【RAG全栈】Task03:索引构建
摘要 Embedding将离散数据转化为低维向量,相似对象向量距离更近,常用余弦相似度、点积和欧氏距离衡量。RAG中,离线构建向量数据库,在线查询时计算相似度召回相关文档。多模态大模型可直接处理图像等数据,通过向量转换实现跨模态相似度计算。向量数据库(如Pinecone、Milvus)专门优化高维向量存储检索,解决传统数据库效率问题。Milvus支持多种部署模式,从Lite到分布式,满足不同规模需
1. 向量嵌入
Embedding(嵌入)是一种将离散的、高维的数据(如文字、图片、声音、视频)转换为连续的、低维的数值向量的技术。
- 核心原则:在 Embedding 构建的向量空间中,语义上相似的对象,其对应的向量在空间中的距离会更近;而语义上不相关的对象,它们的向量距离会更远。
- 关键度量:我们通常使用以下数学方法来衡量向量间的“距离”或“相似度”:
- 余弦相似度 (Cosine Similarity) :计算两个向量夹角的余弦值。值越接近 1,代表方向越一致,语义越相似。这是最常用的度量方式。
- 点积 (Dot Product) :计算两个向量的乘积和。在向量归一化后,点积等价于余弦相似度。
- 欧氏距离 (Euclidean Distance) :计算两个向量在空间中的直线距离。距离越小,语义越相似。
Embedding(嵌入)在RAG中的使用如下:
- 离线索引构建:将知识库内文档切分后,使用 Embedding 模型将每个文档块(Chunk)转换为向量,存入专门的向量数据库中。
- 在线查询检索:当用户提出问题时,使用同一个 Embedding 模型将用户的问题也转换为一个向量。
- 相似度计算:在向量数据库中,计算“问题向量”与所有“文档块向量”的相似度。
- 召回上下文:选取相似度最高的 Top-K 个文档块或者大于Top-P阈值的文档块,作为补充的上下文信息,与原始问题一同送给大语言模型(LLM)生成最终答案。
2.多模态向量嵌入
在多模态大模型出来之前处理带图片的文本,通常使用ocr对图片进行识别文字后再用文本向量模型对其识别;通过多模态大模型可以直接将图片、语音、视频等进行识别。
示例代码
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
import os
# 如果模型自动下载不了,可以用下面魔搭社区的模型链接下载
# https://www.modelscope.cn/models/BAAI/bge-visualized/files
# 检查模型文件是否存在,如果不存在则使用在线模型
model_weight_path = "../../models/bge/Visualized_base_en_v1.5.pth"
if not os.path.exists(model_weight_path):
print("本地模型权重文件未找到,使用在线BGE模型...")
# 方法1:只使用基础的BGE文本模型
model = Visualized_BGE(model_name_bge="BAAI/bge-base-en-v1.5")
else:
model = Visualized_BGE(model_name_bge="BAAI/bge-base-en-v1.5",
model_weight=model_weight_path)
model.eval()
with torch.no_grad():
text_emb = model.encode(text="datawhale开源组织的logo")
img_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png")
multi_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png", text="datawhale开源组织的logo")
img_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png")
multi_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png", text="datawhale开源组织的logo")
# 计算相似度
sim_1 = img_emb_1 @ img_emb_2.T
sim_2 = img_emb_1 @ multi_emb_1.T
sim_3 = text_emb @ multi_emb_1.T
sim_4 = multi_emb_1 @ multi_emb_2.T
print("=== 相似度计算结果 ===")
print(f"纯图像 vs 纯图像: {sim_1}")
print(f"图文结合1 vs 纯图像: {sim_2}")
print(f"图文结合1 vs 纯文本: {sim_3}")
print(f"图文结合1 vs 图文结合2: {sim_4}")
# 向量信息分析
print("\n=== 嵌入向量信息 ===")
print(f"多模态向量维度: {multi_emb_1.shape}")
print(f"图像向量维度: {img_emb_1.shape}")
print(f"多模态向量示例 (前10个元素): {multi_emb_1[0][:10]}")
print(f"图像向量示例 (前10个元素): {img_emb_1[0][:10]}")
运行效果

3.向量数据库
传统的数据库(如 MySQL)擅长处理结构化数据的精确匹配查询(例如,WHERE age = 25),但它们并非为处理高维向量的相似性搜索而设计的。在庞大的向量集合中进行暴力、线性的相似度计算,其计算成本和时间延迟无法接受。向量数据库 (Vector Database) 很好的解决了这一问题,它是一种专门设计用于高效存储、管理和查询高维向量的数据库系统。在 RAG 流程中,它扮演着“知识库”的角色,是连接数据与大语言模型的关键桥梁。
主流向量数据库:
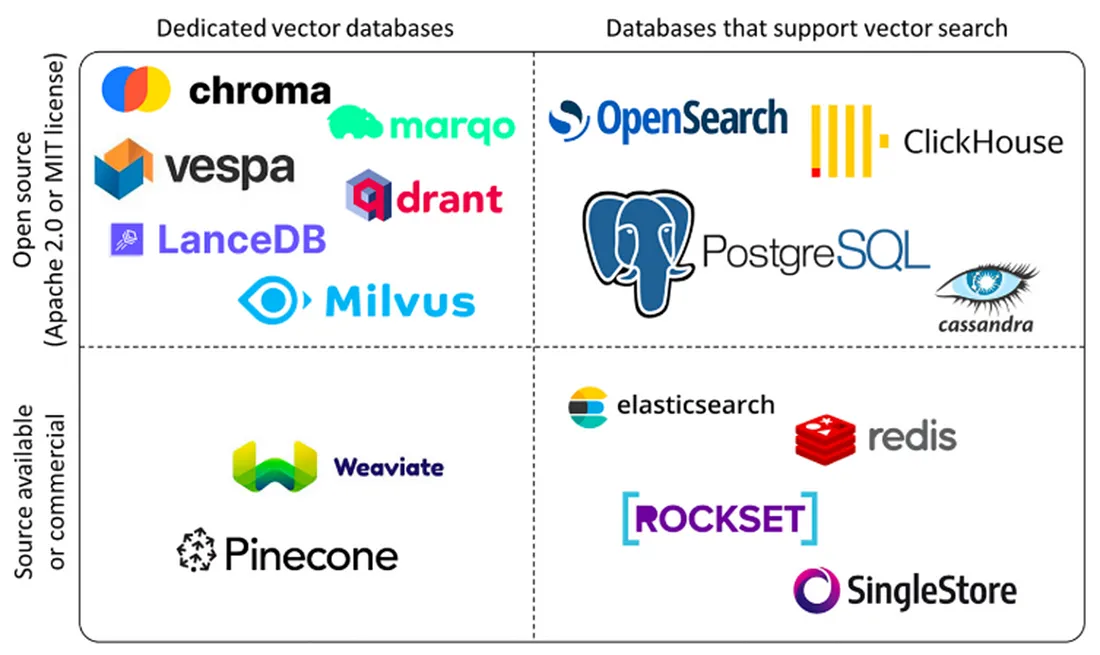
Pinecone是一款完全托管的向量数据库服务,采用Serverless架构设计。它提供存储计算分离、自动扩展和负载均衡等企业级特性,并保证99.95%的SLA。Pinecone支持多种语言SDK,提供极高可用性和低延迟搜索(<100ms),特别适合企业级生产环境、高并发场景和大规模部署。
Milvus 是一款开源的分布式向量数据库,采用分布式架构设计,支持GPU加速和多种索引算法。它能够处理亿级向量检索,提供高性能GPU加速和完善的生态系统。Milvus特别适合大规模部署、高性能要求的场景,以及需要自定义开发的开源项目。
Qdrant 是一款高性能的开源向量数据库,采用Rust开发,支持二进制量化技术。它提供多种索引策略和向量混合搜索功能,能够实现极高的性能(RPS>4000)和低延迟搜索。Qdrant特别适合性能敏感应用、高并发场景以及中小规模部署。
