MySQL(七) - 索引管理
本文围绕 MySQL 索引展开,先介绍索引本质、作用、特点、底层 B + 树结构及适用与不适用场景,再分类说明按功能、物理存储、字段数量划分的索引类型及选择建议。接着提供数据准备的 SQL 脚本,最后详细阐述索引管理操作,包括创建(建表时与建表后)、查看(SHOW INDEX 与 EXPLAIN 分析)、修改(删除旧索引重建新索引)和删除(单索引与批量删除)的语法、参数解释及实操示例,助力优化数据
一、索引介绍
在MySQL数据库中,索引(Index)是一种特殊的数据结构,它与数据表关联,用于快速定位和访问表中的数据。形象地说,索引就像书籍的目录——通过目录可以直接找到目标章节,而无需逐页翻阅;同理,通过索引可以避免全表扫描,大幅提升查询效率。
1. 索引的本质与作用
索引的核心本质是为数据建立有序的检索路径,其主要作用包括:
- 加速查询速度:通过索引可以快速定位符合条件的数据行,尤其在大数据量的表中,查询效率提升显著。
- 减少数据扫描范围:索引会对字段值进行排序和存储,查询时只需扫描索引结构而非整个表,降低IO操作成本。
- 支持排序与分组:若查询包含
ORDER BY或GROUP BY,且排序/分组字段已建立索引,MySQL可直接利用索引的有序性避免额外排序,提高处理效率。
2. 索引的特点
- 空间换时间:索引需要额外的磁盘空间存储(类似书籍目录会占用一定页数),但换来的是查询速度的提升。
- 会影响写操作效率:当对表执行
INSERT、UPDATE、DELETE时,MySQL不仅要修改数据,还要同步维护索引结构(如插入新值时更新索引排序),因此过多的索引会降低写操作性能。 - 并非万能:对于数据量极小的表(如几十行数据),全表扫描可能比索引查询更快;对于频繁修改的字段,建立索引可能得不偿失。
3. 索引的底层数据结构
MySQL中最常用的索引类型基于B+树数据结构实现(InnoDB存储引擎默认),其特点如下:
- 层级低:B+树是一种平衡多路查找树,通常3-4层即可存储数百万条数据,查询时只需3-4次磁盘IO,效率极高。
- 有序性:B+树的叶子节点按字段值有序排列,且通过指针串联,便于范围查询(如
BETWEEN、>=等条件)。 - 聚簇索引特性:InnoDB的聚簇索引(主键索引)叶子节点直接存储整行数据,而非聚簇索引(二级索引)叶子节点存储主键值,查询时需通过主键回表获取完整数据。
4. 索引的适用场景
- 频繁查询的字段:如用户表的
user_id、订单表的order_no等频繁作为查询条件的字段。 - 关联查询的字段:如外键字段(如
student_course表的student_id和course_id),用于多表JOIN时加速关联。 - 排序/分组的字段:如需要按
create_time排序或按major分组的查询,对这些字段建立索引可避免额外排序。 - 区分度高的字段:如身份证号(几乎唯一)比性别(仅“男/女”)更适合建索引,区分度低的字段索引效率差。
5. 索引的不适用场景
- 数据量极小的表:全表扫描效率已足够,无需额外维护索引。
- 频繁更新的字段:每次更新都会触发索引重建,增加性能开销。
- 查询中不使用的字段:建立索引会浪费空间且影响写性能。
- 区分度极低的字段:如“状态”字段(仅0/1),索引过滤效果差,可能仍需扫描大量数据。
二、索引类型
MySQL支持多种类型的索引,不同类型的索引适用于不同的场景,了解其特性有助于合理设计索引策略。以下是常见的索引类型及特点:
1. 按功能划分
1.1 主键索引(Primary Key)
- 定义:用于唯一标识表中的每一行记录,一张表只能有一个主键索引,且主键字段不允许为
NULL。 - 特点:
- 自动具备唯一性约束,确保字段值不重复。
- InnoDB存储引擎中,主键索引是聚簇索引,其叶子节点直接存储整行数据,查询效率最高。
- 若表中未显式定义主键,InnoDB会自动生成一个隐藏的自增主键(6字节)作为聚簇索引。
1.2 唯一索引(Unique Index)
- 定义:用于保证字段值的唯一性,但允许字段为
NULL(一张表可以有多个唯一索引,且多个NULL值视为不重复)。 - 特点:
- 与主键索引的区别:唯一索引允许
