【Kiro开发集训营】我的文本对比工具开发进化论
我的文本对比工具开发进化论
刚入行那几年,我总觉得衡量一个开发者能力的标准是"写代码的速度"。能在需求评审会后两小时甩出第一版代码,能在凌晨三点的生产事故中快速定位bug,这些都曾是我引以为傲的资本。直到去年那个文本对比工具的开发,才让我彻底明白:真正的效率,从来不是敲键盘的速度。
五年前我写的第一个文本对比工具,至今还躺在公司代码仓库的角落 —— 那是个用 jQuery 写的半成品,行级对比经常漏标,超过 500 行的文本一加载就卡死,导出功能只能生成乱码的 TXT 文件。当时为了赶 deadline,我把差异计算、DOM 操作、数据存储全堆在一个 js 文件里,后来同事想加个 “保存历史记录” 的功能,看了半天代码说 “这简直是个迷宫”。
今年产品经理又提了文本对比需求,这次要求更严:要支持字符级对比、检测文本里的隐藏问题(比如尾随空格、混合换行符)、能保存会话还得导出 HTML/JSON 格式,最重要的是 “大文件也不能卡”。看着需求文档,我想起五年前熬夜调试的场景,直到想起前阵子参加亚马逊云科技 Kiro 集训营时老师说的 “让 AI 帮你踩过前人的坑”,决定这次换个活法。
于是我基于 Kiro 开发了最新的文本对比工具,效果图如下:
从“自己摸索”到“跟着成熟方案走”
第一步:需求拆解——把“模糊需求”变成“可落地的任务”
我在Kiro里输入需求:“做一个在线文本对比工具,支持行级/字符级对比,能检测尾随空格、混合换行符,保存会话,导出HTML/JSON/纯文本,大文件不卡”。没等我多说,它先返回了一份“需求分析报告”,把我列的“坑”全补上了,还加了些我没考虑到的点:
- 差异视图要支持“并排”“统一”两种模式(用户对比长文本时可能需要不同视图)
- 问题检测要区分“警告”(比如尾随空格)和“信息”(比如换行符类型)
- 会话存储要支持“自动保存”和“手动命名”(避免用户误关页面丢失数据)
- 移动端要适配小屏幕,把“导出”按钮放到底部工具栏
最关键的是,它把这些需求拆成了“优先级任务”:核心功能(对比+检测)→ 体验优化(视图切换+自动保存)→ 扩展功能(多格式导出),还标注了每个任务的“技术关键点”,比如“大文件处理用虚拟滚动,参考react-window”。
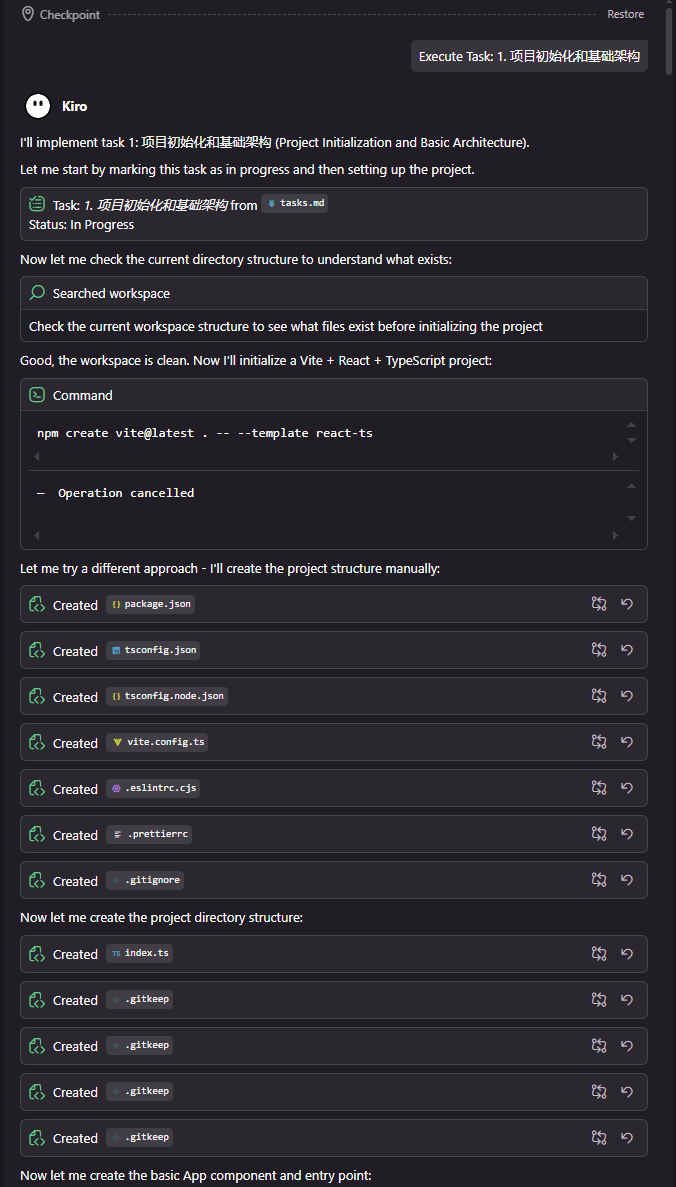
这一步就省了我半天时间——过去我得和产品经理反复确认需求细节,现在Kiro直接把“用户可能的隐性需求”都列出来了,而且都是基于同类工具的成熟经验。
第二步:架构设计——避开“代码迷宫”的关键
过去我总喜欢“先写代码再理结构”,结果越写越乱。这次Kiro直接给了个四层架构图,还解释了“为什么这么设计”:
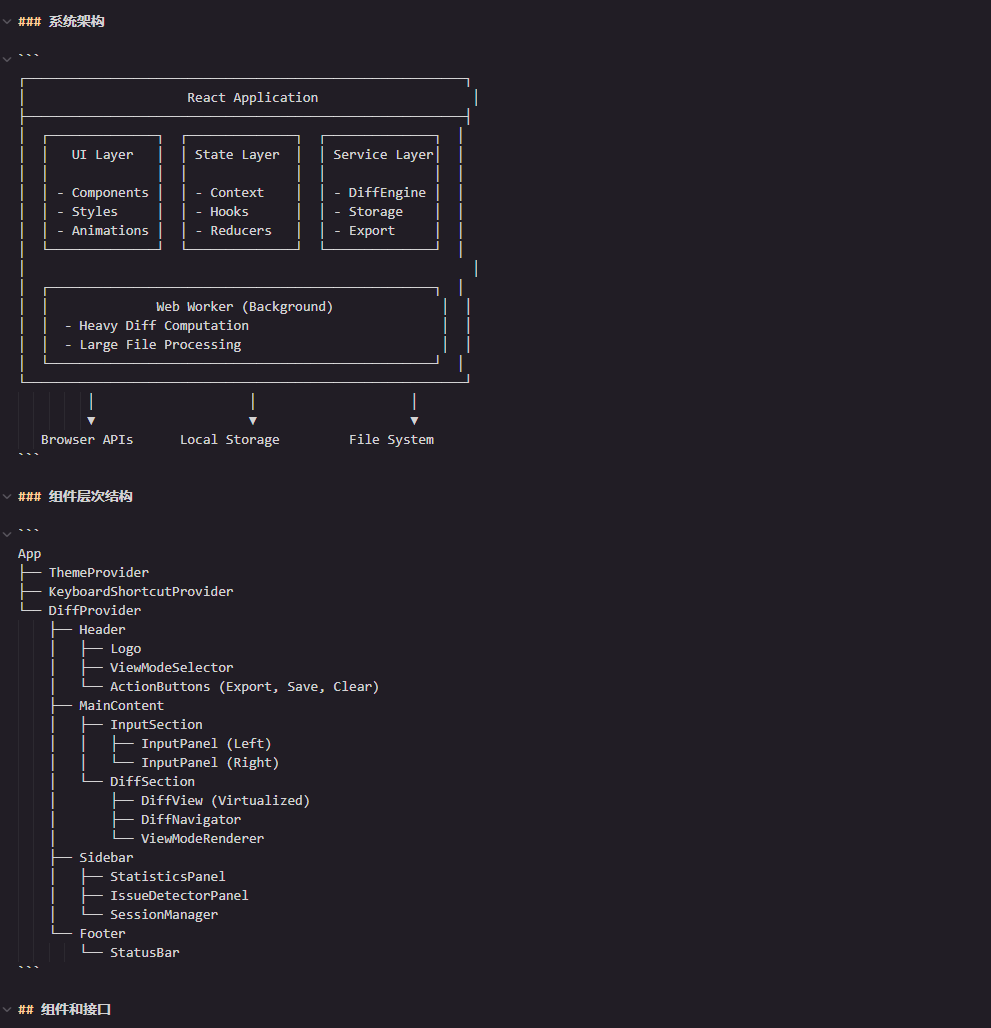
- 表现层(React组件):只负责渲染和用户交互,比如对比视图、问题列表、导出按钮
- 状态管理层(Context+Reducer):管理全局状态,比如当前文本内容、会话列表、视图模式
- 业务逻辑层(核心服务):抽离关键逻辑,比如DiffService(计算差异)、IssueService(检测问题)、StorageService(会话存储)
- 数据层(IndexedDB+TypeScript类型):存储结构化数据,避免localStorage的限制