Weaviate 是一款支持GraphQL的AI集成向量数据库,提供20+AI模块和多模态支持。它采用GraphQL API设计,支持RAG优化,特别适合AI开发、多模态处理和快速开发场景。Weaviate具有活跃的社区支持和易于集成的特点。
Chroma 是一款轻量级的开源向量数据库,采用本地优先设计,无依赖。它提供零配置安装、本地运行和低资源消耗等特性,特别适合原型开发、教育培训和小规模应用。Chroma的部署简单,适合快速原型开发。
4.Milvus实践
Milvus 是一个开源的、专为大规模向量相似性搜索和分析而设计的向量数据库。它诞生于 Zilliz 公司,并已成为 LF AI & Data 基金会的顶级项目,在AI领域拥有广泛的应用。
与 FAISS、ChromaDB 等轻量级本地存储方案不同,Milvus 从设计之初就瞄准了生产环境。
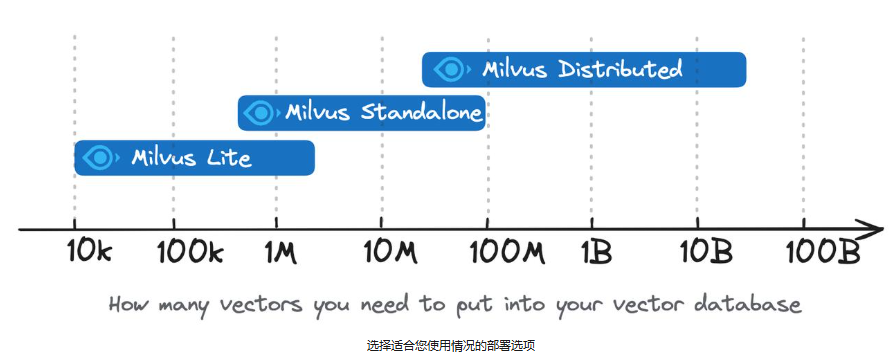
Milvus 部署模式的选择取决于项目的阶段和规模。Milvus 为从快速原型开发到大规模企业部署的各种需求提供了灵活而强大的解决方案。
Milvus Lite 建议用于较小的数据集,多达几百万个向量。
Milvus Standalone 适用于中型数据集,可扩展至 1 ~ 10亿向量。
Milvus Distributed 专为大规模部署而设计,能够处理从一亿到数百亿向量的数据集。
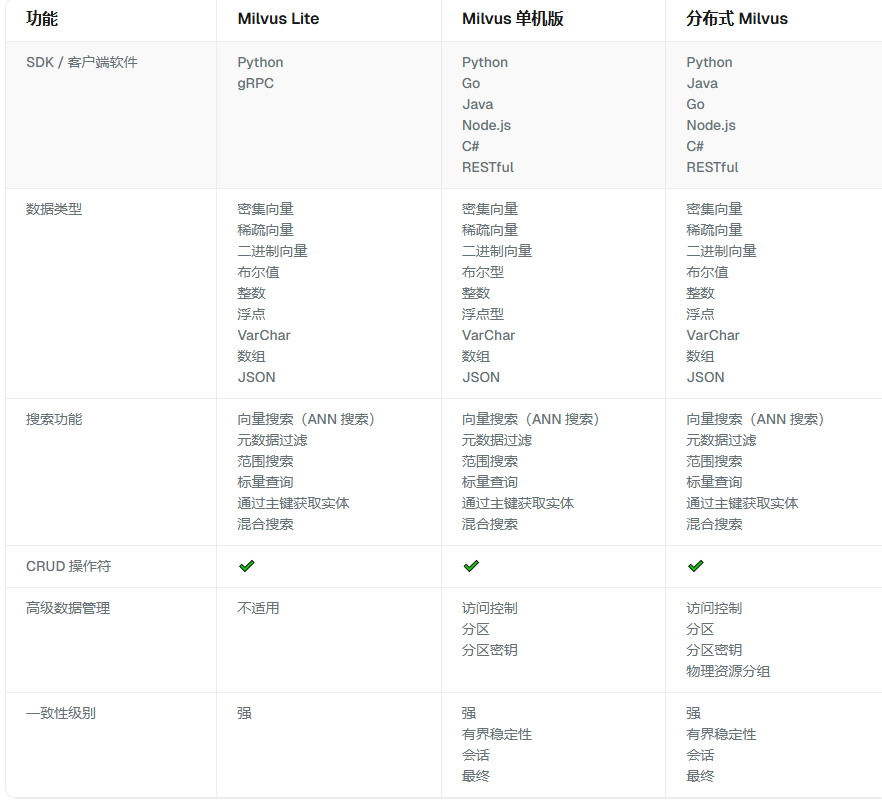
① Milvus Lite安装
Milvus Lite是一个 Python 库。
# 安装库
pip install pymilvus
pip install -U pymilvus[milvus-lite]
# 导入必要的库
from pymilvus import MilvusClient
② Milvus Standalone安装
Milvus Standalone 是单机服务器部署。
在 Docker 中安装 Milvus:
# 1. 安装Docker
#安装必要支持
sudo apt install apt-transport-https ca-certificates curl software-properties-common gnupg lsb-release
# 配置 阿里源(推荐使用阿里的gpg KEY)
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
#更新 源
sudo apt update
sudo apt-get update
#安装最新版本的Docker
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin
#等待安装完成
#查看Docker版本
sudo docker version
#查看Docker运行状态
sudo systemctl status docker
# 2. 安装Milvus
# 下载官方提供的安装脚本
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
# 安装Milvus 并且启动
bash standalone_embed.sh start
# 停止Milvus服务
bash standalone_embed.sh stop
# 删除Milvus的所有容器
bash standalone_embed.sh delete
# 3. 安装attu
docker run -d --name milvus-attu -p 8000:3000 -e MILVUS_URL=host.docker.internal:19530 zilliz/attu:v2.6
请注意,MILVUS_URL这应该是 Attu Docker 容器可以访问的地址。因此,“127.0.0.1” 或 “localhost” 将不起作用。
网页链接:http://localhost:8000/
数据库连接代码: client = MilvusClient(uri="http://127.0.0.1:19530")运行服务后,访问 Milvus WebUI,网址是 http://127.0.0.1:8000
③ Milvus操作示例
import os
from tqdm import tqdm
from glob import glob
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
from pymilvus import MilvusClient, FieldSchema, CollectionSchema, DataType
import numpy as np
import cv2
from PIL import Image
# 1. 初始化设置
MODEL_NAME = "BAAI/bge-base-en-v1.5"
MODEL_PATH = "../../models/bge/Visualized_base_en_v1.5.pth"
DATA_DIR = "../../data/C3"
COLLECTION_NAME = "multimodal_demo"
MILVUS_URI = "http://localhost:19530"
# 2. 定义工具 (编码器和可视化函数)
class Encoder:
"""编码器类,用于将图像和文本编码为向量。"""
def __init__(self, model_name: str, model_path: str):
self.model = Visualized_BGE(model_name_bge=model_name, model_weight=model_path)
self.model.eval()
def encode_query(self, image_path: str, text: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=image_path, text=text)
return query_emb.tolist()[0]
def encode_image(self, image_path: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=image_path)
return query_emb.tolist()[0]
def visualize_results(query_image_path: str, retrieved_images: list, img_height: int = 300, img_width: int = 300, row_count: int = 3) -> np.ndarray:
"""从检索到的图像列表创建一个全景图用于可视化。"""
panoramic_width = img_width * row_count
panoramic_height = img_height * row_count