NULL,且一张表可创建多个。 - 常用于需要唯一标识但不作为主键的字段(如学号、手机号等)。
- 与主键索引的区别:唯一索引允许
1.3 普通索引(Normal Index)
- 定义:最基础的索引类型,仅用于加速查询,不附加任何约束(允许重复值和
NULL)。 - 特点:
- 无唯一性限制,适合频繁作为查询条件但无需唯一约束的字段(如姓名、专业等)。
- 是使用最广泛的索引类型,创建和维护成本较低。
1.4 全文索引(Fulltext Index)
- 定义:用于对长文本字段(如
TEXT、VARCHAR)进行全文检索,支持关键词匹配,不适合精确查询。 - 特点:
- 仅支持
InnoDB和MyISAM存储引擎,且仅适用于CHAR、VARCHAR、TEXT类型字段。 - 查询时需使用
MATCH() AGAINST()语法,而非普通的LIKE(LIKE '%关键词%'无法利用全文索引)。
- 仅支持
2. 按物理存储划分
2.1 聚簇索引(Clustered Index)
- 定义:索引的叶子节点直接存储整行数据,索引与数据物理存储在一起。
- 特点:
- InnoDB中,主键索引默认是聚簇索引;若未定义主键,则选择唯一索引作为聚簇索引;若均无,则生成隐藏聚簇索引。
- 数据行的物理顺序与索引顺序一致,因此聚簇索引查询效率极高(无需回表)。
- 一张表只能有一个聚簇索引。
2.2 非聚簇索引(Non-Clustered Index)
- 定义:索引的叶子节点存储的是主键值(而非整行数据),索引与数据物理存储分离。
- 特点:
- 除聚簇索引外的所有索引(如唯一索引、普通索引)均为非聚簇索引,也称为“二级索引”。
- 查询时需先通过非聚簇索引找到主键,再通过聚簇索引获取完整数据(称为“回表”),效率略低于聚簇索引。
- 示例:若
student表的student_id是聚簇索引,则student_no的唯一索引为非聚簇索引,其叶子节点存储student_id的值。
3. 按字段数量划分
3.1 单列索引(Single-Column Index)
- 定义:基于单个字段创建的索引,适用于查询条件仅涉及该字段的场景。
3.2 联合索引(Composite Index)
- 定义:基于多个字段联合创建的索引,索引的排序顺序遵循“最左前缀原则”(即优先按第一个字段排序,再按第二个字段,以此类推)。
- 特点:
- 适用于查询条件包含多个字段的场景(如
WHERE major = '计算机' AND gender = '男')。 - 需注意字段顺序:区分度高的字段应放在前面,可提高索引过滤效率。
- 适用于查询条件包含多个字段的场景(如
4. 索引类型选择建议
- 频繁作为
WHERE条件、JOIN关联、ORDER BY/GROUP BY的字段,优先考虑创建索引。 - 唯一标识字段(如学号、身份证号)使用唯一索引,避免重复数据。
- 多字段组合查询优先使用联合索引,并合理安排字段顺序。
- 长文本检索使用全文索引,替代低效的
LIKE '%...%'查询。 - 避免过度创建索引,尤其是写入频繁的表,需平衡查询与写入性能。
三、准备数据
-- 创建数据库
CREATE DATABASE IF NOT EXISTS test001;
-- 切换数据库
USE test001;
-- 删除数据表
DROP TABLE IF EXISTS student_course;
DROP TABLE IF EXISTS student;
DROP TABLE IF EXISTS course;
-- 1. 学生表(主表)
CREATE TABLE IF NOT EXISTS `student` (
student_id INT NOT NULL AUTO_INCREMENT COMMENT '学生ID(主键)',
student_no VARCHAR(20) NOT NULL COMMENT '学号(唯一标识,如2024001)',
student_name VARCHAR(50) NOT NULL COMMENT '学生姓名',
gender CHAR(1) NOT NULL COMMENT '性别(男/女)',
birth_date DATE NULL COMMENT '出生日期',