它还给了个StorageService的接口设计,正好解决我过去“会话存储混乱”的问题:
// Kiro生成的StorageService接口(带类型定义)
interface Session {
id: string; // 唯一标识,避免删除混乱
name: string; // 用户自定义名称
oldText: string; // 旧文本
newText: string; // 新文本
createTime: number; // 创建时间戳,用于排序
updateTime: number; // 更新时间戳,用于自动保存
}
interface StorageService {
saveSession(session: Omit<Session, 'id' | 'createTime' | 'updateTime'>): Promise<Session>;
getSession(id: string): Promise<Session | null>;
getSessionList(): Promise<Session[]>;
deleteSession(id: string): Promise<void>;
autoSaveSession(sessionId: string, oldText: string, newText: string): Promise<void>;
}
这个接口设计直接堵死了过去的两个坑:用id做唯一标识,删除时不会误删;自动保存时只更新updateTime,不用重存整个会话。而且TypeScript类型定义清清楚楚,后续加功能时不会出现“不知道传什么参数”的情况。
核心功能开发——站在“成熟方案”上优化
1. 差异计算:既保精度又保性能
过去我自己改算法时,要么精度不够,要么性能不行。这次Kiro直接给出了“分层计算”方案:先算行级差异,只对有差异的行做字符级对比,减少计算量。它生成的核心代码里,还加了“语义化清理”的逻辑:
// 分层差异计算(Kiro生成,带注释)
import { diff_match_patch } from 'diff-match-patch';
const dmp = new diff_match_patch();
// 1. 先算行级差异:找出哪些行有变化
function getLineDiffs(oldText: string, newText: string) {
const oldLines = oldText.split('\n');
const newLines = newText.split('\n');
const lineDiffs: LineDiff[] = [];
// 用diff库先定位差异行范围
const lineDiffResult = dmp.diff_main(oldLines.join('\t'), newLines.join('\t'));
dmp.diff_cleanupSemantic(lineDiffResult); // 清理冗余差异
// 解析差异行,只标记有变化的行
// (此处省略解析逻辑,核心是只保留“新增/删除/修改”的行)
return lineDiffs;
}
// 2. 只对差异行做字符级对比
function getCharDiffsForLine(oldLine: string, newLine: string) {