panoramic_image = np.full((panoramic_height, panoramic_width, 3), 255, dtype=np.uint8)
query_display_area = np.full((panoramic_height, img_width, 3), 255, dtype=np.uint8)
# 处理查询图像
query_pil = Image.open(query_image_path).convert("RGB")
query_cv = np.array(query_pil)[:, :, ::-1]
resized_query = cv2.resize(query_cv, (img_width, img_height))
bordered_query = cv2.copyMakeBorder(resized_query, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=(255, 0, 0))
query_display_area[img_height * (row_count - 1):, :] = cv2.resize(bordered_query, (img_width, img_height))
cv2.putText(query_display_area, "Query", (10, panoramic_height - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
# 处理检索到的图像
for i, img_path in enumerate(retrieved_images):
row, col = i // row_count, i % row_count
start_row, start_col = row * img_height, col * img_width
retrieved_pil = Image.open(img_path).convert("RGB")
retrieved_cv = np.array(retrieved_pil)[:, :, ::-1]
resized_retrieved = cv2.resize(retrieved_cv, (img_width - 4, img_height - 4))
bordered_retrieved = cv2.copyMakeBorder(resized_retrieved, 2, 2, 2, 2, cv2.BORDER_CONSTANT, value=(0, 0, 0))
panoramic_image[start_row:start_row + img_height, start_col:start_col + img_width] = bordered_retrieved
# 添加索引号
cv2.putText(panoramic_image, str(i), (start_col + 10, start_row + 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
return np.hstack([query_display_area, panoramic_image])
# 3. 初始化客户端
print("--> 正在初始化编码器和Milvus客户端...")
encoder = Encoder(MODEL_NAME, MODEL_PATH)
milvus_client = MilvusClient(uri=MILVUS_URI)
# 4. 创建 Milvus Collection
print(f"\n--> 正在创建 Collection '{COLLECTION_NAME}'")
if milvus_client.has_collection(COLLECTION_NAME):
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除已存在的 Collection: '{COLLECTION_NAME}'")
image_list = glob(os.path.join(DATA_DIR, "dragon", "*.png"))
if not image_list:
raise FileNotFoundError(f"在 {DATA_DIR}/dragon/ 中未找到任何 .png 图像。")
dim = len(encoder.encode_image(image_list[0]))
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim),
FieldSchema(name="image_path", dtype=DataType.VARCHAR, max_length=512),
]
# 创建集合 Schema
schema = CollectionSchema(fields, description="多模态图文检索")
print("Schema 结构:")
print(schema)
# 创建集合
milvus_client.create_collection(collection_name=COLLECTION_NAME, schema=schema)
print(f"成功创建 Collection: '{COLLECTION_NAME}'")
print("Collection 结构:")
print(milvus_client.describe_collection(collection_name=COLLECTION_NAME))
# 5. 准备并插入数据
print(f"\n--> 正在向 '{COLLECTION_NAME}' 插入数据")
data_to_insert = []
for image_path in tqdm(image_list, desc="生成图像嵌入"):
vector = encoder.encode_image(image_path)
data_to_insert.append({"vector": vector, "image_path": image_path})
if data_to_insert:
result = milvus_client.insert(collection_name=COLLECTION_NAME, data=data_to_insert)
print(f"成功插入 {result['insert_count']} 条数据。")
# 6. 创建索引
print(f"\n--> 正在为 '{COLLECTION_NAME}' 创建索引")
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="HNSW",
metric_type="COSINE",
params={"M": 16, "efConstruction": 256}
)
milvus_client.create_index(collection_name=COLLECTION_NAME, index_params=index_params)