major VARCHAR(50) NOT NULL COMMENT '所属专业',
enroll_date DATE NOT NULL COMMENT '入学时间',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
-- 列级约束
PRIMARY KEY (student_id),
UNIQUE KEY uk_student_no (student_no), -- 学号唯一
CHECK (gender IN ('男', '女')) -- 限制性别只能是男或女
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_general_ci
AUTO_INCREMENT = 1001 -- 学生ID从1001开始
COMMENT = '学生信息表';
-- 先删除已存在的同名存储过程(避免冲突)
DROP PROCEDURE IF EXISTS insert_student_batch;
-- 核心修正:DELIMITER 只在存储过程定义前后修改,内部不修改
DELIMITER // -- 将语句结束符临时改为//
CREATE PROCEDURE insert_student_batch()
BEGIN
DECLARE i INT DEFAULT 0; -- 循环计数器
DECLARE base_no INT DEFAULT 202400001; -- 学号起始值(202400001开始)
DECLARE name_prefix VARCHAR(10); -- 姓名前缀(模拟不同姓名)
DECLARE gender CHAR(1); -- 性别
DECLARE major_arr VARCHAR(200); -- 专业列表(用逗号分隔)
DECLARE major VARCHAR(50); -- 随机选的专业
DECLARE birth_date DATE; -- 出生日期(1998-2005年随机)
DECLARE enroll_date DATE; -- 入学时间(2024年随机)
-- 初始化专业列表(可根据需要扩展)
SET major_arr = '计算机科学与技术,软件工程,人工智能,电子信息工程,自动化,财务管理,汉语言文学,法学,英语,临床医学';
-- 循环插入10万条数据
WHILE i < 100000 DO
-- 1. 随机生成姓名(前缀+数字,模拟不同姓名)
SET name_prefix = ELT(FLOOR(1 + RAND() * 20),
'张','李','王','刘','陈','杨','赵','黄','周','吴',
'徐','孙','胡','朱','高','林','何','郭','马','罗');
SET @student_name = CONCAT(name_prefix, FLOOR(RAND() * 999));
-- 2. 随机性别(男/女)
SET gender = IF(RAND() > 0.5, '男', '女');
-- 3. 随机出生日期(1998-01-01 到 2005-12-31)
SET birth_date = DATE_ADD('1998-01-01', INTERVAL FLOOR(RAND() * 2922) DAY);
-- 4. 随机专业(从专业列表中取)
SET major = SUBSTRING_INDEX(SUBSTRING_INDEX(major_arr, ',', FLOOR(1 + RAND() * 10)), ',', -1);
-- 5. 入学时间(2024-09-01 前后随机)
SET enroll_date = DATE_ADD('2024-09-01', INTERVAL FLOOR(RAND() * 30) - 15 DAY);
-- 6. 插入数据(学号=起始值+计数器,保证唯一)
INSERT INTO student (
student_no, student_name, gender, birth_date, major, enroll_date
) VALUES (
CONCAT(base_no + i), -- 学号:202400001、202400002...