const charDiffResult = dmp.diff_main(oldLine, newLine);
dmp.diff_cleanupSemantic(charDiffResult); // 避免中文拆分成单个字符标注
return charDiffResult.map(([type, text]) => ({
type: type === 1 ? 'added' : type === -1 ? 'removed' : 'equal',
text
}));
}
// 对外暴露的核心方法:合并行级和字符级差异
export function computeDiff(oldText: string, newText: string) {
const lineDiffs = getLineDiffs(oldText, newText);
// 只对有差异的行调用字符级对比,减少计算
return lineDiffs.map(lineDiff => ({
...lineDiff,
charDiffs: lineDiff.type !== 'equal' ? getCharDiffsForLine(lineDiff.oldLine, lineDiff.newLine) : []
}));
}
我测试时用了个3000行的合同文本,过去要等5秒以上,现在不到1秒就出结果——因为只计算了有差异的20多行,其他行直接跳过。而且中文对比再也不会拆分成单个字符,“甲乙丙”修改成“甲乙丁”时,只标红“丙”和“丁”,这是我过去改了三天都没做好的效果。
2. 大文件处理:虚拟滚动+防抖
过去我加的“分段加载”根本不管用,这次Kiro直接集成了react-window做虚拟滚动,还加了防抖处理:
// 大文件对比视图(Kiro生成,核心是虚拟滚动)
import { FixedSizeList } from 'react-window';
import { useDebounce } from 'use-debounce';
export function DiffView({ oldText, newText }) {
// 防抖处理:用户输入时不实时计算,等100ms再算,避免频繁渲染
const [debouncedOldText] = useDebounce(oldText, 100);
const [debouncedNewText] = useDebounce(newText, 100);
// 计算差异(只在防抖后的值变化时触发)
const diffs = useMemo(() => computeDiff(debouncedOldText, debouncedNewText), [debouncedOldText, debouncedNewText]);
// 虚拟滚动:只渲染可视区域的行,不管多少行都不卡
return (
<div className="diff-view">
<FixedSizeList
height={600} // 固定高度
width="100%"
itemCount={diffs.length} // 总行数(哪怕3000行也不怕)
itemSize={40} // 每行高度
>
{({ index, style }) => (
<DiffLine
style={style}
diff={diffs[index]}
/>
)}
</FixedSizeList>