print("成功为向量字段创建 HNSW 索引。")
print("索引详情:")
print(milvus_client.describe_index(collection_name=COLLECTION_NAME, index_name="vector"))
milvus_client.load_collection(collection_name=COLLECTION_NAME)
print("已加载 Collection 到内存中。")
# 7. 执行多模态检索
print(f"\n--> 正在 '{COLLECTION_NAME}' 中执行检索")
query_image_path = os.path.join(DATA_DIR, "dragon", "query.png")
query_text = "一条龙"
query_vector = encoder.encode_query(image_path=query_image_path, text=query_text)
search_results = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[query_vector],
output_fields=["image_path"],
limit=5,
search_params={"metric_type": "COSINE", "params": {"ef": 128}}
)[0]
retrieved_images = []
print("检索结果:")
for i, hit in enumerate(search_results):
print(f" Top {i+1}: ID={hit['id']}, 距离={hit['distance']:.4f}, 路径='{hit['entity']['image_path']}'")
retrieved_images.append(hit['entity']['image_path'])
# 8. 可视化与清理
print(f"\n--> 正在可视化结果并清理资源")
if not retrieved_images:
print("没有检索到任何图像。")
else:
panoramic_image = visualize_results(query_image_path, retrieved_images)
combined_image_path = os.path.join(DATA_DIR, "search_result.png")
cv2.imwrite(combined_image_path, panoramic_image)
print(f"结果图像已保存到: {combined_image_path}")
Image.open(combined_image_path).show()
milvus_client.release_collection(collection_name=COLLECTION_NAME)
print(f"已从内存中释放 Collection: '{COLLECTION_NAME}'")
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除 Collection: '{COLLECTION_NAME}'")
运行结果

5.索引优化
| 检索类型 | 核心技术 | 优势 | 劣势 | 最佳适用场景 |
|---|---|---|---|---|
| MULTIMODAL | 多模态向量 | 综合理解图文信息 | 计算复杂度高 | 结合图像和文本的多模态向量检索 |
| DENSE | 语义向量 | 深层语义理解 | 可能忽略关键词 | 基于语义的密集向量检索 |
| SPARSE | 关键词匹配 | 速度快、简单 | 语义理解差 | 基于关键词的稀疏向量检索 |
| HYBRID | 融合技术 | 平衡多种方法 | 参数调优复杂 | 稀疏+密集向量RRF融合检索 |
基于上述4种检索,示例代码
import json
import os
from tqdm import tqdm
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
from pymilvus import connections, MilvusClient, FieldSchema, CollectionSchema, DataType, Collection, AnnSearchRequest, RRFRanker
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
import numpy as np
import cv2
from PIL import Image
from typing import List, Dict, Any
from dataclasses import dataclass
# 设置环境变量使用国内镜像
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
@dataclass
class DragonImage:
"""龙类图像数据类"""
img_id: str
path: str
title: str
description: str
category: str
location: str
environment: str
combat_details: Dict[str, Any] = None
scene_info: Dict[str, Any] = None
class DragonDataset:
"""龙类图像数据集管理类"""
def __init__(self, data_dir: str, metadata_path: str):
self.data_dir = data_dir
self.metadata_path = metadata_path
self.images: List[DragonImage] = []
self._load_metadata()
def _load_metadata(self):
"""加载图像元数据"""
with open(self.metadata_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for img_data in data:
# 确保图片路径是完整的
if not img_data['path'].startswith(self.data_dir):
img_data['path'] = os.path.join(self.data_dir, img_data['path'].split('/')[-1])
self.images.append(DragonImage(**img_data))
def get_text_content(self, img: DragonImage) -> str:
"""获取图像的文本描述内容"""
parts = [
img.title, img.description,
img.location, img.environment
]
if img.combat_details:
parts.extend(img.combat_details.get('combat_style', []))
parts.extend(img.combat_details.get('abilities_used', []))
if img.scene_info:
parts.append(img.scene_info.get('time_of_day', ''))
return ' '.join(filter(None, parts))
class HybridMultimodalEncoder:
"""混合多模态编码器类"""
def __init__(self, visual_model_name: str, visual_model_path: str):
# 初始化Visual-BGE模型(用于多模态)
self.visual_model = Visualized_BGE(model_name_bge=visual_model_name, model_weight=visual_model_path)
self.visual_model.eval()
# 初始化BGE-M3模型(用于混合检索)
self.bge_m3 = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
print(f"BGE-M3 密集向量维度: {self.bge_m3.dim['dense']}")
def encode_multimodal(self, image_path: str, text: str) -> list[float]:
"""编码多模态内容(图像+文本)"""
with torch.no_grad():
query_emb = self.visual_model.encode(image=image_path, text=text)
return query_emb.tolist()[0]
def encode_text_hybrid(self, text: str) -> dict:
"""使用BGE-M3编码文本,返回稀疏和密集向量"""
embeddings = self.bge_m3([text])
return {
'sparse': embeddings["sparse"],
'dense': embeddings["dense"]
}
def encode_query(self, image_path: str = None, text: str = None, mode: str = "multimodal") -> dict:
"""编码查询,支持多种模式"""
result = {}
if mode in ["multimodal", "all"] and image_path and text:
result['multimodal'] = self.encode_multimodal(image_path, text)
if mode in ["hybrid", "dense", "sparse", "all"] and text:
text_embeddings = self.encode_text_hybrid(text)
result['dense'] = text_embeddings['dense'][0]
result['sparse'] = text_embeddings['sparse']._getrow(0)
return result
def visualize_results(query_image_path: str, retrieved_results: list, search_mode: str,
img_height: int = 300, img_width: int = 300, row_count: int = 3) -> np.ndarray:
"""从检索到的结果创建一个全景图用于可视化"""
panoramic_width = img_width * row_count
panoramic_height = img_height * row_count
panoramic_image = np.full((panoramic_height, panoramic_width, 3), 255, dtype=np.uint8)
query_display_area = np.full((panoramic_height, img_width, 3), 255, dtype=np.uint8)
# 处理查询图像
if query_image_path and os.path.exists(query_image_path):
query_pil = Image.open(query_image_path).convert("RGB")
query_cv = np.array(query_pil)[:, :, ::-1]
resized_query = cv2.resize(query_cv, (img_width, img_height))
bordered_query = cv2.copyMakeBorder(resized_query, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=(255, 0, 0))
query_display_area[img_height * (row_count - 1):, :] = cv2.resize(bordered_query, (img_width, img_height))
cv2.putText(query_display_area, "Query", (10, panoramic_height - 40), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 0, 0), 2)
cv2.putText(query_display_area, search_mode, (10, panoramic_height - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 100, 0), 2)
# 处理检索到的图像
for i, result in enumerate(retrieved_results):
row, col = i // row_count, i % row_count
start_row, start_col = row * img_height, col * img_width
img_path = result['image_path']
retrieved_pil = Image.open(img_path).convert("RGB")