@student_name,
gender,
birth_date,
major,
enroll_date
);
SET i = i + 1; -- 计数器+1
END WHILE;
END // -- 存储过程定义结束(用//作为结束符)
DELIMITER ; -- 恢复默认的语句结束符为;
SET AUTOCOMMIT = 0; -- 关闭自动提交
ALTER TABLE student DISABLE KEYS; -- 关闭非主键索引
-- 执行存储过程插入10万条数据
CALL insert_student_batch();
COMMIT; -- 手动提交事务
SET AUTOCOMMIT = 1; -- 恢复自动提交
ALTER TABLE student ENABLE KEYS; -- 重建索引
-- 验证插入结果
SELECT COUNT(*) AS total_student FROM student;
四、索引管理
索引管理是MySQL数据库性能优化的核心环节,涵盖索引的创建、查看、修改与删除四大核心操作。合理的索引管理能最大化查询效率,同时避免冗余索引对写入性能的拖累,需严格结合业务查询场景执行。
1. 创建索引
1.1 创建索引语法及解释
MySQL支持两种核心场景的索引创建方式:建表时同步创建索引,适用于表结构初始化;建表后补充创建索引,适用于业务迭代中新增查询需求的场景。两种方式的语法各有侧重,但核心参数一致。
1. 建表时创建索引语法:
CREATE TABLE table_name (
column1 datatype [constraints],
column2 datatype [constraints],
...
[PRIMARY KEY (col1, ...)],
[INDEX|KEY [index_name] (col1, ...)],
[UNIQUE [INDEX|KEY] [index_name] (col1, ...)],
[FULLTEXT [INDEX|KEY] [index_name] (col1, ...)],
[SPATIAL [INDEX|KEY] [index_name] (col1, ...)]
);
2. 建表后创建索引语法:
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
ON table_name (column_name[(length) [ASC | DESC]], ...);
或
ALTER TABLE table_name ADD [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY [index_name 1] (column_name[(length) [ASC | DESC]]),
...
ALTER TABLE table_name ADD [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY [index_name n] (column_name[(length) [ASC | DESC]]);
语法参数解释:
- UNIQUE:可选参数,指定为唯一索引,确保索引字段值不重复(允许一个空值)。
- FULLTEXT:可选参数,指定为全文索引,仅适用于CHAR、VARCHAR、TEXT类型字段,用于长文本关键词检索。
- SPATIAL:可选参数,指定为空间索引,仅适用于空间数据类型(如GEOMETRY、POINT、POLYGON等),用于地理空间数据的高效查询,仅支持MyISAM、InnoDB(MySQL 5.7+)存储引擎。
- index_name:自定义索引标识,建议遵循“前缀+字段名”规则(如idx_student_name、uk_student_no),便于识别索引类型和关联字段。
- table_name:指定要创建索引的目标表,需确保表已存在于当前数据库中。
- column_name…:索引关联的字段,联合索引需按“区分度高→区分度低”的顺序排列,提升过滤效率。
- (length):可选参数,索引字符长度,仅适用于字符串类型字段(如VARCHAR、CHAR),指定索引仅包含字段的前N个字符,用于减少索引存储空间、提升索引效率。例如
idx_name (student_name(10))表示仅对姓名的前10个字符创建索引,适用于字段值较长但前N个字符已具备高区分度的场景。 - ASC|DESC:可选参数,指定索引字段的排序方式,