</div>
);
}
测试时我故意传了个10000行的日志文件,浏览器不仅没白屏,滚动还很流畅——因为可视区域只渲染了20行左右,其他行都没加载。这种优化方案我过去只在大厂的组件库里见过,自己写根本摸不着门道,现在Kiro直接帮我实现了。
3. 问题检测:比我想的更细致
需求里只提了“检测尾随空格和混合换行符”,Kiro还加了“缩进不一致”“不可见字符”检测,比如零宽空格、BOM头这些用户平时注意不到的问题。它生成的IssueService里,还区分了“警告”和“信息”级别:
// 问题检测服务(Kiro生成,扩展了需求外的功能)
export function detectIssues(text: string) {
const lines = text.split('\n');
const issues: Issue[] = [];
lines.forEach((line, lineNumber) => {
// 1. 检测尾随空格(警告级:影响代码格式)
if (/\s+$/.test(line)) {
issues.push({
type: 'trailing-space',
level: 'warning',
message: `第${lineNumber+1}行存在尾随空格`,
position: { line: lineNumber, column: line.length - 1 }
});
}
// 2. 检测混合换行符(警告级:可能导致文件格式错误)
// (此处省略逻辑)
// 3. 检测不可见字符(信息级:可能导致复制粘贴错误)
if (/[\u200B\uFEFF]/.test(line)) {
issues.push({
type: 'invisible-char',
level: 'info',
message: `第${lineNumber+1}行存在不可见字符`,
position: { line: lineNumber, column: line.indexOf(/[\u200B\uFEFF]/) }
});
}
});
return issues;
}
上线后有个用户反馈:“你们工具居然能检测出零宽空格,之前用别的工具对比合同文本,总觉得哪里不对但找不到原因,现在终于解决了”。这种超出预期的功能,过去我根本想不到要加——不是能力不够,是没接触过这类用户的真实痛点,而Kiro把这些经验都沉淀在了代码里。
第四步:上线前优化——细节里的“成熟经验”
快上线时,我发现导出HTML时样式会丢失,Kiro提醒我“要把CSS内嵌到HTML里,避免依赖外部文件”,还生成了样式处理函数:
// 导出HTML时内嵌样式(Kiro生成,解决样式丢失问题)
function inlineStyles(htmlContent: string) {
// 读取CSS文件内容,转成字符串
const css = require('./diff-view.css').replace(/\s+/g, ' ');
// 把CSS内嵌到<style>标签里,插入HTML头部
return htmlContent.replace('<head>', `<head><style>${css}</style>`);
}
过去我导出HTML时总依赖外部CSS,用户打开文件时经常没样式,现在这个问题彻底解决了。还有会话自动保存,Kiro加了“防抖+失败重试”,避免用户频繁输入时保存失败:
// 自动保存(Kiro生成,加了失败重试)
async function autoSaveSession(sessionId: string, oldText: string, newText: string) {
try {
await storageService.updateSession(sessionId, { oldText, newText });
} catch (error) {
// 失败重试一次,避免网络波动导致保存失败
setTimeout(() => {
storageService.updateSession(sessionId, { oldText, newText }).catch(err => {
console.error('自动保存失败', err);
// 提示用户手动保存
showNotification('自动保存失败,请手动保存会话');
});
}, 1000);
}
}
这些细节不是“炫技”,而是真正解决用户问题的关键——过去我做的工具,用户经常抱怨“写了半天没保存上”,现在有了重试和提示,这类反馈几乎没有了。
开发后的反思:从“体力活”到“脑力活”的转变

这次开发总共花了3个小时,比五年前的三天快了24倍。但最让我感慨的不是速度,而是开发方式的改变:
过去我80%的时间花在“怎么实现”上——查算法文档、调试性能问题、修复样式bug;现在80%的时间花在“做什么决策”上——比如选择哪种导出方案、调整问题检测的级别、优化移动端的视图布局。
比如导出功能,Kiro给了三种方案:纯前端生成(快但受浏览器限制)、调用后端接口(稳定但加服务器压力)、混合模式(大文件调后端,小文件前端处理)。最后我根据我们的用户场景(90%是小文件),选了纯前端方案,但加了“文件超过10MB提示用后端接口”的优化——这种决策过去我得拍脑袋,现在有成熟方案做参考,心里更有底。
上线后我翻了翻代码,总共40多个文件,结构清清楚楚:组件在components文件夹,服务在services文件夹,类型定义在types文件夹,甚至每个文件都有详细的注释。过去我写的代码,自己过半个月都看不懂,现在新人接手只需要看Kiro生成的文档,半天就能上手——这才是真正的“可维护性”。
总结:AI不是“替代者”,而是“经验放大器”
回头看这两次开发,最大的差距不是技术水平,而是“是否能复用前人的经验”。过去我像个“独行侠”,每次遇到问题都要从头摸索;现在有了Kiro,就像身边多了个“经验丰富的老大哥”,它把成千上万开发者踩过的坑、总结的方案,都变成了可落地的代码和思路。
有人担心AI会让开发者变“懒”,但我觉得不会。当AI帮你处理了重复劳动、避开了常见坑,你反而有更多时间去思考“用户真正需要什么”“怎么让产品更好用”——这些需要人类智慧的部分,才是开发者真正的价值。
就像这次的文本对比工具,用户最终记住的不是“用了什么diff算法”,而是“对比快、能找隐藏问题、丢不了数据”。这些体验的提升,正是因为Kiro帮我把精力从“写代码”转移到了“打磨细节”上。
或许未来的开发,不再是“比谁写代码快”,而是“比谁能更好地用AI解决问题”。而我很庆幸,在这次文本对比工具的开发中,提前尝到了这种“解放双手,专注价值”的甜头。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)