retrieved_cv = np.array(retrieved_pil)[:, :, ::-1]
resized_retrieved = cv2.resize(retrieved_cv, (img_width - 4, img_height - 4))
bordered_retrieved = cv2.copyMakeBorder(resized_retrieved, 2, 2, 2, 2, cv2.BORDER_CONSTANT, value=(0, 0, 0))
panoramic_image[start_row:start_row + img_height, start_col:start_col + img_width] = bordered_retrieved
# 添加索引号和相似度
cv2.putText(panoramic_image, f"{i+1}", (start_col + 10, start_row + 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
cv2.putText(panoramic_image, f"{result['distance']:.3f}", (start_col + 10, start_row + img_height - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
return np.hstack([query_display_area, panoramic_image])
class HybridMultimodalSearcher:
"""混合多模态搜索系统"""
def __init__(self, data_dir: str, metadata_path: str, collection_name: str, milvus_uri: str):
self.data_dir = data_dir
self.metadata_path = metadata_path
self.collection_name = collection_name
self.milvus_uri = milvus_uri
# 初始化数据集和编码器
print("--> 正在初始化数据集...")
self.dataset = DragonDataset(data_dir, metadata_path)
print(f"加载了 {len(self.dataset.images)} 张龙类图像")
print("--> 正在初始化混合多模态编码器...")
self.encoder = HybridMultimodalEncoder(
visual_model_name="BAAI/bge-base-en-v1.5",
visual_model_path="../../models/bge/Visualized_base_en_v1.5.pth"
)
# 连接Milvus
print(f"--> 正在连接到 Milvus: {milvus_uri}")
connections.connect(uri=milvus_uri)
self.milvus_client = MilvusClient(uri=milvus_uri)
# 连接本地 Milvus
# print(f"--> 正在连接到本地 Milvus 数据库: {milvus_uri}")
# self.milvus_client=MilvusClient(milvus_uri)
# print("✓ Milvus 连接成功")
self.collection = None
def create_collection(self):
"""创建Collection"""
print(f"--> 正在创建 Collection '{self.collection_name}'")
if self.milvus_client.has_collection(self.collection_name):
self.milvus_client.drop_collection(self.collection_name)
print(f"已删除已存在的 Collection: '{self.collection_name}'")
# 获取向量维度
sample_text = self.dataset.get_text_content(self.dataset.images[0])
sample_path = self.dataset.images[0].path
multimodal_dim = len(self.encoder.encode_multimodal(sample_path, sample_text))
dense_dim = self.encoder.bge_m3.dim["dense"]
print(f"多模态向量维度: {multimodal_dim}")
print(f"密集向量维度: {dense_dim}")
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="img_id", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="image_path", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=256),
FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=4096),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=64),
FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=128),
FieldSchema(name="environment", dtype=DataType.VARCHAR, max_length=64),
# 三种向量类型
FieldSchema(name="multimodal_vector", dtype=DataType.FLOAT_VECTOR, dim=multimodal_dim),
FieldSchema(name="text_sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="text_dense_vector", dtype=DataType.FLOAT_VECTOR, dim=dense_dim)
]
schema = CollectionSchema(fields, description="混合多模态龙类图像检索")
self.collection = Collection(name=self.collection_name, schema=schema, consistency_level="Strong")
print("--> Collection 创建成功")
# 创建索引
print("--> 正在创建索引...")