ASC为升序(默认),DESC为降序。InnoDB存储引擎中,B+树索引默认升序,指定DESC仅影响索引的逻辑排序,物理存储仍为升序,主要用于优化特定排序查询(如ORDER BY 字段 DESC)。 - PRIMARY KEY:特殊索引类型,一张表仅能有一个,字段值非空且唯一,InnoDB中默认作为聚簇索引。
1.2 建表时创建索引示例
创建课程表时,同步创建主键索引、唯一索引和普通索引,适配课程编号查询、课程名称模糊查询等场景。
-- 课程表(含多种索引)
CREATE TABLE IF NOT EXISTS `course` (
course_id INT NOT NULL AUTO_INCREMENT COMMENT '课程ID(主键)',
course_no VARCHAR(20) NOT NULL COMMENT '课程编号(如CS101)',
course_name VARCHAR(100) NOT NULL COMMENT '课程名称',
credit TINYINT NOT NULL COMMENT '学分(1-6分)',
teacher_name VARCHAR(50) NOT NULL COMMENT '授课教师',
course_hours INT NOT NULL COMMENT '课时数',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间',
-- 主键索引(聚簇索引,加速课程ID查询)
PRIMARY KEY (course_id),
-- 唯一索引(保证课程编号不重复)
UNIQUE KEY uk_course_no (course_no),
-- 普通索引(加速课程名称模糊查询)
INDEX idx_course_name (course_name),
-- 联合索引(适配“教师+学分”组合查询)
INDEX idx_teacher_credit (teacher_name, credit)
)
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_general_ci
AUTO_INCREMENT = 101 -- 课程ID从101开始
COMMENT = '课程信息表';
1.3 建表后创建索引示例
以下示例基于前文创建的student(学生表),结合实际业务查询场景设计索引。
1.3.1 创建普通索引
为出生日期字段建立普通索引,加速按生日范围查询(如统计某年龄段学生)。
CREATE INDEX idx_student_birth ON student (birth_date);
1.3.2 创建唯一索引
新增联系电话字段,并创建唯一索引,确保手机号不重复(适用于登录或通知场景)。
ALTER TABLE student ADD COLUMN phone VARCHAR(15) NULL DEFAULT NULL COMMENT '联系电话';
CREATE UNIQUE INDEX uk_phone ON student (phone);
1.3.3 创建全文索引
为文本型学生信息字段添加全文索引,支持关键词模糊搜索(如查找包含“奖学金”“竞赛”等描述的学生)。
ALTER TABLE student ADD COLUMN student_info TEXT NULL DEFAULT NULL COMMENT '学生基本信息';
CREATE FULLTEXT INDEX ft_student_info ON student (student_info);
1.3.4 创建复合索引
在专业和入学时间上建立复合索引,高效支持“按专业筛选并按入学时间排序”的查询(如各专业新生列表)。
CREATE INDEX idx_major_enroll ON student (major, enroll_date);
1.3.5 用ALTER TABLE批量创建索引
在 course 表中一次性添加普通索引(按教师名查询课程)和唯一索引(确保课程名称不重复)。
ALTER TABLE course
ADD INDEX idx_course_teacher (teacher_name),
ADD UNIQUE KEY uk_course_name (course_name);
1.3.6 指定索引字符长度
