平均输出长度联系起来,形成一个分布,AMO-Bench独自处在“低准确率、高输出长度”的角落,这从结果上反向证明了该基准的题目难度最高,迫使模型消耗最多的计算资源(生成了最长的文本)却依然取得最低的正确率。
4.2.2 测试时扩展效应
通过控制模型的推理强度(如GPT-5的low/medium/high模式),观察到性能与输出长度的对数近似线性相关。这表明当前模型的主要限制并非能力上限,而是计算资源分配不足。
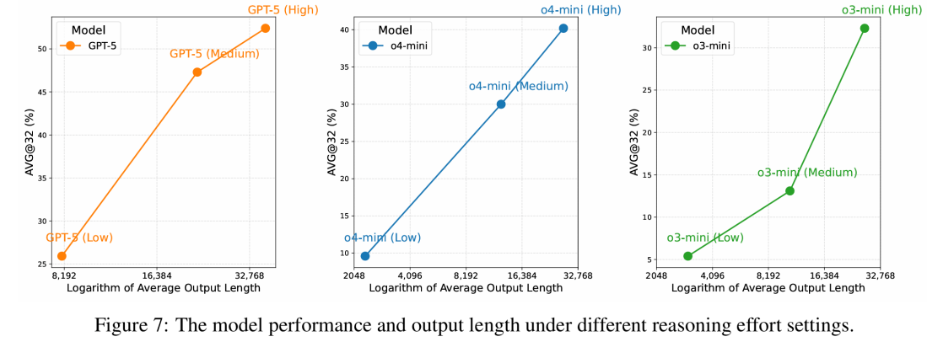
图7展示了模型性能会随着其输出长度的对数增加而呈现近乎线性的增长趋势
4.2.3 潜在能力分析
pass@k曲线分析显示,当k=32时,顶级推理模型的pass@k值超过70%(GPT-5-Thinking达到86.0%)。这表明模型具备解决这些问题的潜力,但需要更有效的推理路径搜索策略。
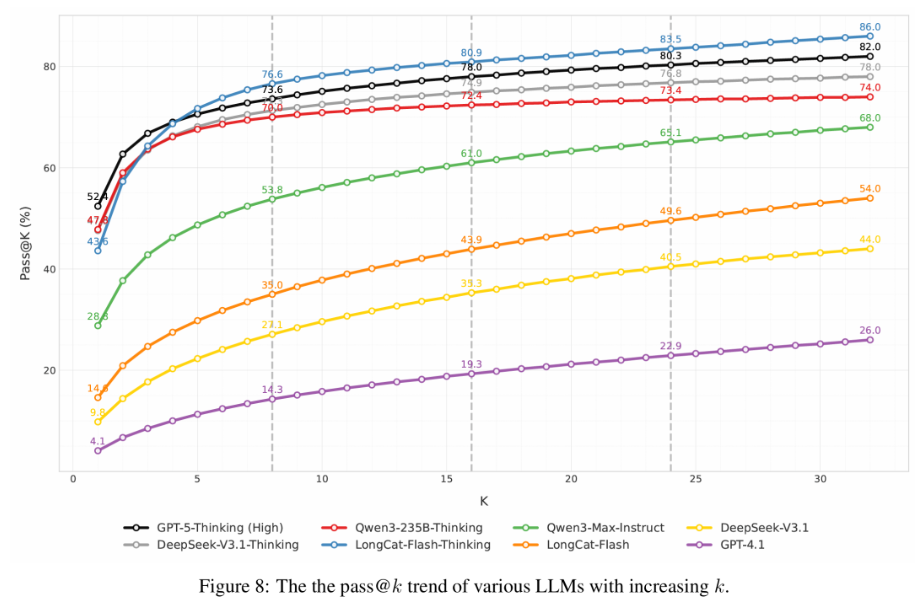
趋势图8描绘了不同模型的“pass@k”指标如何随着采样次数k的增加而变化,揭示了当前模型并非“不会做”,而是无法稳定地找到正确路径,其内在潜力仍有待通过后续技术(如强化学习)来激发。
5 AMO-Bench-P子集
为促进研究复现和广泛应用,团队发布了AMO-Bench-P子集,包含39道支持全自动解析的题目。该子集在保持挑战性的同时,提供了更高的评估效率。
以下是部分模型在全量数据集和子集上的性能对比:
| 模型 | AMO-Bench(全量) | AMO-Bench-P(子集) |
|---|---|---|
| GPT-5-Thinking (High) | 52.4% | 54.8% |
| Qwen3-235B-A22B-Thinking-2507 | 47.8% | 56.2% |
| DeepSeek-V3.1-Thinking | 47.6% | 53.0% |
| LongCat-Flash-Thinking | 43.6% | 45.3% |
| o4-mini (High) | 40.2% | 43.8% |
6 结论与展望
AMO-Bench基准的建立为解决大语言模型数学推理评估的三大挑战提供了有效方案。实验结果表明,当前最先进的大语言模型在面对真正具有挑战性的数学问题时仍存在显著差距。
未来,团队将持续扩展题目库,增加更多推理赛道,推动数学推理评估标准的不断提升。同时,通过优化推理策略、增加计算预算和改进训练方法,大语言模型的数学推理能力仍有巨大提升空间。
🚗🤖 这是我们的官方 GitHub 仓库!汇总了自动驾驶与机器人领域前沿资源,涵盖 VLM/VLA 技术、端到端模型、SLAM 方案等,同步公众号「智驾与机器人前瞻局」内容,论文 + 代码 + 解析一键获取→ 👉
https://github.com/YangHRandLiuZ/Autonomous-Driving-Robot-Frontier-Learning
欢迎 PR 补充,一起完善这个学习库!也麻烦给我们的仓库点上一个小⭐⭐,这对我们真的很重要!感谢你的支持~
别急着走!搜索并关注“智驾和机器人前瞻局”公众号。更多优质内容等你来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)