# 多模态向量索引
multimodal_index = {"index_type": "HNSW", "metric_type": "COSINE", "params": {"M": 16, "efConstruction": 256}}
self.collection.create_index("multimodal_vector", multimodal_index)
print("多模态向量索引创建成功")
# 稀疏向量索引
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
self.collection.create_index("text_sparse_vector", sparse_index)
print("稀疏向量索引创建成功")
# 密集向量索引
dense_index = {"index_type": "AUTOINDEX", "metric_type": "IP"}
self.collection.create_index("text_dense_vector", dense_index)
print("密集向量索引创建成功")
self.collection.load()
print(f"--> Collection '{self.collection_name}' 已加载到内存")
def insert_data(self):
"""插入数据"""
if self.collection.is_empty:
print("--> Collection 为空,开始插入数据...")
# 准备批量数据
img_ids, image_paths, titles, descriptions = [], [], [], []
categories, locations, environments = [], [], []
multimodal_vectors, text_sparse_vectors, text_dense_vectors = [], [], []
for img_data in tqdm(self.dataset.images, desc="生成向量嵌入"):
text_content = self.dataset.get_text_content(img_data)
# 生成多模态向量(图像+文本)
multimodal_vector = self.encoder.encode_multimodal(img_data.path, text_content)
# 生成文本的混合向量(稀疏+密集)
text_embeddings = self.encoder.encode_text_hybrid(text_content)
# 收集数据
img_ids.append(img_data.img_id)
image_paths.append(img_data.path)
titles.append(img_data.title)
descriptions.append(img_data.description)
categories.append(img_data.category)
locations.append(img_data.location)
environments.append(img_data.environment)
multimodal_vectors.append(multimodal_vector)
text_sparse_vectors.append(text_embeddings['sparse']._getrow(0))
text_dense_vectors.append(text_embeddings['dense'][0])
# 插入数据
self.collection.insert([
img_ids, image_paths, titles, descriptions, categories, locations, environments,
multimodal_vectors, text_sparse_vectors, text_dense_vectors
])
self.collection.flush()
print(f"--> 数据插入完成,总数: {self.collection.num_entities}")
else:
print(f"--> Collection 中已有 {self.collection.num_entities} 条数据,跳过插入")
def search(self, query_image_path: str, query_text: str, mode: str = "hybrid", top_k: int = 5) -> list:
"""执行搜索"""
search_params = {"metric_type": "IP", "params": {}}
cosine_params = {"metric_type": "COSINE", "params": {"ef": 128}}
output_fields = ["img_id", "image_path", "title", "description", "category", "location", "environment"]
if mode == "multimodal":
# 多模态检索
query_vector = self.encoder.encode_multimodal(query_image_path, query_text)
results = self.collection.search(
[query_vector], "multimodal_vector", param=cosine_params,
limit=top_k, output_fields=output_fields
)[0]
elif mode == "dense":
# 密集向量检索
query_embeddings = self.encoder.encode_text_hybrid(query_text)
dense_vec = query_embeddings['dense'][0]
results = self.collection.search(
[dense_vec], "text_dense_vector", param=search_params,
limit=top_k, output_fields=output_fields
)[0]
elif mode == "sparse":
# 稀疏向量检索
query_embeddings = self.encoder.encode_text_hybrid(query_text)
sparse_vec = query_embeddings['sparse']._getrow(0)
results = self.collection.search(
[sparse_vec], "text_sparse_vector", param=search_params,
limit=top_k, output_fields=output_fields
)[0]
elif mode == "hybrid":
# 混合检索(稀疏+密集)
query_embeddings = self.encoder.encode_text_hybrid(query_text)
dense_vec = query_embeddings['dense'][0]
sparse_vec = query_embeddings['sparse']._getrow(0)
# 创建RRF融合器
rerank = RRFRanker(k=60)
# 创建搜索请求
dense_req = AnnSearchRequest([dense_vec], "text_dense_vector", search_params, limit=top_k)
sparse_req = AnnSearchRequest([sparse_vec], "text_sparse_vector", search_params, limit=top_k)
# 执行混合搜索
results = self.collection.hybrid_search(
[sparse_req, dense_req], rerank=rerank, limit=top_k, output_fields=output_fields
)[0]
return results
def compare_search_modes(self, query_image_path: str, query_text: str, top_k: int = 5):
"""对比不同搜索模式的效果"""
modes = ["multimodal", "dense", "sparse", "hybrid"]
results = {}
print(f"\n{'='*50}")
print(f"查询图像: {query_image_path}")
print(f"查询文本: {query_text}")
print(f"{'='*50}")
for mode in modes:
print(f"\n--- [{mode.upper()}] 搜索结果 ---")
search_results = self.search(query_image_path, query_text, mode, top_k)
mode_results = []
for i, hit in enumerate(search_results):
print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")
print(f" 路径: {hit.entity.get('image_path')}")
print(f" 描述: {hit.entity.get('description')[:80]}...")