对姓名字段前8个字符建立索引,在节省存储空间的同时提升按姓名前缀查询的效率(适用于中文姓名通常不超过4个汉字的场景)。
CREATE INDEX idx_student_name_short ON student (student_name(8));
1.3.7 指定降序索引
按入学时间降序建立索引,优化“最新入学学生优先”的查询性能(如首页展示最新注册学生)。
CREATE INDEX idx_enroll_date_desc ON student (enroll_date DESC);
2. 查看索引
查看索引是验证索引创建有效性、分析索引使用情况的关键操作,MySQL提供多种方式查询索引的结构、类型及关联信息,适用于不同场景。
2.1 查看索引语法及解释
常用的索引查看方式分为两类:一类是通过SHOW命令快速查看单表索引;另一类是查询系统数据字典表,支持多表索引批量筛选和精细化查询。
1. SHOW INDEX(快速查看单表索引):
SHOW INDEX|KEYS FROM 表名 [FROM 数据库名];
2. EXPLAIN(分析索引使用情况):
EXPLAIN SELECT 查询语句;
语法参数解释:
-
表名/数据库名:指定要查询的目标表和所属数据库,若未指定数据库名,默认查询当前数据库。
-
EXPLAIN:通过分析查询执行计划,判断索引是否被使用(关键看key列是否显示索引名)、扫描行数等性能指标。
2.2 查看索引示例
2.2.1 查看student表索引
SHOW INDEX FROM student;
或
SHOW KEYS FROM student;
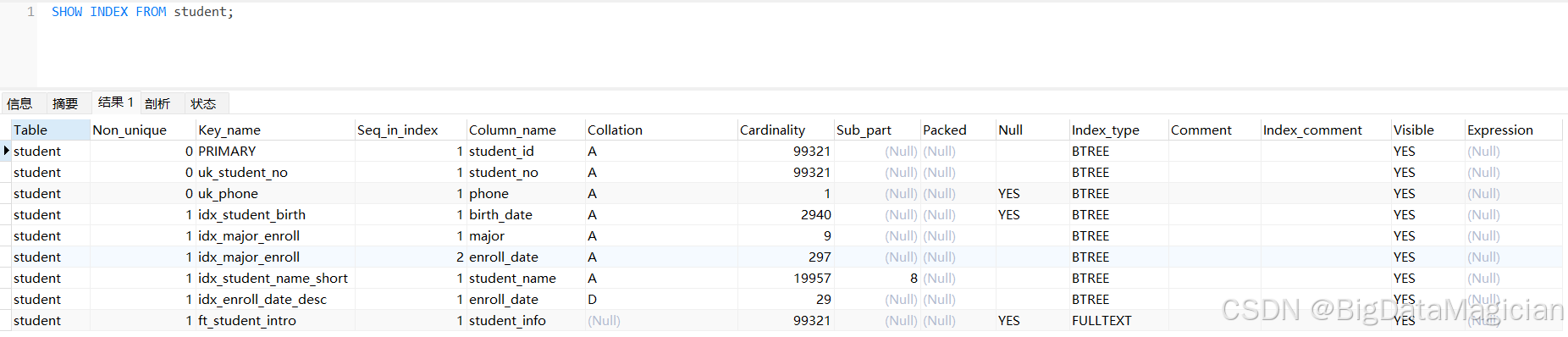
结果字段解释:
| 字段名 | 说明 |
|---|---|
| Table | 表名(此处为 student) |
| Non_unique | 是否为唯一索引: • 0:唯一索引(如主键、UNIQUE)• 1:非唯一索引(普通索引) |
| Key_name | 索引名称(如 PRIMARY、uk_student_no、idx_major_enroll) |
| Seq_in_index | 索引中列的顺序位置(复合索引中从 1 开始) |
| Column_name | 构成该索引的列名 |
| Collation | 排序方式: • A:升序(ASC)• D:降序(DESC)• (Null):未指定排序 |
| Cardinality | 索引的基数(大致表示索引中不同值的数量),值越大查询效率越高 |
| Sub_part | 如果索引只基于列的部分字符(如 student_name(8)),则显示长度;否则为 NULL |
| Packed | 是否压缩存储(通常为 YES 或 NULL) |
| Null | 是否允许 NULL 值: • YES:允许• NO:不允许 |
| Index_type | 索引类型: • BTREE:B树索引(默认,适用于等值、范围查询)• FULLTEXT:全文索引(用于文本搜索) |
| Comment | 索引注释(一般为空) |
| Index_comment | 用户自定义的索引注释(如建表时添加的 COMMENT) |
| Visible | 是否可见: • YES:可见(可被优化器使用)• NO:不可见(用于测试或临时禁用) |
| Expression | 如果是表达式索引,则显示表达式内容(MySQL 8.0+) |
2.2.2 分析索引使用情况
EXPLAIN SELECT * FROM student WHERE birth_date = '2005-12-31';

执行结果字段说明:
| 字段 | 值 | 说明 |
|---|---|---|
| id | 1 | 查询执行顺序标识,为主查询。 |
| select_type | SIMPLE | 简单查询,无子查询或联合。 |
| table | student | 操作的目标表。 |
| partitions | (Null) | 未使用分区表。 |
| type | ref | 索引引用(Index Reference) → 表示通过非唯一索引查找匹配行,效率较高。 |
| possible_keys | idx_student_birth | MySQL 认为可能使用的索引是 idx_student_birth。 |