mode_results.append({
'image_path': hit.entity.get('image_path'),
'distance': hit.distance,
'title': hit.entity.get('title')
})
results[mode] = mode_results
return results
def visualize_comparison(self, query_image_path: str, query_text: str, top_k: int = 3):
"""可视化对比不同搜索模式"""
modes = ["multimodal", "dense", "sparse", "hybrid"]
for mode in modes:
results = self.search(query_image_path, query_text, mode, top_k)
retrieved_results = []
for hit in results:
retrieved_results.append({
'image_path': hit.entity.get('image_path'),
'distance': hit.distance
})
if retrieved_results:
panoramic_image = visualize_results(query_image_path, retrieved_results, mode.upper())
output_path = f"../../data/C4/{mode}_search_result.png"
cv2.imwrite(output_path, panoramic_image)
print(f"{mode.upper()} 搜索结果已保存到: {output_path}")
def cleanup(self):
"""清理资源"""
if self.collection:
self.collection.release()
print(f"已从内存中释放 Collection: '{self.collection_name}'")
self.milvus_client.drop_collection(self.collection_name)
print(f"已删除 Collection: '{self.collection_name}'")
# 主程序
if __name__ == "__main__":
# 初始化设置
DATA_DIR = "../../data/C3/dragon"
METADATA_PATH = "../../data/C4/metadata/dragon.json"
COLLECTION_NAME = "hybrid_multimodal_dragon_demo"
MILVUS_URI = "http://localhost:19530"
# MILVUS_URI="./milvus_data.db" # 本地数据库文件路径
# 创建混合多模态搜索系统
searcher = HybridMultimodalSearcher(DATA_DIR, METADATA_PATH, COLLECTION_NAME, MILVUS_URI)
try:
# 创建Collection并插入数据
searcher.create_collection()
searcher.insert_data()
# 执行搜索对比
query_image_path = os.path.join(DATA_DIR, "query.png")
query_text = "悬崖上的巨龙"
# 对比不同搜索模式
results = searcher.compare_search_modes(query_image_path, query_text, top_k=3)
# 可视化结果
searcher.visualize_comparison(query_image_path, query_text, top_k=3)
print(f"\n{'='*50}")
print("搜索模式分析:")
print("- MULTIMODAL: 结合图像和文本的多模态向量检索")
print("- DENSE: 基于语义的密集向量检索")
print("- SPARSE: 基于关键词的稀疏向量检索")
print("- HYBRID: 稀疏+密集向量RRF融合检索")
print(f"{'='*50}")
finally:
# 清理资源
searcher.cleanup() 执行结果如下:
--- [MULTIMODAL] 搜索结果 ---
1. 悬崖上的白龙 (Score: 0.7278)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.6551)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 霸王龙的怒吼 (Score: 0.6429)
路径: ../../data/C3/dragon/dragon03.png
描述: 史前时代的霸王龙张开血盆大口,发出震天的怒吼。在它身后,几只翼龙在阴沉的天空中盘旋,展现了白垩纪的原始力量。...--- [DENSE] 搜索结果 ---
1. 悬崖上的白龙 (Score: 0.7214)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.5353)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 驯龙高手:无牙仔 (Score: 0.5231)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...--- [SPARSE] 搜索结果 ---
1. 悬崖上的白龙 (Score: 0.2254)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 奔跑的奶龙 (Score: 0.0962)
路径: ../../data/C3/dragon/dragon04.png
描述: 一只Q版的黄色小恐龙,有着大大的绿色眼睛和友善的微笑。是一部动画中的角色,非常可爱。...
3. 中华金龙 (Score: 0.0857)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...--- [HYBRID] 搜索结果 ---
1. 悬崖上的白龙 (Score: 0.0328)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.0320)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 奔跑的奶龙 (Score: 0.0161)
路径: ../../data/C3/dragon/dragon04.png
描述: 一只Q版的黄色小恐龙,有着大大的绿色眼睛和友善的微笑。是一部动画中的角色,非常可爱。...

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)