| key | idx_student_birth | ✅ 实际使用的索引为 idx_student_birth → 索引生效! |
| key_len | 4 | 索引使用的字节数: • DATE 类型在 MySQL 中占 3 字节,但此处显示为 4 可能因存储方式或填充所致,正常范围。 |
| ref | const | 使用常量值进行索引查找(即 birth_date = '2005-12-31' 是固定值)。 |
| rows | 38 | 预估需扫描的行数(非常小),表明性能良好。 |
| filtered | 100.00 | 所有符合条件的行都被保留(无额外过滤)。 |
| Extra | (Null) | 没有额外操作,WHERE 条件中的列全部在索引中 |
如果索引未被使用,可能原因如下:
| 序号 | 原因分类 | 详细说明 | 典型表现 | 解决方案 / 建议 |
|---|---|---|---|---|
| 1 | 统计信息过期 | MySQL 优化器依赖表的统计信息(如行数、值分布)选择执行计划;若信息陈旧,可能导致错误决策。 | 新增/删除大量数据后,原本有效的索引突然不被使用。 | 执行 ANALYZE TABLE student; 更新统计信息。 |
| 2 | 索引选择性低(数据分布密集) | 索引列的重复值过多(如性别、状态字段),导致通过索引查找效率低于全表扫描。 | Cardinality 值远小于总行数(接近1或很小)。 |
避免对低区分度字段单独建索引;可考虑复合索引提升选择性。 |
| 3 | 查询返回数据比例过高 | 当 WHERE 条件匹配的行数占总行数比例较大(通常 > 20%~30%),优化器认为全表扫描更高效。 | 范围查询(如 BETWEEN、>)覆盖大量数据时索引失效。 |
缩小查询范围;或改用分页、聚合等策略减少返回量。 |
| 4 | 索引无法有效支持查询条件 | 查询使用了函数、表达式、类型转换、前导通配符(如 LIKE '%张')等,导致索引不能直接匹配。 |
WHERE YEAR(birth_date) = 2005 或 WHERE name LIKE '%张%' |
改写查询避免函数操作;使用计算列+索引;全文索引替代模糊搜索。 |
3. 修改索引
MySQL不支持直接修改索引的结构(如字段顺序、索引类型),需通过“删除旧索引+创建新索引”的组合操作实现修改效果,本质是索引的重建过程。
4. 删除索引
当索引冗余、未被使用或严重影响写入性能时,需及时删除索引。删除索引会释放磁盘空间,降低数据修改时的索引维护成本,但需谨慎操作,避免误删有效索引。
4.1 删除索引语法及解释
MySQL提供两种等价的索引删除语法,支持单索引删除和批量删除,删除前需注意主键索引的特殊限制(需先取消字段自增属性)。
1. DROP INDEX(推荐,语法简洁):
DROP INDEX 索引名 ON 表名;
2. ALTER TABLE(支持批量删除):
ALTER TABLE 表名 DROP INDEX 索引名1, DROP INDEX 索引名2, ...;
-- 特殊:删除主键索引(需先取消自增)
ALTER TABLE 表名 MODIFY 主键字段 数据类型 NOT NULL, -- 取消自增属性
DROP PRIMARY KEY;
语法参数解释:
-
索引名:需删除的索引标识,可通过SHOW INDEX查询确认。
-
主键索引删除限制:若主键字段有AUTO_INCREMENT属性,需先通过MODIFY语句取消自增,否则无法删除主键索引。
-
批量删除:ALTER TABLE支持在同一语句中删除多个索引,用逗号分隔即可。
4.2 删除索引示例
4.2.1 删除普通索引和唯一索引
删除student表中冗余的普通索引和不再需要的唯一索引。
-- 删除普通索引(idx_student_birth)
DROP INDEX idx_student_birth ON student;
-- 删除唯一索引(uk_phone)
DROP INDEX uk_phone ON student;
4.2.2 批量删除索引
用ALTER TABLE批量删除course表中的多个冗余索引。
ALTER TABLE course
DROP INDEX idx_course_teacher,
DROP INDEX idx_teacher_credit;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)